
Как-то я уже писал тут о переезде из Азии в Европу, а теперь хочу написать, что я в этой Европе делаю. Есть такая профессия — DevOps, точнее нет, но так получилось, что это именно то чем я сейчас занимаюсь. Сейчас для оркестрации всего что бежит в докере мы используем rancher, о чем я тоже уже писал. Но вот случилось ужасное, вышел ранчер 2.0 который переехал на kubernetes (дальше просто k8s) и поскольку k8s сейчас действительно стандарт для управления кластером, возникло желание тоже построить всю инфраструктуру заново с блекджеком и библиотекаршами. Что еще добавляет пикантности это то что компания постоянно нанимает разных специалистов из разных стран и с разными традициями и кто-то и собой приносит puppet, кому-то милее ansible, а кто-то вообще считает что Makefile + bash — наше все. Поэтому однозначного мнения как все должно работать просто нет, а очень хочется.
Предварительно был собран такой зоопарк технологий и инструментов:

Управление инфраструктурой
- Minikube
- Rke
- Terraform
- Kops
- Kubespray
- Ansible
Управление приложением
- Kubernetes
- Rancher
- Kubectl
- Helm
- Confd
- Kompose
- Jenkins
Логирование и мониторинг
- Elasticsearch
- Kibana
- Fluent bit
- Telegraf
- Influxdb
- Zabbix
- Prometheus
- Grafana
- Kapacitor
Дальше попробую коротко описать каждый пункт этого зоопарка, описать зачем оно надо и почему было выбрано именно это решение. На самом деле практически любой пункт можно заменить десятком аналогов и мы до сих пор не до конца уверены в выборе, так что если у кого есть свое мнение или рекомендации, с удовольствием прочитаю в комментариях.
Центром всего будет kubernetes потому что сейчас это действительно решение которому просто нет альтернатив, которое поддерживается всеми провайдерами от амазона и микрософта и до mail.ru. Как альтернативы рассматривались
Swarm— который так и не взлетелNomad— который похоже писали чужие для хищниковCattle— движок от ранчера 1.х, на котором сейчас и живем, в принципе все устраивает, но сам ранчер уже от него отказался в пользу k8s так что развития не будет.
Создание инфраструктуры
Для начала нам надо создать инфраструктуру, и развернуть на нем кластер k8s. Вариантов есть несколько, все они работают и поэтому тяжело выбрать лучший.
Minikube — отличный вариант для запуска кластера на на машине разработчика, для тестовых целей.
Rke — Rancher kubernetes engine, прост как дверь минимальный конфиг для создания кластера выглядит
nodes:
- address: localhost
role: [controlplane,worker,etcd]И все, этого достаточно чтоб запустить кластер на локальной машине, при этом позволяет создавать production ready HA кластеры, менять конфигурацию, апгрейдить кластер, дампить etcd базу данных и еще много чего.
Kops — позволяет не только создавать кластер, но еще и предварительно создавать инстансы в aws или gce. Так же позволяет генерировать конфигурацию для terraform. Интересный инструмент, но у нас пока не прижился. Его вполне заменяют terraform + rke при этом проще и гибче.
Kubespray — по факту это просто ansible роль, которая создает k8s кластер, чертовски мощная, гибкая, конфигурируемая. Это практически решение по умолчанию для разворачивания k8s.
Terraform — инструмент для создания инфраструктуры в aws, azure или куче других мест. Гибок, стабилен — рекомендую.
Ansible — это не совсем про k8s но мы его используем везде и тут тоже: подправить конфиги, установить/обновить софт, раздать сертификаты. Дешево и сердито.
Управление приложением
Итак, у нас есть кластер, теперь на нем надо что-то полезное запустить, остался только вопрос как это сделать.
Вариант первый: используем голый k8s все деплоим при помощи kubectl. В принципе этот вариант имеет право на жизнь. Kubectl достаточной мощный инструмент который позволяет сделать все что нам надо, включая деплоймент, апгрейд, контролирование текущего состояния, изменение конфигурации на лету, просмотр логов и подключение к конкретным контейнерам. Но иногда хочется чтоб все было немного удобнее, поэтому переходим идем дальше.
Rancher
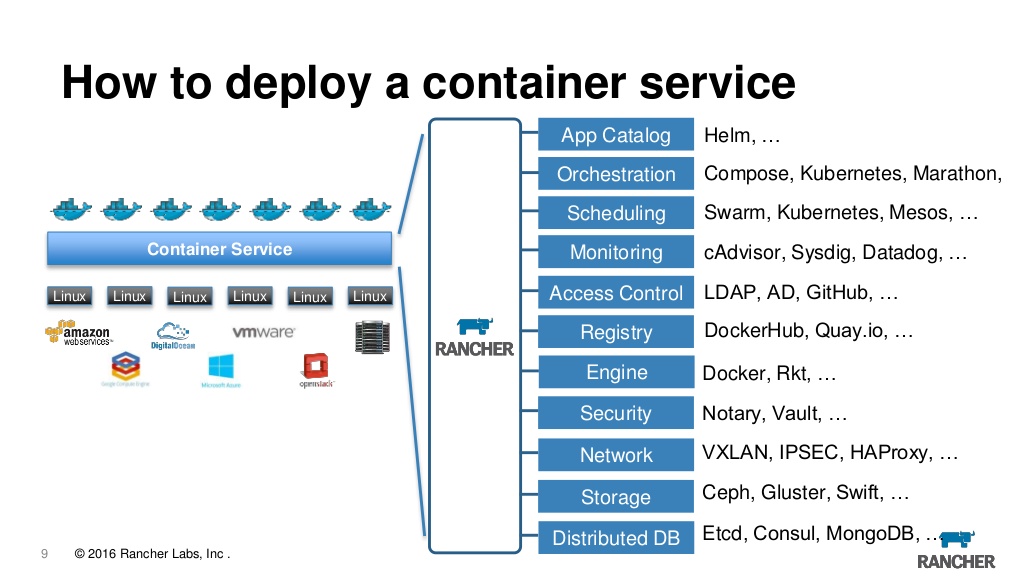
По сути, сейчас rancher это веб морда для управления k8s и заодно много мелких плюшек которые добавляют удобства. Тут и просмотр логов, и доступ в консоль и конфигурирование и апгрейд приложений и управление доступом на основе ролей и встроенный метадата сервер, алармы, перенаправление логов, управление секретами и многое другое. Пользуемся ранчером первой версии уже несколько лет и пока им совершенно довольны, хотя надо признать что при переходе на k8s возникает вопрос, действительно ли он нам нужен. Приятно, что в ранчер можно импортировать любой заранее созданный кластер, причем от любого провайдера то есть в один сервер можно импортировать кластер из EKS из azure и созданный локально и рулить ими из одного места. Более того, если вдруг надоест, то можно просто снести ранчер сервер и продолжить пользоваться кластером напрямую через kubeclt или любой другой инструмент.
Сейчас популярна очень правильная концепция все как код. Например инфраструктура как код, реализована при помощи terraform, сборка как код реализована через jenkins pipeline. Теперь дошла очередь и до приложения. Инсталляция и конфигурация приложения должна тоже быть описана в каком-нибудь манифесте и сохранена в гите. Rancher версий 1.х использовал стандартный docker-compose.yml и все было хорошо, но при переезде на k8s они переключились на helm charts. Helm — с моей точки зрения, совершенно ужасное поделие со странной логикой и архитектурой. Это один из тех проектов от которого остается ощущение, что его написали хищники для чужих или наоборот. Проблема только в том, что в мире k8s хелму просто нет альтернатив и это де факто — стандарт. Поэтому будем колоться плакать, но продолжать использовать helm. В версии 3.х разработчики обещают переписать его практически с нуля, выбросив из него все странности и упростив архитектуру. Вот тогда-то мы и заживем, а пока будем есть что есть.
Еще надо хотя бы упомянуть здесь jenkins, он не относиться напрямую к теме кубернетиса, но именно с его помощью приложения деплоятся в кластер. Он есть, он работает и он тема для отдельной статьи.
Мониторинг
Теперь у нас есть кластер и в нем даже крутиться какое-то приложение, казалось бы — можно выдохнуть, но на самом деле все только начинается. Как стабильно работает наше приложение? Как быстро? Хватает ли ему ресурсов? Что вообще происходит в кластере?
Да следующая тема это мониторинг и логирование. Однозначных ответов тут только три. Хранить логи в elasticsearch, смотреть их через kibana рисовать графики в grafana. На все остальные вопросы есть по десятку правильных ответов.
Grafana
Тут начнем с grafana сама по себе она практически ничего не делает, но ее можно пристегнуть как красивую морду к любой из нижеописанных систем и получить красивые и иногда наглядные графики, кроме того тут же можно настроить алармы, но лучше для этого использовать другие решения например prometheus alertmanager и ElastAlert.
fluent-bit
С моей точки зрения на данный момент это лучший агрегатор и роутер логов, кроме того прямо из коробки в нем есть поддержка k8s. Есть еще Fluentd но он писан на руби и тянет за собой слишком много легаси кода, что делает его гораздо менее привлекательным. Так что если вам нужен какой-то конкретный модуль из fluentd который еще не портирован в fluent-bit пользуйте его, во всех остальных — бит это лучший выбор. Он быстрее, стабильнее, потребляет меньше памяти. Позволяет собирать логи из всех или из избранных контейнеров, фильтровать их, обогащать добавляя данные специфические для кубернетиса и отправлять это все в elasticsearch или во множество других хранилищ. Если сравнить его с традиционными logstash + docker-bit + file-bit это решение однозначно лучше по всем параметрам. Исторически мы все еще используем logspout + logstash но fluent-bit однозначно выигрывает.
Prometheus
Система мониторинга написанная специально для микросервисной архитектуры. Де факто стандарт в индустрии, более того есть еще проект который называется Prometheus Operator, писаный специально для k8s. Что выбрать решает каждый сам, но начинать лучше с голого прометеуса, просто для того чтобы понять логику его работы, она достаточно сильно отличается от привычных систем. Еще надо упомянуть node-exporter который позволяет собирать метрики уровня машины и prometheus-rancher-exporter который позволяет собирать метрики через rancher api. В общем если у вас есть кластер на kubernetes, то prometheus — must have.
Тут можно было бы и остановиться, но исторически сложилось, что у нас есть еще несколько систем мониторинга. Во первых это zabbix очень удобно на одной панели видеть все проблемы всей инфраструктуры. Наличие авто дискавери позволяет на лету находить и добавлять в мониторинг новые сети, ноды, сервисы и вообще практически что угодно, это делает его более чем удобным инструментом для мониторинга динамических инфраструктур. Кроме того в версии 4.0 в заббикс добавили сбор метрик из экспортеров прометеуса и получается, что все это можно очень красиво интегрировать в одну систему. Хотя нет пока однозначного ответа надо ли тащить zabbix в k8s кластер, но попробовать однозначно интересно.
Еще просто как вариант можно использовать TIG (telegraf + influxdb + grafana) настраивается просто, работает стабильно, позволяет агрегировать метрики, по контейнерам, приложениям, нодам и прочее, но по сути полностью дублирует функционал prometheus, а "остаться должен только один".
Вот так и получается, что еще не запустив ничего полезного, надо установить и настроить обвязку из пары десятков вспомогательных сервисов и инструментов. При этом в статье не были подняты вопросы управления постоянными данными, секретами и прочими странными вещами каждый из которых может потянуть на отдельную публикацию.
А как вы себе видите идеальную инфраструктуру?
Если есть мнение напишите пожалуйста в комментариях, а может даже присоединяйтесь к нашей команде и помогите собрать это все на месте.
Комментарии (35)

gecube
22.10.2018 17:14Ой, мне есть что сказать.
Первое. Не Capacitor, а Kapacitor. Это часть стека TICK, который состоит из telegraf+influxdb+chronograf+kapacitor. Кратко. Хронограф — это менеджмент influxdb + графики типа grafana. Заодно в нем можно писать скрипты для kapacitor, который выполняет роль реалтайм процессинга. По-пррстому говоря — на нем можно скользить алертинг. Примеры скриптов есть в гитхабе. Плюсы: законсенная платформа, богатый язык скриптов. Скрипты позволяют все алерты описать как текст и положить в контроль версий. МинусыHA для influxdb, kapacitor. Странноватый язык скриптов. Со всего решения по сути годен только агент телеграфа. Он реально прекрасен. Его, кстати, можно приделать к прометеусу, но есть нюанс — все метрики будут в прометей-формате, но названия не матчатся с такими же методиками в node exporter. И это подстава, т.к. готовых дашборд для той же графаны нет. Придется делать руками. Я думал, что осилю, но нет. Проще раскатать node exporter + prometheus + grafanagecube
22.10.2018 17:20Далее. Если речь идёт про мониторинг докера, то штатным вариантом является установка cadvisor. Он прекрасно интегрируется с прометеусом, но, как всегда, есть нюанс. То ли я его не так готовил, то ли сам по себе cadvisor глючное поделие, но жрет он ресурсы годы, где запущен, как не в себя. Телеграф гораздо более щадяш к ресурсам, но см.выше. Короче, нужно решить каким образом снимать метрики докер-контейнеров. В общем, здесь prometheus + cadvisor = прокол.
Едем дальше.
Агрегация логов. Самый оптимум — graylog. Считай, тот же эластик, но с человеческим лицом. Для системного логгирования можно использовать в качестве цели для rsyslog или все логгирование сделать вокруг journald и, например, передавать его gelf. Кстати, docker умеет и напрямую в gelf, и в journald. А с последним ещё и команда docker logs работает, т.к. логи есть на роде, что удобно разработчикам.
Поэтому у меня есть стойкие сомнения в необходимости fluentd/fluent-beatgecube
22.10.2018 17:27Но при любом раскладе, мне fluentd, и его производные, нравятся больше, чем elastic'овский beats / logstash. Уж, извините.
Про алертинг из логов — тоже интересная тема. Сейчас реализуется промежуточными самописными сервисами, которые дёргают эластик определенным запросом и пишут в базу результат. Можно было обойтись алертинг из кибаны (но он платный!!!) или алертингом из графаны ( а он ущербный и по нескольким критериям/граничным значениям плохо работает, а ещё вопросы с темплейтингом и т.п ). Поэтому интересно было бы почитать про ElastAlert — возможно, узнаю что-то новое для себя.
Хочется подчеркнуть, что в масштабах энтерпрайза — платформа для мониторинга — это не единый продукт, а платформа, состоящая из нескольких законченных продуктов и прослоек между ними. Увы, поиски серебряной пули и единой коробки, которая закрывает все потребности, не увенчались успехом.kefiiir Автор
22.10.2018 17:39>Но при любом раскладе, мне fluentd, и его производные, нравятся больше, чем elastic'овский beats / logstash. Уж, извините.
тут даже спорить не буду, сам того же мнения.
>Поэтому интересно было бы почитать про ElastAlert
Есть не нулевая вероятность, что в ближайшем будущем займусь им, и за одно по ходу дела напишу статью со всеми граблями
>Увы, поиски серебряной пули и единой коробки, которая закрывает все потребности, не увенчались успехом.
Постоянный ее поиск и доработка напильником, так можно описать рабочие задачи.
Спасибо за коментарии, было интересно услышать чужое мнение.
kefiiir Автор
22.10.2018 17:35cadvisor
поставить, посмотреть, порадоваться и снети. По крайней мере тот же telegraf выдает те же метрики, но жрет ресурсов на порядок меньше.
graylog — не зашел. Может быть я просто не умею его готовить, но я не понял зачем он мне нужен.
gelf и rsyslog просто уступают fluent-bit и в надежности и в функциональности. И с тем и с другим были проблемы, кроме того возможность обогащения метаданными имеющим отношение именно к k8s с именами подов и прочего. Добавить сюда кучу плагинов и футпринтв в 450kb для меня выбор очевиден.gecube
22.10.2018 17:48cadvisor
поставить, посмотреть, порадоваться и снети. По крайней мере тот же telegraf выдает те же метрики, но жрет ресурсов на порядок меньше.
да, я об этом же и говорю. Но, повторюсь, что те же дашборды для cadvisor/prometheus в графане лучше, чем дашборды для мониторинга docker для influxdb/telegraf.
Но дашборды доработать всегда можно )
gecube
22.10.2018 18:11Да, кстати, внезапно — fluent bit и fluent-beats (скорее даже fluent-plugin-beats) оказались разными (!) продуктами. Я малость удивлен. Аргх. Надо же было развести почти одинаковых названий )
kefiiir Автор
22.10.2018 17:27>Kapacitor
да, спасибо, просто описка.
>Со всего решения по сути годен только агент телеграфа.
У меня тоже сложилось именно такое мнение, агент отличен, все остальное дальше песочницы не пошло. Хотя надо признать последний раз на это все смотрел примерно год назад, и тогда оно было просто недописано до приемлемого состояния, поэтому вариант Tergraf + Inluxdb + Grafana был выбран, как более функциональный и стабильный. Кроме того под ту же графану с телеграфом есть готовые дашборды которые пришлось совсем немного обрабатывать напильником под свои нужды.Stanislavvv
24.10.2018 12:58Рекомендую обратить внимание на clickhouse вместо influxdb.
1) нормальная репликация данных между нодами
2) почти полноценный sql
3) с ним работает и телеграф и графана (плугин от vertamedia)
4) позволяет хранить данные столько, сколько есть места и работать с ними почти независимо от объёма оперативной памяти (в отличие от influxdb)
5) на большинстве запросов упирается в чтение колонок с диска, если вообще упирается
Перешли на него после того, как не смогли сделать так, чтоб influxdb работал устойчиво при попытке хранить сырые неагрегированные данные не за 3 последних дня, а за 7 — тупо переставало хватать памяти.
Сейчас данные хранятся за 6 месяцев.
Правда, у кх есть и недостатки:
1) настоятельно рекомендуется заливать данные большими кусками не чаще, чем примерно раз в секунду (если не получается большими кусками — можно инсертить в таблицу типа Buffer, которая соберёт всё в один кусок и засунет в таблицу-бекенд)
Из-за этого пункта мы слегка попатчили плугин для записи в кх, чтобы метрики улетали не напрямую в таблицы (напр. «cpu»), а в буферные («buff_cpu»). Можно было бы и со стороны БД переделать, конечно.
2) если нужен кластер с репликацией — обязательно требуется zookeeper
3) несмотря на то, что язык запросов более sql, чем в influxdb — это не совсем sql и кой-какие вещи там либо ещё не реализованы, либо даже не будут реализовываться.gecube
24.10.2018 13:59Мне кажется, что в качестве оперативного средства хранения — все-таки prometheus.
Т.е. цепочка такая
а) агент (telegraf или node_exporter+на каждый сервис своя статусная страница в формате прометея)
б) агрегатор (prometheus)
в) оповещалка (кластер из alertmanager)
г) визуализация (grafana)
д) ДОЛГОВРЕМЕННОЕ хранение метрик — вот вопрос. Решения есть вроде Timescaledb, m3db и федерации prometheus. Но никто не мешает писать и в clickhouse, причем пачками и тачками.
А еще можно поддаться на рекламу mail.ru и начать везде вставлять tarantool (в нем есть, кстати, позитивные моменты)
tbicr
22.10.2018 20:39Слышал, что prometheus плох с push моделью, если сравнивать с telegraf + influex, может сталкивались?
kefiiir Автор
23.10.2018 10:44Prometheus вообще не писался из расчета на push, из коробки там только pull. Есть несколько костылей типа pushgatway но у него совсем другие задачи, он скорее для лямбд или прочих коротко живущих сущностей. Еще есть StatsD exporter и Prometheus Aggregation Gateway, но они тоже немного для другого и даже по официальной документации больше похожи на временные решения «We recommend this only as an intermediate solution and recommend switching to native Prometheus instrumentation in the long term.»
tbicr
23.10.2018 11:38Тогда возникает вопрос насколько хорошо он работает с мультипроцессорными приложениями и воркерами, запускаемыми либо по крону, либо по событиям в rabbit/kafka? Нужно ли ему говорить ручками, что появилась новая машина или есть механизм autodiscovery?
kefiiir Автор
23.10.2018 11:52Если коротко то да. Есть лучший на рынке механизм autodiscovery потому что именно под такие задачи и писался изначально. Здесь можно загуглить про kubernetes annotations и уже упомянутый pushgatway. Кроме того он умеет подключатся например к CloudWatch и брать информацию о созданых/запущеных нодах или лямдах. Вобщем тяжело придумать ситуацию в которая не покрыта функционалом. Еще можно использовать Prometheus Operator в котором почти все, что может относиться к прометеусу настроена из коробки.
gecube
23.10.2018 11:56+1Меня очень волнует вопрос мониторинга ETL с помощью Прометеуса. То что я вижу — выглядит как костыли. Все-таки push-идеология лучше подходит для ETL'ей.
kefiiir Автор
23.10.2018 12:10тут уже очень специфический вопрос, если например обработка данных идет секунды, то мониторить лучше принимающий сервис, сколько принято сколько обработано и отдельно длинну очереди. Дополнительно метрики обрабатывающего процесса можно отправлять в пуш гейтвей, но это уже зависит от логики вашего приложения. Если же обработка идет значительно дольше среднего скрап периода, то тогда смело можно просто к обработчику применять правило автодискавери. А вообще как тут уже упоминали в комментариях — серебряной пули не существует. Push проще для понимания, что-то произошло — ты это что-то отправил, но в прометеусе выбрали другую модель в факе даже есть такой вопрос з забавным ответом (Overall, we believe that pulling is slightly better than pushing, but it should not be considered a major point when considering a monitoring system). В том же забиксе тоже существуют как активные так и пассивные проверки (читай пуш и пул) для каждых задач надо выбирать наиболее подходящий инструмент, и именно муки выбора и сподвигли меня на написание этой статьи.
Vermut666
23.10.2018 12:33Очень актуальная для меня сейчас статья. Хочеться уже договориться однажды всем и не изобретать каждый раз новый велосипед, тем более, что ситуация на рынке продуктов начинает стабилизироваться.
Моя задача похожа, но в ней акцент на AWS инфраструктуру (по возможности без вендор-лока).
Развертывание: terraform в ASG на спот-инстансах.
Оркестратор: EKS (kubernetes) + minikube для локальных. Docker for Win/Mac имеет встроенный k8 режим тоже.
Релиз-менеждер: helm c надеждами на helm3. industry-standard, никуда не деться.
А вот дальше терзания. Хочеться остаться в ELK, т.к. он есть как SaaS и в AWS, и отдельно. Логи уходят туда. Вероятнее всего APM тоже туда.
Дальше большой соблазн не плодить и метрики слать туда же, благо есть всякие Beats. Но стандарт у нас Prometheus с возможностью pull, Grafana, которая удобнее.
Ошибки — в ELK или в Sentry? Sentry опять таки стандарт.
Не слишком ли много всего получится? ELK, Prometheus+Grafana, и что-то для Alerting. Что можно с чем объединить?
kefiiir Автор
23.10.2018 12:54Слишком много всего получается, но меньше тоже никак. От метрик в ELK отказались по целому ряду причин, медленно, неэффективно по месту и памяти, сырая система алармов в бесплатной версии, родные биты очень капризные иногда просто переставали собирать данные. Логи в ELK для общего разбора что происходит и некоторых очень специфических метрик, которые берутся из логов приложения. Параллельно логи так же уходят в Sentry, уже дублирование, но так просто удобнее. Что тут можно оптимизировать просто не вижу, кроме того что logspout + logstash заменим на fluent-bit.
Дальше все еще хуже, метрики это Telegraf + InfluxDB + Grafana тут же базовые алармы, все это крутится естественно внутри докеров. А потом опять начинается дублирование: Zabbix на котором крутятся веб скрипы, метрики типа реальная скорость подключения от одного дата центра к другому и еще пару штук метрик, просто потому что можем и потому что все проблемы видеть на одном дашборде удобнее и еще потому, что хорошая система нотификации. Вот большую часть этого может на себя взять Prometheus за исключением внешних проверок доступности. Alerts тоже очень хорошо реализованы в Prometheus.
Хочется объединить и так же хочется, но при этом не хочется терять удобство, вот и мучаемся.Vermut666
23.10.2018 13:08Т.е. пытаться заменить Telegraf+InfluxDB+Grafana+Zabbix на Telegraf+Prometheus+Grafana?
kefiiir Автор
23.10.2018 13:14нет, скорее всего просто выкинуть Telegraf+InfluxDB. А вот что делать с забиксом еще не решили, хочется сначала потестировать новые плюшки типа «pull lprometheus metrix to zabbix» а еще есть странный вариант zabbix-exporter для прометеуса, но вот он пожалуй совсем не нужен. Пока что склоняемся от забикса оставить только внешние тесты и веб скрипты, просто потому, что это тоже надо где-то делать, а забикс все равно используется для внутренней инфраструктуры.
gecube
23.10.2018 14:15Sentry он немного для другого, чем ELK. ELK — это общее решение, универсальное. А sentry — специализированная штука, которая ловит эксепшены (т.е. это инструмент разработчика в первую очередь). Сделать из ELK подобие сентри можно, но я не видел хороших готовых коробочных решений. Я видел какое-то законченное решение для NPM на базе Эластика, но, к сожалению, название забыл.
Еще могу упомянуть такие страшные штуки как sensu — фреймворк для мониторинга (т.е. по сути аналог заббикс и Ко), но с широким распространением prometheus, sensu скорее всего канет в Лету.

weslyg
23.10.2018 13:32Может кто знает, что нибудь адекватнее alertmanager для prometheus?
kefiiir Автор
23.10.2018 13:36ну его надо один раз грокнуть и больше ничего не надо, функционал у него покрывает все. А если хочется что-то простое и сразу можно прикрутить графану, там есть базовая система алармов. Еще можно взять какое-нибудь готовое решение вроде kube-prometheus
и просто пользоваться им как примером.gecube
23.10.2018 14:11еще раз повторюсь, что в графане система алармов убогая. Совсем для нищих.
Из плюсов, что графана умеет алертить через веб-хуки или через тот же alertmanager, что может дать возможность построить интересную систему. Но при этом алерты будут приходить из разных источников (прометеус, графана и что там еще в инфраструктуре есть).kefiiir Автор
23.10.2018 14:16Так мы уже договорились, что она убогая, тут и спорить не о чем.
P.S.
Так просто информации для: зато она умеет картинки отправлять =)
weslyg
23.10.2018 15:05Она умеет) но даже синглстат не запилили, я пытался скостылить, не вышло… Эх работала бы moira с prometheus… мечты мечты…
kefiiir Автор
23.10.2018 15:29Чисто в порядке бреда не пробовали moria + Graphite Exporter. Собирать и в графите отправлять их в морию, а паралельно через экспортер в прометеус. Я понимаю, что конструкция странная, но например можно node-exporter + alertmanager заменить на collectd + moria + Graphite Exporter. Хотя бы ради эксперимента.
gecube
23.10.2018 16:06я moira попробовал, но, во-первых, их уже две версии. Во-вторых, там даже нет внятной инструкции по установке. Все как-то через одно место. А вообще, конечно, проект перспективный был (или есть!?)
kefiiir Автор
23.10.2018 17:49Вот тут не подскажу, у себя в голове похоронил графит и все что с ним связно, как-то не выглядит он как современный фреймворк, хотя его сейчас местами на golang переписывают, все модно молодежно.
gecube
23.10.2018 20:04Очень правильная история есть в bosun: эта среда позволяет проверять сработал ли бы alert на исторических данных. Очень полезно для отладки alert'ов (а у них, между прочим, свой жизненный цикл есть, как и у метрик, и у всего, что можно описать -as-a-Code).
kefiiir Автор
25.10.2018 13:02Только что вычитал, что bosun умет работать с elasticsearch. Есть ли смысл ставить его вместо elastalert?
buldo
23.10.2018 22:35Есть. Мойрой вроде как пользуются в довольно крупных проектах, да и Контур с неё никогда не слезет и будет развивать.
gecube
24.10.2018 10:56Контур пускай пользует. Это их внутренний продукт, который они опенсорснули.
Я говорил о том, что документация на грани фантастики.
Репозиторий находится с полтычка: github.com/moira-alert
А дальше начинаются чудеса.
hub.docker.com/r/kontur/moira — описания нет, а есть еще и такое — hub.docker.com/r/skbkontur/moira-web
github.com/moira-alert/doc — здесь докер-компоуз (очень логично, т.к. doc обычно называют документацию) — эти файлы у меня и не взлетели. Образы, кстати, указаны другие, чем kontur/moira
и т.д.
короче, нужен нормальный гайд для новичков. Вот запустить graylog какой-нибудь или prometheus можно вообще за пять минут. А здесь какой-то мрак.
Я уж не говорю о том, что заточка на Графит — такое себе. Хотя я бы даже его прицепил, при условии, что moira взлетит и ее можно будет оценить для использования.
methodx
Хороший рассказ, а также подача материала. Спасибо.
Никак. Все зависит от конкретного случая, требований к проекту, архитектурной карты и.т.д…
kefiiir Автор
>Никак. Все зависит от конкретного случая, требований к проекту, архитектурной карты и.т.д…
Это помнятно, просто интеремно было бы послушать еще что-то мнение.