

Приходя на новый проект, я регулярно сталкиваюсь с одной из следующих ситуаций:
- Тестов нет совсем.
- Тестов мало, их редко пишут и не запускают на постоянной основе.
- Тесты присутствуют и включены в CI (Continuous Integration), но приносят больше вреда, чем пользы.
К сожалению, именно к последнему сценарию часто приводят серьезные попытки начать внедрять тестирование при отсутствии соответствующих навыков.
Что можно сделать, чтобы изменить сложившуюся ситуацию? Идея использования тестов не нова. При этом большинство туториалов напоминают знаменитую картинку про то, как нарисовать сову: подключаем JUnit, пишем первый тест, используем первый мок — и вперед! Такие статьи не отвечают на вопросы о том, какие тесты нужно писать, на что стоит обращать внимание и как со всем этим жить. Отсюда и родилась идея данной статьи. Я постарался кратко обобщить свой опыт внедрения тестов в разных проектах, чтобы облегчить этот путь для всех желающих.
Совсем вводных статей по данной теме более чем достаточно, поэтому не будем повторяться и попытаемся зайти с другой стороны. В первой части развенчаем миф о том, что тестирование несет исключительно дополнительные затраты. Будет показано, как создание качественных тестов может в свою очередь ускорить процесс разработки. Затем на примере небольшого проекта будут рассмотрены базовые принципы и правила, которых стоит придерживаться, чтобы эту выгоду реализовать. Наконец, в заключительном разделе будут даны конкретные рекомендации по внедрению: как избежать типичных проблем, когда тесты начинают, наоборот, существенно тормозить разработку.
Так как моя основная специализация — Java backend, то в примерах будет использован следующий стек технологий: Java, JUnit, H2, Mockito, Spring, Hibernate. При этом значительная часть статьи посвящена общим вопросам тестирования и советы в ней применимы к гораздо более широкому кругу задач.
Однако будьте осторожны! Тесты вызывают сильнейшую зависимость: однажды научившись ими пользоваться, вы уже не сможете без них жить.
Тесты vs скорость разработки
Главные вопросы, которые возникают при обсуждении внедрения тестирования: сколько времени займет написание тестов и какие преимущества это будет иметь? Тестирование, как и любая другая технология, потребует серьезных усилий на освоение и внедрение, поэтому на первых порах никакой значимой выгоды ожидать не стоит. Что касается временных затрат, то они сильно зависят от конкретной команды. Однако меньше чем на 20–30 % дополнительных затрат на кодирование рассчитывать точно не стоит. Меньшего просто не хватит для достижения хоть какого-то результата. Ожидание мгновенной отдачи часто является главной причиной сворачивания этой деятельности еще до того, как тесты станут приносить пользу.
Но о какой же тогда эффективности идет речь? Давайте отбросим лирику о трудностях внедрения и посмотрим, какие конкретные возможности по экономии времени открывает тестирование.
Запуск кода в произвольном месте
При отсутствии тестов в проекте единственным способом запуска является поднятие приложения целиком. Хорошо, если на это будет уходить секунд 15–20, но далеко не редки случаи больших проектов, в которых полноценный запуск может занимать от нескольких минут. Что же это означает для разработчиков? Существенную часть их рабочего времени будут составлять эти короткие сессии ожидания, на протяжении которых нельзя продолжать работать над текущей задачей, но при этом времени на переключение на что-то другое слишком мало. Многие хотя бы раз сталкивались с такими проектами, где написанный за час код требует многочасовой отладки из-за долгих перезапусков между исправлениями. В тестах же можно ограничиться запуском маленьких частей приложения, что позволит значительно сократить время ожидания и повысит продуктивность работы над кодом.
Кроме того, возможность запуска кода в произвольном месте ведет к более тщательной отладке. Зачастую проверка даже основных позитивных сценариев использования через интерфейс приложения требует серьезных усилий и времени. Наличие же тестов позволяет проводить детальную проверку конкретного функционала гораздо проще и быстрее.
Еще один плюс — возможность регулирования размера тестируемого юнита. В зависимости от сложности проверяемой логики, можно ограничиться одним методом, классом, группой классов, реализующих некоторую функциональность, сервисом и так далее, вплоть до автоматизации тестирования приложения целиком. Такая гибкость позволяет разгрузить высокоуровневые тесты от многих деталей за счет того, что они будут проверены на более низких уровнях.
Повторный запуск тестов
Этот плюс часто приводят как суть автоматизации тестирования, однако давайте рассмотрим его под менее привычным углом зрения. Какие новые возможности для разработчиков он открывает?
Во-первых, каждый новый пришедший на проект разработчик сможет легко запустить имеющиеся тесты, чтобы разобраться в логике приложения на примерах. К сожалению, важность этого сильно недооценена. В современных условиях одни и те же люди редко работают над проектом дольше 1–2 лет. А так как команды состоят из нескольких человек, то появление нового участника каждые 2–3 месяца — типичная ситуация для относительно крупных проектов. Особо тяжелые проекты переживают смены целых поколений разработчиков! Возможность легко запустить любую часть приложения и посмотреть на поведение системы в разы упрощает погружение новых программистов в проект. Кроме того, более детальное изучение логики кода уменьшает количество допущенных ошибок на выходе и время на их отладку в будущем.
Во-вторых, возможность легко убедиться в том, что приложение работает корректно, открывает дорогу для непрерывного рефакторинга (Continuous Refactoring). Этот термин, к сожалению, гораздо менее популярен, чем CI. Он означает, что рефакторинг можно и нужно делать при каждой доработке кода. Именно регулярное следование небезызвестному правилу бойскаута «оставь место стоянки чище, чем оно было до твоего прихода», позволяет избегать деградации кодовой базы и гарантирует проекту долгую и счастливую жизнь.
Отладка
Отладка уже была упомянута в предыдущих пунктах, но этот момент настолько важен, что заслуживает более внимательного рассмотрения. К сожалению, не существует достоверного способа измерить соотношение между временем, потраченным на написание кода и на его отладку, так как эти процессы практически неотделимы друг от друга. Тем не менее наличие качественных тестов в проекте существенно сокращает время отладки, вплоть до почти полного отсутствия необходимости запускать дебаггер.
Эффективность
Все перечисленное может дать существенную экономию времени на первичную отладку кода. При правильном подходе только это уже окупит все дополнительные затраты на разработку. Остальные бонусы тестирования — повышение качества кодовой базы (плохо спроектированный код тяжело тестировать), уменьшение количества дефектов, возможность убедиться в корректности кода в любой момент и т. д. — достанутся практически бесплатно.
От теории к практике
На словах это все выглядит неплохо, но давайте перейдем к делу. Как уже было сказано ранее, материалов о том, как произвести первичную настройку тестовой среды, более чем достаточно. Потому сразу перейдем к готовому проекту. Исходники тут.
Задача
В качестве шаблонной задачки рассмотрим небольшой фрагмент бэкенда интернет-магазина. Напишем типовой API для работы с продуктами: создание, получение, редактирование. А также пару методов для работы с клиентами: смена «любимого продукта» и расчет бонусных баллов по заказу.
Доменная модель
Чтобы не перегружать пример, ограничимся минимальным набором полей и классов.
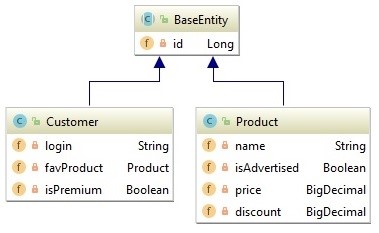
У клиента (Customer) есть логин, ссылка на любимый продукт и флаг, указывающий на то, является ли он премиальным клиентом.
У продукта (Product) — название, цена, скидка и флаг, указывающий на то, рекламируется ли он в данный момент.
Структура проекта
Структура основного кода проекта выглядит следующим образом.
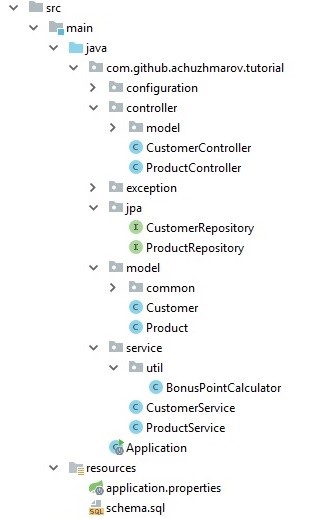
Классы разбиты по слоям:
- Model — доменная модель проекта;
- Jpa — репозитории для работы с БД на основе Spring Data;
- Service — бизнес-логика приложения;
- Controller — контроллеры, реализующие API.
Структура юнит-тестов.
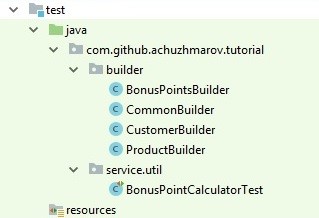
Классы тестов лежат в тех же пакетах, что и оригинальный код. Дополнительно создан пакет с билдерами для подготовки тестовых данных, но об этом ниже.
Удобно разделять юнит-тесты и интеграционные тесты. Они зачастую имеют разные зависимости, и для комфортной разработки должна быть возможность запустить либо одни, либо другие. Этого можно добиться разными способами: конвенции именования, модули, пакеты, sourceSets. Выбор конкретного способа — исключительно вопрос вкуса. В данном проекте интеграционные тесты лежат в отдельном sourceSet — integrationTest.
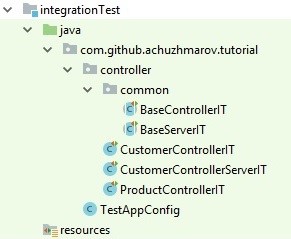
Подобно юнит-тестам, классы с интеграционными тестами лежат в тех же пакетах, что и оригинальный код. Дополнительно есть базовые классы, которые помогают избавиться от дублирования конфигурации и при необходимости содержат полезные универсальные методы.
Интеграционные тесты
Есть разные подходы к тому, с каких тестов стоит начинать. В случае, если проверяемая логика не очень сложна, можно сразу переходить к интеграционным (их еще иногда называют приемочными — acceptance). В отличие от юнит-тестов они позволяют убедиться, что приложение в целом работает корректно.
Архитектура
Для начала надо определиться, на каком конкретно уровне будут выполняться интеграционные проверки. Spring Boot предоставляет полную свободу выбора: можно поднимать часть контекста, весь контекст и даже полноценный сервер, доступный из тестов. При увеличении размера приложения этот вопрос становится все более сложным. Часто приходится писать разные тесты на разных уровнях.
Хорошей точкой старта будут тесты контроллеров без запуска сервера. В относительно небольших приложениях вполне приемлемо поднимать весь контекст целиком, так как по умолчанию он переиспользуется между тестами и инициализируется только один раз. Рассмотрим основные методы класса
ProductController:@PostMapping("new")
public Product createProduct(@RequestBody Product product) {
return productService.createProduct(product);
}
@GetMapping("{productId}")
public Product getProduct(@PathVariable("productId") long productId) {
return productService.getProduct(productId);
}
@PostMapping("{productId}/edit")
public void updateProduct(@PathVariable("productId") long productId, @RequestBody Product product) {
productService.updateProduct(productId, product);
}Вопрос обработки ошибок оставим в стороне. Предположим, что она реализована снаружи на основе анализа выбрасываемых исключений. Код методов очень простой, их реализация в сервисе
ProductService не сильно сложнее:@Transactional(readOnly = true)
public Product getProduct(Long productId) {
return productRepository.findById(productId)
.orElseThrow(() -> new DataNotFoundException("Product", productId));
}
@Transactional
public Product createProduct(Product product) {
return productRepository.save(new Product(product));
}
@Transactional
public Product updateProduct(Long productId, Product product) {
Product dbProduct = productRepository.findById(productId)
.orElseThrow(() -> new DataNotFoundException("Product", productId));
dbProduct.setPrice(product.getPrice());
dbProduct.setDiscount(product.getDiscount());
dbProduct.setName(product.getName());
dbProduct.setIsAdvertised(product.isAdvertised());
return productRepository.save(dbProduct);
}Репозиторий
ProductRepository вообще не содержит собственных методов:public interface ProductRepository extends JpaRepository<Product, Long> {
}Все намекает на то, что юнит-тесты этим классам не нужны просто потому, что всю цепочку можно легко и эффективно проверить несколькими интеграционными тестами. Дублирование одних и тех же проверок в разных тестах приводит к усложнению отладки. В случае появления ошибки в коде теперь упадет не один тест, а сразу 10–15. Это в свою очередь потребует дальнейшего анализа. Если же дублирования нет, то единственный упавший тест, скорее всего, сразу укажет на ошибку.
Конфигурация
Для удобства выделим базовый класс
BaseControllerIT, который содержит конфигурацию Spring и пару полей:@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
@Transactional
public abstract class BaseControllerIT {
@Autowired
protected ProductRepository productRepository;
@Autowired
protected CustomerRepository customerRepository;
}Репозитории вынесены в базовый класс, чтобы не захламлять классы тестов. Их роль исключительно вспомогательная: подготовка данных и проверка состояния базы после работы контроллера. При увеличении размера приложения это может перестать быть удобным, но для начала вполне подойдет.
Основная конфигурация Spring задается следующими строчками:
@SpringBootTest — используется для того, чтобы задать контекст приложения. WebEnvironment.NONE означает, что веб-контекст поднимать не надо.@Transactional — оборачивает все тесты класса в транзакцию с автоматическим откатом для сохранения состояния базы.Структура теста
Перейдем к минималистичному набору тестов для класса
ProductController — ProductControllerIT.@Test
public void createProduct_productSaved() {
Product product =
product("productName").price("1.01").discount("0.1").advertised(true).build();
Product createdProduct = productController.createProduct(product);
Product dbProduct = productRepository.getOne(createdProduct.getId());
assertEquals("productName", dbProduct.getName());
assertEquals(number("1.01"), dbProduct.getPrice());
assertEquals(number("0.1"), dbProduct.getDiscount());
assertEquals(true, dbProduct.isAdvertised());
}Код теста должен быть предельно прост и понятен с первого взгляда. Если это не так, то большая часть плюсов тестов, описанных в первом разделе статьи, теряется. Хорошей практикой является разделение тела теста на три визуально отделяемые друг от друга части: подготовка данных, вызов тестируемого метода, валидация результатов. При этом очень желательно, чтобы код теста помещался на экране целиком.
Лично мне кажется более наглядным, когда тестовые значения из секции подготовки данных используются потом и в проверках. Альтернативно можно было бы явно сравнивать объекты, например так:
assertEquals(product, dbProduct);В другом тесте на обновление информации о продукте (
updateProduct) видно, что создание данных стало немного сложнее и для сохранения визуальной целостности трех частей теста они отделены двумя переводами строк подряд:@Test
public void updateProduct_productUpdated() {
Product product = product("productName").build();
productRepository.save(product);
Product updatedProduct = product("updatedName").price("1.1").discount("0.5").advertised(true).build();
updatedProduct.setId(product.getId());
productController.updateProduct(product.getId(), updatedProduct);
Product dbProduct = productRepository.getOne(product.getId());
assertEquals("updatedName", dbProduct.getName());
assertEquals(number("1.1"), dbProduct.getPrice());
assertEquals(number("0.5"), dbProduct.getDiscount());
assertEquals(true, dbProduct.isAdvertised());
}Каждую из трех частей теста можно упростить. Для подготовки данных отлично подходят тестовые билдеры, которые содержат в себе логику создания объектов, удобную для использования из тестов. Слишком сложные вызовы методов можно выносить во вспомогательные методы внутри тестовых классов, скрывая часть нерелевантных для данного класса параметров. Для упрощения сложных проверок можно также писать вспомогательные функции либо реализовывать собственные матчеры. Главное при всех этих упрощениях — не потерять наглядности теста: все должно быть понятно с первого взгляда на основной метод, без необходимости перехода вглубь.
Тестовые билдеры
Тестовые билдеры заслуживают отдельного внимания. Инкапсуляция логики создания объектов упрощает сопровождение тестов. В частности, заполнение не релевантных данному тесту полей модели можно скрыть внутри билдера. Для этого нужно не создавать его напрямую, а использовать статический метод, который заполнит недостающие поля значениями по умолчанию. Например, в случае появления новых обязательных полей в модели их можно будет легко добавить в этот метод. В
ProductBuilder он выглядит так:public static ProductBuilder product(String name) {
return new ProductBuilder()
.name(name)
.advertised(false)
.price("0.00");
}Название теста
Крайне важно понимать, что конкретно проверяется в данном тесте. Для наглядности лучше всего дать ответ на этот вопрос в его названии. На примере тестов для метода
getProduct рассмотрим используемую конвенцию именования:@Test
public void getProduct_oneProductInDb_productReturned() {
Product product = product("productName").build();
productRepository.save(product);
Product result = productController.getProduct(product.getId());
assertEquals("productName", result.getName());
}
@Test
public void getProduct_twoProductsInDb_correctProductReturned() {
Product product1 = product("product1").build();
Product product2 = product("product2").build();
productRepository.save(product1);
productRepository.save(product2);
Product result = productController.getProduct(product1.getId());
assertEquals("product1", result.getName());
}В общем случае заголовок тестового метода состоит из трех частей, разделенных подчеркиванием: имя тестируемого метода, сценарий, ожидаемый результат. Однако здравый смысл никто не отменял, и вполне оправданным может быть опускание каких-то частей названия, если они не нужны в данном контексте (например, сценарий в единственном тесте на создание продукта). Цель такого именования — добиться того, чтобы суть каждого теста была понятна без изучения кода. Это делает окошко результатов прохождения тестов максимально наглядным, а именно с него обычно и начинается работа с тестами.
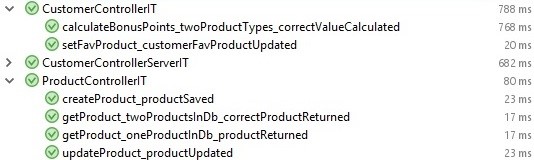
Выводы
Вот и все. На первое время минималистичного набора из четырех тестов вполне достаточно для проверки методов класса
ProductController. В случае выявления багов всегда можно будет добавить недостающие тесты. При этом минимальное количество тестов значительно сокращает время и силы на их поддержку. В свою очередь это является критичным в процессе внедрения тестирования, так как первые тесты обычно получаются не самого лучшего качества и создают много неожиданных проблем. В то же время такого тестового набора вполне достаточно для получения бонусов, описанных в первой части статьи.Стоит обратить внимание, что такие тесты не проверяют веб-слой приложения, однако зачастую этого и не требуется. При необходимости можно написать отдельные тесты для веб-слоя с заглушкой вместо базы (
@WebMvcTest, MockMvc, @MockBean) или использовать полноценный сервер. Последнее может затруднить отладку и усложнить работу с транзакциями, поскольку транзакцию сервера тест уже контролировать не сможет. Пример такого интеграционного теста можно посмотреть в классе CustomerControllerServerIT.Юнит-тесты
Юнит-тесты имеют ряд преимуществ перед интеграционными:
- Запуск занимает миллисекунды;
- Небольшой размер тестируемого юнита;
- Легко реализовать проверку большого количества вариантов, так как при вызове метода напрямую подготовка данных значительно упрощается.
Несмотря на это, юнит-тесты по своей природе не могут гарантировать работоспособность приложения в целом и не позволяют избежать написания интеграционных. Если логика тестируемого юнита проста, дублирование интеграционных проверок юнит-тестами не принесет никакой выгоды, а лишь добавит больше кода для поддержки.
Единственный класс в данном примере, который заслуживает юнит-тестирования, — это
BonusPointCalculator. Его отличительная особенность — большое количество ветвлений бизнес-логики. Например, предполагается, что покупатель получает бонусами 10 % от стоимости продукта, помноженные на не более чем 2 мультипликатора из следующего списка:- Продукт стоит больше 10 000 (? 4);
- Продукт участвует в рекламной кампании (? 3);
- Продукт является «любимым» продуктом клиента (? 5);
- Клиент имеет премиальный статус (? 2);
- В случае, если клиент имеет премиальный статус и покупает «любимый» продукт, вместо двух обозначенных мультипликаторов используется один (? 8).
В реальной жизни, безусловно, стоило бы спроектировать гибкий универсальный механизм расчета этих бонусов, но для упрощения примера ограничимся фиксированной реализацией. Код расчета мультипликаторов выглядит так:
private List<BigDecimal> calculateMultipliers(Customer customer, Product product) {
List<BigDecimal> multipliers = new ArrayList<>();
if (customer.getFavProduct() != null && customer.getFavProduct().equals(product)) {
if (customer.isPremium()) {
multipliers.add(PREMIUM_FAVORITE_MULTIPLIER);
} else {
multipliers.add(FAVORITE_MULTIPLIER);
}
} else if (customer.isPremium()) {
multipliers.add(PREMIUM_MULTIPLIER);
}
if (product.isAdvertised()) {
multipliers.add(ADVERTISED_MULTIPLIER);
}
if (product.getPrice().compareTo(EXPENSIVE_THRESHOLD) >= 0) {
multipliers.add(EXPENSIVE_MULTIPLIER);
}
return multipliers;
}Большое количество вариантов приводит к тому, что двумя-тремя интеграционными тестами здесь уже не ограничишься. Минималистичный набор юнит-тестов отлично подойдет для отладки такого функционала.
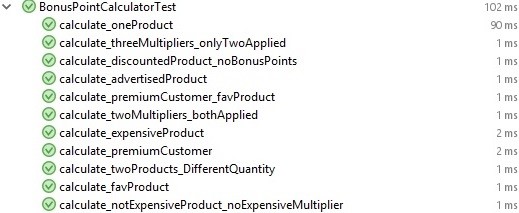
Соответствующий набор тестов можно посмотреть в классе
BonusPointCalculatorTest. Вот некоторые из них:@Test
public void calculate_oneProduct() {
Product product = product("product").price("1.00").build();
Customer customer = customer("customer").build();
Map<Product, Long> quantities = mapOf(product, 1L);
BigDecimal bonus = bonusPointCalculator.calculate(customer, list(product), quantities::get);
BigDecimal expectedBonus = bonusPoints("0.10").build();
assertEquals(expectedBonus, bonus);
}
@Test
public void calculate_favProduct() {
Product product = product("product").price("1.00").build();
Customer customer = customer("customer").favProduct(product).build();
Map<Product, Long> quantities = mapOf(product, 1L);
BigDecimal bonus = bonusPointCalculator.calculate(customer, list(product), quantities::get);
BigDecimal expectedBonus = bonusPoints("0.10").addMultiplier(FAVORITE_MULTIPLIER).build();
assertEquals(expectedBonus, bonus);
}Стоит обратить внимание, что в тестах идет обращение именно к публичному API класса — методу
calculate. Тестирование контракта класса, а не его реализации позволяет избегать поломок тестов из-за нефункциональных изменений и рефакторинга.Наконец, когда мы проверили внутреннюю логику юнит-тестами, в интеграционный все эти детали выносить уже не нужно. В данном случае достаточно одного более-менее репрезентативного теста, например такого:
@Test
public void calculateBonusPoints_twoProductTypes_correctValueCalculated() {
Product product1 = product("product1").price("1.01").build();
Product product2 = product("product2").price("10.00").build();
productRepository.save(product1);
productRepository.save(product2);
Customer customer = customer("customer").build();
customerRepository.save(customer);
Map<Long, Long> quantities = mapOf(product1.getId(), 1L, product2.getId(), 2L);
BigDecimal bonus = customerController.calculateBonusPoints(
new CalculateBonusPointsRequest("customer", quantities)
);
BigDecimal bonusPointsProduct1 = bonusPoints("0.10").build();
BigDecimal bonusPointsProduct2 = bonusPoints("1.00").quantity(2).build();
BigDecimal expectedBonus = bonusPointsProduct1.add(bonusPointsProduct2);
assertEquals(expectedBonus, bonus);
}Как и в случае с интеграционными тестами, использованный набор юнит-тестов очень небольшой и не гарантирует полной корректности приложения. Тем не менее его наличие значительно повышает уверенность в коде, облегчает отладку и дает прочие бонусы, перечисленные в первой части статьи.
Рекомендации по внедрению
Надеюсь, предыдущих разделов было достаточно, чтобы убедить хотя бы одного разработчика попробовать начать использовать тесты в своем проекте. В этой главе будут кратко перечислены основные рекомендации, которые помогут избежать серьезных проблем и приведут к снижению первичных издержек на внедрение.
Постарайтесь начать внедрение тестов на новом приложении. Написать первые тесты в большом legacy-проекте будет намного сложнее и потребует большей квалификации, чем в свежесозданном. Поэтому по возможности лучше начинать с небольшого нового приложения. Если же новых полноценных приложений не ожидается, можно попробовать разработать какую-нибудь полезную утилиту для внутреннего использования. Главное, чтобы задача была более-менее реалистичной — выдуманные примеры не дадут полноценного опыта.
Настройте регулярный запуск тестов. Если тесты не запускаются на регулярной основе, то они не только перестают выполнять свою основную функцию — проверку корректности кода, — но и быстро устаревают. Потому крайне важно настроить хотя бы минимальный CI-конвейер с автоматическим запуском тестов при каждом обновлении кода в репозитории.
Не гонитесь за покрытием. Как и в случае любой другой технологии, первое время тесты будут получаться не самого хорошего качества. Здесь может помочь соответствующая литература (ссылки в конце статьи) или грамотный ментор, но необходимости самостоятельного набивания шишек это не отменяет. Тесты в этом плане похожи на остальной код: понять, как они повлияют на проект, получится только пожив с ними некоторое время. Поэтому для минимизации ущерба первое время лучше не гнаться за количеством и красивыми цифрами вроде стопроцентного покрытия. Вместо этого стоит ограничиться основными позитивными сценариями по собственному функционалу приложения.
Не увлекайтесь юнит-тестами. В продолжение темы «количество vs качество» нужно отметить, что честными юнит-тестами первое время увлекаться не стоит, потому что это легко может привести к чрезмерной спецификации приложения. В свою очередь это станет серьезным тормозящим фактором при последующем рефакторинге и доработках приложения. Юнит-тесты следует использовать только при наличии сложной логики в конкретном классе или группе классов, которую неудобно проверять на уровне интеграционных.
Не увлекайтесь заглушками классов и методов приложения. Заглушки (stub, mock) — еще один инструмент, который требует взвешенного подхода и соблюдения баланса. С одной стороны, полная изоляция юнита позволяет сосредоточиться на тестируемой логике и не думать об остальных частях системы. С другой стороны, это потребует дополнительного времени на разработку и, как и при использовании юнит-тестов, может привести к чрезмерной спецификации поведения.
Отвяжите интеграционные тесты от внешних систем. Очень частая ошибка в интеграционных тестах — использование реальной базы данных, очередей сообщений и прочих внешних по отношению к приложению систем. Безусловно, возможность запустить тест в реальном окружении полезна для отладки и разработки. Такие тесты в небольших количествах могут иметь смысл, особенно для запуска в интерактивном режиме. Однако повсеместное их использование приводит к целому ряду проблем:
- Для запусков тестов нужно будет настраивать внешнее окружение. Например, устанавливать базу данных на каждую машину, где будет собираться приложение. Это усложнит вход новых разработчиков в проект и настройку CI.
- Состояние внешних систем может отличаться на разных машинах перед запуском тестов. Например, в базе могут уже находиться нужные приложению таблицы с данными, которые не ожидаются в тесте. Это приведет к непредсказуемым сбоям в работе тестов, и их устранение потребует значительного количества времени.
- В случае, если ведется параллельная работа над несколькими проектами, возможно неочевидное влияние одних проектов на другие. Например, специфические настройки базы, выполненные для одного из проектов, смогут помочь корректно работать функционалу другого проекта, который, однако, сломается при запуске на чистой базе на другой машине.
- Тесты выполняются долго: полный прогон может достигать десятков минут. Это приводит к тому, что разработчики перестают запускать тесты локально и смотрят на их результаты только после отправки изменений в удаленный репозиторий. Такое поведение сводит на нет большинство плюсов тестов, о которых говорилось в первой части статьи.
Очищайте контекст между интеграционными тестами. Часто для ускорения работы интеграционных тестов приходится переиспользовать между ними один и тот же контекст. Такую рекомендацию дает даже официальная документация Spring. При этом нужно избегать влияния тестов друг на друга. Так как запускаются они в произвольном порядке, то наличие таких связей может привести к случайным невоспроизводимым ошибкам. Чтобы этого не произошло, тесты не должны оставлять после себя никаких изменений в контексте. Например при использовании базы данных, для изоляции обычно бывает достаточно откатывать все совершенные в тесте транзакции. В случае, если изменений в контексте избежать не удается, можно настроить его пересоздание с помощью аннотации
@DirtiesContext.Чтобы этого не произошло, тесты не должны оставлять после себя никаких изменений в контексте. Например, при использовании базы данных обычно бывает достаточно просто откатывать все совершенные в тесте транзакции.
Следите за тем, чтобы тесты выполнялись за разумное время. Даже если тесты не зависят от реальных внешних систем, время их выполнения может легко выйти из-под контроля. Чтобы такого не происходило, нужно постоянно следить за этим показателем и принимать меры в случае необходимости. Самое меньшее, что можно сделать, — выделить медленные тесты в отдельную группу, чтобы они не мешали работе над не связанными с ними задачами.
Старайтесь делать тесты максимально понятными и читаемыми. Как уже было показано в примере, тесты надо писать так, чтобы в них не нужно было разбираться. Время, потраченное на изучение теста, могло бы быть потрачено на изучение кода.
Не зацикливайтесь на TDD (Test-Driven Development). TDD является довольно популярной практикой, однако я не считаю ее обязательной, особенно на первых этапах внедрения. В целом, умение писать хорошие тесты не связано с тем, в какой момент они написаны. Что действительно важно, так это делать первичную отладку кода уже на тестах, поскольку это один из основных способов экономии времени.
Первые тесты написаны, что дальше?
Далее надо внимательно наблюдать за жизнью тестов в проекте и периодически задавать себе вопросы, подобные следующим:
- Какие тесты мешают рефакторингу и доработкам (требуют постоянных исправлений)? Такие тесты требуется переписать либо полностью удалить из проекта и заменить более высокоуровневыми.
- Какие тесты часто и непредсказуемо ломаются при многократном либо параллельном запуске, при запуске в разных средах (компьютер коллеги, сервер CI)? Они также требуют переработки.
- Какие ошибки проходят мимо тестов? На каждый такой баг желательно добавлять новый тест и в будущем иметь их в виду при написании тестов для аналогичного функционала.
- Какие тесты работают слишком долго? Нужно постараться их переписать. Если это невозможно, то отделить их от более быстрых, чтобы сохранить возможность оперативного локального прогона.
Дополнительно стоит обратить внимание на те преимущества тестов, которые были описаны в начале статьи. Если вы их не получаете, значит, что-то пошло не так. Регулярная ретроспектива — наиболее дешевый путь к стабильному росту качества и эффективности используемых тестов.
Заключение
Поначалу лучше не гнаться за количеством тестов, а сосредоточиться на их качестве. Огромное число неуместных юнит-тестов может легко стать якорем, тянущим проект на дно. Кроме того, наличие юнит-тестов не освобождает от необходимости написания интеграционных. Поэтому наиболее эффективная стратегия на первое время — начинать с покрытия основных позитивных сценариев интеграционными тестами и, в случае если этого оказывается недостаточно, добавлять локальные проверки юнит-тестами. Со временем будет накапливаться обратная связь, которая поможет исправить допущенные ошибки и получить более четкое представление об эффективном использовании разных методик автоматического тестирования.
Надеюсь, среди прочитавших найдутся те, чьи тонкие струны души окажутся задеты моим графоманством, и в мире появится еще несколько проектов с хорошими и эффективными тестами!
Исходники проекта на GitHub
The Art of Unit Testing, Roy Osherove
Test-driven Development: By Example, Kent Beck
Refactoring: Improving the Design of Existing Code, Martin Fowler
Комментарии (35)


dbelob
31.10.2018 13:06Спасибо за интересную статью с хорошим дополнением проектом! Какое покрытие (процентное) тестами (юнит- и интеграционными) получается на практике в текущих проектах?
Teemitze
31.10.2018 13:38+1Спасибо за такую прекрасную статью, начал использовать тесты недавно. Действительно это экономит кучу времени, да и ошибки, которые ранее не замечал, начали проявляться в тестах.
feoktant
31.10.2018 13:38+2интеграционным (их еще иногда называют приемочными — acceptance)
Мне кажется, здесь неточность.
Интеграционный тест не обязательно является приемочным. Это не синоним. На примере веб сервиса, интеграционный тест — это тест между компонентами. Например, контроллером и сервисом, сервисом и репозиторем, репозиторием и реальной БД. Или любая комбинация этих компонентов. Приемочным тест будет, если все эти компоненты используются тестом вместе: поднята реальная база данных, и делается реальный HTTP запрос на контроллер.
Что скажете?achuzhmarov Автор
31.10.2018 14:57+1К сожалению, с терминологией в части тестирования до сих пор большая путаница. Практически в каждой новой команде приходится находить общий язык с нуля. Лично я выделяю интеграционные тесты как противоположность юнит-тестам. Т.е. если используется хотя бы одна внешняя система (в том числе, in-memory database), то я называю такой тест интеграционным. В таком контексте приемочные тесты являются некоторой разновидностью интеграционных, которую бывает удобно выделить в рамках конкретного проекта, чтобы не путаться. Например, в моем текущем проекте есть два уровня интеграционных тестов — на одном проверяются внутренние сервисы, а на другом уже дергаются методы api. Соответственно, те которые дергают сервисы мы просто называем интеграционными, а более высокоуровневые — приемочными. Хотя в этом случае оба слоя тестов работают с in-memory базой.
feoktant
31.10.2018 13:40+1Что вы скажете о нескольких ассертах в одном тесте?
assertEquals("updatedName", dbProduct.getName()); assertEquals(number("1.1"), dbProduct.getPrice()); assertEquals(number("0.5"), dbProduct.getDiscount()); assertEquals(true, dbProduct.isAdvertised());
СтОит ли избавляться от такого кода, переписывать на кастомные Matchers, или указывать причину падающего ассерта?achuzhmarov Автор
31.10.2018 15:26+2Этот вопрос — один из типичных холиваров в тестировании. Как видно из моего кода, я не считаю наличие нескольких ассертов абсолютным злом. Пока весь тест целиком помещается на экран, легко читается, а ассерты по сути проверяют одно предположение — это допустимо. Часто наличие нескольких ассертов сигнализирует о том, что тест проверяет больше одного предположения. В таком случае упрятывание их в один кастомный Matcher только скрывает проблему, не решая ее. Что касается указанного фрагмента кода, по идее тут сможет помочь новый Junit с assertAll, но мне пока не довелось обкатать этот вариант в боевых условиях.
lxsmkv
31.10.2018 22:31+1Проблема нескольких ассертов в том, что упадет первый и по остальным не будет информации. Если вас устраивает это — то в этом нет ничего осудительного. Это ваше осознанное решение. Допускать вероятность перекрывания одной ошибкой другой или нет.
Решение вы наверняка знаете — это «мягкие» ассерты.achuzhmarov Автор
01.11.2018 08:08Решение вы наверняка знаете — это «мягкие» ассерты.
Насколько я знаю, вменяемая реализация таких ассертов из коробки появилась только в JUnit 5 (assertAll), который все еще довольно редко встречается в реальных проектах. А время на переход на новые технологии, к сожалению, можно выделить далеко не всегда. В JUnit 4 нужно подключать дополнительную библиотеку, явно создавать дополнительный объект и опять же, явно вызывать на нем проверку после ассертов. Что на мой взгляд не очень удобно.
UnknownUser
31.10.2018 14:10Спасибо за статью!
Действительно, даются ответы на вопросы, которые мучают меня каждый раз когда пытаюсь начать писать тесты для своих проектов.
Ещё бы где нибудь научится — как объяснить своим коллегам, начальству, заказчикам и начальству заказчиков, что тесты — очень хорошая идея, их надо писать, на них стоит выделять время разработчиков.

Perlovich
31.10.2018 14:58+1Очень частая ошибка в интеграционных тестах — использование реальной базы данных
Ну почему сразу ошибка-то. Если пишешь какой-нибудь REST API, то очень удобно при тестировании этого реста сверятся с БД: смотреть, что были применены именно нужные изменения.
Для запусков тестов нужно будет настраивать внешнее окружение.
Во многих проектах каждому разработчику итак надо поднять свою БД. Благо, в проектах есть init и update SQL скрипты, которые сами все настроят.
Состояние внешних систем может отличаться на разных машинах перед запуском тестов.
Тесты могут очищать БД и накатывать нужные данные. В моем опыте здесь нет особых проблем с поддержкой.
Да, я согласен, что интеграционным тестам лучше не стучаться по HTTP к каким-нибудь 3d parties. Но имхо использование настоящей БД при тестировании — это удобно и естественно.achuzhmarov Автор
31.10.2018 16:09+1Возможно, я немного погорячился с формулировкой и бывают ситуации, когда плюсы использования реальной базы перевешивают минусы. Лично я считаю крайне важным возможность выкачать код любого проекта из репозитория и сразу же запустить его тесты из коробки без каких-либо дополнительных телодвижений. В том числе это значительно облегчает погружение и внесение доработок в незнакомые проекты. При повседневной работе над своим текущим проектом я вообще не использую реальной базы: все проверяется на h2.
Вдобавок, в тех проектах, что я встречал, использование реальной базы часто провоцирует людей на создание дополнительных условий для запуска теста (например, тест может рассчитывать, что в базе уже лежат какие-то тестовые данные). В случае когда база виртуальная, создать себе похожие проблемы значительно сложнее.
В целом, ниже уже написали про альтернативы в виде виртуализации внешних систем. При грамотном подходе, такой вариант, безусловно, имеет право быть.gubber
01.11.2018 13:23При повседневной работе над своим текущим проектом я вообще не использую реальной базы: все проверяется на h2
Не помню, какое время назад, примерно год-полтора назад. Была статья на эту тему.
Смысл её был в том, что на проде нашли странную ошибку, которая на тестах не вылезала. Т.е. код отрабатывал одинаково, но вот результаты работы были разными. Оказалось, что ошибка закралась в разном алгоритме работы H2 и Postgres.
В итоге все тесты переписали на Postgres и нашли ещё несколько неочевидных ошибок.
В общем, использования H2 нормально, но может приводить к скрытым ошибкам.
В наших проектах мы используем несколько подходов.
1. Embended Postgres. Разработчику не надо заморачиваться с поднятием БД.
2. Предварительный запуск БД в контейнере. Данный вариант позволяет собрать некоторую «эталонную» версию БД, чтобы не тратить время на создание структуры и прогон всех UPDATE скриптов.
Плюс мы приняли решение, что один тест должен уметь запускаться на одном контексте два раза. Т.е. мы знаем правила нашей системы и делаем формируем объекты с учётом этих правил. На пример, у нас есть «идентифицирующие» поля, это далеко не всегда ID. И такие поля у нас генерируются с учётом timestamp, что позволяет нам не беспокоиться об очистке контекста и отката транзакций.achuzhmarov Автор
01.11.2018 15:311. Embended Postgres. Разработчику не надо заморачиваться с поднятием БД.
2. Предварительный запуск БД в контейнере. Данный вариант позволяет собрать некоторую «эталонную» версию БД, чтобы не тратить время на создание структуры и прогон всех UPDATE скриптов.
А вы случайно не сравнивали скорость работы тестов в таких сценариях против использования H2? Интересно, проседает ли она и насколько. Я пробовал использовать Embedded Postgres в тестах, но он значительно медленнее стартует — это сильно мешает при повседневной разработке когда постоянно гоняешь тесты из IDE. В результате в моем текущем проекте есть возможность легко подменить H2 на EmbeddedPostgres в тесте как раз на случай расследования специфичных для него проблем, но сами тесты по умолчанию работают на H2.
Nichola
31.10.2018 15:25+1Спасибо за хорошую структурированную статью.
Со своей стороны замечу что отвязка от внешних систем рекомендуемая у вас имеет альтернативы в виде виртуализации внешних систем, контейнеризации и их комбинаций, ещё есть вариант подмены тестовыми аналогами, в спринге это кажется будут тестовые аспекты которые вы используете в тестовом контексте чтоб например работать с h2db вместо sql server.
dehasi
31.10.2018 16:46+1Зачем вы тестируете
Product createdProduct = productController.createProduct(product);
Не лучше ли взять для тестиования котроллеров Spring mockMVC?achuzhmarov Автор
31.10.2018 17:30+1Я упоминал его в качестве альтернативного подхода. Это вопрос выбора архитектуры ваших тестов. Лично мне удобнее тестировать методы контроллеров напрямую. В частности, это нагляднее, легче переходить внутрь тестируемого класса, проще работать с отладчиком. MockMVC я использую только если мне нужно проверить что-то специфичное, например, механизм секьюрити или ошибки сериализации объектов. Каких-то значимых проблем с игнорированием этого слоя обычно не возникает. Если же в вашем случае ситуация отличается, то конечно же стоит рассмотреть альтернативные моему подходу варианты.
В моем текущем проекте, например, значительная часть слоя контроллеров (все что касается url, method, параметров запроса) вообще автоматически генерируется по swagger-спецификации и особого смысла проверять это тестами нет.
poxvuibr
31.10.2018 19:26+1А что вы скажете по поводу подготовки данных для теста? Ну, то есть, как приводить базу данных в исходное состояние?
igor_suhorukov
31.10.2018 22:41+1Как один из вариантов dbunit или обёртка для него Spring Test dbunit
poxvuibr
01.11.2018 11:15В посте ничего про dbunit нет, поэтому я и поинтересовался. Но вообще dbunit такая проблема, что очень муторно писать тесты с ним. Колонки все эти руками заполнять и зачастую не в одной таблице. Тяжело.
achuzhmarov Автор
01.11.2018 12:20По умолчанию я стараюсь делать так, чтобы каждый тест стартовал с пустой базой и сам помещал в нее все что нужно. Первая часть теста — это подготовка данных с помощью билдеров и сохранение их в базу при необходимости. При таком подходе откат транзакции теста автоматически вернет ее в исходное состояние.
Если такой подход начинает приводить к серьезным проблемам производительности, то тут уже приходится думать над частными решениями в каждом конкретном случае.poxvuibr
01.11.2018 12:57Первая часть теста — это подготовка данных с помощью билдеров и сохранение их в базу при необходимости.
Это в методе setUp? Билдеры занимаются созданием данных специально для добавления в базу? Методы сохранения данных, полученных с помощью билдеров, написаны специально для тестов и работают только в них?
achuzhmarov Автор
01.11.2018 13:33Прямо в теле теста. Билдеры просто умеют создавать объекты. Их можно как передавать в качестве параметров, так и сохранять в базу. Для сохранения в базу использую дефолтную реализацию репозиториев через SpringData. Плюс в том, что никакого кода кроме объявления интерфейса в таком случае писать не нужно и можно полагаться на то, что этот функционал рабочий. Эти же репозитории используются и в продакшн-коде.
Подробности по коду и реализации можете посмотреть в моем проекте на гитхабе. В одном из примеров упомянутых в статье подготовка данных в начале теста выглядит так:
Product product = product(«productName»).build();
productRepository.save(product);poxvuibr
01.11.2018 13:52То есть получается, что у вас билдеры просто заменители sql. Сталкивались с проблемами при изменении схемы данных? Как их решили?
achuzhmarov Автор
01.11.2018 15:10Хм, я правильно понял, что вы не используете ORM (Object-relational mapping) в своих задачах? Потому что в противном случае изменения схемы базы данных отразятся на изменении модели данных в проекте безотносительно тестов и описанной вами проблемы не возникнет. Если это так, то просто взять мой подход и применить не получится, придется подумать как лучше реализовать эти идеи в условиях вашего стека технологий.
3dcryx
01.11.2018 08:59Интересно былобы прочитать как предлогается писать тесты для:
1) Графических интерфейсов (убедится, что кнопка Х делает именно то что на ней написано)
2) Производительности (грубо говоря убедится что новая версия функции работает на 20% быстрее старой)
3) Чтук вроде распознования объектов (результатом являются координаты прямоугольника внутри которого искомый объект)
4) Любых real-time игр
5) Драйверов
6) Кода управляющего MRI сканером (не принципиально чем, суть в том что это какойнибудь большой сложный и важный внешний прибор)gubber
01.11.2018 13:30Это другого уровня тесты.
1. В современных движках разработки UI есть свои тесты, включая проверку работы компонентов. Это отдельная тема.
2. Тесты на производительность не запускаются один раз. Т.к. производительность, это не одна операция в единицу секунды. А 10^x операций в течении определённого периода времени.
gubber
01.11.2018 13:26Test
public void getProduct_twoProductsInDb_correctProductReturned() {
Product product1 = product(«product1»).build();
Product product2 = product(«product2»).build();
productRepository.save(product1);
productRepository.save(product2);
Product result = productController.getProduct(product1.getId());
assertEquals(«product1», result.getName());
}
Очень стрёмный тест, если честно. Если предположить, что в БД есть ограничение на длину строки = 3 символам, то тест может отрабатывать корректно, за счёт кэширования данных на уровне ORM, а вот в реальности результат работы может быть другой.achuzhmarov Автор
01.11.2018 13:53Все зависит от того, что конкретно вы хотите проверять. В некотором роде это решение — часть архитектуры ваших тестов. В общем случае, чем больше слоев проверяется, тем сложнее становится написание и сопровождение тестов.
Приведенные мной тесты сосредоточены вокруг логики работы самого приложения. Я считаю, что это хорошая стартовая точка, особенно при первичном внедрении тестирования. В случае если в вашей конкретной ситуации таких проверок оказывается недостаточно (например, возникают регулярные проблемы с БД), то безусловно стоит рассмотреть другие подходы.
Barrya42
Давно хочу хочу опробовать тесты, сейчас как раз есть несколько небольших приложений. Но что то все ни как не могу себя заствить. А приложения растут…
dipsy
Я, как человек ленивый, понял, что тесты позволяют сэкономить много времени, возможно вам просто нравится работать.
Barrya42
Отнюдь, я отлично осознаю практическую пользу тестов. Так же осознаю что для получения этой пользы нужно потратить время на изучение и внедрение этой технологии, а так же то что это нужно делать в ближайшее время.
warranty_voider
Начните с тестов для сложной логики, которую неудобно тестировать руками. Как в примере с вычислением бонусов в статье. Это должен быть новый компонент, на существующую кодовую базу тесты писать может быть неудобно. Т.е. ситуация в целом такая:
Решиться на написание теста для одного нового компонента значительно проще, чем на 100% покрытие всего приложения. И даже если на этом компоненте все и остановится, у вас будут хоть какие-то тесты. Когда (не если) компонент сломается, а тесты помогут быстрее решить проблему, задумайтесь еще раз. Удачи!
Arranticus
Тут как обычно, начать не сложно, сложно заниматься этим регулярно.