
Прим. перев.: Оригинальная статья была написана инженером из Швеции — Christian Abdelmassih, — который увлекается архитектурой уровня enterprise, ИТ-безопасностью и облачными вычислениями. Недавно он получил степень магистра в области Computer Science и спешит поделиться своим трудом — магистерской диссертацией, а точнее — её частью, посвящённой проблемам изоляции контейнеризированного [и запущенного в Kubernetes] приложения. В качестве «клиента», для которого была подготовлена эта исследовательская работа, выступает ни много ни мало полиция его родины.

Оркестровка контейнеров и облачные (cloud-native) вычисления стали очень популярными в последние годы. Их адаптация дошла до такого уровня, что интерес к ним проявляют даже финансовые предприятия, банки, госсектор. На фоне других компаний их выделяют обширные требования в области безопасности информации и ИТ.
Один из важных аспектов — как могут использоваться контейнеры в production-окружениях и в то же время поддерживаться системное разграничение между приложениями. Поскольку такие организации используют частные облачные окружения, основанные на виртуализации поверх bare metal, потеря такой изоляции при миграции в окружение с оркестрируемыми контейнерами недопустима. С учётом этих ограничений и написана моя диссертация, а в качестве целевого клиента в ней рассматривается Полиция Швеции.
Конкретным вопросом исследования, рассматриваемого в диссертации, является:
Этот вопрос требует тщательной проработки. Чтобы начать с чего-то, посмотрим на общий знаменатель — приложения.
Уязвимости в веб-приложениях — настоящий зоопарк из векторов атак. Наиболее значимые риски которых представлены в OWASP Top 10 (2013, 2017). Подобные ресурсы способствуют обучению разработчиков в области снижения типовых рисков. Однако даже если разработчики написали безупречный код, приложение всё ещё может быть уязвимым — например, через пакетные зависимости.
David Gilbertson написал замечательную историю о том, как можно добиться инъекции кода через зловредный пакет, распространяемый, например, в рамках NPM для приложений на базе Node.js. Для обнаружения уязвимостей можно использовать сканеры зависимостей, однако они только снижают риск, но не ликвидируют его полностью.
Даже если вы создаёте приложения без сторонних зависимостей, всё ещё нереалистично будет полагать, что приложение никогда не станет уязвимым.
Из-за этих рисков мы не можем говорить, что веб-приложения безопасны.
Вместо этого стоит придерживаться стратегии «глубокой обороны» (defense in depth, DID). Взглянем же на следующий уровень: контейнеры и виртуальные машины.
Контейнер — изолированное пользовательское (user-space) окружение, которое зачастую реализуется с помощью возможностей ядра. Например, Docker для этого использует пространства имён Linux, cgroups и capabilities. В этом смысле изоляция Docker-контейнеров сильно отличается от виртуальных машин, запускаемых гипервизорами типа 1 (т.е. работающими прямо на железе; bare-metal hypervisors).
Разграничение для таких виртуальных машин может быть реализовано на настолько низком уровне, что и в реальном железе, например, через Intel VT. Docker-контейнеры, в свою очередь, для разграничения опираются на ядро Linux. Это отличие очень важно учитывать, когда речь идёт об атаках уровнем ниже (layer-below attacks).
Если злоумышленник способен исполнять код в виртуальной машине или контейнере, он потенциально может добраться до уровня ниже, выполнив атаку выхода за пределы (escape attack).

в зависимости от того, используются контейнеры или виртуальные машины на железе, разграничение реализуется на разных уровнях инфраструктуры.
Возможность таких атак была доказана для гипервизора VMware ESXi во время конкурса хакеров Pwn2Own 2017, а также GeekPwn2018. Результатом стала пара CVE (CVE-2017–4902, CVE-2018–6981), которые могут использоваться в атаках layer-below для выхода из виртуальных машин (virtual machine escape). Виртуальные машины на железных серверах не гарантируют абсолютной безопасности даже несмотря на то, что используют технологии разграничения уровня железа.
С другой стороны, если мы посмотрим на векторы атаки на стоящий на bare-metal гипервизор в сравнении с ядром Linux, очевидно, что у последнего гораздо большая поверхность атаки — из-за его [ядра Linux] размера и спектра возможностей. Большая поверхность атаки подразумевает больше векторов потенциальных атак для облачных окружений, использующих контейнерную изоляцию. Это проявляется в растущем внимании к атакам выхода из контейнера (container escape attacks), которые стали возможными благодаря эксплоитам к ядру (например, CVE-2016–5195 [т.е. Dirty COW — прим. перев.], CVE-2017–1000405).
Для повышения изоляции внутри контейнера можно использовать модули вроде SELinux или AppArmor. К сожалению, такие механизмы безопасности в ядре не предотвращают escape-атаки на само ядро. Они лишь ограничат возможные действия злоумышленника, если выход за пределы не представляется возможным. Если же мы хотим разобраться с выходами за пределы контейнера, необходим механизм изоляции вне контейнера или даже ядра. Например, песочница (sandbox)!
gVisor — песочница для исполняемой среды контейнеров, код которой был открыт Google и которая добавляет дополнительное ядро между контейнером и ядром ОС. Такой тип песочницы может улучшить ситуацию с атаками выхода за пределы контейнера, которые осуществляются на уровне ядра. Однако эксплоиты к ядру — лишь один из инструментов злоумышленника.
Чтобы увидеть, как другие атаки могут привести к схожим результатам, необходимо взглянуть на более общую картину, как используются контейнеры в эпоху cloud native.
Чтобы управлять контейнерами, запущенными в окружениях со множеством узлов, внедряют оркестровку, лидирующую роль в которой отдают Kubernetes. Как выясняется, баги оркестратора тоже могут повлиять на изоляцию контейнеров.
Tim Allclair выступил с замечательной презентацией на KubeCon 2018, в которой отметил некоторые поверхности атаки. В своём докладе он упоминает пример (CVE-2017–1002101), как баги оркестровки могут повлиять на изоляцию — в данном случае через возможность монтирования дискового пространства, находящегося вне pod'а. Уязвимости подобного вида очень проблематичны, т.к. могут обходить песочницу, в которую обёрнут контейнер.
Внедрив Kubernetes, мы расширили поверхность атаки. К ней относятся системы, которые хостятся на master'е Kubernetes'а. Одной из них является API-сервер Kubernetes, где недавно обнаружили уязвимость, позволяющую превышать полномочия (CVE-2018–1002105). Поскольку поверхность атаки Kubernetes master'а выходит за рамки моей диссертации, эта конкретная уязвимость не берётся во внимание.
Почему escape-атаки столь важны? Контейнеры представили возможность запуска множества совместно размещённых приложений в рамках одной ОС. Так возник риск, связанный с изоляцией приложений. Если критичное для бизнеса приложение и другое уязвимое приложение работают на одном хосте, злоумышленник может через атаку уязвимого приложения получить доступ к критичному.
В зависимости от того, с какими данными работает организация, их утечка может навредить не только самой организации, но и физическим лицам, и целой стране. Как помните, речь идёт про госсектор, финансы, банки… — утечка может серьёзно повлиять на жизнь людей.
Так может ли оркестровка контейнеров вообще использоваться в подобных окружениях? Перед тем, как приниматься за дальнейшие размышления, надо провести оценку рисков.
Ещё до того, как вводить меры безопасности, важно подумать над тем, какую же информацию организация на самом деле пытается защитить. Решение о том, нужны ли дальнейшие шаги по предотвращению возможных escape-атак на контейнеры, зависит от данных, с которыми работает организация, и услуг, которые она оказывает.
В перспективе это означает, что для достижения возможности выхода из контейнера на корректно настроенном хосте, защищённом песочницей для контейнера, злоумышленник должен:
Как можно догадаться, организация, которая не считает подобный сценарий допустимым, должна работать с данными или предлагать услуги, которые весьма требовательны к конфиденциальности, целостности и/или доступности.
Поскольку диссертация посвящена именно таким клиентам, потеря системной изоляции посредством выхода за пределы контейнера непозволительна, т.к. её последствия слишком значительны. Какие же шаги можно предпринять для улучшения изоляции? Чтобы подняться выше на уровень в лестнице изоляции, стоит также посмотреть на песочницы, в которые обёрнуто ядро ОС, т.е. виртуальные машины!
Технологии виртуализации, в которых используются hosted-гипервизоры, улучшат ситуацию, однако мы хотим ограничить поверхность атаки ещё больше. Поэтому давайте изучим устанавливаемые на железо гипервизоры и посмотрим, к чему они нас приведут.
В исследовании шведского агентства Swedish Defence Research Agency рассматривались риски виртуализации в отношении к Вооружённым силам Швеции (Swedish Armed Forces). Его заключение гласило о пользе этих технологий для вооружённых сил даже при наличии строгих требований к безопасности и рисков, которые приносит виртуализация.
В связи с этим мы можем заявить, что виртуализация применяется (в определённой степени) в оборонной промышленности, поскольку несёт допустимые риски. Поскольку агентства и предприятия в оборонной индустрии — одни из самых требовательных к ИТ-безопасности клиентов, мы можем также утверждать, что допустимый риск для них означает его допустимость и для клиентов, рассматриваемых в диссертации. И всё это — несмотря на потенциальные выходы за пределы виртуальной машины, рассмотренные выше.
Если мы решим использовать такой тип песочниц для контейнеров, необходимо учесть несколько вещей в контексте облачной (cloud-native) специфики.
Идея заключается в том, чтобы узлами Kubernetes-кластера были виртуальные машины, использующие виртуализацию на железе. Поскольку виртуальные машины будут играть роль песочниц для контейнеров, что запускаются в pod'ах, каждый узел можно рассматривать как защищённое песочницей окружение.
Важное замечание по поводу этих песочниц в контексте уже упомянутых ранее песочниц для контейнеров: такой подход позволяет помещать множество контейнеров в одну песочницу. Такая гибкость позволяет снизить накладные расходы, если сравнивать со случаем, когда у каждого контейнера своя песочница. Поскольку каждая песочница приносит свою ОС, мы хотим снизить их количество, поддерживая изоляцию.
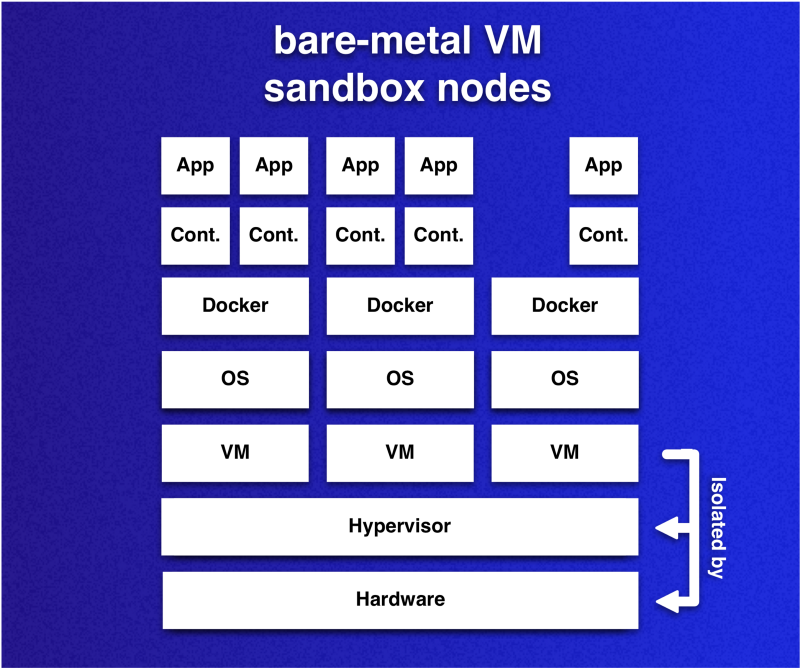
Установленные на железе виртуальные машины — узлы кластера — выступают в роли песочниц для контейнеров. Контейнеры, запущенные в разных ВМ, разграничены с допустимым уровнем риска. Однако это не относится к контейнерам, запущенным в одной ВМ.
Однако, поскольку Kubernetes способен по разным причинам изменять размещение pod'ов, что может испортить используемую идею песочниц, потребуется добавить ограничения на механизм совместного размещения pod'ов. Добиться нужного можно многими путями.
К моменту написания статьи Kubernetes (v1.13) поддерживает три основных метода контроля планирования и/или запуска pod'ов:
Какой(ие) метод(ы) использовать, зависит от приложений организации. Однако важно заметить, что методы отличаются в своей возможности отбрасывать pod'ы после того, как они вошли в стадию исполнения (execution). Сейчас на это способны только taints — через действие
В диссертации предлагается идея использовать систему классификации, показывающей, как чувствительность отражается на совместном размещении. Идея в том, чтобы использовать связь 1:1 между контейнером и pod'ом и определять совместное размещение pod'ов на основе классификации контейнеризированных приложений.
Для простоты и возможности повторного использования применяется следующая 3-ступенчатая система классификации:
Чтобы соответствовать требованиям совместного размещения для множества классифицированных приложений используются taints и tolerations, с которыми каждому узлу назначается класс, и PodAffinity для применения дополнительных ограничений для pod'ов с приложениями класса P или PG.
Этот упрощённый пример показывает, как могут использоваться taints и tolerations для реализации контроля совместного размещения:

Pod'ы 2 и 3 содержат приложения из одной частной группы, а приложение на Pod 1 — более чувствительное и требует выделенного узла.
Однако для классов P и PG потребуются дополнительные правила Affinity, которые гарантируют, что запросы на разграничение выполняются по мере роста кластера и размещённых в нём приложений. Посмотрим, как можно реализовать эти правила для разных классов:
Правила Affinity для приложений класса P требуют выделенных узлов. В этом случае pod не будет планироваться, если pod выходит без
Для приложений класса PG правила Affinity будут делать совместное размещение pod'ам, у которых задан идентификатор группы
Такой подход позволит нам с помощью системы классификации разграничивать контейнеры, опираясь на соответствующие требования контейнеризированного приложения.
Что же мы получили?
Мы рассмотрели способ реализации песочниц, основанных на гипервизоре типа 1 (т.е. запускаемых на bare metal), для создания узлов в Kubernetes-кластерах и представили систему классификации, определяющую требования к разграничению контейнеризированных приложений. Если сравнивать этот подход с другими рассмотренными решениями, он имеет преимущества в смысле обеспечения системной изоляции.
Важный вывод заключается в том, что стратегия изоляции ограничивает распространение escape-атаки на контейнер. Другими словами, сам по себе выход из контейнера не предотвращается, однако его последствия смягчаются. Очевидно, что вместе с этим приходят дополнительные сложности, которые необходимо учитывать, делая подобные сравнения.
Чтобы воспользоваться указанным методом в облачном окружении и обеспечить масштабируемость, к автоматизации будут предъявлены дополнительные требования. Например, к автоматизации создания виртуальных машин и их использования в Kubernetes-кластере. Самым же главным будет реализация и проверка повсеместного учёта классификации приложений.
Такова часть моей диссертации, посвящённая изоляции контейнеризированного приложения.
Чтобы предотвратить возможность злоумышленника, выполнившего выход из контейнера на одном узле, атаковать сервисы других узлов, необходимо рассмотреть распространяемые по сети атаки (network propagated attacks). Для учёта этих рисков в моей диссертации предлагается сегментация сети кластера и представляются облачные архитектуры, в одной из которых имеется аппаратный firewall.
Желающие могут ознакомиться с полным документом — текст диссертации в публичном доступе: «Container Orchestration in Security Demanding Environments at the Swedish Police Authority».
Читайте также в нашем блоге:
Оркестровка контейнеров и облачные (cloud-native) вычисления стали очень популярными в последние годы. Их адаптация дошла до такого уровня, что интерес к ним проявляют даже финансовые предприятия, банки, госсектор. На фоне других компаний их выделяют обширные требования в области безопасности информации и ИТ.
Один из важных аспектов — как могут использоваться контейнеры в production-окружениях и в то же время поддерживаться системное разграничение между приложениями. Поскольку такие организации используют частные облачные окружения, основанные на виртуализации поверх bare metal, потеря такой изоляции при миграции в окружение с оркестрируемыми контейнерами недопустима. С учётом этих ограничений и написана моя диссертация, а в качестве целевого клиента в ней рассматривается Полиция Швеции.
Конкретным вопросом исследования, рассматриваемого в диссертации, является:
Как в Docker и Kubernetes поддерживается разграничение приложений, если сравнить с виртуальными машинами, работающими поверх гипервизора ESXi, запущенного на bare metal?
Этот вопрос требует тщательной проработки. Чтобы начать с чего-то, посмотрим на общий знаменатель — приложения.
Веб-приложения запутаны
Уязвимости в веб-приложениях — настоящий зоопарк из векторов атак. Наиболее значимые риски которых представлены в OWASP Top 10 (2013, 2017). Подобные ресурсы способствуют обучению разработчиков в области снижения типовых рисков. Однако даже если разработчики написали безупречный код, приложение всё ещё может быть уязвимым — например, через пакетные зависимости.
David Gilbertson написал замечательную историю о том, как можно добиться инъекции кода через зловредный пакет, распространяемый, например, в рамках NPM для приложений на базе Node.js. Для обнаружения уязвимостей можно использовать сканеры зависимостей, однако они только снижают риск, но не ликвидируют его полностью.
Даже если вы создаёте приложения без сторонних зависимостей, всё ещё нереалистично будет полагать, что приложение никогда не станет уязвимым.
Из-за этих рисков мы не можем говорить, что веб-приложения безопасны.
Вместо этого стоит придерживаться стратегии «глубокой обороны» (defense in depth, DID). Взглянем же на следующий уровень: контейнеры и виртуальные машины.
Контейнеры против виртуальных машин — сказ об изоляции
Контейнер — изолированное пользовательское (user-space) окружение, которое зачастую реализуется с помощью возможностей ядра. Например, Docker для этого использует пространства имён Linux, cgroups и capabilities. В этом смысле изоляция Docker-контейнеров сильно отличается от виртуальных машин, запускаемых гипервизорами типа 1 (т.е. работающими прямо на железе; bare-metal hypervisors).
Разграничение для таких виртуальных машин может быть реализовано на настолько низком уровне, что и в реальном железе, например, через Intel VT. Docker-контейнеры, в свою очередь, для разграничения опираются на ядро Linux. Это отличие очень важно учитывать, когда речь идёт об атаках уровнем ниже (layer-below attacks).
Если злоумышленник способен исполнять код в виртуальной машине или контейнере, он потенциально может добраться до уровня ниже, выполнив атаку выхода за пределы (escape attack).
в зависимости от того, используются контейнеры или виртуальные машины на железе, разграничение реализуется на разных уровнях инфраструктуры.
Возможность таких атак была доказана для гипервизора VMware ESXi во время конкурса хакеров Pwn2Own 2017, а также GeekPwn2018. Результатом стала пара CVE (CVE-2017–4902, CVE-2018–6981), которые могут использоваться в атаках layer-below для выхода из виртуальных машин (virtual machine escape). Виртуальные машины на железных серверах не гарантируют абсолютной безопасности даже несмотря на то, что используют технологии разграничения уровня железа.
С другой стороны, если мы посмотрим на векторы атаки на стоящий на bare-metal гипервизор в сравнении с ядром Linux, очевидно, что у последнего гораздо большая поверхность атаки — из-за его [ядра Linux] размера и спектра возможностей. Большая поверхность атаки подразумевает больше векторов потенциальных атак для облачных окружений, использующих контейнерную изоляцию. Это проявляется в растущем внимании к атакам выхода из контейнера (container escape attacks), которые стали возможными благодаря эксплоитам к ядру (например, CVE-2016–5195 [т.е. Dirty COW — прим. перев.], CVE-2017–1000405).
Для повышения изоляции внутри контейнера можно использовать модули вроде SELinux или AppArmor. К сожалению, такие механизмы безопасности в ядре не предотвращают escape-атаки на само ядро. Они лишь ограничат возможные действия злоумышленника, если выход за пределы не представляется возможным. Если же мы хотим разобраться с выходами за пределы контейнера, необходим механизм изоляции вне контейнера или даже ядра. Например, песочница (sandbox)!
gVisor — песочница для исполняемой среды контейнеров, код которой был открыт Google и которая добавляет дополнительное ядро между контейнером и ядром ОС. Такой тип песочницы может улучшить ситуацию с атаками выхода за пределы контейнера, которые осуществляются на уровне ядра. Однако эксплоиты к ядру — лишь один из инструментов злоумышленника.
Чтобы увидеть, как другие атаки могут привести к схожим результатам, необходимо взглянуть на более общую картину, как используются контейнеры в эпоху cloud native.
Влияние оркестровки контейнеров на изоляцию
Чтобы управлять контейнерами, запущенными в окружениях со множеством узлов, внедряют оркестровку, лидирующую роль в которой отдают Kubernetes. Как выясняется, баги оркестратора тоже могут повлиять на изоляцию контейнеров.
Tim Allclair выступил с замечательной презентацией на KubeCon 2018, в которой отметил некоторые поверхности атаки. В своём докладе он упоминает пример (CVE-2017–1002101), как баги оркестровки могут повлиять на изоляцию — в данном случае через возможность монтирования дискового пространства, находящегося вне pod'а. Уязвимости подобного вида очень проблематичны, т.к. могут обходить песочницу, в которую обёрнут контейнер.
Внедрив Kubernetes, мы расширили поверхность атаки. К ней относятся системы, которые хостятся на master'е Kubernetes'а. Одной из них является API-сервер Kubernetes, где недавно обнаружили уязвимость, позволяющую превышать полномочия (CVE-2018–1002105). Поскольку поверхность атаки Kubernetes master'а выходит за рамки моей диссертации, эта конкретная уязвимость не берётся во внимание.
Почему escape-атаки столь важны? Контейнеры представили возможность запуска множества совместно размещённых приложений в рамках одной ОС. Так возник риск, связанный с изоляцией приложений. Если критичное для бизнеса приложение и другое уязвимое приложение работают на одном хосте, злоумышленник может через атаку уязвимого приложения получить доступ к критичному.
В зависимости от того, с какими данными работает организация, их утечка может навредить не только самой организации, но и физическим лицам, и целой стране. Как помните, речь идёт про госсектор, финансы, банки… — утечка может серьёзно повлиять на жизнь людей.
Так может ли оркестровка контейнеров вообще использоваться в подобных окружениях? Перед тем, как приниматься за дальнейшие размышления, надо провести оценку рисков.
Какой риск допустим?
Ещё до того, как вводить меры безопасности, важно подумать над тем, какую же информацию организация на самом деле пытается защитить. Решение о том, нужны ли дальнейшие шаги по предотвращению возможных escape-атак на контейнеры, зависит от данных, с которыми работает организация, и услуг, которые она оказывает.
В перспективе это означает, что для достижения возможности выхода из контейнера на корректно настроенном хосте, защищённом песочницей для контейнера, злоумышленник должен:
- исполнить код в контейнере, например, через инъекцию кода или с помощью уязвимости в коде приложения;
- воспользоваться другой уязвимостью, zero-day или для которой ещё не применили патч, чтобы выйти из контейнера даже несмотря на то, что имеется песочница.
Как можно догадаться, организация, которая не считает подобный сценарий допустимым, должна работать с данными или предлагать услуги, которые весьма требовательны к конфиденциальности, целостности и/или доступности.
Поскольку диссертация посвящена именно таким клиентам, потеря системной изоляции посредством выхода за пределы контейнера непозволительна, т.к. её последствия слишком значительны. Какие же шаги можно предпринять для улучшения изоляции? Чтобы подняться выше на уровень в лестнице изоляции, стоит также посмотреть на песочницы, в которые обёрнуто ядро ОС, т.е. виртуальные машины!
Технологии виртуализации, в которых используются hosted-гипервизоры, улучшат ситуацию, однако мы хотим ограничить поверхность атаки ещё больше. Поэтому давайте изучим устанавливаемые на железо гипервизоры и посмотрим, к чему они нас приведут.
Гипервизоры на железе
В исследовании шведского агентства Swedish Defence Research Agency рассматривались риски виртуализации в отношении к Вооружённым силам Швеции (Swedish Armed Forces). Его заключение гласило о пользе этих технологий для вооружённых сил даже при наличии строгих требований к безопасности и рисков, которые приносит виртуализация.
В связи с этим мы можем заявить, что виртуализация применяется (в определённой степени) в оборонной промышленности, поскольку несёт допустимые риски. Поскольку агентства и предприятия в оборонной индустрии — одни из самых требовательных к ИТ-безопасности клиентов, мы можем также утверждать, что допустимый риск для них означает его допустимость и для клиентов, рассматриваемых в диссертации. И всё это — несмотря на потенциальные выходы за пределы виртуальной машины, рассмотренные выше.
Если мы решим использовать такой тип песочниц для контейнеров, необходимо учесть несколько вещей в контексте облачной (cloud-native) специфики.
Узлы-песочницы для виртуальных машин
Идея заключается в том, чтобы узлами Kubernetes-кластера были виртуальные машины, использующие виртуализацию на железе. Поскольку виртуальные машины будут играть роль песочниц для контейнеров, что запускаются в pod'ах, каждый узел можно рассматривать как защищённое песочницей окружение.
Важное замечание по поводу этих песочниц в контексте уже упомянутых ранее песочниц для контейнеров: такой подход позволяет помещать множество контейнеров в одну песочницу. Такая гибкость позволяет снизить накладные расходы, если сравнивать со случаем, когда у каждого контейнера своя песочница. Поскольку каждая песочница приносит свою ОС, мы хотим снизить их количество, поддерживая изоляцию.
Установленные на железе виртуальные машины — узлы кластера — выступают в роли песочниц для контейнеров. Контейнеры, запущенные в разных ВМ, разграничены с допустимым уровнем риска. Однако это не относится к контейнерам, запущенным в одной ВМ.
Однако, поскольку Kubernetes способен по разным причинам изменять размещение pod'ов, что может испортить используемую идею песочниц, потребуется добавить ограничения на механизм совместного размещения pod'ов. Добиться нужного можно многими путями.
К моменту написания статьи Kubernetes (v1.13) поддерживает три основных метода контроля планирования и/или запуска pod'ов:
Какой(ие) метод(ы) использовать, зависит от приложений организации. Однако важно заметить, что методы отличаются в своей возможности отбрасывать pod'ы после того, как они вошли в стадию исполнения (execution). Сейчас на это способны только taints — через действие
NoExecute. Если же никак этот момент не обрабатывать и какие-то лейблы поменяются, то всё может привести к нежелательному совместному размещению.Соответствие требованиям к совместному размещению
В диссертации предлагается идея использовать систему классификации, показывающей, как чувствительность отражается на совместном размещении. Идея в том, чтобы использовать связь 1:1 между контейнером и pod'ом и определять совместное размещение pod'ов на основе классификации контейнеризированных приложений.
Для простоты и возможности повторного использования применяется следующая 3-ступенчатая система классификации:
- Класс O: приложение не является чувствительным и не имеет требований к изоляции. Его можно размещать на любых узлах, которые не принадлежат другим классам.
- Класс PG (private group): Приложение, в совокупности с набором других приложений, формирует частную группу, для которой требуется выделенный узел. Приложение может размещаться только на узлах класса PG, имеющих соответствующий идентификатор частной группы.
- Класс P (private): Приложение требует частного и отдельного узла и может размещаться только на пустых узлах своего класса (P).
Чтобы соответствовать требованиям совместного размещения для множества классифицированных приложений используются taints и tolerations, с которыми каждому узлу назначается класс, и PodAffinity для применения дополнительных ограничений для pod'ов с приложениями класса P или PG.
Этот упрощённый пример показывает, как могут использоваться taints и tolerations для реализации контроля совместного размещения:
Pod'ы 2 и 3 содержат приложения из одной частной группы, а приложение на Pod 1 — более чувствительное и требует выделенного узла.
Однако для классов P и PG потребуются дополнительные правила Affinity, которые гарантируют, что запросы на разграничение выполняются по мере роста кластера и размещённых в нём приложений. Посмотрим, как можно реализовать эти правила для разных классов:
# Class P
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
namespaces: ["default"]
labelSelector:
matchExpressions:
- key: non-existing-key
operator: DoesNotExistПравила Affinity для приложений класса P требуют выделенных узлов. В этом случае pod не будет планироваться, если pod выходит без
non-existing-key. Всё будет работать, пока ни у одного pod'а не появится этот ключ.# Class PG
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
labelSelector:
matchLabels:
class-pg-group-1: foobar
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
labelSelector:
matchExpressions:
- key: class-pg-group-1
operator: DoesNotExistДля приложений класса PG правила Affinity будут делать совместное размещение pod'ам, у которых задан идентификатор группы
class-pg-group-1, и на узлах, имеющих pod'ы без идентификатора.Такой подход позволит нам с помощью системы классификации разграничивать контейнеры, опираясь на соответствующие требования контейнеризированного приложения.
Что же мы получили?
Заключение
Мы рассмотрели способ реализации песочниц, основанных на гипервизоре типа 1 (т.е. запускаемых на bare metal), для создания узлов в Kubernetes-кластерах и представили систему классификации, определяющую требования к разграничению контейнеризированных приложений. Если сравнивать этот подход с другими рассмотренными решениями, он имеет преимущества в смысле обеспечения системной изоляции.
Важный вывод заключается в том, что стратегия изоляции ограничивает распространение escape-атаки на контейнер. Другими словами, сам по себе выход из контейнера не предотвращается, однако его последствия смягчаются. Очевидно, что вместе с этим приходят дополнительные сложности, которые необходимо учитывать, делая подобные сравнения.
Чтобы воспользоваться указанным методом в облачном окружении и обеспечить масштабируемость, к автоматизации будут предъявлены дополнительные требования. Например, к автоматизации создания виртуальных машин и их использования в Kubernetes-кластере. Самым же главным будет реализация и проверка повсеместного учёта классификации приложений.
Такова часть моей диссертации, посвящённая изоляции контейнеризированного приложения.
Чтобы предотвратить возможность злоумышленника, выполнившего выход из контейнера на одном узле, атаковать сервисы других узлов, необходимо рассмотреть распространяемые по сети атаки (network propagated attacks). Для учёта этих рисков в моей диссертации предлагается сегментация сети кластера и представляются облачные архитектуры, в одной из которых имеется аппаратный firewall.
Желающие могут ознакомиться с полным документом — текст диссертации в публичном доступе: «Container Orchestration in Security Demanding Environments at the Swedish Police Authority».
P.S. от переводчика
Читайте также в нашем блоге:
- «Уязвимость CVE-2019-5736 в runc, позволяющая получить права root на хосте»;
- «9 лучших практик по обеспечению безопасности в Kubernetes»;
- «11 способов (не) стать жертвой взлома в Kubernetes»;
- «Понимаем RBAC в Kubernetes»;
- «OPA и SPIFFE — два новых проекта в CNCF для безопасности облачных приложений»;
- «Vulnerable Docker VM — виртуалка-головоломка по Docker и pentesting».
Комментарии (9)

wtfman
18.02.2019 15:27Спасибо за статью! Возник вопрос про использованию контейнеров в информационных системах, которые должны быть аттестованы для обработки информации, которая относится к классу информации ограниченного доступа. Есть ли у вас такой опыт? какие средства защиты вы рекомендуете к использованию?

gecube
18.02.2019 21:28Вы хотите за техническую часть поговорить или за документальную (сертификаты, справки, ФСБ и ФСТЭК)?
wtfman
19.02.2019 13:10Хотел бы обсудить техническую часть, которая может лечь в основу защищенной системы. При аттестации которой не возникнет проблем :)
VolCh
Интересно, имеет ли смысл делать кластер из виртуалок, на каждой ноде которого можно запустить только один под/контейнер. Чтобы использовать инфраструктуру k8s/docker, но иметь изоляцию уровня виртуалки даже между инстансами одного сервиса.
CrzyDocTI
так работает Swarm
VolCh
Swarm в этом плане работает так же как k8s.
n1nj4p0w3r
имеет смысл запускать контейнеры как легковесные виртуалки: kata containers, firecracker, VMware vic
gecube
Я думаю, что нам не хватает "контроллера"-прослойки, который позволит заменить docker в виде движка контейнеров на "легковесные", но полноценные ВМ. Т.е. использовать базу кубернетеса,, но шедюлить ВМки. Насколько я помню, определенные наработки в эту сторону идут
n1nj4p0w3r
Ну так kata containers это и есть замена движка докера на kvm используя crio