

Маркеры — дело полезное. Полезное в разумных количествах. Когда их становится слишком много, польза улетучивается. Как поступить, если требуется отметить на карте поисковую выдачу, в которой десятки тысяч объектов? В статье я расскажу, как мы решаем эту задачу на WebGL-карте без ущерба для её внешнего вида и производительности.
Предыстория
В 2016 году 2ГИС выпустил в бой свой первый проект на WebGL — Этажи: трёхмерные поэтажные планы зданий.
Этажи новосибирского ТЦ Аура
Сразу после релиза Этажей наша команда начала разработку полноценного трёхмерного картографического движка на WebGL. Движок разрабатывался совместно с новой версией 2gis.ru и сейчас находится в статусе публичной беты.
Красная площадь, отрисованная на WebGL. Планы зданий теперь встроены прямо в карту
Задача генерализации подписей
Любой, кто захочет написать собственный картографический движок, рано или поздно столкнётся с проблемой размещения подписей на карте. Объектов на карте много, и невозможно подписать каждый так, чтобы подписи не пересекались между собой.
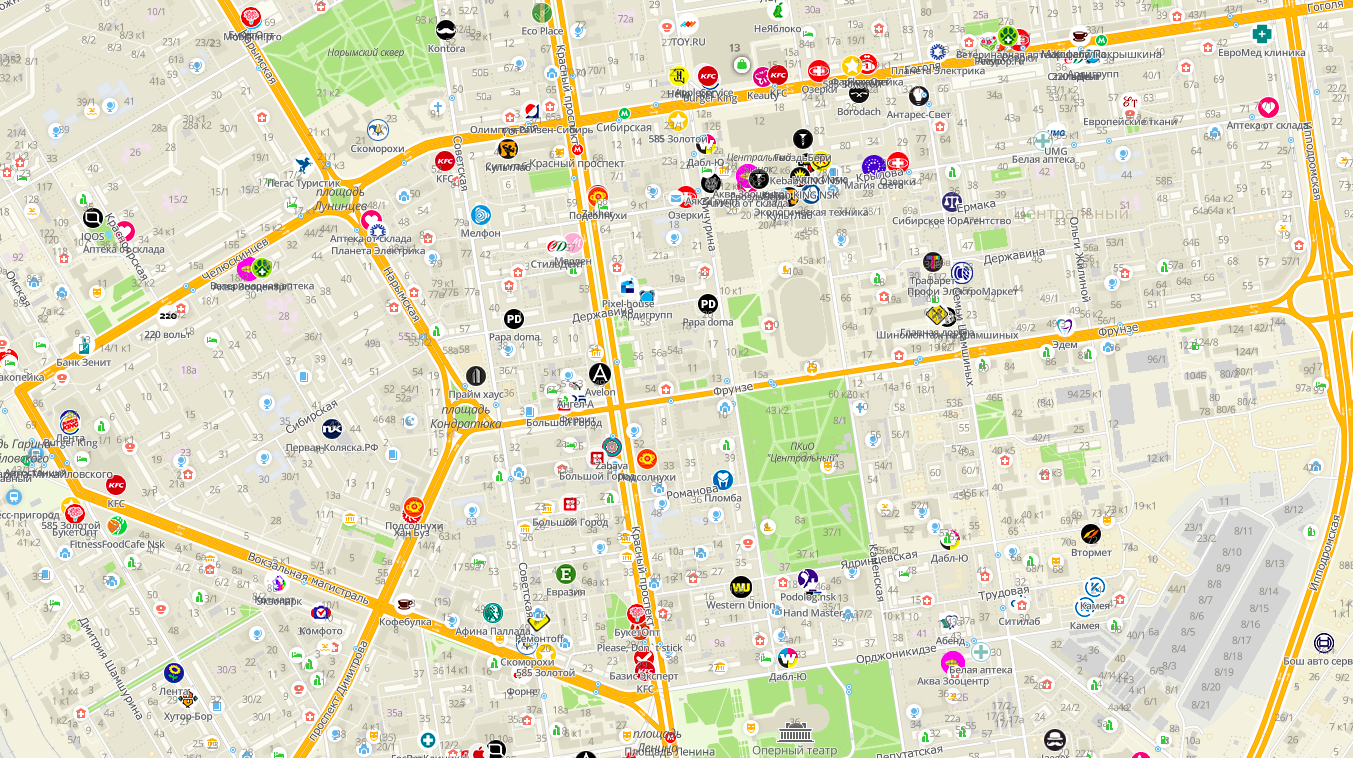
Что будет, если в Новосибирске подписать все объекты сразу
Для решения этой проблемы необходима генерализация подписей. Генерализация в общем смысле — преобразование картографических данных таким образом, чтобы они были пригодны для отображения на мелких масштабах. Её можно делать разными методами. Для подписей обычно применяется метод отбора: из общего числа выбирается некоторое подмножество наиболее приоритетных подписей, не пересекающихся друг с другом.
Приоритет подписи определяется её типом, а также текущим масштабом карты. Например, при мелком масштабе нужны подписи городов и стран, а при крупном масштабе гораздо важнее становятся подписи дорог и номера домов. Часто приоритет названия населённого пункта определяется размером его населения. Чем оно больше, тем важнее подпись.
Генерализация требуется не только для подписей, но и для маркеров, которыми на карте отмечаются результаты поиска. Например, при поиске по запросу «магазин» в Москве найдётся более 15000 результатов. Отмечать их на карте все сразу, — очевидно, плохая идея.
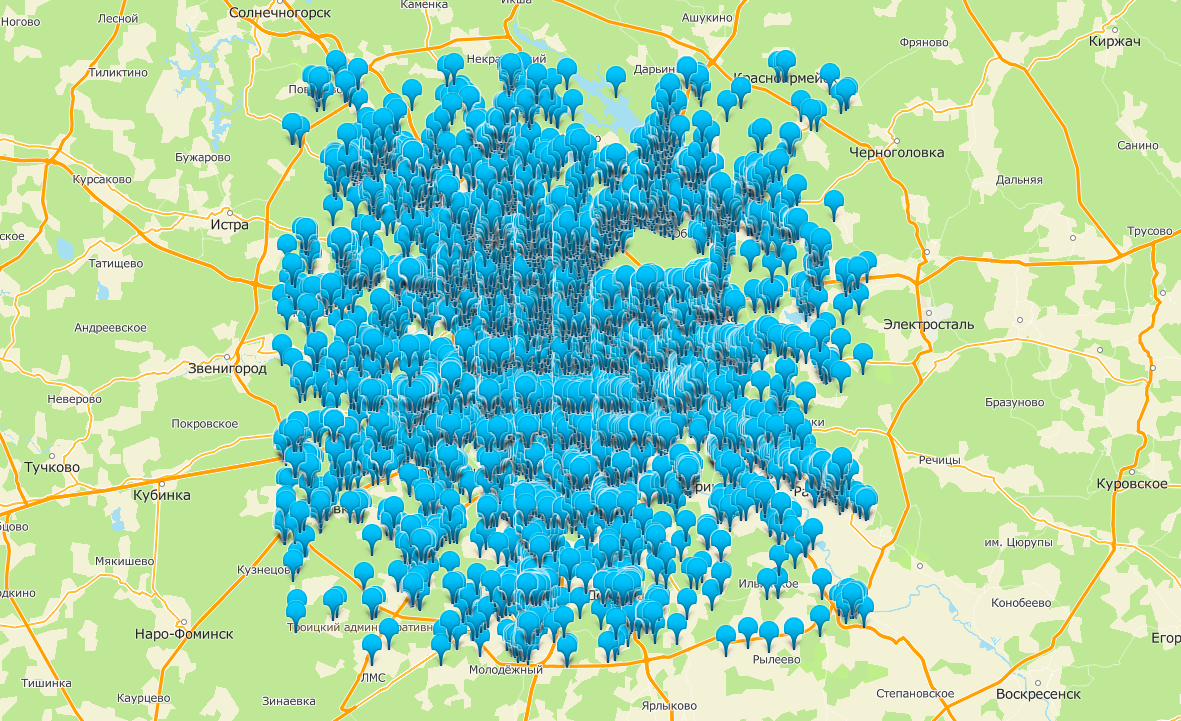
Все магазины Москвы на карте. Без генерализации тут не обойтись
Любое взаимодействие пользователя с картой (перемещение, изменение масштаба, поворот и наклон) приводит к изменению положения маркеров на экране, поэтому генерализацию нужно уметь перерассчитывать на лету. Следовательно, она должна быть быстрой.
В этой статье на примере генерализации маркеров я покажу разные способы решения этой задачи, которые в разное время применялись в наших проектах.
Общий подход к генерализации
- Спроецировать каждый маркер в плоскость экрана и рассчитать для него баунд — прямоугольную область, которую он занимает на экране.
- Упорядочить маркеры по приоритету.
- Последовательно рассматривать каждый маркер и размещать его на экране, если он не пересекается с другими маркерами, размещёнными перед ним.
С пунктом 1 всё ясно — это просто вычисления. С пунктом 2 нам тоже повезло: список маркеров, который приходит нам с бекенда, уже упорядочен по приоритету алгоритмами поиска. В верх выдачи попадают наиболее релевантные результаты, которые с наибольшей вероятностью будут интересны пользователю.
Главная проблема — в пункте 3: от того, как он реализован, может сильно зависеть время расчёта генерализации.
Для поиска пересечений между маркерами нам необходима некоторая структура данных, которая:
- Хранит баунды добавленных на экран маркеров.
- Имеет метод
insert(marker), чтобы добавить маркер на экран. - Имеет метод
collides(marker), чтобы проверить маркер на пересечение с уже добавленными на экран.
Рассмотрим несколько реализаций этой структуры. Все дальнейшие примеры будут написаны на языке TypeScript, который мы используем в большинстве наших проектов. Во всех примерах маркеры будут представляться объектами следующего вида:
interface Marker {
minX: number;
maxX: number;
minY: number;
maxY: number;
}Все рассмотренные подходы будут реализациями следующего интерфейса:
interface CollisionDetector {
insert(item: Marker): void;
collides(item: Marker): boolean;
}Для сравнения производительности будет замеряться время исполнения следующего кода:
for (const marker of markers) {
if (!impl.collides(marker)) {
impl.insert(marker);
}
}Массив markers будет содержать 100 000 элементов размера 30x50, случайно размещённых на плоскости размера 1920x1080.
Производительность будем замерять на Macbook Air 2012 года.
Тесты и примеры кода, приведённые в статье, также выложены на GitHub.
Наивная реализация
Для начала рассмотрим самый простой вариант, когда маркер проверяется на пересечение с остальными в простом цикле.
class NaiveImpl implements CollisionDetector {
private markers: Marker[];
constructor() {
this.markers = [];
}
insert(marker: Marker): void {
this.markers.push(marker);
}
collides(candidate: Marker): boolean {
for (marker of this.markers) {
if (
candidate.minX <= marker.maxX &&
candidate.minY <= marker.maxY &&
candidate.maxX >= marker.minX &&
candidate.maxY >= marker.minY
) {
return true;
}
}
return false;
}
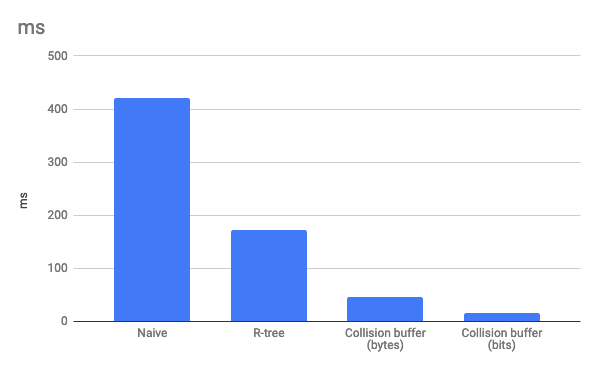
}Время расчёта генерализации для 100 000 маркеров: 420 мс. Многовато. Даже если расчёт генерализации идёт в веб-воркере и не блокирует главный тред, такая задержка будет заметна на глаз, особенно с учётом того, что эту операцию необходимо производить после каждого движения карты. Более того, на мобильных устройствах со слабым процессором задержка может быть ещё больше.
Реализация с применением R-дерева
Так как в наивной реализации каждый маркер проверяется на пересечение со всеми предыдущими, в худшем случае трудоёмкость этого алгоритма — квадратичная. Можно улучшить её, применив структуру данных R-дерево. В качестве реализации R-дерева возьмём библиотеку RBush:
import * as rbush from 'rbush';
export class RTreeImpl implements CollisionDetector {
private tree: rbush.RBush<Marker>;
constructor() {
this.tree = rbush();
}
insert(marker: Marker): void {
this.tree.insert(marker);
}
collides(candidate: Marker): boolean {
return this.tree.collides(candidate);
}
}Время расчёта генерализации для 100 000 маркеров: 173 мс. Значительно лучше. Такой подход мы применили в Этажах (об этом упоминалось в моей предыдущей статье).
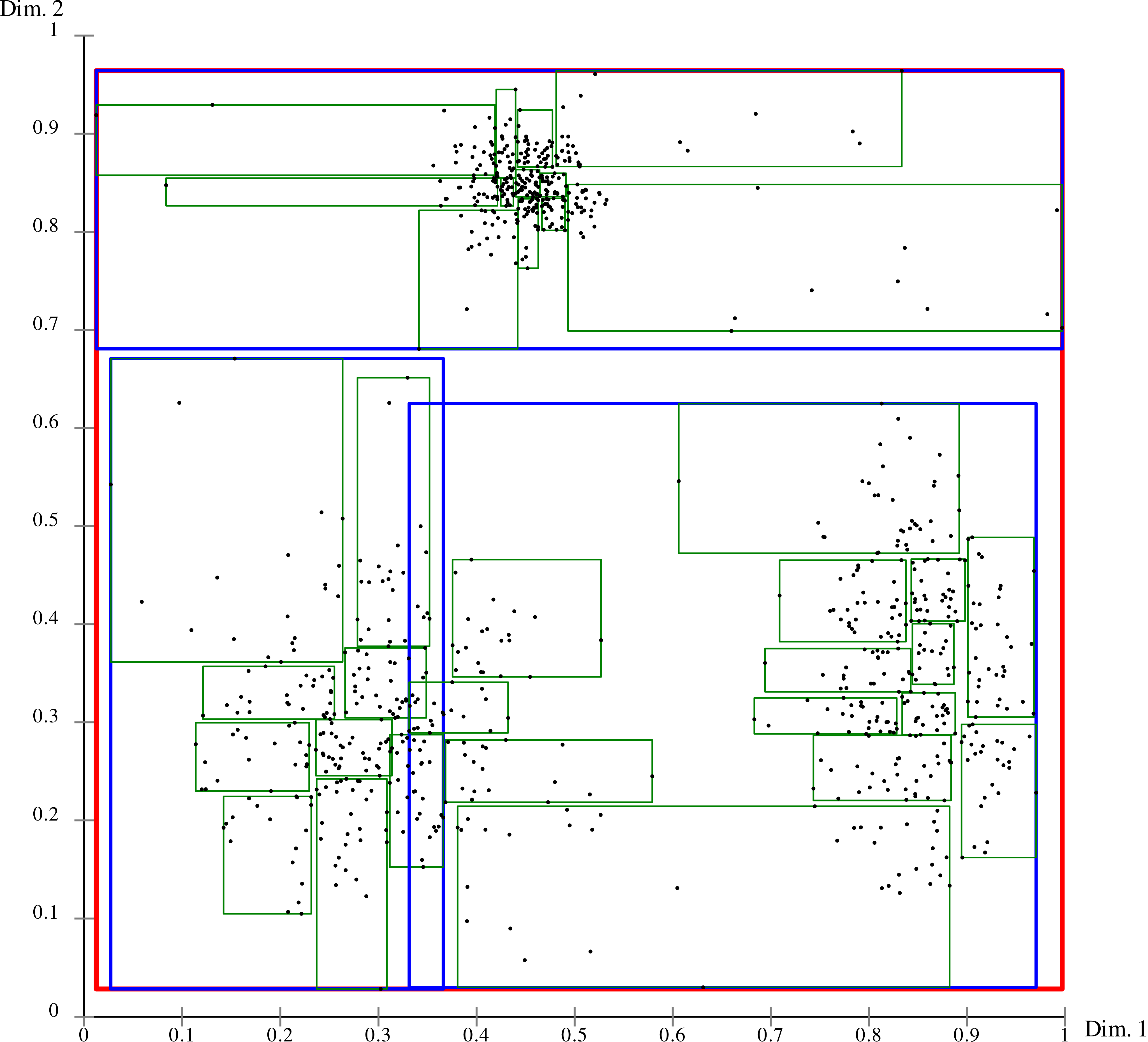
Визуализация хранения точек в R-дереве. Иерархическое деление плоскости на прямоугольники позволяет быстро сужать область поиска и не перебирать все объекты
Реализация с применением буфера коллизий
Отрисовка карты — гораздо более сложная задача, чем отрисовка плана одного здания. Это проявляется и в генерализации. Даже в крупнейших ТЦ мира на одном этаже редко бывает 1 000 организаций. При этом, простой поисковый запрос в крупном городе может вернуть десятки тысяч результатов.
Когда мы начали разработку WebGL-карты, стали думать: можно ли ещё ускорить генерализацию. Интересную идею предложил нам тогда работавший у нас stellarator: вместо R-дерева использовать буфер, в котором хранить состояние каждого пикселя экрана (занят или не занят). При вставке маркера на экран «закрашивать» соответствующее место в буфере, а при проверке возможности вставки — проверять значения пикселей в требуемой области.
class CollisionBufferByteImpl implements CollisionDetector {
private buffer: Uint8Array;
private height: number;
constructor(width: number, height: number) {
this.buffer = new Uint8Array(width * height);
this.height = height;
}
insert(marker: Marker): void {
const { minX, minY, maxX, maxY } = marker;
for (let i = minX; i < maxX; i++) {
for (let j = minY; j < maxY; j++) {
buffer[i * this.height + j] = 1;
}
}
}
collides(candidate: Marker): boolean {
const { minX, minY, maxX, maxY } = candidate;
for (let i = minX; i < maxX; i++) {
for (let j = minY; j < maxY; j++) {
if (buffer[i * this.height + j]) {
return true;
}
}
}
return false;
}
}Время расчёта генерализации для 100 000 маркеров: 46 мс.
Почему так быстро? Подход этот на первый взгляд кажется наивным, а вложенные циклы в обоих методах не похожи на быстрый код. Однако, если приглядеться к коду повнимательнее, можно заметить, что время исполнения обоих методов не зависит от общего количества маркеров. Таким образом, при фиксированном размере маркеров WxH получим трудоёмкость O(W * H * n), то есть линейную!
Оптимизация подхода с буфером коллизий
Можно улучшить предыдущий подход как по скорости, так и по занимаемой памяти, если сделать так, чтобы один пиксель представлялся в памяти не одним байтом, а одним битом. Код после этой оптимизации, правда, заметно усложняется и обрастает некоторым количеством побитовой магии:
export class CollisionBufferBitImpl implements CollisionDetector {
private width: number;
private height: number;
private buffer: Uint8Array;
constructor(width: number, height: number) {
this.width = Math.ceil(width / 8) * 8;
this.height = height;
this.buffer = new Uint8Array(this.width * this.height / 8);
}
insert(marker: Marker): void {
const { minX, minY, maxX, maxY } = marker;
const { width, buffer } = this;
for (let j = minY; j < maxY; j++) {
const start = j * width + minX >> 3;
const end = j * width + maxX >> 3;
if (start === end) {
buffer[start] = buffer[start] | (255 >> (minX & 7) & 255 << (8 - (maxX & 7)));
} else {
buffer[start] = buffer[start] | (255 >> (minX & 7));
for (let i = start + 1; i < end; i++) {
buffer[i] = 255;
}
buffer[end] = buffer[end] | (255 << (8 - (maxX & 7)));
}
}
}
collides(marker: Marker): boolean {
const { minX, minY, maxX, maxY } = marker;
const { width, buffer } = this;
for (let j = minY; j < maxY; j++) {
const start = j * width + minX >> 3;
const end = j * width + maxX >> 3;
let sum = 0;
if (start === end) {
sum = buffer[start] & (255 >> (minX & 7) & 255 << (8 - (maxX & 7)));
} else {
sum = buffer[start] & (255 >> (minX & 7));
for (let i = start + 1; i < end; i++) {
sum = buffer[i] | sum;
}
sum = buffer[end] & (255 << (8 - (maxX & 7))) | sum;
}
if (sum !== 0) {
return true;
}
}
return false;
}
}Время расчёта генерализации для 100 000 маркеров: 16 мс. Как видим, усложнение логики оправдывает себя и позволяет ускорить расчёт генерализации ещё почти в три раза.
Ограничения буфера коллизий
Важно понимать, что буфер коллизий не является полноценной заменой R-дереву. У него гораздо меньше возможностей и больше ограничений:
- Нельзя понять, с чем именно пересекается маркер. Буфер только хранит данные о том, какие пиксели заняты, а какие нет. Следовательно, невозможно реализовать операцию, которая вернёт список маркеров, пересекающихся с данным.
- Нельзя удалить ранее добавленный маркер. Буфер не хранит данные о том, сколько маркеров находятся в данном пикселе. Следовательно, невозможно корректно реализовать операцию удаления маркера из буфера.
- Высокая чувствительность к размеру элементов. Если попытаться добавить в буфер коллизий маркеры, занимающие весь экран, производительность резко упадёт.
- Работает в ограниченной площади. Размер буфера задаётся при его создании, и невозможно поместить в него маркер, выходящий за пределы этого размера. Поэтому при использовании этого подхода необходимо вручную отфильтровывать маркеры, не попадающие на экран.
Все эти ограничения решению задачи генерализации маркеров не помешали. Сейчас этот метод успешно применяется для маркеров в бета-версии 2gis.ru.
Однако, для генерализации основных подписей на карте требования более сложные. Например, для них нужно делать так, чтобы иконка POI не могла «убить» собственную подпись. Так как буфер коллизий не различает, с чем именно произошло пересечение, такую логику он реализовать не позволяет. Поэтому для них пришлось оставить решение с RBush.
Вывод
В статье показан путь, который мы прошли от самого простого решения до используемого сейчас.
Применение R-дерева было первым важным шагом, позволившим многократно ускорить наивную реализацию. Оно отлично работает в Этажах, однако по факту мы используем только малую часть возможностей этой структуры данных.
Отказавшись от R-дерева и заменив его простым двумерным массивом, который делает ровно то, что нам нужно, и ничего кроме этого, мы получили ещё больший рост производительности.
Этот пример показал нам, как важно, выбирая решение для задачи из нескольких вариантов, понимать и осознавать ограничения каждого из них. Ограничения важны и полезны, и не стоит их бояться: умело ограничив себя в чём-то несущественном, можно получить взамен огромную пользу там, где она действительно нужна. Например, упростить решение какой-либо задачи, или оградить себя от целого класса проблем, или, как в нашем случае, в разы улучшить производительность.
Комментарии (17)

bopoh13
06.03.2019 10:50Бета выводит сообщение
Только для больших, но в браузере DuckDuckGo и FireFox Focus отображается нормально. Тормозит меньше, чем текущая карта (кликать только нельзя). Тело BQ x32. Обратите внимание, что расположение окна в подвале не учитывает, что адресная строка браузеров сворачивается, когда листаю карту вниз.
Sanch_ru
06.03.2019 11:09Спасибо за обратную связь – beta.2gis.ru с новой WebLG картой это продукт для десктоп компьютеров, а для телефонов у нас есть отдельная веб-версия m.2gis.ru, но WebGL карта туда пока не внедрена

Zibx
06.03.2019 10:50Почему не QuadTree использовался? Есть его волшебная модификация Loose QuadTree. Вот ссылка на чудесное описание — долистайте до заголовка «4. Loose Quadtree».
В вашем случае можно было обойтись и обычным с модифицированной логикой вставки элемента: Если размер области ноды равны ширине двух маркеров и нода собралась делиться, то забить. И там же проверять — если элемент накладывается на соседний, то прервать процесс добавления. Оптимально должно получиться на двух и четырёх элементах до переполнения.RLRR Автор
06.03.2019 12:18+1Спасибо за классную ссылку!
Дерево квадрантов одно время мы использовали; конкретную реализацию не вспомню (что-то с npm), но это был обычный (не loose) вариант без каких-либо модификаций. RBush в сравнении с ним показал намного лучшую производительность, поэтому решили перейти на него.
Odrin
06.03.2019 11:17Нельзя понять, с чем именно пересекается маркер. Буфер только хранит данные о том, какие пиксели заняты, а какие нет. Следовательно, невозможно реализовать операцию, которая вернёт список маркеров, пересекающихся с данным.
Что если отказаться от оптимизации подхода с буфером и в буфере хранить не 0/1, а индекс элемента в массиве? Соответственно при добавлении нового маркера на карту класть его в массив, а элементы буфера заполнять значением индекса. Если использовать Uint16Array вместо Uint8Array то на карту уместится до 65535 маркеров (хотя при размере маркера 30x50 даже 255 элементов должно всегда хватать).RLRR Автор
06.03.2019 12:31+1Да, так можно сделать! Помимо количества маркеров, ещё одно важное ограничение такого подхода в том, что не получится хранить пересекающиеся баунды, так как каждый пиксель может хранить только один индекс.
К сожалению, для наших требований к генерализации подписей это критично: у нас есть подписи разных типов, и некоторым типам нужно разрешать пересекаться с другими. Из-за этого при проверке возможности вставки нужно знать полный список пересечений.
Inobelar
06.03.2019 22:54Подскажите, не даст ли больший выиграш переход на WASM, вместо таких оптимизаций?
RLRR Автор
07.03.2019 08:47Современные браузеры оптимизируют исполнение JS так хорошо, что переход на WASM, как правило, не даёт значительного роста производительности. Выигрыш от правильного выбора алгоритма и структуры данных для решения задачи всегда будет выше.
Мы экспериментировали с asm.js и даже реализовывали на нём генерализацию (писали asm.js-код вручную). Впоследствии отказались от этой технологии ради читаемости кода и переписали всё на обычный JavaScript. Точных чисел не вспомню, но ухудшение производительности было некритичным.

kashey
06.03.2019 11:50Как я почти решил эту проблему (не было задачи наклонять)
1. Берем github.com/mourner/flatbush
2. Начинаем добавлять точки, только маленького размера
3. Постепенно увеличиваем размер (по сути k-nearest neightbours) — очень важно понять в каком порядке точки друг на друга накладываются, сохраняем указатель на тот маркер, который «самый главный»
4.…
5. делаем выборку по bounding box маркера, прося только один результат (такого метода в flatbush нет), получаем leaderMarkerId, и таким образом формируем список маркеров который надо показать.
Это работает за O(nlogn), где «logn», ака «глубина дерева» обычно не более 10. Самое главное — данные добавляются в RTree только один раз, далее идут чтения.RLRR Автор
07.03.2019 11:27Самое главное — данные добавляются в RTree только один раз, далее идут чтения.
Вставлять в R-дерево пачку элементов разом действительно выгоднее, чем по одному (в библиотеке RBush даже сделан специальный метод для этого).
У нас, правда, на экране обычно отображается очень малая часть от общего числа маркеров: всего их могут быть десятки тысяч, а на экране редко умещается больше пары сотен. Поэтому мы добавляем в дерево только те элементы, которые будут отображены (делая проверку перед каждой вставкой). Несмотря на то, что элементы таким образом приходится добавлять по одному, получается намного быстрее.kashey
07.03.2019 11:41> Вставлять в R-дерево пачку элементов разом действительно выгоднее, чем по одному (в библиотеке RBush даже сделан специальный метод для этого).
А в flatbush другого метода так вообще нет. Но, прочитай алгоритм еще раз,- вставка данных производится __вообще__ один раз.
Далее как не мотай или зум меняй — только чтения.
Плюс можно использовать еще одну библиотеку, опять же от mourner — supercluster , которая сделает что-то типа иерхического z-index, отдаленно напоминащее ваше решение.
Кстати да — если вам добавить «early-z» — будет вообще летать.
Tachyon
07.03.2019 07:19Извините за офтоп, но то здание что изображено на КДПВ- бредни дизайнера, или реально существующий объект?
InnaSavchkova
07.03.2019 07:49Дмитрий, это технопарк новосибирского Академгородка.
Вот пруф на карте.

Un1oR
А для чего вам генерализация именно в плоскости экрана? Почему нельзя генерализовать все маркера один раз в плоскости карты и больше не трогать. Кажется, изменения перспективы не должны драматически портить визуал.
Ну и второй связанный вопрос, если вы постоянно пересчитываете генерализацию, то как решаете и решаете ли проблему её стабильности и отсутствия мерцаний маркеров в окрестностях конфликтующих позиций?
RLRR Автор
В 2D-карте мы так и делали (вычисляли генерализацию один раз для каждого целочисленного зума), но в 3D, если сильно наклонить карту, маркеры будут всё же сильно наезжать друг на друга — выглядит это не очень.
С нестабильностью боремся несколькими способами:
1. Маркерам, которые в данный момент видны на экране, поднимаем в генерализации приоритет.
2. Маркерам, которые в данный момент не видны на экране, при проверке пересечения расширяем баунд на несколько пикселей.
Эти подходы значительно снижают мерцание и позволяют добиться приемлемой (хоть и неидеальной) стабильности.