

Сразу хочу оговориться, что эта статья не только подразумевает пассивное чтение, но и приглашает всех желающих присоединяться к разработке. Системные программисты, разработчики железа, сетевые и DevOps инженеры — добро пожаловать.
Поскольку проект идет на стыке сетевых технологий и хардварного дизайна, давайте разделим наш разговор на три части — так будет проще адаптировать информацию под ту или иную аудиторию читателей.
Определим первую часть как вводную. Здесь мы поговорим о хардварном инкапсуляторе ethernet-трафика, созданном на FPGA, обсудим его основные функции, архитектурные особенности и преимущества по сравнению с программными решениями.
Вторая часть, назовем ее «сетевой», будет более интересна для разработчиков железа, желающих ознакомиться с сетевыми технологиями поближе. Она будет посвящена тому, какую роль «Etherblade.net» может занять в сетях операторов связи. Так же разговор пойдет о концепции SDN (software defined networking) и о том, как открытое сетевое железо может дополнять решения больших вендоров, таких как «Cisco» и «Juniper», и даже конкурировать с ними.
И третья часть — «хардварная», которая скорее заинтересует сетевых инженеров, желающих приобщиться к аппаратному дизайну и начать разрабатывать сетевые устройства самостоятельно. В ней мы подробно рассмотрим FPGA-workflow, «союз софта и железа», FPGA-платы, среды разработки и другие моменты, рассказывающие о том, как подключиться к участию в проекте «EtherBlade.net».
Итак, поехали!
Инкапсуляция Ethernet
Цель проекта Etherblade.net — спроектировать и построить устройство, умеющее на аппаратном уровне эмулировать L2-ethernet-канал поверх L3-среды. Простой пример использования — подключение разрозненных серверов и рабочих станций между собой так же, как если бы между ними был обычный физический ethernet-кабель.
В интернете можно встретить разные термины для данной технологии. Самые распространенные из них — pseudowire, evpn, L2VPN, e-line/e-tree/e-lan и тд. Ну, и огромное количество производных терминов — разные для различных типов транспортных сетей, через которые прокладывается виртуальный ethernet-канал.
Так, например, эмуляция ethernet поверх IP-сети обеспечивается следующими технологиями — EoIP, VxLAN, OTV;
эмуляция ethernet поверх MPLS сети — технологиями VPLS и EoMPLS;
эмуляция ethernet поверх ethernet — задача технологий MetroEthernet, PBB-802.1ah и т.д.
Работа маркетологов — придумывать термины, но если бы дизайнеры железа изобретали отдельное устройство под каждый термин или аббревиатуру, они сошли бы с ума. Поэтому цель разработчиков железа и наша с вами цель — разработать универсальное устройство — инкапсулятор, который умеет инкапсулировать ethernet-фреймы в любой протокол транспортной сети, будь то IP/IPv6, MPLS, Ethernet и т.д.
И такой инкапсулятор уже реализован и развивается в проекте под названием «Etherblade-Version1 – encapsulator core».
Для лучшего понимания предлагаю рассмотреть рисунок поясняющий данный принцип инкапсуляции:
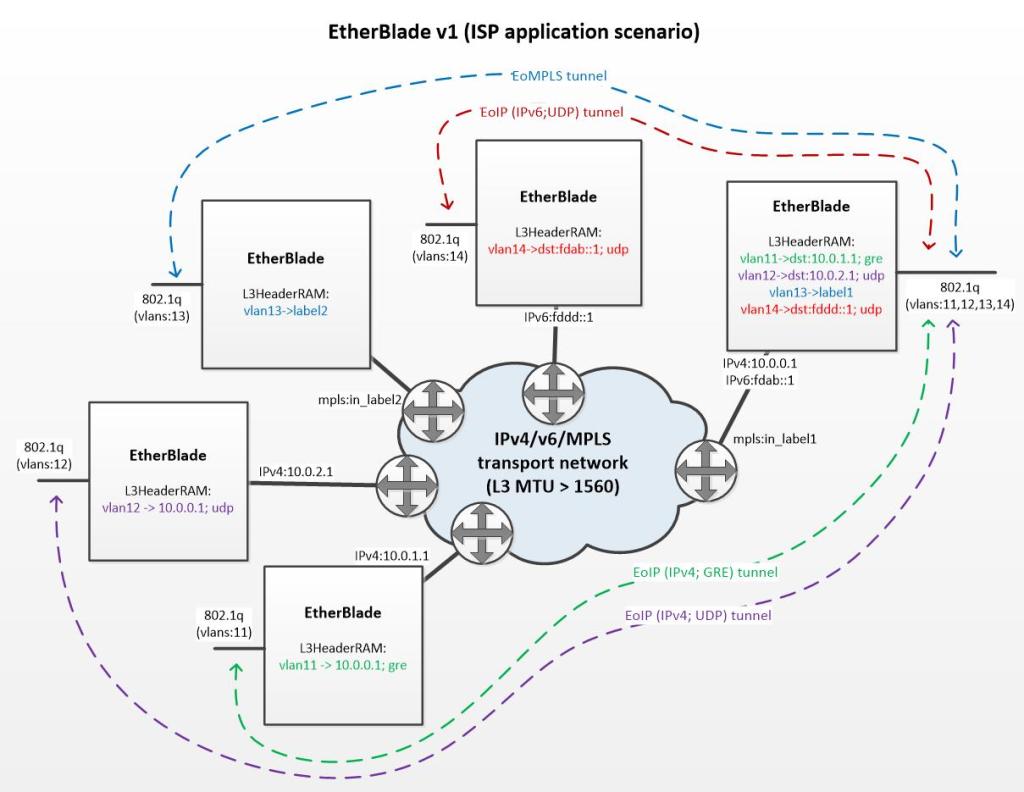
Мы видим, что инкапсуляторы находятся по периметру транспортной сети оператора связи. Каждый инкапсулятор имеет два интерфейса (L2 — транковый порт, «смотрящий» в сторону клиентов, и L3-интерфейс, который «смотрит» в сторону транспортной сети).
Давайте рассмотрим подробнее самый правый инкапсулятор. К нему подключены клиенты, где трафик каждого клиента “ходит” в отдельном vlan-e. Устройство должно уметь создавать виртуальные каналы для отдельных клиентов или, говоря научным языком, уметь инкапсулировать ethernet трафик для разных vlan-ов разными L3-заголовками. На рисунке показано, как один инкапсулятор осуществляет эмуляцию четырех виртуальных каналов для четырех клиентов:
- vlan-11 (зеленый) — Ethernet over IP (IPv4+GRE);
- vlan-12 (фиолетовый) — Ethernet over IP (IPv4+UDP);
- vlan-13 (голубой) — Ethernet over MPLS;
- vlan-14 (красный) — Ethernet over IP (IPv6+UDP);
Итак, с функционалом разобрались, теперь давайте поговорим о вариантах реализации инкапсулятора.
Почему FPGA?
FPGA это, по сути, чип, заменяющий паяльник и коробку микросхем (логические элементы, микросхемы памяти и тд). То есть, имея FPGA, мы имеем возможность создать железо под свои нужды и задачи.
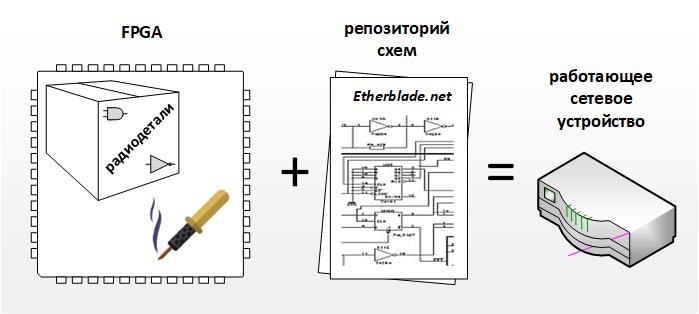
Но кроме «набора элементов и паяльника» необходимо еще иметь и принципиальные схемы. Так вот репозиторием таких схем, из которых можно «спаять» инкапсулятор внутри FPGA и получить работающее устройство, и является проект «Etherblade.net». Еще одним важным преимуществом FPGA можно назвать то, что его элементы можно «перепаять» под новые схемы, ну а сами схемы, благодаря репозиторию, не нужно создавать и верифицировать «с нуля» для реализации нового функционала.
И все таки, почему FPGA, а не софтовое решение?
Конечно, если бы вопрос ставился о разработке системы «с нуля», то взять готовый компьютер и написать к нему программу было бы проще и быстрее, чем разрабатывать специализированное аппаратное устройство.
За простоту и скорость разработки, тем не менее, приходится платить худшей производительностью, и это является основным недостатком софтового решения. Дело в том, что софт это компьютерная программа, имеющая варьируемое время исполнения из-за ветвлений и циклов. Добавим сюда постоянные прерывания микропроцессора операционной системой и рециркуляцию трафика в подсистеме DMA.
В хардварной реализации наш инкапсулятор это, по сути, прямоточный «store-and-forward» буфер оснащенный дополнительной памятью в которой хранятся заголовки. Благодаря простоте и линейности аппаратное решение обрабатывает трафик со скоростью равной пропускной способности ethernet канала с минимальными задержками и стабильным джиттером. В качестве бонуса добавим сюда меньшее электропотребление и меньшую стоимость FPGA решений по сравнению с микропроцессорными системами.
Прежде чем перейти к следующей теме, позвольте мне поделиться с Вами этой ссылкой на видео демонстрирующее инкапсулятор в действии. Видео сопряжено английскими субтитрами, а при необходимости в «Youtube» имеется опция включения автоперевода на русский язык.
В заключительной части статьи хотелось бы сказать о паре блоков которые также разрабатываются в рамках проекта «Etherblade.net».
Разработка приемника «Etherblade-Version2 – decapsulator core»
Возможно, вы заметили, что на предыдущей сетевой диаграмме (где изображены инкапсуляторы, подключенные к сети провайдера) есть одна маленькая ремарка, указывающая на то, что MTU в сети должно быть больше 1560. Для больших операторов связи это не является проблемой, так как они работают на «темных» оптоволоконных каналах со включенной поддержкой jumbo-frames на оборудовании. В этом случае инкапсулированные пакеты ethernet, максимальным размером 1500 байт и дополнительным L3-заголовком могут свободно «ходить» по таким сетям.
А что, если в качестве транспортной сети мы хотели бы использовать обычный интернет с инкапсуляторами подключенными, скажем, к домашним DSL или 4G модемам? В этом случае приемная часть инкапсуляторов должна уметь собирать фрагментированные ethernet-фреймы.
Ни «Cisco» ни «Juniper», на данный момент, не предлагают такой функционал в своих устройствах и это понятно, ведь их оборудование ориентировано на больших операторов связи. Проект «EtherBlade.net» изначально ориентирован на клиентов разных калибров и уже имеет в своем арсенале разработанный метод «хардварной» сборки фрагментов, позволяющий эмулировать «ethernet-anywhere» каналы c «telco-grade» качеством сервиса. За подробной документацией и исходными кодами добро пожаловать на https://etherblade.net.
10 Гигабит
На настоящий момент также ведется активная работа над десятигигабитной версией инкапсулятора и портированием его на железо, в частности на показанную в начале статьи Intel Cyclone 10GX плату от питерской команды General R&D.
Помимо описанного в данной статье функционала десятигигабитные инкапсуляторы могут применяться в сетях операторов связи для перенаправления «интересного» трафика на клиринговые центры DDoS, сервера «Яровой» и т.д. Подробнее об этом — в следующей статье, посвященной концепции SDN (software defined networking) и использованию «Etherblade.net» в больших сетях – stay tuned.
Комментарии (54)

maxbrsw
08.02.2019 16:50+2Позвольте пару вопросов:
1)Почему именно Intel?
2)Существует ли возможность посмотреть на layout этой борды?
3)Не думали замахнуться на большие скорости(в т.ч. существенно большие)?
4)Как подбирали декапы под циклоном?
etherblade Автор
09.02.2019 00:511. Проект является репозиторием схем и по сути вендор-независимый. Можно портировать как на Intel так и на Xilinx.
2. Pinout всегда идет вместе с FPGA платой — иначе как с ней работать если не знать к каким «ножкам» какая периферия подключена?
3. Десять гигабит похоже на скорость близкую к максимальной для FPGA. Тем не менее из FPGA можно «выпечь» ASIC способный работать на большей тактовой частоте/скорости (40 и 100Гигабит) — ну тут уже все гораздо серьезней становится именно с финансовой точки зрения.
4. Подбор «декапов» это скорее вопрос к разработчикам платы.JerleShannara
09.02.2019 02:00Можно на QSFP замахнуться и выжать 40GbE, можно застрелить жабу, пролюбить сроки и замахнуться на Stratix с его трансиверами (там уже вроде 100GbE получить можно).
etherblade Автор
09.02.2019 03:38FPGA в силу своей конфигурационной гибкости достаточно ограничена по тактовой частоте в силу избыточной логики, особенно на коммутационных блоках. Для построения систем со скоростями 10гигиабит — FPGA подойдет. Та так же FPGA — отличный вариант для тестирования и отладки схем. Все что выше по скоростям — делаем из отлаженных на FPGA схем ASIC.
JerleShannara
09.02.2019 04:52Arria 10 вроде вполне переваривает 40GbE, а с десятым стратиксом пришел новый интерконнект, который сделан весьма подходящим для построения конвеера и разбивания комбинаторики и как следствие задирание частоты работы бЭсплатно для разработчика (можно где-то на 5-10% частоту повысить установкой одной единственной галочки, а далее руками, у интеловцев на эту тему онлайн обучалка есть весьма недурная). По ценнику — для мелкой серии ПЛИС будет всеж дешевле, чем заказной кремний, правда сейчас привезти в РФ стратиксы почти нереально.
Brak0del
09.02.2019 06:14Вот всё-таки не понял, почему вы FPGA ограничили 10Гб/с или это ограничения вашей реализации? Вон у xilinx есть корки для 40 и 100Гб для представителей 7 серии. Насколько понимаю реализовано это через GTX/GTH трансиверы. А по поводу частот, у них там просто широкие шины внутри, судя по рисункам, 128 или 256 бит.
microtrigger
08.02.2019 17:30+1Прошу уточнить что именно будет open и под какой лицензией?
etherblade Автор
09.02.2019 01:01Репозиторий открытый, можно портировать блоки на FPGA платы, начинать свои проекты на основе имеющихся блоков и т.д. Единственным ограничением является недопустимость реализации блоков в виде ASIC без согласования с авторами.

amarao
08.02.2019 17:41Задача крайне важная, но вечно натыкающаяся на то, что L3 — это не L2. Вот я вижу энкапсуляцию (для простоты обсуждения, 10.0.0.1). Почему 10.0.0.1? Откуда там 10.0.0.1 (а не 192.168.2.3, например)? Предполагается, что где-то там наверху кто-то из множества таких устройств соберёт бридж на центральном сервере? Как конкретная железка стала понимать, что 10.0.0.1, а не что-то другое и по какому признаку оно его меняет?
И главный вопрос: а где оно физически находится? Болтается на линке между клиентским портом и портом провайдера? (Со своим БП и прочими неудобствами?).mmmmmike
08.02.2019 18:49FMC-бутерброд по толщине прекрасно вписывается в 1U, также существует огромное множество отладочных плат под FPGA с 2-4 SFP либо 2 QSFP в PCI/PCIe форм-факторе.
amarao
08.02.2019 18:55Я смотрю на это с точки зрения датацентров, и обычно тут ToR, который 1-2 юнита на 40+ железок снизу. Вот специализированная SFP'шка (которая говорит сетевухе «я sfp с ethernet», а сама шлёт L3) — это была бы сказка, да.
etherblade Автор
09.02.2019 01:28Предлагаю Вам посмотреть видео демонстрирующее инкапсулятор в действии:
Ссылка на видео.
Первая часть видео рассказывает об архитектуре инкапсулятора, а вторая демонстрирует его в действии. Принцип простой, в памяти хранятся L3 заголовки которыми инкапсулируются входящие L2 ethernet фреймы — то есть происходит преобразование (L2->L3).
Если необходимо, видео сопряжено английскими субтитрами, а при необходимости в «Youtube» имеется опция включения автоперевода на русский язык.
На приемном инкапсуляторе происходит обратное преобразование (L3->L2) которое делает из L3 исходный L2 фрейм (то есть просто игнорируются первые N-байт равные длине L3 заголовка). Если не требуется сборка фрагментированных фрагментов — логика преобразования (L3->L2) чрезвычайно проста.
xcore78
09.02.2019 03:48+1Небольшой совет: интуитивно принято заголовки (особенно если вы говорите prepend) приклеивать перед фреймом.
Содержимое аидео функционально похоже на OpenFlow устройство без контроллера. Самое сложное как в OpenFlow, так и в MPLS (как и в IP-маршрутизации в целом) — сигналинг.
Раз у вас есть такая демка, расскажите, как устроены потроха? Например, как-где происходит выделение буферов, как устроен QoS в целом и частностях, как организована «сеть» внутри устройства: есть ли микробуферизация, на какие части делите пакет, как склеиваете обратно. Это вот прямо то, что очень интересно лично мне :-)etherblade Автор
09.02.2019 14:42Содержимое аидео функционально похоже на OpenFlow устройство без контроллера. Самое сложное как в OpenFlow, так и в MPLS (как и в IP-маршрутизации в целом) — сигналинг.
Для лабораторного сценария (быстрый колхозный вариант) можно взять raspberry-pi которая будет общаться с SDN-контроллером через по протоколу IP а с другой стороны прописывать необходимые заголовки в FPGA для разных вланов через com-port. Это простой pseudowire overlay там сигналинга нет, нужет только начальный provisioning L3 заголовков.xcore78
09.02.2019 20:33+1ком-портом вы себя сильно ограничиваете — не сейчас, так в перспективе. Не хотите прикрутить третий эзернет на гиг для управления? Модуль вам все равно понадобится, если вы решите пойти дальше экспериментов по изменению пакетов.
etherblade Автор
10.02.2019 00:49Я кстати хотел написать в третей части статьи и уточнить что etherblade.net это по сути только репозиторий схем (IP-cores) — для построения hardware plane.
Целью проекта не является создание конечной системы. То есть создание обвязки — системы на чипе, портирование на FPGA платы, написание embedded management software которое будет коммуницировать с SDN контроллером, создание которого так же выходит за рамки данного проекта — предполагается отдать на разработку в комьюнити.
На самом деле etherblade.net это только 5-10% работы, оставшиеся 90% это сигналинг написание софта, интеграция, портирование, тестирование (все, что не Verilog).
Как предписывает концепция SDN, программисты и разработчики железа работают отдельно и делают свои части (определили интерфейс взаимодействия софта и железа и вперед).
Модуль вам все равно понадобится, если вы решите пойти дальше экспериментов по изменению пакетов.
Да, можно даже взять FPGA с третьим интерфейсом (CycloneV например) с хардварной ARM процессорной частью и линуксом и как Вы абсолютно правильно говорите отдельным out-of-band management ethernet интерфейсом. Опять же портирование на платы хотелось бы вынести за рамки проекта.
etherblade Автор
09.02.2019 15:00Например, как-где происходит выделение буферов, как устроен QoS в целом и частностях
С QoS не заморачиваюсь поскольку это pseudowire устройство всего с двумя интерфейсами работает по принципу «первый пришел первый вышел» — switchfabric congestion отсутствует так как нет этого самого switchfabris и, к слову, mac-learning тоже нет.
есть ли микробуферизация, на какие части делите пакет, как склеиваете обратно. Это вот прямо то, что очень интересно лично мне :-)
По сути дела инкапсулятор это фреймовый буфер (на данный момент он на 4 фрейма размером 2048байт каждый).
Разделение пакета это Вы имеете в виду фрагментацию? Фрагментация в разработке в другой части проекта. Самая сложная чась — склейка фрагментированных фрагментов. Демонстрация принципа алгоритма склейки фрагментов в железе без участия софта здесь.
К вопросу на счет внутреннего устройства на сайте есть раздел «documentation» там есть документация и исходный Verilog. Боюсь что лучше чем там написано я сейчас не смогу объяснить.xcore78
09.02.2019 20:46Фрагментация — это термин L3+, я про внутреннее хранение и обработку фреймов.
Я так понял, вы просто складываете фрейм целиком.
(Кольцевой) буфер на 2-3 фрейма даст вам лучшую производительность — маркировка и обработка очереди у вас уже, судя по презентации, в каком-то виде есть.
Или соль в том, что вы декодируете заголовок входящего потока на лету, помещая фрейм в буфер с пред-созданным заголовком (mpls, GRE, IPIP)?
После просмотра видео очередной вопрос на перфоманс: вы измеряли внесённую задержку с подходом «положи весь фрейм в буфер, обменяйся сигналами с блоками приёма и обработки, дождись обработки фрейма»?
Задержка обработки в некотором роде связана с глубиной буферизации на входе. Какие ресурсы по памяти предоставляет вам FPGA? Будете ли вы использовать внешнюю память, если-когда памяти на чипе вам не хватит?
Верилог я не пойму :) В любом случае, верилог — это реализация концепции, мне интереснее сама концепция.etherblade Автор
10.02.2019 15:45Я так понял, вы просто складываете фрейм целиком.
Да принимаем фрейм целиком — классический «store-and-forward».
(Кольцевой) буфер на 2-3 фрейма даст вам лучшую производительность — маркировка и обработка очереди у вас уже, судя по презентации, в каком-то виде есть.
Или соль в том, что вы декодируете заголовок входящего потока на лету, помещая фрейм в буфер с пред-созданным заголовком (mpls, GRE, IPIP)?
Используется кольцевой буфер на 4фрейма каждый максимальным размером 2048 байт.
Декодировки фрейма на лету нет, но при буфферизации фрейма в отдельные регистры записываются номер vlan и в конце значение счетчика длины принятого фрейма.
После просмотра видео очередной вопрос на перфоманс: вы измеряли внесённую задержку с подходом «положи весь фрейм в буфер, обменяйся сигналами с блоками приёма и обработки, дождись обработки фрейма»?
Обработки фрейма и обмена сигналами после приема фрейма нет. Сразу после приема фрейма уже имеются все данные для генерации правильного заголовка (так как номер vlan уже увляется указателем на память с заголовком из которой сразу же можно считывать данные для L3 заголовка).
Ну и сам исходный буфферизованный фрейм уже имеется сохраненным в другом блоке памяти.
На выходе системы стоит мультиплексор который склеивает (направляет данные из генератора L3 заголовоков и как L3 заголовок закончился переключается на память где хранится исходный фрейм).
Задержка обработки в некотором роде связана с глубиной буферизации на входе. Какие ресурсы по памяти предоставляет вам FPGA?
В данной реализации фреймовый кольцевой буффер построен на ячейке SRAM размером 8192байта достаточной для буфферизации четырех фреймов каждый максимальным размером 2048 байт.
Будете ли вы использовать внешнюю память, если-когда памяти на чипе вам не хватит?
В FPGA таких SRAM ячеек тысячи, из маленьких можно комбинировать бОльшую память (если нужнен буффер на 16, 32 или 64 фрейма).
Внешняя память это DDR DRAM, в FPGA ее нет (она как правило внешняя) и она нам не нужна.
Верилог я не пойму :) В любом случае, верилог — это реализация концепции, мне интереснее сама концепция.
Верилог — дело десятое. Важно понять то, что хардварный дизайн более схож с дизайном водопроводных систем (я не шучу), где много всего происходит одновременно, чем с традиционным линейным программированием :-)
И как вы правильно сказали «колцевые буфферы» — наше все.
Посмотрите документацию на проект “EtherBlade.net Ver1”, там есть pdf-ка — в ней более детально расписано то что я изложил здесь.
Если интересно, про устройство кольцевого буффера на основе SRAM посмотрите документацию на “EHA – Ethernet Hardware Encapsulator” – legacy project (версия первая).
Опять же для разработки control-plane все это дело абстрагируется до блоков адресов для программирования data-path.
xcore78
08.02.2019 21:55+2Скажите, вы просто хотите дешево терминировать MPLS? Или проект в целом больше учебный, чем продакшен?
Уже спрашивали выше, но считаю нужным продублировать: 10Гбит/с — это очень, очень, очень мало для того, чтобы возиться с кастомным FPGA. Как вы обосновываете экономическую сторону? (если, опять же, проект преследует не ислючительно учебные цели)
Спасибо. В любом случае, дело вы делаете интересное.etherblade Автор
09.02.2019 01:40Академическая составляющая проекта чрезвычайно важна!
Ну ведь не имея 1гигабит нельзя получить 10гигабит так же как не имея 10гигабит нельзя получить 40 или 100.
Тем не менее переход на более высокую скорость требует гораздо меньшего количества инженер-часов если а) архитектура устройства определена и отработана, б) блоки и протоколы верификации имеются в наличии, в) накоплен опыт разработки подобных систем.xcore78
09.02.2019 02:01+1На более высокой скорости у вас будет другая архитектура в силу разных ньюансов. Вы правы, не _абсолютно_ всё придется переделывать. Но и простой сменой трансивера+serdes вы не обойдётесь.
Поэтому я и спросил, какая цель проекта. В опенсорсе как таковом уже есть baremetal коммутаторы (например, bm-switch.com). Причина терминации на оконечке мне пока из ваших объяснений не ясна (спросите знакомого сетевого инженера, что он думает про «отдать периметр сигнализации и/или транспорта другим людям»).etherblade Автор
09.02.2019 03:19В опенсорсе как таковом уже есть baremetal коммутаторы (например, bm-switch.com).
Но ведь сами внутренности коммутирующего ASICа закрыты, правильно?
Под опенсорс-ом здесь понимается то что система комманд программирования чипа открыта но не сами «внутренности» чипа.
Если я не прав дайте ссылку на RTL ASICa плиз, я как вижу там используется StrataXGS Tomahawk от BroadCom.xcore78
09.02.2019 03:33+2Я не занимаюсь непосредственно разработкой на броадкоме, предметно ответить по чипу не смогу.
Знаю только о существовании Broadcom SDK. Внутренности чипа открыты настолько, насколько это нужно для управления чипом. Увы, даже если бы я что-то знал непосредственно — там везде NDA.
Вы смотрели в сторону P4 (https://p4.org/)?
(извините, я продолжаю не понимать, какая цель проекта, поэтому, возможно, задаю нерелевантные вопросы)
etherblade Автор
09.02.2019 03:09-1На более высокой скорости у вас будет другая архитектура в силу разных ньюансов. Вы правы, не _абсолютно_ всё придется переделывать. Но и простой сменой трансивера+serdes вы не обойдётесь.
Правильно, существуют два пути повышения скорости:
Первый увеличение разрядности шины, второй повышение тактовой частоты устройства.
Для того что бы получить 10гигабит line-rate на FPGA мы должны реализовать инкапсулятор на 64-х разрядной шине (которая будет обрабатывать восемь байт за такт вместо одно как на гигабите) и запустив нашу плату на частоте 156.25 МГц получаем десять гигабит.
То есть переход от одного гигабита на десять это фактически смена архитектуры но мы все же находимся в зоне комфорта «жирной» FPGA такой как Cyclone 10GX.
Переход от десяти гигабит на более высокие скорости это уже увеличение тактовой частоты (так как шина уже 64бита куда больше?).
FPGA не может работать на очень высоких тактовых частотах следовательно выход один — берем схемы из репозитория и выпекаем по ним ASIC. ASIC в отличие от FPGA модно запустить на гигагерцовых частотах получив на нем 40-100 гигабит line-rate скорость.
Des333
09.02.2019 03:23-1Больше 64-битной шины, например, 512-битная :)
etherblade Автор
09.02.2019 15:24Денис приветствую,
Для простоты перехода от гигабита на десять можно договориться что L3 заголовок всегда кратный 8 байтам (64битам) что бы избежать misalignment между заголовком и телом пакета при их склеивании на выходе мультиплексором.
В этом случает потребуется 8-to-64bit gearbox между восьмибитным выходом генератора заголовка и 64 битным выходящим мультиплексором. Генератор заголовков все равно останется восьмибитныйм, поэтому пока отправляется тело предыдущего пакета одновременно с этим уже идет генерация следующего заголовка и его упаковка в 64битный формат для конечной отправки.
При дальнейшем расширении шины я боюсь что восьмибитный генератор заголовков не будет успевать их генерировать и упаковывать в 64бита (со скоростью байт за такт) пока отправляется предыдущий пакет со скоростью 64 байта за такт то есть выходная скорость будет падать так как слишком большая разница между компонентами.
В коммутаторах такой проблемы нет так как они не меняют сам фрейм то есть им все равно какая шина (хоть 512), они одинаковыми порциями загребают такими же порциями и выбрасывают на выходе.Des333
09.02.2019 15:42+2Конечно, Вы правы — переход на более широкую шину может привести к значительному усложнению/переделке дизайна.
Просто в сообщении выше Вы написали:
Переход от десяти гигабит на более высокие скорости это уже увеличение тактовой частоты (так как шина уже 64бита куда больше?).
И как вывод:
FPGA не может работать на очень высоких тактовых частотах следовательно выход один — берем схемы из репозитория и выпекаем по ним ASIC
А это не совсем верно (точнее, совсем не верно) — топовые FPGA позволяют получить поддержку 40G/100G. Для этого придётся использовать шины шириной порядка 256/512 бит и частоты порядка 312.5 МГц.
Конечно, такая разработка:
- Много сложнее и дольше, чем для 1G/10G
- Может потребовать написания с нуля большого числа модулей. Так как модули для 1G/10G переиспользовать не получится
Но, как говорится, C'est la vie.
Если хочется поддерживать на FPGA большие скорости, придётся прилагать большие усилия.
xcore78
09.02.2019 03:37Какой порядок PPS вы планируете получите сейчас, на 10Gbps?
Что планируете получить на 100Gbps путем описанного масштабирования?
Для пакетов размером 64B-128B, например.etherblade Автор
09.02.2019 03:52Планируем получить 10Gb ethernet line-rate speed как в ethernet коммутаторах.
Размер пакетов тут особой роли не играет (ну почти не играет у каждого фрейма ведь есть — избыточная преамбула ethernet, inter-frame-interval, CRCs).xcore78
09.02.2019 03:57Если просто взять и поделить, это 19.5 млн пакетов в секунду. Которые должны как минимум быть просто последовательно обработаны (в вашем случае с 2 портами этого достаточно). У вас устройство работает только в симплексном режиме? Количество портов не превысит два?
Для какого размера таблицы правил инкапсуляции число 19.5 млн еще будет выполняться?xcore78
09.02.2019 20:29+2Меня мало волнуют минусы или плюсы, которые вы ставите у себя в голове. Но заданные вопросы — по существу. Если вы их не понимаете — минусы эти вам, а не мне.
old_bear
09.02.2019 10:36так как шина уже 64бита куда больше?
Зачем сковывать себя типовыми разрядностями? Это же FPGA — там можно всё, что в чип лезет.
Кстати, сейчас типовая частота для расслабленного дизайна в FPGA уже не 150 а 300 Мгц.old_bear
09.02.2019 19:44Минусёры, вы хоть отпишитесь с чем вы не согласны (аж до слива кармы) — с возможностью реализовать любые тайные желания в FPGA или с относительно несложным достижением 300 МГц в проектах на актуальных семействах.
А то как дети малые, право слово.
Leks62
09.02.2019 14:06+1etherblade в вашей модели, как я понял, 10G инкапсулируется в те же самые 10G и объем трафика на выходе должен увеличиться. Получается в предельных режимах возможна потеря пакетов?
etherblade Автор
09.02.2019 14:19Верно все как на коммутаторах — 100% загрузка буфера инкапсулятора вызовет buffer-overflow на входящем FIFO и данные фреймы будут промаркированы как «битые» и отброшены инкапсулятором.
Можно сделать инкапсулятор с более глубокой буфферизацией (на 32 ethernet фрейма вместо четырех) для лучшей обработки burst-траффика.Brak0del
09.02.2019 14:48Это интересно, а не пробовали замерять деградацию производительности для таких случаев (переполнения fifo)? Особенно интересно как поведёт себя девайс в случае нагрузки tcp, какие просадки будут. На уровне ethernet никакого flow control не используете? И если не используете, то по каким соображениям?
etherblade Автор
09.02.2019 15:47Это очень интересно.
Вообще сам процесс синтезирования RTL (читай Verilog/VHDL) и портирования его на FPGA, создание системы на кристалле и тестирования всего этого дела в работе интереснейшее занятие.
Похоже пора создавать форум, выкладывать гайды по портированию и ждать результатов тестов от community. Помню в СССР был журнал радио где выкладывалась схема, которую паяли у себя дома, тестировали и в следующих журналах делились мнениями и необходимыми доработками.
Сегодня есть FPGA так что можно делать чипы не отходя от лаптопа.Brak0del
09.02.2019 16:00Знаете, с синтезом и проектированием под FPGA хорошо знаком) Вопросы задавал не спроста, а с целью обогащения опытом, есть серьезные подозрения (но, конечно, могу и ошибаться) что в вашей реализации будут существенные просадки для tcp и прозрачной ваша реализация не будет. Думал, что вы это уже решили, похоже ещё не добрались.
etherblade Автор
09.02.2019 16:07Почему будут просадки по tcp? Инкапсулятор не будет даже знать что у него там за пакет. Это ведь по сути дела хардварный буфер с некоторой логикой прикрепления заголовков из памяти в зависимости номера VLAN. В инкапсуяторе нет TCP/IP стека, тем не менее инкапсулировать ethernet в IPv4/IPv6 он умеет если в памяти адресуемой данным номером влана прописан заголовок формата IPv4/IPv6.
Brak0del
09.02.2019 16:21Вы пишете, что теряются пакеты когда переполняется fifo, это будет вызывать повторные пересылки у tcp (хоть инкапсулятор не знает о типе нагрузки, о потерях пакетов узнают клиент и сервер tcp и начнут реагировать), будет уменьшаться congestion window у отправителя да и просто больше подтверждений будет сыпаться вместо полезного трафика, т.е. пойдет деградация. Спору нет, если нагрузка слабая или не tcp, никто и не заметит, а вот на полную если загрузить с одного клиента tcp, тогда, по-моему, пойдут чудеса.
etherblade Автор
09.02.2019 18:19tcp — саморегулируемый протокол, он начинает разгоняться с нуля и при первых дропах (возникающих в самом узком месте сети я не думаю что 10гигабитный инкапсулятор часто будет таковым являться) начинает «сбрасывать газ».
В любом случае хардварному буферу не интересно какой там пакет. Его заботит только один параметр — номер vlan входящего ethernet фрейма.Brak0del
09.02.2019 18:29+1По поводу tcp и саморегулируемости, он не только сбрасывает газ, но может и добавлять его, когда видит такую возможность, в результате могут появляться ощутимые скачки. Суммируя ваш ответ, правильно ли понимаю, что в девайсе никакого управления потоком не реализовывали, даже на ethernet уровне, и такие вещи не планируете?
etherblade Автор
09.02.2019 19:31Абсолютно никакого — через некоторое время (при полном заполнении буфера) начнутся dropped frames на входном интерфейсе при достижении пиковой пропускной способности выходного интерфейса.
Brak0del
09.02.2019 19:06И ещё вопрос, по ссылке на ваш проект в описании сказано следующее:
Additional features like encryption can be added with zero impact on the system’s performance.
. Подскажите, как это измерялось или на чем базируется предположение? Учитывая, что время на зашифрование пакетов существенно разнится в зависимости от размеров пакета, не говоря уже об особенностях алгоритма шифрования, интересно, как вы это планируете реализовать, не ухудшив производительность?etherblade Автор
09.02.2019 19:23Предполагается использование модулей потокового шифрования — line-rate.
GarryC
А Вы точно уверены, что
Что то мне кажется, что специализированные приемопередатчики в МПС дешевле и меньше едят, чем синтезированные, или надо брать FPGA с готовыми сетевыми блоками.
QwertyOFF
Сейчас делаю проект на Zynq 7045 (система на кристалле от Xilinx). В РФ чипы продают по цене порядка 30 т.р. SFP+ трансивер (и даже не один) можно подключить к выводам SoC без необходимости использовать какие-либо микросхемы физического уровня. Бонусом получаете двухъядерный процессор и возможность обработки потока данных на ПЛИС. Не думаю, что получится сэкономить используя МПС.
old_bear
Причём можно в FPGA вытащить из процессора вычислительно-критичный кусок С-кода без написания HDL-я при помощи волшебного софта Xilinx SDx. Хотя всё равно нужно понимать, что делаешь но это быстрее чем HDL писать и фиксить.
Mogwaika
А это уже работает эффективно для чего-то кроме фильтров?
old_bear
Есть определённые правила, которые надо соблюдать при написании кода, но в общем вполне сносно. Ну и проверять надо результаты, т.к. синтезатор изредка лажает.
etherblade Автор
Скажите, что Вы имеете в виду под специализированными приемопередатчиками в МПС? Маршрутизатор с network-ASICs на линейных картах?