

В материале, перевод которого мы сегодня публикуем, речь пойдёт об эффективной работе с памятью в среде Node.js. В частности, здесь будут рассмотрены такие концепции, как потоки, буферы и метод потоков
pipe(). В экспериментах будет использован Node.js v8.12.0. Репозиторий с кодом примеров можно найти здесь.Задача: копирование огромного файла
Если кого-нибудь попросят создать в среде Node.js программу для копирования файлов, то он, вероятнее всего, тут же напишет примерно то, что показано ниже. Назовём файл, содержащий этот код,
basic_copy.js.const fs = require('fs');
let fileName = process.argv[2];
let destPath = process.argv[3];
fs.readFile(fileName, (err, data) => {
if (err) throw err;
fs.writeFile(destPath || 'output', data, (err) => {
if (err) throw err;
});
console.log('New file has been created!');
});Эта программа создаёт обработчики для чтения и записи файла с заданным именем и пытается записать данные файла после их прочтения. Для маленьких файлов такой подход оказывается вполне рабочим.
Предположим, что нашему приложению надо скопировать огромный файл (будем считать «огромными» файлы, размер которых превышает 4 Гб) в ходе процесса резервного копирования данных. У меня, например, есть видеофайл размером 7.4 Гб, который я, с помощью вышеописанной программы, попробую скопировать из моей текущей директории в директорию
Documents. Вот команда для запуска копирования:$ node basic_copy.js cartoonMovie.mkv ~/Documents/bigMovie.mkvВ Ubuntu, после выполнения этой команды, было выведено сообщение об ошибке, связанной с переполнением буфера:
/home/shobarani/Workspace/basic_copy.js:7
if (err) throw err;
^
RangeError: File size is greater than possible Buffer: 0x7fffffff bytes
at FSReqWrap.readFileAfterStat [as oncomplete] (fs.js:453:11)Как видно, операция чтения файла не удалась из-за того, что Node.js позволяет считывать в буфер лишь 2 Гб данных. Как преодолеть это ограничение? Выполняя операции, интенсивно использующие подсистему ввода-вывода (копирование файлов, их обработка, сжатие), нужно учитывать возможности систем и ограничения, связанные с памятью.
Потоки и буферы в Node.js
Для того чтобы обойти вышеописанную проблему, нам нужен механизм, с помощью которого можно разбивать большие массивы данных на небольшие фрагменты. Также нам понадобятся структуры данных, позволяющие хранить эти фрагменты и работать с ними. Буфер — это структура данных, которая позволяет хранить двоичные данные. Далее, нам нужно иметь возможность читать фрагменты данных с диска и записывать их на диск. Эту возможность могут дать нам потоки. Поговорим о буферах и потоках.
?Буферы
Буфер можно создать, инициализировав объект
Buffer.let buffer = new Buffer(10); // 10 - это размер буфера
console.log(buffer); // выводит <Buffer 00 00 00 00 00 00 00 00 00 00> В версиях Node.js, новее 8-й, лучше всего, для создания буферов, пользоваться следующей конструкцией:
let buffer = new Buffer.alloc(10);
console.log(buffer); // выводит <Buffer 00 00 00 00 00 00 00 00 00 00>Если у нас уже есть некие данные, вроде массива или чего-то подобного, буфер можно создать на основе этих данных.
let name = 'Node JS DEV';
let buffer = Buffer.from(name);
console.log(buffer) // выводит <Buffer 4e 6f 64 65 20 4a 53 20 44 45 5>У буферов есть методы, которые позволяют «заглядывать» в них и узнавать о том, какие данные там находятся — это методы
toString() и toJSON().Мы, в процессе оптимизации кода, не будем создавать буферы самостоятельно. Node.js создаёт эти структуры данных автоматически, при работе с потоками или сетевыми сокетами.
?Потоки
Потоки, если обратиться к языку научной фантастики, можно сравнить с порталами в другие миры. Существует четыре типа потоков:
- Поток для чтения (из него можно читать данные).
- Поток для записи (в него можно отправлять данные).
- Дуплексный поток (он открыт и для чтения из него данных, и для отправки данных в него).
- Трансформирующий поток (особый дуплексный поток, позволяющий обрабатывать данные, например — сжимать их или проверять их корректность).
Потоки нам нужны из-за того, что жизненно важной целью API потоков в Node.js, и, в частности, метода
stream.pipe(), является ограничение буферизации данных до приемлемых уровней. Делается это для того чтобы работа с источниками и получателями данных, отличающимися разными скоростями обработки данных, не приводила бы к переполнению имеющейся памяти.Другими словами, нам, для решения задачи копирования большого файла, нужен какой-то механизм, позволяющий не перегружать систему.
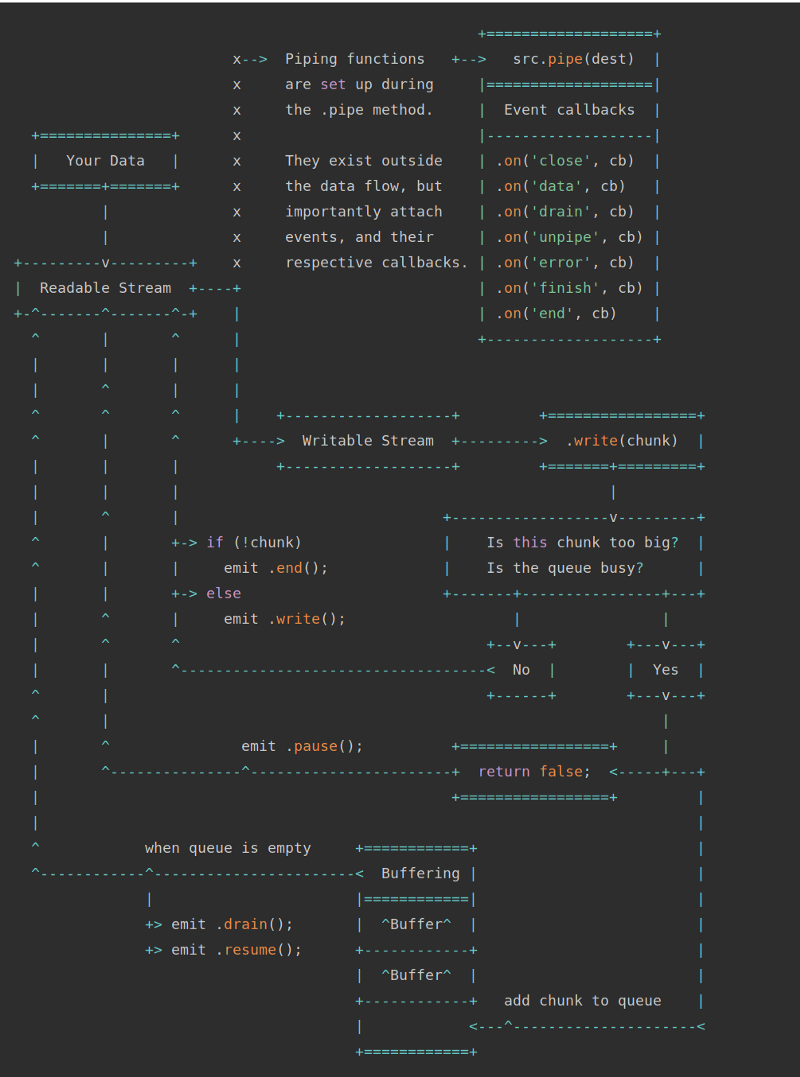
Потоки и буферы (по материалам документации Node.js)
На предыдущей схеме показаны два типа потоков — потоки для чтения (Readable Streams) и потоки для записи (Writable Streams). Метод
pipe() — это очень простой механизм, позволяющий прикреплять потоки для чтения к потокам для записи. Если вам пока вышеприведённая схема не особенно понятна — ничего страшного. После разбора нижеследующих примеров вы легко с ней разберётесь. В частности, сейчас мы рассмотрим примеры обработки данных с использованием метода pipe().Решение 1. Копирование файлов с использованием потоков
Рассмотрим решение проблемы копирования огромного файла, о которой мы говорили выше. Это решение может быть основано на двух потоках и будет выглядеть следующим образом:
- Мы ожидаем появления очередного фрагмента данных в потоке для чтения.
- Записываем полученные данные в поток для записи.
- Отслеживаем ход операции копирования.
Назовём программу, реализующую эту идею,
streams_copy_basic.js. Вот её код:/*
Копирование файлов с использованием потоков и событий. Автор: Naren Arya
*/
const stream = require('stream');
const fs = require('fs');
let fileName = process.argv[2];
let destPath = process.argv[3];
const readable = fs.createReadStream(fileName);
const writeable = fs.createWriteStream(destPath || "output");
fs.stat(fileName, (err, stats) => {
this.fileSize = stats.size;
this.counter = 1;
this.fileArray = fileName.split('.');
try {
this.duplicate = destPath + "/" + this.fileArray[0] + '_Copy.' + this.fileArray[1];
} catch(e) {
console.exception('File name is invalid! please pass the proper one');
}
process.stdout.write(`File: ${this.duplicate} is being created:`);
readable.on('data', (chunk)=> {
let percentageCopied = ((chunk.length * this.counter) / this.fileSize) * 100;
process.stdout.clearLine(); // очистить текущий текст
process.stdout.cursorTo(0);
process.stdout.write(`${Math.round(percentageCopied)}%`);
writeable.write(chunk);
this.counter += 1;
});
readable.on('end', (e) => {
process.stdout.clearLine(); // очистить текущий текст
process.stdout.cursorTo(0);
process.stdout.write("Successfully finished the operation");
return;
});
readable.on('error', (e) => {
console.log("Some error occurred: ", e);
});
writeable.on('finish', () => {
console.log("Successfully created the file copy!");
});
});Мы ожидаем, что пользователь, запуская эту программу, предоставит ей два имени файла. Первое — это файл-источник, второе — имя его будущей копии. Мы создаём два потока — поток для чтения и поток для записи, перенося фрагменты данных из первого во второй. Тут имеются и некоторые вспомогательные механизмы. Они используются для наблюдения за процессом копирования и для вывода соответствующих сведений в консоль.
Мы пользуемся здесь механизмом событий, в частности, речь идёт о подписке на следующие события:
data— вызывается при чтении фрагмента данных.end— вызывается при окончании чтения данных из потока для чтения.error— вызывается в случае возникновения ошибки в процессе чтения данных.
С помощью этой программы файл размером 7.4 Гб копируется без сообщений об ошибках.
$ time node streams_copy_basic.js cartoonMovie.mkv ~/Documents/4kdemo.mkvОднако тут есть одна проблема. Её можно выявить, если взглянуть на данные по использованию системных ресурсов различными процессами.
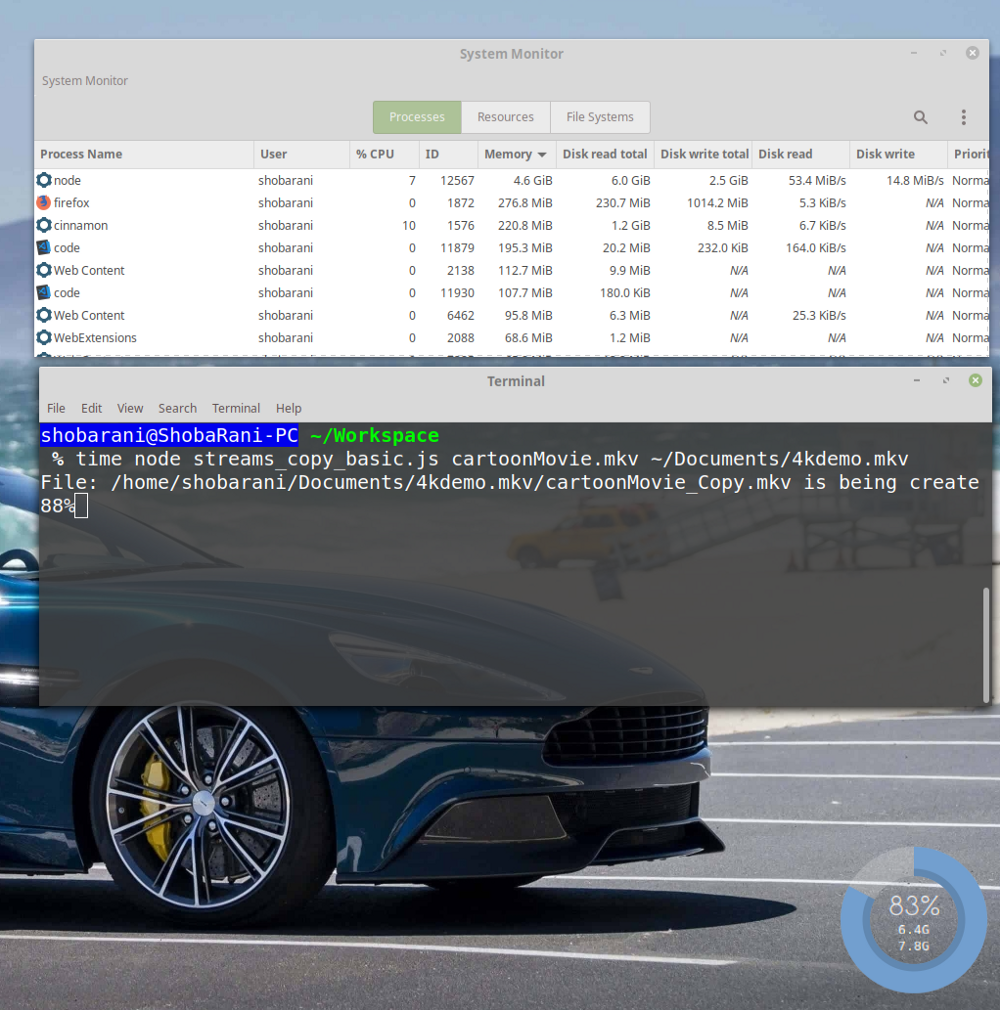
Данные об использовании системных ресурсов
Обратите внимание на то, что процесс
node, выполнив копирование 88% файла, занимает 4.6 Гб памяти. Это очень много, такое обращение с памятью способно помешать работе других программ.?Причины чрезмерного потребления памяти
Обратите внимание на скорости чтения данных с диска и записи данных на диск с предыдущей иллюстрации (колонки
Disk Read и Disk Write). А именно, тут можно видеть следующие показатели:Disk Read: 53.4 MiB/s
Disk Write: 14.8 MiB/sТакая разница в скоростях чтения из записи данных означает, что источник данных выдаёт их гораздо быстрее, чем приёмник может их принять и обработать. Компьютеру приходится хранить в памяти прочитанные фрагменты данных до момента их записи на диск. Как результат, мы и видим такие показатели использования памяти.
На моём компьютере эта программа выполнялась 3 минуты 16 секунд. Вот сведения о ходе её выполнения:
17.16s user 25.06s system 21% cpu 3:16.61 totalРешение 2. Копирование файлов с использованием потоков и с автоматической настройкой скорости чтения и записи данных
Для того чтобы справиться с вышеописанной проблемой, мы можем модифицировать программу так, чтобы в ходе копирования файлов скорости чтения и записи данных настраивались бы автоматически. Этот механизм называют back pressure. Для того чтобы его задействовать, нам не нужно делать ничего особенного. Достаточно, с помощью метода
pipe(), подключить поток для чтения к потоку для записи, а Node.js автоматически настроит скорости передачи данных.Назовём эту программу
streams_copy_efficient.js. Вот её код:/*
Копирование файлов с использованием потоков и метода pipe(). Автор: Naren Arya
*/
const stream = require('stream');
const fs = require('fs');
let fileName = process.argv[2];
let destPath = process.argv[3];
const readable = fs.createReadStream(fileName);
const writeable = fs.createWriteStream(destPath || "output");
fs.stat(fileName, (err, stats) => {
this.fileSize = stats.size;
this.counter = 1;
this.fileArray = fileName.split('.');
try {
this.duplicate = destPath + "/" + this.fileArray[0] + '_Copy.' + this.fileArray[1];
} catch(e) {
console.exception('File name is invalid! please pass the proper one');
}
process.stdout.write(`File: ${this.duplicate} is being created:`);
readable.on('data', (chunk) => {
let percentageCopied = ((chunk.length * this.counter) / this.fileSize) * 100;
process.stdout.clearLine(); // очистить текущий текст
process.stdout.cursorTo(0);
process.stdout.write(`${Math.round(percentageCopied)}%`);
this.counter += 1;
});
readable.on('error', (e) => {
console.log("Some error occurred: ", e);
});
writeable.on('finish', () => {
process.stdout.clearLine(); // очистить текущий текст
process.stdout.cursorTo(0);
process.stdout.write("Successfully created the file copy!");
});
readable.pipe(writeable); // Включаем автопилот!
});Основное отличие этой программы от предыдущей заключается в том, что код для копирования фрагментов данных заменён на следующую строку:
readable.pipe(writeable); // Включаем автопилот!В основе всего того, что тут происходит, лежит метод
pipe(). Он контролирует скорости чтения и записи, что приводит к тому, что память теперь не оказывается перегруженной.Запустим программу.
$ time node streams_copy_efficient.js cartoonMovie.mkv ~/Documents/4kdemo.mkvМы копируем тот же самый огромный файл. Теперь посмотрим на то, как выглядит работа с памятью и с диском.
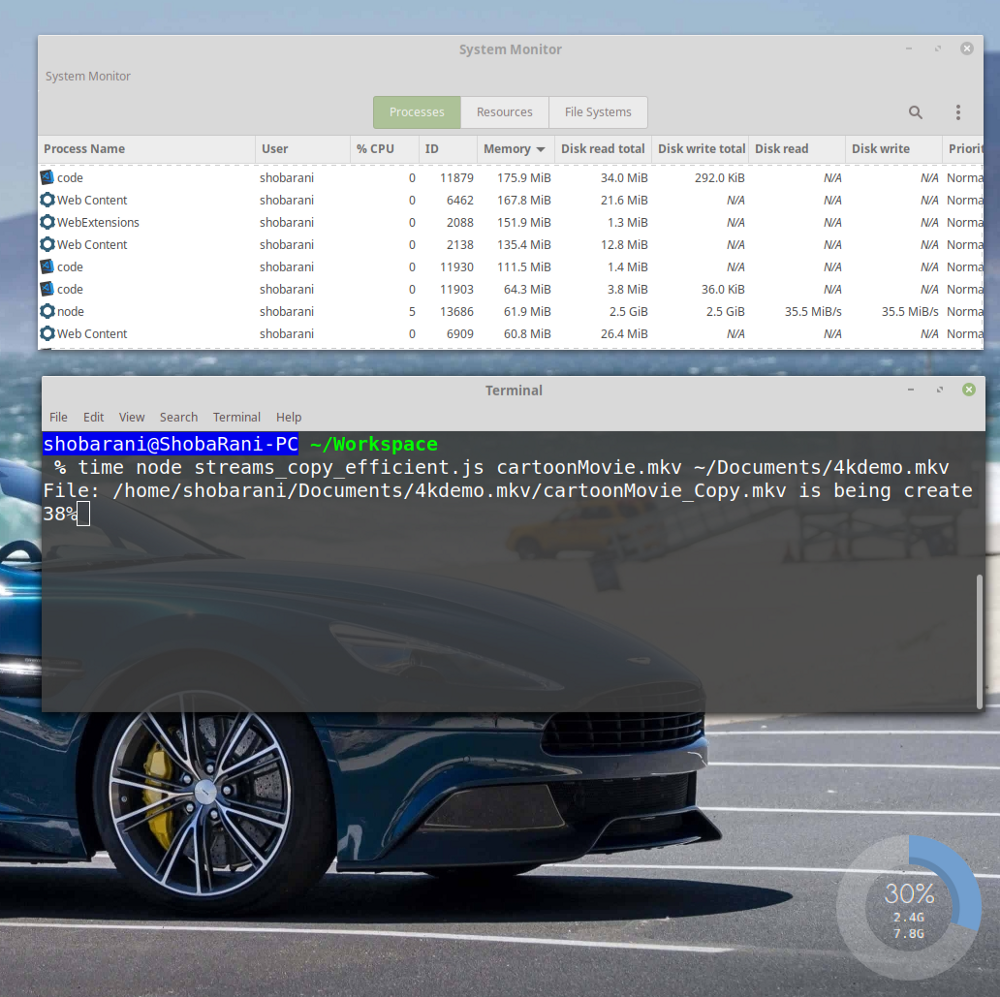
Благодаря использованию pipe() скорости чтения и записи настраиваются автоматически
Теперь мы видим, что процесс
node потребляет всего 61.9 Мб памяти. Если же взглянуть на данные по использованию диска, то можно увидеть следующее:Disk Read: 35.5 MiB/s
Disk Write: 35.5 MiB/sБлагодаря механизму back pressure скорости чтения и записи теперь всегда равны друг другу. Кроме того, новая программа выполняется на 13 секунд быстрее старой.
12.13s user 28.50s system 22% cpu 3:03.35 totalБлагодаря использованию метода
pipe() нам удалось уменьшить время выполнения программы и снизить потребление памяти на 98.68%.В данном случае 61.9 Мб — это размер буфера, создаваемый потоком чтения данных. Мы вполне можем задать этот размер самостоятельно, воспользовавшись методом
read() потока для чтения данных:const readable = fs.createReadStream(fileName);
readable.read(no_of_bytes_size);Здесь мы копировали файл в локальной файловой системе, однако тот же подход можно использовать и для оптимизации многих других задач ввода-вывода данных. Например — это работа с потоками данных, источником которых является Kafka, а приёмником — база данных. По такой же схеме можно организовать чтение данных с диска, их сжатие, что называется, «на лету», и запись обратно на диск уже в сжатом виде. На самом деле, можно найти и множество других вариантов применения описанной здесь технологии.
Итоги
Одной из целей написания этой статьи была демонстрация того, как легко можно писать плохие программы на Node.js, даже несмотря на то, что эта платформа предоставляет в распоряжение разработчика замечательные API. Уделив некоторое внимание этим API, можно улучшить качество серверных программных проектов.
Уважаемые читатели! Как вы работаете с буферами и потоками в Node.js?

Комментарии (11)

little-brother
19.12.2018 16:04Для русской аудитории данный вопрос уже давно прекрасно раскрыл Илья Кантор в своем скринкасте по Node.js (уроки 23-26).
Ожидал увидеть что-то другое, нежели о копировании файлов.bro-dev0
20.12.2018 01:33Ненавижу сайты где не пишут дату публикации, тут 2013 у меня минута целая ушла, чтобы найти, и учитывая что нода появилась в 2009, это для неё доисторический период.
jehy
19.12.2018 17:45Хоть бы была приписка о том, что пример синтетический, и копировать файлы таким образом нельзя ни в коем случае. А то ж код потащат в проекты…
kalyukdo
19.12.2018 21:42Еще бы сноску добавить: «прежде чем писать свой велосипед, почитайте доку по работе nodejs там уже много чего есть»
nodejs.org/dist/latest-v11.x/docs/api/fs.html#fs_fs_copyfile_src_dest_flags_callback
может копировать откуда угодно и куда угодноfunca
20.12.2018 01:32Справедливости ради, эта функция реализует весьма специфическую логику и подойдет не в каждой ситуации. Тут есть перевод эпичного чеклиста про копирование файла в общем случае https://m.habr.com/post/301924/.
taliban
20.12.2018 20:56Умнички, цепляться на реализацию копирования в статье про работу с памятью. Я поражаюсь людьми, которые даже не удосужились понять суть статьи, но зато свои 5 копеек обязательно вставить умудряются, профессионалы ведь, доку выучили, а там копирование по другому описано!
kalyukdo
21.12.2018 01:19за реализацию никто не цепляется, просто люди насмотрятся такого, потом в реальные проекты без надобности тащат велосипеды, а потом приходишь на проект, а там ни доки, ни велосипедистов, и не понятно как это все работает, а писать свои велосипеды вместо тех решений которые предлагает сам язык (или система), по мне так не оправданное дело за исключением ситуации в комментарии выше :), пишите сразу уже на своем языке, зато доку не нужно будет учить
ReklatsMasters
Тема хорошая, но как всегда, странные примеры.
Это вообще лучше забыть как страшный сон и не упоминать даже. Так делать больше нельзя.
Должно быть
Buffer.alloc(10);. Ошибка при копировании видимо, но лично у меня глаз сразу цепляется.Я не знаю, что тут хотел сказать автор. Чем по его мнению должен был являться
this? В данном случае это глобальный объект. А добавлять свойства ни в глобал, ни в какие-то объекты ноды не нужно. Обычныйlet/constподошёл бы идеально.Также можно было бы рассказать про
fs.copyFile, который как раз в 8й ноде появился и про параметрhighWaterMark, который позволяет размер чанка настроить.V1tol
Казалось бы — статья про Node.js и streams. Почему для серверной платформы выбран пример с копированием локального файла? Ведь самый подходящий пример — это скачивание большого файла по http и сохранение его на диск с помощью стримов. Или наоборот — отдача локального файла по http. Сразу всем понятно, для чего это, какая от этого польза и новички могут даже скопипастить себе код в свой проект на экспрессе.
Inflight
Этот пример проще самому протестировать у себя на компьютере, например. А адаптировать его для других целей не так уж и сложно.