

Автор: Денис Цыплаков, Solution Architect, DataArt
В DataArt я работаю по двум направлениям. В первом помогаю людям чинить системы, сломанные тем или иным образом и по самым разным причинам. Во втором помогаю проектировать новые системы так, чтобы они в будущем сломаны не были или, если говорить реалистичнее, чтобы сломать их было сложнее.
Если вы не делаете что-то принципиально новое, например, первый в мире интернет-поисковик или искусственный интеллект для управления запуском ядерных ракет, создать дизайн хорошей системы довольно просто. Достаточно учесть все требования, посмотреть на дизайн похожих систем и сделать примерно так же, не совершив при этом грубых ошибок. Звучит как чрезмерное упрощение вопроса, но давайте вспомним, что на дворе 2019 год, и «типовые рецепты» дизайна систем есть практически для всего. Бизнес может подкидывать сложные технические задачи — скажем, обработать миллион разнородных PDF-файлов и вынуть из них таблицы с данными о расходах — но вот архитектура систем редко отличается большой оригинальностью. Главное тут — не ошибиться с определением того, какую именно систему мы строим, и не промахнуться с выбором технологий.
В последнем пункте регулярно возникают типичные ошибки, о некоторых из них я расскажу в статье.
В чем сложность выбора технического стека? Добавление любой технологии в проект делает его сложнее и приносит какие-то ограничения. Соответственно, добавлять новый инструмент (фреймворк, библиотеку) следует, только когда это инструмент приносит больше пользы, чем наносит вреда. В разговорах с членами команды про добавление библиотек и фреймворков я часто в шутку использую следующий прием: «Хочешь добавить новую зависимость в проект — ставишь команде ящик пива. Если считаешь, что эта зависимость ящика пива не стоит, не добавляй».
Допустим, мы создаем некое приложение, скажем, на Java и для манипуляции датами добавляем в проект библиотеку TimeMagus (пример вымышленный). Библиотека отличная, она предоставляет нам множество возможностей, отсутствующих в стандартной библиотеке классов. Чем такое решение может быть вредно? Давайте разберем по пунктам возможные сценарии:
- Далеко не все разработчики знают нестандартную библиотеку, порог вхождения для новых разработчиков будет выше. Возрастает шанс, что новый разработчик совершит ошибку при манипуляциях с датой при помощи неизвестной ему библиотеки.
- Увеличивается размер дистрибутива. Когда размер среднего приложения на Spring Boot может легко разрастись до 100 Мб, это совсем не пустяк. Я видел случаи, когда ради одного метода в дистрибутив затягивалась библиотека на 30 Мб. Это обосновывали так: «Эту я библиотеку использовал в прошлом проекте, и там есть удобный метод».
- В зависимости от библиотеки может заметно увеличиваться время старта.
- Разработчик библиотеки может забросить свое детище, тогда библиотека начнет конфликтовать с новой версией Java, или в ней обнаружится баг (вызванный например изменением временных поясов), а никакой патч не выпустят.
- Лицензия библиотеки в какой-то момент вступит в конфликт с лицензией вашего продукта (вы же проверяете лицензии для всех-всех продуктов, которые используете?).
- Jar hell — библиотеке TimeMagus нужна последняя версия библиотеки SuperCollections, затем через несколько месяцев вам необходимо подключить библиотеку для интеграции со сторонним API, которая не работает с последней версией SuperCollections, а работает только с версией 2.x. Не подключать API вы не можете никак и другой библиотеки для работы с этим API нет.
С другой стороны, стандартная библиотека предоставляет нам достаточно удобные средства для манипуляции датами, и если у вас нет необходимости например поддерживать какой-то экзотический календарь или вычислять количество дней от сегодняшнего до «второго дня третьего новолуния в предыдущий год парящего орла», возможно, стоит воздержаться от использования третьесторонней библиотеки. Даже если она совершенно замечательная и в масштабе проекта сэкономит вам целых 50 строк кода.
Рассмотренный пример достаточно прост, и я думаю, принять решение тут несложно. Но есть ряд технологий, которые широко распространены, у всех на слуху, и польза их очевидна, что делает выбор более сложным — они действительно предоставляют серьезные преимущества разработчику. Но это не всегда должно служить поводом затягивать их в свой проект. Давайте рассмотрим некоторые из них.
Docker
До появления этой действительно классной технологии при развертывании систем возникало множество неприятных и сложных вопросов, связанных с конфликтом версий и непонятными зависимостями. Docker позволяет упаковать слепок состояния системы, выкатить его в продакшн и там запустить. Это позволяет упомянутых конфликтов избежать, что, конечно, здорово.
Раньше это делалось каким-то чудовищным образом, а некоторые задачи не решались вообще никак. Например, у вас есть приложение на PHP, которое использует библиотеку ImageMagick для работы с изображениями, также вашему приложению нужны специфические настройки php.ini, а само приложение хостится при помощи Apache httpd. Но есть проблема: некоторые регулярные рутины реализованы запуском Python-скриптов из cron, и библиотека, используемая этими скриптами, конфликтует с версиями библиотек, используемыми в вашем приложении. Докер позволяет упаковать все ваше приложение вместе с настройками, библиотеками и HTTP-сервером в один контейнер, который обслуживает запросы на 80-ом порту, а рутины — в другой контейнер. Все вместе будет прекрасно работать, и о конфликте библиотек можно будет забыть.
Стоит ли использовать Docker для упаковки каждого приложения? Мое мнение: нет, не стоит. На картинке представлена типичная композиция докеризированного приложения, развернутого в AWS. Прямоугольниками здесь обозначены слои изоляции, которые у нас есть.
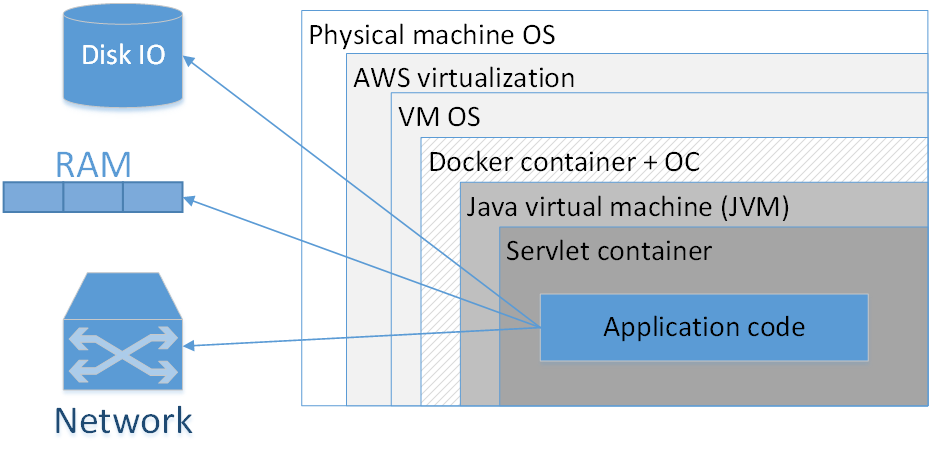
Самый большой прямоугольник — физическая машина. Далее — операционная система физической машины. Затем — амазоновский виртуализатор, потом — ОС виртуальной машины, дальше — докер-контейнер, за ним — ОС контейнера, JVM, потом — Servlet-контейнер (если это веб-приложение), и уже внутри него содержится код вашего приложения. Т. е. мы уже видим довольно много слоев изоляции.
Ситуация будет выглядеть еще хуже, если мы посмотрим на аббревиатуру JVM. JVM — это, как ни странно, Java Virtual Machine, т. е., вообще-то, как минимум одна виртуальная машина в Java у нас есть всегда. Добавление сюда еще дополнительного Docker-контейнера, во-первых, часто не дает такого уж заметного преимущества, потому что JVM сама по себе уже неплохо изолирует нас от внешнего окружения, во-вторых, не обходится даром.
Я взял цифры из исследования компании IBM, если не ошибаюсь, двухлетней давности. Кратко, если мы говорим о дисковых операциях, использовании процессора или доступе памяти, Docker почти не добавляет оверхеда (буквально доли процента), но если речь идет о network latency, задержки вполне ощутимы. Они не гигантские, но в зависимости от того, какое у вас приложение, могут вас неприятно удивить.
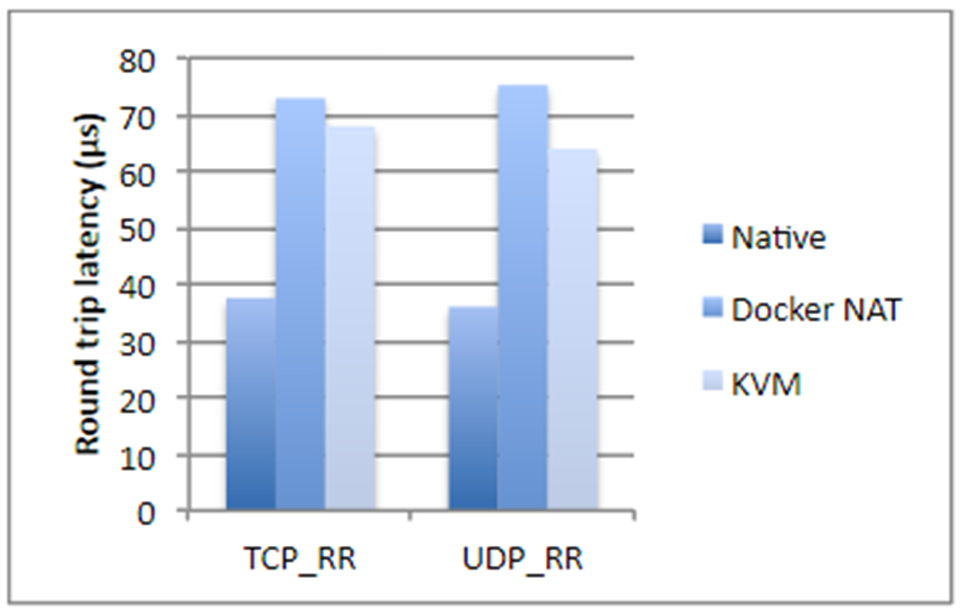
Плюс ко всему Docker съедает дополнительное место на диске, занимает часть памяти, добавляет start up time. Все три момента для большинства систем некритичны — обычно и места на диске, и памяти достаточно много. Время запуска, как правило, тоже проблема не критическая, главное, чтобы приложение запускалось. Но все же возникают ситуации, когда памяти может не хватать, и суммарное время старта системы, состоящей из двадцати зависимых сервисов, уже достаточно большое. К тому же, это сказывается на стоимости хостинга. И если вы занимаетесь каким-нибудь высокочастотным трейдингом, Docker вам категорически не подходит. В общем случае любое приложение, чувствительное к задержкам в сети в пределах до 250–500 мс, лучше не докеризировать.
Также с докером заметно усложняется разбор проблем в сетевых протоколах, растут не только задержки, но и все тайминги становятся другими.
Когда Docker действительно нужен?
Когда у нас разные версии JRE, и при этом хорошо бы JRE тащить с собой. Бывают случаи, когда для запуска нужна определенная версия Java (не «последняя Java 8», а что-то более специфическое). В этом случае хорошо упаковать JRE вместе с приложением и запускать как контейнер. В принципе, понятно, что разные версии Java можно поставить на целевую систему за счет JAVA_HOME и т. д. Но Docker в этом смысле заметно удобнее, потому что вы знаете точную версию JRE, все упаковано вместе и с другой JRE даже случайно приложение не запустится.
Также Docker необходим, если у вас есть зависимости на какие-то бинарные библиотеки, например, для обработки изображений. В этом случае неплохой идеей может оказаться упаковка всех необходимых библиотек вместе с самим Java-приложением.
Следующий кейс относится к системе, представляющим собой сложный композит из разных сервисов, написанных на различных языках. У вас есть кусочек на Node.js, есть часть на Java, библиотека на Go, а в придачу — какой-нибудь Machine Learning на Python. Весь этот зоопарк надо долго и тщательно настраивать, чтобы научить его элементы видеть друг друга. Зависимости, пути, IP-адреса — все это надо расписать и аккуратно поднять в продакшене. Конечно, в этом случае Docker вам здорово поможет. Более того, делать это без его помощи попросту мучительно.
Докер может обеспечить некоторое удобство, когда для запуска приложения вам в командной строке надо указывать множество разных параметров. С другой стороны, с этим прекрасно справляются bash-скрипты, часто из одной строки. Сами решайте, что использовать лучше.
Последнее, что навскидку приходит в голову — ситуация, когда вы используете, скажем, Kubernetes, и вам нужно делать оркестрацию системы, т. е. поднимать какое-то количество различных микросервисов, автоматически масштабирующихся по определенным правилам.
Во всех остальных случаях Spring Boot оказывается достаточно, чтобы упаковать все в один jar-файл. И, в принципе, спрингбутовый jar — неплохая метафора Docker-контейнера. Это, понятно, не одно и то же, но по степени удобства развертывания они действительно похожи.
Kubernetes
Что делать, если мы используем Kubernetes? Начнем с того, что эта технология позволяет деплоить на разные машины большое количество микросервисов, управлять ими, делать autoscaling и т. д. Однако существует достаточно много приложений, которые позволяют управлять оркестрацией, наример, Puppet, CF engine, SaltStack и прочие. Сам же Kubernetes, безусловно, хорош, но может добавлять значительный overhead, жить с которым готов далеко не каждый проект.
Мой любимый инструмент — Ansible в сочетании с Terraform там, где это нужно. Ansible достаточно простой декларативный легкий инструмент. Он не требует установок специальных агентов и имеет вполне понятный синтаксис конфигурационных файлов. Если вы знакомы с Docker compose, сразу увидите перекликающиеся секции. И если вы используете Ansible, нет необходимости докерезировать — можно развертывать системы более классическими средствами.
Понятно, что все равно это разные технологии, но есть какое-то множество задач, в которых они взаимозаменяемы. И добросовестный подход к проектированию требует анализа, какая технология больше подойдет для разрабатываемой системы. И как будет лучше соответствовать ей через несколько лет.
Если количество различных сервисов в вашей системе невелико и их конфигурация относительно проста, например, у вас всего один jar-файл, при этом какого-то внезапного, взрывного роста сложности вы не видите, возможно, стоит обойтись классическими механизмами развертывания.
Тут возникает вопрос «подождите, как один jar-файл?». Система же должна состоять из множества как можно более атомарных микросервисов! Давайте разберем, кому и что система должна с микросервисами.
Микросервисы
Прежде всего, микросервисы позволяют достичь большей гибкости и масштабируемости, позволяют гибко версионировать отдельные части системы. Предположим, у нас есть какое-то приложение, которое в продакшене уже много лет. Функционал растет, но мы не можем бесконечно развивать его экстенсивным образом. Например.
У нас есть приложение на Spring Boot 1 и Java 8. Прекрасное, стабильное сочетание. Но на дворе 2019 год и, хотим мы того или нет, нужно двигаться в сторону Spring Boot 2 и Java 12. Даже относительно простой переход большой системы на новую версию Spring Boot может быть весьма трудозатратен, а про прыжок над пропастью с Java 8 на Java 12 я и говорить не хочу. Т. е. в теории все просто: мигрируем, правим возникшие проблемы, все тестируем и запускаем в production. На практике это может означать несколько месяцев работы, не приносящей бизнесу нового функционала. Немножечко переехать на Java 12, как вы понимаете, тоже не получится. Тут нам может помочь микросервисная архитектура.
Мы может выделить какую-то компактную группу функций нашего приложения в отдельный сервис, мигрировать эту группу функций на новый технический стек и за относительно короткое время выкатить это в продакшен. Повторять процесс кусочек за кусочком до полного исчерпания старых технологий.
Также микросервисы позволяют обеспечить fault isolation, когда один упавший компонент не рушит всю систему.
Микросервисы позволяют нам иметь гибкий технический стек, т. е. не писать все монолитно на одном языке и одной версии, а при необходимости использовать разный технический стек для отдельных компонент. Разумеется, лучше когда вы используете однородный технический стек, но это не всегда возможно, и в таком случае микросервисы могут выручить.
Также микросервисы позволяют техническим способом решить ряд менеджерских проблем. Например, когда ваша большая команда состоит из отдельных групп, работающих в разных компаниях (сидящих в разных временных зонах и говорящих на разных языках). Микросервисы помогают изолировать это организационное многообразие по компонентам, которые будут развиваться отдельно. Проблемы одной части команды будут оставаться внутри одного сервиса, а не расползаться по всему приложению.
Но микросервисы — не единственный способ решения перечисленных проблем. Как ни странно, несколько десятков лет назад для половины из них люди придумали классы, а чуть позже — компоненты и паттерн Inversion of Control.
Если мы посмотрим на Spring, увидим, что фактически это микросервисная архитектура внутри Java-процесса. Мы можем объявлять компонент, который, по сути, представляет собой сервис. У нас есть возможность делать lookup через @Autowired, есть средства управления жизненным циклом компоненты и возможность раздельно конфигурировать компоненты из десятка разных источников. В принципе, мы получаем почти все то же самое, что имеем с микросервисами — только внутри одного процесса, что существенно сокращает издержки. Обычный Java-class — тот же API-контракт, который точно так же позволяет изолировать детали реализации.
Строго говоря, в Java-мире микросервисы больше всего похожи на OSGi — там мы имеем практически точную копию всего, что есть в микросервисах, разве что, кроме возможности использования разных языков программирования и исполнения кода на разных серверах. Но даже оставаясь в пределах возможностей Java-классов, мы имеем достаточно мощный инструмент для решения большого количества проблем с изоляцией.
Даже в «менеджерском» сценарии с изоляцией команды мы можем создать отдельный репозиторий, который содержит отдельный Java-модуль с четким внешним контрактом и набором тестов. Это существенно сократит возможности одной команды по неосторожности усложнить жизнь другой команды.
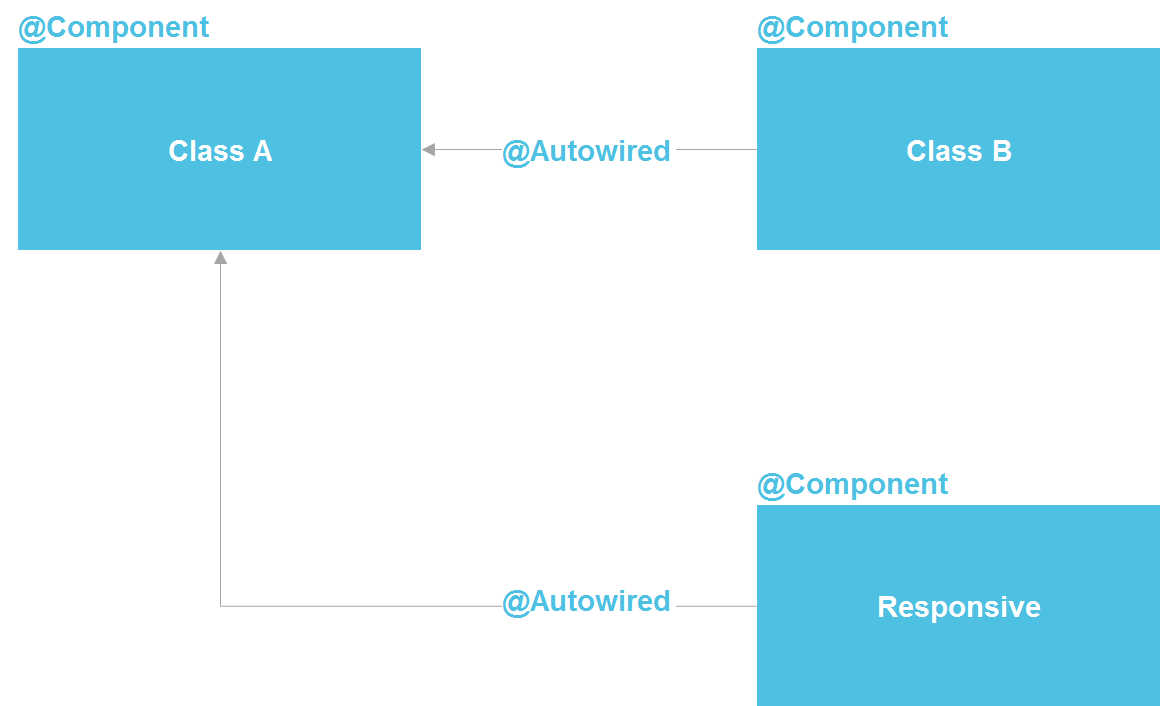
Мне неоднократно приходилось слышать, что изолировать детали реализации без микросервисов никак нельзя. Но я могу ответить, что вся software-индустрия как раз про изоляцию реализации. Для этого была придумана сначала подпрограмма (в 50-х годах прошлого века), потом функции, процедуры, классы, еще позже микросервисы. Но то, что микросервисы в этом ряду появились последними, не делает их наивысшей точкой развития и не обязывает нас с вами всегда прибегать к их помощи.
При использовании микросервисов надо также принимать во внимание, что вызовы между ними занимают некоторое время. Часто это неважно, но мне доводилось видеть случай, когда заказчику необходимо было уместить время ответа системы в 3 секунды. Это было контрактное обязательство для подключения к сторонней системе. Цепочка вызовов проходила через несколько десятков атомарных микросервисов, и накладные расходы на совершение HTTP-вызовов никак не позволяли ужаться в 3 секунды. В целом надо понимать, что любое разделение монолитного кода на некоторое количество сервисов неизбежно ухудшает общую производительность системы. Просто потому, что данные не могут телепортироваться между процессами и серверами «за бесплатно».
Когда микросервисы все же нужны?
В каких же случаях монолитное приложение действительно нужно разбить на несколько микросервисов? Во-первых, когда в функциональных областях присутствует несбалансированное использование ресурсов.
Например, у нас есть группа API-вызовов, которые выполняют вычисления, требующие большого количества процессорного времени. И есть группа API-вызовов, которые выполняются очень быстро, но требуют для выполнения держать в памяти громоздкую структуру данных на 64 Гб. Для первой группы нам нужна группа машин, имеющих в общей сложности 32 процессора, для второй достаточно одной машины (ОК, пусть будет две машины для отказоустойчивости) с 64 Гб памяти. Если у нас монолитное приложение, то нам на каждой машине будут нужны 64 Гб памяти, что увеличивает стоимость каждой машины. Если же эти функции разделены на два отдельных сервиса, мы можем сэкономить ресурсы за счет оптимизации сервера под конкретную функцию. Конфигурация серверов может выглядеть например вот так:

Микросервисы нужны и если нам нужно серьезно масштабировать какую-то узкую функциональную область. Например, сотня API-методов вызываются с периодичностью 10 раз в секунду, а, скажем, четыре API-метода вызываются 10 тысяч раз в секунду. Масштабировать всю систему часто нет необходимости, т. е. мы, конечно, можем размножить все 100 методов на множество серверов, но это, как правило, заметно дороже и сложнее, чем масштабирование узкой группы методов. Мы можем выделить эти четыре вызова в отдельный сервис и масштабировать только его на большое количество серверов.
Также понятно, что микросервис может нам понадобиться, если отдельная функциональная область у нас написана, например, на Python. Потому что какая-то библиотека (скажем, для Machine Learning) оказалась доступна только на Python, и мы хотим выделить ее в отдельный сервис. Также имеет смысл сделать микросервис, если какая-то часть системы подвержена сбоям. Хорошо, конечно, писать код так, чтобы сбоев не было в принципе, но причины могут быть и внешними. Да и от собственных ошибок никто не застрахован. В этом случае баг можно изолировать внутри отдельного процесса.
Если в вашем приложении ничего из вышеперечисленного нет и в обозримой перспективе не предвидится, скорее всего, монолитное приложение вам подойдет лучше всего. Единственное — рекомендую писать его так, чтобы не связанные друг с другом функциональные области не зависели друг от друга в коде. Чтобы при необходимости не связанные между собой функциональные области можно было отделить друг от друга. Впрочем, это всегда хорошая рекомендация, следование которой повышает внутреннюю непротиворечивость и приучает аккуратно формулировать контракты модулей.
Реактивная архитектура и реактивное программирование
Реактивный подход — вещь относительно новая. Моментом его появления можно считать 2014 год, когда был опубликован The Reactive Manifesto. Уже через два года после публикации манифеста он был у всех на слуху. Это действительно революционный подход к проектированию систем. Его отдельные элементы использовались десятки лет назад, но все принципы реактивного подхода вместе, в том виде, как это изложено в манифесте, позволили индустрии сделать серьезный шаг вперед к проектированию более надежных и более высокопроизводительных систем.
К сожалению, реактивный подход к проектированию часто путают с реактивным программированием. На вопрос, зачем в проекте использовать реактивную библиотеку, мне доводилось слышать ответ: «Это реактивный подход, ты что реактивный манифест не читал!?» Манифест я читал и подписывал, но, вот беда, реактивное программирование не имеет к реактивному подходу к проектированию систем прямого отношения, кроме того что в названиях обоих есть слово «реактивный». Можно легко сделать реактивную систему, используя на 100% традиционный набор инструментов, и создать совершенно не реактивную систему, используя новейшие наработки функционального программирования.
Реактивный подход к проектированию систем — достаточно общий принцип, применимый к очень многим системам — он определенно заслуживает отдельной статьи. Здесь же я хотел бы рассказать о применимости реактивного программирования.
В чем суть реактивного программирования? Сначала рассмотрим, как работает обычная нереактивная программа.
Нитью исполняется какой-то код, делающий какие-то вычисления. Затем наступает необходимость произвести какую-то операцию ввода-вывода, например, HTTP-запрос. Код посылает по сети пакет, и нить блокируется в ожидании ответа. Происходит переключение контекста, и на процессоре начинает исполняться другая нить. Когда по сети приходит ответ, контекст опять переключается, и первая нить продолжает исполнение, обрабатывая ответ.
Как такой же фрагмент кода будет работать в реактивном стиле? Нить исполняет вычисления, посылает HTTP-запрос и вместо того чтобы заблокироваться и при получении результата синхронно обработать его, описывает код (оставляет callback) который должен быть исполнен в качестве реакции (отсюда слово реактивный) на результат. После этого нить продолжает работу, делая какие-то другие вычисления (может быть, как раз обрабатывая результаты других HTTP-запросов) без переключения контекста.
Основное преимущество здесь — отсутствие переключения контекста. В зависимости от архитектуры системы эта операция может занимать несколько тысяч тактов. Т. е. для процессора с тактовой частотой 3 Ghz переключение контекста займет не менее микросекунды, на самом деле, за счет инвалидации кэша и т. п. скорее несколько десятков микросекунд. Говоря практически, для среднего Java-приложения, обрабатывающего много коротких HTTP-запросов — прирост производительности может составить 5-10%. Нельзя сказать, что решающе много, но, скажем, если вы арендуете 100 серверов по 50 $/мес каждый — вы сможете сэкономить $500 в месяц на хостинге. Не супермного, но хватит, чтобы несколько раз напоить команду пивом.
Итак, вперед за пивом? Давайте рассмотрим ситуацию подробно.
Программу в классическом императивном стиле значительно проще читать, понимать и как следствие отлаживать и модифицировать. В принципе, хорошо написанная реактивная программа тоже достаточно понятно выглядит, проблема в том, что написать хорошую, понятную не только автору кода здесь и сейчас, но и другому человеку через полтора года, реактивную программу намного сложнее. Но это достаточно слабый аргумент, я не сомневаюсь, что для читателей статьи писать простой и понятный реактивный код не составляет проблемы. Давайте рассмотрим другие аспекты реактивного программирования.
Далеко не все операции ввода-вывода поддерживают неблокирующие вызовы. Например, JDBC на текущий момент не поддерживает (в этом направлении идут работы см. ADA, R2DBC, но пока все это не вышло на уровень релиза). Поскольку сейчас 90 % всех приложений ходят к базам данных, использование реактивного фреймворка автоматически из достоинства превращается в недостаток. Для такой ситуации есть решение — обрабатывать HTTP-вызовы в одном пуле потоков, а обращения к базе данных в другом пуле потоков. Но при этом процесс значительно усложняется, и без острой необходимости я бы так делать не стал.
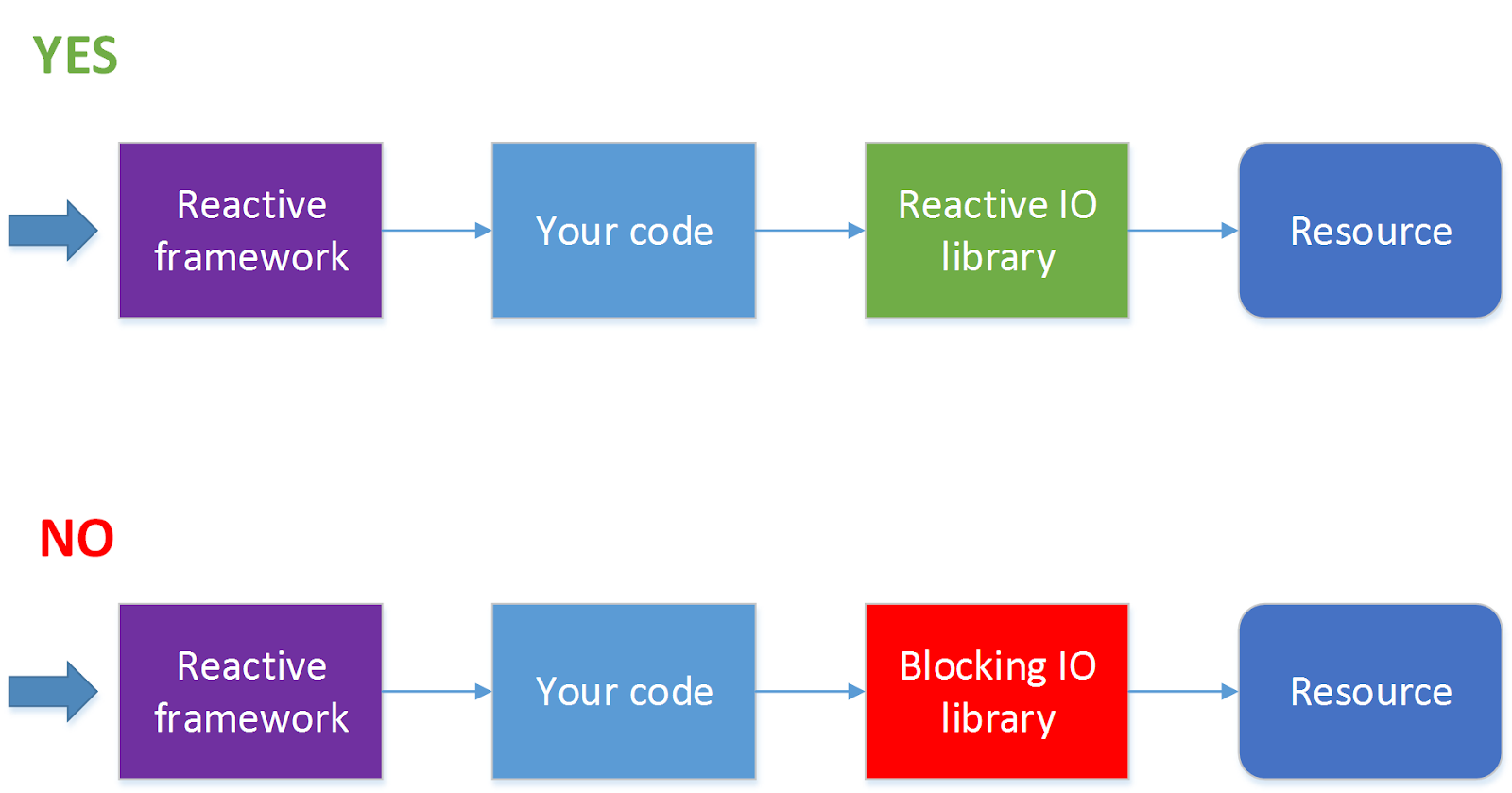
Когда стоит использовать реактивный фреймворк?
Использовать фреймворк, позволяющий производить реактивную обработку запросов, стоит, когда запросов у вас много (несколько сотен секунду и более) и при этом на обработку каждого из них тратится очень небольшое количество тактов процессора. Самый простой пример — проксирование запросов или балансировка запросов между сервисами или какая-то достаточно легковесная обработка ответов, пришедших от другого сервиса. Где под сервисом мы понимаем нечто, запрос к чему можно послать асинхронно, например, по HTTP.
Если же при обработке запросов вам надо будет блокировать нить в ожидании ответа, или обработка запросов занимает относительно много времени, например, надо конвертировать картинку из одного формата в другой, писать программу в реактивном стиле, возможно, не стоит.
Также не стоит без необходимости писать в реактивном стиле сложные многошаговые алгоритмы обработки данных. Например, задачу «найти в каталоге и всех его подкаталогах файлы с определенными свойствами, сконвертировать их содержимое и переслать другому сервису» можно реализовать в виде набора асинхронных вызовов, но, в зависимости от деталей задачи, такая реализация может выглядеть совершенно непрозрачно и при этом не давать заметных преимуществ перед классическим последовательным алгоритмом. Скажем, если эта операция должна запускаться раз в сутки, и нет большой разницы, будет она исполняться 10 или 11 минут, возможно, стоит выбрать не самую что ни на есть лучшую, а более простую реализацию.
Заключение
В заключение хочется сказать, что любая технология всегда предназначена для решения конкретных задач. И если при проектировании системы в обозримой перспективе эти задачи перед вами не стоят, скорее всего, эта технология вам здесь и сейчас не нужна, какой бы прекрасной она при этом ни была.
Комментарии (90)

coramba
16.01.2019 19:31И если при проектировании системы в обозримой перспективе эти задачи перед вами не стоят, скорее всего, эта технология вам здесь и сейчас не нужна, какой бы прекрасной она при этом ни была.
Полностью согласен и сам не раз сталкивался с такой проблемой. Люди пытаются вкрячить в свои процессы какую-то технологию, просто потому, что она на слуху и «все так пишут». Частный случай карго-культа.
Но вот что обязательно стоит учитывать при планировании своей системы, это возможность расширения или замены какой-то ее части в принципе. Иначе можно столкнуться с ситуацией, когда технология на старте отмечена как «когда-нибудь совсем нескоро», сегодня это «нескоро» наступило, но перейти на нее мы не можем, просто потому, что для этого придется переделывать проект с нуля.
sentyaev
16.01.2019 19:56Но вот что обязательно стоит учитывать при планировании своей системы, это возможность расширения или замены какой-то ее части в принципе.
Собственно DDD как раз об этом, а микросервисы — это какая-то извращенная реализация DDD подхода, т.к. выносится часть системы в отдельный сервис не потому-что это необходимо (например нужно горизонтально масштабировать часть системы), а просто потому-что могут.
VolCh
17.01.2019 13:02Ну, микросервисы обеспечивают бОльшую изоляцию контекстов друг от друга.

Semenych
17.01.2019 14:16Вопрос в том, как степень изоляции действительно требуется и делать изоляцию больше чем требуется — это жечь деньги без пользы.
sentyaev
17.01.2019 16:07На самом деле нет. Если у разработчиков при разработке монолита не хватило ума правиьльно выделить контексты и сделать взаимодействие между ними через слой доменной логики или слой логики приложения, то и микросервисы они скорее всего станут выделять каким-нибудь странным образом, например по микросервису на таблицу базы данных.
И кто им потом помешает при взаимодействии микросервисов в интерфейсы позапихать детали реализации?
Грубо говоря если наривовать на животе кубики, красивого преса все равно не будет.VolCh
17.01.2019 17:42Как минимум, будут исключены возможности доступа к «чужим» данным не через публичный интерфейс.
coramba
17.01.2019 23:42+1*улыбающийся-терминатор-2.jpeg*
нет ничего невозможного для пыткого велосипедостроителя!
tamapw
18.01.2019 06:21Ой ли? Там уже будет зависеть от ситуации.
У нас, к примеру, все микросервисы крутятся в openshift и настройку осуществляем тоже мы, через чарты.
Таким образом, при особом желании, можно скрестить несколько микросервисов и напрямую заставить их смотреть в одну базу, к примеру. Или смотреть в базы своих соседей. Особых трудностей сделать это нет.
Разумеется, так никто не делает, но сама возможность никуда не делась.
А про доступ через публичный интерфейс — ничего не мешает написать защищённый системный метод, который будет принимать в себя произвольный запрос и отдавать данные по этому запросу. Это будет лютая дырка в безопасности, но кто же помешает людям сделать именно так?
Ndochp
18.01.2019 14:47Хнык хнык в этом месте. Мне как разработчику не микросервисов, но 1С очень очень не хватает промежуточной «package» видимости.
И вот уже появляется толпа методов в публичном интерфейсе нужных только для того, чтобы форма объекта могла со своим объектом пообщаться. Естественно вся эта толпа публичных, но по факту служебных процедур и функций никем не тестируется на некорректные входные параметры и тд. Так как разработчик знает, что вызывать этот публичный метод будет только он из одного единственного места.
(а когда при доработке другой программист попробует воспользоваться этим публичным методом, то огребет по полной — от неожиданных и плохо описанных структур в параметрах, до сайд эффектов, которые ему не нужны, но про которые он не знает)

CrazyOpossum
16.01.2019 20:26Как такой же фрагмент кода будет работать в реактивном стиле? Нить исполняет вычисления, посылает HTTP-запрос и вместо того чтобы заблокироваться и при получении результата синхронно обработать его, описывает код (оставляет callback) который должен быть исполнен в качестве реакции (отсюда слово реактивный) на результат. После этого нить продолжает работу, делая какие-то другие вычисления (может быть, как раз обрабатывая результаты других HTTP-запросов) без переключения контекста.
Это не реактивное, а асинхронное программирование на коллбеках. Хотя реактивные фреймворки зачастую имеют асинхронный реактор, но одной из фич реактивного программирования является как раз избегание коллбэков. Реактивное программирование — это прежде всего про потоки данных внутри системы и распространение изменений. Никаких отложенных вызовов не предполагается. За манифест спасибо, посмотрю.rfq
16.01.2019 21:23«Хотя реактивные фреймворки зачастую имеют асинхронный реактор, но одной из фич реактивного программирования является как раз избегание коллбэков»
Откуда такое заключение? Если заглянем в wikipedia.org/Reactive_programming, то там написано: Update process: callbacks versus dataflow versus actors, то есть, никакой дискриминации колбэков. А если учесть, что callbacks, dataflow и actors — разновидности асинхронного вызова процедуры, то выбор конкретной разновидности определяется только удобством.CrazyOpossum
17.01.2019 23:02Вроде бы и да, но в этой статье я вижу другой смысл. В RP коллбеки очень тонкие и не порождают новые коллбеки (они могут, но это не идиоматично). Их задача — получить сообщение и послать его в граф. В статье описывается функция которая занимается вычислениями, выводом и вводом, хотя в RP все три части разделены.
Semenych
17.01.2019 00:04не идиоматично — но увы в коде тех проектов в которых мне доводилось делать — аудит вполне распространено. Понятно, что «по феншую такого быть не должно», но грань тут достаточно тонкая и не все ее в должной мере понимают

GrigoryPerepechko
17.01.2019 11:01Автор хотел на примере блокировки потоков показать крутость реактивного программирования, но показал крутость асинхронного (non-blocking) подхода.
Реактивное программирование по определению использует асинхронный подход, но нужно понимать что это абстракция более высокого порядка.
В том же .net есть старая парадигма APM когда вместо блокирующих методов создаются пары BeginXXX / EndXXX (в BeginXXX передается колбек, в котором нужно вызвать EndXXX который вернет результат или ошибку).
А реактивный это уже IObservable, и LINQ-подобные операции (Select/Where/Join/Aggregate) над источником событий. За счет того что это модель push (в нашу цепочку операторов событие пропихивается источником), а не pull (когда мы делаем условный вызов и ждем результат), модель неизбежно асинхронная.
Но опять же, важно доказывая вред блокирующего подхода противопоставлять ему не реактивный, а асинхронный

SirEdvin
17.01.2019 22:14Я взял цифры из исследования компании IBM, если не ошибаюсь, двухлетней давности. Кратко, если мы говорим о дисковых операциях, использовании процессора или доступе памяти, Docker почти не добавляет оверхеда (буквально доли процента), но если речь идет о network latency, задержки вполне ощутимы. Они не гигантские, но в зависимости от того, какое у вас приложение, могут вас неприятно удивить.
Есть один грязный лайфхак, который безумно очевиден и многие его практикуют. Просто не используйте докер сети, можно все в хостовой сети запустить. Они скорее всего вам не нужны, а оверхед от них приличный.
Semenych
17.01.2019 00:10Я правильно понимаю, что речь идет о
"bridge": "none",
"iptables": "false"
про что написано — Disabling the default bridge network is an advanced option that most users will not need.
Как-то это м-м-м «грязно» :-)SirEdvin
17.01.2019 00:30Я имел ввиду, что контейнеры можно запускать с
--network-mode hostи сетевой оверхед практически не будет вас касатся.
Конечно, вы потеряете изоляцию между сервисами в сети, но тут уже нужно выбирать, что важнее.

dominigato
17.01.2019 00:09Docker сети это обычные linux bridge с iptalbes. Непонятно отчего там будут задержки, ну разве что от iptables.
Ну и ценность контейнера не только в том что вы описали, а время разработки например — идентичность среды для продакшна, ну или хотя бы ее похожесть. Удобство развертывания и оркестрация, очень много хороших тулов вокруг этого. Часто контейнеры заменяют виртуалки, что как раз экономит ресурсы.
И опять же ценность кубернетис это еще и удобство роллбеков и роллинг апдейтов. Плюс High Availability. И если вам критична доступность системы 24/7/365 то это как-раз может быть решением. И это уж точно стоит нескольких там микросекунд задержки.
К тому же контейнеризация это не обязательно Docker вообще-то. Можно даже и без сервиса вообще — как у Red Hat сделано с podman. Запускается как system service себе — если уж так критично время запуска. Ну а в идеале вообще HA решает эту проблему и запускаться можно достаточно долго без ущерба.
Я, конечно, за здравую организацию архитектуры, но нужно смотреть шире и принимать во внимание косвенную выгоду тоже, как например удобство разработки в докере, количество багов отловленных до продакшена и время-деньги на этом сэкономленные. Я за то чтобы принимать во внимание весь процесс разработки, а не только время отклика сервиса.
sergey-gornostaev
17.01.2019 07:25-1идентичность среды для продакшна
Не является проблемой в java-разработке.
Lure_of_Chaos
17.01.2019 09:07Удивительно, но еще как является
Semenych
17.01.2019 09:56Я думаю сильно зависит от предметной области и того как написано приложение. При правильном подходе скорее не является, чем является, но предметная область, понятно может вносить коррективы.

vedenin1980
17.01.2019 13:58Не является проблемой в java-разработке.
Разница даже в минорных версиях JRE уже может приводить к тому, что проблема в продакшене не будет воспроизводиться на дев.стенде.
Практически дюбой микросервис требует открытых портов (для Rest, http, socket), которые могут на проде быть заняты другими сервисами.
Редкое Java приложение вообще не использует внешних баз данных или систем кэширования, которые тоже нужно устанавливать и их версии и конфигурации могут отличаться.
Поэтому «идентичность среды для продакшна» хоть для Java, хоть для любого другого языка важна. Особенно понимаешь важность, когда на продакшен у разработчиков нет иного доступа кроме получения логов, а на тестовом сервере проблема вообще не воспроизводится.
nicholas_k
17.01.2019 11:00Поднять аналог среды исполнения с помощью docker-compose, например, может сэкономить невероятное количество времени, особенно когда вводишь нового человека в проект.

bm13kk
17.01.2019 01:13Я так понял тут 2 статьи. Первая — описана заголовком и она хороша. Ее можно обсудить. Например, стек операционок и виртуалок — новая данность и докер не более чем использует ее. Современные приложения в браузере имеют более глубокий стек.
И вторая статья — пропаганда рекативного подхода. И автор хотел именно это обсудить. А первую статью использовал как подводку. Но вторая статья получилась скомканной и малопонятной. Например, совершенно не понятно, кто отвечает за конечный ответ сервера. Получается что один таск, отвечает за получение данных, а другой — за ответ. А если запущенных вторичных тасков несколько, кто собирает все данные и отвечает?mayorovp
17.01.2019 09:57Данные с нескольких тасков можно собрать через
CompletableFuture.allOf,Promise.all,Task.WhenAllи аналогичные API.
Semenych
17.01.2019 09:59Нет это все одна статья, написана по мотивам разбора проблем. Одна из существенных проблем вызвана использованием реактивного программирования и главной из причин почему был использован реактивный фреймворк — было «мы хотим реактивную систему».
Статья строго по реалиям жизни.bm13kk
17.01.2019 11:11Я ни разу не хочу сказать, что статья не нужна или, тем более, не относится к реальности. Я очень даже хочу создавать системы, которые отвечают первой картинке с элипсами. Тезисы, что докер или ассинхронная обертка для каждого ИО сами по себе только усложнят проекты (или даже замедлят) — очень даже импонируют. Я надеюсь, что мои проеты уже отвечают хотя бы половине требований. Но с банальными подходами, вроде серверная часть разделена на фронтенд и бекенд.
Другое дело, что в статье я не вижу ни одной вещи, которую я понимаю как точно применить в существующих проектах. Например вторая картинка «да\нет» — худший пример плохой презентации. Мы лучше, мотому что мы зеленые, а вы красные. Я не вижу ни одного пункта, как это «продать» CTO для одобрение интеграции.
Я бы хотел увидеть отдельную статью, как правильно использовать реактивный подход. Желательно с примерами. Как взять обычный монолитный блокирующий средний проект (скажем с миллионом пользователей) и точечно его обновить чтобы отвечать уровню реактивного.mayorovp
17.01.2019 11:35Нижняя строчка плохая не потому что красная, а потому что не работает как задумывалось. Обновить точечно ничего не получится по той же причине: пока есть блокирующие звенья, всё будет висеть на них и прироста не будет.
bm13kk
18.01.2019 20:00> как задумывалось
а как задумывалось? Вот из статьи не понятно вообще. Если задумывалось «реактивный проект» а получился «блокирующий» — то получается тавтология.
bm13kk
18.01.2019 20:10Окей я не правильно использовал «точечно». Надо было «минимало».
Но говорить, что «минимально не получится» — будет протеворечить статье. Так как в ней говорится, что в «нити» надо выносить мелкие атомарные куски. То есть то, что будет легко отделяемо даже в блокирующем коде [пока это не лапша].
Блокирующие звенья — я тоже могу отделить. Но не все. Как я спрашивал выше, таск отвечающий за ответ — в любом случае блокирующий и ждущий пока все остальные таски ответят.
cc SemenychSemenych
18.01.2019 22:41Я прощу прощения, если я отвечу немного в сторону. В статье я не рекомендую конкретный способ решения проблем, собственно про это можно было бы написать, но это тема для отдельной статьи.
Мое мнение, что играть в эти игры с перекидыванием задач между не блокирующимися потоками — довольно опасное занятие. Очень легко получить сложный, непредсказуемо работающий код.
Я бы решал задачу примерно так
1. обычные требования среднего веб приложения — вообще не использовать реактивный фреймворк, никакой пользы он не принесет. Те 5-10% процентов экономии которые он дает все равно «растворятся» в общих накладных расходах. Длинные, хорошо написанные, последовательные, блокирующиеся, императивные методы — что может быть лучше и понятнее?
2. Есть длинные задачи — использовать пул тредов и асинхронный запуск задач через org.springframework.scheduling.annotation.Async например. Тут все понятно и все это обычно умеют
3. если есть какие-то супер плотные, обоснованные бизнесом требования по использованию процессора — использовать например WebFlux — и изолировать его использование в отдельный, как можно более компактный сервис. Никаких жонглированием задачами между пулами внутри не делать — такой код относительно легко написать, но очень тяжело поддерживать.

batyrmastyr
17.01.2019 13:14Вторая часть, как по мне, водянистое «семь раз отмерь, один раз отрежь прежде чем гнаться за модой на „реактивное“ программирование». Которое к тому же не реактивное (= сверхбыстрое) а, скорее, реакционное.
VolCh
17.01.2019 17:45«реактивный самолёт» — это не «сверхбыстрый самолёт», а самолёт на реактивной тяге
batyrmastyr
17.01.2019 22:15Хотел было возразить, что у нас не о самолётах речь, а разговорное речи «реактивный» используется как синоним «очень подвижный, энергичный, быстрый», но разговорный вариант во всех словарях, кроме арго, идёт в самом конце, а основные толкования близки по смыслу к использованию в программировании.
Был неправ.
Semenych
17.01.2019 14:29Если посмотреть на комментарии, то часть читателей ругается за пропаганду реактивного подхода, а часть за критику и не понимание.
При этом сам статья, про то, что можно и так и этак, главное осознавать к чему это ведет и какие плюсы и минусы.bm13kk
18.01.2019 20:19Повторю, я не против статьи, информации в ней, опыте или подходах. Я говорю про ее структуру.
> При этом сам статья, про то, что можно и так и этак
Сейчас статья:
* Есть докер и у него такие плюсы минусы.
* Есть реактивное — у него такие плюсы минусы.
Связь между пунктами, тем более достатками и недостатками, надо еще искать. Более того, первое технология, хотя для нее нужно немного философии. Второе — философия без технологии.
А надо было:
* Есть проблема Х.
** В докере ее можно решить способом А. Будут таки плюсы минусы.
** Либо в докоре же можно решить способом Б. Плюсы минусы
** А можно решить в реактивном стиле способом В. +-
* Есть проблема Y…
Вот это уже сравнение.
Semenych
18.01.2019 22:46К сожалению на работает так как вы хотите. Нельзя рецепт счастья написать для таких случаев. Слишком много разных критериев надо учитывать, от технических до совершенно субъективных. Мне казалось я написал в виде достаточном для того, чтобы дать дальнейший толчок мысли читателя. Но вот давать рецепт для общего случая — я считаю это не профессиональным.
Тем более что все быстро меняется и «твердые» рецепты быстро устаревают.
pomme
17.01.2019 02:47В общем случае любое приложение, чувствительное к задержкам в сети в пределах до 250–500 мс, лучше не докеризировать.
Автор точно имеет в виду мс, а не мкс? +250 мс — это грандиозные задержки, особенно для микросервисных архитектур, где обычно реквест проходит несколько слоев обработки.
Да и на диаграмме над цитатой видно, что Docker добавляет средний оверхед при обработке сетевого пакета порядка 30 мкс, а не мс.Semenych
17.01.2019 09:57-1Я имею ввиду, если вам важно 250 мс, то добавочные 30мс внесут заметную погрешность >10%
pomme
18.01.2019 00:09Еще раз, на графике виден оверхед не 30 мс, а 30 мкс.
Ни миллисекунды, а МИКРОсекунды. разница в 1000 раз.
30 мкс — задержка незаметна везде, кроме крайне чувствительных сервисов, вроде FHT.
30 мс — неприятно для всех, а для микросервисных архитектур — неприемлемо.
shashilx
17.01.2019 10:35-3нахожу нечто мне интересное. а оно… докером. а я нехочу докером. у меня уже есть система, это моми проблемы, что я ее порушу. но я хочу на живое поставить, а не в докер. спрашиваешь — а как не в докере? ответ — да хз, ставь в докере. уроды, чесна.

Quilin
17.01.2019 13:06Вот уроды, написали нечто интересное и не дают порушить систему!
shashilx
17.01.2019 13:08знаете, я не из тех, которые делают по мануалу без думно. если я чтото делаю — я понимаю что я делаю. да и почему комуто должно быть какоето дело что я порушу СВОЮ систему.
tamapw
17.01.2019 13:19знаете, я не из тех, которые делают по мануалу без думно. если я чтото делаю — я понимаю что я делаю. да и почему комуто должно быть какоето дело что я порушу СВОЮ систему
Потому что вы(не конкретно вы, а общно — пользователи) потом придёте к создателю этой приблуды и начнёте вопить, «а чего это вы мне всё сломали?!», «не работает ваша херня, а я так много сил потратил, скачивая её! Почините!».
Поэтому, чтобы большинство жило счастливо приходится ограничивать их, тем самым ограничивая и тех, кто способен сам разобраться и починить.shashilx
17.01.2019 13:21это я прекрасно понимаю. я как раз из тех, кто способен сам. но прочитайте же — спрашиваешь разраба как без докера — ответ — ахз, юзайте докер. это главный посыл в моем сообщении. поколение докеров выросло, кароч. все что возможно давайте запихаем в докер.
t_kanstantsin
17.01.2019 19:47спрашиваешь — а как не в докере? ответ — да хз
А зачем разработчику париться и пооддерживать весь зоопарк операционок, их мажорных версий и программ, которые просто рядом стоят, но не дают поставить очередную зависимость, т.к. конфликтуют?
shashilx
17.01.2019 19:51откуда же вы взяли зоопарк операционок, если вопрос был — как не в докер? устроит ведь ответ под любой *nix, я уже сам разберусь что нужно допилить под ${мой_дистрибутив}. но ответ ведь — ахз, т.е. мы умеем только в докер. за докером — полный ахз.зачем вы придумали зоопарк?
4tlen
17.01.2019 14:31Зачем threads переводить как нити?
Semenych
17.01.2019 15:04Сам удивляюсь, почему так переводят. Вообще стандарты перевода отдельная тема, больше всего меня удивляет Исаак Азимов ставшей Айзеком и spice melange ставшее спайсом.
4tlen
17.01.2019 15:37После перевода не отдают на вычитку человеку в теме. Ну не знает переводчик про потоки и Азимова не читал. Досадные мелочи.
Сам спросил, сам ответил, сам молодец :)Semenych
17.01.2019 16:14человек в теме это я, threads переводится как нити примерно с прошлого века.
4tlen
17.01.2019 18:15+1threads переводится как нити в контексте нить комментариев (в адаптации на русский «ветка»). Тред в каментах, нить разговора. Когда про программирование — thread это поток. Причем не тот который stream. А Айзек это все таки имя Исаак. Но раз уж сложилось исторически что стали произносить Айзек и в русском языке, отступать уже некуда. Хотя непонятно как Ньютон Исааком остался.

Dimezis
17.01.2019 14:31Как такой же фрагмент кода будет работать в реактивном стиле? Нить исполняет вычисления, посылает HTTP-запрос и вместо того чтобы заблокироваться и при получении результата синхронно обработать его, описывает код (оставляет callback) который должен быть исполнен в качестве реакции (отсюда слово реактивный) на результат. После этого нить продолжает работу, делая какие-то другие вычисления (может быть, как раз обрабатывая результаты других HTTP-запросов) без переключения контекста.
Основное преимущество здесь — отсутствие переключения контекста
Это фантастика какая-то. Какой-то поток все равно должен заблокироваться во время IO и ждать результат. Если это не тот же самый поток, произойдет точно такое же переключение контекста. Чтобы переключения не было, блокироваться и выполнять callback должен тот же поток, а в этом смысла нет в данном случае.
Просто таски в Rx* выполняются на планировщиках, но переключение контекста с ними такое же реальное, как и при любом другом подходе.Semenych
17.01.2019 15:09Посмотрите на пакет docs.oracle.com/javase/8/docs/api/java/nio/package-summary.html и саб пакеты он как раз про неблокирующее чтение
Dimezis
17.01.2019 15:12Да, но это никаким образом не относится к реактивному программированию и тому, что написал автор. Nio можно с любым подходом использовать
mayorovp
17.01.2019 15:27Тут имелось в виду, что если есть две задачи, выполняющиеся параллельно — то один поток может начать выполнять первую, отправить http-запрос, а потом без переключения контекста начать выполнять вторую и отправить второй http-запрос.
А потом поток заблокируется и будет ждать прихода http-ответов. И обработает их точно так же подряд, и всё это без переключений контекста, если всё это каким-то чудом в квант времени уложится.Dimezis
17.01.2019 15:37Ок, понятно что имелось в виду, согласен.
Но опять же, реактивное программирование здесь не при чем.
Такое поведение достигается за счет планировщика с 2+ тредами, но не за счет «реактивности». Можно сделать то же самое, используя, например, обычный ExecutorService в Java.
Поэтому «отсутствие переключения контекста» — никак не основное преимущество RP.mayorovp
17.01.2019 16:14А второй-то тред зачем тут нужен?
Dimezis
17.01.2019 16:18Чтобы на одном из них был блокирующий IO, а на другом гонялись в это время любые другие таски
mayorovp
17.01.2019 16:24Блокирующего IO вообще не должно быть.
Dimezis
17.01.2019 16:27:)
Мы обсуждаем пример из статьи, а не спорим как должно бытьmayorovp
17.01.2019 16:29Ну так читайте статью дальше примера-то!
Далеко не все операции ввода-вывода поддерживают неблокирующие вызовы. Например, JDBC на текущий момент не поддерживает (в этом направлении идут работы см. ADA, R2DBC, но пока все это не вышло на уровень релиза). Поскольку сейчас 90 % всех приложений ходят к базам данных, использование реактивного фреймворка автоматически из достоинства превращается в недостаток. Для такой ситуации есть решение — обрабатывать HTTP-вызовы в одном пуле потоков, а обращения к базе данных в другом пуле потоков. Но при этом процесс значительно усложняется, и без острой необходимости я бы так делать не стал.

bevice
19.01.2019 00:31Hypervisor->guest->docker->jvm->app, и вся идея выбросить докер и потерять в удобстве деплоя. А почему не выбросить JVM? Нельзя, мы на ней пишем. А гипервизор? Тоже нельзя, нам так удобнее в амазоне покупать инстансы. А докер — это проблема админов, его выкинем.
Сеть докера работает на linux bridge, это вносит задержку, но она незначительна и измеряется микросекундами. Если задержка критически важна, что 30-50мкс (тут выше путались, так что поясню — это микросекунды, это в тысячу раз меньше миллисекунд) это значительно — выкинуть нужно сначала JVM.Semenych
19.01.2019 00:45Выкинуть JVM идея хорошая, но без нее к сожалению программа не работает. Вообще. Никак. Так что выкручиваемся как можем.
bevice
19.01.2019 01:58Ну а без докера не работают контейнеры, но его почему-то предлагают выкинуть. Я к тому, что оптимизировать нужно самую тяжелую часть, а она в такой ситуации как правило — JVM. Выкидывание контейнера добавит проблем к масштабируемости, стоимости администрирования и позволит увеличить хорошо если на 1% отзывчивость. Вот на графике, который привел автор видно, что докер добавляет 0.030мс к времени обработки, а автор рассуждает о приложениях, для которых критично время 250 и больше мс.
Я отказываюсь понимать пользу оптимизации в 0.012% за счет отказа простоты деплоя.
bobzer
19.01.2019 05:54Впервые за несколько лет увидел адекватную оценку этих техник. Сам понимал всегда что в большинстве проектов они не нужны, и вот в этой статье нашёл подтверждение своему мнению, разложенное по полочкам. Искренне сочувствую тем, кто внедрил в своих проектах не решение конкретных проблем, а модную штуку, которая сделала проект хуже, зато добавила крутую строчку в резюме программиста.
Не хочу сказать, что эти техники плохи, просто не надо возить уголь автобусами — они хоть и вместительные и грузоподъемные, но всё же неудобно как-то…
maxim_ge
Касательно микросервисов небезызвестный Martin Fowler в статье MonolithFirst выразился так:
Т.е. если начинаешь проект сразу с микросервисов — получаешь проблемы.
Один из вариантов разработки — начать с малого количества «макросервисов», а затем их дробить по мере необходимости.
Правда, это было довольно давно (лето 2015 года).
Ну и у Райффайзенбанк есть статья здесь: Микросервисы делают мир проще (а вот и нет)
Semenych
Спасибо за ссылки, я тоже придерживаюсь принципе «сначала монолит» прежде всего потому, что угадать как именно надо будет разбивать с начала сложно и не нужно. А вот разбитое не в том месте потом сращивать может быть дорого.
maxim_ge
Кроме того — вот мы мигрируем сейчас в облака систему, у которой в Back Office 300 (триста) таблиц, «сущностей» над этими таблицами под сотню, неужто мы должны сотню микросервисов сделать? «Монолит», очевидно, напрашивается.
Конечно, нужно сразу избавляться от взаимных зависимостей в коде, чтобы облегчить отстрел микросервисов по мере необходимости («But if you start with a monolith, the parts will become extremely tightly coupled to each other», ссылка). Согласен, OSGi — отличный способ для этого, по сути, «микросервисы».
VolCh
Обычно всё же среди сотен сущностей относительно легко выделяются кластеры сильно связанных сущностей, при этом сами кластеры слабо связаны друг с другом.
maxim_ge
Конкретный пример. Client не связан с Article, в рамках Back Office, все вместе это требуется при заказах и оплатах.
Делать четыре микросервиса:
— Client
— Article
— Order
— Payment
и еще к ним непонятное количество микросервисов, которые делают отчеты?
Мне пока видится, что нужны три монолита: BO (редактирование справочников), Sales (заказы, оплаты и проч.) и Reports.
Quilin
Микросервис per entity — как и практически любое архитектурное разделение per entity — плохая идея за редкими исключениями. Делите по бизнесу, по его процессам.
Часто встречаю такую тему, кстати, "у нас Х таблиц в базе, куда нам столько микросервисов", есть ощущение что это каргокульт: если у меня есть микросервис, скажем, форумного движка, то в нем очевидно окажется сущность Forum и называться он скорее всего будет ForumService. Но при этом в нем будут содержаться и темы, и модераторы, и комментарии, и спасибы, и прочие. Но со стороны все равно появится ощущение, что это сервис только форумов.
Semenych
Я еще слышал мнение, что на запись и чтение сервисы должны быть отдельным (и жить в разных репах разумеется).
Я считаю что дробить надо по крупным тесно связанным блокам бизнес логики, скажем так обозримого размера.
Pongo
Quilin
Это какое-то кардинальное применение CQRS. Как мне кажется, перебор.
shurup
Вот ещё в копилочку — доклад по теме: «Микросервисы: размер имеет значение, даже если у вас Kubernetes», в нём как раз есть отсылки к Martin Fowler.