

Не найдя в интернете ни одного конкретного примера реализации Gherkin с паттерном проектирования Page Object для Codeception, подумалось, что будет не лишним рассказать интернету о собственной реализации этого паттерна.
Эта статья рассчитана скорее на тех, кто уже немного знаком с Codeception или похожими фреймворками, но ещё не знает, как при помощи Page Object сделать тесты более читаемыми, упростить их поддержку и сократить объемы лишнего кода. Тем не менее, я постаралась пошагово изложить все основные моменты сборки проекта автоматизации с нуля.
Шаблон Page Object позволяет инкапсулировать работу с элементами страницы, что в свою очередь позволяет уменьшить количество кода и упростить его поддержку. Все изменения в UI легко и быстро внедряются — достаточно обновить Page Object класс, описывающий эту страницу. Ещё одно важное преимущество такого архитектурного подхода — он позволяет не загромождать тестовый сценарий HTML деталями, что делает его более понятным и простым для восприятия.
Так выглядит тест без применения Page Object
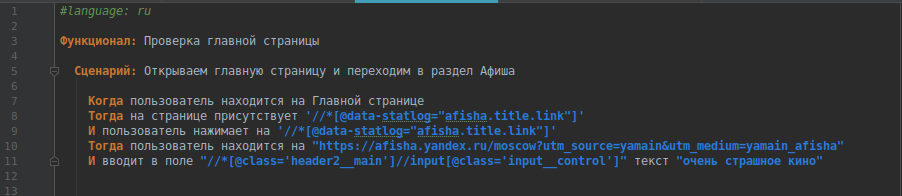
С применением Page Object
Детально останавливаться на установке базового окружения не буду, приведу свои исходные данные:
- Ubuntu Bionic Beaver
- PHP 7.1.19-1
- Composer — менеджер по управлению зависимостями для PHP, установлен глобально
- PhpStorm — среда разработки
Для запуска тестов нам также понадобится:
- Сhromedriver 2.41 (по ссылке можно не только скачать, но и посмотреть, какой драйвер соответствует вашей версии хрома)
- Chrome 67.0.3396.99
- Selenium-server-standalone-3.14.0 (статья об установке selenium на ubuntu)
Разворачиваем Codeception
Приступаем к установке Codeception:
Открываем в терминале нужную нам директорию, где будем собирать проект, или создаём директорию для проекта и переходим в неё:
mkdir ProjectTutorial
cd ProjectTutorialУстанавливаем фреймворк Codeception и его зависимости:
composer require codeception/codeception --dev
Файл установки зависимостей composer.json в проекте будет выглядеть так:
{
"require": {
"php": ">=5.6.0 <8.0",
"facebook/webdriver": ">=1.1.3 <2.0",
"behat/gherkin": "^4.4.0",
"codeception/phpunit-wrapper": "^6.0.9|^7.0.6"
},
"require-dev": {
"codeception/codeception": "^2.5",
"codeception/base": "^2.5"
}
}Разворачиваем проект:
php vendor/bin/codecept bootstrap
Больше информации о способах установки проекта можно получить в официальной документации.
На этом этапе в нашем проекте создаются три набора (suite) тестов. По умолчанию Codeception разделяет их на приемочные, функциональные и юнит. К этим наборам Codeception также генерирует три yml файла. В них мы указываем все необходимые конфигурации, подключаем модули и свойства для запуска наших тестов.
Этот урок построен на примере Acceptance теста, поэтому и настройки буду приводить в Acceptance.suite.yml.
Открываем наш проект в PHP Storm (или другой любимой среде разработки) и переходим в Acceptance.suite.yml (по умолчанию он лежит в папке tests/acceptance.suite.yml).
Прописываем минимально необходимые зависимости и обязательно обращаем внимание на форматирование. Модули разделяются знаком "-" и должны располагаться на одном уровне, иначе при запуске теста посыпятся ошибки.
Получается:
actor: AcceptanceTester
modules:
enabled:
- WebDriver:
url: 'http://yandex.ru/' //тут может быть любой сайт, для которого вы будете писать свой сценарий
browser: 'chrome'
- \Helper\Acceptance //в этом модуле будут находиться методы взаимодействия с элементами страницы
gherkin:
contexts:
default:
- AcceptanceTesterИ ещё немного подготовительных работ:
Создадим в корне проекта отдельную директорию (у меня lib).
В этой директории создаем исполняемый файл run.sh, который будет запускать Selenium и Chrome Driver.
Помещаем сюда же Selenium и Chrome Driver, и пишем в run.sh команду запуска:
java -jar -Dwebdriver.chrome.driver=chromedriver_241 selenium-server-standalone-3.14.0.jarКак это выглядит в проекте:

Возвращаемся в консоль и меняем права доступа:
chmod +x ./run.sh(прим. Названия драйверов, лежащих в директории, должны точно соответствовать указанным в команде запуска).
Запустить Selenium и Webdriver можно прямо сейчас, чтобы больше к этому не возвращаться. Для этого открываем новую вкладку терминала, переходим в директорию, где лежит файл run.sh и пишем команду запуска:
~/AutomationProjects/ProjectTutorial/lib$ ./run.shУбедились, что сервер запущен:
Оставляем его в запущенном состоянии. На этом подготовительные работы завершены.
Пишем тестовый сценарий
Переходим к созданию feature файла для нашего тестового сценария. Для этого в Codeception предусмотрена специальная команда, запускаем её в консоли:
cept g:feature acceptance check(прим. “check” — название моего теста)
Видим в папке acceptance новый файл check.feature.
Дефолтное содержимое нам не нужно, сразу удаляем и пишем свой тест.
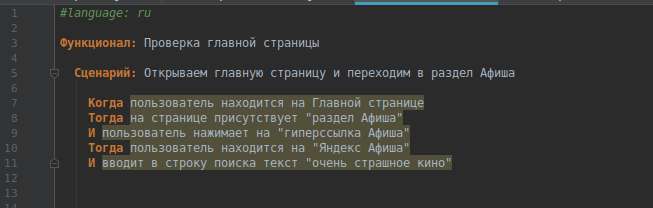
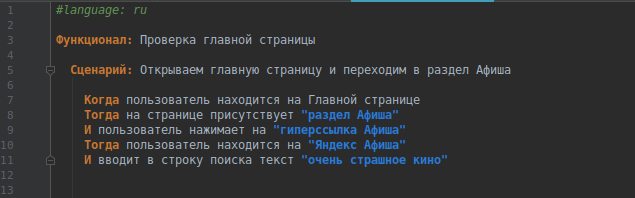
Для того, чтобы сборщик распознал кириллицу, не забываем начинать сценарий с #language: ru.
Пишем коротенький сценарий на русском языке. Напоминаю, что каждое предложение должно начинаться с ключевых слов: “Когда”, “Тогда”, “И”, символа “*” и др.
Для своего примера я взяла сайт Яндекс, вы можете взять любой.
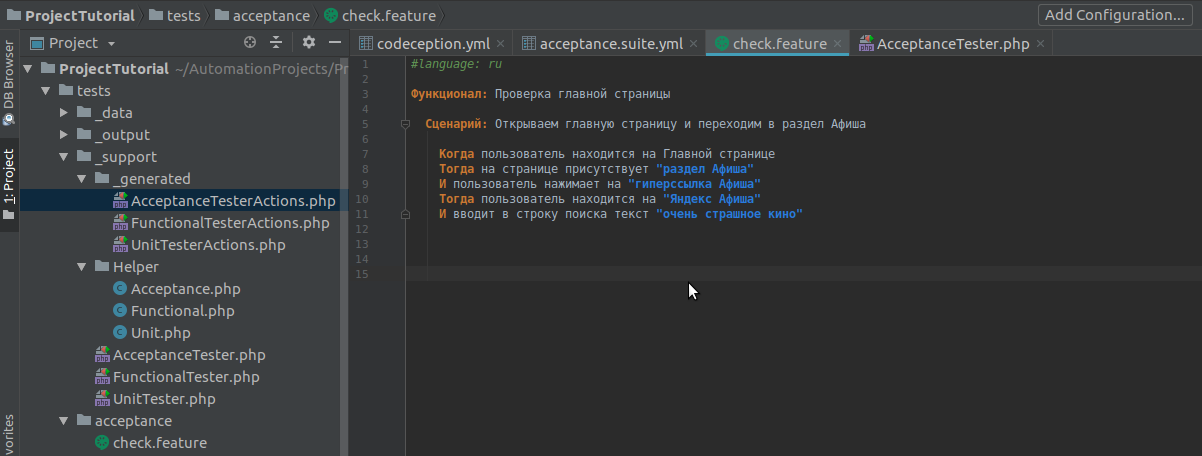
Чтобы увидеть, какие в тесте есть шаги, прогоняем в терминале свой сценарий:
cept dry-run acceptance check.feature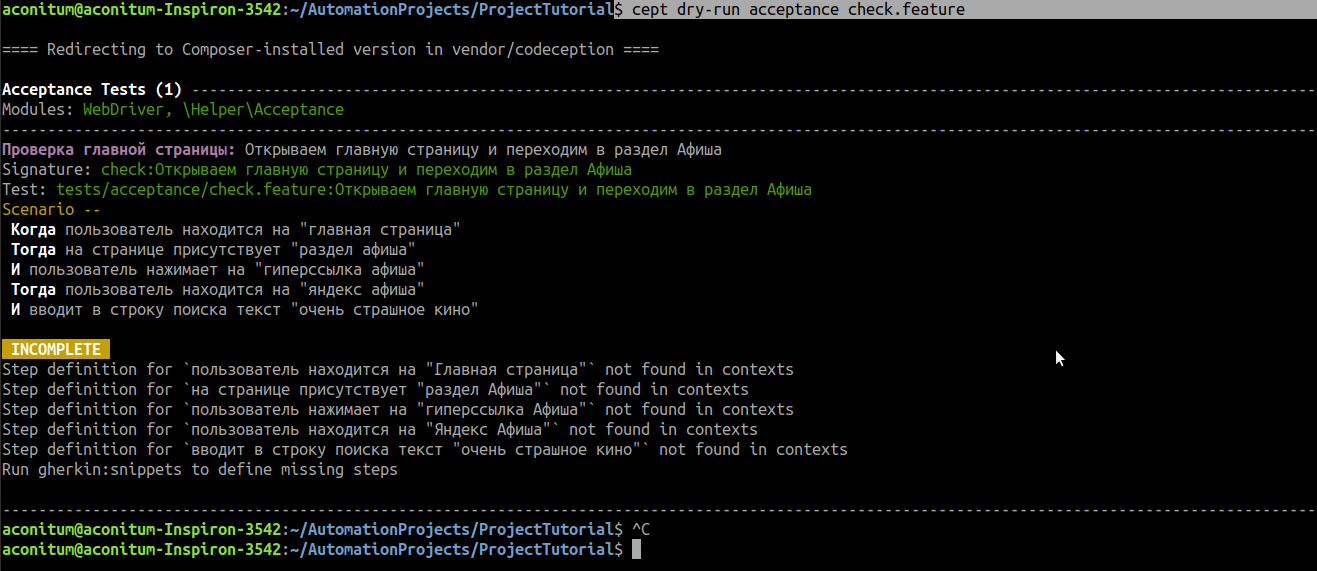
Шаги сценария выводятся в консоль, но их реализации ещё нет.
Тогда запускаем команду, которая автоматически сгенерирует шаблоны для реализации наших методов:
cept gherkin:snippets acceptance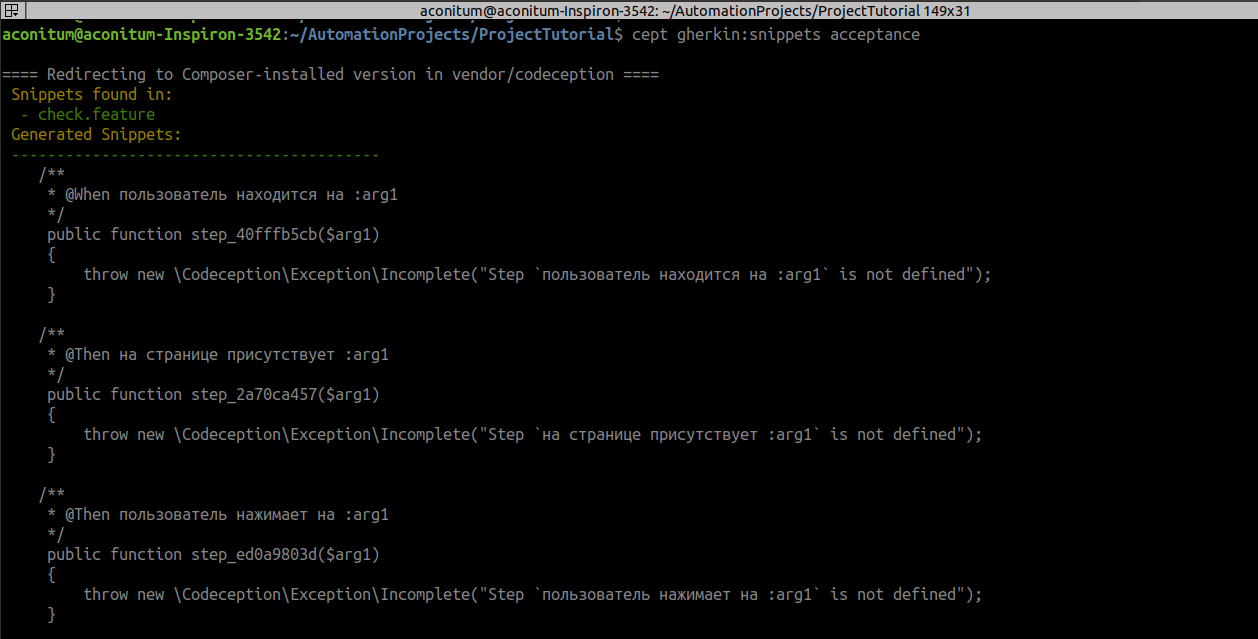
Все названия из сценария, которые были в кавычках, заменяются на переменные :arg.
Копируем их из терминала и вставляем в файл AcceptanceTester.php, где будут лежать методы работы с элементами страницы.
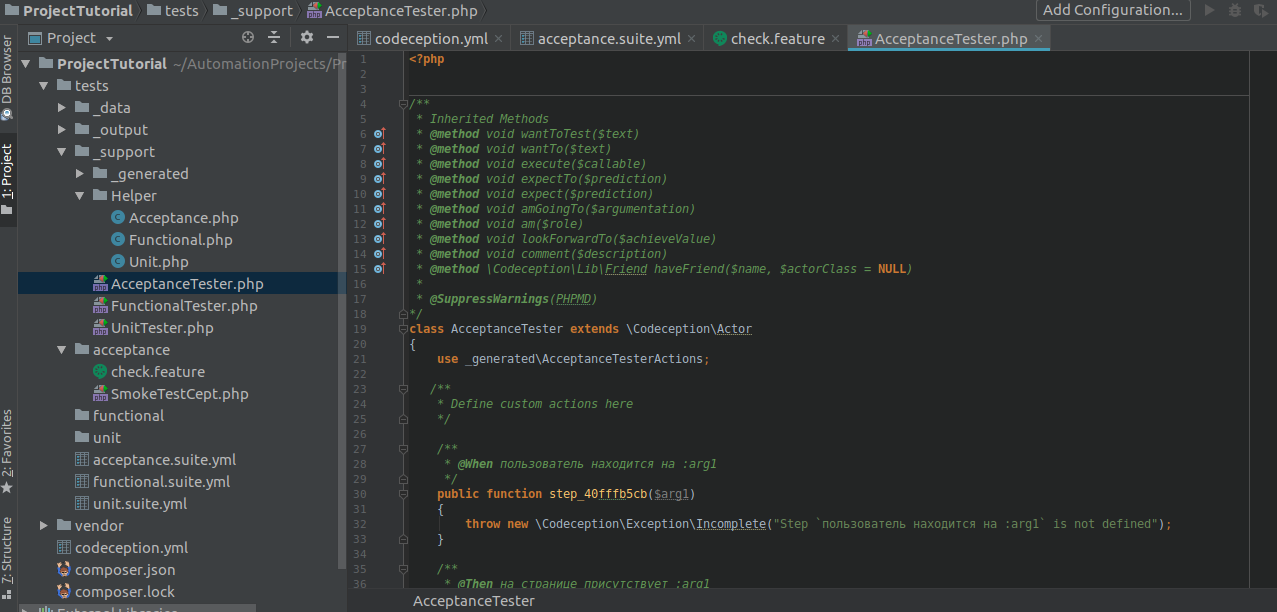
Переименуем методы в читаемые, отражающие их суть (не обязательно), и напишем их реализацию.
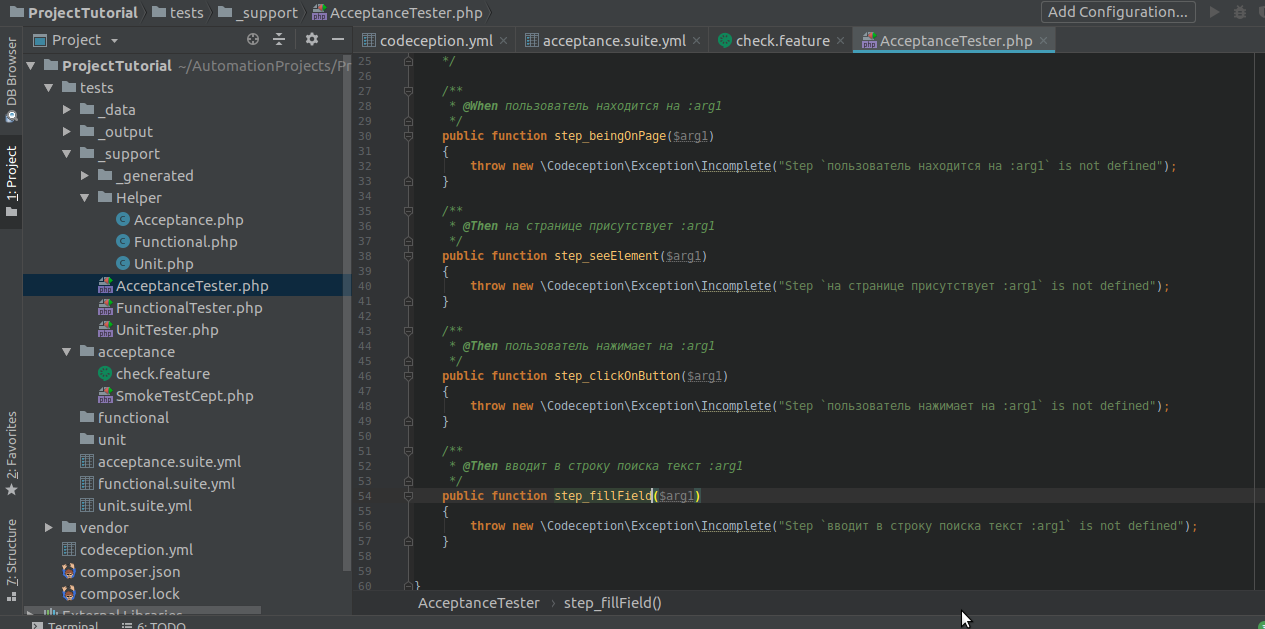
Тут всё просто, но ещё проще, если вы работаете в умной среде разработки, типа Storm, которая сама будет подсказывать нужные команды из библиотеки:
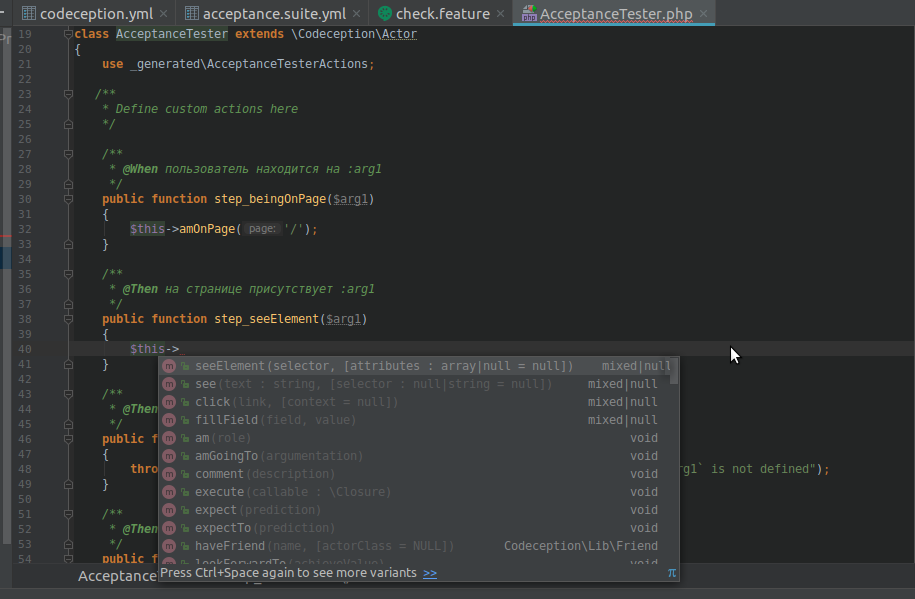
Удаляем лишнее и пишем методы:
/**
* @When пользователь находится на Главной странице
*/
public function step_beingOnMainPage($page)
{
$this->amOnPage('/');
}
/**
* @Then на странице присутствует :element
*/
public function step_seeElement($element)
{
this->seeElement($element);
}
/**
* @Then пользователь нажимает на :button
*/
public function step_clickOnButton($button)
{
$this->click($button);
}
/**
* @Then вводит в поле :field текст :text
*/
public function step_fillField($field, $text)
{
$this->fillField($field, $text);
}Посмотрим, что получилось. Запускаем команду, которая покажет нам, какие методы (step) у нас теперь имеют реализацию.
cept gherkin:steps acceptance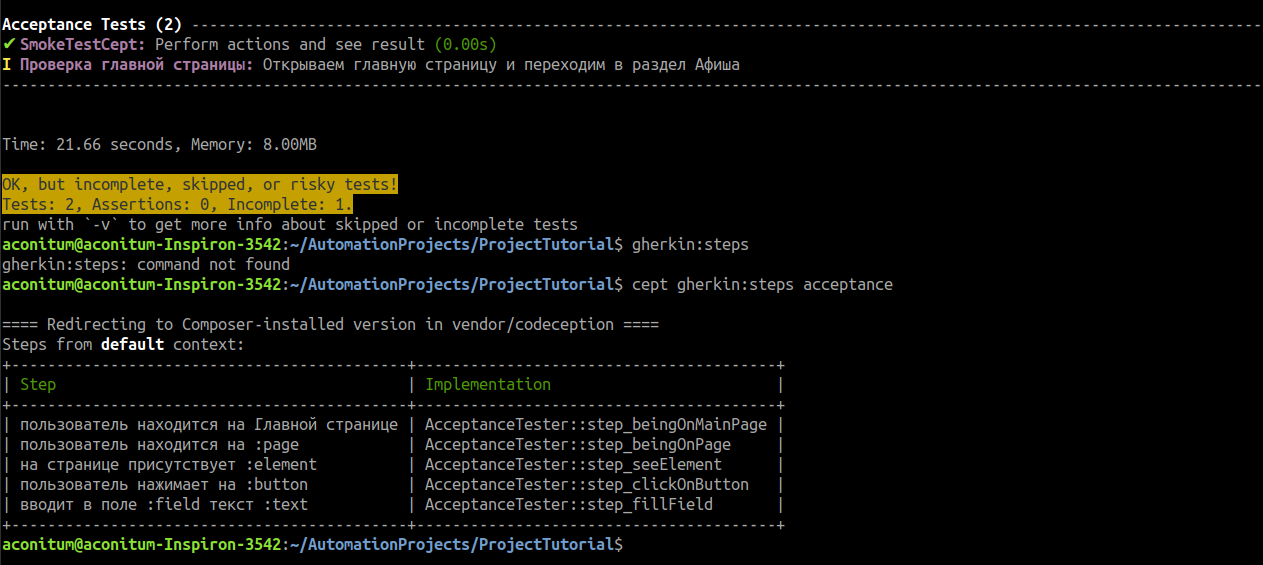
Успех!
Но степы в feature файле всё ещё не распознаются как методы.
Чтобы Storm понял, что делать со степами, провернем трюк с реализацией интерфейса Context из namespace Gherkin Context.
namespace Behat\Behat\Context {
interface Context {}
}Заворачиваем наш класс AcceptanceTester в namespace и наследуем от Context
implements \Behat\Behat\Context\Context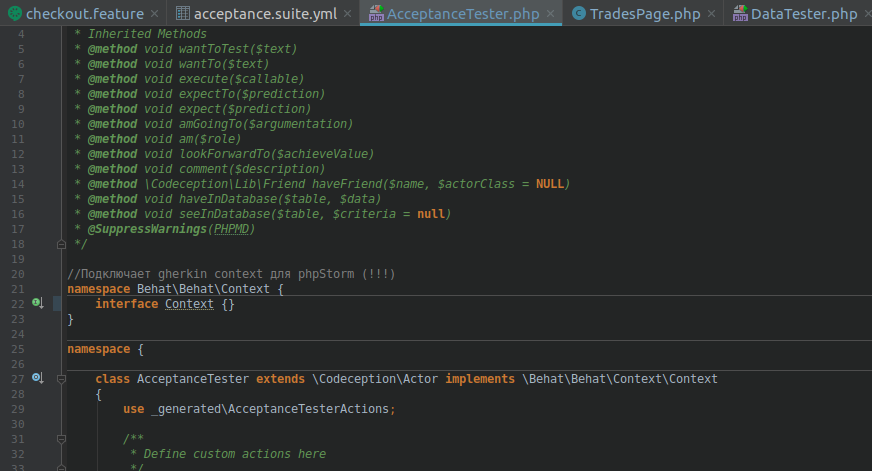
Теперь все степы feature файла привязаны к их реализации:
Для того, чтобы Webdriver понял, на что кликать и куда смотреть, нужно заменить читаемые названия элементов и адреса страниц на соответствующие локаторы и URL, которые в виде аргументов попадут в методы.
Тогда получим тест вида:
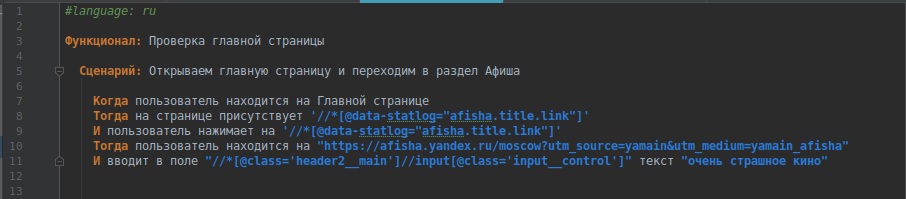
И можно запускать:
cept run acceptance
Passed.
прим. Если элементы страницы долго грузятся, можно добавить в нужный метод ожидание:
$this->waitForElementVisible($element);Возвращаемся к нашему тестовому сценарию. Расстраиваемся, что вся читаемость теста теряется из-за того, что вместо понятных названий элементов и страниц мы видим HTML элементы и url.
Если мы хотим это исправить, пришло время переходить к реализации паттерна Page Object.
Переходим к Page Object
В каталоге _support создаём директорию Page, куда будем складывать наши страницы-классы:
php vendor/bin/codecept generate:pageobject MainPageПервый Page Object — главная страница Яндекса, назовем её MainPage, класс назовем так же:
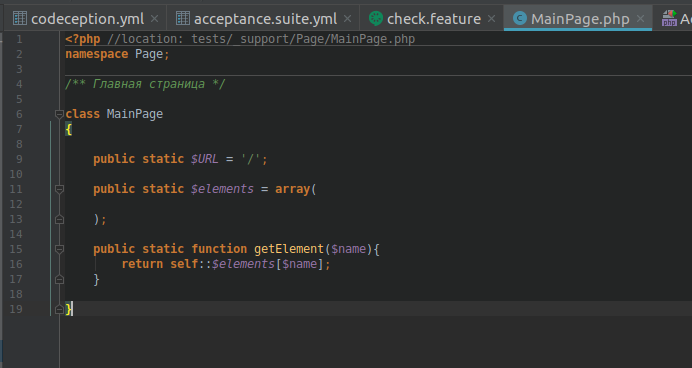
Здесь мы объявляем статические поля и методы, чтобы их можно было вызывать, не создавая объекта.
Поскольку в конфигурациях Acceptance.suite.yml мы уже указали стартовую страницу url: yandex.ru, то для главной страницы достаточно будет указать
public static $URL = '/';Дальше идёт массив элементов страницы. Описываем локаторы для нескольких элементов и даем им понятные и уникальные названия.
Теперь необходимо добавить метод getElement, который будет возвращать локатор по названию элемента из массива.
В результате имеем:
<?php //location: tests/_support/Page/MainPage.php
namespace Page;
/** Главная страница */
class MainPage
{
public static $URL = '/';
public static $elements = array(
'раздел Афиша' => "//*[@id='wd-wrapper-_afisha']",
'гиперссылка Афиша' => "//*[@data-statlog='afisha.title.link']",
'иконка Погода' => "//*[@class='weather__icon weather__icon_ovc']|//*[@class='weather__icon weather__icon_skc_d']",
);
public static function getElement($name){
return self::$elements[$name];
}
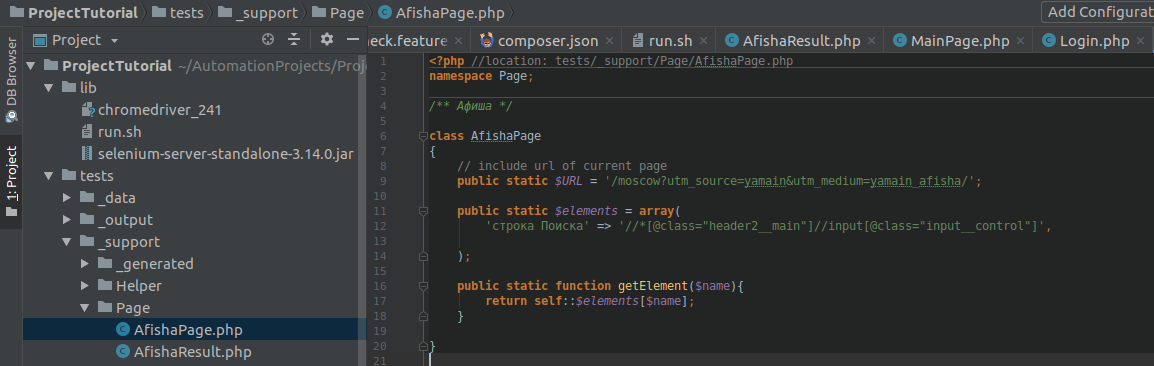
}Добавлю ещё пару классов страниц:
/** Афиша */
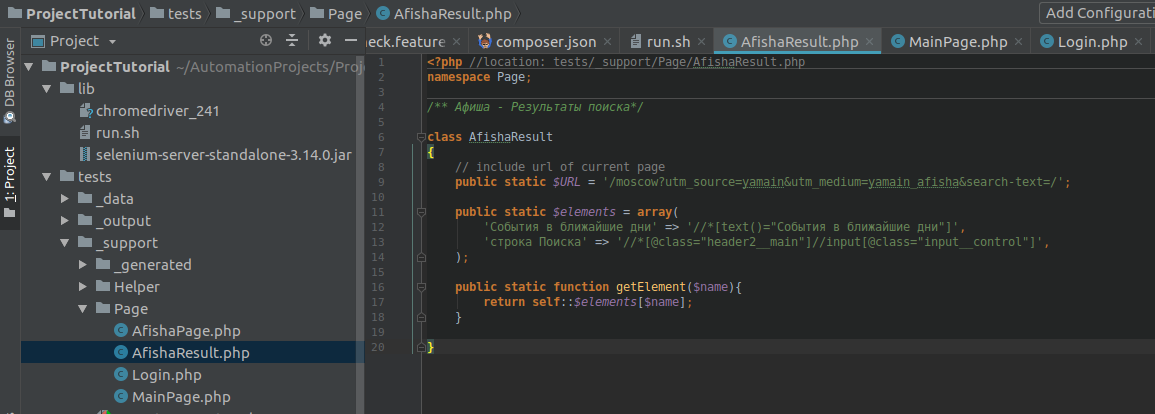
/** Афиша — Результаты поиска*/
Возвращаемся в класс AcceptanceTester.php, где мы писали наши методы.
Создадим в нём массив из классов PageObject, где мы присвоим страницам названия и укажем их имена классов в пространстве имен:
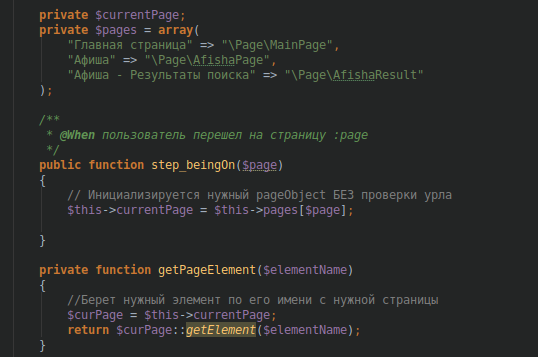
private $pages = array(
"Главная страница" => "\Page\MainPage",
"Афиша" => "\Page\AfishaPage",
"Афиша - Результаты поиска" => "\Page\AfishaResult"
);Каждый новый PageObject аналогичным образом добавляем в этот массив.
Дальше нам нужно создать поле currentPage, в котором будет храниться ссылка на PageObject текущей страницы:
private $currentPage;Теперь напишем метод, при вызове которого мы сможем получить currentPage и инициализировать нужный нам класс PageObject.
Логично таким методом сделать степ «Когда пользователь перешел на страницу „Название страницы“. Тогда самый простой способ инициализации класса PageObject, без проверок, будет выглядеть так:
/**
* @When пользователь перешел на страницу :page
*/
public function step_beingOn($page)
{
// Инициализируется нужный pageObject
$this->currentPage = $this->pages[$page];
}Теперь пишем метод getPageElement, который позволит нам получать элемент, а точнее, его локатор с текущей страницы:
private function getPageElement($elementName)
{
//Берет нужный элемент по его имени с нужной страницы
$curPage = $this->currentPage;
return $curPage::getElement($elementName);
}
Для уже реализованных методов необходимо заменить аргументы, которые в начале мы получали непосредственно из текста feature, на элементы из PageObject, то есть:
$argпримет вид
getPageElement($arg))Тогда наши методы примут вид:
/**
* @When пользователь находится на странице :page
*/
public function step_beingOnMainPage($page)
{
// Открывается страница и инициализируется нужный pageObject
$this->currentPage = $this->pages[$page];
$curPage = $this->currentPage;
$this->amOnPage($curPage::$URL);
}
/**
* @Then на странице присутствует :element
*/
public function step_seeElement($element)
{
$this->waitForElementVisible($this->getPageElement($element));
$this->seeElement($this->getPageElement($element));
}
/**
* @Then пользователь нажимает на :button
*/
public function step_clickOnButton($button)
{
$this->click($this->getPageElement($button));
}
/**
* @Then вводит в поле :field текст :text
*/
public function step_fillField($field, $text)
{
$this->fillField($this->getPageElement($field), $text);
}
/**
* @Then пользователь удаляет текст в поле :field
*/
public function step_deleteText($field)
{
$this->clearField($this->getPageElement($field));
}
Добавила ещё один метод для отображения результатов поиска по нажатию клавиши Enter:
/**
* @Then нажимает на клавиатуре ENTER
*/
public function step_keyboardButton()
{
$this->pressKey('//input',WebDriverKeys::ENTER);
}Последний шаг — когда все необходимые методы и PageObjects описаны, нужно провести рефакторинг самого теста. Добавим шаги, которые будут инициализировать PageObject при переходе на новую страницу. У нас это “*пользователь перешел на страницу :page”.
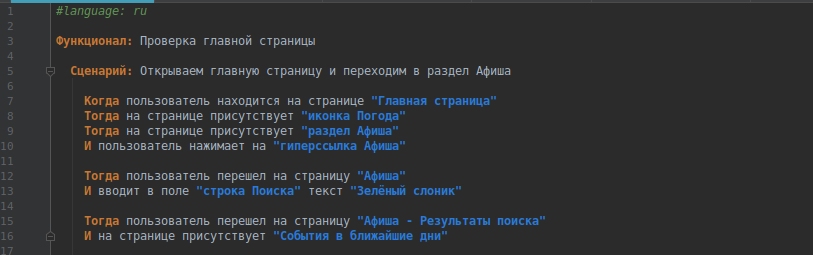
Для наглядности допишу ещё несколько шагов. В результате получился такой тест:
#language: ru
Функционал: Поиск на Яндекс Афише
Сценарий: Открываем главную страницу. Переходим в раздел Афиша. Ищем хорошее кино.
Когда пользователь находится на странице "Главная страница"
Тогда на странице присутствует "иконка Погода"
Тогда на странице присутствует "раздел Афиша"
И пользователь нажимает на "гиперссылка Афиша"
Тогда пользователь перешел на страницу "Афиша"
И вводит в поле "строка Поиска" текст "Зелёный слоник"
И нажимает на клавиатуре ENTER
Тогда пользователь перешел на страницу "Афиша - Результаты поиска"
И на странице присутствует "События в ближайшие дни"
Тогда пользователь удаляет текст в поле "строка Поиска"
И вводит в поле "строка Поиска" текст "Головаластик"
И нажимает на клавиатуре ENTER
Такой тестовый сценарий понятен и читаем для любого постороннего человека.
Запускаем!
Для просмотра более детального результата прогона можно воспользоваться командой
cept run acceptance --debugСмотрим результат:
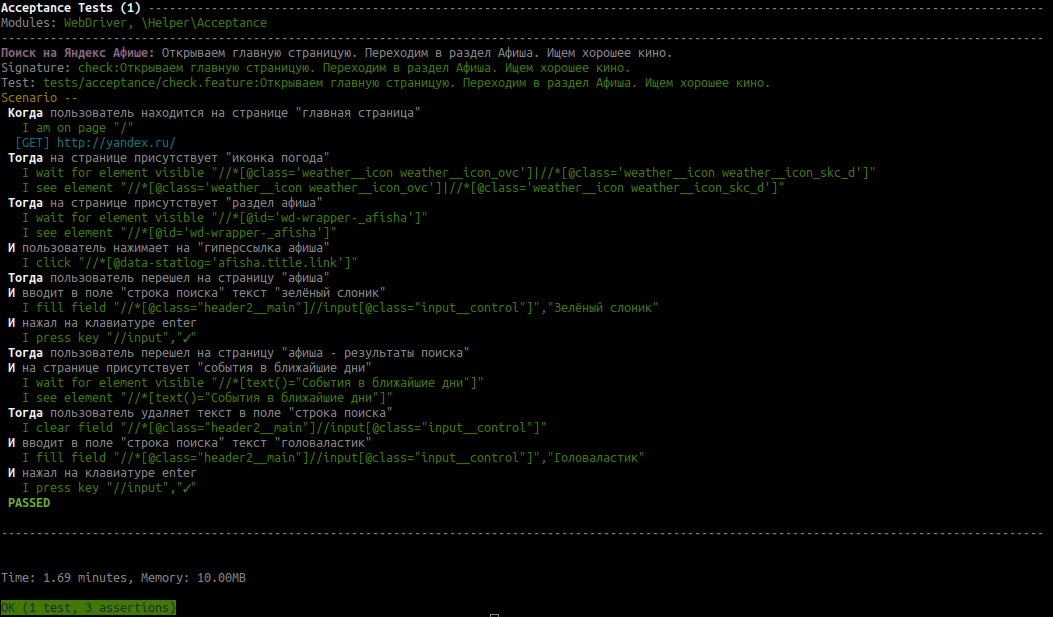
Таким образом, использование Page Object паттерна позволяет отделить все элементы страниц от тестовых сценариев и хранить их в отдельной директории.
С самим проектом можно ознакомиться по ссылке https://github.com/Remneva/ProjectTutorial
Как начинающий автоматизатор, буду признательна, если и вы поделитесь своими идеями и, возможно, подскажете как можно логичнее преобразовать и упростить структуру проекта.
Комментарии (13)

Aconitum_napellus Автор
19.10.2018 18:00В ответ на коммент, который случайно удалила:( епортеры к нему прикручиваются, конечно, тот же Allure, например)

PerlPower
19.10.2018 18:24Спасибо за подробную статью. Что делать в ситуации когда вы по gherkin сгенерировали тесты, переименовали методы тестов, написали реализацию тестов, а потом допустим другой начальник посмотрел результат и сказал что половину нужно переделать. Свои пожелания он тоже записал в виде gherkin требований. Какой тогда будет воркфлоу?
Aconitum_napellus Автор
20.10.2018 11:01Если я правильно поняла, и изменения касаются именно сценария теста, то поступаем точно так же, как и с ручным кейсом. Переписываем его на gherkin, или пишем новый, это уж как проще, по ситуации. Сами методы взаимодействия с элементами страницы стоит продумывать таким образом, чтобы их можно было переиспользовать по макисмуму в разных случаях, то есть, не привязываться ни к конкретным страницам, ни к конкретным элементам, по возможности. Тогда собрать новый сценарий на gherkin из уже имеющихся методов и готовых page object займёт не больше времени, чем написать обычный ручной сценарий.
AlexMt
21.10.2018 00:55Не посчитайте меня хейтером, но:
1) Gherkin в codeception скорее в догонку. Почти 2 года писал на Codeception и много раз убедился что классических Test/Cest/Cept хватает с головой. Cept вообще Gherkin без излишеств.
2) Gherkin и русский язык — зло. Пожалейте тех, кто будет делать таблицы, до символа "|" в русской раскладке добраться сложно.
3) Gherkin в принципе хорошо зашел в Cucumber, ведь язык то по сути DSL, и для Java он выходит как интерпретируемый. Что сильно облегчает работу, ведь мы не должны делать mvn clean test каждый раз. В интерпретируемом языке интерпретируемая обвязка мне кажется излишеством.
4) Очень здорово видеть адептов Codeception на хабре! :)Fesor
21.10.2018 01:18Gherkin в codeception скорее в догонку.
Все так, Михаил этого даже не отрицает)
и для Java он выходит как интерпретируемый.
Открою для вас тайну — все DSL-и так или иначе интерпритируются. И да, кукубрер это не совсем java. Да, есть кукумбер для JVM но реализация геркина есть под все языки. Просто где-то (c# — > SpecFlow например) оно называется не огурцами.
Так что нет. соль не в этом. Вся мощь геркина в specification by example. А то что рекомпилить не надо — ну реализация стэпов меняется чаще чем сценарии. А e2e тесты можно и не на java писать для удобства.
AlexMt
21.10.2018 02:04Я понимаю и полностью согласен, сам использовал Gherkin под java/python/php за весь свой опыт автоматизации. И я согласен за переносимость. Хотя это боль и унижение, если имплементацию нужно делать более одного раза имхо, то есть проще просто отказаться от Gherkin-шагов вообще.
Я говорил про то, что при необходимости написания множества схожих сценариев и прозрачности выполняемых шагов, можно работу разделить условно на две команды, где одна будет имплементить шаги, а другая их писать и переиспользовать в .feature файлах, не задумываясь над реализацией. Но пока что на практике я не видел ни одной команды, где бы это заработалоFesor
21.10.2018 12:56> Хотя это боль и унижение, если имплементацию нужно делать более одного раза
Не сказал бы, обычно просто в разных контекстах тесттирование происходит. Например одни и те же сценарии можно гонять на уровне e2e либо на уровне api. И может статься например что для e2e только самые важные гоняются а для api все. Ну разные есть варианты.
Если же прям совсем одинаковая реализация — то возникают вопросы зачем так сделали.
nizkopal
Привет.
Хм. Про Геркин есть в официальной документации, очень подробно и с примерами: codeception.com/docs/07-BDD
Про PageObject тоже: codeception.com/docs/06-ReusingTestCode
Уверены, что Вы что-то новое описали? :)
Aconitum_napellus Автор
Если вы посмотрите документацию, то увидите, что варианта совместного использования gherkin и page object там не приводится. Иначе, конечно, не пришлось бы ничего выдумывать :)
nizkopal
— Я написал статью о том, как использовать bash-команду rm с ключами -f и -r одновременно.
— Постойте, но эти ключи описаны в документации.
— Да, но там отдельный пункт про каждый из этих ключей и нет пункта про их совместное использование.
Ну такое… :)
Fesor
Геркин сценарии используются для описания приемочных тестов, а не «я кликаю на кнопку». То есть если проще — геркин сценарии не должны быть привязаны к UI. UI — это самая изменчивая штука в приложении, тогда как геркин сценарии пишутся часто (ну или должны писаться) задолго до того как у вас мокапы какие-то появятся. Геркин это вообще отличный инструмент для уточнения требований.
Типичная история — люди видят геркин и думают «о, я смогу заставить своих QA писать тесты! круто!» Хотя попросите вы их писать тесты хоть на PHP с готовыми стэпами — разницы особо не будет. Зато сами по себе сценарии будут значительно более стабильны, проще контролировать что происходит, больше свободы в плане оптимизации стэпов, ну и все плюшки от того что вы пишите более специализированные вещи а не пытаетесь втиснуть все в рамки геркина.
Так что могу сказать что и так выдумывать ничего не надо. Геркин не должен с page object хоть как-то рядом работать. А вот реализации стэпов — могут, но это ничем не отличается от просто использования page object-ов которые уже покрывает дока.
Aconitum_napellus Автор
Спасибо за подробный ответ! В силу практически отсутствуещго опыта я ещё не встречала такого подхода, как вы описали. Полезная для меня информация. Мой пример был навеян подходом, который был реализован на java + selenium + cucumber на одном очень крупном проекте в одной претенциозной компании, из-за чего я по дефолту и незнанию приняла это за некий станарт)