
Распределенные системы используют, когда возникает необходимость в горизонтальном масштабировании, чтобы обеспечить повышенные показатели производительности, которые не способна обеспечить за адекватные деньги вертикально масштабированная система.
Как и переход с однопоточной парадигмы на многопоточную, миграция на распределенную систему требует своего рода погружения и понимания того, как это работает внутри, на что нужно обращать внимание.
Одна из проблем, которая встает перед человеком, который хочет мигрировать проект на распределенную систему или начать на ней проект, — какой продукт выбрать.
Мы, как компания, которая «собаку сьела» в разработке систем такого рода, помогаем нашим клиентам взвешенно принимать такие решения применительно к распределенным системам хранения. Также мы выпускаем серию вебинаров для более широкой аудитории, которые посвящены базовым принципам, рассказанным простым языком, и безотносительно каких-то конкретных продуктовых предпочтений помогают составить карту значимых характеристик, чтобы облегчить выбор.
Эта статья основана на наших материалах по консистентности и ACID-гарантиям в распределенных системах.
«Согласованность данных (иногда консистентность данных, англ. data consistency) — согласованность данных друг с другом, целостность данных, а также внутренняя непротиворечивость.» (Wikipedia)
Согласованность подразумевает, что в любой момент времени приложения могут быть уверены, что работают с корректной, технически актуальной версией данных, и могут расчитывать на нее при принятии решений.
В распределенных системах обеспечивать согласованность становится сложнее и дороже, потому что появляется целый ряд новых вызовов, связанных с сетевым обменом между различными узлами, возможностью отказа отдельных узлов и — зачастую — отсутствием единой памяти, которая может служить для верификации.
Например, если у меня есть система из 4 узлов: A, B, C и D, которая обслуживает банковские транзакции, и узлы C и D отделились от A и B (скажем, из-за сетевых проблем), вполне возможно, я теперь не имею доступа к части транзакций. Как мне действовать в этой ситуации? Разные системы принимают разные подходы.

На верхнем уровне есть 2 ключевых направления, которые выражены в CAP-теореме.
«Теорема CAP (известная также как теорема Брюера) — эвристическое утверждение о том, что в любой реализации распределённых вычислений возможно обеспечить не более двух из трёх следующих свойств:
(Wikipedia)
Когда CAP-теорема говорит о консистентности, она подразумевает достаточно строгое определение, включающее линеаризацию записей и чтений, и оговаривает только консистетность при записи отдельных значений. (Martin Kleppman)
CAP-теорема говорит о том, что если мы хотим быть устойчивы к сетевым проблемам, то мы в целом должны выбрать, чем жертвовать: консистентностью или доступностью. Есть также расширенная версия этой теоремы — PACELC (Wikipedia), которая дополнительно рассказывает о том, что даже в отсутствии сетевых проблем мы должны выбирать между скоростью отклика и консистетностью.
И хотя, на первый взгляд выходца из мира классических СУБД, кажется, что выбор очевиден, и консистетность — самое главное, что у нас есть, это далеко не всегда так, что ярко иллюстрирует взрывной рост целого ряда NoSQL СУБД, которые сделали другой выбор и, несмотря на это, получили огромную пользовательскую базу. Apache Cassandra с ее знаменитой eventual consistency является хорошим примером.
Все из-за того, что это выбор, который подразумевает, что мы чем-то жертвуем, и далеко не всегда мы этим жертвовать готовы.
Часто проблема консистентности в распределенных системах решается просто отказом от этой консистентности.
Но нужно и важно понимать, когда отказ от этой консистентности допустим, а когда она является бизнес-критичным требованием.
Например, если я проектирую компонент, который отвечает за хранение пользовательских сессий, здесь мне, скорее всего, консистентность не так важна, да и потеря данных некритична, если она происходит только в проблемных случаях — очень редко. Худшее, что случится, — пользователю нужно будет перелогиниться, и для многих бизнесов это практически никак не повлияет на их финансовые показатели.
Если я делаю аналитику на потоке данных с датчиков, во многих случаях мне совсем некритично потерять часть данных и получить на небольшом промежутке времени пониженную дискретизацию, особенно, если «eventually» данные я все-таки увижу.
Но если я делаю банковскую систему, консистентность денежных проводок критична для моего бизнеса. Если я начислил пеню на кредит клиента из-за того, что просто не увидел в срок внесенный платеж, хотя он был в системе — это очень-очень плохо. Как и если клиент может несколько раз снять все деньги с моей кредитной карты, потому что у меня в момент проведения транзакции возникли сетевые проблемы, и на часть моего кластера информация о снятии не дошла.
Если вы оформляете дорогостоящую покупку в интернет-магазине, вы не хотите, чтобы о вашем заказе забыли, несмотря на рапортующую об успехе веб-страницу.
Но если вы делаете выбор в пользу консистентности, вы жертвуете доступностью. И зачастую это ожидается, скорее всего, вы не раз сталкивались с этим лично.
Лучше, если корзина интернет-магазина скажет «попробуйте позднее, распределенная СУБД недоступна», чем если отрапортует об успехе и забудет заказ. Лучше получить отказ в транзакции из-за недоступности сервисов банка, чем отбивку об успехе и потом разбирательства с банком из-за того, что он забыл, что вы внесли платеж по кредиту.
Наконец, если мы смотрим на расширенную, PACELC теорему, то мы понимаем, что даже в случае штатной работы системы, выбирая консистентность, мы можем жертвовать низкими задержками, получая потенциально более низкий уровень максимальной производительности.
Поэтому, отвечая на вопрос «зачем это нужно?»: это нужно, если для вашей задачи критично иметь актуальные, целостные данные, и альтернатива принесет вам существенные потери, большие, чем временная недоступность сервиса на период инцидента или его более низкая производительность.
Соответственно, первое решение, которое вам нужно принять — где вы находитесь в CAP-теореме, вы хотите консистентность или доступность в случае инцидента.
Далее нужно понять, на каком уровне вы хотите проводить изменения. Возможно, вам хватит обычных атомарных записей, затрагивающих единственный объект, как умела и умеет MongoDB (сейчас она расширяет это дополнительно поддержкой полноценных транзакций). Напомню, что CAP-теорема ничего не говорит о консистентности операций записи, затрагивающих множественные объекты: система вполне может быть CP (т.е. предпочитать консистентность доступности) и при этом предоставлять только атомарные одиночные записи.
Если вам этого не хватает, мы начинаем подходить к концепции полноценных распределенных ACID-транзакций.
Замечу, что даже переходя в дивный новый мир распределенных ACID-транзакций, мы зачастую вынуждены чем-то жертвовать. Так например, ряд распределенных систем хранения имеет распределенные транзакции, но только в рамках одной партиции. Или, например, система может не поддерживать «I»-часть на нужном вам уровне, не имея изоляции, либо имея недостаточное количество уровней изоляции.
Эти ограничения зачастую были сделаны по какой-то причине: либо для упрощения реализации, либо, например, для повышения производительности, либо для чего-то еще. Они достаточны для большого количества кейсов, поэтому не стоит рассматривать их как минусы сами по себе.
Нужно понять, являются ли эти ограничения проблемой для вашего конкретного сценария. Если нет, — у вас есть более широкий выбор, и вы можете больший вес дать, например, показателям производительности или способности системы обеспечивать катастрофоустойчивость и т.д. Наконец, нужно не забывать, что у ряда систем эти параметры могут настраиваться вплоть до того, что система может быть CP или AP в зависимости от конфигурации.
Если наш продукт стремится быть CP, то обычно у него есть либо кворумный подход к выбору данных, либо выделенные узлы, которые являются основными владельцами записей, через них проходят все изменения данных, и в случае сетевых проблем, если эти мастер-узлы не могут дать ответ, считается, что данные в принципе, невозможно получить, либо арбитраж, когда внешний высокодоступный компонент (например, кластер ZooKeeper) может говорить, какой из сегментов кластера является основным, содержит актуальную версию данных и может эффективно обслуживать запросы.
Наконец, если нас интересует не просто CP, но поддержка полноценных распределенных ACID-транзакций, то зачастую или используется все же единый источник истины, например, централизованное дисковое хранилище, где наши узлы, по сути, выступают лишь кешами к нему, которые можно инвалидировать в момент коммита, или применяется протокол многофазового коммита.
Первый подход с единым диском также упрощает реализацию, дает низкие задержки на распределенных транзакциях, но торгует взамен очень ограниченной масштабируемостью на нагрузках с большими объемами записи.
Второй подход дает намного больше свободы в масштабировании, и, в свою очередь, делится на двухфазный (Wikipedia) и трехфазный (Wikipedia) протоколы коммита.
Рассмотрим на примере двухфазного коммита, который использует, например, Apache Ignite.
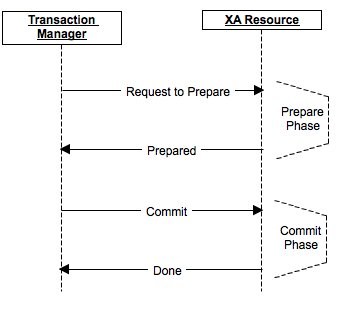
?
Процедура коммита делится на 2 фазы: prepare и commit.
На фазе prepare рассылается сообщение о подготовке к коммиту, и каждый участник при необходимости делает блокировку, выполняет все операции вплоть до фактического commit не включительно, рассылает prepare на свои реплики, если это предполагается продуктом. Если хотя бы один из участников ответил по какой-то причине отказом или оказался недоступен — данные фактически не поменялись, коммита не было. Участники откатывают изменения, снимают блокировки и возвращаются на исходное состояние.
На фазе commit отправляется фактическое выполнение commit на узлах кластера. Если по какой-то причине часть узлов была недоступна или ответила ошибкой, то к этому времени данные занесены в их redo-лог (поскольку prepare был выполнен успешно), и коммит в любом случае может быть завершен хотя бы в отложенном состоянии.
Наконец, если отказывает координатор, то на prepare-этапе коммит будет отменен, на commit-этапе может быть выбран новый координатор, и, если все узлы выполнили prepare, он может проверить и обеспечить выполнение этапа commit.
Разные продукты имеют свои особенности реализации и оптимизации. Так, например, некоторые продукты умеют в отдельных случаях сводить 2-х фазный коммит к 1-фазному, значительно выигрывая по производительности.
Ключевой вывод: распределенные системы хранения данных — это достаточно развитый рынок, и продукты на нем могут обеспечивать высокую консистентность данных.
При этом продукты этой категории находятся на разных точках шкалы консистентности, от полностью AP-продуктов без какой-либо транзкционности, до CP-продуктов, которые дополнительно дают еще и полноценные ACID-транзакции. Часть продуктов может быть настроена в одну или в другую сторону.
Когда вы выбираете, что нужно вам, нужно учитывать потребности вашего кейса и хорошо понимать, на какие жертвы и компромиссы вы готовы пойти, потому что ничего не бывает бесплатно, и выбирая одно, вы, скорее всего, откажетесь от чего-то другого.
Оценивая продукты с этой стороны, стоит обращать внимание на то:
Как и переход с однопоточной парадигмы на многопоточную, миграция на распределенную систему требует своего рода погружения и понимания того, как это работает внутри, на что нужно обращать внимание.
Одна из проблем, которая встает перед человеком, который хочет мигрировать проект на распределенную систему или начать на ней проект, — какой продукт выбрать.
Мы, как компания, которая «собаку сьела» в разработке систем такого рода, помогаем нашим клиентам взвешенно принимать такие решения применительно к распределенным системам хранения. Также мы выпускаем серию вебинаров для более широкой аудитории, которые посвящены базовым принципам, рассказанным простым языком, и безотносительно каких-то конкретных продуктовых предпочтений помогают составить карту значимых характеристик, чтобы облегчить выбор.
Эта статья основана на наших материалах по консистентности и ACID-гарантиям в распределенных системах.
Что это такое и зачем это нужно?
«Согласованность данных (иногда консистентность данных, англ. data consistency) — согласованность данных друг с другом, целостность данных, а также внутренняя непротиворечивость.» (Wikipedia)
Согласованность подразумевает, что в любой момент времени приложения могут быть уверены, что работают с корректной, технически актуальной версией данных, и могут расчитывать на нее при принятии решений.
В распределенных системах обеспечивать согласованность становится сложнее и дороже, потому что появляется целый ряд новых вызовов, связанных с сетевым обменом между различными узлами, возможностью отказа отдельных узлов и — зачастую — отсутствием единой памяти, которая может служить для верификации.
Например, если у меня есть система из 4 узлов: A, B, C и D, которая обслуживает банковские транзакции, и узлы C и D отделились от A и B (скажем, из-за сетевых проблем), вполне возможно, я теперь не имею доступа к части транзакций. Как мне действовать в этой ситуации? Разные системы принимают разные подходы.
На верхнем уровне есть 2 ключевых направления, которые выражены в CAP-теореме.
«Теорема CAP (известная также как теорема Брюера) — эвристическое утверждение о том, что в любой реализации распределённых вычислений возможно обеспечить не более двух из трёх следующих свойств:
- согласованность данных (англ. consistency) — во всех вычислительных узлах в один момент времени данные не противоречат друг другу;
- доступность (англ. availability) — любой запрос к распределённой системе завершается корректным откликом, однако без гарантии, что ответы всех узлов системы совпадают;
- устойчивость к разделению (англ. partition tolerance) — расщепление распределённой системы на несколько изолированных секций не приводит к некорректности отклика от каждой из секций.»
(Wikipedia)
Когда CAP-теорема говорит о консистентности, она подразумевает достаточно строгое определение, включающее линеаризацию записей и чтений, и оговаривает только консистетность при записи отдельных значений. (Martin Kleppman)
CAP-теорема говорит о том, что если мы хотим быть устойчивы к сетевым проблемам, то мы в целом должны выбрать, чем жертвовать: консистентностью или доступностью. Есть также расширенная версия этой теоремы — PACELC (Wikipedia), которая дополнительно рассказывает о том, что даже в отсутствии сетевых проблем мы должны выбирать между скоростью отклика и консистетностью.
И хотя, на первый взгляд выходца из мира классических СУБД, кажется, что выбор очевиден, и консистетность — самое главное, что у нас есть, это далеко не всегда так, что ярко иллюстрирует взрывной рост целого ряда NoSQL СУБД, которые сделали другой выбор и, несмотря на это, получили огромную пользовательскую базу. Apache Cassandra с ее знаменитой eventual consistency является хорошим примером.
Все из-за того, что это выбор, который подразумевает, что мы чем-то жертвуем, и далеко не всегда мы этим жертвовать готовы.
Часто проблема консистентности в распределенных системах решается просто отказом от этой консистентности.
Но нужно и важно понимать, когда отказ от этой консистентности допустим, а когда она является бизнес-критичным требованием.
Например, если я проектирую компонент, который отвечает за хранение пользовательских сессий, здесь мне, скорее всего, консистентность не так важна, да и потеря данных некритична, если она происходит только в проблемных случаях — очень редко. Худшее, что случится, — пользователю нужно будет перелогиниться, и для многих бизнесов это практически никак не повлияет на их финансовые показатели.
Если я делаю аналитику на потоке данных с датчиков, во многих случаях мне совсем некритично потерять часть данных и получить на небольшом промежутке времени пониженную дискретизацию, особенно, если «eventually» данные я все-таки увижу.
Но если я делаю банковскую систему, консистентность денежных проводок критична для моего бизнеса. Если я начислил пеню на кредит клиента из-за того, что просто не увидел в срок внесенный платеж, хотя он был в системе — это очень-очень плохо. Как и если клиент может несколько раз снять все деньги с моей кредитной карты, потому что у меня в момент проведения транзакции возникли сетевые проблемы, и на часть моего кластера информация о снятии не дошла.
Если вы оформляете дорогостоящую покупку в интернет-магазине, вы не хотите, чтобы о вашем заказе забыли, несмотря на рапортующую об успехе веб-страницу.
Но если вы делаете выбор в пользу консистентности, вы жертвуете доступностью. И зачастую это ожидается, скорее всего, вы не раз сталкивались с этим лично.
Лучше, если корзина интернет-магазина скажет «попробуйте позднее, распределенная СУБД недоступна», чем если отрапортует об успехе и забудет заказ. Лучше получить отказ в транзакции из-за недоступности сервисов банка, чем отбивку об успехе и потом разбирательства с банком из-за того, что он забыл, что вы внесли платеж по кредиту.
Наконец, если мы смотрим на расширенную, PACELC теорему, то мы понимаем, что даже в случае штатной работы системы, выбирая консистентность, мы можем жертвовать низкими задержками, получая потенциально более низкий уровень максимальной производительности.
Поэтому, отвечая на вопрос «зачем это нужно?»: это нужно, если для вашей задачи критично иметь актуальные, целостные данные, и альтернатива принесет вам существенные потери, большие, чем временная недоступность сервиса на период инцидента или его более низкая производительность.
Как это обеспечить?
Соответственно, первое решение, которое вам нужно принять — где вы находитесь в CAP-теореме, вы хотите консистентность или доступность в случае инцидента.
Далее нужно понять, на каком уровне вы хотите проводить изменения. Возможно, вам хватит обычных атомарных записей, затрагивающих единственный объект, как умела и умеет MongoDB (сейчас она расширяет это дополнительно поддержкой полноценных транзакций). Напомню, что CAP-теорема ничего не говорит о консистентности операций записи, затрагивающих множественные объекты: система вполне может быть CP (т.е. предпочитать консистентность доступности) и при этом предоставлять только атомарные одиночные записи.
Если вам этого не хватает, мы начинаем подходить к концепции полноценных распределенных ACID-транзакций.
Замечу, что даже переходя в дивный новый мир распределенных ACID-транзакций, мы зачастую вынуждены чем-то жертвовать. Так например, ряд распределенных систем хранения имеет распределенные транзакции, но только в рамках одной партиции. Или, например, система может не поддерживать «I»-часть на нужном вам уровне, не имея изоляции, либо имея недостаточное количество уровней изоляции.
Эти ограничения зачастую были сделаны по какой-то причине: либо для упрощения реализации, либо, например, для повышения производительности, либо для чего-то еще. Они достаточны для большого количества кейсов, поэтому не стоит рассматривать их как минусы сами по себе.
Нужно понять, являются ли эти ограничения проблемой для вашего конкретного сценария. Если нет, — у вас есть более широкий выбор, и вы можете больший вес дать, например, показателям производительности или способности системы обеспечивать катастрофоустойчивость и т.д. Наконец, нужно не забывать, что у ряда систем эти параметры могут настраиваться вплоть до того, что система может быть CP или AP в зависимости от конфигурации.
Если наш продукт стремится быть CP, то обычно у него есть либо кворумный подход к выбору данных, либо выделенные узлы, которые являются основными владельцами записей, через них проходят все изменения данных, и в случае сетевых проблем, если эти мастер-узлы не могут дать ответ, считается, что данные в принципе, невозможно получить, либо арбитраж, когда внешний высокодоступный компонент (например, кластер ZooKeeper) может говорить, какой из сегментов кластера является основным, содержит актуальную версию данных и может эффективно обслуживать запросы.
Наконец, если нас интересует не просто CP, но поддержка полноценных распределенных ACID-транзакций, то зачастую или используется все же единый источник истины, например, централизованное дисковое хранилище, где наши узлы, по сути, выступают лишь кешами к нему, которые можно инвалидировать в момент коммита, или применяется протокол многофазового коммита.
Первый подход с единым диском также упрощает реализацию, дает низкие задержки на распределенных транзакциях, но торгует взамен очень ограниченной масштабируемостью на нагрузках с большими объемами записи.
Второй подход дает намного больше свободы в масштабировании, и, в свою очередь, делится на двухфазный (Wikipedia) и трехфазный (Wikipedia) протоколы коммита.
Рассмотрим на примере двухфазного коммита, который использует, например, Apache Ignite.
?
Процедура коммита делится на 2 фазы: prepare и commit.
На фазе prepare рассылается сообщение о подготовке к коммиту, и каждый участник при необходимости делает блокировку, выполняет все операции вплоть до фактического commit не включительно, рассылает prepare на свои реплики, если это предполагается продуктом. Если хотя бы один из участников ответил по какой-то причине отказом или оказался недоступен — данные фактически не поменялись, коммита не было. Участники откатывают изменения, снимают блокировки и возвращаются на исходное состояние.
На фазе commit отправляется фактическое выполнение commit на узлах кластера. Если по какой-то причине часть узлов была недоступна или ответила ошибкой, то к этому времени данные занесены в их redo-лог (поскольку prepare был выполнен успешно), и коммит в любом случае может быть завершен хотя бы в отложенном состоянии.
Наконец, если отказывает координатор, то на prepare-этапе коммит будет отменен, на commit-этапе может быть выбран новый координатор, и, если все узлы выполнили prepare, он может проверить и обеспечить выполнение этапа commit.
Разные продукты имеют свои особенности реализации и оптимизации. Так, например, некоторые продукты умеют в отдельных случаях сводить 2-х фазный коммит к 1-фазному, значительно выигрывая по производительности.
Выводы
Ключевой вывод: распределенные системы хранения данных — это достаточно развитый рынок, и продукты на нем могут обеспечивать высокую консистентность данных.
При этом продукты этой категории находятся на разных точках шкалы консистентности, от полностью AP-продуктов без какой-либо транзкционности, до CP-продуктов, которые дополнительно дают еще и полноценные ACID-транзакции. Часть продуктов может быть настроена в одну или в другую сторону.
Когда вы выбираете, что нужно вам, нужно учитывать потребности вашего кейса и хорошо понимать, на какие жертвы и компромиссы вы готовы пойти, потому что ничего не бывает бесплатно, и выбирая одно, вы, скорее всего, откажетесь от чего-то другого.
Оценивая продукты с этой стороны, стоит обращать внимание на то:
- где они находятся в CAP-теореме;
- поддерживают ли они распределенные ACID-транзакции;
- какие ограничения они накладывают на распределенные транзакции (например, только в рамках одной партиции и т.д.);
- удобство и эффективность пользования распределенными транзакциями, их интегрированность в другие компоненты продукта.