
Балансируя пользователецентричное и автороцентричное ранжирование, мы можем добиваться правильного соотношения счастья пользователей и счастья авторов.
— Коллеги, всем привет. Меня зовут Боря. Я занимаюсь качеством ранжирования в Дзене. Я уверен, что это один из самых интересных сервисов Яндекса, у нас очень крутое машинное обучение, и в следующие 17 минут я вас в этом постараюсь убедить.
Что такое Дзен? Если совсем просто, Дзен — это сервис персональных рекомендаций. Мы стараемся рекомендовать пользователям релевантный им контент, основываясь на том, что мы знаем об интересах этих пользователей. Наша высокоуровневая цель — чтобы пользователи хотели в Дзене проводить время. И что очень важно — чтобы они об этом времени не жалели.
Примерно так выглядит наша основная форма потребления контента. Это бесконечная лента рекомендаций. И тут видно, что мы, в принципе, стараемся рекомендовать очень материалы на очень разные темы. Тут есть разные тематики: что-то про бизнес, что-то про юмор, даже что-то про фэнтези. То есть в ленте можно найти как познавательные и образовательные статьи, так и более развлекательные. И, разумеется, персонализация. Лента Дзена у всех выглядит по-разному — в зависимости от того, что пользователю интересно. Плюс, конечно, немного рекламы.

Очень важный момент. В самом начале, когда мы только появились, мы были, по сути, агрегатором контента из интернета. То есть мы обходили существующие сайты, брали с них контент, и показывали его пользователю в зависимости от интересов. Сейчас ситуация иная. Сейчас Дзен — это целая блогерская платформа, на которой каждый человек может завести свой канал, будь то какой-нибудь известный блогер или начинающий автор, которому есть о чем рассказать. Новые авторы видят вот такой приятный приветственный экран, в котором мы рассказываем о сервисе — что Дзен сам будет подбирать аудиторию, а от него требуется только писать хорошие материалы.
Сейчас на платформу приходится более половины общего трафика в Дзене. И этот показатель будет только расти. Мы понимаем, что ранжировать уже имеющийся контент контент могут все. Разумеется, мы сделаем это лучше всех. Но уникальный контент есть далеко не у всех, и мы верим, что именно в этом будет наше конкурентное преимущество.

Важно понимать, что Дзен уже очень большой. По данным Яндекс.Радара, на конец прошлого года у нас число дневных читателей примерно 10–12 млн в день, число читателей в месяц примерно 35 млн в день, и даже по некоторым данным, из того же Яндекс.Радара, мы в прошлом году впервые обошли по аудитории Яндекс.Новости. Это значит, что мы на полном серьезе делаем интернет, у нас задачи очень серьезные, их много, и мы очень ждем вашей помощи.
Поговорим про детали того, как это работает, и обсудим то, чем же у нас можно заниматься стажеру, чем можно помочь нашему сервису.
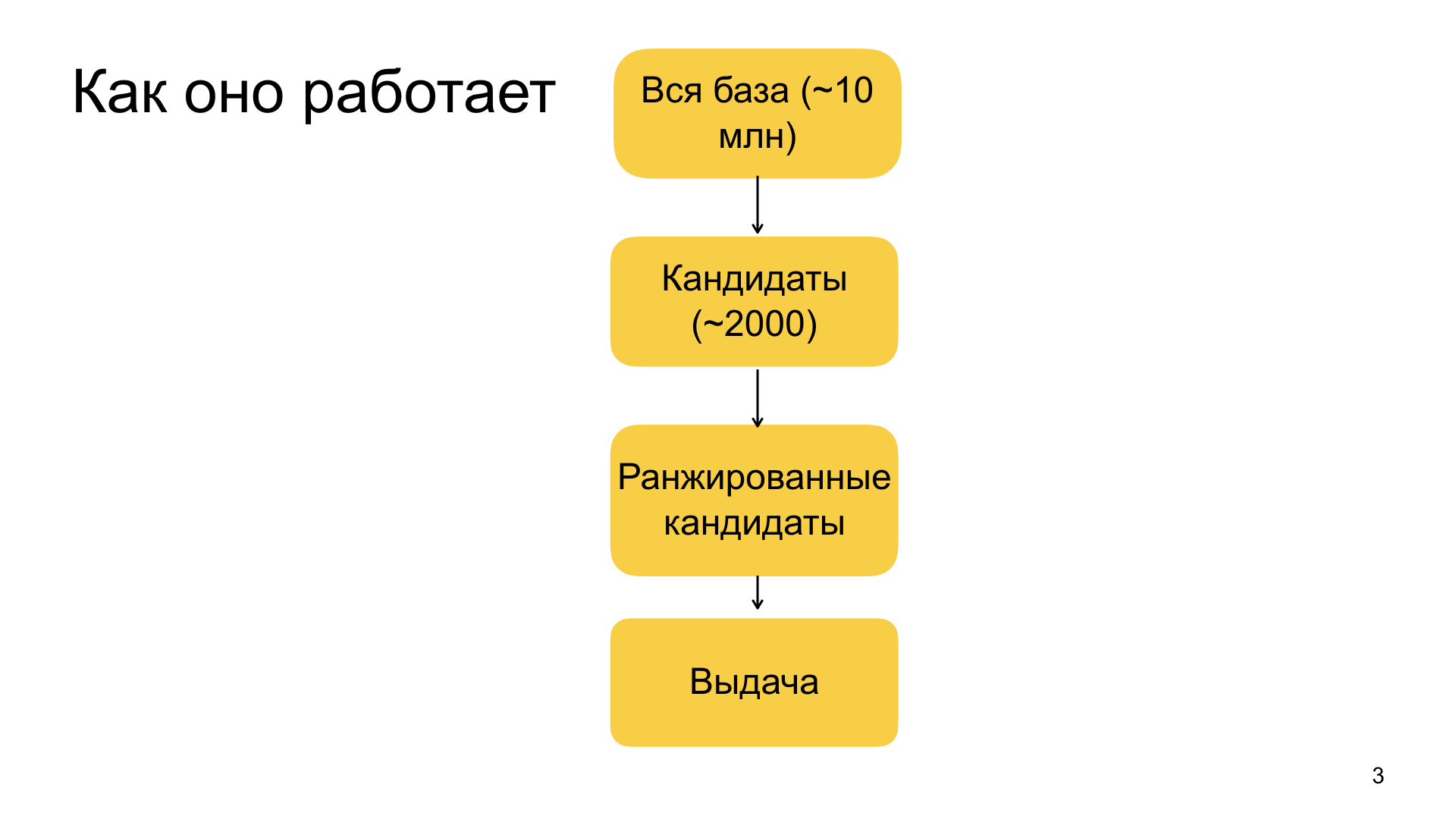
Общая схема рекомендаций у нас устроена примерно так. Все начинается с нашей большой базы документов, из которой мы выбираем материалы для рекомендаций. Она состоит из десятков миллионов документов. Причем эта база постоянно пополняется — ежедневно в нее поступает около миллиона новых документов. В идеале мы бы хотели применить весь наш аппарат машинного обучения ко всем этим десяткам миллионов документов персонально для каждого пользователя, и выбрать ему самое-самое релевантное. Но, к сожалению, на практике так сделать не получается, потому что Дзен — это сервис, который работает в реальном времени. У нас есть очень жесткие гарантии на то, насколько быстро мы готовы отвечать, поэтому из практических соображений мы вынуждены на первом этапе сужать базу из десятков миллионов документов до тысяч потенциальных рекомендаций, которые мы можем уже полностью отранжировать нашей моделью и выбрать из них самые релевантные. Этот этап сужения базы с десятков миллионов примерно до тысяч у нас называется отбором кандидатов или легким ранжированием.
Когда у нас есть этот набор, мы применяем к нему нашу сложную большую модель машинного обучения, которая на верхнем уровне представляет из себя градиентный бустинг. Тут все без сюрпризов, но факторы у нас очень разнообразные — от каких-то простых, которые характеризуют, например, то, насколько пользователю релевантен данный домен, источник, насколько он часто на него заходит, кликает, оставляет фидбек, лайки и дизлайки. Так и более сложные факторы, которые основаны, например, на нейросетевых признаках. Мы обрабатываем текст статьи, мы обрабатываем картинки, другие источники данных, и используем такие композитные признаки тоже. Все это схема довольно сложная, в деталях рассказать не успею.
После того, как мы отранжировали наши 2 тыс. кандидатов, мы отбираем из них топ. Размер топа зависит от того, сколько нам надо порекомендовать материалов. Это всегда определяется по-разному. И таким образом мы формируем итоговую выдачу.
Так выглядит схема на высоком уровне. Теперь давайте поговорим о том, какие же компоненты всего этого процесса нам интересно улучшать.

Оказывается, что нам интересно заниматься примерно всем. Задач очень много. Мы хотим увеличивать скорость доставки данных для ранжирования: чем более свежие у нас данные, тем более релевантные мы делаем рекомендации. Хочется ускорять время работы сервиса: чем быстрее работаем, тем лучше пользовательский экспириенс. Мы хотим повышать надежность сервиса.
Нам важно улучшать ранжирование. То есть нам нужно применять и новые модели машинного обучения, и улучшать наши текущие модели в других странах. Мы рекомендуемся не только в России, но и во многих других странах мира.
Также мы хотим учитывать региональность и рекомендовать людям контент, который относится к их региону.
И очень важно — нам надо развивать нашу авторскую платформу. Это наше будущее, нам надо в нее вкладываться. Задач тут тоже очень много. В частности, нам надо уметь находить и бустить качественный контент. Нам важно показывать хорошие материалы, а не треш. Нам нужно уметь ранжировать новые форматы контента. У нас есть не только статьи, но и короткие видео, и посты, которые пользователи смотрят прямо в ленте. Все эти форматы нужно уметь ранжировать.
И очень важный момент, о котором я хочу поговорить немного подробнее в более технических деталях — нам важно уметь для каждого автора находить релевантную ему аудиторию, даже если речь идет о довольно нишевых авторах и темах. Давайте поговорим подробнее, в чем же здесь проблема и как мы ее решаем.
Давайте рассмотрим это на примере.
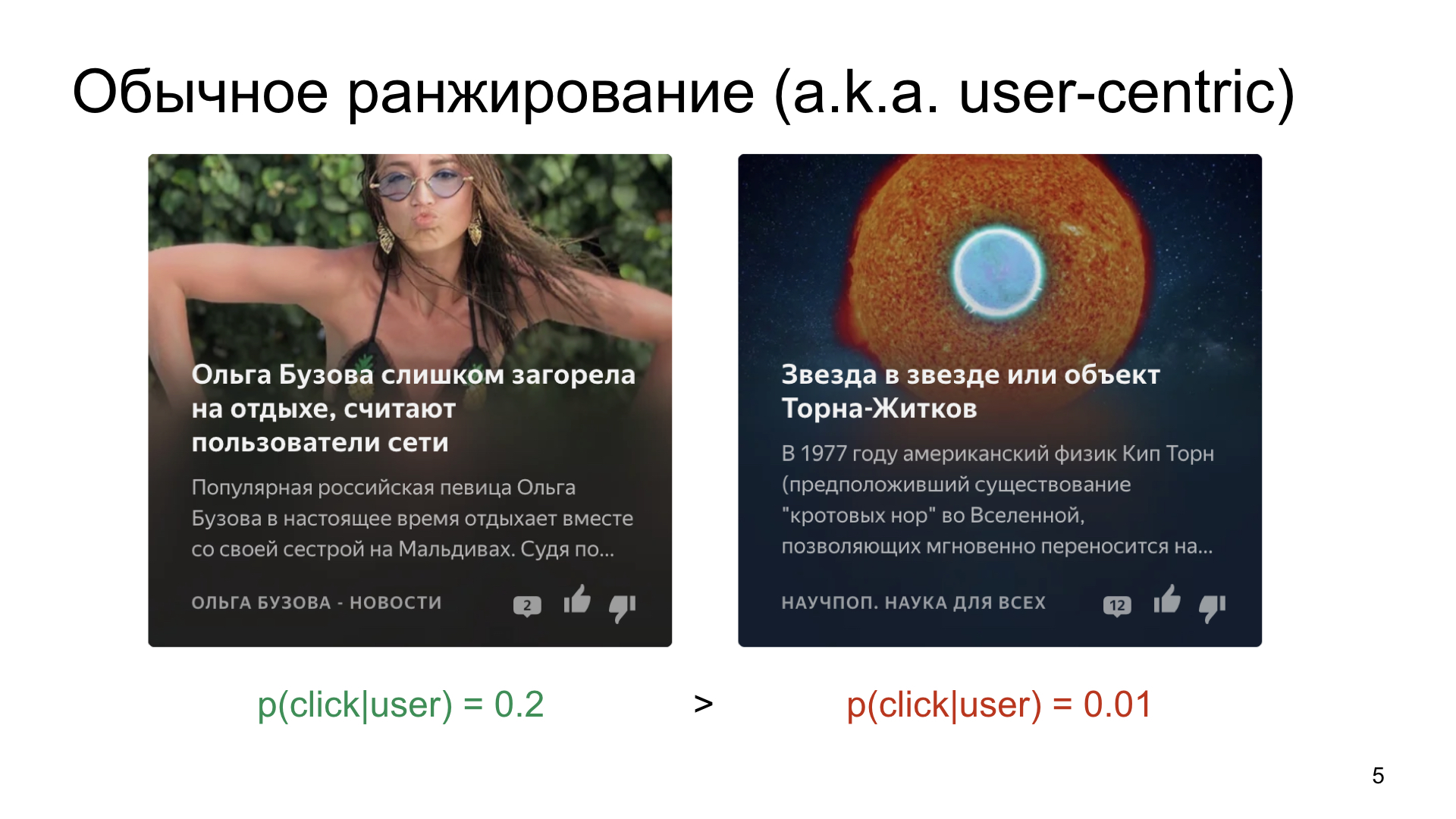
Мы выбираем, предположим, из двух карточек, которые мы хотим показать пользователю.
Так устроен мир и так устроен человек, что есть нечто более среднепопулярное, где вероятность клика в среднем процентов 20, а есть что-то более нишевое, например статьи про науку или про космос.
Если мы просто ранжируем карточки по вероятности клика, то, разумеется более кликабельный и более простой контент будет собирать очень большое количество показов, а даже очень хорошая статья про науку — нет. Конечно, нам такого не хочется. Мы хотим находить заинтересованную аудиторию даже для нишевых каналов.

Почему это хочется делать? На самом деле, здесь есть две причины. Первая — продуктовая. То есть мы хотим, чтобы Дзен был некоторым срезом интернета. Чтобы всё, что пользователь может найти и чем он интересуется в большом интернете, было представлено в Дзене. И чтобы он получал то, что ему интересно.
У научных каналов есть своя аудитория. Но есть такой нюанс. Если любителям науки показать науку и популярный контент, они на него кликнут с большей вероятностью, чем на науку. Но если им показать только науку, они на науку тоже кликнут, и даже ничуть об этом не пожалеют. Вопрос в том, как находить таких людей и как показывать контент, ориентируясь не на пользователя, а на автора.

Как же это делать? Обычная формула ранжирования, которая предсказывает вероятность кликов, нам здесь не поможет, потому что в среднем более нишевые статьи будут проигрывать. Но можно пойти другим путем — выделить некоторую квоту, и в ней более или менее равномерно дать показы авторам, дать им своего рода минимальную гарантию. Так делать можно, и это сделает авторов немного счастливее, но, к сожалению, это сделает менее счастливыми наших пользователей. Пользователи будут меньше кликать, больше расстраиваться и уходить. Мы этого, конечно, не хотим.
Как здесь быть?
Мы долго думали и придумали новую концепцию. Мы назвали ее автороцентричным ранжированием или показами для автора.
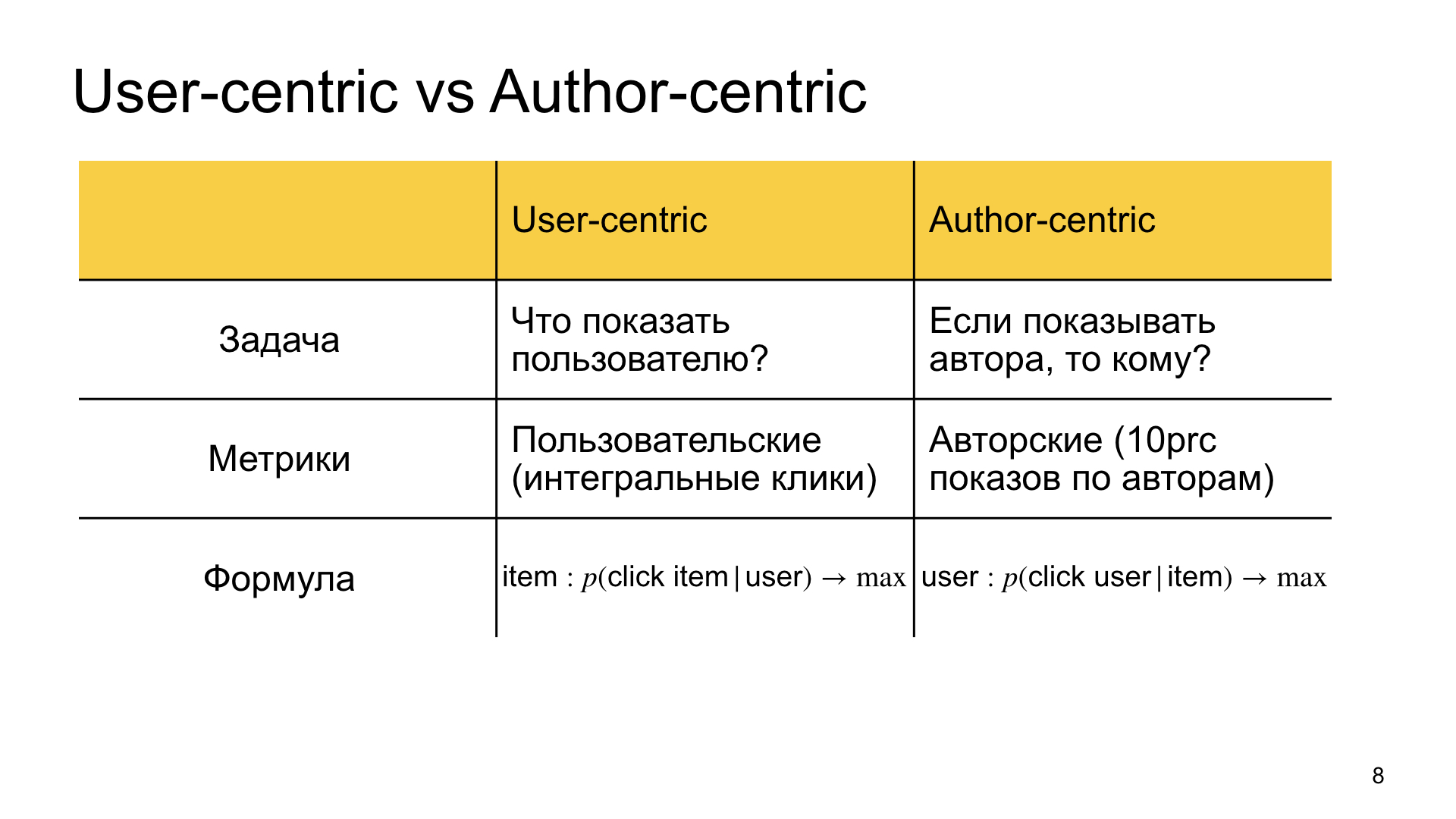
Какова наша цель в обычном ранжировании, которое мы называем пользователецентричным? Найти материал, который наиболее релевантен пользователю. Мы отвечаем на вопрос, что показать пользователю.
В автороцентричном ранжировании мы как бы переворачиваем постановку задачи и говорим, что мы хотим показать данного автора, и вопрос в том, кому его показать, кому он наиболее релевантен. Отсюда и разница в метриках. В первом случае нас больше интересуют пользовательские метрики, то есть интегральные клики, интегральное время в Дзене и так далее. Во втором случае нас интересуют так называемые авторские метрики. Например, мы измеряем то, насколько хорошо живется в Дзене, например, bottom 10% авторов. Если им живется достаточно хорошо, то и все остальные тоже счастливы.

Как же мы это делаем? Предположим, что у нас есть обычная формула ранжирования. Для простоты предположим, что она предсказывает вероятность клика пользователя на данный айтем, на данную карточку. Что мы сделаем? Давайте теперь для каждой статьи зафиксируем ее и применим нашу модель для этой статьи, в идеале — ко всем пользователям, на практике — к какому-то семплу пользователей. И построим распределение наших scores, то есть оценок вероятности кликнуть на статью, для каждой статьи по пользователям. Теперь для каждой статьи у нас есть такое распределение, как на графике (слайд выше — прим. ред.). После этого отранжируем статьи для пользователя и выберем топ не просто по вероятности клика, а по перцентили, в которую данный пользователь попадает для данной статьи. То есть мы оценим вероятность клика, посмотрим, куда пользователь попадает в этом распределении, и отранжируем по этой величине.

Вот у нас те же две карточки, одна из них более кликабельна, 20%, другая — менее, 1%. Теперь, если взять конкретного пользователя, возможна такая ситуация, что у него на более популярную карточку вероятность клика больше, чем на менее популярную, скажем, 10% против 3%. Но так как в среднем вероятность клика на популярную карточку 20%, а у пользователя 10%, то он в среднем менее релевантен данной публикации, чем средний пользователь Дзена. А в другой ситуации наоборот: у него вероятность клика 3%, но в среднем у статьи 1%. Поэтому он является более релевантной для статьи аудиторией в среднем, чем остальные пользователи Дзена. Поэтому ключевой инсайт здесь в том, что даже если вероятность клика на статью меньше, с помощью такого фреймворка мы имеем шанс показать менее популярную статью, если пользователь входит в наиболее доверенное ядро для данной публикации.

Если пользователи приходят к нам более или менее равномерно, то данный score, по которому мы ранжируем, то есть перцентиль, в который попадает каждый пользователь, будет распределена равномерно по пользователям. Это значит, что если все статьи ранжировать таким образом, то все они соберут более-менее одинаковое количество показов. Не будет выбросов в десятки миллионов показов против 10 показов у каких-нибудь менее релевантных карточек. Таким образом, балансируя пользователецентричное и автороцентричное ранжирование, мы можем добиваться того соотношения счастья пользователей и счастья авторов, которое мы считаем правильным.
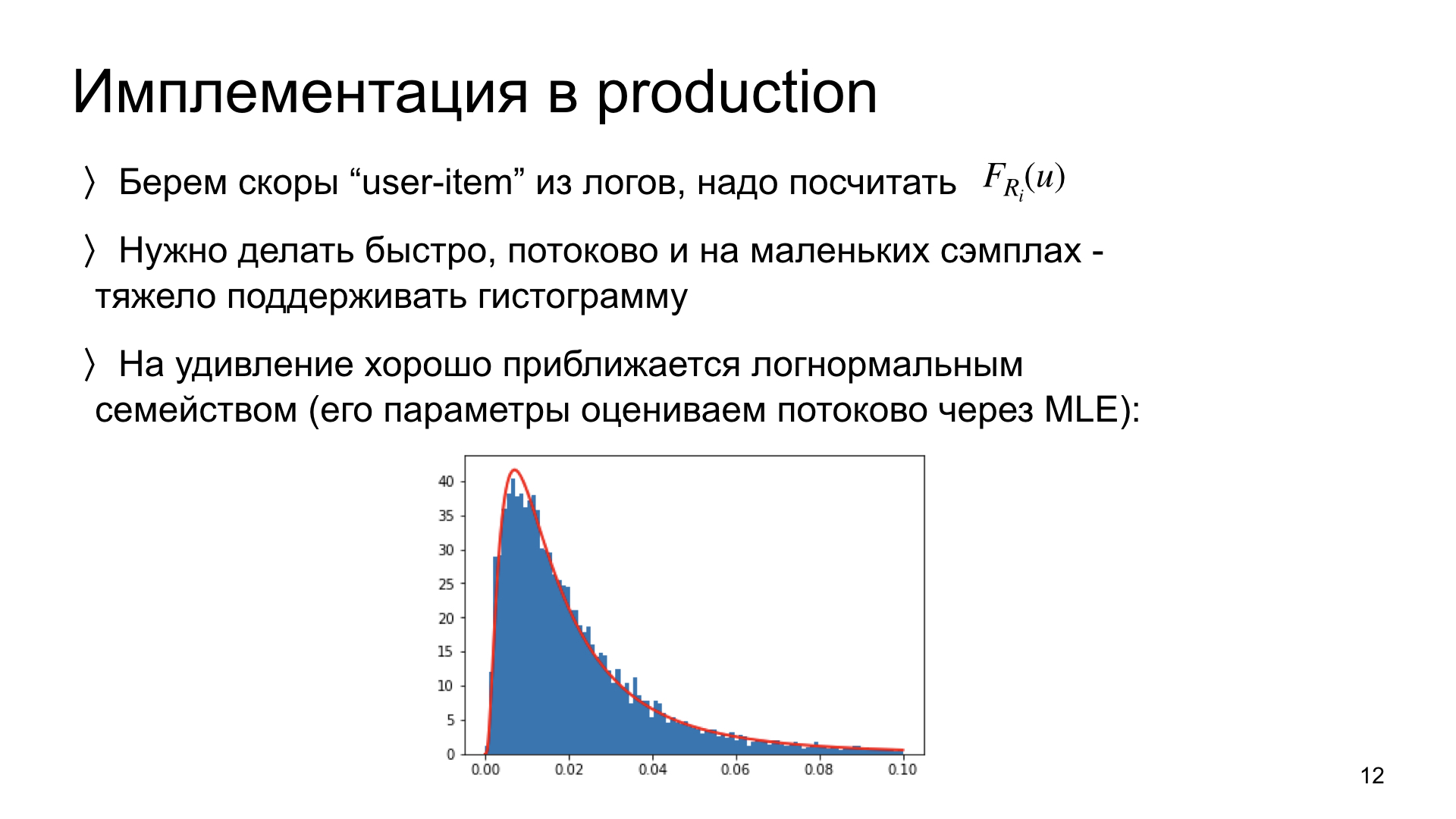
Пару слов о том, как мы это реализовываем в продакшене. Нам нужно посмотреть на наши логи и из них посчитать данное распределение для каждой статьи. Важное ограничение: нам нужно уметь это делать, во-первых, быстро, во-вторых, в потоковом режиме. То есть в идеале для того, чтобы обновить оценку распределения по новым данным, нам нужно иметь в памяти не все предыдущие данные, а только текущую оценку. Такая система масштабируется, такая схема работает. В идеале нам нужно уметь это делать на маленьких данных. Если у какой-нибудь статьи всего 300 показов, то нам нужно уметь за такое количество наблюдений адекватно оценить распределение.
Мы провели эксперименты и обнаружили, что такие распределения scores на удивление хорошо приближаются к лог-нормальным распределениям. То есть это эмпирическое наблюдение. А раз так, то мы вместо того, чтобы оценивать не параметрически всю гистограмму распределения, можем оценить только два параметра данного распределения. Причем мы можем это делать в потоке, используя только текущую оценку параметров и новые наблюдения. Такая схема получается очень быстрой и работает очень хорошо. Сейчас она у нас находится в продакшене.
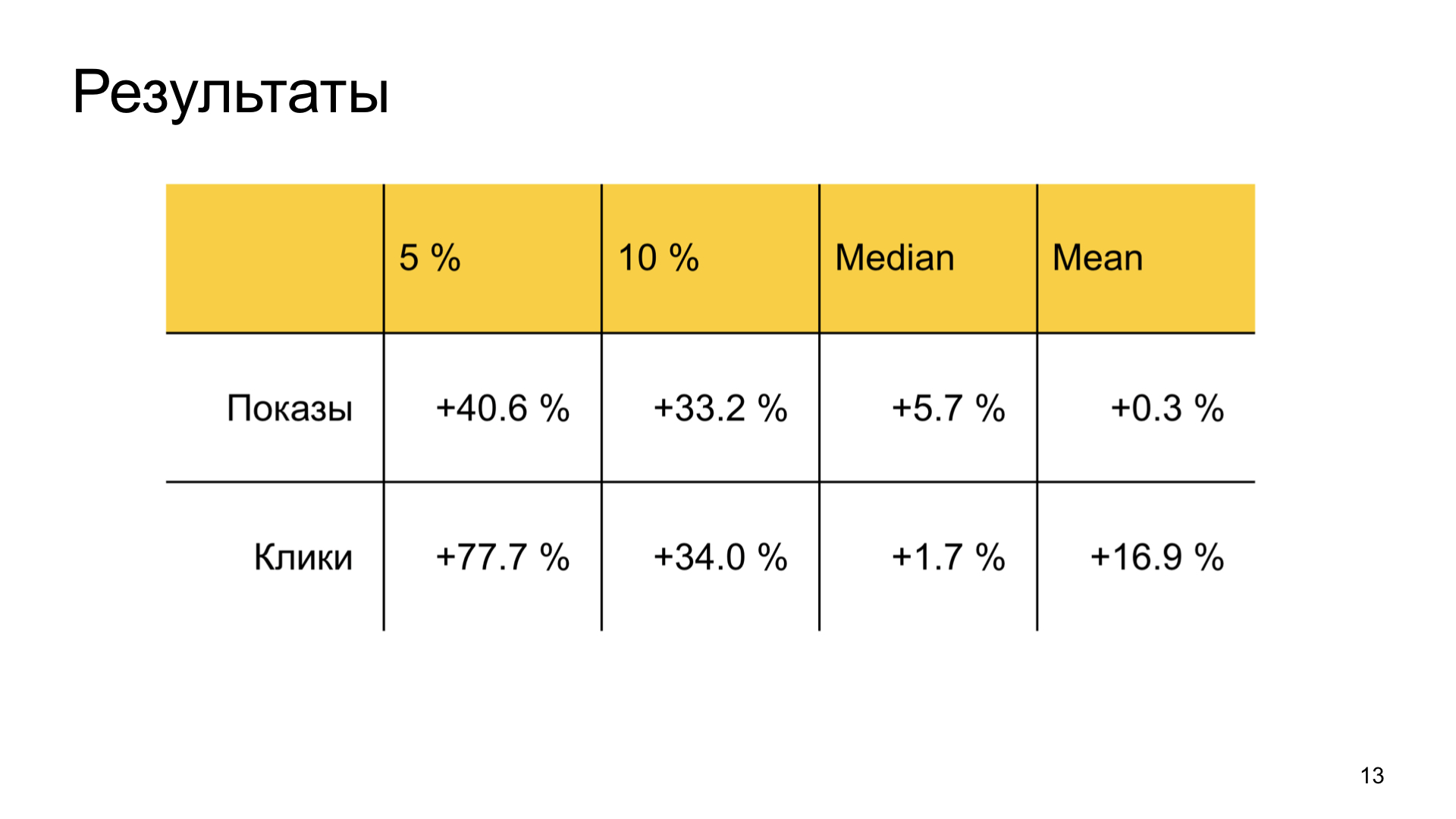
Результаты тоже получаются хорошими. Мы сильно растим счастье обделенных вниманием хороших авторов в Дзене и при этом не просаживаем общие пользовательские метрики. То есть бизнес-задача полностью достигается.
Я сейчас показал один из примеров задач, которыми у нас можно заниматься. Разумеется, этих задач много, и с каждой из них нам нужна ваша помощь. Очень надеемся, что вы захотите у нас работать. Напоследок скажу пару слов о том, чего же мы ждем от стажеров и чего мы от них не ждем. От стажера мы ждем самого главного — умения писать код. У нас в сервисе нет дата-саентистов в чистом виде. У нас все — ML-инженеры, они должны уметь делать полный цикл задач. Они должны уметь и имплементировать свое решение в продакшен, и применять ML. То есть мы ожидаем, что вы умеете писать код на базовом уровне, понимаете подходы, знаете алгоритмы, структуры данных, основы машинного обучения.
Чего мы не ждем от стажеров? В первую очередь, мы не ждем глубокого знания каких-то языков или фреймворков. То есть если вы не знаете, как работают корутины в Python — ничего страшного, мы вас всему научим. И мы не ждем от вас большого опыта. Мы ждем от вас знаний, желания работать. Если нет опыта — ничего страшного. Всему научим, и все будет хорошо. Спасибо!
Комментарии (39)

tuxi
17.03.2019 12:44+1Тут бы не помешал бы раздел «Минутка заботы от НЛО»
То, что предлагает Дзен в своей ленте, иногда хуже чем худшие версии газеты «Спид-Инфо» в свое время. Но там то хоть картинки были интересные.

ilya_pu
17.03.2019 12:58+1Как читатель ленты дзен, могу отметить одну проблему: со временем, если я когда-то читал много статей на определенную тему, в моей ленте практически перестают попадаться другие темы, которые мне, быть может, не менее интересны. Собственно, дзен недалеко ушел от баннерной рекламы, которая рекламирует мне товар давно мной купленный и потому совершенно неинтересный. С точки зрения теории, теория и практика — одно и то же, но на практике это совсем не так!
Whiteha
17.03.2019 13:26Очень напрягает в Дзене когда ты читаешь научпоп, мед статьи по современным достижениям, а тебе ленту периодически заваливает «пришельцами с нибиру» и, советами «как с помощью градусника проверить щитовидную железу», иными словами не хватает фильтрации к псевдонаучности и желтухе, хотя бы самой грубой.

SADKO
17.03.2019 13:48+1А это наверное потому, что язык мед и научпоп статей, не далёк от статей про то как международная группа учёных археологов проводя вскрытие пирамиды обнаруженной и запечатанной в 1998 году правительством Египта, обнаружили среди многих мумий, мумию предположительно пришельца ;-)
Ну, или сотрудники Института Апледжера в серии экспериментов обнаружили статистически значимое влияние минералов на краниальные ритмы мозга.
На хабре, такой наукообразной лажи тоже навалом.
Superkotik
17.03.2019 14:21-1Руководитель группы счастья авторов? Позвольте спросить — это еще что за херня? В Яндексе давно пора ввести должность руководителя группы счастья пользователей яндекс, который бы выпилил гребаный дзен к чертовой матери.
www.youtube.com/watch?v=P04sIgL32E8

sairus777
17.03.2019 15:09+1Да, желтуха очень быстро захватывает всю ленту… Стоит раз отвлечься на дурную статью, как начинается засилье желтой прессы. Чего хронически не понимают ни здесь, ни на ютубе — так это то, что пользователь сам хочет в явном виде управлять наполнением контента под разные свои задачи. Что у каждого есть свой спектр тем, которые хотелось бы фильтровать вручную. Неуместно рекомендовать контент про кино, если пользователь сейчас ищет научный контент (несмотря на его историю интереса к фильмам).
Чего еще хронически не понимают — это разный качественный уровень статей (как уже было отмечено выше про псевдо-научный контент).tuxi
17.03.2019 15:30+1Даже если не кликать на желтизну, все равно упорно лезет «бузова». Посмотрите сколько усилий делается на Хабре, чтобы поддерживать качество контента на высоте. А Дзен — у него же обратная задача. Это же монетизация в чистом виде. Я часто читаю РБК, никогда не подписывался на Дзен. И вот в статьях на РБК, внизу есть лента Дзена. Заголовки и содержимое — взрывает мозг
что то типа такого
sairus777
17.03.2019 15:44Согласен, первый же вопрос, на котором заваливаются 100% маркетологов: «как Ваш продукт поможет мне решать мои задачи?». Парадокс в том, что наиболее качественные материалы чаще всего нишевые, т.к. нацелены на решение конкретных задач квалифицированного читателя.
pcdesign
17.03.2019 16:51Мои попытки блокировать Дзен:
1) Прописал в hosts 127.0.0.1 zen.yandex.ru — на какое-то время помогло. Потом перестало.
2) Заблочил на уровне Adblock — тоже помогло на какое-то время.
3) Засунул запрет за js в браузере для хоста zen.yandex.ru — помогло для мобильных устройств, но не для браузера десктопа.
4) Выбрал в настройках дзена — английский язык (жаль нельзя выбрать какой-нибудь китайский). Теперь вместо Бузовой мне показывают Ким Кардашан.
Если честно, то устал.
expromt
17.03.2019 17:35Тоже достал в свое время :-)
Заблокировал довольно легко:
Добавил в hosts 127.0.0.1 zen.yandex.ru и нужно после добавления записи почистить историю браузера или хотя бы скрипты. Сами новости тянутся не с zen.yandex.ru, с этого адреса тянется только скрипт Дзена который потом кешируется в браузере. Заблокировал таким образом очень давно, и с тех пор ни разу не видел дзена.pcdesign
17.03.2019 17:36Это потому что вы не авторизовались на яндексе. А попробуйте авторизоваться и зайти на главную страницу.

sysd
17.03.2019 21:01ublock-origin вроде научился резать. Дзен, насколько я понял из эксппериментов с блокировщиками, лезет не zen.yandex.ru, а с yastatic.net, а на нем в свою очередь завязана часть дополнительного функционала сервисов и вся остальная мерзость. Но поиск работает.

LevOrdabesov
18.03.2019 19:42pcdesign
18.03.2019 20:00Спасибо за ссылку, но я к опере привык.
LevOrdabesov
18.03.2019 20:16+1Есть для хром-движка. Или речь об опере 12?
pcdesign
18.03.2019 21:17Поставил это расширение.
Сначало не работало, зашел в настройки поставил галки.
Стало блокироваться.
Спасибо большое!
sysd
19.03.2019 09:08Отлично, спасибо. Хотя уже на DDG пытаюсь переезжать.
LevOrdabesov
19.03.2019 11:26Кстати, да. С тех пор, как зен появился, я постепенно пришёл к выводу: зен есть на тех сайтах, куда ходить и особо не стоит. В итоге как-то так поменялись привычки, что теперь и без блокировщика зен не вижу. Новости гораздо лучше поданы там том же Рейтерс, чем в исполнении отечественных новостных агентств. Для курсов валют есть масса специализированных сайтов. Для космических новостей – Хабр :)
В итоге вместо информационного сервиса получился детектор скама.
StrangerInTheKy
18.03.2019 02:55+1Результаты тоже получаются хорошими. Мы сильно растим счастье обделенных хороших авторов в Дзене и при этом не просаживаем общие пользовательские метрики. То есть бизнес-задача полностью достигается.
Это вообще шедевральное завершение статьи. Сам сделал работу, сам ее оценил, сам себя за нее похвалил. Полное самообслуживание. Фидбек от пользователей? Нет, не слышали.
А между тем, уровень дремучести и пуританства у модераторов Дзена превышает таковой у Римской Католической церкви образца 15-го века: shakko-kitsune.livejournal.com/1376977.html (запись в ЖЖ искусствоведа Софьи Багдасаровой, повествующая о перепетиях общения с алгоритмами и техподдержкой Яндекса).
P. S. Про алгоритмы «кому что показывать» там тоже есть пара нелестных замечаний.
LinearLeopard
18.03.2019 06:17Не знаю, как обстоит дело с качеством предсказывания аудитории для авторов, но вот предсказывание статей для читателей, похоже, сломано совсем.
Краткое содержание: хохлы обосрались, пиндосы обосрались, санкции не работают, украина лучше всех, Россия скоро распадётся, доллар рухнет, Беларусь анексируют, доллар растёт, шокирующие подробности о <типо кто-то известный>, 10 лайфхаков со сливочным маслом, Нострадамус предсказал смерть человечества в 2019.
Одна техническая или научная статья или пусть даже политическая, но написанная нормальным тоном за день — хороший результат.
akademik21
18.03.2019 10:29Яндекс.Дзен — мусор. И мусор по контентной наполненности, а не по идее. Кликбейтное наполнение, статьи с заголовками в 3 раза более интересными, чем тело. И самое прискорбное — отсутствие рубильника в настройках яндекса «не хочу видеть этот позор нигде и никогда», ну этому у яндекса я даже не удивляюсь.
Megakazbek
18.03.2019 11:21Это логично, так как основной параметр, по которому определяется годится статья или нет — это клик пользователя. Т.е. оценивается не контент, а заголовок, по которому кликают, а от содержания уже ничего не зависит и не удивительно, что в такой системе ценностей побеждают именно кликбейтные заголовки с мусорным содержанием.
Megakazbek
18.03.2019 14:22Вообще, статья хорошо показывает, что при использовании всяких этих метрик, ранжирований и машинных обучений, не нужно забывать о связи с реальностью. Они сидят в Яндексе, думают, что управляют блогерской платформой и делают авторов счастливыми, а пользователь при этом видит агрегацию мусорного контента и недоумевает, что это вообще за хрень.
immaculate
18.03.2019 15:32Почти все, что мне выдает Яндекс.Дзен — кликбейт. Короткие статьи ни о чем, с громкими названиями. Например: «Как мы нашли в лесу клад Колчака с тоннами золота и оружия». Открываешь, там какая-то чепуха как кто-то с миноискателем лазил по лесу и нашел гнилой ящик с кучей ржавчины. Предположительно, это остатки какого-то оружия. Статья на 2-3 абзаца, и совершенно ни о чем.
И таких авторов там вагон и маленькая тележка. Нереально достало, просто перестал кликать по любым статьям в этом Дзене, чтобы не разочаровываться.
Такое ощущение, что 95% блогов в этом дзене генерируется псевдо-ИИ или вообще цепями Маркова.
P. S. Подумалось, что это проблема не только конкретного Дзена. Все рекомендательные системы, по-моему, работают криво, и рано или поздно начинают вызывать лишь раздражение. От Facebook до Netflix. Но конкретно в Яндекс.Дзен еще и мусорных авторов на порядки больше чем где-либо.
LevOrdabesov
Вопрос к докладчику!
Всегда было интересно: вам правда нравится бузову живым людям показывать? Или вы работаете на этой работе, потому что «ну всем же нужно есть»?
dkasyanov
Кажется смешным, но люди переходят по таким ссылкам
LevOrdabesov
Да чего уж тут смешного…
qbz
Одни люди делают системы, другие эти системы используют.