
 Если вы лениво следите за последними новостями, просматривая заголовки в своей ленте, то в течение последних двух лет вы сталкивались с пассажами примерно такого уровня: «Amazon борется с доминацией Intel и запускает производство своих серверных CPU», «Intel теряет значительную долю рынка», «Amazon отказывается от процессоров Intel», «В разработке находятся серверные ARM-процессоры от Amazon», «Intel переносит потребительский релиз 10 нм CPU» и наконец «Intel представит 7 нм процессор в 2020 году».
Если вы лениво следите за последними новостями, просматривая заголовки в своей ленте, то в течение последних двух лет вы сталкивались с пассажами примерно такого уровня: «Amazon борется с доминацией Intel и запускает производство своих серверных CPU», «Intel теряет значительную долю рынка», «Amazon отказывается от процессоров Intel», «В разработке находятся серверные ARM-процессоры от Amazon», «Intel переносит потребительский релиз 10 нм CPU» и наконец «Intel представит 7 нм процессор в 2020 году». Конечно, заголовки эти весьма примерные и если вы не занимаетесь обслуживанием серверов или не арендуете мощности у AWS, то все это вас слабо касается. Ну барахтаются там гиганты между собой, как девицы на вечеринке лупят друг друга мешками, набитыми деньгами, при этом Qualcomm и AMD ведут каждый свою разработку, у NVIDIA какое-то движение с их CUDA, а Apple как обычно тихо в углу
{kind=link}
Откуда вообще весь этот шум
Зарождение тренда на гнобление Intel началось с момента, когда компания заявила о проблемах с массовым производством 10 нм чипов и объявила о переносе релиза. Ждали-то чип еще в 2016 году в рамках серии CPU Cannon Lake, но у Intel что-то не заладилось и сроки разработки не раз переносились. Вот их старый roadmap:

Сюда же можно добавить неоднократное нарушение компанией собственного цикла «новый техпроцесс — улучшение производительности» и мы имеем ситуацию, при которой компания стала целью нападок различных изданий и медиа. Разговоры вокруг этой технологии дошли до того, что в сети стали появляться материалы, авторы которых утверждали полный отказ от 10 нм как таковых. Мол, все мы останемся на текущих 14 нм чипах в ближайшем будущем.
Компания отреагировала достаточно быстро и заявила, что «отказ от разработки 10 нм чипов» — банальный наброс:
С другой стороны в не слишком чистоплотных медиа обсуждается вопрос близости 7 нм чипов от гиганта, а логика в этих обсуждениях весьма проста: «пока не будет 10 нм, не будет и 7 нм». Это не так. Возможно, вероятность того, что 7 нм появятся раньше «десяти» и есть, но маркетологи компании этого сделать не позволят. Но как это возможно?
Разработкой чипов с архитектурами 10 и 7 нм занимаются принципиально разные инженерные команды. То есть процессоры с шагом в 7 нм не являются наследниками технических решений «десятки» и разрабатываются параллельно с 10 нм-чипами. При этом команда, которая работает над 7 нм оказалась более успешной, чем их коллеги, о чем заявляли сами Intel в лице директора по разработкам Мурти Рендучинтала (Murthy Renduchintala).
Основной проблемой перехода к 10 нм техпроцессу называется стремление Intel в 2,7-раза увеличить плотность транзисторов на квадратный миллиметр на той же технологии литографии, которая сейчас используется для производства других серийных моделей компании.
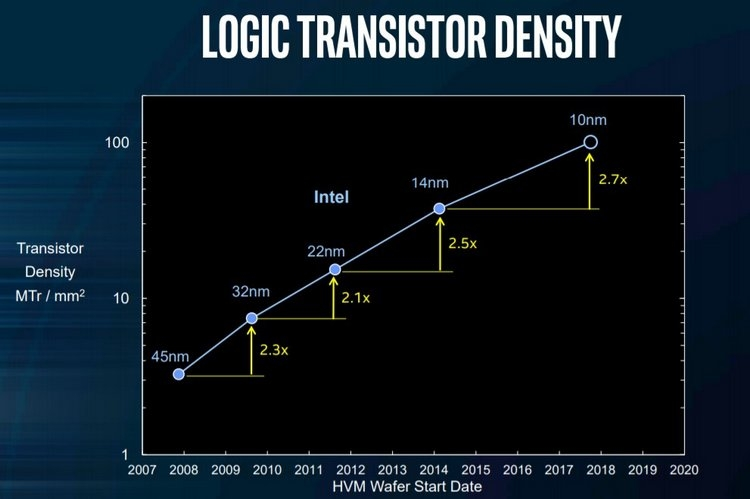
Roadmap компании по увеличению числа транзисторов от техпроцесса к техпроцессу
Но почему же с разработкой 7 нм-чипов таких проблем нет? Причины три: другая команда, меньший аппетит в плане плотности (Intel хочет увеличить плотность транзисторов не в 2,5-3, а «всего» в 2 раза) и новый способ литографии в глубоком ультрафиолете (EUV).
При этом уже в конце 2019 года AMD планирует выпустить свой коммерческий 7 нм процессор, но даже это не «убивает» Intel на рынке, как это пытается сделать пресса. Потому что даже текущие 14 нм+ CPU восьмого поколения имеют более высокую плотность транзисторов, чем более технологичные в плане нанометража процессоры конкурентов.
Тут вроде разобрались. Идем дальше к Amazon, ARM CPU Graviton и битве за серверный рынок.
Amazon снижает зависимость от Intel внедрением своего чипа Graviton, но не «убивает» сотрудничество
Особо горячие головы говорили, что если Amazon переведет весь AWS на процессоры собственной разработки Graviton на базе Cortex-A72, то «Intel капут». Собственно, истерия вокруг того, что «Король мертв! Ну, точнее скоро умрет!» и то, что Amazon может стать новым гигантом рынка и стала причиной для написания этого материала. Вообще, Amazon пыталась внедрить серверные ARM-решения еще несколько лет назад в рамках сотрудничества с AMD в 2015 году, но тогда что-то пошло не так. Почитать можно тут.
Но вернемся к вопросу путаницы в медиа. У нас есть следующие вводные:
- CPU от Intel крайне широко используются в AWS.
- Это долгосрочное сотрудничество.
- Чипы от Intel дорогие, что сказывается на прайсе AWS и конечной марже.
- Amazon занимается разработкой ARM-чипов (!).
В медиа предпочитают игнорировать пункт №4 и крайне активно пишут о том, что причин не отказываться от Intel у Amazon нет. Мол, гигант сможет замкнуть свою AWS-экосистему в плане CPU на собственную разработку и останется от этого только в выигрыше. Кроме этого, при превышении паспортных частот, процессоры от Intel весьма горячи и прожорливы, как те самые электровафельницы, так что энергоэффективные ARM выглядят еще лучше.
Проблема в том, что ARM исторически — это чипы с малым энергопотреблением для электротехнических и мобильных устройств. Сама архитектура подразумевает, что в угоду этой самой энергоэффективности ARM-чипам приходится отказываться от «грубой силы», которой обладают «старшие братья» от той же Intel или AMD.
Сама компания Amazon позиционирует Graviton как легкомасштабируемое облачное ARM-решение по низкой стоимости:
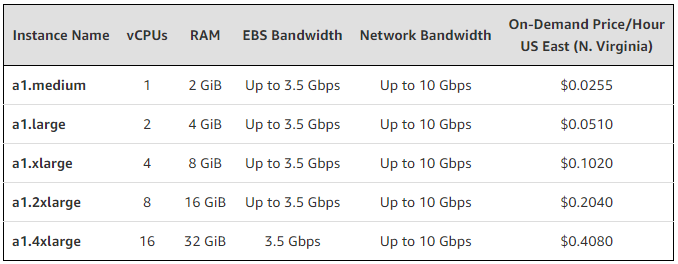
Фактически же ниша Graviton весьма мала из-за того, что на него нельзя повесить что-либо «тяжелое». ARM-процессор от Amazon хорош как бюджетное решение для малого и среднего бизнеса, но если речь идет о серьезном «обвесе», требующего постоянных и/или быстрых вычислений, Graviton начинает буквально задыхаться там, где процессоры Intel немного нагреваются. Тот же Extremetech в статье, приведенной выше, утверждает, что в зависимости от задач 16 ядер Graviton дают производительность на уровне всего 5 интеловских ядер Xeon E5-2697v4 поколения Broadwell, а это далеко не новый процессор. Существует мнение, что Graviton займет свою нишу еще и в сегменте линейных облачных задач, которые не будут требовать от него мощи, сопоставимой с процессорами Intel или AMD.
Итого
Если очистить всю эту историю от информационного шума и громких заголовков, то мы имеем по истории с серверными (и не только) процессорами Intel и Graviton от Amazon, разговорами вокруг «10 нм не скоро, 7 нм увидят только наши внуки» и прочее, следующее:
- 10 и 7 нм чипы от Intel будут, первые задержались, вторые идут по плану.
- 10 нм задержались скорее всего, из-за жадности Intel в плане 2,7-кратного увеличения числа транзисторов при той же технологии литографии.
- Gravition — ARM-процессор имеющий ряд ограничений, обусловленных архитектурой.
- Amazon отбирает у Intel часть собственного AWS-рынка, но не объявляет войну. Кроме того, AWS — не единственный крупный клиент Intel. Их чуть больше десяти.
- Для высоконагруженных систем Gravition не подходит, тут все еще актуальны предложения с процессорами Intel на борту.
- В медиа любят набрасывать, но никто «умирать» не собирается.
Надеемся, мы помогли немного разобраться в этом бардаке. Комментарии от специалистов и уточнения по теме приветствуются.
Комментарии (49)

pfg21
12.12.2018 16:01+2кроме попугаев скорости ядра есть еще такой параметр как цена.
если 16 ядерный арм будет работать как 5 ядерный интел, а стоит будет в несколько раз дешевле. то рынок скажет свое слово.
х86 архитектура перегружена дополнениями и расширениями, а также поддержкой всех наследованных команд, а это все выражается в площади кристалла и цене :(
арм стартует с более более высокого старта, не таща воз старья за собой.
и пока еще сильно новичок на «стероидном» рынке процов.
посмотрим.
lokkiuni
12.12.2018 18:35+4Ох, со времён п4/к7 эту песню слышу. Ничего поддержка команд не стоит, это по сути часть прошивки — «словаря» для декодера команд, который их во внутренние микрооперации переводит.
В общем, нужно быстрые ядра — делаются быстрые ядра. Нужно много слабых — делается много слабых. Архитектура не так много роли играет, как кажется, и каких-либо чудес, за исключением случаев, когда задача грамотно использует особенности архитектуры, не случается. Добавили к АРМ всю «ненужную» обвеску х86 — получили похожую производительность с похожими проблемами, см современные процессоры телефонов/планшетов что х86, что арм — по факту, на вкус и цвет.
Jamdaze
13.12.2018 09:52А вы смотрели эти кристаллы в разрезе? Там подавляющая часть занята кэшами всех уровней.
crezd
12.12.2018 17:23Есть ли смысл Интелу выкатывать 10нм если параллельно и даже с большим успехом продвигается разработка 7нм, может перескочить?
zorge_van_daar
12.12.2018 19:22На 10 нм они хотят получить плотность выше, чем на 7 нм. А чем выше плотность, тем больше поместится транзисторов на пластину кремния. А для настольного сегмента, количество транзисторов скорее всего важнее некоторых преимуществ меньшего техпроцесса — например сниженного энергопотребления. Плюс производственные линии с глубоким ультрофиолетом это очень дорого и, поговаривают, их не так легко сделать в нужном количестве. А закон Мура это не о техпроцессе, а о цене транзистора.
Mad__Max
13.12.2018 06:06Не хотят. x2 плотности транзисторов на 7нм это 2 раза больше от плановых показателей 10нм, которые в свою очередь должны были быть х2.7 от 14 нм.
Хотя эти «иксы» у Итела сильно маркетинговые. Если не голую теорию взять, а реальные чипы выходившие в продажу, то показатели будут намного скромнее. Между 45нм и 14нм нет 12 кратного увеличения плотности транзисторов на мм2 чипа как должно было бы быть, если верить красивым графикам, нарисованным маркетологами Intel (45нм==>32нм==>22нм==>14нм: 2.3*2.1*2.5 = 12.075x)
Например:
Core 2 Duo (ядро wolfdale): 45 нм, 411 млн транзисторов, 107 mm? ==> 3.84М / mm?
или
8-core Xeon Nehalem-EX 45 нм, 2300 млн, 684 mm? ==> 3.36 М / mm?
и современный
Core i7 (ядро Skylake K) 14 нм, 1750 млн, 122 mm? ==> 14.34 М / mm?
Хорошо если 5 кратное увеличение плотности размещения транзисторов с трудом натянется, а вовсе не 12 кратное.
Маркетинговые попугаи они такие маркетинговые…
Вот примерно как более-менее реальный график (что характерно от маркетологов той же самой компании) должен выглядеть:
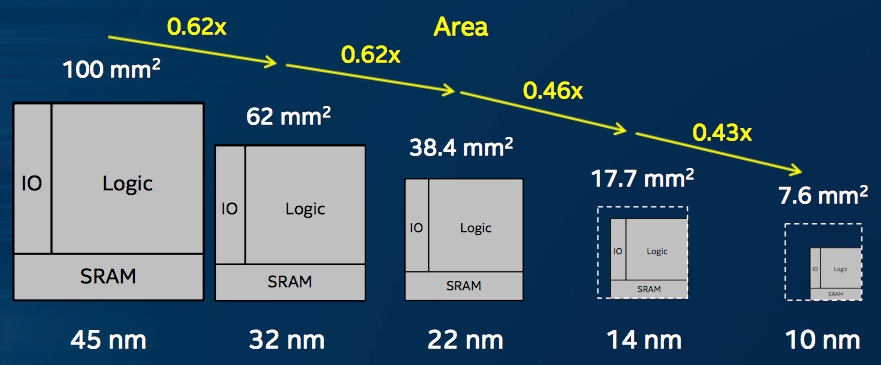
Сокращения площади одного и того же чипа с 100 мм2 до 17.7 мм2. Или 100/17.7 = 5.6 раз увеличения плотности упаковки элементов. Никаких х12 и в помине нет.acmnu
13.12.2018 16:53Я не удивлюсь, если это маркетинг так переводит некий внутренний показатель, который объемный, а не двумерный. Все же элементы не плоские, и даже не кубические, а обладают сложной формой, хотя и выложены в один слой.
Losted
12.12.2018 19:04+3В статье все-таки немного упущено, что AWS начало использование AMD EPYC в новом поколении инстансов (M5, R5).
Singaporian
12.12.2018 23:47-2в угоду этой самой энергоэффективности ARM-чипам приходится отказываться «грубой силы», которой обладают «старшие братья» от той же Intel или AMD
Что? Я может что-то не понимаю?
ARM — это RISC. Он рациональнее делает задачи, разбивая их на примитивы, потому ему и не надо энергии так много, как процессорам на CISC (Intel/AMD), которые километровые инструкции выполняют.
«Грубая сила» — какой-то странный показатель для процессора. При абсолютно равных физических параметрах, ARM будет работать:
- быстрее
- энергоэффективнее.
Nick_Shl
13.12.2018 00:28+4Открою вам секрет: x86 процессоры тоже уже давно RISC, выполняющие только одну программу: эмулирование x86.
Singaporian
13.12.2018 09:29Подробнее?
VioletGiraffe
13.12.2018 13:02ru.wikipedia.org/wiki/%D0%9C%D0%B8%D0%BA%D1%80%D0%BE%D0%BA%D0%BE%D0%B4
Исходные инструкции транслируются процессором в микрокод, и микрокод уже оптимизируется и выполняется. Здесь же можно вспомнить и о том, что у современных х86 процессоров уже давно не 8 регистров общего назначения, а около 150 (меняется от поколения к поколению), и сложные техники register renaming для эффективного распихивания данных из восьми «виртуальных» регистров, которыми оперирует исходная программа, в эти 150 физических.Singaporian
13.12.2018 13:26Я знаю, что такое микрокод.
Речь идет про другое:
"x86 процессоры тоже уже давно RISC, выполняющие только одну программу: эмулирование x86."
Этот момент никак не покрыт в этой статье. Я даже не понял, что человек сказать хотел. Вы поняли? Можете сформулировать это по другому? Увязать x86, регистры и RISC?VioletGiraffe
13.12.2018 13:51+1Микрокодовая архитектура это и есть RISC. Трансляция ISA x86 в микрокод — эмуляция CISC-архитектуры х86 на RISC-железе. Я так понимаю, по крайней мере, если вы так не считаете — давайте обсуждать, мне интересно разобраться.
Singaporian
13.12.2018 14:30Давайте опустимся до деталей.
Есть управляющие регистры и есть теневые регистры. К последним у вас нет доступа программно. Задача микрокода разложить сложную операцию на атомарные. Их может быть много — и тогда используются теневые регистры. Является ли это эмуляцией? Вот не согласен. Это реальные физические регистры, просто они недоступны извне.
Теперь посмотрим на RISC — в современных версиях, например в IV-й, конечно же есть сложные операции, которые надо разложить (и микрокод тут пришел на помощь). То есть когда надо RISC-вые процессоры используют микрокод, а когда можно обойтись без него — не используют.
Теперь CISC. В распоряжении у CISC-процессоров те же регистры. И тот же микрокод. И CISC использует его тоже. Только более широко — все же он тем и отличается от RISC, что у него добавляются сложные инструкции, которые надо раскладывать на примитивы.
Но RISC — это не микрокод. Хотя бы потому, что RISC — это просто список инструкций. Очень абстрактная вещь, которую не потрогать. Другими словами, RISC — это «умеренный подход».
А микрокод — это программа. А еще потому, что есть микрокод без RISC, а есть RISC без микрокода.
Singaporian
13.12.2018 09:15Люди, которые минусуют в карму — если вы не объясняете, за что вы это делаете, очень скоро тут останется одно быдло, а нормальные люди уйдут. Совершенно очевидно, что я один тут разработчик из Intel, а вокруг меня огромная толпа, напичканная стереотипами, готовая стереть любого целой сворой только лишь за альтернативное мнение.
xaoc80
13.12.2018 12:06Вы тут не один разработчик из Интел, это очевидно)
Singaporian
13.12.2018 12:20Это не меняет сути. Лучше не писать ничего. Меня вон за вопрос «Подробнее?» даже заминусовали (и, какая внезапность, ответить по сути ему было нечего).
Тут просто ад какой-то творится. Еще пару неудачных вопросов и я вообще не смогу тут писать. Так что, коллега, извините, не могу тратить свои посты на общение с вами при всем моем желании пообщаться.Am0ralist
13.12.2018 12:45Еще пару неудачных вопросов и я вообще не смогу тут писать.
Это ж насколько нужно неудачные вопросы задавать, чтоб более чем на -40 в карму влететь от ваших 12,2 текущих?Singaporian
13.12.2018 13:27Я думал с нуля писать нельзя.
У меня уже не 12, а 9, кстати.Am0ralist
13.12.2018 14:31+1Из рековери мода сможете написать статью, если что. А при минус 30 вы просто комментарии сможете оставлять раз в сутки.
Не, ну и если совсем плохо станет — обнулить карму один раз можно, но в этом я сомневаюсь, что вам потребуется)
SergeyMax
13.12.2018 14:54ARM — это RISC. Он рациональнее делает задачи, разбивая их на примитивы
В результате получается, что вместо одной инструкции, условно перемножающей два произвольных операнда, вам потребуется выполнить две инструкции для загрузки определённых регистров, затем выполнить инструкцию умножения, а потом по вкусу добить всё инструкциями для раскладывания результатов в нужные места.Singaporian
13.12.2018 15:09Верно. С той лишь разницей, что у CISC дополнительные инструкции — это не тоже самое, что вы привели в пример «условно перемножающей два произвольных операнда». Там очень сложные коплексные инструкции, которые тоже надо разбивать. Только итерация остается одна — а это значит, что нагрузка ложится на работу микрокода, который скрывает реализацию «под капотом».
SergeyMax
13.12.2018 15:30Нет, вы неправильно понимаете суть различий между RISC и CISC. Они в основном отличаются не «дополнительными инструкциями» (хотя конечно и этим тоже), а вариативностью операндов. То есть грубо говоря ARM умеет умножать только два регистра из ограниченного набора, а x86 умножает между собой условно говоря любые регистры, константы, память с косвенной адресацией, и так далее. В результате RISC-код получается раздутым быссмысленными инструкциями предзагрузки регистров, а RISC-процессор для такого кода — получается ну, скажем так, простым в исполнении.
geisha
13.12.2018 02:09+1и новый способ литографии в глубоком ультрафиолете (EUV).
Ага, «новую» технологию планировали выкатить совсем недавно в 2007 году. Новая прям как первый айфон, процессоры Core 2 Duo и премьер Путин.
Stas911
13.12.2018 05:34Дык не для всех задач CPU нужен — если там раз в день получаются результаты и считаются (пока писал коммент понял, что тут вообще проще лямбдами все сделать)
barbos6
13.12.2018 07:21Дык не для всех задач CPU нужен
Да, не зря в старыхбукваряхкнигах писали, что микроЭВМ-ы бывают многоплатные, одноплатные и бесплатные. :)
potan
13.12.2018 14:44a1.large дороже чем t3.medium при одинаковых числе ядер и памяти. Непонятно, почему он позиционируется как дешевый.
ZloyKakPes
13.12.2018 14:53У t3 есть burst по CPU или если его выключить, то надо платить. Так что a1 все равно дешевле будет.
Chamie
14.12.2018 15:47в зависимости от задач 16 ядер Graviton дают производительность на уровне всего 5 интеловских ядер Xeon
Это как? «Значение бывает разным и строго равно пяти»?
altrus
Какой приятный литературный язык…
По поводу «нагрузки на процессор» в сравнении Graviton и Intel — а какой процент задач, из всех крутящихся в AWS, плохо масштабируется и требует именно мощных CPU?
Я думаю, достаточно маленький, чтобы частичный отказ от Intel был ощутимым для обеих сторон.
springimport
Тут какое дело, можно сидеть на интелах и получать загрузку условной страницы за 1 секунду, а можно на arm и довольствоваться в лучшем случае 2-3 секундами. А если брать высокопроизводительные инстансы типа c4 и c5 с частотой под 3ггц то там еще больше разница.
Ради интереса пробовал на 3b+ малине проект. Разница в 3-5 раз по сравнению с сервером и еще больше по сравнению с i7.
altrus
Какая-то странная математика у вас. Вы тогда и учитывайте, что загрузка одной страницы на АРМ будет вам (владельцу приложения) стоить условно доллар, а на Интеле — пять.
Смысл моего комментария был в том, что немалая часть потребителей AWS это простые е-коммерсы и иже с ними, которые переход на АРМ не заметят. Только по цене.
А тот, у кого страница грузится секунду (имеется в виду нагрузка сервера) может и на Интел остаться.
Оптимизация расходов (для Амазон).
springimport
В относительных значений так и выходит, но абсолютных разницы особой нет: что $5 в месяц, что $25.
Может быть для простых сайтов и подойдет, я не тестировал конкретно a1. Уже средние сайты требуют нормального cpu.
Для понимания масштаба экономии: как известно, amd возвращается на рынок предлагая серверные эпики по цене до двух раз меньше чем у конкурента. Для ec2 появляются новые предложение c их процессорами… на 10% дешевле.
Так что я бы особо не надеялся на какое-то удешевление.
lokkiuni
Так помимо процессоров надо ещё и всё остальное, в частности память, которая нынче совесем не 3 копейки стоит.
willyd
Там разница 50%. Что-то я сомневаюсь, что там будет какая-то выгода для обычных клиентов. Если у вас есть возможности и силы протестировать различные конфигурации для каждой роли, и выбрать оптимальное, может вы и получите какую-то выгоду.
bugdesigner
На малине кроме процессора ещё схд на micro-sd, что явно не добавляет производительности, а возможно, является узким местом. Правильно сравнивать северные решения на разных CPU, когда периферия приблизительно одного уровня.
gotozero
Помимо этого, ядра малинки далеко не самые быстрые и по старому техпроцессу сделаны.
Не говоря про кэши и прочие характеристики, которые в малинке не так важны, как важно её удобство для разработки.
springimport
Я для этого прикупил ssd и тупняки исчезли.
Вчера посмотрел arm в aws. Ради интереса выбрал максимальный вариант с 16 ядрами. Могу сказать что по ощущениям быстрее малины, но далеко не х86.
acmnu
Думаю на фоне тормозов js и многомегабайтных страничек время генерации информации на бакенде в большинстве случаев ничтожно.
springimport
Вы ошибаетесь если говорить про мадженту 2. Там все тяжелое, но сам бэк — самый тяж.
Chamie
denisromanenko
nginx с node масштабируются хорошо.
Бизнес-приложения — вряд ли, если кто-то этим очень внимательно не озаботился.
Та же 1С умрёт на 8 ядрах по 2Ghz, но будет хорошо жить на 2-х ядрах по 3.4 Ghz.
Думаю, в AWS крутится немало такого же требовательного к частоте одного ядра корпоративного софта.
Гравитоны для Lightsail пойдут скорее всего.