
Предисловие
Данная статья не совсем похожа на те, что публиковались ранее про сканирования интернетов определенных стран, потому как я не преследовал целей массового сканирования конкретного сегмента интернета на открытые порты и наличие самых популярных уязвимостей ввиду того, что это противоречит законодательству.
У меня был скорее немного другой интерес — попробовать определить все актуальные сайты в доменной зоне BY разными методиками, определить стек используемых технологий, через сервисы вроде Shodan, VirusTotal и др. выполнить пассивную разведку по IP и открытым портам ну и в довесок собрать немного другой полезной информации для формирования некой общей статистики по уровню защищенности относительно сайтов и пользователей.
Вводная и наш инструментарий
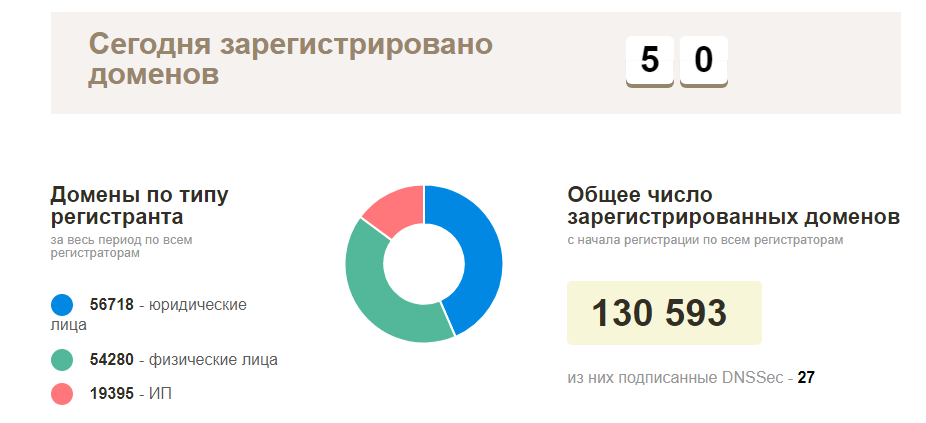
План в самом начале был простой — обратиться к местному регистратору за списком актуальных зарегистрированных доменов, далее все проверить на доступность и начинать изучать функционирующие сайты. В реальности всё оказалось куда сложнее — такого рода информацию естественно, никто предоставлять не захотел, за исключением официальной странички статистики актуальных зарегистрированных доменных имен в зоне BY (порядка 130 тысяч доменов). Если такой информации нет, значит придется собирать самостоятельно.
По инструментарию на самом деле все довольно просто — смотрим в сторону open source, что-то всегда можно дописать, допилить какие-то минимальные костыли. Из наиболее популярного, использовались следующие тулзы:
- WhatWeb
- curl
- dig
- wafw00f
- API сторонних сервисов (VirusTotal, Google SafeBrwosing, Shodan, Vulners)
Начало активностей: Отправная точка
В качестве вводной как я уже говорил — в идеале подходили доменные имена, но где их взять? Стартовать нужно с чего-то попроще, в данном случае нам подойдут IP адреса, но опять же — при реверс лукапах не всегда можно словить все домены, а при сборе хостнеймов — не всегда корректный домен. На данном этапе я стал думать о возможных сценариях сбора такого рода информации, опять же — во внимание еще брался тот факт, что наш бюджет это 5$ на аренду VPS, остальное все должно быть бесплатным.
Наши потенциальные источники информации:
- IP адреса (ip2location сайт)
- Поиск доменов по второй части email адреса (но где их взять? Разберемся чуть ниже)
- Некоторые регистраторы/хостинг провайдеры могут предоставить нам такую информацию в форме поддоменов
- Сабдомены и их последующий реверс (тут могут помочь Sublist3r и Aquatone)
- Брутфорс и ручной ввод (долго, муторно, но можно, хотя этот вариант я не использовал)
Забегу немного вперед и скажу, что с таким подходом у меня получилось собрать около 50 тысяч уникальных доменов и сайтов соответственно (не все успел обработать). Если бы и дальше продолжал активно собирать информацию, то наверняка за менее чем месяц работы мой конвейер осилил бы всю базу, либо большую ее часть.
Переходим к делу
В предыдущих статьях информацию об IP адресах брали с IP2LOCATION сайта, я на эти статьи по понятной причине не натыкался (т.к. все действия происходили намного раньше), но тоже пришел к данному ресурсу. Правда, в моем случае подход отличался — я решил не забирать к себе локально базу и не извлекать информацию из CSV, а решил мониторить изменения непосредственно на сайте, на постоянной основе и в качестве основной базы откуда все последующие скрипты будут брать цели — сделал таблицу с IP адресами в разных форматах: CIDR, список «от» и «до», пометка страны (на всякий случай), AS Number, AS Description.
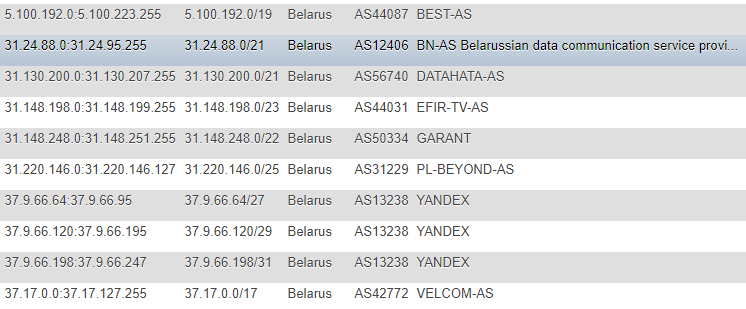
Формат не самый оптимальный, но для демки и разовой акции меня вполне устраивал, а дабы на постоянной основе не обращаться за вспомогательной информацией вроде ASN, я решил ее дополнительно логировать у себя. Для получения этой информации я обращался к сервису IpToASN, у них есть удобное API (с ограничениями), которое по сути надо просто к себе интегрировать.
function ipList() {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "https://lite.ip2location.com/belarus-ip-address-ranges");
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ipList = curl_exec($ch);
curl_close ($ch);
preg_match_all("/(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\<\/td\>\s+\<td\>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/", $ipList, $matches);
return $matches[0];
}
function iprange2cidr($ipStart, $ipEnd){
if (is_string($ipStart) || is_string($ipEnd)){
$start = ip2long($ipStart);
$end = ip2long($ipEnd);
}
else{
$start = $ipStart;
$end = $ipEnd;
}
$result = array();
while($end >= $start){
$maxSize = 32;
while ($maxSize > 0){
$mask = hexdec(iMask($maxSize - 1));
$maskBase = $start & $mask;
if($maskBase != $start) break;
$maxSize--;
}
$x = log($end - $start + 1)/log(2);
$maxDiff = floor(32 - floor($x));
if($maxSize < $maxDiff){
$maxSize = $maxDiff;
}
$ip = long2ip($start);
array_push($result, "$ip/$maxSize");
$start += pow(2, (32-$maxSize));
}
return $result;
}
$getIpList = ipList();
foreach($getIpList as $item) {
$cidr = iprange2cidr($ip[0], $ip[1]);
}
После того, как мы разобрались с IP, нам нужно прогнать всю нашу базу через сервисы reverse lookup, увы без каких либо ограничений — это невозможно, разве что, за деньги.
Из сервисов которые для этого замечательно подходят и удобны в использовании я хочу отметить целых два:
- VirusTotal — лимит но частоте обращений с одного API ключа
- Hackertarget.com (их API) — лимит по количеству обращений с одного IP
По обходу лимитов получились следующие варианты:
- В первом случае один из сценариев это выдерживать таймауты в 15 секунд, итого у нас будет 4 обращения в минуту, что сильно может сказаться на нашей скорости и в данной ситуации будет кстати использование 2-3 таких ключей, при этом я бы рекомендовал так же прибегнуть к proxy и менять user-agent.
- Во втором случае, я писал скрипт для автоматического парсинга базы proxy на основании публично доступной информации, их валидации и последующего использования (но позже от этого варианта отошел т.к. хватало по сути и VirusTotal)
Идем далее и плавно переходим к email адресам. Они так же могут быть источником полезной информации, но где же их собирать? Решение не пришлось искать долго, т.к. в нашем сегменте персональных сайтов пользователи держат мало, а в основной массе это организации — то нам подойдут профильные сайты вроде каталогов интернет магазинов, форумов, условных маркетплейсов.
К примеру беглый осмотр одной из таких вот площадок показал, что очень много пользователей добавляют свои email прямо к себе в публичный профиль и соответственно — это дело можно аккуратно спарсить для последующего использования.
#!/usr/bin/env python3
import sys, threading, time, os, urllib, re, requests, pymysql
from html.parser import HTMLParser
from urllib import request
from bs4 import BeautifulSoup
# HEADERS CONFIG
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11.9; rv:42.0) Gecko/20200202 Firefox/41.0'
}
file = open('dat.html', 'w')
def parseMails(uid):
page = 'https://profile.onliner.by/user/'+str(uid)+''
cookie = {'onl_session': 'YOUR_SESSION_COOOKIE_HERE'}
r = requests.get(page, headers = headers, cookies = cookie)
data = BeautifulSoup(r.text)
userinfo = data.find_all('dl', {'class': 'uprofile-info'})
find_email = []
for item in userinfo:
find_email += str(item.find('a'))
get_mail = ''.join(find_email)
detect_email = re.compile(".+?>(.+@.+?)</a>").search(get_mail)
file.write("<li>('"+detect_email.group(1)+"'),</li>")
for uid in range(1, 10000):
t = threading.Thread(target=parseMails, args=(uid,))
t.start()
time.sleep(0.3)
В подробности парсинга каждой из площадок вдаваться не буду, где-то удобнее угадывать ID пользователя методом перебора, где-то проще распарсить карту сайта, получить из нее информацию о страницах компаний и далее уже собирать адреса из них. После сбора адресов, нам остается выполнить несколько простых операций сразу отсортировав по доменной зоне, сохранив для себя «хвостики» и прогнать для исключения дубликатов по имеющейся базе.
На этом этапе я считаю, что с формированием скоупа мы можем заканчивать и переходить к разведке. Разведка как мы уже знаем, может быть двух видов — активной и пассивной, в нашем случае — наиболее актуальным будет пассивный подход. Но опять же, просто обращение к сайту на 80 или 443 порт без вредоносной нагрузки и эксплуатации уязвимостей — вполне себе легитимное действие. Наш интерес — это ответы сервера на единственный запрос, в некоторых случаях запросов может быть два (перенаправление с http на https), в более редких — целых три (когда используется www).
Разведка
Оперируя такой информацией как домен, мы можем собрать следующие данные:
- Записи DNS (NS, MX, TXT)
- Заголовки ответов
- Определить используемый стек технологий
- Понять по какому протоколу работает сайт
- Попробовать определить открытые порты (по базе Shodan / Censys) без прямого сканирования
- Попробовать определить уязвимости исходя из корреляции информации из Shodan / Censys с базой Vulners
- Находится ли он в базе вредоносных Google Safe Browsing
- По домену собрать email адреса, а так же сопоставить уже найденные и проверить по Have I Been Pwned, в дополнение — привязку к социальным сетям
- Домен — это в некоторых случаях не только лицо компании, но и продукт ее деятельности, email адреса для регистрации на сервисах и т.п., соответственно — можно поискать информацию которая с ними ассоциируется на ресурсах вроде GitHub, Pastebin, Google Dorks (Google CSE)
Всегда можно пойти напролом и воспользоваться как вариант masscan или nmap, zmap, настроив их предварительно через Tor с запуском в рандомное время или даже с нескольких инстансов, но у нас другие цели и из названия следует, что таки прямых сканирований я не делал.
Собираем DNS записи, проверяем возможность амплификации запросов и ошибки конфигурации вроде AXFR:
dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'Пример сбора записей MX (см. в NS, просто заменить 'ns' на 'mx'
$digNs = trim(shell_exec("dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'"));
$ns = explode("\n", $digNs);
foreach($ns as $target) {
$axfr = trim(shell_exec("dig -t axfr $domain @$target | awk '{print $1}' | sed 's/\.$//g'"));
$axfr = preg_replace("/\;/", "", $axfr);
if(!empty(trim($axfr))) {
$axfr = preg_replace("/\;/", "", $axfr);
$res = json_encode(explode("\n", trim($axfr)));dig +short test.openresolver.com TXT @$dnsВ моем случае NS сервера брались из БД, по тому на конце переменная, туда можно подставить просто любой сервер по сути. По поводу корректности результатов данного сервиса — не могу быть уверен, что там прям на 100% все ровно работает и результаты всегда валидны, но, надеюсь, что большинство результатов — реальны.
Если нам для каких либо целей нужно сохранять у себя полноценный конечный URL к сайту, для этого я воспользовался cURL:
curl -I -L $target | awk '/Location/{print $2}'Он сам перейдет по всем редиректом и выведет финальный, т.е. актуальный URL сайта. В моем случае это было крайне полезно при последующем использовании такой тулы как WhatWeb.
Для чего нам использовать его? Дабы определить используемую OS, веб-сервер, CMS сайта, какие-то заголовки, дополнительные модули вроде JS / HTML библиотек/фреймворков, а так же тайтл сайта по которому впоследствии можно попробовать отфильтровать к тому же и по сфере деятельности.
Очень удобным вариантом в данном случае будет экспорт результатов работы тула в формате XML для последующего разбора и импорта в БД если есть цель это все в последствии обрабатывать.
whatweb --no-errors https://www.mywebsite.com --log-xml=results.xmlДля себя я на выходе делал по итогу JSON и его уже складывал в БД.
К слову о заголовках, можно почти тоже самое выполнять и обычным cURL выполняя запрос вида:
curl -I https://www.mywebsite.comВ заголовках отлавливать самостоятельно информацию о CMS и веб-серверах с помощью регулярных выражений к примеру.
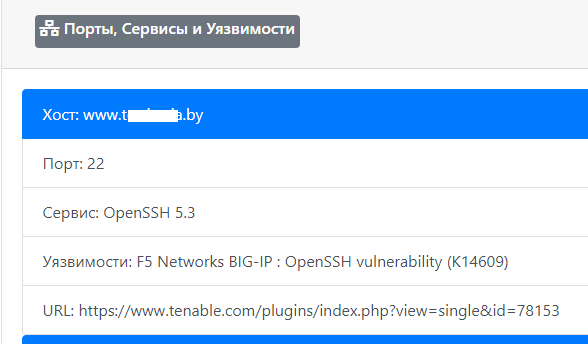
Кроме стека из полезного, мы так же можем выделить возможность сбора информации об открытых портах с помощью Shodan и далее уже используя полученные данные — выполнить проверку по базе Vulners с помощью их API (ссылки на сервисы приведены в шапке). Конечно же, с точностью при таком раскладе могут быть проблемы, все же это не прямое сканирование с ручной валидацией, а банальное «жонглирование» данными из сторонних источников, но лучше хотя бы так чем совсем ничего.
function shodanHost($host) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "https://api.shodan.io/shodan/host/".$host."?key=<YOUR_API_KEY>");
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$shodanResponse = curl_exec($ch);
curl_close ($ch);
return json_decode($shodanResponse);
}
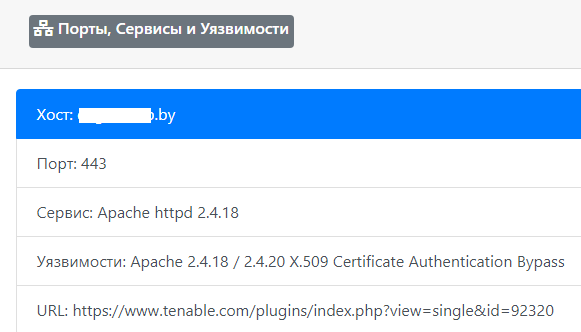
Да, раз уж заговорили за API, то у Vulners есть ограничения и наиболее оптимальным решением будет — использование их скрипта на Python, там без кручений-верчений все будет отлично работать, в случае с PHP столкнулся с некоторыми небольшими трудностями (опять же — доп. таймауты спасли ситуацию).
Одним из последних тестов — будем изучать информацию по используемым firewall с помощью такого скрипта как «wafw00f». При тестировании этой замечательной тулы заметил одну интересность, не всегда с первого раза получалось определить тип используемого файрвола.
Чтобы посмотреть какие типы файрволов потенциально может определить wafw00f можно ввести следующую команду:
wafw00f -lДля определения типа файрвола — wafw00f анализирует заголовки ответа сервера после отправки стандартного запроса к сайту, в случае если данной попытки не достаточно, он формирует дополнительный простой тестовый запрос ну и если этого в очередной раз не достаточно — то третья методика оперирует данными после первых двух попыток.
Т.к. нам для статистики по сути весь ответ не нужен, то все лишнее мы обрезаем регулярным выражением и оставляем лишь название firewall:
/is\sbehind\sa\s(.+?)\n/Ну и как я ранее писал — кроме информации о домене и сайте, так же в пассивном режиме актуализировалась информация о email адресах и социальных сетях:

Самым простым было разобраться с валидацией адресов в Twitter (2 способа), с Facebook (1 способ) в этом плане оказалось немного сложнее из-за чуть более замысловатой системы генерации сессии реального пользователя.
Перейдем к сухой статистике
Статистика по DNS
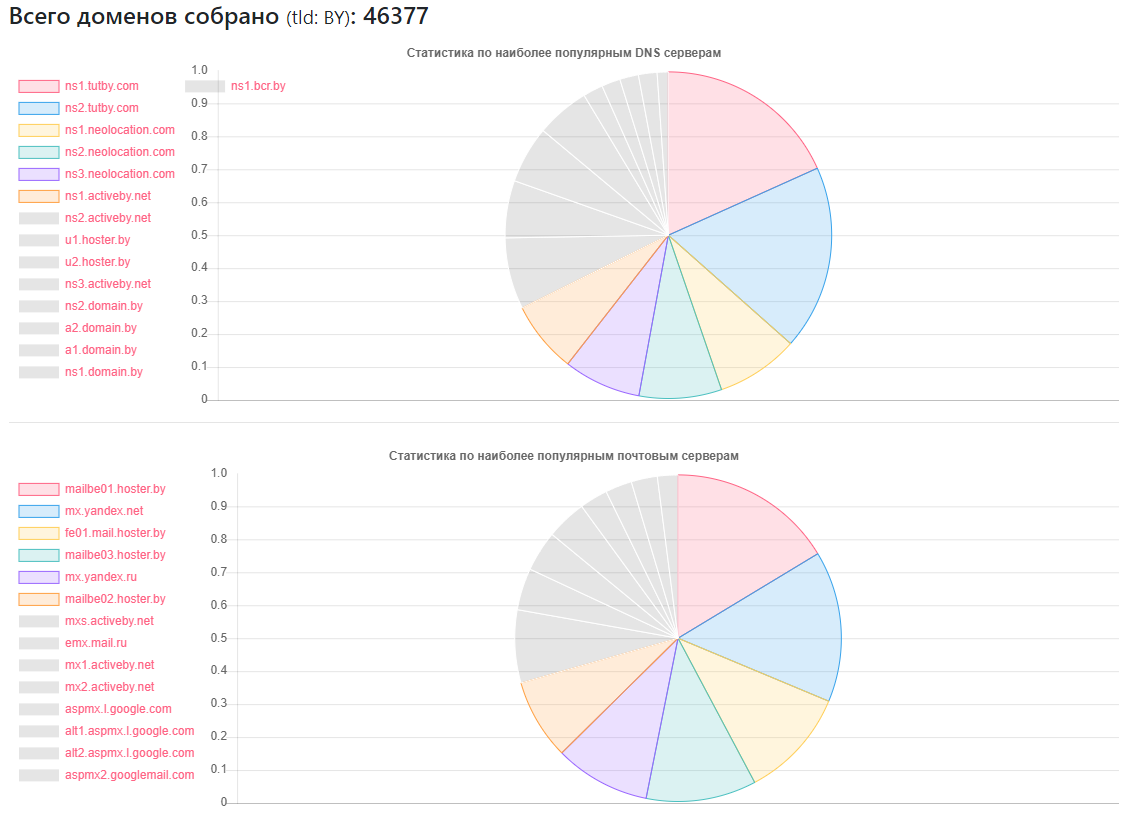
Провайдер — сколько сайтов
ns1.tutby.com: 10899
ns2.tutby.com: 10899
ns1.neolocation.com: 4877
ns2.neolocation.com: 4873
ns3.neolocation.com: 4572
ns1.activeby.net: 4231
ns2.activeby.net: 4229
u1.hoster.by: 3382
u2.hoster.by: 3378
Уникальных DNS обнаружено: 2462
Уникальных MX (почтовых) серверов: 9175 (кроме популярных сервисов, есть достаточное количество администраторов которые используют собственные почтовые службы)
Подвержены DNS Zone Transfer: 1011
Подвержены DNS Amplification: 531
Немного любителей CloudFlare: 375 (основываясь на используемых записях NS)
Статистика по CMS
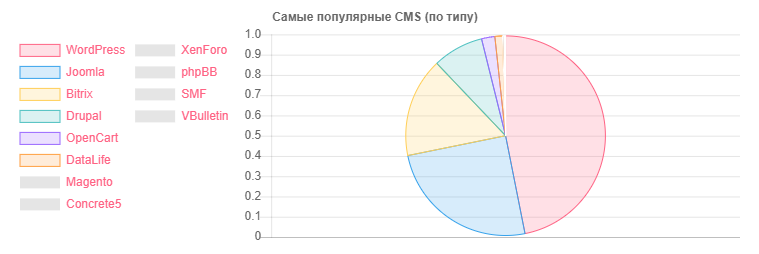
CMS — Количество
WordPress: 5118
Joomla: 2722
Bitrix: 1757
Drupal: 898
OpenCart: 235
DataLife: 133
Magento: 32
- Потенциально уязвимых установок WordPress: 2977
- Потенциально уязвимых установок Joomla: 212
- При помощи сервиса Google SafeBrowsing получилось выявить потенциально опасных или зараженных сайтов: около 10.000 (в разное время, кто-то фиксил, кого-то видимо ломали, статистика не совсем объективная)
- Про HTTP и HTTPS — последним пользуется менее половины сайтов от найденного объема, но с учетом того, что моя база не полная, а являешься лишь 40% от всего количества, то вполне возможно, что большая часть сайтов из второй половины могут и общаются по HTTPS.
Статистика по Firewall:

Firewall — Количество
ModSecurity: 4354
IBM Web App Security: 126
Better WP Security: 110
CloudFlare: 104
Imperva SecureSphere: 45
Juniper WebApp Secure: 45
Статистика по веб серверам
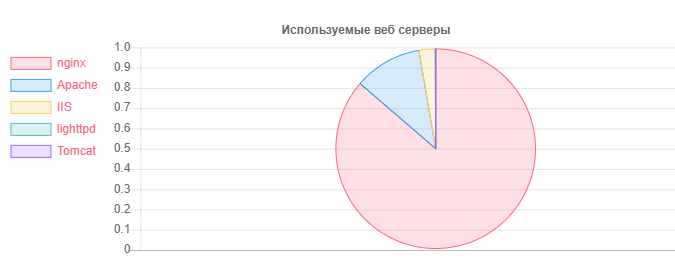
Веб-сервер — Количество
Nginx: 31752
Apache: 4042
IIS: 959
Устаревших и потенциально уязвимых установок Nginx: 20966
Устаревших и потенциально уязвимых установок Apache: 995
Несмотря на то, что лидером по к примеру доменам и хостингу в целом у нас является hoster.by, отличится смогли и Открытый контакт, но правда по количеству сайтов на одном IP:
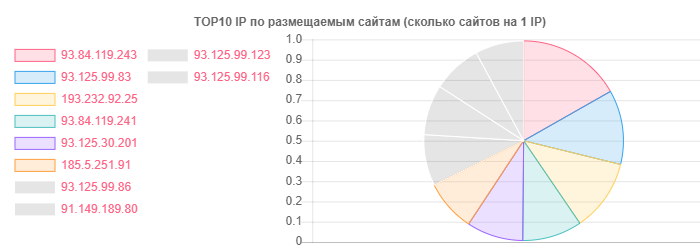
IP — Сайтов
93.84.119.243: 556
93.125.99.83: 399
193.232.92.25: 386
По email детальную статистику совсем уж решил не дергать, по доменной зоне не сортировать, скорее интерес был посмотреть расположение пользователей к конкретным вендорам:
- На сервисе TUT.BY: 38282
- На сервисе Yandex(by|ru): 28127
- На сервисе Gmail: 33452
- Привязаны к Facebook: 866
- Привязаны к Twitter: 652
- Фигурировали в утечках по информации HIBP: 7844
- Пассивная разведка помогла выявить более 13 тысяч email адресов
Как видим, в целом картинка довольно позитивная, особенно порадовало активное использование nginx со стороны хостинг провайдеров. Возможно, это в большей степени связано с популярным среди рядовых пользователей — shared типом хостинга.
Из того, что не очень понравилось — есть достаточное количество хостинг провайдеров средней руки, у которых были замечены ошибки вроде AXFR, использовались устаревшие версии SSH и Apache ну и некоторые другие мелкие проблемки. Тут конечно же, больше света на ситуацию смог бы пролить ресерч с активной фазой, но на данный момент в силу нашего законодательства это как мне кажется — невозможно, а записываться ради таких дел в ряды вредителей не особо и хотелось бы.
Картина по email в целом довольно радужная, если это можно так назвать. Ах да, там где указан провайдер TUT.BY — это имелось ввиду использование домена, т.к. данный сервис работает на базе Яндекса.
Заключение
В качестве заключения могу сказать одно — даже с имеющимися результатами, можно быстро понять, что существует большой объем работ для специалистов которые занимаются очисткой сайтов от вирусов, настройкой WAF и конфигурацией/допиливанием разных CMS.
Ну, а если серьезно — то как и в предыдущих двух статьях мы видим, что проблемы существуют абсолютно на разных уровнях в абсолютно всех сегментах сети интернет и странах, и всплывают некоторые из них даже при отдаленном изучении вопроса, без использования offensive методик, т.е. оперируя публично доступной информацией для сбора которой особых навыков и не требуется.
Комментарии (18)


remzalp
30.03.2019 11:21https://www.ripe.net/manage-ips-and-asns/db/support/querying-the-ripe-database
Мне кажется, что по Европейскому региону есть замечательная БД по автономным системам с довольно таки свободным доступом.
Почему не использовали?sm0k3net Автор
30.03.2019 23:02До нее не добрался, но обязательно изучу, спасибо за информацию.
По той с которой система работает на данный момент — с большего все ок, хотя переодически пролетали то ли Литовские, то ли Польские IP.remzalp
01.04.2019 06:37Ну как бы это и есть первоисточник, с которого остальные перераздают данные разной степени актуальности :))
Я даже дополню картинкой — кто за что отвечает во всём мире, с https://www.iana.org/numbers


grey_rat
30.03.2019 12:17Что тут сканировать, вся страна за NAT, нет даже внутреннего пиринга по стране из-за того же NAT. Весь трафик уходит на Россию.

SobakaRU
31.03.2019 00:37Вы какую-то феерическую ерунду написали: все три ваших утверждения не имеют ничего общего с действительностью.
grey_rat
31.03.2019 11:01Покажите ссылки на действительность. Только ютуб не так давно через байфлаевский CDN сделали, а так вообще ничего небыло.
SobakaRU
31.03.2019 12:09Покажите ссылки на действительность.
Странная ситуация, когда можно ляпнуть любой бред и требовать его опровержений ссылками.
- Все ваши измышления по поводу NAT'а за гранью моего понимания (подозреваю, что вы просто плохо представляете что это такое). Типичная цена реального IP-адреса у провайдеров в РБ от 1.5 до 5 рублей в месяц (0.6-2€). Ажиотажа и дефицита нет иначе цены были бы не такие смешные.
- Внутренний пиринг в РБ живет и здравствует как минимум с начала 2000-х (или еще с более раннего времени). Да, есть ограничения на прямые соединения между операторами, но точка обмена трафиком присутствует и, по понятным причинам, вполне себе востребована.
- Тезис про YouTube притянут за уши: знаю сравнительно небольшого провайдера в Минске, который уж несколько лет назад, как ставил у себя в сети гугловый GGC. А уж Белтелекому с их объёмами трафика совсем без этого никуда.
- По поводу «всего трафика на Россию» — тоже, конечно, неправда. Вот картинка с сайта того же НЦОТа где нарисована магистральная оптика и видны интерконнекты с соседями:
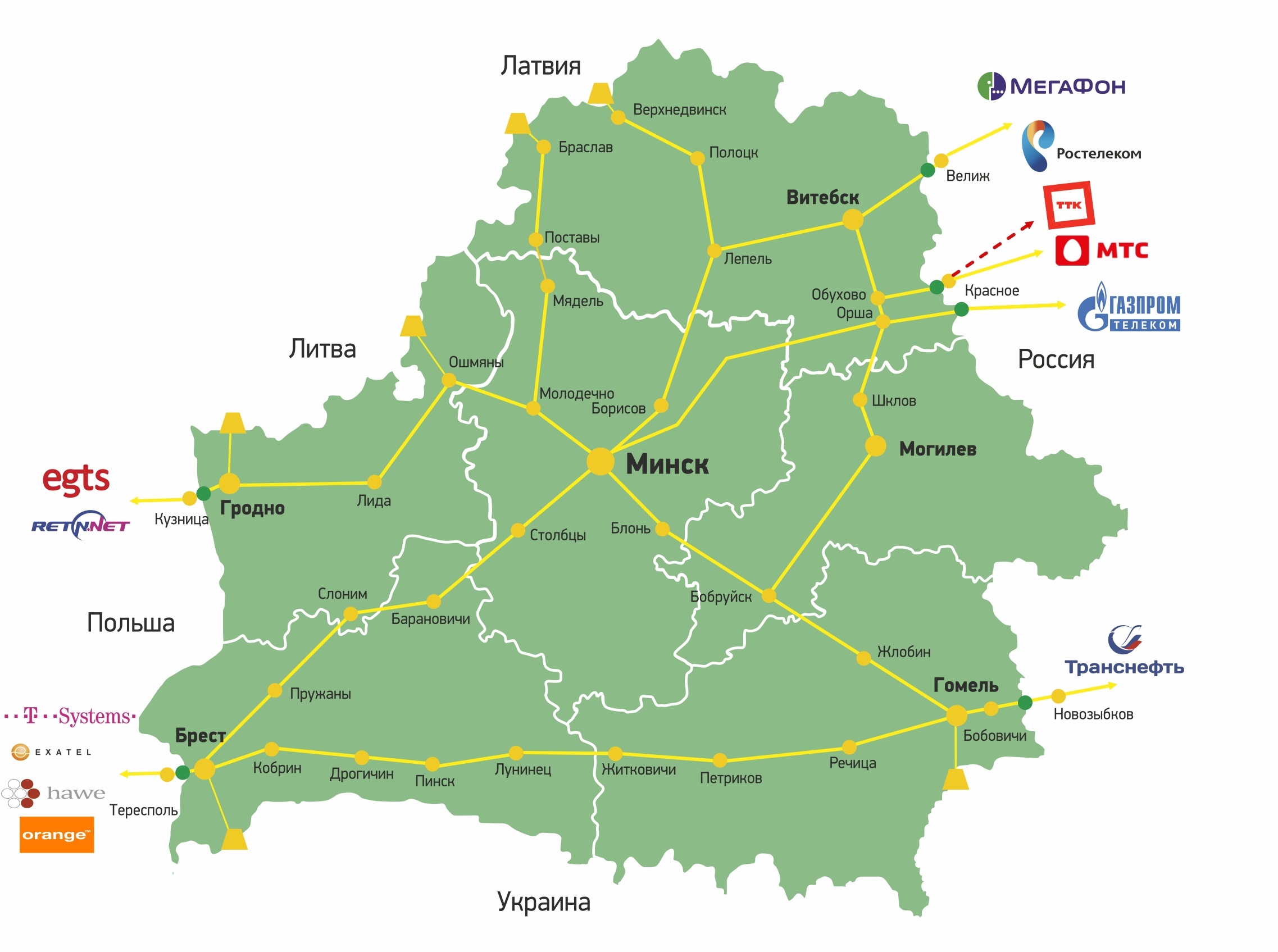 Конечно, в числах в сторону РФ трафика бежит побольше, но про «весь» я бы не говорил. Опять же, знаю живые примеры операторов в Минске у которых как минимум часть аплинков уходят в Польшу.
Конечно, в числах в сторону РФ трафика бежит побольше, но про «весь» я бы не говорил. Опять же, знаю живые примеры операторов в Минске у которых как минимум часть аплинков уходят в Польшу.
Aelliari
31.03.2019 16:54Внезапно, но некоторые ISP в РБ не дают возможность получить белый IP даже за деньги для физических лиц >.<, а у некоторых можно получить белый динамический бесплатно (или так было до недавнего времени), а при определённых настройках — с достаточно большим периодом смены.
А пиринг действительно есть и есть давно, хотя вероятно до сих пор найдутся странные провы у которых доступа к нему нет.
grey_rat
01.04.2019 20:23Все ваши измышления по поводу NAT'а за гранью моего понимания (подозреваю, что вы просто плохо представляете что это такое). Типичная цена реального IP-адреса у провайдеров в РБ от 1.5 до 5 рублей в месяц (0.6-2€). Ажиотажа и дефицита нет иначе цены были бы не такие смешные.
При чём здесь статический IP? Речь шла про белую динамику и возможность обмена по внутренним IP. У Белтелекома нет возможности обмениваться данными даже внутри своей сети где IP вида 100....., не говоря уже про связь с другими провайдерами. Физически провайдеры в пиринге, а фактически, абонент любого провайдера (кроме МТС) качает торрент только с пиров России и Украины, так как практически все пиры из Беларуси не доступны. Пиринг в Беларуси — это только доступ к сайтам.
Тезис про YouTube притянут за уши
Про ютуб digital.report/google-monopoly
Вот картинка с сайта того же НЦОТа где нарисована магистральная оптика и видны интерконнекты с соседями
на этой картинке не нарисована пропускная способность этих кабелей. И пропускная способность магистральных кабелей — это не значит, что по ним бежит беларуский трафик. 90% в Россию и 10% в другую сторону — это фактически весь трафик Беларуси. При этом внутреннего трафика за исключением тутбая, онлайнера и ютуба — практически нет.

mikechips
31.03.2019 03:49Имел дело с белорусской юрисдикцией. Если у тебя магазин или похожий коммерческий проект — сервер или шаред брать строго отечественный, причем обычно с дырами в безопасности, и при этом чувствительные данные хранить в облаке вроде AWS — стыд и позор. Пакет Яровой на фоне этого еще басни.
После такого опыта более чем уверен, что при тщательном сканировании это все хозяйство несложно поломать. Я понимаю, что цели у автора другие — просто пытаюсь пояснить, откуда столько дыр.
grey_rat
01.04.2019 20:21.
SobakaRU
01.04.2019 21:10У вас какая-то личная драма по поводу торрентов и вы ее экстраполируете зачем-то на всё вокруг: «пиринга нет», «страна за NATом» и т. д.
Пиринг по итогу есть и позволяет провайдерам экономить деньги на внутреннем трафике (который невелик, да). Юзеры за NAT'ом, потому что так удобно провайдерам и это общепринятая практика в условиях условного дефицита пула ipv4. При этом подавляющему большинству пользователей плевать NAT у них или нет, а 99% желающих могут легко получить белый IP за копейки, если понимают зачем он им, собственно, нужен. Если вы думаете, что это специфика РБ и все поголовно западные провайдеры раздают белую динамику, то я вас разочарую. В этом плане нас спасет только ipv6 и он вполне себе внедряется потихоньку.
При чём здесь статический IP? Речь шла про белую динамику и возможность обмена по внутренним IP.
При том, что если у вас белый IP на «Байфлае», а у меня белый IP на «Деловой сети», то мы с вам прекрасно можем обмениваться всем, чем угодно. И, внезапно, еще и через пиринг.
Что касается прямого взаимодействия между клиентами, которые сидят за NAT'ом, то с точки зрения абстрактного провайдера было бы очень странно это позволять. Провайдеры, в массе своей, существуют с целью зарабатывания денег, а как внятно тарифицировать внутренний обмен трафиком мне не очень понятно. Мало того, возникает еще куча геморроя в лице мамкиных хакеров и всякого мутного контента типа порнухи и вареза. И сказать, в случае жалоб, «мы ничего не знаем — это из интерентов» не получится.
Эта история про зарабатывание денег касается, кстати, и БТКшного GGC. БТК ставит у себя кэш не для того, чтоб сэкономить деньги куче коммерческих провайдеров, которые будут рады сосать GGC бесплатно через пиринг. БТК его ставит чтоб сэкономить себе родимому внешний канал. Это нормально. Плач Ярославны по поводу «неконкуретного поведения» я не очень разделяю. Коммерческие провайдеры должны не плакать, а консолидироваться и аргументировать гуглу почему они тоже хотят себе GGC.grey_rat
02.04.2019 10:33Разница в том, что у других существуют какие-либо свои внутренние ресурсы, в отличие от РБ, которая изначально выбрала политику полностью зарубежного контента и борьбы с беларуским p2p. Кроме тутбая и онлайнера в стране ничего и нет. Кроме Белтелекома у других провайдеров внутренний файлообмен возможен по внутрилокальным IP. Почти всегда у клиента стоит роутер через который осуществляется выход в интернет.
Провайдеры, в массе своей, существуют с целью зарабатывания денег, а как внятно тарифицировать внутренний обмен трафиком мне не очень понятно.
С незапамятных времён, ещё когда существовала помегабайтная оплата, всё было тарифицировано, настроено и работало. Сейчас многие провайдеры просто делают скорость по РБ без ограничения.
В этом плане нас спасет только ipv6 и он вполне себе внедряется потихоньку.
всё как было так и остаётся, никакого развития нет www.google.com/intl/en/ipv6/statistics.html#tab=per-country-ipv6-adoption теже 0,03% были 5-7 лет назад.
а 99% желающих могут легко получить белый IP за копейки
как минимум Велком не даёт статику физ.лицам в Ethernet сети. А на байфлае он стоит не копейки.
pansa
«такого рода информацию естественно, никто предоставлять не захотел»
Вот это как раз *не*естественно. По многим зонам списки доменов можно получить более-менее легко. И не только ccTLD, но и большинство gTLD. Но вот .by, .ua и еще несколько менее крупных зон достать не удаётся. Причем, с .by посылают чуть ли не к местным чекистам — как их там по батюшке, не знаю (хех, какой милый каламбурчик!).