

Привет хабр!
Появилось таки некоторое количество времени, и я решил написать сий пост, идея которого возникла уже давно.
Связан он будет будет с такой, казалось бы, простой вещью, как URI, детальному рассмотрению которой в рунете уделяется как-то мало внимания.
"Пфф, ссылки они и в Африке ссылки, чего тут разбираться?" — скажете вы, тогда я задам вопрос:
Что есть что и куда нас приведет?
http://example.comwww.example.com//www.example.commailto:user@example.com
Если вы не знаете однозначного ответа или вам просто интересно
Перед тем как начать хотел бы обозначить, что есть пост на схожую тему, в котором все обозначено проще и немного понятнее. Целью же этого поста, я ставлю более глубокое изучение вопроса и сбор информации об URI в одном месте, дабы «не потерять». Ну, почти в одном месте, статья будет разделена на две части
А для удобства бахнем оглавление, которое работает не без особенностей URI, которую мы рассмотрим попозжа, в этой статье.
ОГЛАВЛЕНИЕ
Ознакомление
1. URI
Унифицированный Идентификатор Ресурса, в простонародье — URI
Самое свежее описание того, чем же все-таки являются эти пресловутые URI датируется январем аж 2005-го, а именно RFC3986, написанный самим Тимом Бёнесом-Ли, родоначальника всеми нами любимого тырнета.
Резюмируя п.1.1 можно сформулировать определение:
URI — последовательность символов, идентифицирующая физический или абстрактный ресурс, который не обязательно должен быть доступен через сеть Интернет, причем, тип ресурса, к которому будет получен доступ, определяется контекстом и/или механизмом.
Например:
- перейдя по
http://example.com— мы попадем на http-сервер ресурса идентифицируемого какexample.com - в то же время
ftp://example.com— приведет наc на ftp-сервер того же самого ресурса - или например
http://localhost/— URI идентифицирующий саму машину откуда производится доступ
В современном интернете, чаще всего используется две разновидности
URI — URL и URN.Основное различие между ними — в задачах:
- URL — Uniform Resource Locator, помогает найти какой либо ресурс
- URN — Uniform Resource Name, помогает этот ресурс идентифицировать
Упрощая:
URL — отвечает на вопрос: «Где и как найти что-то?», URN — отвечает на вопрос: «Как это что-то идентифицировать».Дело в том, что URL увидел свет и был документирован в 1990 году, в то время как URI был документирован лишь в 1994 году. И вплоть до 2002 года, до выхода RFC3305, уместными были оба варианта именования, что, порой вносило путаницу.
В п.2 RFC3305 сообщается об устаревании такого термина как URL, применимо к ссылкам, и что отныне верным будет именование URI, с того момента, во всех документах W3C использует термин URI. Исходя из этого, применяя термин URL к соответствующим ссылкам, вы не делаете смысловой ошибки, но делаете ее с точки зрения правильного именования.
Так же примечателен тот момент, что вплоть до выхода RFC2396, в 1997 году, URI расшифровывался как Universal Resource Identifier, что можно увидеть в RFC1630
Обобщая всевозможные варианты, URI имеет следующий вид:

Забегая вперед, стоит отметить, что не все три компоненты являются строго обязательными. Для того чтобы ссылка считалась URI необходимо наличие:
- либо
scheme+authority+path, - либо
sheme+path, - либо только
path.
1.1. Синтаксис
Согласно п.2 RFC3986:
URI составлен из ограниченного набора символов, состоящих из цифр, букв и нескольких графических символов, все эти символы вписываются в кодировку US-ASCII (ASCII). Зарезервированное подмножество символов может использоваться, чтобы разграничить компоненты синтаксиса в URI, в то время как остающиеся символы: не зарезервированный набор и включая те зарезервированные символы, которые не действуют как разделители в данной компоненте URI, определяют данные идентификации каждого компонента.
Зарезервированные символы
Зарезервированные символы делятся на два типа:- gen-delims, они же «главные разделители», т.е. символы, разделяющие URI на крупные компоненты.
":", "/", "?", "#", "[", "]", "@" - sub-delims, они же «под разделители» — символы, которые разделяют текущую крупную компоненту, на более мелкие составляющие, для каждой компоненты они свои, вот список самых распространенных:
"!", "$", "&", "'", "(", ")", "*", "+", ",", ";", "="
Не зарезервированные символы
Исходя из предыдущего пункта, не зарезервированные символы — символы, не входящие вgen-delims, а так же не значимые для данной компоненты sub-delims. Но в общем случае это:ALPHA, DIGIT, "-", ".", "_", "~"
Для данного случая, согласно ABNF:
ALPHA— любая буква верхнего и нижнего регистров кодировки ASCII (в regExp [A-Za-z])
DIGIT— любая цифра (в regExp [0-9])
HEXDIG— шестнадцатиричная цифра (в regExp [0-9A-F])
Процентное кодирование
В случае, если используются символы выходящие за пределы кодировки ASCII используется механизм т.н. "Процентного кодирования". Так же он применяется для передачи зарезервированных символов в составе данных. Зарезервированные символы, по правилам, не участвуют в процентном кодировании.Процентно-кодированный символ представляет из себя символьный триплет, состоящий из знака "%" и следующих за ним двух шестнадцатиричных чисел:
pct-encoded = "%" HEXDIG HEXDIG1.2. Компоненты URI
Следующий список содержит описания крупных компонент, составляющих URI:
- Scheme (схема)
Каждый URI начинается с имени схемы, которое относится к спецификации для присвоения идентификаторов в этой схеме. Также, синтаксис URI — объединенная и расширяемая система именования, причем, спецификация каждой схемы может далее ограничить синтаксис и семантику идентификаторов, использующих эту схему.
Название схемы обязательно начинается с буквы и далее может быть продолжено любым количеством разрешенных символов.
Разрешенные символы для схемы:
ALPHA, DIGIT, "+", "-", "." - Authority (честно говоря, не знаю как перевести слово на русский, без потери смысла)
Компонента authority начинается с двойного слеша(//) и заканчивается следующим слешем(/), знаком вопроса(?) или октоторпом(#)(да-да, «решеточка» зовется именно так=)) или концом URI
Authority состоит из:
Каждую из подкомпонент, отдельно, мы рассмотрим чуть позже, в разделе посвященном URL.[ userinfo "@" ] host [ ":" port ]
где в квадратных скобках опциональные компоненты
- Path (Путь)
Компонента пути содержит данные, обычно, организованные в иерархической форме, которые, вместе с данными в неиерархическом компоненте запроса (Query), служит, чтобы идентифицировать ресурс в рамках схемы URI и authority (если таковая компонента указана).
Путь начинается со слеша(/) и заканчивается знаком вопроса(?), октоторпом(#) или концом URI
Разрешенные символы для пути:
Не зарезервированные, процентно-кодированные, sub-delims, ":", "@" - Query (Запрос)
Компонента запроса содержит данные, организованные в неиерархической форме, которые, вместе с данными в иерархическом компоненте пути (Path), служит, чтобы идентифицировать ресурс в рамках схемы URI и authority (если таковая компонента указана).
Запрос начинается с первого знака вопроса(?) и заканчивается октоторпом(#) или концом URI
Разрешенные символы для запроса:
В запросе чаще всего передаются данные в формате key=value (ключ=значение), значение рекомендуется передавать в процентно-кодированном виде, обусловлено это тем, что в значении может встретиться символ "&", который используется для разделения пар ключ-значение, в результате появления такого артефакта дальнейшая последовательность пар ключ-значение может быть нарушена.Не зарезервированные, процентно-кодированные, sub-delims, ":", "@", "/", "?" - Fragment (Фрагмент)
Компонента фрагмент позволяет осуществить косвенную идентификацию вторичного ресурса по отношению к первому.
Семантика фрагмента никак не ограничена, фрагмент начинается октоторпом(#) и заканчивается концом URI, при этом может состоять из абсолютно любого набора символов.
Примером применения фрагментов является оглавление данной статьи. Оно состоит из относительных ссылок
<a href="#someanchor"></a>, а по статье, в определенных местах, раскиданы т.н. «якоря» — теги<anchor>someanchor</anchor>.
Переходя по указанной в оглавлении ссылке, браузер производит переход ко вторичному ресурсу относительно данной страницы, т.е. скроллит вниз, до появления нужного<anchor>на экране.
2. URL
Стандарт URL документирован в RFC1738.
Из п.2:
URL используются, чтобы определить местоположение ресурсов, обеспечивая абстрактную идентификацию расположения ресурса. Определив местоположение ресурса, система может выполнить множество операций на ресурсе, которые могут быть характеризованы такими словами как 'доступ', 'обновление', 'замена', 'поиск атрибутов'. В целом только метод доступа должен быть определен для любой схемы URL.Т. о.: URL призван решить широкий ряд задач, начиная с получения и заканчивая изменением данных на ресурсе, а обязательным параметром для получения доступа — является метод, т. е. любой полноценный (абсолютный) URL можно свести к виду:
<scheme>:<часть свойственная этой схеме>2.1. Структура
В целом, URL имеет схожую структуру, для всех схем, хотя для каждой отдельно взятой схемы, структура может отличаться от общего шаблона.
Графически ее можно выразить в следующем виде:
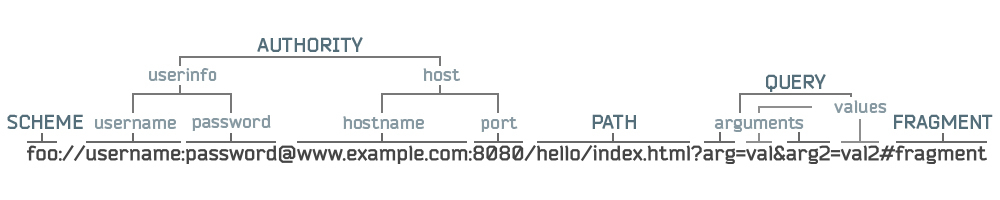
И вот, примерно на этом моменте, можно рассмотреть различия между абсолютными (absolute) и относительными (relative) URL, данные определения распространяются не только на URL, но и на URI в целом.
- Относительная ссылка использует иерархический синтаксис, чтобы выразить ссылку URI относительно пространства имен другого иерархического URI.
Относительные ссылки так же делятся на несколько подвидов:
- Ссылка сетевого пути
Имеет вид:
Такой тип ссылок применяется не часто, смысл заключается в переходе по указанной ссылке с применением текущей схемы.//<authority> <path> [<query>] [<fragment>]
Т. е.: находясь, например наhttp://example.comи перейдя по ссылке//domain.com— мы попадем наhttp://domain.com
А в случае если перейдем по той же ссылке сftp://example.com, то попадем наftp://domain.com - Ссылка абсолютного пути
Имеет вид:
На этот раз мы останемся в пределах текущего хоста, но попадем по пути path в любом случае, по какому бы пути мы сейчас не находились./<path> [<query>] [<fragment>]
Т. е.: даже находясь наhttp://example.com/just/some/long/pathи перейдя по ссылке/path, мы попадем наhttp://example.com/path - Ссылка относительного пути
Имеет вид:
Теперь же, мы будем перемещаться в пределах текущего положения.<path> [<query>] [<fragment>]
Т. е.: находясь наhttp://example.com/just/some/long/pathи перейдя по ссылкеpath, мы попадем наhttp://example.com/just/some/long/path/path - Ссылка того же документа
Фактически это ссылки, состоящие только из фрагментарной части URI, либо же ссылки, у которых все компоненты за исключением фрагментарной совпадают с исходной.
Т.е.#fragmentиhttp://habrahabr.ru/topic/232385/#fragmentявляются ссылками того же документа.
- Ссылка сетевого пути
- Абсолютная ссылка — ссылка вида
Применяя абсолютные ссылки, мы будем попадать на нужный нам ресурс вне зависимости от того, откуда мы переходим.<scheme> <authority> [<path>] [<query>] [<fragment>]
Т. е.: находись мы наhttp://example.com/just/some/long/pathили же наftp://example.com, перейдя поhttp://domain.com/path, мы в любом случае попадем наhttp://domain.com/path
После того, как мы разобрались с тем, что же такое относительные и абсолютные пути — можно отвечать на вопрос заданный в начале поста:
- http://example.com — откроет
http://example.com - www.example.com — по-идее должен открыть
http://habrahabr.ru/topic/232385/www.example.com, но хабр сам исправляет ссылку, хотя по стандартамwww.example.com— ссылка относительного пути - //www.example.com — откроет
www.example.comсо схемой с которой вы просматриваете текущую страницу, т.е. скорее всего будет открытhttp://example.com - mailto:user@example.com — здесь уже вступают в силу настройки браузера, он предложит вам открыть эту ссылку при помощи почтовой программы и отправить электронное письмо адресату
user@example.com, а так, это абсолютный URL со схемойmailto
Мы уже рассмотрели крупные компоненты, а теперь давайте углубимся в детали построения URL.
- Scheme — как говорилось ранее: схема определяет метод доступа к ресурсу. Список актуальных схем можно посмотреть тут.
- Userinfo — под-компонент authority, использующийся для авторизации пользователя на ресурсе. Состоит из username и необязательного password, от остальной части authority отделяется символом "
@". Не смотря на то, что параметр password указан в спецификации, его использование крайне не рекомендуется, т. к. фактически производится передача пароля к учетной записи username, в незашифрованном виде.
Разрешенные символы:Не зарезервированные, процентно-кодированные, sub-delims, ":"
Пример можно привести следующий:
На локалке есть папка test, на которую стоит доступ по паре логин-пароль. То есть, перейдя поhttp://localhost/test/, я увижу следующее: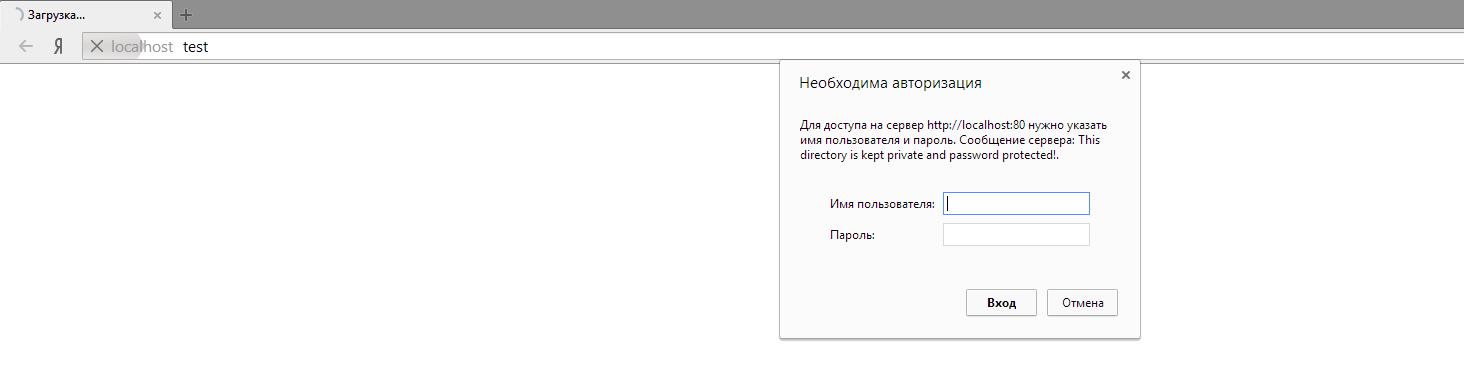
А если я перейду по ссылкеhttp://admin:admin@localhost/test/, то процедура авторизации произойдет автоматически, с данными указанными в блоке userinfo:
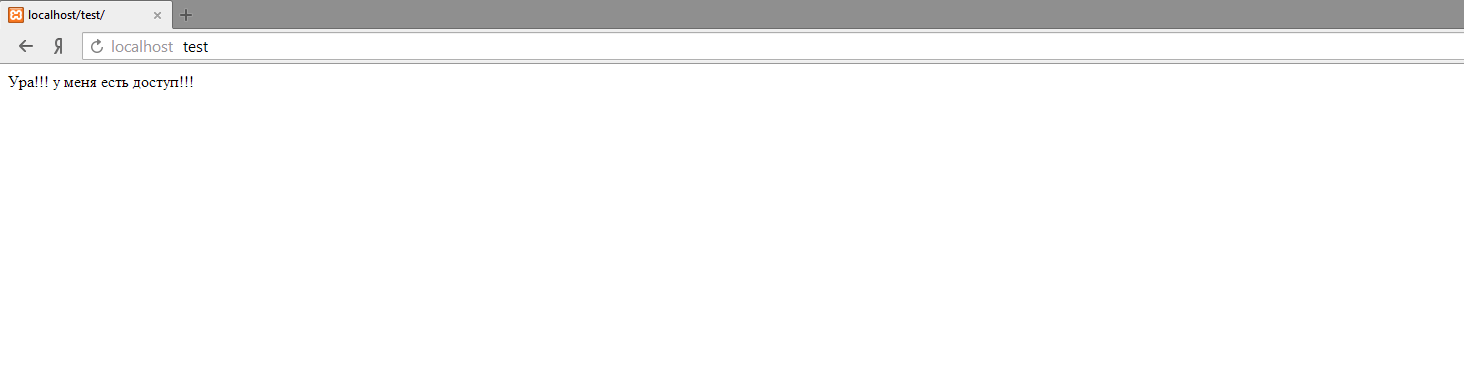
- Host — компонент authority, использующийся для определения целевого узла (или ресурса, если угодно, но понятие «узел» будет более точным), который может находиться как в сети интернет, так и вне её, в зависимости от указанной схемы. Данная компонента не чувствительна к регистру.
Хост может представлять из себя либо IP-адрес, либо регистрационное имя (reg-name) и, опционально, следующий за ними порт(port).
Предусматривается как поддержка существующих форматов IP-адресов (IPv4, IPv6), так и всевозможных будущих, которые будут описаны впоследствии.
Регистрационное имя — привычные нам, т. н. доменные имена — последовательность символов, обычно предназначенных для поиска в локально определенном узле или реестре имени службы, хотя специфичная для схемы семантика URI может потребовать, чтобы вместо этого использовался определенный реестр (или фиксированная таблица имен).
Наиболее распространенный механизм реестра имен — Система Доменных Имен (DNS).
Доменное имя, используемое для поиска в DNS, состоит из доменных меток, разделенных при помощи ".", каждая доменная метка может содержать следующие символы:
Синтаксис регистрационного имени позволяет использование процентно-кодированных символов, для представления не-ASCII символов, в едином порядке, не зависящем от технологии разрешения имен. Символы, не входящие в ASCII, должны быть сначала закодированы в UTF-8, а затем каждый октет UTF-8 последовательности должен быть процентно закодирован.Не зарезервированные, процентно-кодированные, sub-delims
В случае, если регистрационное имя с не-ASCII символами представляет собой многоязычное доменное имя, разрешаемое через DNS, оно должно быть преобразовано в кодировку IDNA (RFC3490) до поиска имени и, как следствие, регистраторами доменных имен такие регистрационные имена должны предоставляться в кодировке IDNA.
Port (Порт) — десятичный номер порта, отделяется от hostname одним двоеточием ":", может состоять только из цифр. Схема может определять порт по-умолчанию, который будет использоваться в случае если порт не указан. Например, для схемы HTTP порт по-умолчанию — 80, что соответствует зарезервированному под неё порту 80/TCP. Тип порта, так же как и назначенный номер порта, определяется схемой. - Компоненты Запрос и Фрагмент полностью описаны ранее.


3. URN
Стандарт URN документирован в RFC2141.
Из п.1:
Унифицированные имена ресурсов (URN) предназначены, чтобы служить постоянными, независимыми от расположения, идентификаторами ресурсов и разработаны для упрощения отображения других пространств имен (которые совместно используют свойства URN) в URN-пространство. Таким образом, синтаксис URN обеспечивает средство закодировать символьные данные в форме, которая может быть отправлена посредством существующих протоколов, записана при помощи большинства клавиатур, и т.д.Т. е., в отличие от URL, который ссылается на како-то место, где хранится документ, URN ссылается на сам документ, и при перемещении документа в другое место ссылка не изменится.
В силу того, что URN концептуально отличается от URL, то и система разрешения имен у него другая — DDDS, которая преобразует URN в URL, по которым можно найти ресурс/объект или что бы то ни было, на что ссылается URN.
3.1. Структура
URN имеет следующий вид:
"urn:" <NID> ":" <NSS>- «urn:» — обязательная, регистронезависимая часть URN
- NID — Namespace Identifier, данная компонента определяет синтаксическую интерпретацию компоненты NSS.
Минимальная длина — 2 символа, максимальная — 32, разрешенные символы:
NID должен начинаться только с буквы или цифры.латинские буквы, цифры, "-"
Так же, слово «urn» для NID является зарезервированным, дабы избежать неоднозначности при определении URN в целом.
Список официально зарегистрированных NID можно посмотреть тут - NSS — Namespace Specific String, эта компонента служит непосредственно для передачи каких-либо данных.
Разрешенные символы:
Зарезервированные символы:латинские буквы, цифры, процентно-кодированные, "(", ")", "+", ",", "-", ".", ":", "=", "@", ";", "$", "_", "!", "*", "'"
Запрещенные символы должны быть процентно-кодированы. Если указанный символ встретится в явном виде, его позиция будет считаться концом URN:"%", "/", "?", "#"
октеты 0-32 (0-20 hex), "\", """, "&", "<", ">", "[", "]", "^", "`", "{", "|", "}", "~", октеты 127-255 (7F-FF hex)
Самоидентифицирующийся URN
Такие URN содержат в NID название хэш-функции, а в NSS значение хэша, вычисленного для идентифицируемого объекта. Такие ссылки используются в magnet-ссылках и заголовках p2p-сети Gnutela2.Например, URN из magnet-ссылки с одного торрент-трекера:
magnet:?xt=urn:btih:c68abc1ba9b8c7c4bc373862cad1a8c01d69e53d...С теорией все, во второй части рассмотрим, что можно и что нужно делать с URI, если мы их обрабатываем, а именно — нормализация, разбор и т.д.
За сим откланяюсь, спасибо что читали, надеюсь не было скучно, удачи!
Комментарии (47)

eyeofhell
12.07.2015 08:26+10заканчивается следующим слешем(/), знаком вопроса(?) или октоторпом(#)(да-да, «решеточка» зовется именно так=)) или концом URI
Октоторп О_О. Мир никогда не будет прежним…
За статью отдельное спасибо, экскурс в отличия URL от URI более чем познавательный.
BTW, я вижу в описании частей URI что, к примеру, один заканчивается на "?", а другой с этого же "?" начинается. Они что, накладываются друг на друга? Символ "?" входит одновременно в две части URI?
xobotyi Автор
12.07.2015 10:31Хм, действительно есть некая двоякость в описании, но вообще, для всех под-компонент, кроме пути, границы указаны исключающим образом, т.е. ни краевые слеши, ни знаки вопроса и т.д. не входят в сами под-компоненты,
т.е. для URIhttp://habrahabr.ru:80/post/232385/?some=val#comment_8495021:
http— scheme
habrahabr.ru:80— host
/post/232385/— path
some=val— query
comment_8495021— fragment
Попробую как-нибудь перефразировать сейчас то что в статье.

Chulup
12.07.2015 10:33Путь начинается со слеша(/) и заканчивается знаком вопроса(?), октоторпом(#) или концом URI
Я не помню, как это в RFC, но это значит, что "?", "#" и конец строки указывают, где уже НЕ путь. То есть, ["/", "?#\$"), если можно так выразиться =)xobotyi Автор
12.07.2015 10:36Ну вообще да, т.е. когда я писал у меня не было мыслей о том что оно может быть как-либо двояко воспринято, но вот прецедент.
Когда оканчивается включительно так обычно и пишут «включительно» %)
grumbler66rus
12.07.2015 12:00А это есть в Законе Мерфи, вот неточная цитата: даже если высказывание исключает неверное толкование, всегда найдётся тот, кто поймёт его неправильно. :)
xobotyi Автор
12.07.2015 10:40А вообще, если судить по регулярке, которая описана в RFC, то они в конечном итоге делают разделение как я указал выше.
Описываемые спецсимволы разделяют под-компоненты, но в них не входят, исключение составляет путь, он включает в себя и начальный и конечный слеш.


Vindicar
12.07.2015 12:36Интересно! То есть, хотя разнообразные подключаемые внешние JS-скрипты обычно делают что-то вроде:
на самом деле они могли бы просто опустить схему? Как-то так:url = (is_https?'https://':'http://')+host+path;
url = '//'+host+path;xobotyi Автор
12.07.2015 12:43Да, конкретно скрипты из CDN гугла так и подключаются, все ссылки которые оттуда копируются идут в формате ссылок сетевого пути, на хабрасторадже так же.
Но это чревато в случае использования из под https, ибо https есть не везде.
negodnik
14.07.2015 03:50Но это чревато в случае использования из под https, ибо https есть не везде.
Но подключенный http из https все равно не заработает в адекватных браузерах.

vintage
12.07.2015 13:04+1Для того чтобы ссылка считалась URI необходимо наличие:
либо scheme+authority+path,
либо sheme+authority,
либо только path.
Глупости какие-то. В абсолютном uri схема обязательна.
The scheme and path components are required, though the path may be
empty (no characters). When authority is present, the path must
either be empty or begin with a slash ("/") character. When
authority is not present, the path cannot begin with two slash
characters ("//"). These restrictions result in five different ABNF
rules for a path (Section 3.3), only one of which will match any
given URI reference.
А вот в относительном URI любые компоненты слева могут быть обрезаны. Так что «только path» — это относительный URI, «только query» и «только fragment» — тоже.xobotyi Автор
12.07.2015 13:09А в том моменте разве шла вообще речь об относительных и абсолютных URI?
Там указаны все комбинации при которых ссылка = URI, про относительность и абсолютность ни слова, про это более чем подробно рассказано в разделе 2.1vintage
12.07.2015 13:15-1В том моменте написаны глупости не соответствующие спецификации.
URI-reference = URI / relative-ref
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
relative-ref = relative-part [ "?" query ] [ "#" fragment ]
В URI схема обязательная, всё остальное — нет.
В relative-ref вообще нет ничего обязательного.xobotyi Автор
12.07.2015 13:37Т.е. ABNF вы читать не умеете и мне пытаетесь предъявить, что я пишу глупости. Ну тогда поехали.
URI-reference = URI / relative-ref
Читается какURI и/или relative-ref
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
Читается какscheme и ":" и hier-part и/или [ "?" и query ] и/или [ "#" и fragment ]
relative-ref = relative-part [ "?" query ] [ "#" fragment ]
Читается какrelative-part и/или [ "?" и query ] и/или [ "#" и fragment ]
Что естьhier-part? Этоauthority + path, ноpathможет быть нулевым, то естьhier-part = authority [ "/" path ], или если так не нравится, то можно не оборачивать в квадратные скобки, но тогда учитывать что отсутствиеpathэто тожеpath.
Что естьrelative-part? Это"/" path / path, то естьrelative-part = ["/"] path
То есть, резюмируя получаем следующую ABNF формулу:
URI-reference = scheme ":" authority [ "/" path ] [ "?" query ] [ "#" fragment ] / ["/"] path [ "?" query ] [ "#" fragment ]
То есть всегда обязательны либоscheme ":" authority и любой набор оставшихся компоненти тогда это абсолютный URI, либо любой набор компонент при отсутствующейscheme ":" authorityи тогда это относительный URI.
Ссылки сетевого пути в расчет не берутся ибо это специфичный вариант, разряда «исключение из общих правил».
Таким образом, ничего противоречащего спецификации в приведенном вами отрывке статьи нет.
Так кто из нас тут глупости то пишет?vintage
12.07.2015 14:33Как всё запущено…
ABNF вы читать не умеете и мне пытаетесь предъявить, что я пишу глупости.
Умею и читать, и писать. Писал парсеры на основе BNF. Кроме того мною разработана нотация лишённая основных недостатков BNF.
Читается как URI и/или relative-ref
Не «и/или», а только «или».
Что есть hier-part?
hier-part = "//" authority path-abempty / path-absolute / path-rootless / path-empty
path-abempty = *( "/" segment )
path-absolute = "/" [ segment-nz *( "/" segment ) ]
path-rootless = segment-nz *( "/" segment )
path-empty = 0<pchar>
… а не то, что вы написали.
И authority и собственно path — опциональны. Разница между «компонент есть, но он пустой» и «компонента нет» — есть только в BNF нотации. Семантической разницы тут нет.
xobotyi Автор
12.07.2015 15:08+1Был дурак, исправился…
Только щас понял что действительно неверно было написано, пост подправил, должно быть так:
либо scheme+authority+path,
либо sheme+path,
либо только path.
Искренние извинения, сказывается недостаток сна (T_T)vintage
12.07.2015 22:12Должно быть так: схема обязательна, всё остальное опционально.
xobotyi Автор
12.07.2015 22:17Для абсолютного URI схема обязательна, все остальное опционально.
Для относительного URI вообще все опционально, но при этом схема отсутствует.
Как-то так, завтра по-утру на свежую голову поправлю.

gonzazoid
12.07.2015 18:05>Кроме того мною разработана нотация лишённая основных недостатков BNF
Не поделитесь? Если сильно непричесано — то хотя бы приватно.vintage
12.07.2015 22:21Она описана в статье про формат Tree.
Выглядит грамматика, например, так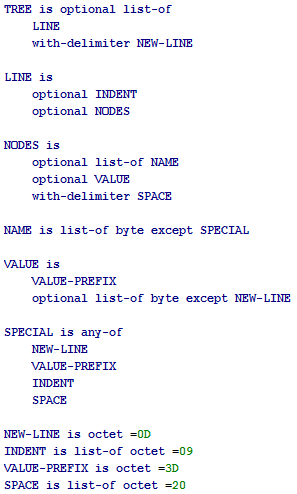
gonzazoid
13.07.2015 12:55ага, вспомнил. Знатный был срач. Тем не менее я в свое время ссылочку на статью добавил в свой стек лист, есть ощущение что ряд задач, которые у меня маячат на горизонте ближе к Вашему формату, чем к json. Спасибо.

pansa
12.07.2015 14:05+2Пара дополнений на которые сам когда-то наткнулся:
1) #fragment НЕ передается в HTTP-запросе на сервер, а используется только самим браузером.
2) существует HTML-тэг base — которым можно переопределить часть authority для всех относительных URI на данной странице. Это иногда может сбивать с толку.
Вдруг кто не знает. :)
P.S. Да, еще я бы акцентировал, что PATH и QUERY регистрозависимы, в отличие от HOST.xobotyi Автор
12.07.2015 14:10Ну, это уже в больше степени браузерные аспекты и особенности HTTP, тем не менее, я планировал отметить эти моменты во второй главе =)
vintage
12.07.2015 14:40base не authority переопределяет, а base-uri, который по умолчанию равен uri, по которому эта страница получена.
scheme и host регистронезависимы. Остальные компоненты — в зависимости от реализации. Как правило регистрозависимость path зависит от регистрозависимости файловой системы, где ищутся соответствующие файлы.pansa
12.07.2015 15:15> scheme и host регистронезависимы
Да, это есть в статье и с этим никто не спорил вроде бы. А вот про регистрозависимость остальных частей сказано расплывчато, что я и хотел подчеркнуть.
> Остальные компоненты — в зависимости от реализации.
Обсуждается не реализация, которая может (не)соответствовать RFC, а как это задумано, как должно быть. Должно быть — регистрозависимо. Хотя, конечно, в большистве случаев это не нужно и принудительно можно отключить. В том числе могут влиять и ФС, но это всего одна из возможных причин. Никаких файлов может не быть вовсе.
xobotyi Автор
12.07.2015 15:34Они не должны быть регистронезависимы, они могут быть регистронезависимы.
Спецификация допускает использование как верхнего так и нижнего регистров, остальное зависит от:
а) Спецификации схемы, которая может наложить эти ограничения, т.е. у HTTP нормализация URI производится таковым образом, что схема и хост — регистронезависимы, а все остальное нормализуется как регистрозависимое;
б) Реализации, тут уже кто на что способен, как говорится.pansa
12.07.2015 15:49Согласен, но почти =) Читаем:
6.2.2. Syntax-Based Normalization
…
When a URI uses components of the generic syntax, the component
syntax equivalence rules always apply; namely, that the scheme and
host are case-insensitive and therefore should be normalized to
lowercase. For example, the URI <HTTP://www.EXAMPLE.com/> is
equivalent to <www.example.com>. The other generic syntax
components are assumed to be case-sensitive unless specifically
defined otherwise by the scheme (see Section 6.2.3).
Я это понимаю, так, что компоненты предполагаются регистрозависимыми, ЕСЛИ некоторая схема явно не отменяет это.
Т.е они могут быть регистроНЕзависимыми. Раз уж мы так трепетны к букве RFC :)xobotyi Автор
12.07.2015 15:53Переводится как «предполагается что должны быть регистрозависимыми». Короче конечная инстанция в данном вопросе — спецификация схемы.
xobotyi Автор
12.07.2015 14:53P.S. Да, еще я бы акцентировал, что PATH и QUERY регистрозависимы, в отличие от HOST.
scheme — регистронезависим
host — регистронезависим
path — в зависимости от имплементации файловой системы сервера
query — регистрозависим
fragment — в зависимости от браузераpansa
12.07.2015 16:14+1А про зависимость от ФС сервера можно где-то в RFC ссылку? Я понимаю о чем речь, но это особенности реализации конкретных http-серверов, и обсуждаемые RFC тут ни при чем. Повторюсь, например, у меня реализация какого-нибудь REST-API, и там не будет никаких подкаталогов и файлов, иерархия PATH будет чисто виртуальной. И вообще без разницы на какой ФС работает сервер.
noxwell
12.07.2015 18:31+1Кстати, меня все время мучил вопрос, почему в ссылке на локальный файл три слеша, например, file:///C:/test.htm. Думал в этой статье найти ответ, но нет, пришлось гуглить. Оказывается если в URI опущен host, то подразумевается localhost, то есть ссылка выше будет приравнена к file://localhost/C:/test.htm. Интересно, это особенность только схемы file, или это правило универсально?
xobotyi Автор
12.07.2015 18:34+2Истолковать можно следующим образом:
схема — file
хост — нулевой, т.е. локалхост
путь — /C:/test.htm, т.е. здесь путь отсчитывается от корня, вот и получается 3 слеша
Я это планировал включить в следующую часть.
Egor3f
12.07.2015 22:58+1Мне ещё любопытно – почему в схемах http://, ftp://, file:// используются слэши, а в схемах mailto:, tel:, magnet: – их нет?
xobotyi Автор
13.07.2015 11:32у mailto:, magnet: и иже с ними нет части authority, есть path, query и т.д., но authority нету.
//относится именно к компоненте authority.
Если, например посмотреть RFC по mailto, то можно увидеть вот такой момент:
mailto:addr1%2C%20addr2
is equivalent to
mailto:?to=addr1%2C%20addr2
is equivalent to
mailto:addr1?to=addr2
Таким образом, mailto:addr@gmail.com это всего лишь специфичный для mailto синтаксис аналогичный mailto:?to=addr@gmail.com, т.е. для схемы mailto путь, если он задан, в конечном итоге преобразуется в хедер «to».

zlyoha
17.07.2015 12:34Синтаксис регистрационного имени позволяет использование процентно-кодированных символов, для представления не-ASCII символов
На chrome работает, IE11 не справляется, а в Firefox принудительно добавляет www., так не должно быть?
http://%D0%BF%D1%80%D0%B5%D0%B7%D0%B8%D0%B4%D0%B5%D0%BD%D1%82.%D1%80%D1%84 http://www.президент.рф/
zlyoha
17.07.2015 16:45В FF помогает установка browser.fixup.alternate.enabled = false
При этом имя декодирует, но все равно выдает ошибку. После перезагрузки страницы все ок.
Если кому интересно — принцип работы domain guessing
xobotyi Автор
20.07.2015 11:34+1для доменов с национальными символами есть такая порнуха как IRI и IDN, там используется punycode шифрование, и к несчастью, это стандарт…

qw1
Всем, кто дочитал до конца, в подарок альбом Kongos — Lunatic