
Мы в компании всегда стремимся повысить сопровождаемость нашего кода, используя общепринятые практики, в том числе в вопросах многопоточности. Это не решает всех сложностей, которые приносит за собой постоянно растущая нагрузка, но упрощает поддержку — выигрывает и читаемость кода, и скорость разработки новых фич.
Сейчас у нас 47 000 пользователей ежедневно, около 30 серверов в production, 2 000 API запросов в секунду и ежедневные релизы. Сервис Miro развивается с 2011 года, и в текущей реализации пользовательские запросы обрабатываются параллельно кластером разнородных серверов.

Главная ценность нашего продукта — коллаборативные пользовательские доски, поэтому основная нагрузка приходится на них. Основной подсистемой, управляющей большей частью конкурентного доступа, является stateful система пользовательских сессий на доске.
Для каждой открываемой доски на одном из серверов поднимается состояние. В нём хранятся как прикладные runtime данные, необходимые для обеспечения коллаборации и отображения содержимого, так и системные, такие как привязка к обрабатывающим потокам. Информация о том, на каком сервере хранится состояние, записывается в распределённую структуру и доступна кластеру до тех пор, пока сервер работает, и на доске находится хотя бы один пользователь. Мы используем Hazelcast для обеспечения работы этой части подсистемы. Все новые подключения к доске направляются на сервер с этим состоянием.
При подключении к серверу пользователь попадает в принимающий поток, единственная задача которого — привязать соединение к состоянию соответствующей доски, в потоках которого будет происходить вся дальнейшая работа.
С доской ассоциированы два потока: сетевой, обрабатывающий соединения, и “бизнесовый”, отвечающий за бизнес-логику. Это позволяет превратить выполнение разнородных задач обработки сетевых пакетов и исполнения бизнес-команд из последовательного в параллельное. Обработанные сетевые команды от пользователей формируют прикладные бизнес-задания и направляют их в бизнес-поток, где те обрабатываются последовательно. Это позволяет избегать лишней синхронизации при разработке прикладного кода.
Деление кода на бизнес/прикладной и системный — наша внутренняя условность. Она позволяет разграничить код, ответственный за фичи и возможности для пользователей, от низкоуровневых деталей коммуникации, шедулинга и хранения, являющихся обслуживающим инструментом.
Если принимающий поток обнаруживает, что для доски состояние отсутствует, ставится соответствующая задача инициализации. Инициализацией состояния занимается отдельный тип потока.
Типы задач и их направление можно изобразить следующим образом:
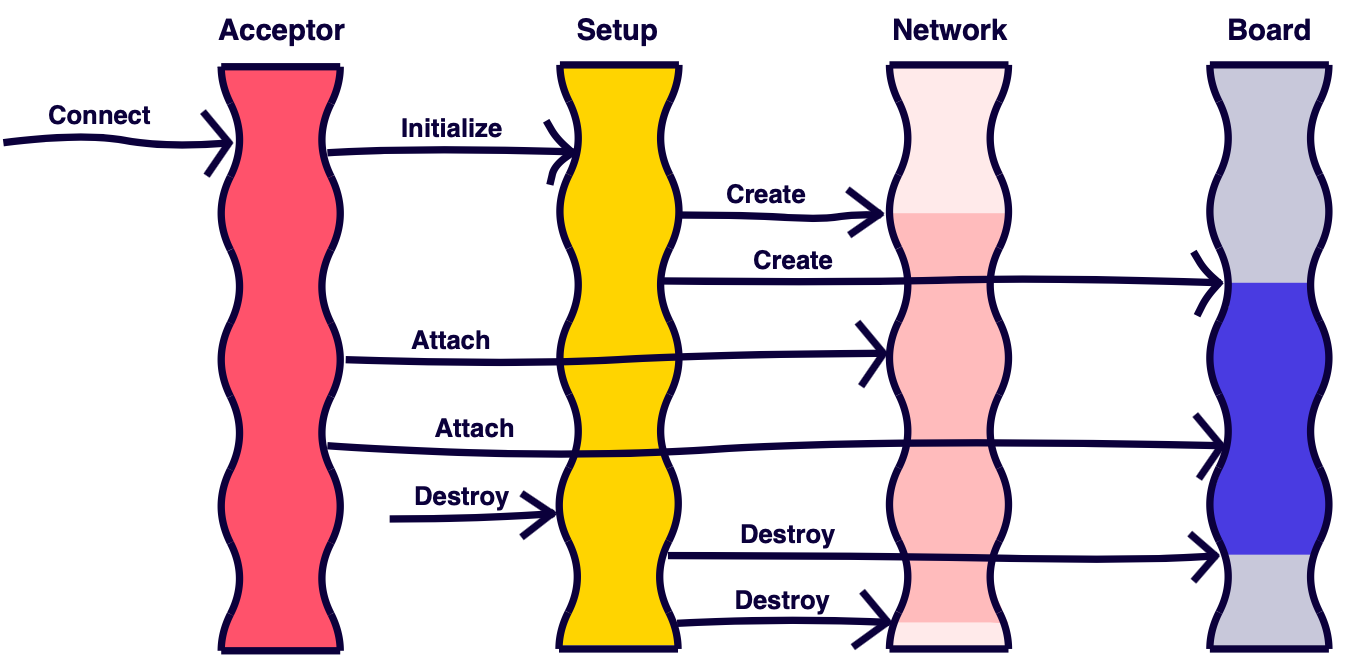
Такая реализация позволяет нам решать следующие проблемы:
Описанная выше подсистема в реализации получается довольно нетривиальной. Разработчику приходится держать в голове схему работы системы и учитывать обратный процесс закрытия досок. При закрытии необходимо убрать все подписки, удалить записи из реестров и сделать это в тех же потоках, в которых они были инициализированы.
Мы заметили, что баги и сложности модификации кода, которые возникали в этой подсистеме, часто были связаны с непониманием контекста выполнения. Жонглирование потоками и задачами затрудняло ответ на вопрос, в каком именно потоке выполняется отдельно взятый участок кода.
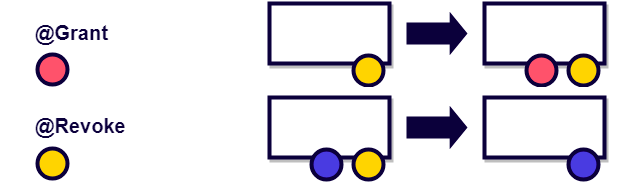
Для решения этой проблемы мы воспользовались методом раскраски потоков — это политика, направленная на регулирование использования потоков в системе. Потокам назначаются цвета, а методы определяют рамки допустимости выполнения внутри потоков. Цвет здесь — это абстракция, им может быть любая сущность, например, перечисление. В Java языком цветовой разметки могут служить аннотации:
Аннотации добавляются к методу, с помощью них можно задавать допустимость выполнения метода. Например, если аннотация у метода допускает жёлтый и красный цвет, то первый поток сможет вызвать метод, а для второго такой вызов будет ошибочным.

Можно задавать недопустимые цвета:

Можно в динамике добавлять и удалять привилегии потоков:
Отсутствие аннотации или аннотация как в примере ниже говорит, что метод может выполняться в любом потоке:

Android-разработчикам может быть знаком такой подход по аннотациям MainThread, UiThread, WorkerThread и т.п.
В раскраске потоков используется принцип самодокументирования кода, а сам метод хорошо поддаётся статическому анализу. Используя статический анализ, можно до выполнения кода сказать, правильно он написан или нет. Если исключить аннотации Grant и Revoke и считать, что поток при инициализации уже имеет неизменяемый набор привилегий, то это будет flow-insensitive анализ — простая версия статического анализа, которая не учитывает порядок вызовов.
В момент внедрения метода раскраски потоков в нашей devops-инфраструктуре не было готовых решений для статического анализа, поэтому мы пошли более простым и дешёвым путём — ввели свои аннотации, которые однозначно ассоциируются с каждым типом потоков. Проверять их корректность мы стали с помощью аспектов в runtime.
Для аспектов мы используем библиотеку aspectj и maven плагин, осуществляющий weaving при компиляции проекта. Первоначально weaving был настроен на load-time при загрузке классов ClassLoader’ом. Однако мы столкнулись с тем, что weaver иногда некорректно вёл себя при конкурентной загрузке одного и того же класса, в результате чего исходный байт код класса оставался без изменений. В итоге это выливалось в весьма непредсказуемое и трудно воспроизводимое поведение на production. Возможно, в текущих версиях библиотеки такой проблемы нет.
Решение на аспектах позволило быстро найти большинство проблем в коде.
Важно не забывать всегда держать аннотации в актуальном состоянии: их можно удалить, полениться добавить, weaving аспектов вообще может быть отключён, — в этом случае раскраска быстро потеряет свою актуальность и ценность.
К одной из разновидностей раскрашивания относится аннотация GuardedBy из java.util.concurrent. Она разграничивает доступ к полям и методам, указывая какие блокировки необходимы для корректного доступа.
Современные IDE даже поддерживают анализ этой аннотации. Например, IDEA выдаёт такое сообщение, если в коде что-то не так:

Сам метод раскраски потоков не новый, но, кажется, что в таких языках как Java, где часто многопоточный доступ идёт к mutable объектам, его использование не только в рамках документирования, но и на этапе компиляции, сборки могло бы значительно упростить разработку многопоточного кода.
Мы до сих пор используем реализацию на аспектах. Если вы знакомы с более элегантным решением или средством анализа, позволяющим повысить устойчивость этого подхода к изменения системы, пожалуйста, поделитесь им в комментариях.
Сейчас у нас 47 000 пользователей ежедневно, около 30 серверов в production, 2 000 API запросов в секунду и ежедневные релизы. Сервис Miro развивается с 2011 года, и в текущей реализации пользовательские запросы обрабатываются параллельно кластером разнородных серверов.
Подсистема управления конкурентным доступом
Главная ценность нашего продукта — коллаборативные пользовательские доски, поэтому основная нагрузка приходится на них. Основной подсистемой, управляющей большей частью конкурентного доступа, является stateful система пользовательских сессий на доске.
Для каждой открываемой доски на одном из серверов поднимается состояние. В нём хранятся как прикладные runtime данные, необходимые для обеспечения коллаборации и отображения содержимого, так и системные, такие как привязка к обрабатывающим потокам. Информация о том, на каком сервере хранится состояние, записывается в распределённую структуру и доступна кластеру до тех пор, пока сервер работает, и на доске находится хотя бы один пользователь. Мы используем Hazelcast для обеспечения работы этой части подсистемы. Все новые подключения к доске направляются на сервер с этим состоянием.
При подключении к серверу пользователь попадает в принимающий поток, единственная задача которого — привязать соединение к состоянию соответствующей доски, в потоках которого будет происходить вся дальнейшая работа.
С доской ассоциированы два потока: сетевой, обрабатывающий соединения, и “бизнесовый”, отвечающий за бизнес-логику. Это позволяет превратить выполнение разнородных задач обработки сетевых пакетов и исполнения бизнес-команд из последовательного в параллельное. Обработанные сетевые команды от пользователей формируют прикладные бизнес-задания и направляют их в бизнес-поток, где те обрабатываются последовательно. Это позволяет избегать лишней синхронизации при разработке прикладного кода.
Деление кода на бизнес/прикладной и системный — наша внутренняя условность. Она позволяет разграничить код, ответственный за фичи и возможности для пользователей, от низкоуровневых деталей коммуникации, шедулинга и хранения, являющихся обслуживающим инструментом.
Если принимающий поток обнаруживает, что для доски состояние отсутствует, ставится соответствующая задача инициализации. Инициализацией состояния занимается отдельный тип потока.
Типы задач и их направление можно изобразить следующим образом:
Такая реализация позволяет нам решать следующие проблемы:
- В принимающем потоке отсутствует бизнес-логика, которая могла бы замедлить новое подключение. Такой тип потока на сервере существует в единственном экземпляре, поэтому задержки в нём сразу скажутся на времени открытия досок, а при ошибке в бизнес-коде его можно легко повесить.
- Инициализация состояния выполняется не в бизнес-потоке досок и не влияет на время обработки бизнес-команд от пользователей. Она может занимать некоторое время, а бизнес-потоки обрабатывают сразу несколько досок, поэтому открытие новых досок не оказывает непосредственное влияние на уже работающие.
- Парсинг сетевых команд чаще выполняется быстрее, чем их непосредственное выполнение, поэтому конфигурация пула сетевых потоков может быть отличной от конфигурации пула бизнес-потоков, чтобы эффективно использовать ресурсы системы.
Раскраска потоков
Описанная выше подсистема в реализации получается довольно нетривиальной. Разработчику приходится держать в голове схему работы системы и учитывать обратный процесс закрытия досок. При закрытии необходимо убрать все подписки, удалить записи из реестров и сделать это в тех же потоках, в которых они были инициализированы.
Мы заметили, что баги и сложности модификации кода, которые возникали в этой подсистеме, часто были связаны с непониманием контекста выполнения. Жонглирование потоками и задачами затрудняло ответ на вопрос, в каком именно потоке выполняется отдельно взятый участок кода.
Для решения этой проблемы мы воспользовались методом раскраски потоков — это политика, направленная на регулирование использования потоков в системе. Потокам назначаются цвета, а методы определяют рамки допустимости выполнения внутри потоков. Цвет здесь — это абстракция, им может быть любая сущность, например, перечисление. В Java языком цветовой разметки могут служить аннотации:
@Color
@IncompatibleColors
@AnyColor
@Grant
@RevokeАннотации добавляются к методу, с помощью них можно задавать допустимость выполнения метода. Например, если аннотация у метода допускает жёлтый и красный цвет, то первый поток сможет вызвать метод, а для второго такой вызов будет ошибочным.
Можно задавать недопустимые цвета:
Можно в динамике добавлять и удалять привилегии потоков:
Отсутствие аннотации или аннотация как в примере ниже говорит, что метод может выполняться в любом потоке:
Android-разработчикам может быть знаком такой подход по аннотациям MainThread, UiThread, WorkerThread и т.п.
В раскраске потоков используется принцип самодокументирования кода, а сам метод хорошо поддаётся статическому анализу. Используя статический анализ, можно до выполнения кода сказать, правильно он написан или нет. Если исключить аннотации Grant и Revoke и считать, что поток при инициализации уже имеет неизменяемый набор привилегий, то это будет flow-insensitive анализ — простая версия статического анализа, которая не учитывает порядок вызовов.
В момент внедрения метода раскраски потоков в нашей devops-инфраструктуре не было готовых решений для статического анализа, поэтому мы пошли более простым и дешёвым путём — ввели свои аннотации, которые однозначно ассоциируются с каждым типом потоков. Проверять их корректность мы стали с помощью аспектов в runtime.
@Aspect
public class ThreadAnnotationAspect {
@Pointcut("if()")
public static boolean isActive() {
… // здесь учитываются флаги, определяющие включены ли аспекты. Используется, например, в ряде тестов
}
@Pointcut("execution(@ThreadAnnotation * *.*(..))")
public static void annotatedMethod() {
}
@Around("isActive() && annotatedMethod()")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
Thread thread = Thread.currentThread();
Method method = ((MethodSignature) jp.getSignature()).getMethod();
ThreadAnnotation annotation = getThreadAnnotation(method);
if (!annotationMatches(annotation, thread)) {
throw new ThreadAnnotationMismatchException(method, thread);
}
return jp.proceed();
}
}
Для аспектов мы используем библиотеку aspectj и maven плагин, осуществляющий weaving при компиляции проекта. Первоначально weaving был настроен на load-time при загрузке классов ClassLoader’ом. Однако мы столкнулись с тем, что weaver иногда некорректно вёл себя при конкурентной загрузке одного и того же класса, в результате чего исходный байт код класса оставался без изменений. В итоге это выливалось в весьма непредсказуемое и трудно воспроизводимое поведение на production. Возможно, в текущих версиях библиотеки такой проблемы нет.
Решение на аспектах позволило быстро найти большинство проблем в коде.
Важно не забывать всегда держать аннотации в актуальном состоянии: их можно удалить, полениться добавить, weaving аспектов вообще может быть отключён, — в этом случае раскраска быстро потеряет свою актуальность и ценность.
GuardedBy
К одной из разновидностей раскрашивания относится аннотация GuardedBy из java.util.concurrent. Она разграничивает доступ к полям и методам, указывая какие блокировки необходимы для корректного доступа.
public class PrivateLock {
private final Object lock = Object();
@GuardedBy (“lock”)
Widget widget;
void method() {
synchronized (lock) {
//Access or modify the state of widget
}
}
}
Современные IDE даже поддерживают анализ этой аннотации. Например, IDEA выдаёт такое сообщение, если в коде что-то не так:
Сам метод раскраски потоков не новый, но, кажется, что в таких языках как Java, где часто многопоточный доступ идёт к mutable объектам, его использование не только в рамках документирования, но и на этапе компиляции, сборки могло бы значительно упростить разработку многопоточного кода.
Мы до сих пор используем реализацию на аспектах. Если вы знакомы с более элегантным решением или средством анализа, позволяющим повысить устойчивость этого подхода к изменения системы, пожалуйста, поделитесь им в комментариях.
apanasevich
>около 30 серверов в production, 2 000 API запросов в секунду
2К на каждый? Или всего?
conoos Автор
Всего