
Некоторое время назад я начал понимать необходимость разнообразить мой опыт программирования исключительно на C#. После некоторого изучения различных вариантов, таких как Haskell, Scala, Rust и некоторых других, выбор пал на последний. Со временем я начал обращать внимание, что Rust всё больше и больше рекламируется исключительно как "системный язык", который нужен для вырвиглазно сложных компиляторов и супер-нагруженных систем, с особыми требованиями к безопасности и многопоточности, а для вариантов попроще есть Go/Python/Java/..., в то время как я с удовольствием и весьма успешно использовал его как замену моей рабочей лошадке C#.

В этой статье я хотел рассказать, почему я считаю этот тренд в целом вредным, и почему Rust является хорошим языком общего назначения, на котором можно делать любые проекты, начиная со всяких микросервисов, и заканчивая скриптованием ежедневной рутины.
Введение
Зачем, собственно, учить новый язык, тем более сложный? Мне кажется, что ближе всего к истине ответ статьи "Побеждая посредственность", а именно:
Каждый знает, что писать всю программу вручную на машинном языке — ошибочно. Но гораздо реже понимают то, что существует и более общий принцип: при наличии выбора из нескольких языков ошибочно программировать на чем-то, кроме самого мощного, если на выбор не влияют другие причины.
Чем сложнее язык, тем богаче фразы, составленные с его помощью, и тем лучше он может выразить требуемую предметную область. Т.к. концепции обычно изучаются единожды, а применяются многократно, намного выгоднее с точки зрения вложения собственного времени изучить всякие страшные слова вроде "монадические трансформеры" (а еще, желательно, их смысл), чтобы потом экономить свои ментальные силы и тратить их на что-то более приятное. И поэтому весьма грустно видеть тренд некоторых компаний делать специально "упрощенные" языки. В итоге словарь этих языков намного меньше, и выучить его не составляет особого труда, но читать потом программы "моя твоя покупать лук" весьма тяжело, не говоря про возможные неоднозначные трактовки.
Основы
Как обычно новичок знакомится с языком программирования? Он гуглит самую популярную книжку по языку, достаёт её, и начинает читать. Как правило, там содержится HelloWorld, инструкция по установке компилятора, а дальше базовая информация по языку с постепенным усложнением. В случае раста, это растбук, а первым примером является чтение числа из консоли и вывод его на экран. Как бы мы это сделали в том же C#? Ну наверное как-то так
var number = int.Parse(Console.ReadLine());
Console.WriteLine($"You guessed: {number}");А что у нас в расте?
let mut guess = String::new();
io::stdin().read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse()
.expect("Please type a number!");
println!("You guessed: {}", guess);Утроенное количество кода, все эти реверансы с созданием переменной перед использованием (привет Паскаль!), вызовом кучи вспомогательного кода, и т.п. "Что за ужас" подумает среднестатистический разработчик и в очередной раз убедится в "системности" языка.
А ведь на самом деле это можно написать существенно проще:
let mut guess = String::new();
io::stdin().read_line(&mut guess)?;
let guess: u32 = guess.trim().parse()?;
println!("You guessed: {}", guess);Всё еще остается отдельное создание переменной и чтение в неё из потока, но тут уже накладывает отпечаток идеология раста, что выделение буфера он перекладывает на пользователя. Сперва непривычно, но потом понимаешь, что с ответственностью приходит и соответствующая сила. Ну а для тех, кто не парится, всегда есть опция написать трёхстрочную функцию и забыть этот вопрос раз и навсегда.
Почему пример в книжке составлен таким образом? Скорее всего из-за того, что объяснение обработки ошибок происходит сильно позже, а игнорировать их как в случае с C# не позволяет парадигма раста, который контролирует все возможные пути, где что-то может пойти не так.
Лайфтаймы и борроучекер
Ох уж эти страшные звери. Люди бросаются непонятными заклинаниями навроде
fn search<F>(self, hash: u64, is_match: F, compare_hashes: bool)
-> RawEntryMut<'a, K, V, S>
where for<'b> F: FnMut(&'b K) -> boolНовички в панике бегут, ребята из го говорят "мы же вас предупреждали про ненужную сложность", хаскеллисты говорят "столько сложности для языка, в котором даже эффектов нет", а джависты крутят пальцем у виска "стоило ли огород городить, чтобы только от GC отказаться".
На деле же при написании прикладной программы вам скорее всего не понадобится указывать ни одного лайфтайма вообще. Причина этого в том, что в расте есть правила вывода лайфтаймов, которые почти всегда компилятор может выставить сам. Вот они:
- Each elided lifetime in input position becomes a distinct lifetime parameter.
- If there is exactly one input lifetime position (elided or not), that lifetime is assigned to all elided output lifetimes.
- If there are multiple input lifetime positions, but one of them is &self or &mut self, the lifetime of self is assigned to all elided output lifetimes.
- Otherwise, it is an error to elide an output lifetime.
Или, если в двух словах, в случае статических функций время жизни всех аргументов полагаются равными, в случае инстансных методов время жизни всех результирующих ссылок полагается равным времени жизни инстанса, на котором мы вызываем метод. И на практике это почти всегда соблюдается в случае прикладного кода. Поэтому, там вы вместо ужаса выше обычно будете писать что-то вроде
struct Point(i32, i32);
impl Point {
pub fn get_x(&self) -> &i32 {
&self.0
}
pub fn get_y(&self) -> &i32 {
&self.1
}
}И компилятор сам с радостью выведет всё, что нужно, чтобы это работало.
Лично я вижу прелесть концепции в автоматическом управлении в нескольких аспектах
- с точки зрения человека с опытом программирования на языке с GC память не является отдельным видов ресурсов. В C# есть целая история с интерфейсом
IDisposable, который используется для детерминированной очистки ресурсов, именно потому, что GC удаляет объект "когда то там", а нам может потребоваться освободить ресурс немедленно. В итоге есть целый ворох следствий: и про правильную реализацию финализаторов надо не забыть, и целое ключевое слово для этого было введено (как и try-with-resources в Java), и компилятор перелопатить, чтобы генерировал foreach с учетом этого… Унификация всех видов ресурсов, которые освободятся автоматически, и максимально быстро после последнего использования это очень приятно. Открыл себе файл, и работаешь с ним, он закроется когда нужно без всяких скоупингов. Сразу отвечу на потенциальное возражение, что DI контейнеры несколько облегчают жизнь, но не решают всех вопросов - с точки зрения человека с опытом программирования на языке с ручным управлением, в 99% случаев не надо использовать умные указатели, достаточно использовать обычные ссылки.
В итоге, код получается чистый (как в языке с GC), но в то же время все ресурсы освобождаются максимально быстро (как в языке с ручным управлением). А лайфтайм: декларативное описание ожидаемого времени жизни объекта. А декларативное описание всегда лучше, чем императивное "освободи объект здесь".
Жестокий компилятор
Некоторое следствие предыдущего пункта. Есть хорошая картинка, она в целом описывает многие языки, но нарисованна конкретно для случая раста:
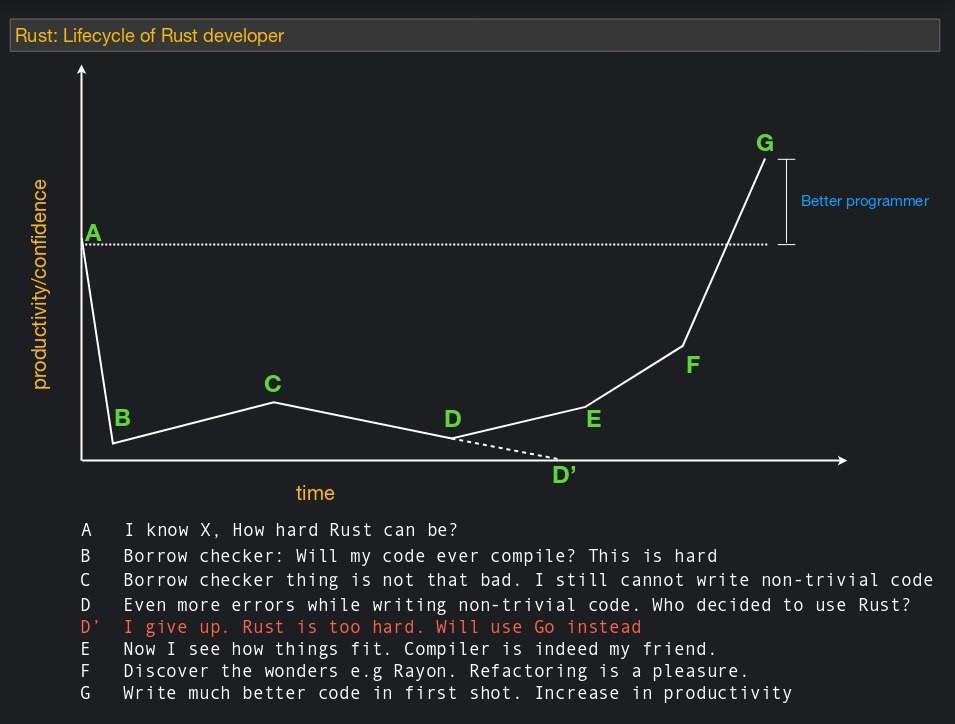
На самом деле компилятор действительно довольно придирчивый. Особенно это было верно до появления Rust 2018, когда компилятор в некоторых случаях не пропускал совершенно очевидно правильный код. Но и сейчас возникают проблемы, особенно от непонимания концепции владения. Например, когда человек пытается реализовать двусвязный список. При наивной реализации он сначала попробует сделать
pub struct Node {
value: u64,
next: Option<Box<Node>>,
prev: Option<Box<Node>>,
}Компилятор скомпилирует объявление этой структуры, но воспользоваться ей не получится, т.к. Box<Node> является владеющей ссылкой, или unique_ptr в терминах C++. А уникальная ссылка, конечно же, может быть только одна
Следующая попытка человека может выглядеть так:
pub struct Node {
value: u64,
next: Option<&Box<Node>>,
prev: Option<&Box<Node>>,
}Теперь у нас есть невладеющие ссылки (они же shared_ptr), и их может быть сколько угодно на один объект. Но тут возникает две проблемы: во-первых владелец должен где-то быть. А значит мы скорее всего получим кучу ошибок компиляции "владелец умер, когда кто-то ссылался на его данные", потому как dangling pointers раст не допускает. А во-вторых, что важнее, мы не сможем изменять эти значения, из-за правил раста "либо одна мутабельная ссылка, либо произвольное количество иммутабельных, и никак иначе".
После этого человек обычно начинает биться о клавиатуру, и писать статьи что "в расте даже связный список реализовать нормально не получится". Реализовать же его, конечно, можно, но немного сложнее чем в других языках, придется руками добавить подсчёт ссылок (примитивы Rc/Arc/Cell/RefCell), чтобы рантайме подсчитывать количество этих самых ссылок, потому что компилятор в данной ситуации бессилен.
Причины этого: эта структура данных плохо ложится на концепцию владения раста, вокруг построен весь язык и экосистема в целом. Любые структуры данных, где необходимо наличие нескольких владельцев потребуют некоторых приседаний, например реализация всевозможных лесов/деревьев/графов или тех же связных списков. Но это верно для всех языков программирования: попытки реализовать своё управление памятью в языках с GC приводит к страшным монстрам, работающих через WeakReferences с гигантскими byte[] массивам, воскрешающие объекты в деструкторах, чтобы вернуть их в пул, и прочей страшной некромантией. Попытки уйти от динамической природы JS, чтобы написать производительный код, приводит к еще более странным вещам.
Таким образом, в любом языке программирования есть своя "болевая точка", и в случае раста, это структуры данных с многими владельцами. Но, если мы смотрим с прикладной точки зрения высокоуровневых программистов, наши программы устроенны как раз таким образом. Например, в моем окружении типовое приложение выглядит как некоторый слой контроллеров, которые шарят между собой сервисы. Каждый сервис имеет ссылку на какие-то репозитории, которые возвращают какие-то объекты. Всё это отлично укладывается в концепцию ownership'а. И если учесть, что на практике основными структурами данных являются списки, массивы и хэшмапы, то оказывается, что всё не так уж и плохо.
Что же делать с этим зверем
На самом же деле компилятор изо всех сил пытается помочь. Сообщения об ошибках в расте, наверное, наиболее приятные из всех языков программирования, с которыми я работал.
Например, при попытке использовать первый вариант нашего связного списка выполучите сообщение
error[E0382]: assign to part of moved value: `head`
--> src\main.rs:23:5
|
19 | prev: Some(Box::new(head)),
| ---- value moved here
...
23 | head.next = Some(Box::new(next));
| ^^^^^^^^^ value partially assigned here after move
|
= note: move occurs because `head` has type `Node`, which does not implement the `Copy` traitОн говорит как раз о том, что мы передали владение ссылкой одному элементу, и уже не можем его использовать повторно. Также он нам рассказывает, что есть некий Copy трейт, который позволяет вместо перемещения объекта производить его копирование, из-за чего его использовать после "перемещения", потому что переместили мы копию. Если вы не знали про его существование, то ошибка компиляции снабдит вас информацией для размышления "А может стоит добавить реализацию этого трейта?".
Вообще, раст для меня первый язык, в котором есть compiler-driven development. Вы просто запускаете компиляцию, если что-то не работает, язык просто скажет вам "хмм, что-то не сходится. Я думаю, проблема в Х. Попробуй добавить вот этот код, и всё заработает". Типовой пример, допустим мы написали две функции, и забыли добавить ограничение на генерик:
fn foo<T: Copy>() {
}
fn bar<T>() {
foo::<T>();
}Компилируем, получаем ошибку:
error[E0277]: the trait bound `T: std::marker::Copy` is not satisfied
--> src\main.rs:6:5
|
6 | foo::<T>();
| ^^^^^^^^ the trait `std::marker::Copy` is not implemented for `T`
|
= help: consider adding a `where T: std::marker::Copy` bound
note: required by `foo`
--> src\main.rs:1:1
|
1 | fn foo<T: Copy>() {
| ^^^^^^^^^^^^^^^^^
error: aborting due to previous errorКопипастим where T: std::marker::Copy из сообщения об ошибке, компилируем, всё готово, поехали в прод!
Да, IDE всех современных языков умеют это делать через всякие сниппеты, но во-первых тут польза в том, что вы видите, из какого крейта/неймспейса прилетело ограничение, а во-вторых это поддержка всё же со стороны компилятора, а не IDE. Это очень помогает при кросс-платформенной разработке, когда у вас локально всё собирается, а на некоторой матрице на CI сервере где-то что-то падает из-за условной компиляции. На билд-сервере IDE нет, а так лог глянул, подставил, и всё собралось. Удобно.
Я писал некоторое время назад телеграм-бота на расте, в качестве тренировки языка. И у меня был момент, где я решил отрефакторить всё приложение. Я заменил всё, что хотел, а потом в течение получаса пытался собрать проект, и вставлял предложения от компилятора тут и там. По прошествии этого времени всё собралось и заработало с первого раза.
Ну и могу сказать, что по прошествии года с того момента как я впервые начал на расте писать, я научился писать простые сниппеты без ошибок с первого раза. Звучит смешно, особенно для людей с динамических ЯП, но для меня это был серьезный прогресс. А еще за всё время работы с растом я дебаг включал ровно два раза. И в обоих случаях я дебажил FFI с С++ кодом, который сегфолтился. Растовый код у меня либо работал правильно, либо не собирался. В случае с C# у меня уверенность сильно ниже, я все время думаю "а не придет ли тут null", "а не будет ли тут KeyNotFoundException", "правильно ли я синхронизировал доступ к этим переменным из многих потоков", и т.п. Ну а в случае с JS (когда я фуллстечил и писал фронт в том числе) после каждого изменения следовала обязательная проверка в браузере, что там изменилось.
Уверенность в том, что собралось == работает действительно имеет место. Это не значит, что в коде нет багов, это значит, что все баги связаны с логикой приложения. У вас нет неожиданных нуллов, несихнронизированного доступа, buffer overflow и так далее. А их намного легче отловить, а иногда можно вынести на уровень типов (хорошая статья на тему).
Итого
Раст — отличный язык для написания абсолютно любых приложений, а не только высоконагруженных бирж, блокчейнов и трейдинговых ботов. Всегда вместо передачи ссылки можно просто скопировать значение. Да-да, возможно, растовчане закидают меня камнями, но в в паре мест моего бота я вместо того, чтобы силиться объяснить компилятору, что переменную можно спокойно расшарить, я её клонировал, и передавал копию. Да, это не так классно, но у меня нет цели написать максимально производительное приложение, как нет такой цели у людей, пользующихся C#/Java/Go/… Я хочу быть максимально продуктивным, и получить приложение с приемлемой скоростью. Реализовать приложение на расте по всем канонам, исключив все ненужные копирования — весьма непростая задача. Но написать приложение за то же время, что и на своём любимом языке, и получить еще и бесплатный прирост производительности — очень даже реально.
Попробуйте написать приложение на расте. Если у вас не получается пройти борроучекер, проверьте ваши структуры данных и их взаимосвязи, потому что я постепенно начал понимать, что борроучекер это не просто механизм, отвечающий за возможность освобождения памяти, но и отличный детектор правильности архитектуры приложения, из разряда "хей, а почему это объект Х зависит от У, я этого не предполагал!". Если же вы всё понимаете, но объяснять борроучекеру правильный ответ слишком сложно, просто скопируйте значение. Скорее всего, вы все равно получите приложение, работающее намного быстрее (если вы пишете на Java/C#/..., как я), либо намного стабильнее (если вы пишете на С/С++), за то же самое время, которое вы бы обычно затратили.
Концепции раста очень мощные, и отлично работают на уровне прикладных приложений, которые не задумываются о производительности, но скорее только о продуктивности разработчиков, скорости внедрения новых фич и простоты поддержки. Очень грустно наблюдать, что такой отличный во всех отношениях язык всё больше получает клеймо "странного и сложного языка для низкоуровневых гиковских задач". Надеюсь, я немного пошатнул этот вредный миф, и в мире станет на сколько-то более продуктивных и счастливых разработиков больше.
Комментарии (279)
SQReder
26.12.2018 11:03+4С душой написано, спасибо. Пожалуй, на праздниках попробую-таки раст.

mapron
26.12.2018 14:43+2Да, я как С++-разработчик, получил удовольствие) Именно так и должны выглядеть пропагандистские статьи ;)
san-smith
26.12.2018 18:49+2Прямо озвучили мои мысли. Собрался на праздники в места далекие от интернетов и решил, раз уж такое дело, затариться литературой по расту.
А автору — благодарность за труды.
aikixd
26.12.2018 14:36+2Хотел этот вопрос задать в интернетах, но раз уж такая пляска, спрошу тут:
Вчера писал калькулятор на расте. Суть в том, что можно написать "2 + 2", он это отпарсит и вернет ответ. Я сделал это по привычке на ООП: для выбора действия, я сделал трейт Operation с единственным методом run(i32, i32) -> i32. Сделал структуры с этим трейтом (самы структуры получились пустыми, в них нет состояния) и положил их в словарь в виде трейт объектов, которые дергаются по требованию.
У меня, однако, есть подозрение что это не идиоматично для раста. Я думал использовать функции вместо трейта, но это будет работать лишь в этом частном случае, поскольку у операций нет состояния. Если нужно будет сохранять состояние все равно придется делать структуры, поскольку раст не поддерживает каррирование.
PsyHaSTe Автор
26.12.2018 14:54+3Ну, полагаю, rust-way более функциональный в данном случае. Там, где в ООП вы делаете абстрактный класс и кучу наследников, в ФП вы делаете один энум и матчите его в тех местах, где вам нужно. Где-то это дает выигрыш, где-то нет, это известная проблема выражения.. И для раста это выходит более естественно, чем прямой перенос ООП опыта. Я в серьезных крейтах трейт-объектов вообще не встречал, динамическая диспетчеризация используется очень редко.
Вот пример крейта, построенного достаточно идеоматично: https://github.com/z2oh/sexe/blob/master/sexe-expression/src/lib.rs
0xd34df00d
26.12.2018 18:40ФП эту проблему отлично решает через object algebras, кстати. На тайпклассах одно удовольствие потом с этим работать.
А, ну ниже про tagless final написали.
Antervis
26.12.2018 20:48Там, где в ООП вы делаете абстрактный класс и кучу наследников, в ФП вы делаете один энум и матчите его в тех местах, где вам нужно
так это же по сути «смешать код в кучу» вместо инкапсуляции?PsyHaSTe Автор
26.12.2018 20:52Не совсем, просто подход иной.
К слову, в ООП этот паттерн называется "Visitor", и используется в случаях известного множества классов чуть чаще, чем всегда. Поэтому если вы работали с AST, например, и писали VisitConstant/VisitBlock/VisitCondition/..., то это оно и есть.
BlessMaster
26.12.2018 15:06+3К комментарию выше я бы добавил, что есть два варианта: Вы заранее знаете всё множество операций, оно статично и не будет меняться по ходу дела (и тогда enum дёшево и надёжно решает задачу), либо Вы заранее не знаете, оно будет зависеть от пользователя Вашей библиотеки или ещё как-то динамически изменяться (тогда Ваш подход с трейт-объектами, хоть он и дороже, — лучше решает задачу).
К слову сказать, в Расте есть замыкания (которые "под сахаром" на самом деле тоже структуры).
nexmean
26.12.2018 15:30+5У вашего варианта есть фатальный недостаток. Что если вам понадобятся унарные или тринарные операции?
В функциональных языках есть один очень популярный паттерн — интерпретатор. Реализуется он обычно либо при помощи tagless final кодирования выражений, либо при помощи GADT. GADT в Rust нету, а вот простенький tagless final мы можем сделать используя трейты.
Можно объявить трейт Expression
trait Expression { fn add(&self, right: &Self) -> Self; fn sub(&self, right: &Self) -> Self; fn negate(&self) -> Self; fn eq(&self, right: &Self) -> Bool; }
И сделать для него конкретные реализации, каждая реализация будет конкретным интерпретатором. Например одна реализация будет возвращать строку для вывода, вторая считать результат выражения, третья просто дублировать значение для того, что-бы одно выражение превратить в два выражения, с разными типами.
Для расширения
Expressionможно использовать "наследование" трейтов (хотя в большинстве случаев будет проще и лучше запихать операцию в изначальный трейт):
trait ExpressionMul : Expression { fn mul(&self, right: &Self) -> Self; }
Для удобства потом можно сделать функции, которые будут фиксировать тип в нужном месте.
fn eval(i: i64) -> i64 { i } fn stringify(s: String) -> String { s } fn double<E1: ExpressionMul, E2: ExpressionMul>(pair: (E1, E2)) -> (E1, E2) { pair }PsyHaSTe Автор
26.12.2018 15:53+2Дополню про tagless final хорошей статьей, которая объясняет, как именно этот подход решает упомянутую проблему выражения, примеры на хаскелле и джаве.
freecoder_xx
26.12.2018 15:40Использовать трейты и структуры — вполне себе идиоматично. А вот трейт-объектов старайтесь избегать: применяйте их только там, где действительно другие способы не работают.
khrundel
27.12.2018 07:04Прошу прощения за занудство, но вы решаете задачу неправильно и на ООП языке. Вычисление выражения с учётом приоритета операций и скобок не требует постройки деревьев, один довольно простой стековый автомат нужен чтоб преобразовать это выражение в бесскобочную обратную польскую запись например «a + b*c» -> «a b c * +», а "(a + b)*c" -> «a b + c*». Вычисление выражения, записанного в обратной польской записи реализуется на стековом автомате ещё проще. Можно объединить и получить автомат с 2мя стеками, который считает прямо. Стеки в расте есть.
aikixd
27.12.2018 17:10Это моя первая программа на расте. Я не знаю ни языка, ни библиотеки. Думаю, писать стековую машину или дерево выражений слишком круто для первого раза. Я просто знакомился с трейтами.
JekaMas
26.12.2018 15:04Хорошая статья.
Правда я придерживаюсь мнения, что язык, скорее системный, и мне проще и в пяток раз быстрее делать сервисы на го, а в раст выносить криптографию, системные вещи. Иначе цена решения становится несоразмерной.
"Ну и могу сказать, что по прошествии года с того момента как я впервые начал на расте писать, я научился писать простые сниппеты без ошибок с первого раза."
Это очень ведь дорого...BlessMaster
26.12.2018 15:29+3Это очень ведь дорого...
То, что человек совершает ошибки — вполне нормально.
Раст — язык с дополнительным контролем корректности программы.
Компилятор берёт на себя себя проверку декларируемых намерений и реального их выполнения. То есть, человек гараздо чаще сталкивается с ними не "когда-то потом", а непосредственно на этапе компиляции.
С помощью комплиятора и линтера постепенно вырабатывается навык писать сразу правильно и в соответствии с хорошим стилем. То, на что на самом деле в других языках уходят годы практики и что зависит от культуры написания кода в команде, если программисту повезло оказаться в хорошей команде.
Использовать Rust как дополнительный язык для ускорения узких мест — на самом деле тоже хорошее применение и важная ниша, в которой практически нет конкуренции. Да и глупо рассчитывать на то, что все разом забросят языки, изучению которых посвятили годы, и внезапно займутся переписыванием работающих проектов на новый язык с нуля (что может быть просто экономически нецелесообразно, даже когда язык действительно лучше по многим параметрам).
JekaMas
26.12.2018 16:10Согласен. Мне лично видятся очень хорошими варианты erlang+rust и golang+rust, и если выйдет история и webassembly, то js+rust.
humbug
26.12.2018 15:43+6я научился писать простые сниппеты без ошибок с первого раза.
Это очень ведь дорого...
Зависит от того, с чем сравнивать:
- Можно взять php, начать писать на нём прямо здесь и сейчас, очень дешево вначале, дорого, когда в файле больше 200 строк и очень дорого в поддержке
- Можно взять js, на котором тоже можно быстро начать писать, но неявные приведения типов могут склонить вас сменить профессию с программирования на проституцию
- Можно взять C++, относительно дешево выучить его, писать проектики, а потом три месяца дебажить неопределенное поведение силами двух программистов с суммарным опытом в 20 лет.
А можно взять и начать писать на Rust, в котором отсутствуют вышеперечисленные проблемы, но, блин, компилятор слишком строг. Ругается иногда. Не дает компилировать с первого раза код, который жалкий мешок мяса почему-то считает валидным.
Кому что. Я свой выбор сделал в пользу Rust. Есть моменты, о которых я жалею:
- отсутствие большого количества нормальных production-ready пакетов, на данный момент на вкус и цвет 10000+ пакетов, годных и вылизанных от и до всего чуть больше 100-200 (а у С++ и того нет). Поправьте, если ошибаюсь.
- неоправданно большой граф зависимостей для некоторых пакетов (как если бы 90% npm зависили от left-pad).
- 200 пакетов компилируются за минуту, хотелось бы быстрее
- На данном этапе не понимаю, как интегрировать Rust futures в Js Promise для асинхронного WebSocket, чтобы перенести свой проект из нативного приложения в WASM. Решения на колбеках есть, но хотелось бы чего-то готового и поддержки в tokio/romio. Программистам на Go в этом плане сильно повезло, у них таких проблем нет. Они находятся на этапе: "почему мой hello world на WASM весит несколько мегабайт. Какой рантайм, какой ГЦ? Что это такое? Почему плохой транслятор GO-WASM тащит весь язык в файлик .wasm?"
- устал от HR, приглашают на работу и собеседования каждую неделю. Приходится вслушиваться в произношение людей из Шотландии и Новой Зеландии
- приходится скрывать доходы от друзей, потому что зарплату в $$$ реально девать некуда.
JekaMas
26.12.2018 16:06-1А можно молотком забивать гвозди, а шилом делать дырки.
Я лишь про то, что rust прекрасный инструмент, когда мне нужен максимум скорости. Условно php7 может дать 30-40% от максимума; java — 60%; golang — 80%; и rust, c — 100%. Но в то же время чем ближе к C, тем каждую фичу ждать дольше и дольше, это с одной стороны. С другой, мы можем оценивать задачу по тому, сколько ей надо производительности и соответственно выбирать инструмент.
Про $$$ и golang вы тоже будете удивлены. Скажем так, 150-170k usd год на удаленной работе — не есть большая сложность.humbug
26.12.2018 16:15+2Я лишь про то, что rust прекрасный инструмент, когда мне нужен максимум скорости.
Почему вы акцентируете внимание на скорости, когда это не самое главное? Да, Rust чертовски быстр, и может быть быстрее C, но это не важно. Вы же понимаете, что люди пишут программы не для компьютера, а для других людей?
Когда мне надо наговнякать хоум страничку для друга, на которую никто не будет заходить — я выбираю PHP.
Когда мне надо в браузере работать с UI — я выбираю JS.
Когда мне надо набросать функциональщину для проверки гипотезы — я выбираю Haskell.
Когда мне нужен самый простой язык в мире, у которого 3 разных типа обработки исключений — нет, не выбираю :D
И когда мне нужен безопасный язык с предсказуемым поведением, который может поддерживать разработчик-июнь за 400USD, я выбираю
ПикачуRust, а не тот язык, поддержка которого стоит 150-170k USD в месяц (и то не предел).JekaMas
26.12.2018 16:19Вопрос денег подняли вы.
Как план с junior должен сработать? Через какое время на rust он сможет полноценно закрывать задачи?
И если мы начинаем говорить про программы для людей, то нужен инструмент с кодом, который можно быстро читать.
humbug
26.12.2018 16:25Как план с junior должен сработать? Через какое время на rust он сможет полноценно закрывать задачи?
Древние свитки говорят о двух месяцах. После чего люди коммитят в сложные участки компилятора или пишут фреймворки, которые обгоняют существующие решения по производительности. Давно открывали код gcc, который поддерживают 9 анонимусов в мире? Долгой им жизни...
И если мы начинаем говорить про программы для людей, то нужен инструмент с кодом, который можно быстро читать.
Ага. Чтобы корова меньше ела и давала больше молока ее нужно чаще доить и реже кормить.
Код надо не быстро читать, а понимать правильно и корректно. И инструменты должны давать по рукам, если человек неправильно понял.
JekaMas
26.12.2018 16:27А в статье у автора ушел год и только простые сниппеты с первого раза выходят… И это опытный разработчик.
Что-то не так в свитках...PsyHaSTe Автор
26.12.2018 16:29+5А вы часто пишете на JS код (без IDE), который 100% работает во всех граничных случаях, не складывает случайно строки с числами и т.п. с первого раза? Или С++ код, на который ни один анализатор не ругнется ни одним правилом?
PsyHaSTe Автор
26.12.2018 16:18+2Я лишь про то, что rust прекрасный инструмент, когда мне нужен максимум скорости.
Такое ощущение, что статью вы вообще не читали.JekaMas
26.12.2018 16:27Читал. А вы мой изначальный комментарий?
"Хорошая статья.
Правда я придерживаюсь мнения, что язык, скорее системный, и мне проще и в пяток раз быстрее делать сервисы на го, а в раст выносить криптографию, системные вещи. Иначе цена решения становится несоразмерной."PsyHaSTe Автор
26.12.2018 16:31+3Читал. И, как можно догадаться, не согласен. От того, что вы решение некоторых проблем вынесете «на потом», в рантайм, лучше не становится. Вместо того, чтобы сделать фичу за 3 дня, делаем за день, а потом еще 2 дня дебажимся. Зато количество закрытых тасок удвоили. Вот замечательно-то.
У раста нет объективных причин быть менее продуктивным, чем какой-нибудь котлин или тот же шарп. Есть сложность с пониманием борроу чекера, но на него, как выше сказали, достаточно пары месяцев. Для стартапа который на проект выделяет полгода это наверное слишком долго. Для компании с проектом на год-два уже приемлемо. Дальше стоимость внедрения только падает.JekaMas
26.12.2018 16:39Как же все только живут с этими проблемами на рантайме… Тесты пишут, как и разработчики rust.
Если говорить не голословно, то пока я видел одну неудачную миграцию на rust, которая сильно увеличила сроки проекта и поставила его под вопрос. Сейчас очень хочу узнать не об опыте крутых, без всякого сомнения, одиночек, а о больших и долгих проектах.
FF с его 6% кода на rust не впечатлил пока, динамика там есть, но пока не видно, чтоб он занял существенную долю.
И, повторюсь, вопрос долгой поддержки. Мне лично неясна ниша языка, пока мы не увидели проекты в долгой перспективе. У нас уже есть клевые scala, haskell, но которые слишком дороги в поддержке. Мне хотелось бы, чтобы rust не повторил эту судьбу.
PsyHaSTe Автор
26.12.2018 16:49Как же все только живут с этими проблемами на рантайме…
Плохо живут. Я вот на шарпе когда пишу, понимаю, что в расте такой проблемы бы в принципе не возникло, а тут про нее думать надо.
Тесты пишут, как и разработчики rust.
В шарпе вы не пишете тесты на то, что вместо числа придет «ff», «qwerty» или ящереца в стакане, в JS пишете.
В расте вы не пишете тест на то, что в многопоточном окружении ваш код не сломается, в тех же шарпах — пишите.
Если говорить не голословно, то пока я видел одну неудачную миграцию на rust, которая сильно увеличила сроки проекта и поставила его под вопрос. Сейчас очень хочу узнать не об опыте крутых, без всякого сомнения, одиночек, а о больших и долгих проектах.
В статье про PVS studio было прилично ссылок. Из того, что на слуху, можно вспомнить Parity/Exonum/Redox, например.
FF с его 6% кода на rust не впечатлил пока, динамика там есть, но пока не видно, чтоб он занял существенную долю.
Когда я последний раз смотрел статистику по репозиторию, в FF было 1млн строк кода на С, 1.5 миллиона на расте, 3.5 (или 7, не помню точно) миллиона на С++, и около 5 миллионов всякой шелухи вроде html.
И, повторюсь, вопрос долгой поддержки. Мне лично неясна ниша языка, пока мы не увидели проекты в долгой перспективе. У нас уже есть клевые scala, haskell, но которые слишком дороги в поддержке. Мне хотелось бы, чтобы rust не повторил эту судьбу.
Буквально в прошлом месяце у меня знакомый сменил синиор шарпа позицию на синиор скалиста. Не так уж у неё все плохо.
А вообще, отрицать то, что на расте разработчиков меньше, чем на других языках смысла нет. Поэтому я и решил статью написать, потому что как мне кажется, от раста вся эта его история с его «железячностью» отпугивает тонну людей. А на самом деле все сильно проще, особенно если не заморачиваться в некоторых местах.JekaMas
26.12.2018 16:57+1Статистику тут обычно смотрю https://4e6.github.io/firefox-lang-stats/
Судьба parity мне не понятна пока, но тут скорее вопрос не в языке, а том, что товарищи время от времени мержат в мастер по несколько сот строк кода без ревью и тестов.
Это все молодые проекты, около года. И небольшие, ну пара десятков разработчиков.
Самое интересное в долгой поддержке и/или масштабировании команд.PsyHaSTe Автор
26.12.2018 17:01Огромное спасибо, давно искал эту ссылку! Сильно наврал с цифрами, прошу прощения. Помню примерно «1.7 раста на 7 С++», остальное хуже.
Да, то верная информация.
Это все молодые проекты, около года. И небольшие, ну пара десятков разработчиков.
Самое интересное в долгой поддержке и/или масштабировании команд.
Откуда взятся проектам сильно за год, если язык только 3 года назад в 1.0 вышел? Ведь там менеджеры тоже по той же логие смотрят «пока только появилось, надо обождать, присмотреться, и только потом осваивать».
Откуда сотни разработчиков на одном проекте где-то кроме мозиллы возьмутся тоже не совсем ясно.
Более крупного пока ничего нет, но опыт самого rustc показывает, что и довольно крупные проекты вполне неплохо живут.JekaMas
26.12.2018 17:11+1Пожалуйста.
Поймите, мне тоже неподдельно интересен rust, но у меня просто отличается взгляд на его применение. Маленькие команды очень опытный спецов — это точно сработает и работает.
Увидим ли мы большие команды — вопрос. Увидем ли мы переход от системного языка к общему — тоже вопрос.
Мне лично пока видится, что врядли и нет. Посмотрим.
TargetSan
26.12.2018 17:43+2Я извиняюсь если вопрос покажется некорректным. Но мне правда интересно. Вы бы стали писать на Golang если бы за ним не стоял Гугл? И что произойдёт если гипотетически Гугл скажет "голанг неудачен, пилим всё на тайпскрипт"?
Озвученная вами проблема — извечная проблема курицы и яйца. Никто не хочет писать на новом языке т.к. на нём не пишут толстые корпорации — которые на нём не пишут т.к. пишет мало кто, goto 1. Почти гарантирую, что если бы С++ был создан сейчас в текущем виде, он бы помер не родившись — но его держат мегатонны легаси.JekaMas
26.12.2018 18:06+1Хороший вопрос. У меня в активе языков есть такие вещи как R, closureScript, так что вряд ли я гонюсь за популярными вещами и большими компаниями.
Да, я выбирал язык не из-за Гугла. У меня был PHP, Python, плюс всякое редкое (по месяцу пробовал Nim, Crystal), но не было чего-то достаточно быстрого, клево себя в concurrency и строго типизированного. Рассматривал варианты C#, с которым был год опыта, когда он еще был версий 1.1-1.3, Java, С++, golang.
C# отмелся поскольку совсем другой стек все же. Хотя как язык он мне очень нравился.
Java — слишком большая штука. Ее надо брать не дополнительным инструментом, а единственным и для всего. Но окончательно я ее не отметал.
С++ — я еще помню долгие споры об Oberon/modula/Pascal vs C/C++ и брать язык с всевозрастающей собственной сложностью — это точно нет.
Golang обещал полную обратную совместимость (слово сдержано и с 1.0 по 1.13 ломающих изменений было ровно 2, которые фиксились автоматически гошной же тулзой), приятное мне смещение внимания с языка на продукт (когда можно не изучать и изучать язык каждый год, а заниматься развитием продуктов), почти полная имплементация CSP (за исключением операции удаления потока), очень (очень-очень) быстрая компиляция, что делала работу в TDD удобной и комфортной. Это перевесило, я начал его учить. Скоро и вакансия нашлась.
Нет, про гугл я тогда не думал. В основном думал про те задачи, которые хотелось решать. А это был e-commerse и highload. Там golang себя хорошо нашел. Сейчас занимаюсь распределенными системами и golang себя все еще хорошо чувствует. Как бонус получил golang на мобильных устройствах и есть опыт уже разработки гошных либ для мобильных приложений.
Но не хватает иногда быстрой числодробилки. Можно пойти путем C и его биндингов в Golang. Но rust, хоть также идет по пути усложнения и увеличения объема языка, как С++, но обещает хорошую модель конкуренции и быструю числодробилку, поэтому решил его тоже взять.
Как-то так. Не думаю, что ваше дальнейшее рассуждение о курице и яйце ко мне применимо. У меня другие критерии.
VanquisherWinbringer
26.12.2018 16:37+1Проще для кого? Для человека с 2 годрами опыта на Rust и без опыт Go Проще в пяток раз будет на Rust сделать весь миросервис и работать он будет быстрее и надежнее. Да в целом код на Rust писать мне приятнее и проще чем на Go хотя и там и там у меня опыт одинаковой величины. Просто потому что в Rust есть шикарные enum и генерики поэтому не приходиться костыли делать как в Go с interface{} или вообще, прости господи, кодогенерацией.
JekaMas
26.12.2018 16:42Вы круты, бесспорно, но это разговор о нравится-не нравится пошел. Мне он мало интересен, в отличие от инженерных задач и подходов к ним.
VanquisherWinbringer
26.12.2018 16:48+1мне проще и в пяток раз быстрее делать сервисы на го
Это вы начали давать субъективные оценки. Я вам лишь ответил на вашем же языке.JekaMas
26.12.2018 16:51-1Отнюдь, я говорю о скорости и простоте разработки, а не о нравится-не нравится.
Простите, но мне это напоминает старую статью про го, где разработчик откпзался от него потому что "не чувствовал себя умным", когда писал гошный код.
Мы вроде как задачи решать должны в поставленные сроки и с заданными условиями, а не про вкус и цвет.VanquisherWinbringer
26.12.2018 16:57+1Вы путаете скорость и простоту разработки со скоростью и простотой изучения. Да и вообще, вы как это мерили, посадили в разных комнатах Go и Rust программиста с опытом 1+ год и дали им задачу написать одинаковый микросервис и писать до тех пор пока он не проходит корректно все тесты или это просто ваши голословные утверждения по поводу того что на Go разрабатывать проще и быстрее или на самом деле может на Rust проще и быстрее?
JekaMas
26.12.2018 17:03+1У меня есть в команде разработчик: 2 года go, затем год rust, и вот снова go.
На нем удобно сравнивать. На нем и сравниваем.
Задачи на го идут шустрее в разы.
Ну и я тоже изучаю раст сейчас, пока то, что я вижу точно говорит:
- Код ревью будут сложными и могут быть долгими
- Вход разработчика в проект тоже долгий
- Начала работы новичка в языке — несколько месяцев и точно нужно приставлять наставника.
Изучаю дальше.
freecoder_xx
26.12.2018 17:52+3Вам половину ревью сделают компилятор, rustfmt и clippy. Писать на Rust новый код чуть долше, но вот рефакторить ранее написанный — довольно быстро и приятно. А главное — появляется уверенность в его надежной работе с технической стороны, можно больше внимания уделять проверке логики (даже по сравнению с Java, где у меня на большом проекте примерно 80% времни уходило на исправления NPE-багов).
JekaMas
26.12.2018 18:09Все равно надо код ревьюить и пока мне видится, что при большом объеме фич в языке и довольно «особенном» синтаксисе, подчас, приведет к трудным ревью. Это вопрос, с какой скоростью можно понимать чужой код на rust.
Для меня вопрос открытый, хоть и есть свое мнение.PsyHaSTe Автор
26.12.2018 18:19Фич не так уж много, как может показаться. Растбук сравнительно небольшой (реально прочитать за день, если с растом хоть немного знаком), и покрывает всё, что есть в языке.
Остальное — библиотеки, стандартные паттерны и всё такое, что нужно знать в любом языке.
Это вопрос, с какой скоростью можно понимать чужой код на rust.
Раст это не «новый С++», там нет непересекающихся подмножеств языка, где каждый разработчик пишет на «своём» диалекте и не понимает соседей.
Новая версия раста выходир за в 6 недель, и как правило выходит какая-нибудь мелкая фича, как правило, снятие существовавшего раннее ограничения, стабилизация пары полезностей в стандартой библиотеке и прочая мелочь. Раз в год примерно выходят крупные фичи, вроде того же NLL, или готовящегося async/await и генераторов. Не сказал бы, что это прям очень часто, какой-нибудь C# обновляется примерно так же раз в год.JekaMas
26.12.2018 18:27Раст это не «новый С++», там нет непересекающихся подмножеств языка, где каждый разработчик пишет на «своём» диалекте и не понимает соседей.
Мне это пока сомнительно. Пока выдится именно так. И повторюсь, в сравнении с golang, который поддерживает полную обратную совместимость и даже golang 2.0 взял на себя гарантию, что код любой версии 1.0 будет компилироваться без изменений, изменения в rust смотрятся дополнительной ценой, которую надо платить.
Возможно через полгодика изучения языка количество фич и особенностей не будет казаться таким большим, но пока оно именно такое и пока думается, что это вряд ли изменится, все же язык явно наследник именно c++.PsyHaSTe Автор
26.12.2018 18:50Мне это пока сомнительно. Пока выдится именно так. И повторюсь, в сравнении с golang, который поддерживает полную обратную совместимость и даже golang 2.0 взял на себя гарантию, что код любой версии 1.0 будет компилироваться без изменений, изменения в rust смотрятся дополнительной ценой, которую надо платить.
В расте тоже полная обратная совместимость. Более того, Rust 2018 остается совместимым настолько, что вы можете иметь крейт 2018, который ссылается на 2015, который тоже ссылается на 2018, и всё это будет работать.
А вот будет ли совместимым Go 2.0 — не уверен. Судя по генерикам — вряд ли.
Возможно через полгодика изучения языка количество фич и особенностей не будет казаться таким большим, но пока оно именно такое и пока думается, что это вряд ли изменится, все же язык явно наследник именно c++.
Мое мнение, что аналогия ложная. Впрочем, вам решать.JekaMas
26.12.2018 18:53Поясните про генерики и 2.0. Старый гошный код не должен от них ломаться, судя по драфту.
PsyHaSTe Автор
26.12.2018 20:57Ну хорошо, если так.
Просто я помню .Net 2.0 с генериками, единственный абсолютно несовместимый с предыдущими версиями рантайм, ну и генерики очевидно влияют на механизмы перегрузки, который может поменять семантику уже существующего кода (в го ведь есть перегрузка?).
Если команда го всё это смогла учесть, то могу их только поздравить.
JekaMas
26.12.2018 21:08Бинго! Нет перегрузки.
Но по драфту и текущему обсуждению его генерики не убьют старый год. Там скорее вопрос в том, что тогда надо стандартную библиотеку на генерики переписывать.
Siemargl
26.12.2018 20:10Я бы рекомендовал посмотреть VanquisherWinbringer публикации и код из них, прежде чем обсуждать с ним и делать далеко идущие выводы =)
На мой взгляд, код Раста трудночитаем -> мало кто будет на нем писать со всеми вытекающими. Так что согласен.JekaMas
26.12.2018 20:16Я б рад, но времени не так много, чтобы дополнительные статьи читать.
Тут, скорее, было интересно понять, как складывается отечественное сообщество вокруг языка. Оно определенно складывается. И, к сожалению, должен признать, что оно пока более дружелюбно, чем в свое время гошное. Хотя и тут не без криков о вкусах и понятий вроде «ненавижу язык Х»!
А вы, товарищ, не пробовали rust? Было бы интересно обсудить.Siemargl
26.12.2018 20:29Думаю, не буду участвовать в истерии. Кроме синтаксиса и практического неудобства, раст еще и сырой.
Захочется приключений — вернусь в dlang — он на 5 лет старше и хотя бы прошел детские болезни и оброс фремворками. Ну или уж посмотрю на golang — он практически стабилизировался (еще бы ввели ожидаемую обработку ошибок).JekaMas
26.12.2018 20:44Dlang — сурово. Вы второй человек, которого я встречаю, кто на нем программирует. Удачи вам с ним, уж не знаю, что за задачи у вас.
eao197
26.12.2018 20:49+1Захочется приключений — вернусь в dlang — он на 5 лет старше и хотя бы прошел детские болезни и оброс фремворками.
Где-то можно посмотреть список живых фреймворков для D? На слуху как-то кроме Vibe.d ничего и нет.Siemargl
26.12.2018 22:00code.dlang.org причем с версионированием пакетов и родной системой сборки.
Но D я тоже хвалить не буду — у него тоже есть свои критические (на мой взгляд) недостатки.eao197
26.12.2018 22:06Жаль, ответа по сути не будет. Куча пакетов с номерами версий вроде 0.0.6 или 0.2.0 — на «оброс фремворками» не тянет. Даже если вести отсчет от появления D2.
PsyHaSTe Автор
26.12.2018 21:06На мой взгляд, код Раста трудночитаем -> мало кто будет на нем писать со всеми вытекающими. Так что согласен.
Посмотрим. Мне изначально код раста казался очень даже читаемым, и постепенно это чувство только крепнет. Ну вот возьмем например мою версию телеграм-клиента. Он очень простой, умеет вызывать несколько методов удаленного сервера, и держать соединения. Какие конкретно места по-вашему тут трудночитаемые?
VanquisherWinbringer
26.12.2018 21:58Фу таким быть — обычно к подходу, у меня больше опыта поэтому я знаю как лучше прибегают глуповатые люди не способные аргументировать свое мнение. Поэтому я бы к вашим комментариям тоже отнесся скептически. Ну раз уж на то пошло то я лично участвовал в разработке информационной системы международного уровня, системы федерального значения и одной системы регионального уровня. Да это все было на C#. + Разрабатывал и проектировал с нуля клиент — серверное приложение для одной Туристической компании которым они года два пользовались. Сейчас как там дела уже не знаю. Я же не буду сюда выкладывать код с тех проектов. Да и на гитхабе всякую фигню делаю как попало для души. И да, я больше десятка разных языков из любопытства пробовал и пока что мне из них Rust нравиться.
Siemargl
26.12.2018 23:35-2Вообще то в моем комментарии нет абсолютно никакого негатива. Каждый пусть делает выводы сам.
Только легкое подкалывание Эксперта по языку со статьей от 5 ноября 18г, «Изучаю Rust....» =)
freecoder_xx
26.12.2018 22:00+3Rust трудночитаем только для тех, кто на нем не программирует. Потому что синтаксис непривычный. Но он довольно простой и проблем с восприятием чужого кода, если он не перегружен лайфтаймами (что бывает редко), обычно не возникает. Читать исходники зависимостей проекта — обычная практика в Rust. Часто это быстрее и проще, чем смотреть документацию.
PsyHaSTe Автор
26.12.2018 22:27+1Сейчас отсюда последует leap of logic, что с документаций в расте все плохо :)
freecoder_xx
26.12.2018 23:07+1И ведь подумал, что надо дописать: "хотя с документацией в Rust все в порядке", но не стал. А зря :)
Siemargl
26.12.2018 23:41-4Логика другая — вот я могу читать десяток-два языков и беглый взгляд обычно дает понятие — что тут происходит.
Без документации — она потребуется позже, чтобы нормально писать.
Rust source — WTF ???freecoder_xx
26.12.2018 23:47+5Языки семейства ML и Haskell, например, входят в ваш десяток? Может быть те, которые вы можете читать бегло — это всё вариации примерно одного и того же языка (или двух)?
freecoder_xx
26.12.2018 23:59+2То есть вы испытали дискомфорт от того, что не смогли понять исходник на Rust, не зная его синтаксиса? Ну да, это известная проблема. Просто часто это обобщают, и говорят, что код в принципе нечитаемый и непонятный, тогда как он таковой только для тех, кто не знаком с Rust.
eao197
26.12.2018 17:32+1Можно взять C++, относительно дешево выучить его, писать проектики, а потом три месяца дебажить неопределенное поведение силами двух программистов с суммарным опытом в 20 лет.
А как именно Rust защищает от ошибок с низкоуровневой работой с неправильно выровненными данными (ведь ваша ссылку ведет на исправление именно такой проблемы)?humbug
26.12.2018 17:54+3О, старый друг по комментариям!
Это действительно меткий вопрос, я очень рад, что вы прошли по ссылкам и осознали мою боль. Я хорошо подумаю над ответом и дам его в развёрнутом виде с пруфлинками и всем таким, когда приеду домой.
humbug
27.12.2018 12:50+4Rust не защищает тебя на 100% одним своим присутствием в проекте, но позволяет вывести строгий аргумент безопасности, которые сведут количество подобных ошибок к минимуму, если не к нулю: не пиши unsafe. Если они и возникают, то ты всегда ищешь там «где светло», а светло там, где есть unsafe.
А как именно Rust защищает
У меня вчера был сложный вечер. Меня порывало сказать: "Да никак! Это настолько сложная ошибка, что даже Rust пасует перед ней!", потому что я был под влиянием неприятных воспоминаний, когда не было никакой возможности найти зацепку в коде C++, а только лишь дебажить и дебажить. Как получить зацепку для дебага кода C++, если он весь unsafe со списком в ~200 неопределенных поведений? Ну… делать вот так o_O и искать, искать, искать. Ошибки подстерегали нас на каждом углу, даже сложению знаковых чисел нельзя было доверять. Хотя казалось бы, самая примитивная операция.
На этом можно было бы и закончить комментарий, мол, Rust не защищает, но тут в дело вступает маленький нюанс: а где бы я мог выстрелить в ногу, если бы я писал виртуальную машину на Rust? Только в unsafe. И путем нехитрых изысканий приходим к тому, что unsafe мне бы нужен был только для низкоуровневой работы с памятью. Всё. Делаем o_O на 500 строчках кода, обмазываемся тестами, перепроверяем только код сборщика мусора. Rust выигрывает не в своем фанатичном "безопасно", а в предоставлении системного подхода к поиску низкоуровневых проблем. Ищи там, «где светло».
Что делать, когда этого «светло» нет? Казалось бы, есть ноды https://nodes.tox.chat/, написанные на C, которые уже 5 лет в проде, оттебажены, в которых все хорошо, которые не падают… Ведь так?
Вот ты разработчик, у тебя падает код в 60KLOC, который 5 лет "правильно работал". Что ты будешь делать? Я бы заплакал.
Ну и в противовес: tox-rs (30KLOC) без единого unsafe. И наш сервер не падает в рандомных местах. Не утекает, не ломается. И не утечет, не сломается.
Тут стоит напомнить о свежей баге, найденной в tar, которому 40 лет:
https://utcc.utoronto.ca/~cks/space/blog/sysadmin/TarFindingTruncateBug
if you run GNU Tar with --sparse and a file shrinks while tar is reading it, tar fails to properly handle the resulting earlier than expected end of file. If the file grows again, tar recovers.
Зато на C. И очень быстра.
eao197
27.12.2018 13:06-7Грубо говоря, вы слились.
Ибо была ссылка на конкретную ошибку в плюсовом коде с явным намеком на то, что в Rust-е вы бы от такой были бы защищены. Но проблема в том, что там была ошибка с низкоуровневым кодом, для понимания которой нужно было опускаться на уровень аппаратной архитектуры и особенностей команд конкретного процессора. Rust бы вам магическим образом ничем бы не помог.
Я бы заплакал.
Тряпка! :)
И наш сервер не падает в рандомных местах. Не утекает, не ломается.
Вас может удивить, но на плюсах совсем не сложно сделать сервер, который не падает, не утекает, не ломается. Мы делали это неоднократно.
Но речь про плюсы, не про С. А вы, как и многие здесь, упорно проводите между ними знак равенства.asdf87
27.12.2018 14:03+1Грубо говоря, вы слились.
Действительно грубо.
А можете привести пример проекта вот с этими свойствами (желательно со ссылками, подтверждающими эти свойства):
на плюсах совсем не сложно сделать
сервер, который не падает, не утекает, не ломается
Мы делали это
Интересно узнать о проектах какой сложности идет речь.eao197
27.12.2018 14:16-2Действительно грубо.
Как народец-то обмельчал. Слово «слились» — это уже грубо. Суппорт старого кода всего в 60KLOC — «я б заплакал».
А можете привести
Из публично доступного у нас есть вот это. Игрушка, с собственной реализацией HTTP-сервера.
Интересно
Мне вот было интересно узнать, как Rust защищает от ошибок выравнивания данных в низкоуровневом коде. Но что-то не вышло.
Может вы поддержите предыдущего оратора?Ryppka
27.12.2018 14:46+2Мне вот было интересно узнать, как Rust защищает от ошибок выравнивания данных в низкоуровневом коде. Но что-то не вышло.
Если только синтаксически значительно сужает зону, где они могут появиться, чем облегчает и кодирование, и поиск ошибки. Но не радикально.
В C/C++ то же самое достигается с помощью правильной архитектуры, строгого следования code guidlines и статического анализа. Т.е. более трудоемко. Это цена большей выразительности (на низком уровне — точно) и излишней мягкости Б. Страуструпа.eao197
27.12.2018 14:50-1О том и речь.
Причем я бы не стал смешивать C и С++ здесь. Т.к. в С++ столкнувшись с такой ошибкой можно было бы сделать шаблонный тип вроде properly_aligned_ptr<T> и изменить API так, чтобы интерфейс оперировал такими типами, а не голыми указателями. Тогда как в C пришлось бы следовать устным договоренностям.humbug
27.12.2018 14:58+1Тогда как в C пришлось бы следовать устным договоренностям.
То есть когда у C++ может быть защита на уровне интерфейсов — это хорошо, а когда у Rust есть защита на уровне интерфейсов по дефолту плюс усиленная защиту на уровне типов — это хипстота, смузи и закопайте?
Понятно.
eao197
27.12.2018 15:01когда у Rust есть защита на уровне интерфейсов по дефолту плюс усиленная защиту на уровне типов — это хипстота, смузи и закопайте?
Пожалуйста, найдете в данном обсуждение хоть одно сообщение, где бы я сказал что-то плохое в адрес Rust-а. Может хоть это у вас получится.
Но т.к. вы в разговоре о достоинствах Rust-постоянно смешиваете C и C++, то я еще раз позволю себе напомнить вам, что это разные языки, с разными выразительными возможностями и разной стоимостью написания корректного и надежного кода. Вы, видимо, просто не в курсе.humbug
27.12.2018 15:12Я в курсе, что это разные языки. Я так же в курсе, что на C++ можно писать как на C (за исключением некоторых очень специфичных штук типа structure initializer). А раз это можно делать, то этим люди и занимаются because they can.
И вашем мире розовых пони существует супер-классный C++17-20 (он мне тоже нравится), но на котором можно безопасно писать только с соблюдением устных договоренностей ("Срочно пишем по CppCoreGuidelines"), а в моем мире существует махровый C++, дай бог C++11, который пахнет как гавно, выглядит как говно, на вкус как говно. Его практически невозможно отличить от C, но типа в .cpp файликах, ага.
eao197
27.12.2018 15:19+1Простите, где подтверждения хотя бы каких-либо ваших утверждений?
По поводу современного C++ и CppCoreGuidelines, то могу вам сказать, что примитивные шаблоны вроде not_null или bounded_value, как и смарт-поинтеры и прочие вещи, облегчающие RAII, нормальные разработчики использовать стали задолго до. Где-то даже до принятия C++98 (шаблоны, если вы не в курсе, более-менее массово доступны стали с 1994-1995-х годов). Книги вроде Modern C++ Design и C++ Coding Standards — 101 Rules Guidelines — это 2001-й и 2004-й годы. По мерками ИТ совсем давно.
Говнокод можно наплодить везде. Счастье Rust-а в том, что до него еще говнокодеры из C++, Java и JavaScript-а не добрались. Как доберутся в массовых количествах, так запаритесь unsafe расчищать.humbug
27.12.2018 15:23+3Счастье Rust'а в том, что на нем написать нормальный код проще, нежели наговнокодить.
Но так-то да. Скоро набегут великие "оптимизаторы" из C++, и придется расчищать и опять нюхать.
eao197
27.12.2018 15:29на нем написать нормальный код проще, нежели наговнокодить.
Обсуждение создания двусвязных списков и древовидных структур в Rust-е вот прям яркое тому подтверждение.
Но я тоже жду, пока «оптимизаторы» из C++ перебегут к вам.humbug
27.12.2018 15:31Про двусвязные списки уже давно не актуально.
eao197
27.12.2018 15:39Автору статьи про это расскажите. Он почему-то счел заслуживающим внимание этот вопрос затронуть. Хотя казалось бы.
humbug
27.12.2018 15:14+1Пожалуйста, найдете в данном обсуждение хоть одно сообщение, где бы я сказал что-то плохое в адрес Rust-а.
Rust бы вам магическим образом ничем бы не помог.Я объяснил, как именно он бы мне магически помог.
eao197
27.12.2018 15:24Я объяснил, как именно он бы мне магически помог.
Ошибку Rust бы вам предотвратил? Нет.
Все остальное — это спекуляции на тему того, как быстро конкретный человек в конкретном коде бы нашел проблему.
У меня лет 20 назад был похожий случай. В коде по десериализации двоичных данных было что-то вроде:
float parser::get_float() { const char * ptr = m_current_ptr; m_current_ptr += 4; return *((const float *)ptr); }
На x86 работало нормально. На SPARK-е сразу же SIGBUS. И нашлось без проблем.humbug
27.12.2018 15:38+1Все остальное — это спекуляции на тему того, как быстро конкретный человек в конкретном коде бы нашел проблему.
Да, я тоже так изначально подумал про свои мысли, поэтому так долго не отвечал.
И поэтому я полез в код GC на Rust: withoutboats/shifgrethor, (начало цикла статей).
Вы знаете, код проще читать, тесты проще писать, баги проще искать. Ночью набил пару PR.
eao197
27.12.2018 15:42-3код проще читать, тесты проще писать,
Кому-то код на Lisp-е проще читать, чем код на Pascal.
баги проще искать.
Ну надо же, баги. Казалось бы, откуда им взяться, раз и Rust такой весь из себя, и говнокодеры из C++ еще не подтянулись. Неувязочка ;)
Ryppka
27.12.2018 15:11+2C, все-таки, существенно проще и в него лучше «входят» расширения для поддержки аппаратных/программных «выкрутасов» (типа TR 18037). ИМХО, в определенной сфере применения он удобнее C++, в котором герберизм-саттеризм не дает заниматься делом))).
eao197
27.12.2018 15:12Возможно. Разработчики аппаратуры наверняка входят в C проще.
Но это уже совсем офтопик.Ryppka
27.12.2018 22:53Ну, думаю, что тут главное то, что C для работы на «низком» уровне выразительности хватает, а вот абстракций и концепций, требующих нетривиального рантайма нет. «C++ как улучшенный C» это, ИМХО, преувеличение. Помнится, в первом издании «Языка программирования C++» в финальном примере Страутсруп реализовал драйвер вывода на экран на C, чтобы подчеркнуть, как он писал, «разделение зоны ответсвенности» между этими языками. Как-то так, мне нравиться писать и на C, и на C++.
Antervis
27.12.2018 16:15Вот ты разработчик, у тебя падает код в 60KLOC, который 5 лет «правильно работал». Что ты будешь делать? Я бы заплакал.
boost::stacktrace, google breakpad, в с++20 едет std::stacktrace. Ошибка локализуется еще на этапе чтения логов, до открытия IDE. Да и в целом краши — самые легко отлаживаемые баги. А если вдруг у вас сервер вернул «3» вместо «14», где «светло»?
И наш сервер не падает в рандомных местах. Не утекает, не ломается.
Во-первых, и на плюсах де-факто пишутся безопасные программы. И это не зависит ни от моего, ни от вашего, ни от чьего-бы-то-ни-было еще мнения по поводу плюсов/раста. Во-вторых, я, помнится, критиковал то, что вы сравниваете раст 2015-ого года с с++03. Сейчас вы пошли даже дальше, и сравниваете раст с вообще другим языком, си
п.с. вообще неприятно вести с вами (растовиками) дискуссии. Вы пытаетесь навязать видение мира, в котором ни одна из программ на с++ не работает, а любая попытка его опровергнуть заканчивается ничем кроме пары минусов в карму.humbug
27.12.2018 16:24+1Во-первых, и на плюсах де-факто пишутся безопасные программы.
Согласен. Безопасные пишутся. В 0.1%. А в 99.9% на плюсах пишутся небезопасные программы. И это не зависит ни от моего, ни от вашего, ни от чьего-бы-то-ни-было еще мнения по поводу плюсов/раста.
boost::stacktrace, google breakpad, в с++20 едет std::stacktrace.
А как это бы помогло отдебажить ошибку внутри C++ функции, которую вызывал JIT код, собранный самодельной VM, которая проявлялась только на
g++ -O3 -march=nativeс кучей проходов LLVM?eao197
27.12.2018 16:30внутри C++ функции, которую вызывал JIT код, собранный самодельной VM, которая проявлялась только на g++ -O3 -march=native с кучей проходов LLVM?
Так что есть в Rust для предотвращения этой ошибки? Вы поместите такой же for внутрь unsafe блока и получите те же проблемы.
Antervis
27.12.2018 16:55Безопасные пишутся. В 0.1%. А в 99.9% на плюсах пишутся небезопасные программы
статистику в студию.
А как это бы помогло отдебажить ошибку внутри C++ функции, которую вызывал JIT код, собранный самодельной VM, которая проявлялась только на g++ -O3 -march=native с кучей проходов LLVM?
Давайте маленько притормозим и отделим мух от котлет. Неправильно сгенерированный виртуальной машиной код отношения к плюсам не имеет никакого, положить код на расте может с тем же успехом, и про ваш unsafe ничего не знает. В плюсах, для диагностики плюсового кода необходимый инструментарий имеется.humbug
27.12.2018 18:17Неправильно сгенерированный виртуальной машиной код отношения к плюсам не имеет никакого
Он был правильно сгенерирован. Я спрашиваю каким образом можно отследить фреймы и распечатать stacktrace, если его нет или он покорёжен неопределенным поведением?
Antervis
28.12.2018 11:04каким образом можно отследить фреймы и распечатать stacktrace, если его нет
я лично не сталкивался с тем, чтобы стектрейса не было. Бывал ни о чем не говорящий, но это при работе с графикой, имеющей к плюсам весьма посредственное отношение
или он покорёжен неопределенным поведением
а как это вообще возможно? Память, в которую загружается исполняемый код, обычно лочится на запись.ZyXI
28.12.2018 11:48+2а как это вообще возможно? Память, в которую загружается исполняемый код, обычно лочится на запись.
При чём тут она? В слове «stacktrace» «stack» присутствует не просто так, и он на запись не лочится никогда.
Когда вы вызываете функцию в стек сохраняется указатель на следующую инструкцию (адрес возврата), указатель на стек для восстановления положения в стеке «как было» при возврате из функции (указатель на начало кадра) плюс некоторые другие данные (регистры, иногда безопасный залоченный регион для предотвращения (не слишком больших) выходов за границы массивов на стеке, иногда маркер для создания спекулятивного stacktrace на случай, если стек всё же был повреждён). Когда происходит какая?то проблема и нужен stacktrace вы обходите адреса возврата для понимания, где что было вызвано, в чём вам помогают в первую очередь адреса начала кадра — т.е. знание, какая часть стека относится к какой функции.
Теперь вопрос — что будет, если эти адреса повреждены? Даже если в стеке есть маркеры (которых обычно нет — я слышал, что они добавляются какой?то программой, используемой для отладки, но сейчас не вспомню, какой), то это будет спекуляцией — ничто не запрещает маркеру присутствовать в переменных, размещённых на стеке. А если их там нет, то в стеке почти наверняка будут и указатели на стек, и указатели на код, не имеющие никакого отношения к адресам начала кадра и возврата.
ZyXI
28.12.2018 11:53Вот здесь есть более подробное описание: https://habr.com/company/smart_soft/blog/234239/.
0xd34df00d
28.12.2018 23:15+2статистику в студию.
Личный опыт. Для всех программ, с которыми я работал и которые были сложнее пары сот строк, компилятор рано или поздно утыкался в UB.
Так что нет
здоровыхбезопасных, естьнедообследованныенеоптимизированные.Antervis
29.12.2018 00:23а с каким количеством программ полностью на с++11 и выше вы имели дело?
upd. имеются в виду программы, написанные в соответствии с практиками современного с++, а не с++03 код с другим флагом компилятораPsyHaSTe Автор
29.12.2018 02:03Да давайте сделаем проще. Существование доказать сильно проще, чем универсальность. Покажите достаточно большую программу на С++, в которой нет UB.
Плюс если вспомнить, что некоторые проекты (типа Linux) специально абузят UB через использование одного и того же компилятора, про который известно, как он этот случай обрабатывает.Antervis
29.12.2018 10:55Да давайте сделаем проще. Существование доказать сильно проще, чем универсальност
но вы сами сказали, что существование доказать сильно проще. 0xd34df00d утверждал что все с++ проекты, с которыми он имел дело, имели UB. Я попросил лишь назвать число таковых, на современном с++. Вы сами прекрасно понимаете, что выкладывать примеры коммерческого софта (с которым я имел дело) я не могу.
Плюс если вспомнить, что некоторые проекты (типа Linux) специально абузят UB через использование одного и того же компилятора, про который известно, как он этот случай обрабатывает.
Вы говорите о локальном использовании implementation-defined поведения, но забываете, что раст не стандартизован вообще и в нем всего один компилятор. В терминологии с++, поведение раста на 100% «implementation-defined».red75prim
29.12.2018 12:06+2Похоже на спор о том, что в офисе без перил, дверей в лифтах и электроизоляции можно работать. Можно, конечно, — смотреть куда идёшь, не трогать оголённые провода и т.д. Но позиция людей, говорящих, что им так нравится и всё в порядке, вызывает некоторое удивление.
Вы говорите о локальном использовании implementation-defined поведения
Речь идёт о нестандартных расширениях GCC
-fwrapv,-fno-strict-aliasingи др. Согласно стандарту соответствующие конструкции вызывают undefined behavior. Так что ядро линукса — нестандартный C и до недавнего времени могло компилироваться только с помощью GCC.
В терминологии с++, поведение раста на 100% «implementation-defined».
Есть The Rust Reference и там не написано, что всё поведение — implementation defined. Отсутствие стандарта не означает, что ничего не определено. Кстати, C был стандартизирован через 17 лет после появления — 29 лет назад, а ядро линукса написано на нестандартном C. В общем, не стоит преувеличивать ценность стандартизации.
PsyHaSTe Автор
29.12.2018 12:21но вы сами сказали, что существование доказать сильно проще. 0xd34df00d утверждал что все с++ проекты, с которыми он имел дело, имели UB. Я попросил лишь назвать число таковых, на современном с++. Вы сами прекрасно понимаете, что выкладывать примеры коммерческого софта (с которым я имел дело) я не могу.
Ну возьмите открытый код из гитхаба. Есть же куча крупных проектов. Неужели ни один из них не подходит под ваш критерий?
Вы говорите о локальном использовании implementation-defined поведения, но забываете, что раст не стандартизован вообще и в нем всего один компилятор. В терминологии с++, поведение раста на 100% «implementation-defined».
С одной стороны, пока у нас один компилятор (а он с нами надолго, я думаю, как и csc с сишарпом не имеет альтернатив уже два десятка лет), это не так страшно.
С другой, формализованный IEEE стандарт, конечно же, хотелось бы видеть.
0xd34df00d
29.12.2018 02:11А зачем вы сужаете выборку в выгодную вам сторону?
Antervis
29.12.2018 10:44я уже неоднократно писал, что сравнивать устаревшие плюсы с новым растом некорректно. Почему вы стремитесь к современным плюсам приписать пласт вплоть до ANSI C?
eao197
29.12.2018 10:06-4Для всех программ, с которыми я работал и которые были сложнее пары сот строк, компилятор рано или поздно утыкался в UB.
Да ладно, дался вам этот UB. Наличие UB в коде еще не означает наличие бага. Вот, скажем, такая функция:
Она же не только UB содержит (переполнение при знаковом целочисленном сложении), но и еще ошибку (ее нельзя использовать, если data пустой). Тем не менее, будет ли означать использование этой функции в программе обязательное наличие ошибки?int avg(const vector<int> & data) { return accumulate(begin(data), end(data), 0) / data.size(); }
Вовсе нет, т.к. программист может обеспечить валидность передаваемых в такую avg() данных другими средствами. Например, это может быть прямым следствием использованного вычислительного алгоритма.
Ну и да, в Rust-е ничего не препятствует написанию такого же avg и, если программист ошибся в своих предположениях и задействовал такую avg на неподходящих данных, он получит проблемы в run-time. Да, возможно, диагностировать причину сбоя будет проще. Только вот суть в том, что сбой не был предотвращен.
Или другой пример, приснопамятный двусвязный список:
template<typename T> class list_item { T value_; list_item<T> * prev_; list_item<T> * next_; public: list_item(T && v) : value_{move(v)} {} // prev_ и next_ не инициализированы! void bind(list_item<T> * prev, list_item<T> * next) { prev_ = prev; next_ = next; } list_item<T>* prev() const { return prev_; } list_item<T>* next() const { return next_; } };
Тут работа с методами prev() и next() прямым ходом ведет к UB, т.к. если для нового объекта list_item не был вызван bind(), то возвращаться будет мусор, так что даже такой «типа защищенный» код:
никакой защиты обеспечивать не будет.list_item<T> * prev = item.prev(); if(prev) prev->bind(...);
Но, опять таки, само использование list_item в коде может быть таким, что никаких проблем из-за этого UB не будет.
Так что, резюмируя, UB легко находится практически в любой C++ программе. Но вот к реальным проблемам это ведет далеко не всегда.Cerberuser
29.12.2018 10:26Насколько я понимаю, это называется «контрактом функции», и именно это активно используется оптимизаторами: контракт должен быть таким, чтобы никакого UB не происходило. Соответственно, если контракт нарушен — последствия непредсказуемы.
eao197
29.12.2018 10:42Смысл моего комментария в том, что:
a) формально UB присутствует практически в любой C++ программе, вне зависимости от ее размера и сложности. Есть операции над целыми числами со знаком — получите UB. Есть обращения по указателям — опять UB;
b) наличие формальных UB в коде не ведет автоматически к наличию багов в коде.
Контракты — это вообще отдельная тема для разговора.Cerberuser
29.12.2018 11:06Формально, UB присутствует там, где невозможно доказать его отсутствие. Есть явная проверка, что переполнения при знаковом сложении не будет? Окей — значит, и UB не будет (пример сознательно упрощённый — понятно, что в реальных случаях это будет сделано не так «в лоб»).
eao197
29.12.2018 11:12Простите, мне не интересно заниматься софистикой.
Выше приведен пример функции avg. В которой есть и UB, и ошибка. Компилятор, компилируя эту функцию вообще может не иметь представления о том, где она используется и какие данные ей подсовываются. Эта функция может быть частью отдельной, повторно используемой библиотеки, которая задействуется в совершенно разных проектах.Cerberuser
29.12.2018 11:27Совершенно верно. Компилятор исходит из того, что будут подсунуты такие данные, при которых UB не будет. Если вызывающая сторона знает, что это так, — UB нет. Если не знает — то да, вопрос, кто виноват в его появлении (вызывающая сторона, которая неправильно пользовалась библиотекой, или библиотека, которой можно неправильно воспользоваться), действительно уже на грани софистики. Но оптимизаторы здесь стоят на стороне авторов библиотеки.
Antervis
29.12.2018 11:46Формально, UB присутствует там, где невозможно доказать его отсутствие.
ну, это если совсем формально. Например, если формально, в ссылку можно передать *(T*)nullptr и получить тот самый UB. Более того, компилятор скорее всего даже выкинет проверку ссылки против nullptr, если её туда добавить. Причем так можно сделать и в расте — передать сгенерированную через unsafe ссылку на null в safe код. И там, уже в safe коде, проявится UB.
PsyHaSTe Автор
29.12.2018 12:23+1Она же не только UB содержит (переполнение при знаковом целочисленном сложении), но и еще ошибку (ее нельзя использовать, если data пустой). Тем не менее, будет ли означать использование этой функции в программе обязательное наличие ошибки?
Да, будет означать.eao197
29.12.2018 12:27+1Да, будет означать.
ППЦ какой-то. Так толсто, что даже тонко.PsyHaSTe Автор
29.12.2018 12:28Да нет, я серьезно. Если компилятор вместо вызова функции вставит запуск ханойских башен, вас тоже такой результат устроит, верно?
eao197
29.12.2018 12:31-1Да нет, я серьезно
Простите, но нет, серьезно воспринимать вас и ваши доводы я уже не могу. Любой идиотизм в желании разрекламировать свою любимую игрушку должен иметь свои пределы.PsyHaSTe Автор
29.12.2018 12:33+1Дело не в игрушке. Код с UB — плохой, и его быть не должно. Потом вызываются никогда не вызываемые функции форматирования диска, вместо полезной нагрузки сервак запускает игрушки, и вот это всё.
Если для вас это норм, то я даже и не знаю…eao197
29.12.2018 12:45-1Код с UB — плохой, и его быть не должно.
Имеем код:
Это код с UB. И вот в таком случае UB, действительно, происходит:int sum(int a, int b) { return a + b; }
А вот в таком, уже нет:int s = sum(numeric_limits<int>::max(), numeric_limits<int>::max());
int a = sum(some_value%100, another_value%100);
Код sum один и тот же, в нем UB присутствует. Но вот использование sum может как приводить к появлению UB, так и не приводить.
Из чего легко сделать вывод о том, что присутствие в коде UB не обязательно ведет к ошибкам в этом коде. Но ведь вы утверждаете, что обязательно приведет.
А это уже ППЦ и прямое указание, что вам следует программировать на Rust-е, т.к. в языках, которые за вами сопли не подтирают, вы отстрелите ноги не только себе. Вы это умудряетесь делать даже в C#.
Так что простите, но воспринимать вас всерьез уже невозможно.PsyHaSTe Автор
29.12.2018 13:02+2Код sum один и тот же, в нем UB присутствует. Но вот использование sum может как приводить к появлению UB, так и не приводить.
По размышлению пришел к выводу, что ситуация та же, что в unsafe расте. Так что да, ошибкой, наверное, не будет, но средств выразить на уровне языка "чувак, тут ты отвечаешь за качество результата" нет. В итоге, я могу думаю, что функция работает с любыми двумя интами, а по сути это не так.
Из чего легко сделать вывод о том, что присутствие в коде UB не обязательно ведет к ошибкам в этом коде. Но ведь вы утверждаете, что обязательно приведет.
Наличие UB означает, что можно легко отстрелить ногу, и всё. Если джун написал
int s = unknown_func(numeric_limits<int>::max(), numeric_limits<int>::max());, виноват он, или лид, который написал такуюunknown_func, и не вставил проверки инвариантов? И вне зависимости от того, кто виноват, придется потом тратить кучу времени на поиск того, почему иногда софтина падает.
Cerberuser
29.12.2018 12:37Нет, а серьёзно. Вызов этой функции является UB, на Ваш взгляд? Если да — то в чём здесь «ППЦ»? Если нет — то чем она принципиально отличается от оператора знакового сложения, кроме того, что не прописана в стандарте?
eao197
29.12.2018 12:51Вызов этой функции является UB, на Ваш взгляд?
Пожалуйста, перечитайте внимательно, то, что было написано. В коде есть UB, в коде есть ошибка. Но использование avg не обязательно будет приводить хоть к каким-либо проблемам.
ППЦ — это утверждение, что будет приводить обязательно.
Ну и, поскольку вы можете опять уйти в левые рассуждения про оптимизаторы, UB — это свойства кода. Это когда на конкретный код стандарт языка говорит разработчику: ты не знаешь, что у тебя произойдет при определенных условиях. А не знаешь потому, что гарантирование тебе точного результата на всех платформах либо невозможно, либо слишком дорого.
Компилятор может использовать UB в своих интересах. Причем компилятор-то точно знает, что будет делать код на конкретной целевой платформе. Так что UB — это не столько про компилятор, сколько про исходный код.Cerberuser
29.12.2018 12:53+2Если вызов функции является UB, то он обязательно приводит к проблемам — просто по определению UB.
eao197
29.12.2018 12:58Еще раз: код может содержать в себе UB. Знаковое целочисленное сложение — это наглядный тому пример.
Вызов этого кода не обязательно приводит к UB. Показанные выше примеры с функциями avg и sum тому подтверждение.
humbug
29.12.2018 13:03+1Человек, который использует библиотечную функцию, должен быть уверен, что всё будет хорошо. Функция выглядела бы обычно, если бы у нее были 2 версии:
unsafe int avg(const vector<int> & data) { return accumulate(begin(data), end(data), 0) / data.size(); }
checked_int avg(const vector<int> & data) { if (data.empty()) { exit_or_panic(); } checked_int acc = 0; // checked_int panics on overflow return accumulate(begin(data), end(data), acc) / data.size(); }
И пользователю давали выбор:
- по-умолчанию функция будет безопасна, проверит размер массива, паникует при переполнении (или бросает ошибку, или возвращает ошибку в стиле Rust/Go)
- небезопасный вариант, когда ты 100% уверен во входящих данных, но если подсовываешь во входные данные, на выходе получаешь UB
Я доступно объяснил?
eao197
29.12.2018 13:09-1if (std::distance(begin(data), end(data)) == 0)
Теперь понятно, откуда берется говнокод на C++, о котором вы постоянно говорите.humbug
29.12.2018 13:10:D да, тупанул. Это знатный говнокод, за который меня бы стоит уволить из когорты C++ разрабов. OH WAIT.
Тем не менее эта помарочка все, что вы можете сказать? Никакого прозрения не вызывает? Или так же в голове сплошная безнадега: "Раст плохой, потому что я же учил C++ 10 лет, я не могу выкидывать свой устоявшийся подход к решению проблем на помойку"?
PsyHaSTe Автор
27.12.2018 16:42Карму вам немного выправил. Давать минусы в неё, конечно же, не вижу оснований. В этом треде обсуждение крайне корректное.
Надеюсь, вы не потеряете желание продолжать диалог.
freecoder_xx
27.12.2018 22:35п.с. вообще неприятно вести с вами (растовиками) дискуссии. Вы пытаетесь навязать видение мира, в котором ни одна из программ на с++ не работает, а любая попытка его опровергнуть заканчивается ничем кроме пары минусов в карму.
Не знаю, о ком вы говорите и кто минусует. Лично я еще ни одного минуса "плюсовикам" не выдал. В плюсах разбираюсь слабо, поэтому обычно дискуссии Rust vs. С++ читаю c интересом. Так что обобщать и всех мазать одной краской, думаю, не стоит.
0xd34df00d
26.12.2018 18:44+2Можно взять C++, относительно дешево выучить его, писать проектики, а потом три месяца дебажить неопределенное поведение силами двух программистов с суммарным опытом в 20 лет
Потому что нельзя дешево выучить плюсы. Я начал их ковырять лет в 12, сейчас мне 27, все это время я практически ежедневно пишу код на плюсах и я скорее не знаю плюсы, чем знаю.
ReklatsMasters
26.12.2018 22:17На данном этапе не понимаю, как интегрировать Rust futures в Js Promise для асинхронного WebSocket, чтобы перенести свой проект из нативного приложения в WASM.
IO и всю асинхронщину выносите в js, а на wasm оставляете синхронную работу с данными. Боттлнеком может стать копирование в / из wasm, но я не уверен, нужно на реальном проекте смотреть.

emerald_isle
26.12.2018 23:18устал от HR, приглашают на работу и собеседования каждую неделю. Приходится вслушиваться в произношение людей из Шотландии и Новой Зеландии
приходится скрывать доходы от друзей, потому что зарплату в $$$ реально девать некуда.
Уговорили, rust то я давно начал изучать, всё никак серьёзно за него не возьмусь…
SQReder
29.12.2018 09:56Пора обновить старый стишок к новым реалиям
The code I see
Make sense to me
ButGCCrustc…
It disagrees
{kind=link}
VanquisherWinbringer
26.12.2018 16:05+2По началу, пока с владением не разобрались. Можно в неком подобии функционального стиля писать. Например вот пример функции для сложения и умножения в обоих стилях.
Код, лайфтаймы тут только для процедурного варианта. Если оставить только функциональный то их можно убратьuse std::ops::{Add, Mul}; use std::borrow::Borrow; enum Operation { Add, Mul, } struct Calculator<T> where { pub op: Operation, pub lhs: T, pub rhs: T, pub result: Option<T>, } impl<'a, 'b: 'a, T: 'b + Add<Output=T> + Mul<Output=T> + Borrow<T>> Calculator<T> where &'a T: Add<Output=T> + Mul<Output=T> { pub fn calculate_procedurally(&'b mut self) { let res: T = match self.op { Operation::Add => &self.lhs + &self.rhs, Operation::Mul => &self.lhs * &self.rhs, }; self.result = Some(res); } } impl<T: Add<Output=T> + Mul<Output=T> + Clone> Calculator<T> { pub fn calculate_functionally(mut self) -> Self { self.result = Some( match self.op { Operation::Add => self.lhs.clone() + self.rhs.clone(), Operation::Mul => self.lhs.clone() * self.rhs.clone(), } ); self } } #[cfg(test)] mod example { #[test] fn test_add() { let mut calc = self::super::Calculator::<isize> { op: self::super::Operation::Add, lhs: 2, rhs: 3, result: None, }; calc = calc.calculate_functionally(); assert_eq!(5, calc.result.unwrap()); } #[test] fn test_mul() { let mut calc = self::super::Calculator::<isize> { op: self::super::Operation::Mul, lhs: 2, rhs: 3, result: None, }; calc = calc.calculate_functionally(); assert_eq!(6, calc.result.unwrap()); } #[test] fn test_add_proc() { let mut calc = self::super::Calculator::<isize> { op: self::super::Operation::Add, lhs: 2, rhs: 3, result: None, }; calc.calculate_procedurally(); assert_eq!(5, calc.result.unwrap()); } #[test] fn test_mul_proc() { let mut calc = self::super::Calculator::<isize> { op: self::super::Operation::Mul, lhs: 2, rhs: 3, result: None, }; calc.calculate_procedurally(); assert_eq!(6, calc.result.unwrap()); } }
faiwer
26.12.2018 18:14В статье есть упоминание, что деревья, списки и др. конструкции тяжело кладутся на концепцию borrow-checking Вопрос: в итоге как эта проблема решается?
- списки и деревья просто не используются? не могу себе такого представить
- их сложнее реализовать, но всё же удобно использовать (как и в других языках)?
- их сложно не только реализовать, но и использовать? боль?
Просто, мне кажется, что вне зависимости от того, насколько они подходят под borrow-checking или нет, всё же без списков, деревьев и прочих базовых структур не может обойтись ни 1 императивный язык и ни 1 мало мальски сложная алгоритмически программа. За ФП не скажу. Как этот вопрос решается?
nexmean
26.12.2018 18:20Без unsafe их писать сложно. Использовать их чуть более удобно, чем в других языках без GC. До языков с GC удобство использования конечно не дотягивает.
На самом деле подобные рекурсивные структуры в императивных языках используются довольно редко, в системном программировании же ещё реже.
faiwer
26.12.2018 18:33+1На самом деле подобные рекурсивные структуры в императивных языках используются довольно редко
Ну не знаю. Вот в JS я практически 90+% времени работаю с деревьями. Я имею ввиду не бинарные древа поиска или что-то подобное. Но тасую туда-сюда данные пачками, вездесущие рекурсии, множество перекрёстных ссылок. В общем самые разнообразные безобразия с графами данных. В случае Rust я бы свихнулся?
Вот скажем взять модный нынче virtual-dom. Это большое древо элементов. Мутабельное. Типичная задача по работе с ним — бегать по нему и обновлять что-нибудь в его звеньях. Такое в Rust будет болезненным?
в системном программировании же ещё реже.
Я всегда думал, что в сис. программировании без серьёзных алгоритмов тебе даже дверь в офис не откроют. Что нужно уметь тасовать все известные и неизвестные структуры данных, переплетая их самым дивным образом. Это не так?
faiwer
26.12.2018 18:41js-codeconst tree = { a: { b: { c: 1 } } }; const b = tree.a.b; const inc = tree => { for(const [k, v] of Object.entries(tree)) if(typeof v === 'number') tree[k] += 1; else inc(v); }; inc(tree); b.c += 1; b.c; // 3mayorovp
26.12.2018 19:32До появления NLL вас бы и правда компилятор часто "бил по голове" на каждом шагу. Но с появлением NLL все стало куда проще.
freecoder_xx
26.12.2018 22:45+5В случае Rust у меня будут проблемы только если я захочу иметь возможность что-то мутировать одновременно? Но не будет если я передам ссылку на то, что мутирую, последовательно? Или вообще на каждом шагу компилятор будет бить меня битой по голове?
Вы не можете иметь изменяемую ссылку на структуру и ее внутренность одновременно, потому что это эквивалентно двум изменяемым ссылкам на структуру.
Если вам такое нужно время от времени, то вы можете вынимать значение из структуры с помощью
mem::replace, изменять его как отдельный объект вместе со структурой, а затем помещать измененное значение поля назад в структуру.
Если же вам такое нужно постоянно, то придется использовать контейнерные типы для внутренней изменяемости, такие как
RefCell:
use std::rc::Rc; use std::cell::RefCell; struct MyStruct { a: Rc<RefCell<i32>>, } fn main() { let a = Rc::new(RefCell::new(0)); let s = MyStruct { a }; let b = s.a.clone(); *s.a.borrow_mut() += 1; *b.borrow_mut() += 1; println!("{}", s.a.borrow()); }
Как вы можете видеть — это больно, но терпеть можно :)
Antervis
28.12.2018 14:56Допустим, у нас есть структура данных, за лайфтайм которой отвечает одна сущность (A), а за чтение/запись — другие (B, C, D). Предположим, я дал компилятору понять что A всегда переживет B,C,D и вопрос только в разделении мутирующих ссылок на B,C,D. Вы предлагаете Rc/Arc/RefCell — наипростейшее решение, но оно совершенно не эквивалентно разделению сырых ссылок в многопоточном приложении — Rc может выстрелить в ногу, а Arc/RefCell — существенно замедлить алгоритм. Получается выбор между повсеместным unsafe и стоимостью в рантайме и в подавляющем большинстве случаев выиграет первое. Я правильно понимаю что целый класс задач решается через повсеместный unsafe?
math_coder
28.12.2018 15:35+1Если у вас многопоточное приложение, то каким-то образом вы должны синхронизировать потоки. Именно это и делает
Arc, так что это, вообще говоря, не оверхед, а необходимая функциональность. Если же у вас какой-то свой хитрый способ синхронизации, то стоит подумать о передекомпозиции таким образом, чтобы явно выделить эту синхронизацию и инкапсулировать в неёunsafeы.Antervis
28.12.2018 17:42Arc не отвечает за синхронизацию доступа к объекту между потоками, а только за его удаление. Допустим, ответственность за лайфтайм я/компилятор взяли на себя.
Управляемый объект может быть организован так, что операции над ним потокобезопасны (например, обертка над библиотечным). Так зачем мне дополнительная прослойка?math_coder
28.12.2018 18:03+2Arc не отвечает за синхронизацию доступа к объекту между потоками, а только за его удаление.
Это детали. Может не
Arc, аMutex<Arc>или ещё что-то такое.
Управляемый объект может быть организован так, что операции над ним потокобезопасны (например, обертка над библиотечным).
Да, может. И в случае именно Rust от такого объекта ожидается, что эта его потокобезопасность будет выражена в API этого объекта. Потому что Rust содержит необходимые средства для этого. Если API объекта не сообщает компилятору, что его можно свободно мутировать, то вам придётся сделать над объектом обёртку с unsafe кодом. И дальше вы сможете работать с объектом через эту обёртку без обращения к
unsafe.
VanquisherWinbringer
26.12.2018 18:49+1Вот тут пример того как работают с dom в Rust, wasm фреймворк вдохновленный React и Elm — Yew
PsyHaSTe Автор
26.12.2018 21:01Вот скажем взять модный нынче virtual-dom. Это большое древо элементов. Мутабельное. Типичная задача по работе с ним — бегать по нему и обновлять что-нибудь в его звеньях. Такое в Rust будет болезненным?
В таком случае, я думаю, решение — сделать дерево иммутабельным, и менять целиком, как эти ребята из майкрософта.
А иметь больше мутабельное дерево в расте действительно будет неудобно, скорее всего.
freecoder_xx
26.12.2018 22:21+5Если вам не обязательно хранить ссылку на родителя в дочернем элементе, то реализация будет тривиальна.
В противном случае вам придется:
- Использовать
Rc,RefCellи прочиеWeak; или - Использовать сырые указатели и управлять освобождением памяти вручную; или
- Хранить узлы во внешнем контейнере и ссылаться на них по индексу; или
- Использовать готовые библиотеки, которые скрывают всю кухню за своим API.
Вообще, для лучшего понимания, рекомендую изучить реализацию rust-forest. Там представлено несколько подходов и они довольно неплохо прокомментированы.
Собственно, из-за чего вознрикает проблема с графовыми структурами?
Обычно, в них у вас есть некий объект и вы хотите хранить ссылки на него в нескольких местах одновременно. Но тут возникает сразу две проблемы:
Объект должен быть доступен из разных мест по ссылке, и удален только тогда, когда на него нет ссылок. Если есть по крайней мере одна ссылка, то объект должен жить.
Правила Rust позволяют иметь больше одной ссылки только на неизменяемый объект. Ссылка на изменяемый объект может быть только одна, без каких либо других ссылок на этот объект.
Первая проблема решается подсчетом ссылок (reference counting) и в других популярных прикладных ЯП она обычно скрыта от пользователя за реализацией. То есть любая "ссылка" на объект в таких ЯП всегда есть умный указатель со счетчиком ссылок. В Rust же такого типа ссылку нужно создавать вручную, если она вам нужна. Для этого используются типы
RcиArc. Кроме того, нужно как-то решать вопрос образования циклических ссылок, для чего используетсяWeak.
Вторая проблема решается введением совместно используемых изменяемых контейнеров — это типы
Cell,RefCell,Mutex,RwLock.
Соответственно, ссылки с типами вроде
Rc<RefCell<Node>>всех и пугают.
Для большего понимания я рекомендую прочитать вот эту страницу официальной документации и разобрать приведенный там пример с гаджетами для того, чтобы понять, для чего и как использовать
Rc,RefCellиWeakвместе. Также рекомендую ознакомиться с документацией по cell.- Использовать
PsyHaSTe Автор
26.12.2018 18:26+2Их сложнее реализовывать — нужно руками оборачивать в умные контейнеры Rc/Arc/RefCell/..., о чем я в статье упомянул, пользоваться соответственно слегка труднее, чем значением напрямую — нужно работать через АПИ умного указателя.
Наличие LinkedList в стандартной библиотеке говорит о том, что реализовать, конечно же, можно.
Так что по вашей классификации я бы склонился к пункту 2.VanquisherWinbringer
26.12.2018 18:54Скорее всего, эффективнее такое решать через unsafe — да и вообще, такие структуры надо из библиотек брать. Собственно во всех местах где я знаю используют библиотечные Линкед листы и такое прочее а не пилят каждый раз свои.
Ravager
26.12.2018 19:41и заканчивая скриптованием ежедневной рутины.
Я вас умоляю…
За редким исключением задача скрипта это запуститься, сделать рутину и сдохнуть, освободив память. Сколько там сожрется памяти и как быстро она освободится не играет особой роли. Тем более что скрипт может прожить в репозитории месяц и потом его выкинут за ненадобностью. Исключением здесь могут быть скрипты, лопатящие множество данных в течение продолжительного промежутка времени. Тут уже можно думать о ++ или расте.JekaMas
26.12.2018 20:48А python не зайдет? Со всеми клевыми numpy и pandas?
BlessMaster
28.12.2018 03:34Отлично зайдёт для многих задач, но в какой-то момент можно внезапно споткнуться о GIL и будет очень обидно, поскольку по остальным параметрам всё очень классно, а решить задачу так же красиво, как на Python, на чём-то другом будет достаточно нетривиально.
Например, будет большая модель данных, часть обработки/доставки этих данных придётся сделать на уровне Python, поскольку низкоуровневые библиотеки, умеющие работать параллельно в несколько потоков, именно такую обработку сделать не могут, и придётся искать решение вопросов в духе "где взять больше памяти" и "как эффективно синхронизировать между процессами большие объёмы данных".
PsyHaSTe Автор
26.12.2018 21:03В очередной раз говорю, что смысл раста не в том, какой он замечательно быстрый и экономный.
Ravager
26.12.2018 22:26А в чем тогда его киллер фича кроме жесткого компилятора в плане управления памятью, что для скрипта скорее минус чем плюс?
Порог вхождения высокий, меняющийся стандарт, отсутствие большого количества библиотек на все случаи жизни(в противовес питону например). Почему мне нужно взять раст для скрипта вместо питона например?PsyHaSTe Автор
26.12.2018 22:33+2А в чем тогда его киллер фича кроме жесткого компилятора в плане управления памятью, что для скрипта скорее минус чем плюс?
Даже для скрипта желательно чтобы он делал то, что ожидается. А плюс в том, что если я пишу скрипт на каком-нибудь python/powershell, я его запускаю тонну раз, и проверяю. А в данном случае если код скомпилировался, значит всё правильно. Можно для очистки совести прогнать разок на тестовых данных, но постепенно и это подспудное желание, вызванное опытом на других языках, проходит.
Порог вхождения высокий, меняющийся стандарт, отсутствие большого количества библиотек на все случаи жизни(в противовес питону например). Почему мне нужно взять раст для скрипта вместо питона например?
Скорее вместо го, потому что с питоном у раста те же преимущества, что у го, один бинарник без зависимостей, и вот это всё. Стандарт не меняется, а дополняется. Разница тривиальна: ваш код не ломается от того, что там кто-то новое выходит. Ну а требовать отсутствие новых фич в языке странно.
С библиотеками — да, пока не очень густо, но для скрипта как раз-таки это не проблема, т.к. обычно его задача что-нибудь скачать посчитать, и выдать результат в консоль. Много зависимостей для этого не нужно.
И да, я не безумный фанатик, который предлагает совать раст везде, где ни попадя.
Я просто говорю, что говорить "так, нам производительность не важна, так что С, С++ и раст отпадают" некорректно, и потенциально вы теряете более удобный инструмент, чем тот, на котором в итоге остановитесь. Возможно, оценив раст вы найдете его неподходящим для задачи — ну и ладно, я только за использование правильных инструментов. Но, как говорится, сначала хотя бы дайте шанс, не отметайте с порога, не разобравшись, от чего собственно отказываетесь.
Я считаю, что главное в языке — фундамент и коммьюнити, а слава и библиотеки приходящи. Да, бывают гениальные языки в статусе вечной беты, не доведенные до ума, но раст сейчас больше походит на шарп в начале нулевых: темная лошадка, которая только что появилась, но чертовски привлекательная. Мы, разработчики, являемся той силой, которая нужна любому языку для существования. Если бы весь хабр взял и выучил раст, то уже на завтрашний день была бы тонна вакансий на этот язык, потому что растовые лиды искали бы себе в команду растовых синиоров и мидлов, чтобы писать библиотеки, чтобы привлекать новых людей и так далее. Спрос рождает предложение, но этот спрос формируем мы сами, когда менеджер спрашивает "кого тебе в команду не хватает, чтобы сделать новый проект У? Отдай HRам заявку до конца недели, пожалуйста".
Цель статьи как раз показать, что раст не такой страшный, а в перспективе увеличить количество людей, на нем программирующих, чтобы вместе решать проблемы на языке, который хорошо подходит для их решения.
JekaMas
26.12.2018 23:26Если мне нужна безопасность, то почему не Haskell? В несколько раз лаконичнее, выразительнее и безопасный.
PsyHaSTe Автор
26.12.2018 23:42Тоже хороший вариант. У них разные трейдофы, поэтому зависит от задачи. Например, хаскель поможет отловить эффекты и IO всякие, зато раст защитит от потенциальных косяков в многопотоке. Я хаскель честно не осилил, может когда-нибудь на него тоже буду посмотреть.
0xd34df00d
27.12.2018 01:18зато раст защитит от потенциальных косяков в многопотоке.
Которые в хаскеле у вас принципиально не получится сделать, система типов тоже защищает.
А в случае STM вам ещё придётся очень сильно постараться, чтобы получить дедлок (я в своё время на спор пытался сконструировать пример и не смог).
PsyHaSTe Автор
27.12.2018 11:27Которые в хаскеле у вас принципиально не получится сделать, система типов тоже защищает.
Года пол назад видел обсуждение на ycombinator'е или где-то еще, как раз от хаскеллистов, что раст решает один класс проблем, а хаскель — другой, и в некотором степени они ортогональны. Могу поискать, если сильно интересно. Но вообще выходило, что в хаскелле отстрелить себе ногу вполне можно. Речь как раз про IO была и некоторые другие вещи, насколько я помню.0xd34df00d
28.12.2018 23:23Ну, если вдруг наткнётесь — было бы интересно.
С IO (тем более, с
unsafePerformIO,unsafeDupablePerformIOи в особенности с забавной accursedUnutterablePerformIO) можно очень эффектно ноги отстреливать, да. По последней ссылке есть примеры.Ryppka
29.12.2018 13:27Знание польского делает unsafeDupablePerformIO несколько двусмысленным))) Не смог терпеть)
Ravager
26.12.2018 23:49А в данном случае если код скомпилировался, значит всё правильно.
что правильно? что память не утечет? или что вместо ожидаемого целого не придет строка? большинство проблем возникает из-за логических ошибок и никакой ЯП тут не помощник. конечно статическая типизация тут имеет свои преимущества, но чем конкретно раст в скриптах тут помогает мне непонятно.
С библиотеками — да, пока не очень густо, но для скрипта как раз-таки это не проблема, т.к. обычно его задача что-нибудь скачать посчитать, и выдать результат в консоль. Много зависимостей для этого не нужно.
скрипты скриптам рознь. нужно работать с изображениями, пдф, excel файлами и базой. что-то посчитать и вывести тут хоть что бери.
Я считаю, что главное в языке — фундамент и коммьюнити, а слава и библиотеки приходящи.
главное в языке это иметь киллер фичу, которая окажется востребованной и / или компания которая будет продвигать все это. Есть го и горутины с каналами как киллер фича. почему я должен взять раст и начать писать на нем?
Давайте оставим в стороне истории что если программа скомпилировалась то она корректна. Я каждый день чиню баги в проде, и там отнюдь не проблемы с памятью и ошибки типизации.
В бэкэнде проблема памяти на сервере не особо кого-то беспокоит, память сейчас дешевая и проще докупить плашку памяти чем тратить х2 времени разработки. Большие компании тоже не перейдут на раст ибо легаси и отсутствие библиотек. Остаются только игроделы( и то под вопросом) и энтузиасты.PsyHaSTe Автор
27.12.2018 00:30большинство проблем возникает из-за логических ошибок и никакой ЯП тут не помощник.
Конечно, помощник. Вопрос только в том, насколько полно вы воспользуетесь системой типов. Это уже не раз обсуждалось, из недавнего в этой статье.
скрипты скриптам рознь. нужно работать с изображениями, пдф, excel файлами и базой. что-то посчитать и вывести тут хоть что бери.
Это да. Тогда раст не подходит, и берем что-то другое.
главное в языке это иметь киллер фичу, которая окажется востребованной и / или компания которая будет продвигать все это. Есть го и горутины с каналами как киллер фича. почему я должен взять раст и начать писать на нем?
Борручекер такая киллерфича. Ни один мейнстрим язык не защитит вас от проблем с многопоточностью на уровне типов. Даже хаскель так не умеет.
Давайте оставим в стороне истории что если программа скомпилировалась то она корректна. Я каждый день чиню баги в проде, и там отнюдь не проблемы с памятью и ошибки типизации.
В бэкэнде проблема памяти на сервере не особо кого-то беспокоит, память сейчас дешевая и проще докупить плашку памяти чем тратить х2 времени разработки. Большие компании тоже не перейдут на раст ибо легаси и отсутствие библиотек. Остаются только игроделы( и то под вопросом) и энтузиасты.
Давайте. 80% багов, которая я когда-либо чинил, были связаны с нуллами, неявными приведениями, и комбинацией этих двух вещей. Раст обе проблемы решает радикально. Из остальных процентов 15 это бросили эксепшн, который не ожидался, и который никто не собирался ловить. Ну и 5% на все остальные случаи.
Большие компании тоже не перейдут на раст ибо легаси и отсутствие библиотек. Остаются только игроделы( и то под вопросом) и энтузиасты.
Ту же историю я помню лет 20 назад, только надо поменять раст на джаву, а под популярным языком иметь в виду COBOL0xd34df00d
27.12.2018 01:20Борручекер такая киллерфича. Ни один мейнстрим язык не защитит вас от проблем с многопоточностью на уровне типов. Даже хаскель так не умеет.
Вам не нужно защищаться от конкуретной модификации данных, если у вас нет модификации данных :]
nexmean
27.12.2018 05:18+1Но есть же [в IO].
0xd34df00d
27.12.2018 05:32IO — это такой unsafe, по большому счёту.
asdf87
27.12.2018 06:32Какой выход/вывод? Забить на IO, потому что он «unsafe» в хаскелевом смысле?
0xd34df00d
27.12.2018 06:38Минимизировать количество кода, живущего в монаде IO.
И это вполне реалистично сделать в контексте трединга. TMVar всякие там, например. Ну или хотя бы MVar использовать вместо IORef, по последнему хотя бы прогрепать можно.asdf87
27.12.2018 07:01Что это? Упрощенная форма CSP? Только флажком коммуницируем между параллельными потоками? Расшаренный стейт вообще нельзя? А что если, у меня например большой стейт в памяти и я хочу к нему периодически обращаться из нескольких потоков, но при этом держать его копию для каждого потока это много. Как тогда быть?
eao197
27.12.2018 12:1280% багов, которая я когда-либо чинил, были связаны с нуллами, неявными приведениями, и комбинацией этих двух вещей.
Да вам можно просто позавидовать.PsyHaSTe Автор
27.12.2018 13:23+1Еще хорошей пример — байка про то, как я ловил баг в Linq2Sql. У нас были тесты, которые проверяли весь функционал. И баг, который в тестах не воспроизводился. У клиента был чек на 1000 рублей, была скидка 0 рублей, в итоге ему выставлялся счёт в 0 рублей. Начал разгребать, оказалось, искал много дней баг, наконец нашел. Дело в том, что у нас был запрос вида
var dicsount = GetClientDiscount().Where(x=>SomeCondition(x.SomeField)).Sum(); var totalPrice = price - discount
И если у чувака не было скидок, то LINQ возвращает 0
Только вот когда идет запрос в БД, то ёSELECT SUM(SomeField) from T where SomeConditionё возвращает для пустого множетсва ответов
null.
а дальше всё просто
var discount = null var totalPrice = 1000 - null // null
Дальше
nullпри конверсии при печати превращался в 0 и мы имели тот результат, что имели.
Понятное дело, что это была катастрофа, ведь тесты не могли проверить ничего. Они показывали, что мы обрабатываем ситуацию с пустым множеством скидок, а по факту это было не так.
В итоге я написал рерайтер SumExpressionVisitor, который применял преобразование к дереву, и везде заменял
query.Sum(x=>x.Foo)наquery.NullIfEmpty()?.Sum(x=>x.Foo). Там же кстати пример с тем, как я использовал для тяжелых запросов Like так, чтобы в тестах отрабатывало.
Большинство проблем и решений в моем шарповом опыте выглядит как-то так, да.
С логикой обычно проблем нет, потому что на неё пишутся тесты. А вот на неявную конверсию null -> 0 и различие поведения in-memory DB и реальной — увы.
eao197
27.12.2018 13:28А покажите пример этого же кода на Rust-е, плиз.
PsyHaSTe Автор
27.12.2018 13:31ну взаимодействие с БД нам в данном контексте не сильно интересно, а вот в этом месте:
let discount: Option<i64> = None; let totalPrice = 1000 - discount; // no implementation for `{integer} - std::option::Option<i64>`mayorovp
27.12.2018 14:04Ну хорошо, я напишу вот так:
let totalPrice = match discount { Some(v) => 1000 - v None => None }
Стало лучше? :-) Ошибка-то, на самом деле, в логике запроса и в логике печати...
Каким вообще образом у вас получилось получить для linq to objects-запроса тип
int, а для linq to sql — типint??PsyHaSTe Автор
27.12.2018 14:09Стало лучше? :-) Ошибка-то, на самом деле, в логике запроса и в логике печати...
Стало, потому что
а) есть явная обработка null-а
б) вы бы не смогли это вывести на печать:
let discount: Option<i64> = None; let totalPrice = discount.map(|x| 1000 - x); println!("Общая стоимость: {}", totalPrice); // `std::option::Option<i64>` cannot be formatted with the default formatter
В общем, добавляется как минимум 2 места, где скорее всего была бы вставлена корректная обработка этой ситуации.
eao197
27.12.2018 14:07-1ну взаимодействие с БД нам в данном контексте не сильно интересно
Ошибаетесь, там все интересно, в том числе и проброс ошибок. Кроме того, даже показанный вами пример — это и не пример вовсе. Поскольку получив такую ошибку от компилятора разработчик написал бы что-то вроде
Компилятор был бы удовлетворен, а вот корректен ли был бы такой код и устно ли было бы применение значения 0 — это отдельный вопрос.let discont = GetDiscount(...); let totalPrice = 1000 - discount.value_or(0);
У меня поверхностные впечатления от C#, но, ИМХО, вы бы там могли бы иметь тоже самое. Какой-нибудь NullableValue и писали бы что-то вроде:
NullableValue<Int> discount = GetClientDiscount()...; var totalPrice = 1000 - discount.ValueOr(0)
И, по сути, ваша претензия сводится к тому, что в C# вам приходится пользоваться API, в котором нет Option или чего-то подобного. Хотя язык этому и не препятствует.PsyHaSTe Автор
27.12.2018 14:13+1Компилятор был бы удовлетворен, а вот корректен ли был бы такой код и устно ли было бы применение значения 0 — это отдельный вопрос.
Ну так это и является фиксом бага. Если скидок — нет, то сумма скидки — ноль. Если бы так было написано, всей проблемы вообще не было бы.
У меня поверхностные впечатления от C#, но, ИМХО, вы бы там могли бы иметь тоже самое. Какой-нибудь NullableValue и писали бы что-то вроде
Nullable<decimal>там и был :) Только вот из-за всяких неявных кастов и того, что они не являются объектами первого класса во многих случаях (а также из-за различий reference/value types) получается фигня.
И, по сути, ваша претензия сводится к тому, что в C# вам приходится пользоваться API, в котором нет Option или чего-то подобного. Хотя язык этому и не препятствует.
Это просто еще камешек в огород, чего мне в шарпе не хватает. А отвечал я на то, какие баги я в шарпе чинил, которых в расте бы не возникло. Вы задали вопрос "а на что там 80% времени уходит", я показал конкретный пример из реального проекта.
В шарпе эту проблему собираются решать на уровне варнинга линтера, но это будущее, и не такое уж прекрасное. Приятнее иметь жесткую проверку компилятора, а не просто опциональную атрибуцию.
eao197
27.12.2018 14:18Вы задали вопрос «а на что там 80% времени уходит»
Я не задавал такого вопроса, вы путаете. Я сказал о том, что если у вас 80% ошибок — это null и неявные преобразования, то вам можно только позавидовать. И пока что остаюсь при мнении, что основная работа у вас из категории «не бей лежачего».
Ravager
27.12.2018 12:52Давайте. 80% багов, которая я когда-либо чинил, были связаны с нуллами, неявными приведениями, и комбинацией этих двух вещей. Раст обе проблемы решает радикально. Из остальных процентов 15 это бросили эксепшн, который не ожидался, и который никто не собирался ловить. Ну и 5% на все остальные случаи.
у меня совершенно другая статистика. 80% проблем это логические ошибки вроде забыли в ответ прокинуть какое-то поле. или не учли какой-то вариант входящих данных. или другой сервис отдал какую-то херню вместо json. или написали кривой запрос в бд. может быть у вас сервисы не очень сложные которые не ходят во внешние сервисы или БД?PsyHaSTe Автор
27.12.2018 13:24Я чуть выше ответил, на другой комментарий в этой же ветке. На логику пишутся тесты, а форматы общения обычно согласованы и не меняются без ЧТЗ, или хотя бы уведомления в телеграм и джиру.
написали кривой запрос в бд
на ORM трудно написать кривой запрос. Можно написать неоптимальный, но оптимизация производительности != починка бага.
Salabar
27.12.2018 11:07+2большинство проблем возникает из-за логических ошибок
Логических ошибок можно не совершать хотя бы в теории, а тупая лажа в духе инвалидации итераторов — это штука, с которой ты рано или поздно столкнешься вне зависимости о того, каким клёвым программистом ты себя считаешь.Ravager
27.12.2018 12:39-1Логических ошибок можно не совершать хотя бы в теории
в теории можно писать идеальный код, который сразу компилируется и сразу работает как надо на любом языке. но почему-то никто не пишет.
VanquisherWinbringer
27.12.2018 22:27+2Так для справки — «зеленые потоки» т. е. проще говоря пул потоков ОС с шедулером уже несколько лет не «киллер фича Go» потому что другие языки тоже развивались знаете ли. Да в далеком 2009 году это была «киллер фича». Мы через несколько дней в 2019 будем. С наступающим кстати. Макросы, Борров чекер и лайфтайм, единый бинарник, скорость сравнимая с С\С++, отстуствие рантайма что в результате позволяет его таки адекватно в wasm использовать. У Rust wasm файл меньше мегабайта получается в отличии от Go у которого хеллоу ворд весит несколько мегабайт потому что шедулер, gc вот это все надо тащить с собой. + Та же мощь что и у C\C++ т. е. можно хоть свою операционную систему написать на Rust. Вообще мне нравиться С просто он слишком опасный по сравнению с Rust поэтому мой выбор Rust. Мне мои нервы дороже.
farcaller
26.12.2018 23:51+1один бинарник без зависимостей, и вот это всё.
го настолько упоротый что от libc не зависит в отличие от раста, который иногда боль собрать под musl и очень боль кросс-собрать в принципе если приплыл openssl в зависимостях.
PsyHaSTe Автор
27.12.2018 16:12Ну это прикольно, да.
Хотя я не могу представить реальной ситуации, где мне это бы создало какую-то ценность. Для кого-то независимость от libc киллер-фича, возможно.
В любом случае, хорошо, что есть язык, который заполняет эту нишу.
Ryppka
27.12.2018 17:08Ну да, каждая платформа свои глибцы хвалит))) Иногда думаешь: вот бы Д. МкЛауд среди них появился…
farcaller
27.12.2018 20:54+2Го настолько упорот что не использует libc на OS X где кроме libc стабильных api нет :) полгода назад пробегала баженька что все гошные бинари разом сломались на свежем релизе макоси потому что там что-то в ядре поменяли.
freecoder_xx
26.12.2018 23:03+2Развитая статическая система типов с автоматическим выводом и удобное управление зависимостями. Для скриптовых целей — минимализм и удобство, близкое к динамически типизированным языкам, но с сохранением строгой статической типизации. Для некоторых — это недостаток, для других — киллер-фича.
freecoder_xx
26.12.2018 22:59+1Я использовал в своем Rust-проекте небольшие скрипты, написанные на Rust. Довольно удобно, когда с растом освоился и вникать в питоновские либы нет ни времени, ни желания.
math_coder
27.12.2018 00:31Что-то больно у вас легко всё.
Пробовали ли вы написать на Rust функцию, которая принимает функцию, которая принимает функцию? И чтобы первая функция упаковывала переданную ей функцию вглубь структуры данных для последующего неоднократного коллбэка. И потом вызвать всё это с хитрыми замыканиями. Я пробовал, и код получается весьма перегруженный лайфтаймами и тому подобным. Не скажу, что результат неприемлем — совсем нет — но достаточно громоздок, чтобы начать избегать передавать функции в функции.
Использовали ли вы
RefCell? АMutex? АMutex<RefCell>? А сочетание всего этого сOption? Код, который в C# или там Python выглядел бы какa.b().cначинает выглядеть примерно какa.lock().unwrap().b().as_ref().unwrap().c
На Rust действительно приятно писать код. Он действительно является привильно сделанным Си. Это всё правда. Но если вы можете конкретную штуку написать на чём-то другом — ну, например, F# — лучше писать на другом. Возможно, вы получите меньше удовольствия, но код точно будет существенно короче.
PsyHaSTe Автор
27.12.2018 00:41- Нет, мне всегда хватало первого уровня вложенности. Я вообще стараюсь не писать ничего хитрого, чтобы поддерживать смог достаточно прошаренный джун или обычный миддл-разработчик.
- Использовал. И такого кошмара там не происходит. В C# вы бы писали
lock(_lock) { return a.b().c; }
а в расте будет
a.lock().unwrap().b()?.c
Не сказал бы, что тут больше писать приходится.
И, кстати, в вашем C# коде ошибка, потому что если b() вернет null, то вы получите NullReferenceException в рантайме.
math_coder
27.12.2018 01:27Нет, в C# lock мне писать бы вообще не пришлось. В смысле я бы скорее всего вообще не сообразил, что он нужен. Получился бы ошибочный, но короткий код, при этом ошибка в реальности воспроизводилась бы редко, а то и вообще никогда.
если b() вернет null, то вы получите NullReferenceException в рантайме
Всё правильно, там и должен быть NullReferenceException. В чём ошибка?
justboris
27.12.2018 02:03+3Получился бы ошибочный, но короткий код, при этом ошибка в реальности воспроизводилась бы редко, а то и вообще никогда
Будущие разработчики, которым выпадет искать и чинить эту ошибку, скажут вам большое "спасибо" за такую практичность.
math_coder
27.12.2018 02:06+1Да, и это очень круто, что Rust ловит такие вещи на этапе компиляции — с этим спорить сложно.
dempfi
27.12.2018 01:32+1Чем сложнее язык, тем богаче фразы, составленные с его помощью, и тем лучше он может выразить требуемую предметную область.
Спорное утверждение про зависимость между сложностью и выразительностью. Кажется, что сложность языка и его выразительная мощь ортогональны. (G)ADT, к примеру, очень простая штука, дающая ощутимый буст к выразительной мощности.
PsyHaSTe Автор
27.12.2018 11:36+1Определенно есть положительная корреляция. Любая новая фича требует как минимум места в голое для запоминания. А если у неё еще и свой синтасксис, то тем более.
Если у вас есть специальный цикл в обратном порядке
(n downto 1), то это более выразительный способ выразить идею "получить номера от n до 1", а вот(1 to n).reverse()будет менее наглядным, но более стандартным.
Есть определенная стоимость фичи, и польза, увеличивающая выразительность. В данном случае она выросла незначительно (но всё же выросла), поэтому такую фичу я припомню только в паскале.
Cerberuser
27.12.2018 11:56Синтаксис наподобие `n:-1:1` а-ля MatLab считается? Или здесь выразительность как раз страдает, потому что общую конструкцию (для цикла с произвольным шагом) натягивают на частный случай?
PsyHaSTe Автор
27.12.2018 13:27Тут легко можно считать. Если информационная энтропия кода выше, то в нем больше абстракций, и его сложнее учить, но он выразительнее.
Тут та же проблема, что и с оптимальным кодированием: чем больше основание системы счисления, тем меньше нам надо цифр для кодирования чисел, но тем больше алфавит СС.
dempfi
27.12.2018 12:32+1Понял теперь вашу мысль и согласен — если все решается через синтаксис языка, то сложность и выразительность будут тесно связаны.
Определенно есть положительная корреляция. Любая новая фича требует как минимум места в голое для запоминания. А если у неё еще и свой синтасксис, то тем более.
Есть языки в которых нет операторов прибитых гвоздями в компиляторе. Вместо них используется уже известные функции + инфиксная нотация, что запомнить легче чем кучу операторов с разными правилами. И при этом с ними можно описать сильно больше явлений. Вот и получили простоту с большей выразительной мощью.
И, если нигде не сделал логических ошибок, самые выразительные языки имеют минимум синтаксиса и правил, по факту оперируя несколькими довольно простыми концепциями (Haskell какой-нибудь или Clean).
PsyHaSTe Автор
27.12.2018 13:29Есть языки в которых нет операторов прибитых гвоздями в компиляторе. Вместо них используется уже известные функции + инфиксная нотация, что запомнить легче чем кучу операторов с разными правилами. И при этом с ними можно описать сильно больше явлений. Вот и получили простоту с большей выразительной мощью.
Операторы — это просто более удобная запись функций. В том же расте вы просто реализуете трейт Add/Mul/Div/..., а дальше можете пользоваться
a.add(b)наравне сa + b. Операторы просто удобнее читать. Прибитые гвоздями операторы (Как в C# например) это действительно не очень.
И, если нигде не сделал логических ошибок, самые выразительные языки имеют минимум синтаксиса и правил, по факту оперируя несколькими довольно простыми концепциями (Haskell какой-нибудь или Clean).
Да, расширяемая контекстно-независимая (по возможности) грамматика это прекрасно. Но сахара тоже хочется.
DarkWanderer
28.12.2018 23:35Про C# неправда — операторы не прибиты, их вполне можно перегружать, аналогично C++.
Или я не очень понял о чём речь — потому что на мой взгляд, разницы между add(a,b) и operator+(a,b) абсолютно никакой, если в результате и то и то будет использоваться как a+bPsyHaSTe Автор
29.12.2018 02:06Их можно перегружать, но нельзя написать
T Sum<T>(T[] items) where T : Add<T>
Или я не очень понял о чём речь — потому что на мой взгляд, разницы между add(a,b) и operator+(a,b) абсолютно никакой, если в результате и то и то будет использоваться как a+b
В этом и разница. По операторам невозможны генерики/полиморфизмы. Нельзя сделать
Vec<dyn Add<i32>>как в расте, и пихать разные объекты, которые умеют складываться с i32, и написать какую-то общую фунцкцию обработки, и вот это всё.
Из-за этого в LINQ миллиард методов Sum для всех числовых типов, а можно было бы ограничиться одним генериком.
amarao
27.12.2018 07:01+3Во-первых, я предлагаю убрать из рассмотрения haskell, который хочет оставаться академическим языком и в индустрию его тянут отдельные фанаты.
А во-вторых, самое важное: по моим ощущениям Rust — первый язык, который решил попробовать «с другой стороны». Все предыдущие языки (может быть, за вычетом лиспо-ml'ной школы) подходили с вопросом «как мне сделать X?». В ответ на разные X разные языки предлагали разные ответы.
Rust же подходит с вопросом «как мне НЕ сделать Y?», где в Y — все ужасы неопределённого поведения C, плюс чуть-чуть других гадостей.
Из этого подхода возникает другая ситуация: Rust предлагает такую модель памяти (точнее, весь комплект из borrow/lifetimes), который запрещает делать то, что известно, что плохо. Плюс фантастически педантичная система типов (float не является полностью упорядоченным типом). Так что работа с растом подразумевает подстраивание под компилятор. В замен это обещает безопасность кода без специальных усилий.
Эта революция для тех, кто никогда не сталкивался с линтерами. Те, кто сталкивался, могут вспомнить: linter надо ублажать. Ублажаешь — в коде благодать.
Вот Rust — это такой агрессивный и обширный линтер, встроенный в язык. Линтер, который цепляется не к пробелам, а к типовым ошибкам в дизайне приложений. Прорвался через «линтер» — получил благодать.

no_like
27.12.2018 11:17+3IMO: Cложность написания структур, решится реализацией структур в отдельных библиотеках, ака java.util.Collections, что решит проблему быстрого написания онных с нуля.
Язык перживает основной этап становления на ноги, многи типовые задачи/решения переписываются на него для дальнейшего использования (ORM фраемворки, web фраемворки, Webassembly и тд.)
Ну и конечно же хотелось бы отметить, что в новом году, Rust сообщество также сосредоточится над реализацией async/await концепции.
На мой взгляд, у Rust есть все шансы стать языком следующего поколения.
fukkit
27.12.2018 12:06-4Не уверен, верно ли считать универсальным языком тот, на котором некоторые алгоритмы не возможно реализовать в принципе, и которому не все структуры данных подходят.
Раст заставляет выдумывать доказуемо безопасные (по памяти) алгоритмы. Такая огороженность в некоторых проектах безусловно идет на пользу делу.
Чем дальше от дешевого и медленного железа, ограниченных ресурсов или полётов на Марс, тем меньше потребности в педантичной слежке за памятью и ручном управлении ею.
Во многих случаях дешевле упасть на первой серьезной ошибке, или пройтись GC по мертвым объектам раз в N минут, или профайлером выявить пару утечек в конкретной реализации, или прибить контекст по завершению выполнения, нежели тратить бюджеты на пляски с бубнами вокруг формальных доказательств владения каждым куском памяти.
В любом случае, ждем пока хипстеры соберут основные грабли и устаканят спеки, придумают как закодить связанный список и прочие нетривиальные вещи. Объемы работ и бюджеты по приведению в порядок авгиевых конюшен визионеров, преждевременно поставивших в продакшен поделки на расте, практически, обеспечены. Так что, изучать язык — обязательно!red75prim
27.12.2018 13:10+1нежели тратить бюджеты на пляски с бубнами вокруг формальных доказательств владения каждым куском памяти
Вообще-то, ни один язык хоть немного ориентированный на практическое применение не требует доказательств всего и вся. В Rust это —
unsafe, в Agda —trustMeи т.д.
Хотя доказательство корректности вполне себе полезное дело — позволяет превентивно избежать некоторых плясок с
бубнамиотладчиком в 3 часа ночи пока сервис лежит. Попытка доказать корректность некорректной системы позволяет найти нетривиальные дыры, которые могут проскочить через батареи тестов, fuzzer'ы, санитайзеры, code review и т.п.
PsyHaSTe Автор
27.12.2018 13:41Чем дальше от дешевого и медленного железа, ограниченных ресурсов или полётов на Марс, тем меньше потребности в педантичной слежке за памятью и ручном управлении ею.
То есть, если у нас быстрое железо, то на корректность можно забить? Ну придет пользователю от 0 до 3 емейлов вместо ровно одного, ну так и ладно.
Корректность программы с GC и ручными управлением памяти не связано от слова никак.
Не уверен, верно ли считать универсальным языком тот, на котором некоторые алгоритмы не возможно реализовать в принципе
хмм, это как? Я уверен, что раст — тьюринг-полный язык, а значит изоморфен любым другим таким же языкам. Я помню, в университете тезис Черча проходили, из него следует, что на расте можно написать любую вычислимую функцию.
math_coder
28.12.2018 12:42+4Это известный миф про Rust. Рациональная основа мифа состоит в том, что некоторые структуры данных, например, двусвязный список, проблематично реализовать без использования
unsafe.
Иррациональная же (собственно мифологическая) часть — это то, что если вы в Rust-программе использовали
unsafe, то это, якобы, неправильно. Возможно, играет роль схожесть ключевого слова сunsafeC#/.NET, которое и в самом деле является не столько частью языка/платормы, сколько расширением, и по-умолчанию недоступно.
Но в Rust
unsafe— неотъемлимая часть языка, и есть немало сценариев, когда использованиеunsafeкода абсолютно нормально и не является признаком пахнущего кода. Реализация базовых контейнеров в их числе.Cerberuser
28.12.2018 13:05+2Я от себя добавлю такое простое наблюдение. `unsafe` в библиотеке — это норма жизни, именно потому, что в некоторых случаях иным образом не удастся реализовать удобную функциональность. `unsafe` в пользовательском коде — либо признак, что используемых библиотек недостаточно, либо признак, что сам этот код реализует какую-то нестандартную возможность. Не претендую на истину, но пока всё выглядит именно так.
mayorovp
28.12.2018 13:41+1Да нет никакой семантической разницы между unsafe в C# и unsafe в Rust. В обоих случаях это слово позволяет случайно нарушить внутренние инварианты языка, которые обычно гарантируются компилятором и рантаймом.
И используется оно одинаково: внутри изолированного набора подпрограмм, для которых внеязыковыми средствами доказывается правильное поведение во всех случаях.Ryppka
28.12.2018 15:01В C# unsafe дает доступ к возможностям/синтаксическим конструкциям, недоступным в языке без unsafe.
math_coder
28.12.2018 18:26Идеология разная. В случае C# есть контекст, где использовать
unsafeнельзя, в случае Rust такого нет. То есть в C# разделение на safe и unsafe используется для безопасности, а в Rust — исключительно для удобства программиста.eao197
28.12.2018 19:25То есть в C# разделение на safe и unsafe используется для безопасности, а в Rust — исключительно для удобства программиста.
Т.е. вы сейчас всерьез утверждаете, что в Rust-е разделение на safe и unsafe — это не для безопасности? O_omath_coder
28.12.2018 20:08Для безопасности, но только как следствие корректности: в Rust нет различия между корректным safe-кодом и корректным unsafe-кодом, просто корректный safe-код писать легче. А в C# есть ещё всякие security level и тому подобные рантайм-механизмы, из-за которых сборка, содержащая unsafe код, принципиально отлична от не содержащей такового, даже если unsafe код корректен и даже если он вообще ничего не делает.
eao197
28.12.2018 20:19А в C# есть ещё всякие security level и тому подобные рантайм-механизмы
Не уверен, что это свойство именно языка C#, а не .NET-а в целом (емнип, там вообще без разницы, из какого исходного языка сборка была получена).
Поэтому если брать в рассмотрение только сам язык, то ваше утверждение «для безопасности, но только как следствие корректности» довольно трудно перевести на нормальный язык.math_coder
28.12.2018 20:23Ну конечно речь о платформе. Но тут одно от другого почти неотделимо.
PsyHaSTe Автор
29.12.2018 02:11Вы зря спорите. У unsafe в этих языках есть общие черты, и есть различия. Что представляет собой тот и другой, думаю, все и так знают. А рассуждать, что слон больше похож на змею или на колонну это дело такое :)
Ну конечно речь о платформе. Но тут одно от другого почти неотделимо.
Вполне отделимо. C# развивается с каждым годом, выходят новые версии.
Рантайм же не менялся с введения генериков 13 лет назад.
Ryppka
29.12.2018 13:31Думаю нет, для использования ассембля с небезопасным кодом пользователю нужны определенные права. Когда .NET только вышел, все ржали над тем, что с сетевой шары запустить менеджед код нельзя, а нативное приложение (которое вообще все что хочешь может) — можно. Безопасность имени МС — под фонарем у нас все в порядке, а темные углы — это не к нам.))))
mayorovp
28.12.2018 20:19В песочнице .net запрещен не только unsafe, но и огромная часть стандартной библиотеки…
helgihabr
Нормально так набросили.
Признайтесь, вы специально? )PsyHaSTe Автор
Не знаю, в чем тут наброс. Я действительно считаю, что раст форсится исключительно как "Better C", который "такой же быстрый, но безопасный". И совершенно игнорируют тот факт, что это хороший язык общего назначения, на котором и микросервисы серверлесные можно делать, и другие интересные штуки. Все знают, что крутую распределенную систему можно быстро и удобно сделать на Akka, а вот что есть точно такой же фреймворк для раста (
actix), в котором точно так же удобно можно всё сделать на расте — уже нет.Я правда считаю, что раст продуктивный, и что его производительность — это хорошая, но далеко не единственная черта.И во многих случаях ей можно пожертвовать, получим очень простой и изящный код. В случае с тем же ботом у меня ~3-4 сетевых запроса на каждый пост пользователя: сначала обработка самого сообщения, затем запрос урлов файлов, затем запрос контента файлов, и потом еще и отправка сообщения в телеграм. Сколько относительно этого ест клонирование единственной строковой переменной?
С появлением async/await (уже есть в ночнике, я бота его недавно на него переписал) должна отойти самая насущная на сегодняшний день проблема, неудобный async IO на коллбеках. А других серьезных проблем, способных помешать продуктивно писать код, я не вижу. После некоторой практики на расте можно писать с той же скоростью, что и на C#, но получать намного более серьезные гарантии корректности. Да, эту практику нужно набить, но как я уже сказал в статье, "тяжело в учении — легко в бою", вы учите концепцию один раз, и дальше это как езда на велосипеде, всегда с вами до конца жизни. Затратили сколько-то времени, дальше этим пользуетесь, и чем раньше изучили, тем больше времени сэкономили.
gnaeus
А как у Раста с ORM-ами ну и вообще с поддержкой БД? Можете что-нибудь посоветовать?
Сам давно хотел попробовать что-нибудь кроме .NET на бекэнде. Но после EntityFramework как-то плеваться начинаешь на ORM-ы в других языках.
DSolodukhin
Есть Diesel, правда список поддерживаемых БД скромный — SQLite, PostgreSQL, и MySQL.
Vadem
Удалено.PsyHaSTe Автор
Дела с ORM: неплохо, но до EF конечно же пока не дотягивает. Кое-что есть примерно на уровне Linq2Sql. Классическая связка: r2d2 + diesel. Умеет в генерацию типов по схеме + LINQ-подобный dsl. Лично я проверял работу с постгресом, но есть разные провайдеры. Раньше не умел в миграции, сейчас в репе я что-то вижу на эту тему, но не пробовал.
Прям уровень EF это пока рановато, не зря он уже по сути восьмой версии (6 версий взрослого фреймворка, и две на Core). Но в целом, работать с БД можно.
gnaeus
Спасибо, почитал! Я так понял, что концепта
UnitOfWorkтам нет?Хотя вот это — огонь :)
А аналог
nameof()в Расте есть?red75prim
Есть макрос
stringify!(), превращающий токены в строку. И есть крейтnameofна его основе, делающий примерно то же, что иnameof().PsyHaSTe Автор
Ну вроде как
let connection = pool.get();это оно, нет?нет, но мы же про раст говорим :) 2 секунды, и уже есть :)
https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=2a2b3805c7d9b0cb291a0200f226f38c
gnaeus
Я имею в виду аналог DbContext:
Если я правильно понимаю,
save_changes(&connection)сохраняет прямо в базу. А группировка изменений по нескольким сущностям обеспечивается явной транзакцией. В противовес DbContext.saveChanges() из EF, который группирует изменения в один запрос.А
name_of(Post::published)можно? В .NET я это использую для того, чтобы RAW SQL не требовал изменений после рефакторинга названий классов и полей.PsyHaSTe Автор
А, ну группировки в одну транзакцию действительно я не видел. Хотя возможно уже добавили. Не берусь сказать.
Ниже сказали, я немного неверно понимал как $ident работает. Нужно подумать еще.
PsyHaSTe Автор
Ниже отредактировал ответ.
> А name_of(Post::published) можно?
можно всё, что является идентификатором. Можно посмотреть на реальный макрос реального крейта, там из комментов понятно, какие случаи работают, и даже как именно их обрабатывать: docs.rs/nameof/1.0.1/src/nameof/lib.rs.html#72-93
asdf87
Увы эта реализация не похожа на
nameofиз C#выведет в консоль
https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=3ffad15450a43fabab337e37e22440aa
а C# код
не скомпилируется с ошибкой:
https://dotnetfiddle.net/UHBtJh
PsyHaSTe Автор
Да, вы правы. Я забыл, что $ident может не только использовать существующий идентификатор, но и новый объявлять. Беру паузу на размышление :)
Подглядел в крейт nameof, чтобы посмотреть, как они это сделали. Собственно, так же, как и я, только с гвардом, который как-то использует переменную: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=40fdb6ff604b9f094faaaaf40ee826cb
Siemargl
Отлично. Как и в предыдущем флейме выяснилось, что растишки и сами не знают восхваляемого языка, да и ошибки он позволяет делать на ровном месте.
Код великолепен — как древние С- макросы, только с привкусом брейнфака.PsyHaSTe Автор
От сишных «макросов» тут одно название. Это ближе к лиспу и работе с AST, а не тупая автозамена. Если с лиспом работали, то понимаете, насколько это мощная концепция. Мы буквально за пару минут реализовали фичу языка, которую в шарпах делали несколько месяцев, и которую еще несколько лет ждали в релизе. Как по мне, это успех.
Cerberuser
Ошибки позволяет делать абсолютно любой язык. Просто некоторые в ответ отказываются компилировать код (или, напротив, компилируют то, что компилироваться, по задумке, не должно), а некоторые — доводят ошибку до рантайма и выдают какую-то ересь. Думаю, Вы не станете спорить, что Rust здесь себя проявил как язык из первой категории.
Siemargl
Как раз из второй. Поскольку ошибка макроса дошла до выполнения.
Макросы и трейты — зло. Макросы из трейтов — зло в квадрате.
PsyHaSTe Автор
Ну называйте их не макросами, а плагинами компилятора, если вам так проще. Вы вот LLVM пользуетесь? Там есть трансформаторы кода, оптимизаторы всякие. По сути достаточно близко. Это тоже зло?
Siemargl
Текстовая подстановка — макросы, доступ к информации компилятора — трейты.
Мы кажется, пытались в топике говорить о надежности языка и о прикрытии пятой точки компилятором — так твой пример показал, что нет — здесь (в таком вот использовании) _дыра_.
И я говорю только о том, что это так и в других языках с похожими возможностями — может с разной степени последствий.
И нет, писать на LLVM коде я не планирую — как и ассемблер — он небезопасен в использовании. Хороший язык должен максимально обходиться своими средствами, без всяких там asm/llvm вставок и трейтов тоже. А макросы просто устарели, типобезопасные шаблоны(генерики) — на две головы впереди.
freecoder_xx
Ну «дыра» — это громко сказано. Из-за того, что может быть кто-то недопонял или забыл, что макросы работают на синтаксическом, а не семантическом уровне, сразу злорадствовать о дырах… такое себе. Естественно, от подобных логических ошибок никакой компилятор не защитит, и тесты писать нужно, хотя бы простейшие.
Siemargl
Это не логическая ошибка. Это именно пц
Надо жить без синтаксических макросов. 3й раз пишу, не доходит.
PsyHaSTe Автор
Кому надо? Зачем надо?
0xd34df00d
Не надо, но синтаксические макросы, которые тупо получают поток токенов — это так себе.
Вот хорошо делать, как TH, когда всё уже распаршено и представлено.
PsyHaSTe Автор
По сути так и сделано, но это решено отдельными крейтами, в частности syn и quote. Из преимуществ, можно сделать более удобный крейт для парсинга, не трогая компилятор. В общем, проблем с этим нет, с сырым потоком токенов никто, конечно же, не работает.
Siemargl
Всем надо. Граблеопасная техника.
Сейчас заканчиваю статью о надежном программировании — вот велкам там прогнать раст через прокрустово ложе всех требований (потому что я этого сделать все= не смогу).
PsyHaSTe Автор
Так «в чем опасность-то»? Или это «очевидно» и в обосновании не нуждается?
Siemargl
Т.е сообразить самостоятельно после сделанной ошибки не получилось?
Вообще то после некоторого опыта конечно очевидно. Ослабляет проверку типов.
Но еще есть и гугл и учебники. В частности, в Misra C 2004 правило 93 как рекомендация не использовать, и в Misra C++ 2008 правило 6-2-2 вообще запрещающее функциональные макросы.
PsyHaSTe Автор
А при чем тут правила С? Я вам уже говорил, что «Макрос» в С и расте это две совершенно разные штуковины. Так же, как слово Лист в русском и List в английском означают немного разные вещи.
Siemargl
А сосед-растишка — говорил обратное. Поскольку я не знаю, кому верить, закругляюсь.
Но поскольку ошибка в наличии, она таки требует объяснений.
PsyHaSTe Автор
Там ничего не написано про "макросы в расте такие же как в С". И я предложил бы вам вежливее отзываться о ваших коллегах-программистах.
Ошибка в том, что я забыл, что
$identдолжен являться валидным идентификатором. Но в момент вызова макроса мы этот идентификатор и создаем. Этим можно воспользоваться, например, для генерации бойлерплейт-кода:Поэтому мой код проверял существование идентификатора, но он всегда существует, т.к. мы его и создали, вызывав макрос (как в примере выше).
Фикс: попробовать понять, что скрывается за этим идентификатором: переменная, тип, метод или еще что-нибудь. Если это не получится сделать, значит идентификатор ни к чему не привязан, и это его единственное использование.
Насчет дыры, это не большая дыра, чем такой код
Раст позволит объявить функцию сложения, которая на самом деле вычитает. И ничего не скажет даже.
Siemargl
А чем не нравится «растишка» (без негатива)?
Я честно перебрал термины — пишет на С — сишник, на паскале — паскалист, на расте = ??? растер, растишник. Готов к предложениям.
Действительно, это больше похоже не на синтаксический макрос, как утверждалось выше «соседом», а на шаблон(генерик) с использованием трейтов компилятора — что совсем другое дело.
Тем не менее, я внимательно посмотрел код и вижу (кроме отсутствия безопасности в работе с типами) еще один великолепный пример гениального синтаксиса, требующего 4х кратного копипаста (для ссылок, констант итп — хз).
Потом еще глаз зацепился за unsafe в Особо Опасной функции вывода в строку.
На этом мои изыскания по расту окончены. Спс за общение.
P.S Код по ссылке выше, — можно вполне брать за образец и переписывать под свой язык — написан симпатично — это библиотечка работы с целыми числами любой разрядности
PsyHaSTe Автор
Английский вариант — rustacean, русский, видимо, растовчанин.
Можно подробьнее, в чем копипаст.
Спасибо, эту функцию я и писал.
unsafeтам, потому что для функции предполагается работать вno_stdформате, без аллокаций памяти. Соответственно, вno_stdнет стандартных классов строк/векторов (они все завязаны на аллокации в куче), поэтому вот так.И да, unsafe это вещь, которой можно пользоваться. Если код помечен этим словом, это не означает, что тут ужос ужос и надо всё выкидывать.
mayorovp
hdfan2
Растовщик, растаман.
PsyHaSTe Автор
Макросы не занимаются текстовой подстановкой, если только это не С.
Если бы я писал реальный код, я бы написал два теста: на успешное и неуспешное прохождение, и отловил бы ошибку. Да, от вообще всех ошибок раст не спасает.
То есть все языки, собирающиеся в LLVM стали дырявыми?
Кажется, вы не знаете, что такое макрос.
Siemargl
Ага. Уже значит, компилятор раста не обеспечивает защиту от всех ошибок простой компиляцией, как заявлялось ранее — это прогресс в признании ошибочных заявлений. Это кстати — не «все ошибки» — это простая опечатка, должная быть отловленной ну просто любым адекватным компилятором со стат.типами (правда ее бы и раст отловил при обращении по значению).
Нужны таки еще юниттесты.
PsyHaSTe Автор
А можно увидеть это заявление? А то пока походит больше на strawmen аргументацию.
Остальные пункты вы, видимо, решили проигнорировать.
Siemargl
можно. например
не считая комментариевэто что касается успешной компиляции с несуществующей переменной
про остальное я не вижу конкретных вопросов. про макросы — ваш сочувствующий съехал на «синтаксическую составляющую», например, и что это нормально :fail:
ладно. я с одной стороной думаю, что данный пример показательный «как не надо делать» и в обычном использовании редок, но с другой — списки…
VanquisherWinbringer
ИМХО, как раз таки макросы это крутая фича как в том же Clojure
farcaller
Все упирается в то что крейтов или нет вообще, или заброшенные, или несовместимые.
Я вот недавно писал мелкий сервис который болтает по GRPC, конвертит картинки в jpg/webp, кропает, и заливает в google cloud storage. Три дня на го.
И я хотел бы написать то же на расте, но с картинками как-то все сложно, с API к GCS тоже, ну вот и все — интерес кончился, надо чтоб работало.
PsyHaSTe Автор
С этим трудно поспорить. Я полгода потратил на написание
cv-rs(биниднги к opencv), чтобы мой бот мог картинки анализировать. Было бы намного проще, если бы это кто-то сделал до меня.Но для обычного приложения в стиле MVC с DAL слоем уже всё есть. Для специфики могут быть свои нюансы.
freecoder_xx
Мало библиотек — это, конечно, плохо. Но с другой стороны — у вас есть много возможностей, чтобы создать свою библиотеку или стать мейнтейнером существующей, принести пользу сообществу и прославиться :)
solver
Простите, а в каком месте actix «точно такой же фреймворк» как Akka?
Там только акторы и всё. В акка есть кластер, стримы, http наконец и многое другое.
Этот фреймворк далеко не просто акторы, в нем много библиотек выстраивающих экосистему.
Все равно что сказать, Spring в Java это DI ))
PsyHaSTe Автор
Http в актикс есть, причем http2 автор добавил за пару недель, что ли, причем самостоятельно без помощи. Refactoring is a pleasure — действительно так.
Кластеризация это да, мощная штука, но как уже говорил парень с дотнекста «Я вот щас вам рассказал про кластеры, но если есть возможность, НЕ ДЕЛАЙТЕ их» :)
В данном случае, возможно, вы получите такой буст по производительности. что и кластер уже не нужен будет. И это снимет целую кучу потенциальных проблем.