

На AWS re:Invent 2018, что проходит в эти дни в Лас-Вегасе, состоялся анонс Firecracker — новой технологии виртуализации с открытым кодом, основанной на Linux KVM. Авторы обещают, что с ней «в доли секунды можно запускать легковесные микровиртуальные машины (microVMs) в невиртуализированной среде, получив преимущества и традиционных ВМ — в виде безопасности и изоляции рабочих нагрузок, и контейнеров — в виде эффективного использования ресурсов».
Предыстория
За разработкой Firecracker стоят сотрудники Amazon Web Services, задавшиеся целью улучшить потребление ресурсов и вообще жизнь пользователям таких сервисов, как AWS Lambda (стартовал в 2014 году и позволяет сегодня заявлять о том, что модель serverless продолжит своё существование) и AWS Fargate (появился год назад).
Основу проекту положила Open Source-разработка от Google — crosvm из Chromium OS, что написана на Rust и отвечает за запуск операционных систем с виртуализацией устройств (но без эмуляции реального аппаратного обеспечения). Посему код Firecracker тоже написан на языке Rust, и его авторы обещают возвращать свои исправления в кодовую базу родительского проекта, хотя сами проекты со временем сильно разошлись в своём предназначении.
Первый публичный релиз Firecracker — 0.1.0 — состоялся в марте этого года, а последний актуальный — 0.11.0 — всего несколько дней назад. Эту статью я начал писать вскоре после интернет-анонса Firecracker, когда у проекта было 76 звёзд на GitHub, а на момент публикации этот показатель превысил уже 500.

Особенности Firecracker
Главным компонентом Firecracker является virtual machine monitor (VMM), что использует Linux KVM для создания и запуска так называемых microVMs. Авторы именуют свой продукт «облачной альтернативой QEMU» [используется в Kata Containers], «предназначенной только для безопасного и эффективного запуска контейнеров».
А вот как иллюстрируется пример хостовой системы, в которой запущены упомянутые microVMs:

Разработчики стремятся к минимализму, включая в продукт только самое необходимое и обеспечивая тем самым минимальные расходы на память, а заодно и уменьшая возможности для потенциальных уязвимостей. В Firecracker эмулируются всего 4 устройства: virtio-net, virtio-block, serial console и клавиатура с 1 кнопкой, используемой для остановки работы microVM. В качестве хостовой и гостевой операционных систем на данный момент поддерживаются ОС на базе ядра Linux версии 4.14 (релиз от ноября прошлого года) и выше, а в текущих планах разработчиков — поддерживать две последние стабильные ветки ядра Linux. В разрезе аппаратного обеспечения пока что поддерживаются только процессоры Intel, но AMD и ARM значатся в планах.
Сам Firecracker состоит из единого процесса VMM, который при запуске делает доступным API endpoint (RESTful) на хостовой машине. Собственно API описан в формате OpenAPI и, в частности, позволяет запускать microVM с указанными параметрами (образ ядра, корневая файловая система, аргументы для загрузки) и останавливать её, настраивать виртуальные машины (количество vCPU, оперативной памяти, шаблон для CPU), добавлять на них сетевые интерфейсы, диски (представлены как блочные устройства, доступны режимы read-write и read-only), настраивать систему для логов и метрик.
Главные достоинства Firecracker — безопасность (ориентация на multi-tenant computing, несколько уровней изоляции), высокая производительность (запуск microVM может осуществляться за 125 мс, и авторы обещают улучшить этот показатель в следующем году), минимальные накладные расходы (каждый microVM потребляет около 5 мегабайт памяти). Что прибавляет веса проекту — он уже был протестирован «в бою» и обеспечивает работу ряда сервисов AWS (включая упомянутые Lambda и Fargate).
Подробнее о безопасности
Среди главных возможностей Firecracker, ориентированных на обеспечение высокого уровня безопасности, упоминаются следующие:
- Простая гостевая модель (для всех гостей обеспечен лишь самый минимум — см. выше про 4 устройства).
- Изолирование процесса Firecracker с помощью cgroups и seccomp BPF, а также ограниченного набора разрешённых системных вызовов.
- Статическая линковка процесса Firecracker для его запуска в условиях изоляции от хостового окружения.
Демонстрация работы с Firecracker
В блоге AWS показали, как можно попробовать microVMs в действии. Для этого достаточно создать экземпляр i3.metal и загрузить на него 3 файла (исполняемый файл
firecracker, образ корневой ФС, ядро Linux):
После чего — установить нужные права на /dev/kvm:
$ sudo setfacl -m u:${USER}:rw /dev/kvmЗадать конфигурацию для первой гостевой машины:
$ curl --unix-socket /tmp/firecracker.sock -i -X PUT "http://localhost/machine-config" -H "accept: application/json" -H "Content-Type: application/json" -d "{
\"vcpu_count\": 1,
\"mem_size_mib\": 512
}"… затем ядро для неё:
$ curl --unix-socket /tmp/firecracker.sock -i -X PUT "http://localhost/boot-source" -H "accept: application/json" -H "Content-Type: application/json" -d "{
\"kernel_image_path\": \"./hello-vmlinux.bin\",
\"boot_args\": \"console=ttyS0 reboot=k panic=1 pci=off\"
}"… и корневую ФС:
$ curl --unix-socket /tmp/firecracker.sock -i -X PUT "http://localhost/drives/rootfs" -H "accept: application/json" -H "Content-Type: application/json" -d "{
\"drive_id\": \"rootfs\",
\"path_on_host\": \"./hello-rootfs.ext4\",
\"is_root_device\": true,
\"is_read_only\": false
}"Осталось собственно запустить гостя:
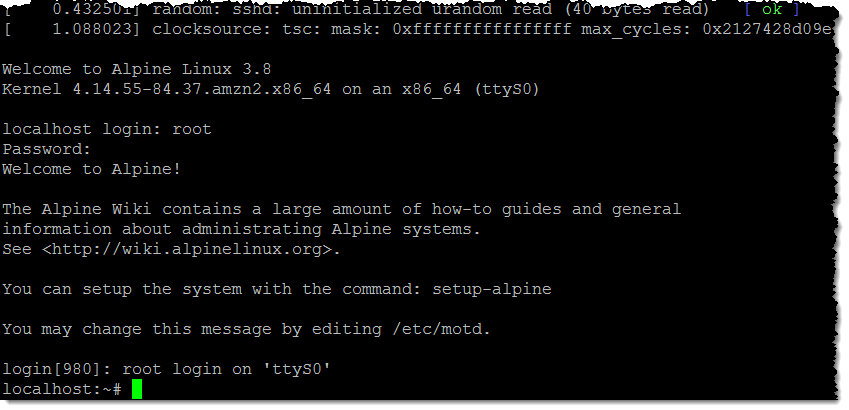
# curl --unix-socket /tmp/firecracker.sock -i -X PUT "http://localhost/actions" -H "accept: application/json" -H "Content-Type: application/json" -d "{
\"action_type\": \"InstanceStart\"
}"Результат:
Что насчёт других проектов для контейнеров?
Хотя авторы Firecracker обещают его «интеграцию с популярными исполняемыми средами для контейнеров», вот что они отвечают на вопрос, можно ли использовать проект с Kubernetes, Docker или Kata containers:
«Пока нет. Мы разрабатываем Firecracker как Open Source-проект, потому что он предлагает значимо другой подход к безопасности в запуске контейнеров. Надеемся, что и другие сообщества, создающие Open Source-технологии для контейнеров, сочтут его полезным. Мы работаем над тем, чтобы обеспечить естественную интеграцию Firecracker в экосистему контейнеров — с целью реализовать в будущем бесшовную интеграцию, предоставив больше возможностей по изоляции рабочих нагрузок в контейнерах».
P.S.
Читайте также в нашем блоге:
- «Прошлое, настоящее и будущее Docker и других исполняемых сред контейнеров в Kubernetes»;
- «Red Hat заменяет Docker на Podman»;
- «CRI-O — альтернатива Docker для запуска контейнеров в Kubernetes»;
- «Kubernetes в Amazon (EKS) стал общедоступным»;
- «Awless — мощная альтернативная CLI-утилита для работы с сервисами AWS».
Комментарии (43)

chemtech
27.11.2018 14:05blind_oracle
27.11.2018 18:14+2Firecracker это гипервизор. Скорее его можно воспринимать как минималистичный QEMU в комплекте с минималистичным же ядром, которое может грузиться очень быстро. А userspace там, в примере, как раз Alpine.
gecube
27.11.2018 21:48Я не совсем понимаю как firecracker может быть гипервизором, что он работает поверх kvm. Гипервизор на гипервизоре можно запустить, но производительность будет ужасная. Здесь же речь идёт об "оркестраторе" по типу докера, но с другим типом полезной нагрузки (т.е. здесь схожесть с openvz).
Вопрос ещё и в том имеет ли эта технология смысл для end-user'а. Т.е. если это всего лишь прослойка, которая позволяет эффективно запускать lambda/serverless, то с большой степенью уверенности могу сказать, что мне пофигу, что у них под капотом: docker, rocket, kata или "тонкие" ВМ… Работает и нормально.tchspprt
27.11.2018 22:26Если Вы не чувствуете разницу между виртуализацией и контейнеризацией и для вас это всё на уровне «работает и нормально» — печально.
КМК пользователю это в первую очередь выгодно, выгоднее чем самим AWS — Ваше ПО наиболее изолированно, чем оно было бы изолированно, например, в Docker-контейнере, при этом Вы не платите за ВМ сполна, т.к. Вы кушаете меньше ресурсов хост-машины.gecube
27.11.2018 23:58+1Вы вообще соображете, что говорите?
Если Вы не чувствуете разницу между виртуализацией и контейнеризацией и для вас это всё на уровне «работает и нормально» — печально.
с точки зрения Ops — несомненно чувствую. С точки зрения архитектора (и слабых мест того или иного решения) — тоже. С точки зрения Dev (побыстрее выкатить фичи и чтоб стабильно работало) — знаете, но внезапно (!) действительно разницы нет.
К тому же речь шла именно про отдельный, изолированный случай — lambda. В остальном я сам способен решить, что мне в текущий момент времени интереснее — полноценные ВМ или контейнеры.
Ваше ПО наиболее изолированно, чем оно было бы изолированно, например, в Docker-контейнере,
а технологически можете аргументировать? Уже были прецеденты, когда docker-изоляция «протекала». В первую очередь — по производительности. Например, habr.com/company/southbridge/blog/429788
В целом, ВМ тоже могут давать схожие эффекты в случае неравномерной нагрузки и тем более — оверселлинга по ресурсам (не знаю грешит ли этим AWS, но вот местечковые провайдеры таким страдают).Ipeacocks
28.11.2018 01:47> С точки зрения Dev (побыстрее выкатить фичи и чтоб стабильно работало) — знаете, но внезапно (!) действительно разницы нет.
Ну если вы считаете, что после выливки кода ваш конвейер закончился — то да, вы правы. А так ваши ошибки в коде в случае KVM более изолированы от хостовой системы.gecube
28.11.2018 08:12Насчёт конвейера — он закончится только в момент вывода программной компоненты из эксплуатации.
А так ваши ошибки в коде в случае KVM более изолированы от хостовой системы.
При условии выполнения каждой лямбды в отдельной "микроВМ" — скорее соглашусь. Но если там поверх ещё докер навернут (а почему нет?). Или если брать изоляцию между каждым инстансом firecrackerIpeacocks
28.11.2018 11:33Даже если там поверх докер (не совсем понятно зачем), то все равно же выход на хост систему (та в которой работает гипервизор) менее вероятен.
gecube
28.11.2018 12:37чтобы лямбды гонять. Или они поверх FireCracker сразу будут выполняться (ну, через ОС, ес-но)?
то все равно же выход на хост систему (та в которой работает гипервизор) менее вероятен.
я с этим и не спорил )
tchspprt
28.11.2018 13:04Вы сами запутались — я прямым текстом сказал, что Docker и контейнеризация — кривая технология, на что вы потребовали обоснования того, что Docker и контейнеризация — кривая технология приведя в пример ссылку того, когда она кривая тем самым доказывая мне то, что я и сам утверждаю. :)
А что мне технологически аргументировать? На соседей разделяется nf_conntrack, разделяется энтропия, разделяется etc…
С точки зрения Dev (побыстрее выкатить фичи и чтоб стабильно работало) — знаете, но внезапно (!) действительно разницы нет.
На моей машине всё работает. (с) Но ладно, да, с точки зрения Dev разницы никакой. Если только не… команда состоит не из 1,5 землекопа, а там начинается игра в футбол, которая зря потратит время всем: «это виноват Dev!» — «не, это Ops'ы косячат!»tchspprt
28.11.2018 13:05То есть говоря отдельно об Dev окружении — разницы никакой. Но говоря в целом о команде — всё равно есть просадка по времени.
gecube
28.11.2018 13:35Я и говорю, что kvm/qemu или любой другой гипервизоре даёт степень изоляции выше, чем докер, но не абсолютную изоляцию (например, проблема с общими iops, оверселлингом cpu и пр. — очень хочется понять, что под капотом Амазона).
При решении каждой конкретной задачи можно решить какой уровень изоляции нужен. Главное понимать trade-off и в какой момент абстракция «потечёт».
Касательно dev/prod-контуров — их полностью идентичными не сделать по разным причинам (экономические, технологические и пр.). Да и не всегда нужно, чтобы dev был точной копией.
Касательно firecracker — это очень интересный вопрос как его предлагает использовать Амазон. Условно, если они представляют его как легковесную замену ВМ, чтобы запускать лямбды (т.е. все инкапсулировано и скрыто от пользователя платформы), то это очень интересное решение. Но ещё и интересно технологически — будет ли firecracker хостинг только лишь одну лямбду, например, или их коллекцию? Или может даже лямбды разных пользователей. Короче — посмотрим.tchspprt
28.11.2018 16:04В целом да. Но дилетантское IMHO — для CPU-bound виртуалки в принципе не подходят — многого не добиться, так что оверселлинг CPU вряд ли в точку.
blind_oracle
27.11.2018 23:13+3KVM предоставляет только базовую инфраструктуру для виртуализации — по сути только процессор и менеджер памяти. Остальное — сеть, видео, USB и прочую периферию предоставляет QEMU, либо иной софт — как описанный тут Firecracker.
Здесь же речь идёт об «оркестраторе» по типу докера, но с другим типом полезной нагрузки (т.е. здесь схожесть с openvz).
Нет тут никакого оркестратора. Тут один процесс Firecracker — одна ВМ. Плюс API. Оркестратор нужно сверху прикручивать через API. Причем тут OpenVZ вообще не понятно.gecube
28.11.2018 00:00Хм. Т.е. получается, что Firecracker — это аналог qemu, но с меньшими возможностями, а поэтому более «легкий»?
gecube
28.11.2018 00:04-1Ну, и меня немного сбило с толку (т.к. читал быстро и по диагонали)
Изолирование процесса Firecracker с помощью cgroups и seccomp BPF
ОК. Т.е. ничего нового на самом деле не сказано ) те же qemu/kvm можно было засунуть в cgroups.
blind_oracle
28.11.2018 00:07Да, это легковесный гипервизор с легковесным ядром (собранным с минимумом функций). Что позволяет ему быстро стартовать.
DaylightIsBurning
28.11.2018 02:13но, вероятно, ядро можно будет при необходимости собирать побольше, в т.ч. подключать модули, что невозможно в случае lxc.
Tangeman
28.11.2018 02:14Да, с меньшими — он не эмулирует реальное железо или процессор, и гораздо шустрее. Скорее он ближе к Xen или к UML, чем к QEMU.
Всё что ему нужно от KVM — это изоляция процесса + прямое выполнение инструкций на хостовом железе (в изоляции от других процессов, разумеется), т.е. с точки зрения гостя у него процессор хоста, но это всё что гостю может быть видно из железа.
cgroups/seccomp нужны исключительно для того чтобы никто не выбрался дальше, ведь фактически Firecracker нужно только read/write и ещё несколько простых и сравнительно безопасных системных вызовов, в то время как QEMU нужно гораздо больше для нормальной работы, и его гораздо сложнее изолировать.
Таким образом, роль самого Firecracker заключается только в инициализации и реализации обмена данными с хостом (на уровне файлов/сокетов для virtio устройств), больше ни к чему гость не имеет доступа и соответственно навредить вряд ли сможет (разве что поедая ресурсы — но от этого как раз спасут cgroups).
В общем, я бы назвал это UML на стероидах.
DaylightIsBurning
27.11.2018 20:00Интересно, почему решили реализовать virtio-block, в дополнение к virtio-net? Не получается эффективно (с незначительным оверхедом) реализовать блочный доступ поверх virtio-net?
blind_oracle
27.11.2018 23:51Блочный доступ через virtio-net — это как?
Tangeman
28.11.2018 01:12Я думаю, имелся в виду NBD и аналоги.
Но смысла в этом оверхеде всё равно нет (он не такой уж и незначительный), если можно отдать block device.blind_oracle
28.11.2018 01:40+1Как-то это неочевидно… Если есть virtio-net для связи с окружающим миром и в ядро впихнули модуль nbd — никто не мешает его юзать, дополнительных телодвижений не нужно. Вопрос — зачем?
Tangeman
28.11.2018 02:06С NBD нужны телодвижения со стороны хоста — как минимум, серверная часть, которая будет отдавать файлы или устройства. Плюс оверхед никуда таки не денется — всё пойдёт через сетевой стек (+ память на буфера, дополнительно к кэшу), пожирая ресурсы дважды, как у гостя, так и у хоста, при этом разбивая доступ на сравнительно мелкие пакеты (никто не даст гостю Jumbo Frames, хотя и они не сильно помогут).
В то же время «прямой» доступ через virtblk — это просто проброс на уровне read()/write(), вероятно даже с прямым доступом к памяти гостя со стороны хоста. Оверхед конечно останется, но ощутимо меньший.
Теперь умножим это на много VM на одном физическом хосте — и получим ужасную картину с оверхедом в случае NBD + гость может воспользоваться уязвимостью со стороны NBD сервера на хосте (если таковая обнаружится).
DaylightIsBurning
28.11.2018 02:07Что бы сделать гипервизор ещё меньше, если в этом была цель.
Разработчики стремятся к минимализму, включая в продукт только самое необходимое и обеспечивая тем самым минимальные расходы на память, а заодно и уменьшая возможности для потенциальных уязвимостей.
blind_oracle
28.11.2018 21:46Я думаю что virtio-block сильно проще nbd в плане кода. Лезть сравнивать лень, но почти уверен. Так что плоскость атаки будет еще меньше.
beduin01
27.11.2018 23:21-7Ну вот хайп Докера и подходит к концу. Страшно представить что для поддержки контейнерного-бума даже целую специальность создали из недо-сисадминов DevOps.
Итог всего этого простой — дико переусложненная экосистема и оверинжиниринг всего и вся.ALexhha
27.11.2018 23:29+6Страшно представить что для поддержки контейнерного-бума даже целую специальность создали из недо-сисадминов DevOps.
у вас абсолютно неправильное представление о devops. И да, не все devops связаны с docker. Хотя последний очень сильно упрощает некоторые моменты в процессе жизненного цикла ПО.

no_like
28.11.2018 02:28Очень рад видеть рост числа энтерпрайз проектов написанных на Rust. Да еще и таких интерестных!
r0mik
28.11.2018 08:45Ох, сколько уже их было, этих супер-быстрых, в следствии своей супер-минималистичности же, гипервизоров, которые в бенчмарках, то есть в тестах, писанных самими же разработчиками, в надцать раз быстрее qemu-kvm и в эти же надцать раз безопаснее и проще.
К примеру тот же freeBSD-шный bhyve…
Хотя это совсем другая песня, тем более что не на растения писанная.
Так вот: сколько уже их было видимо-невидимо (на опеннете что не месяц — новость о новом гипервизоров), да только ни один не выстрелил, потому что всем, по какой-то невиданной причине, почему-то оказывается очень нужна эмуляция всевозможного оборудования, всякие миграции и т.д. и т.п., а тут нам что же предлагают..? — аппаратную клавиатуру с одной кнопкой!
Зачем вообще нужна эта кнопка в таком кейсе? Уже бы тушили питание посредством bios-uefi, если они там, конечно, есть.
PS: простите мне мой сарказм, просто я больше 10 лет наблюдаю как qemu все закапывают...
shurup Автор
28.11.2018 08:50Да почему же сарказм — ведь вполне адекватный (пусть и критичный) взгляд на происходящее :-) Однако у Firecracker сразу есть сильное преимущество в лице собственно AWS и его применения на этой огромной площадке. Т.е.: даже если он не уйдёт куда-то дальше AWS, это уже большая часть рынка. Но уйти дальше он точно [по меньшей мере] попытается: 3000 GitHub-звёзд за сутки — это не шутки: в сообществе им явно заинтересовались. А дальше… чего тут гадать — время покажет, мы всё сами увидим.
Tangeman
28.11.2018 17:23потому что всем, по какой-то невиданной причине, почему-то оказывается очень нужна эмуляция всевозможного оборудования
Основная причина по которой используют qemu/kvm для хостинга (VPS & co) — это изоляция, а не эмуляция. В случае с qemu это большой оверхед (там много лишнего), поэтому минималистический гипервизор который дает только изоляцию, сеть и block-device, при этом способный выполнять любое ядро — это реальная тема, потому что это всё что нужно большинству контейнеров.
Уже бы тушили питание посредством bios-uefi
Тушить питание не проблема, проблема надёжно и безопасно дать OS знать что пора делать graceful shutdown, ACPI/UEFI etc тут явно будет перебором — клавиатуру эмулировать проще на порядок.gecube
28.11.2018 17:40Основная причина по которой используют qemu/kvm для хостинга (VPS & co) — это изоляция, а не эмуляция.
Соглашусь.
Требования для хостинга простые:
— поддержка популярных операционных систем (linux, windows, freebsd различных дистрибутивов и версий)
— поддержка блочных устройств, сети, GPU акселлерации (опционально).
И по идее все… Получатеся, что действительно конфигурация ВМ на хостинга она, в целом, стандартизирована. Плюс еще на хостингах обычно используется закрытый перечень типов железа.
В отличии от запуска гипервизора с ПОЛНЫМ пробросом аппаратного обеспечения на рабочей машине разработчика или пользователя, где действительно нужно тянуть возможность поддержки всех фич и разного типа железа (те же USB пробросы )))
ustas33
28.11.2018 11:49-1HRы и recruiters, теперь ваш ход…
С 1 декабря Firecracker во всех DevOps вакансиях, опыт от 5 лет.
willyd
28.11.2018 12:07А кто-то уже попробовал его?
Tangeman
30.11.2018 04:05Да. Я взял ядро 4.19, добавил ему virtnet/virtblk статикой (чтобы обойтись без initrd), и запустил Ubuntu 18.04. Ядро можно урезать до минимума, всякая поддержка железа не нужна.
Всё почти как обещано — CPU на уровне 95% от хоста (прикидывается ксеоном), а вот с сетью и диском — на полной загрузке жрёт CPU хоста просто безбожно. Сеткой даёт около 30 Gbits/s с хостом (на i7-6700). Впрочем, с qemu ситуация несколько хуже, оверхед там поболе будет, но это зависит.
В остальном — гипервизор как гипервизор, нужно просто юзать. Привлекает то что это один статический экзешник, никакого инсталла, простой API. Расстраивает что нет годного UI (пока), хотя они вроде уже запилили поддержку в containerd.
Если Proxmox это подхватит (рядом с QEMU) — может неплохая альтернатива lxc получится (в плане изоляции как минимум).
Сильно I/O loaded штуки в нём гонять будет накладно (как, впрочем, и в qemu/docker), но «стандартный пакет» для в основном ожидающих задач (веб-сервера & co) вполне сойдёт.
amarao
28.11.2018 15:35Всё это хорошо, если бы не бесконечные Spectre. Виртуализация почти мертва, и не важно насколько хорош софт, если железо протекает.
elve
Я могу ошибаться, но мне это напомнило OpenVZ.
gibson_dev
Для некоторых задач вполне применимая технология
Fedcomp
А OpenVZ это разве не сильно перепиленое ядро линукса которое также сильно отстает? а тут вроде за пределами ядра.
tchspprt
Совсем ни разу не OpenVZ. Даже наоборот — антагонист.
Это, скорее, [серверный|облачный] Qubes OS.
blind_oracle
Нет, это разные вещи. OpenVZ — контейнеры, Firecracker — полноценная виртуализация через CPU с отдельным ядром на каждого гостя.
Ну и OpenVZ мертв уже, да.