

Kubernetes Engine (основанный на Kubernetes сервис для запуска контейнеризированных приложений в Google Cloud — прим. перев.) — один из лучших способов запуска рабочих нагрузок, нуждающихся в масштабировании. Kubernetes обеспечит беспроблемное функционирование большинства приложений, если они контейнеризированы. Но если вы хотите, чтобы приложением было легко управлять, и хотите воспользоваться всеми преимуществами Kubernetes, необходимо следовать лучшим практикам. Они упростят эксплуатацию приложения, его мониторинг и отладку, а также повысят безопасность.
В этой статье мы пройдёмся по списку того, что стоит знать и делать для эффективного функционирования контейнеров в Kubernetes. Желающим углубиться в детали стоит прочитать материал Best Practices for Operating Containers, а также обратить внимание на наш более ранний пост о сборке контейнеров.
1. Используйте родные механизмы контейнеров для логирования
Если приложение запущено в кластере Kubernetes, для логов нужно не так много. Централизованная система логирования, вероятно, уже встроена в используемый кластер. В случае использования Kubernetes Engine за это отвечает Stackdriver Logging. (Прим. перев.: А в случае использования собственной инсталляции Kubernetes рекомендуем присмотреться к нашему Open Source-решению — loghouse.) Не усложняйте себе жизнь и используйте родные механизмы журналирования контейнеров. Пишите логи в stdout и stderr — они будут автоматически получены, сохранены и проиндексированы.
При желании можно также писать логи в формате JSON. Такой подход позволит легко добавлять к ним метаданные. А вместе с ними в Stackdriver Logging появится возможность поиска по логам с использованием этих метаданных.
2. Убедитесь, что контейнеры — stateless и immutable
Для корректного функционирования контейнеров в кластере Kubernetes они должны быть stateless и immutable. Когда эти условия выполнены, Kubernetes сможет выполнять свою работу, создавая и уничтожая сущности приложения, когда и где это необходимо.
Stateless означает, что любое состояние (постоянные данные любого вида) хранятся вне контейнера. Для этого, в зависимости от потребностей, могут быть задействованы разные виды внешних хранилищ: Cloud Storage, Persistent Disks, Redis, Cloud SQL или другие управляемые базы данных. (Прим. перев.: Подробнее об этом читайте также в нашей статье «Операторы для Kubernetes: как запускать stateful-приложения».)
Immutable означает, что контейнер не будет модифицирован во время своей жизни: никаких обновлений, патчей, изменений в конфигурации. Если вам нужно обновить код приложения или применить патч, создайте новый образ и задеплойте его. Рекомендуется выносить конфигурацию контейнера (порт для прослушивания, опции исполняемой среды и т.п.) вовне — в Secrets и ConfigMaps. Их можно обновлять без необходимости собирать новый образ контейнера. Для простого создания пайплайнов со сборкой образов можно использовать Cloud Build. (Прим. перев.: Мы для этих целей используем Open Source-инструмент dapp.)
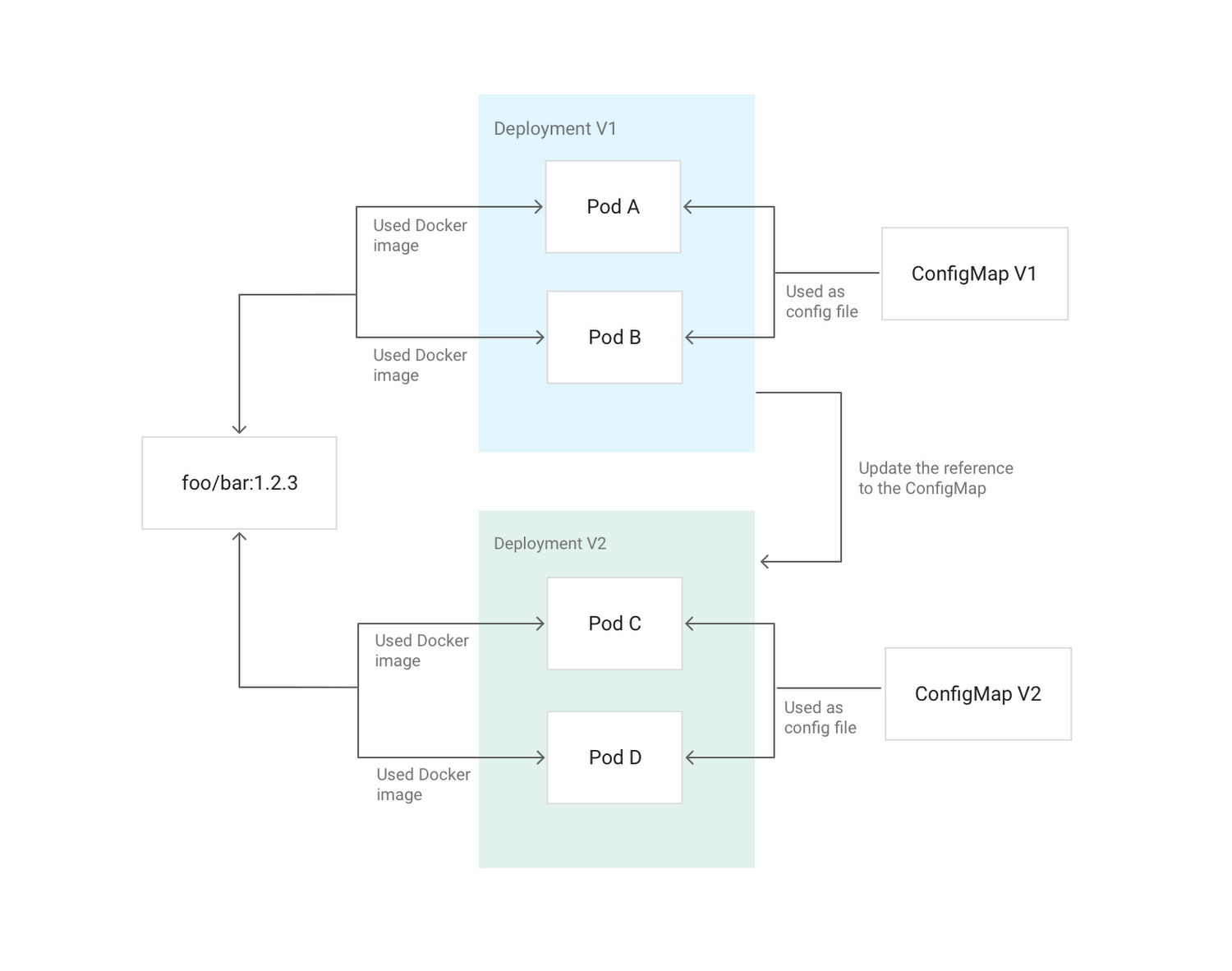
Пример обновления конфигурации Deployment в Kubernetes с помощью ConfigMap, примонтированного в поды в качестве конфига
3. Избегайте привилегированных контейнеров
Вы ведь не запускаете приложения под root'ом на своих серверах, верно? Если злоумышленник проникнет в приложение, он получит доступ с правами root. Те же соображения справедливы и для того, чтобы не запускать привилегированные контейнеры. Если требуется изменять настройки на хосте, можно выдать контейнеру конкретные capabilities с помощью опции
securityContext в Kubernetes. Если требуется изменять sysctls, у Kubernetes есть отдельная аннотация для этого. А вообще, старайтесь максимально использовать init- и sidecar-контейнеры для выполнения подобных привилегированных операций. Они не нуждаются в доступности ни для внутреннего, ни для внешнего трафика.Если вы администрируете кластер, можете воспользоваться Pod Security Policy для ограничений в применении привилегированных контейнеров.
4. Избегайте запуска под root
О привилегированных контейнерах уже сказано, но будет ещё лучше, если в дополнение к этому вы не будете запускать под root'ом приложения внутри контейнера. Если злоумышленник найдёт в приложении с правами root удалённую уязвимость с возможностью исполнения кода, после чего сможет выйти из пределов контейнера через пока ещё неизвестную уязвимость, то получит root'а на хосте.
Лучший путь избежать этого — в первую очередь не запускать ничего под root'ом. Для этого можно воспользоваться директивой
USER в Dockerfile или runAsUser в Kubernetes. Администратор кластера может также настроить принудительное поведение с помощью Pod Security Policy.5. Сделайте приложение простым для мониторинга
Как и логирование, мониторинг — неотъемлемая часть управления приложением. Популярным решением для мониторинга в сообществе Kubernetes является Prometheus — система, которая автоматически обнаруживает поды и сервисы, требующие мониторинга. (Прим. перев.: См. также наш подробный доклад по теме мониторинга с помощью Prometheus и Kubernetes.) Stackdriver способен мониторить кластеры Kubernetes и включает в себя свою версию Prometheus для мониторинга приложений.
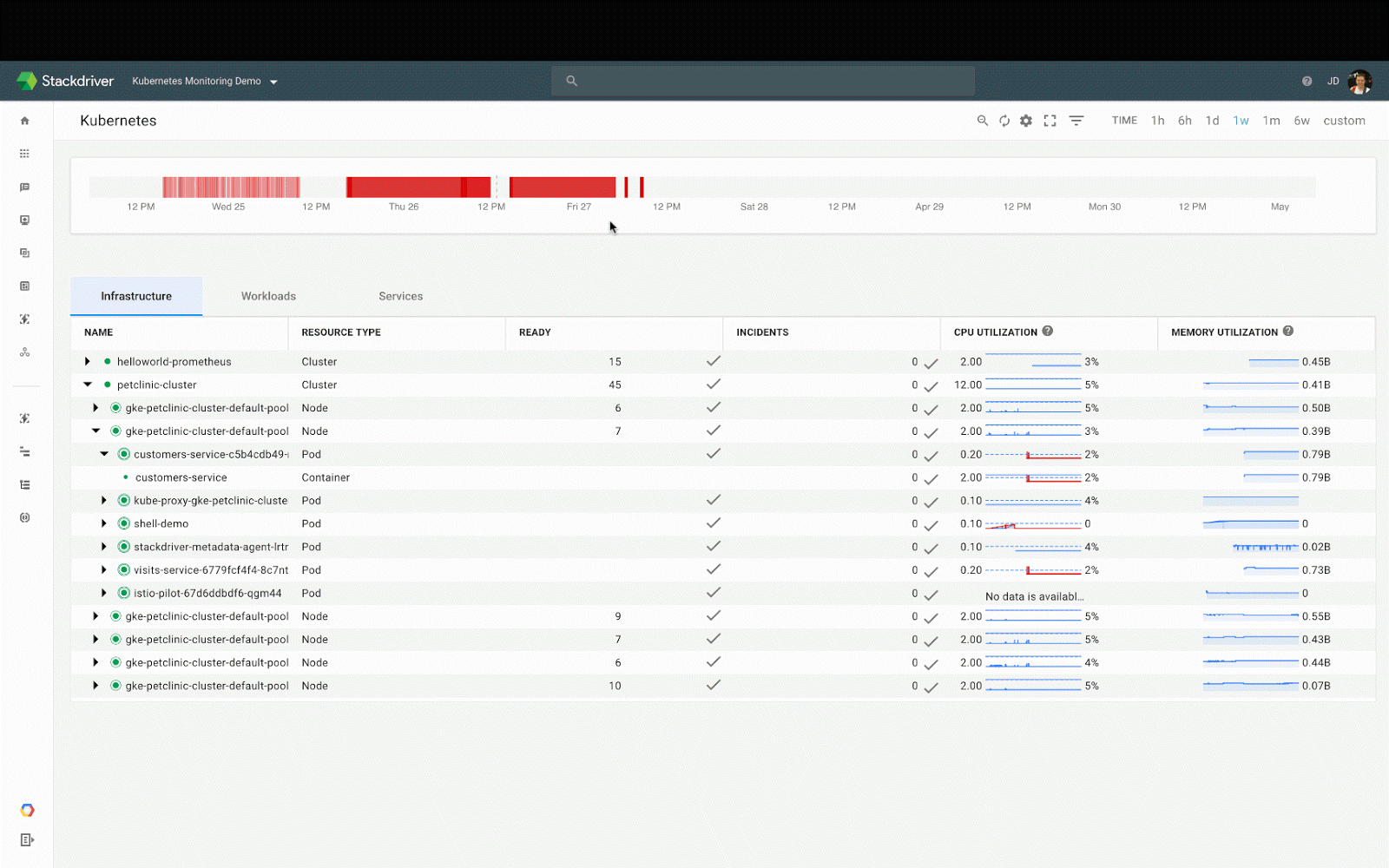
Панель мониторинга Kubernetes в Stackdriver
Prometheus ожидает, что приложение пробросит метрики на HTTP endpoint. Для этого доступны клиентские библиотеки Prometheus. Такой же формат используют другие инструменты вроде OpenCensus и Istio.
6. Сделайте доступным состояние здоровья приложения
Управлению приложением в production помогает его способность сообщать о своём состоянии всей системе. Запущено ли приложение? В порядке ли оно? Готово ли принимать трафик? Как себя ведёт? Наиболее распространённым способом решения этой проблемы является реализация проверок здоровья (health checks). У Kubernetes есть два их типа: liveness и readiness probes.
Для liveness probe (проверки на жизнеспособность) приложение должно иметь HTTP endpoint, возвращающий ответ «200 OK», если оно функционирует и его основные зависимости удовлетворены. Для readiness probe (проверки на готовность к обслуживанию) приложение должно иметь другой HTTP endpoint, возвращающий ответ «200 OK», если приложение находится в здоровом состоянии, шаги по инициализации выполнены и любой корректный запрос не приводит к ошибке. Kubernetes будет направлять трафик на контейнер только в случае готовности приложения в соответствии с этими проверками. Два endpoint'а могут объединены, если разница между состояниями жизнеспособности (liveness) и готовности (readiness) нет.
Подробнее об этом можно прочитать в соответствующей статье от Sandeep Dinesh, Developer Advocate из Google: «Kubernetes best practices: Setting up health checks with readiness and liveness probes».
7. Внимательно выбирайте версию образа
Большинство публичных и приватных образов используют систему тегирования, похожую на описанную в Best Practices for Building Containers. Если образ применяет систему, близкую к семантическому версионированию, необходимо учитывать специфику тегирования. Например, тег
latest может часто перемещаться с образа на образ — на него нельзя полагаться, если вам нужны предсказуемые и воспроизводимые сборки и инсталляции.Можете использовать тег
X.Y.Z (они почти всегда неизменны), однако в таком случае отслеживайте все патчи и обновления к образу. Если у используемого образа есть тег X.Y, это хороший вариант золотой середины. Выбрав его, вы автоматически получаете патчи и в то же время опираетесь на стабильную версию приложения.P.S. от переводчика
Читайте также в нашем блоге:
- «Новая статистика CNCF о контейнерах, cloud native и Kubernetes»;
- «7 принципов проектирования приложений, основанных на контейнерах»;
- «11 способов (не) стать жертвой взлома в Kubernetes»;
- «Наш опыт с Kubernetes в небольших проектах» (обзор и видео доклада);
- «Мониторинг и Kubernetes» (обзор и видео доклада);
- «Собираем Docker-образы для CI/CD быстро и удобно вместе с dapp» (обзор и видео доклада);
- «Практики Continuous Delivery с Docker» (обзор и видео доклада);
- «Смерть микросервисного безумия в 2018 году».
Комментарии (7)

Bsplesk
04.10.2018 00:51-3bullshit
Смысл, как всегда один — думай своей головой, никому не верь и всё проверяй.
Одно ясно по колоссальному инфо шуму и рекламе, а также из финансовых отчетов Cloud провайдеров, что дело это очень прибыльное для них — Клондайк, и если грубо «ламповые»:
- server room (вместе с админами)
- enterprise service bus (вместе с админами)
- message queue(RabbitMQ/WMQ)… etc (вместе с админами)
- application server/java containers (вместе с админами)
- oracle/ms sql server/db2 (вместе с админами и отчасти разработчиками)
- c#/java
всеми правдами и неправдами, будут вытесняться и взамен будут «продвигаться» Cloud Lock решения:
- Google, Amazon, Azure… etc Cloud (Работа будет не для всех и не во всех странах)
- Google Kubernetes Engine/fleet/mesos/в части оркестровки, мониторинга зоопарка (переименовываем админа в свитере с оленями в devOps, отправляем изучать язык программирования python/Go/ruby?, инструменты Op
aensource, и вуаля — спец готов) - Amazon SQS/Cloud Pub/Sub service (плохая новость — работы нет, если только не у Cloud провайдера работаете)
- Container Level OS (работы нет, немного для Ops, если только не у Cloud провайдера работаете)
- DO Spaces Object Storage, Cloud Storage, Persistent Disks, Redis, Cloud SQL, S3… etc (для админов работы нет, немного для Ops, если только не у Cloud провайдера работаете, для разрабов работы будет меньше т.к. перестанут пихать логи в реляционные БД и прочие непотребности)
- python/Go/kotlin/php/js и разноцветные Кубики
Хорошая новость — весь этот Opaensource требует жутких костылей в работе, знаний магии, умения программировать и постоянно подпирать чтобы не развалилось. В тренде будут миграции от одного Vendor Lock Cloud в другой. Переписывания с нуля microservice при добавлении новой фичи, выпиливание vendor lock привязок и впиливание новых, настройка cross cloud взаимодействий, разборов какой из XXX взаимосвязанных сервисов участвующих в процессе виноват в отказе и.т.д.
Интеграция, интеграция, интеграция, ещё раз интеграция со всевозможными сервисами.
Приложения будут жрать в разы больше ресурсов процессора, диска, трафика, но все так и задумано.
Кстати в процессах SDLC — Ops становится таким «полубогом».
Вот как-то так, примерно, как развитие крупных сетей аля Магнит/X5… etc. Которые сжирают всех мелких.
Главное загнать в свои сараи, а дальше достаточно шерсть состригать вовремя.

b0sun
04.10.2018 02:28+1Вас это беспокоит, вы хотите поговорить об этом?
Кому надо — строят собственные облачные решения, вот там работы достаточно и предполагается ещё больше. Кому не надо — считают деньги, реальные физические ресурсы пока ещё в разы дешевле, да и эффективнее в некоторых вопросах. В процессе подсчёта денег все понимают, что фокус давно уже ушёл в разработку от администрирования, и само владение каким-то вычислительным ресурсом должно становиться дешевле и проще. Это нормально, за создание нового всегда готовы платить больше, чем за поддержку старого (да, щас начнётся, конечно… но факт остаётся фактом).
Переписывания с нуля microservice при добавлении новой фичи, выпиливание vendor lock привязок и впиливание новых, настройка cross cloud взаимодействий, разборов какой из XXX взаимосвязанных сервисов участвующих в процессе виноват в отказе и.т.д.
Интеграция, интеграция, интеграция, ещё раз интеграция со всевозможными сервисами.Так оно и есть, а вы разве не для этого в ИТ шли?
softadmin
04.10.2018 10:12+1Для каждой задачи должно быть своё разумное решение. А не городить бесконечный спор о том, что лучше (on-premise или облако). Надо разбирать конкретные кейсы. К примеру, разместить 10 Тб важных данных для нечастого доступа. Имхо, дешевле в S3 или его аналоге, чем городить свою СХД. А что касается статьи, то спасибо автору и переводчику!
Deterok
04.10.2018 10:12python/Go/kotlin/php/js
Мне одному странно видеть «Cloud Lock» решениях эту группу языков?
Мне больше здесь видятся C#/Java, предложенные вами выше.
Bsplesk
04.10.2018 09:18Вас это беспокоит
Давно активно «кручусь» в этой сфере, в том числе подготавливаю инфраструктуры для перехода в так называемую buzzword wordmicroservices architecture, а по факту если отбросить маркетинговый bullshit — подготовка к миграции в Cloud, причем с сохранением возможности переезда в другой (с этим всё печально, каждый провайдер активно расставляет минное поле из Cloud Vendor Lock-in).
Цель одна «перепилить» надёжные, дорогие enterprise решения(которые даже купить стала проблемой )монолиты (мир сошел с ума назвать кластер Java EE серверов с поддержкой OSGi — монолитом, но почему то платформу Google/Amazon Cloud Platform никто монолитом не называет)с классических «нормальных» сервисов на всякое непотребство от Cloud провайдеров, часто в виде спонсируемых ими OpaenSource проектов.
Уже несколько лет наблюдаю за инициативами Cloud провайдеров, вылавливая перспективные для решения задач в моей сфере.
Как свое личное развитие мне интересен соответствующий technology stack — знать который(в реале, а не по bullshit) мои прямые обязанности.
silent_shout
Общий смысл сводится к фразе «Нормально делай — нормально будет».
shurup Автор
Вы ожидали другого общего смысла от лучших практик? :-)