
Только в одних США живёт 3 миллиона человек с ограниченными возможностями передвижения, которые не могут покинуть свои дома. Вспомогательные роботы, способные автоматически ориентироваться на дальних расстояниях, могут сделать таких людей более независимыми, привозя им продукты, лекарства и посылки. Исследования показывают, что глубокое обучение с подкреплением (ОП) хорошо подходит для сопоставления сырых входных данных и действий, к примеру, для обучения захвату объектов или передвижению роботов, но обычно у ОП-агентов отсутствует понимание крупных физических пространств, необходимое для безопасного ориентирования на дальних расстояниях без помощи человека и адаптации к новому окружению.
В трёх недавних работах, "Обучение ориентированию с нуля с АОП", "PRM-RL: осуществление роботизированного ориентирования на дальних расстояниях при помощи комбинации обучения с подкреплением и планирования на основе образцов" и "Ориентирование на дальних расстояниях с PRM-RL", мы изучаем автономных роботов, легко адаптирующихся к новому окружению, комбинируя глубокое ОП с долгосрочным планированием. Мы обучаем локальных агентов-планировщиков выполнению базовых действий, необходимых для ориентирования, и передвижению на короткие расстояния без столкновений с движущимися объектами. Локальные планировщики проводят зашумлённые наблюдения окружающей среды при помощи таких датчиков, как одномерные лидары, выдающие расстояние до препятствия, и выдают линейные и угловые скорости для управления роботом. Мы обучаем локального планировщика в симуляциях при помощи автоматического обучения с подкреплением (АОП), метода, автоматизирующего поиски награды для ОП и архитектуры нейросети. Несмотря на ограниченный радиус действия, 10-15 м, локальные планировщики хорошо адаптируются как к применению в реальных роботах, так и к новым, ранее неизвестным окружениям. Это позволяет использовать их в качестве строительных блоков для ориентирования на больших пространствах. Затем мы строим дорожную карту, граф, где узлами являются отдельные участки, а рёбра соединяют узлы, только если локальные планировщики, хорошо имитирующие реальных роботов при помощи зашумлённых датчиков и управления, могут перемещаться между ними.
В первой нашей работе мы обучаем локального планировщика в статичном окружении небольшого размера. Однако при обучении стандартным глубоким ОП алгоритмом, например, глубоким детерминистским градиентом (DDPG), можно столкнуться с несколькими препятствиями. К примеру, реальной целью локальных планировщиков является достижение заданной цели, в результате чего они получают редкие награды. На практике это требует от исследователей потратить значительное время на пошаговую реализацию алгоритма и ручную подстройку наград. Также исследователям приходится принимать решения по поводу архитектуры нейросетей, не имея чётких успешных рецептов. И, наконец, такие алгоритмы, как DDPG, обучаются нестабильно и часто демонстрируют катастрофическую забываемость.
Для преодоления этих препятствий мы автоматизировали глубокое обучение с подкреплением. АОП – это эволюционная автоматическая обёртка вокруг глубокого ОП, ищущая награды и архитектуру нейросети при помощи крупномасштабной оптимизации гиперпараметров. Работает она в два этапа, поиск награды и поиск архитектуры. Во время поиска награды АОП параллельно обучает популяцию DDPG-агентов на протяжении нескольких поколений, причём у каждого получается своя, немного изменённая функция награды, оптимизированная на истинную задачу локального планировщика: достижение конечной точки пути. В конце фазы поиска награды мы выбираем такую, которая чаще всего приводит агентов к цели. В фазе поиска архитектуры нейросети мы повторяем этот процесс, на этот рас используя выбранную награду и подстраивая слои сети, оптимизируя кумулятивную награду.
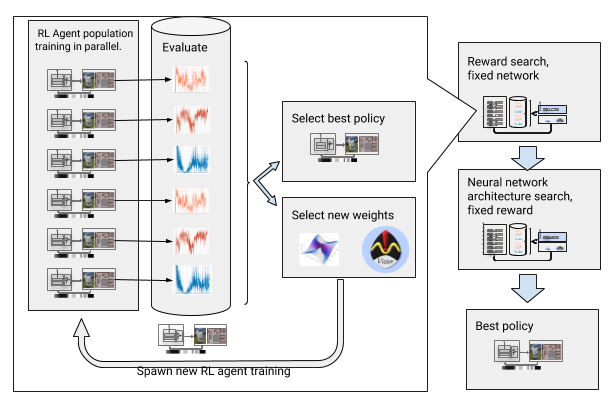
АОП с поиском награды и архитектуры нейросети
Однако такой пошаговый процесс делает АОП неэффективным с точки зрения количества образцов. Обучение АОП с 10 поколениями из 100 агентов требует 5 млрд образцов, что эквивалентно 32 годам обучения! Преимущество в том, что после АОП ручной процесс обучения автоматизируется, и у DDPG не возникает катастрофического забывания. Что самое важное, качество итоговых политик оказывается выше – они устойчивы к шуму от датчика, привода и локализации, и хорошо обобщаются к новым окружениям. Наша лучшая политика на 26% успешнее других методов ориентирования на наших испытательных полигонах.
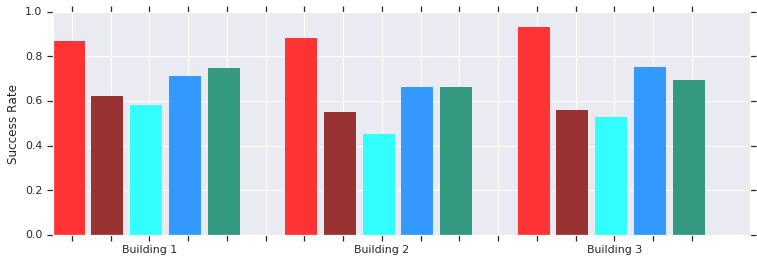
Красный – успехи АОП на коротких расстояниях (до 10 м) в нескольких неизвестных до этого зданиях. Сравнение с DDPG, обученным вручную (тёмно-красный), искусственными полями потенциала (голубой), динамическим окном (синий) и клонированием поведения (зелёный).
Политика локального планировщика АОП хорошо работает с роботами в реальных неструктурированных окружениях
И хотя эти политики способны только на локальное ориентирование, они устойчивы по отношению к движущимся препятствиям и хорошо переносятся на реальных роботов в неструктурированных окружениях. И хотя они были натренированы в симуляциях со статическими объектами, они эффективно справляются и с движущимися. Следующий шаг – скомбинировать АОП-политики с планировкой на основе образцов, чтобы расширить область их работы и научить их ориентироваться на дальних расстояниях.
Планировщики, работающие на основе образцов, работают с ориентированием на дальних расстояниях, аппроксимируя движения робота. К примеру, вероятностные дорожные карты (PRM) робот строит, проводя между участками реализуемые пути перехода. В нашей второй работе, выигравшей награду на конференции ICRA 2018, мы комбинируем PRM с подстроенными вручную локальными ОП-планировщиками (без АОП), чтобы обучать роботов локально, а потом адаптировать их к другим окружениям.
Сначала для каждого робота мы обучаем локальную политику планировщика в обобщённой симуляции. Затем мы создаём PRM с учётом этой политики, так называемую PRM-RL, на основе карты того окружения, где он будет использоваться. Ту же карту можно использовать для любого робота, которого мы желаем использовать в здании.
Для создания PRM-RL мы объединяем узлы из образцов, только если локальный ОП-планировщик может надёжно и неоднократно перемещаться между ними. Это делается в симуляции по методу Монте-Карло. Полученная карта подстраивается под возможности и геометрию определённого робота. У карт для роботов с одинаковой геометрией, но разными датчиками и приводами, будет разная связность. Поскольку агент может поворачивать за угол, можно включать и узлы, не находящиеся в прямой видимости. Однако узлы, расположенные рядом со стенами и препятствиями будут включены в карту с меньшей вероятностью из-за шума датчиков. Во время выполнения ОП-агент перемещается по карте от одного участка до другого.

Карта создаётся с тремя симуляциями Монте-Карло на каждую случайно выбранную пару узлов
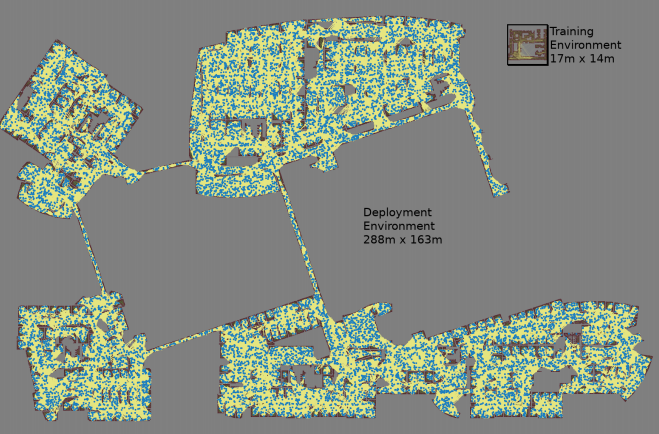
Самая крупная карта имела размер 288х163 м и содержала почти 700 000 рёбер. 300 работников собирали её 4 дня, проведя 1,1 млрд проверок на столкновения.
Третья работа обеспечивает несколько улучшений оригинального PRM-RL. Во-первых, мы заменяем подстроенный вручную DDPG локальными планировщиками с АОП, что даёт улучшение в ориентировании на больших расстояниях. Во-вторых, добавляются карты одновременной локализации и разметки (SLAM), которые роботы используют во время выполнения в качестве источника для построения дорожных карт. Карты SLAM подвержены шуму, и благодаря этому закрывается «разрыв между симулятором и реальностью», известная в робототехнике проблема, из-за которой агенты, обученные в симуляциях, ведут себя в реальном мире значительно хуже. У нас уровень успеха в симуляции совпадает с уровнем успеха реальных роботов. И, наконец, мы добавили распределённые карты зданий, благодаря чему можем создавать очень большие карты, содержащие до 700 000 узлов.
Этот метод мы оценили при помощи нашего АОП-агента, создававшего карты на основе чертежей зданий, превосходящих по площади тренировочное окружение в 200 раз, включая в них только рёбра, успешное прохождение которых осуществлялось в 90% случаев за 20 попыток. Мы сравнили PRM-RL с различными методами на дистанциях до 100 м, серьёзно превышавших дальность действия локального планировщика. PRM-RL достигала успеха в 2-3 раза чаще обычных методов благодаря правильному соединению узлов, подходящему под возможности робота.
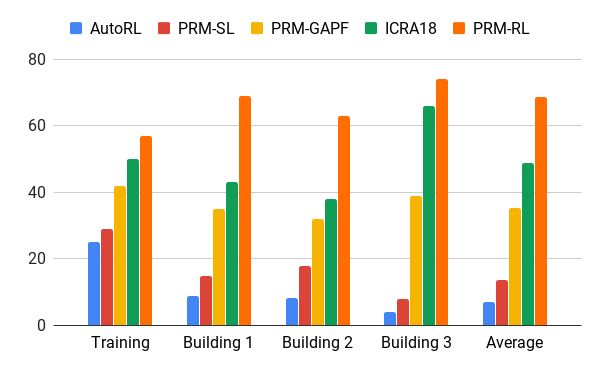
Процент успеха в перемещении на 100 м в разных зданиях. Синий – локальный АОП-планировщик, первая работа; красный – оригинальный PRM; жёлтый – искусственные поля потенциала; зелёный – вторая работа; красный – третья работа, PRM с АОП.
Мы испытывали PRM-RL на множестве реальных роботов в множестве зданий. Внизу показан один из наборов тестов; робот надёжно двигается почти везде, кроме самых беспорядочных мест и участков, выходящих за пределы карты SLAM.

Машинное ориентирование может серьёзно увеличить независимость людей с ограниченными возможностями по передвижению. Этого можно достичь, разработав автономных роботов, способных легко адаптироваться к окружению, и методы, доступные для реализации в новом окружении на основе уже имеющейся информации. Это можно сделать, автоматизировав обучение базовому ориентированию на небольшие дистанции с АОП, а потом использовать приобретённые навыки совместно с картами SLAM для создания дорожных карт. Дорожные карты состоят из узлов, соединённых рёбрами, по которым роботы могут надёжным образом передвигаться. В результате вырабатывается политика поведения робота, которая после одного обучения может использоваться в разных окружениях и выдавать дорожные карты, специально приспособленные для конкретного робота.
В трёх недавних работах, "Обучение ориентированию с нуля с АОП", "PRM-RL: осуществление роботизированного ориентирования на дальних расстояниях при помощи комбинации обучения с подкреплением и планирования на основе образцов" и "Ориентирование на дальних расстояниях с PRM-RL", мы изучаем автономных роботов, легко адаптирующихся к новому окружению, комбинируя глубокое ОП с долгосрочным планированием. Мы обучаем локальных агентов-планировщиков выполнению базовых действий, необходимых для ориентирования, и передвижению на короткие расстояния без столкновений с движущимися объектами. Локальные планировщики проводят зашумлённые наблюдения окружающей среды при помощи таких датчиков, как одномерные лидары, выдающие расстояние до препятствия, и выдают линейные и угловые скорости для управления роботом. Мы обучаем локального планировщика в симуляциях при помощи автоматического обучения с подкреплением (АОП), метода, автоматизирующего поиски награды для ОП и архитектуры нейросети. Несмотря на ограниченный радиус действия, 10-15 м, локальные планировщики хорошо адаптируются как к применению в реальных роботах, так и к новым, ранее неизвестным окружениям. Это позволяет использовать их в качестве строительных блоков для ориентирования на больших пространствах. Затем мы строим дорожную карту, граф, где узлами являются отдельные участки, а рёбра соединяют узлы, только если локальные планировщики, хорошо имитирующие реальных роботов при помощи зашумлённых датчиков и управления, могут перемещаться между ними.
Автоматическое обучение с подкреплением (АОП)
В первой нашей работе мы обучаем локального планировщика в статичном окружении небольшого размера. Однако при обучении стандартным глубоким ОП алгоритмом, например, глубоким детерминистским градиентом (DDPG), можно столкнуться с несколькими препятствиями. К примеру, реальной целью локальных планировщиков является достижение заданной цели, в результате чего они получают редкие награды. На практике это требует от исследователей потратить значительное время на пошаговую реализацию алгоритма и ручную подстройку наград. Также исследователям приходится принимать решения по поводу архитектуры нейросетей, не имея чётких успешных рецептов. И, наконец, такие алгоритмы, как DDPG, обучаются нестабильно и часто демонстрируют катастрофическую забываемость.
Для преодоления этих препятствий мы автоматизировали глубокое обучение с подкреплением. АОП – это эволюционная автоматическая обёртка вокруг глубокого ОП, ищущая награды и архитектуру нейросети при помощи крупномасштабной оптимизации гиперпараметров. Работает она в два этапа, поиск награды и поиск архитектуры. Во время поиска награды АОП параллельно обучает популяцию DDPG-агентов на протяжении нескольких поколений, причём у каждого получается своя, немного изменённая функция награды, оптимизированная на истинную задачу локального планировщика: достижение конечной точки пути. В конце фазы поиска награды мы выбираем такую, которая чаще всего приводит агентов к цели. В фазе поиска архитектуры нейросети мы повторяем этот процесс, на этот рас используя выбранную награду и подстраивая слои сети, оптимизируя кумулятивную награду.
АОП с поиском награды и архитектуры нейросети
Однако такой пошаговый процесс делает АОП неэффективным с точки зрения количества образцов. Обучение АОП с 10 поколениями из 100 агентов требует 5 млрд образцов, что эквивалентно 32 годам обучения! Преимущество в том, что после АОП ручной процесс обучения автоматизируется, и у DDPG не возникает катастрофического забывания. Что самое важное, качество итоговых политик оказывается выше – они устойчивы к шуму от датчика, привода и локализации, и хорошо обобщаются к новым окружениям. Наша лучшая политика на 26% успешнее других методов ориентирования на наших испытательных полигонах.
Красный – успехи АОП на коротких расстояниях (до 10 м) в нескольких неизвестных до этого зданиях. Сравнение с DDPG, обученным вручную (тёмно-красный), искусственными полями потенциала (голубой), динамическим окном (синий) и клонированием поведения (зелёный).
Политика локального планировщика АОП хорошо работает с роботами в реальных неструктурированных окружениях
И хотя эти политики способны только на локальное ориентирование, они устойчивы по отношению к движущимся препятствиям и хорошо переносятся на реальных роботов в неструктурированных окружениях. И хотя они были натренированы в симуляциях со статическими объектами, они эффективно справляются и с движущимися. Следующий шаг – скомбинировать АОП-политики с планировкой на основе образцов, чтобы расширить область их работы и научить их ориентироваться на дальних расстояниях.
Ориентирование на дальних расстояниях при помощи PRM-RL
Планировщики, работающие на основе образцов, работают с ориентированием на дальних расстояниях, аппроксимируя движения робота. К примеру, вероятностные дорожные карты (PRM) робот строит, проводя между участками реализуемые пути перехода. В нашей второй работе, выигравшей награду на конференции ICRA 2018, мы комбинируем PRM с подстроенными вручную локальными ОП-планировщиками (без АОП), чтобы обучать роботов локально, а потом адаптировать их к другим окружениям.
Сначала для каждого робота мы обучаем локальную политику планировщика в обобщённой симуляции. Затем мы создаём PRM с учётом этой политики, так называемую PRM-RL, на основе карты того окружения, где он будет использоваться. Ту же карту можно использовать для любого робота, которого мы желаем использовать в здании.
Для создания PRM-RL мы объединяем узлы из образцов, только если локальный ОП-планировщик может надёжно и неоднократно перемещаться между ними. Это делается в симуляции по методу Монте-Карло. Полученная карта подстраивается под возможности и геометрию определённого робота. У карт для роботов с одинаковой геометрией, но разными датчиками и приводами, будет разная связность. Поскольку агент может поворачивать за угол, можно включать и узлы, не находящиеся в прямой видимости. Однако узлы, расположенные рядом со стенами и препятствиями будут включены в карту с меньшей вероятностью из-за шума датчиков. Во время выполнения ОП-агент перемещается по карте от одного участка до другого.
Карта создаётся с тремя симуляциями Монте-Карло на каждую случайно выбранную пару узлов
Самая крупная карта имела размер 288х163 м и содержала почти 700 000 рёбер. 300 работников собирали её 4 дня, проведя 1,1 млрд проверок на столкновения.
Третья работа обеспечивает несколько улучшений оригинального PRM-RL. Во-первых, мы заменяем подстроенный вручную DDPG локальными планировщиками с АОП, что даёт улучшение в ориентировании на больших расстояниях. Во-вторых, добавляются карты одновременной локализации и разметки (SLAM), которые роботы используют во время выполнения в качестве источника для построения дорожных карт. Карты SLAM подвержены шуму, и благодаря этому закрывается «разрыв между симулятором и реальностью», известная в робототехнике проблема, из-за которой агенты, обученные в симуляциях, ведут себя в реальном мире значительно хуже. У нас уровень успеха в симуляции совпадает с уровнем успеха реальных роботов. И, наконец, мы добавили распределённые карты зданий, благодаря чему можем создавать очень большие карты, содержащие до 700 000 узлов.
Этот метод мы оценили при помощи нашего АОП-агента, создававшего карты на основе чертежей зданий, превосходящих по площади тренировочное окружение в 200 раз, включая в них только рёбра, успешное прохождение которых осуществлялось в 90% случаев за 20 попыток. Мы сравнили PRM-RL с различными методами на дистанциях до 100 м, серьёзно превышавших дальность действия локального планировщика. PRM-RL достигала успеха в 2-3 раза чаще обычных методов благодаря правильному соединению узлов, подходящему под возможности робота.
Процент успеха в перемещении на 100 м в разных зданиях. Синий – локальный АОП-планировщик, первая работа; красный – оригинальный PRM; жёлтый – искусственные поля потенциала; зелёный – вторая работа; красный – третья работа, PRM с АОП.
Мы испытывали PRM-RL на множестве реальных роботов в множестве зданий. Внизу показан один из наборов тестов; робот надёжно двигается почти везде, кроме самых беспорядочных мест и участков, выходящих за пределы карты SLAM.
Заключение
Машинное ориентирование может серьёзно увеличить независимость людей с ограниченными возможностями по передвижению. Этого можно достичь, разработав автономных роботов, способных легко адаптироваться к окружению, и методы, доступные для реализации в новом окружении на основе уже имеющейся информации. Это можно сделать, автоматизировав обучение базовому ориентированию на небольшие дистанции с АОП, а потом использовать приобретённые навыки совместно с картами SLAM для создания дорожных карт. Дорожные карты состоят из узлов, соединённых рёбрами, по которым роботы могут надёжным образом передвигаться. В результате вырабатывается политика поведения робота, которая после одного обучения может использоваться в разных окружениях и выдавать дорожные карты, специально приспособленные для конкретного робота.