
Систему Shenango планируют использовать в дата-центрах.

/ фото Marco Verch CC BY
По данным одного из провайдеров, дата-центры используют всего 20–40% доступных вычислительных мощностей. При высоких нагрузках этот показатель может достигать 60%. Подобное распределение ресурсов ведет к появлению так называемых «зомби-серверов». Это машины, которые большую часть времени простаивают, впустую расходуя электроэнергию. Сегодня 30% серверов в мире стоят без работы, потребляя электричество на $30 млрд в год.
Бороться с неэффективным расходованием вычислительных ресурсов решили в MIT.
Команда инженеров разработала систему балансировки нагрузки на процессоры под названием Shenango. Её цель — мониторить состояние буфера задач и перераспределять «застрявшие» процессы (которые не могут получить процессорное время) на свободные машины.
Как работает Shenango
Shenango представляет собой Linux-библиотеку на языке C с байндингами Rust и C++. Код проекта и тестовые приложения опубликованы в репозитории на GitHub.
Основу решения составляет алгоритм IOKernel, который запускается на выделенном ядре мультипроцессорной системы. Он управляет запросами к CPU с помощью фреймворка DPDK, который позволяет приложениям напрямую взаимодействовать с сетевыми устройствами.
IOKernel решает, каким ядрам передать конкретную задачу. Алгоритм также решает, сколько ядер понадобится. Для каждого процесса определяются основные ядра (guaranteed) и дополнительные (burstable) — вторые запускаются в случае резкого увеличения числа запросов к CPU.
Очередь запросов IOKernel организована в виде кольцевого буфера. Каждые пять микросекунд алгоритм проверяет, все ли задачи, назначенные ядру, выполнены. Для этого он сравнивает текущее местоположение «головы» буфера с предыдущей позицией его «хвоста». Если оказывается, что хвост уже был в очереди на момент предыдущей проверки, система отмечает перегрузку буфера и выделяет под процесс дополнительное ядро.
При распределении нагрузки приоритет отдаётся ядрам, на которых такой же процесс выполнялся раньше и частично остался в кэш-памяти, или любым бездействующим ядрам.
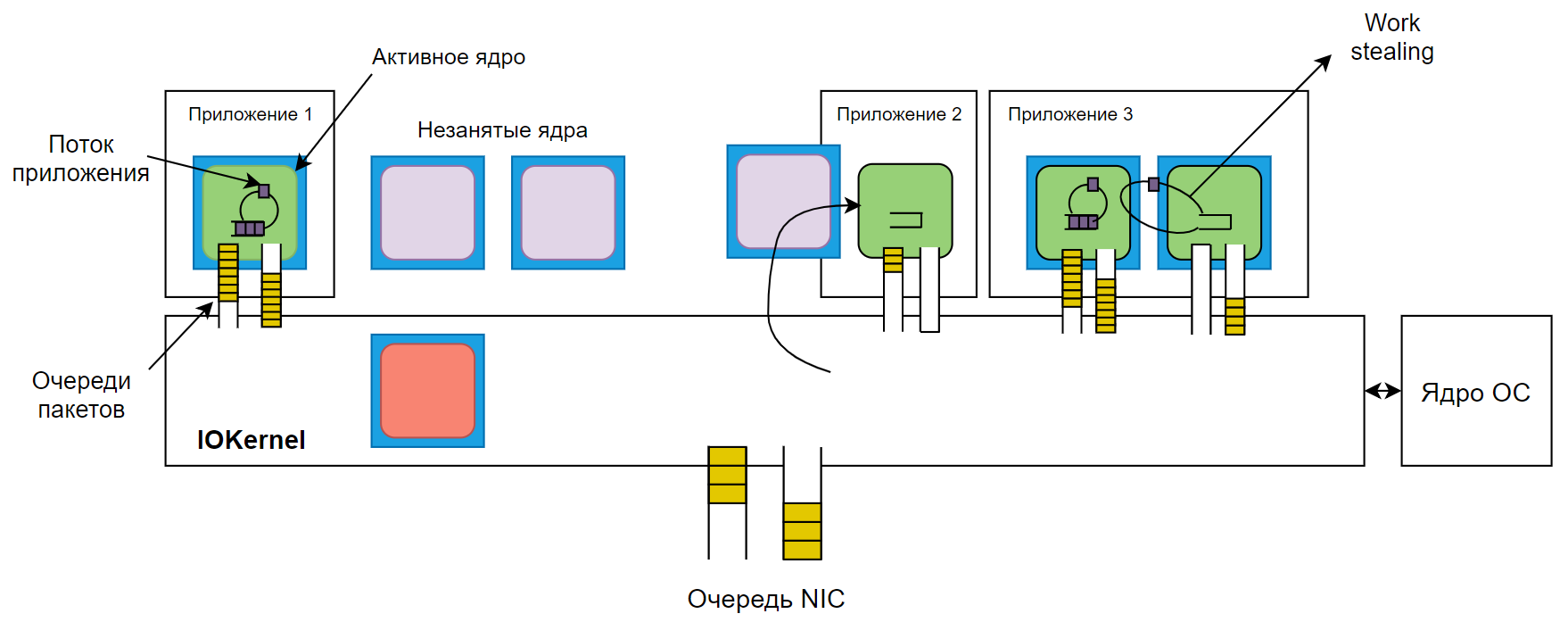
Shenango дополнительно использует подход work stealing. Ядра, выделенные для работы одного приложения, следят за количеством задач друг у друга. Если одно ядро заканчивает свой список заданий раньше остальных, то оно «снимает» часть нагрузки с соседей.
Достоинства и недостатки
По словам инженеров из MIT, Shenango способен обрабатывать пять миллионов запросов за секунду и поддерживать среднее время реакции в 37 микросекунд. Специалисты утверждают, что в некоторых случаях технология способна повысить коэффициент использования процессоров в дата-центрах до 100%. В результате операторы ЦОД смогут экономить на покупке и обслуживании серверов.
Потенциал решения отмечают и специалисты из других университетов. По мнению профессора из корейского института, система из MIT поможет сократить задержки в работе веб-сервисов. Например, она пригодится в работе онлайн-магазинов. В дни распродаж даже секундная задержка загрузки страницы приводит к снижению числа просмотров сайта на 11%. Оперативное распределение нагрузки поможет обслужить больше клиентов.
У технологии пока есть недостатки — она не поддерживает многопроцессорные NUMA-системы, в которых чипы подключены к разным модулям памяти и не «общаются» между собой. В этом случае IOKernel может регулировать работу отдельной группы процессоров, но не все чипы сервера.

/ фото Tim Reckmann CC BY
Аналогичные технологии
Среди других систем балансировки нагрузки на процессоры можно выделить Arachne. Она рассчитывает, сколько ядер понадобится приложению в момент его запуска, и распределяет процессы в соответствии с этим показателем. По оценкам авторов, максимальная задержка работы приложения в Arachne составляет около 10 тыс. микросекунд.
Технология реализована в виде библиотеки C++ для Linux, а её исходный код есть на GitHub.
Ещё один инструмент-балансировщик — ZygOS. Как и Shenango, технология использует для перераспределения процессов метод work stealing. По данным авторов ZygOS, средняя задержка в работе приложений при использовании инструмента составляет около 150 микросекунд, а максимальная — около 450 микросекунд. Код проекта также находится в открытом доступе.
Выводы
Современные ЦОД продолжают расширяться, Особенно тенденция к увеличению заметна на рынке hyperscale дата-центров: сейчас в мире существует 430 гипермасштабируемых ЦОДа, но уже в ближайшие годы их число может увеличится на 30%. По этой причине технологии балансировки нагрузки на процессоры будут очень востребованы. Системы, подобные Shenango, уже сейчас внедряют крупные корпорации, и в будущем количество таких инструментов будет только расти.
Посты из Первого блога о корпоративном IaaS:
- Как повысить энергоэффективность дата-центра
- Что нужно знать о PCI DSS: обзор стандарта
- Мир до и после: как изменилась жизнь с наступлением DNS Flag Day
- Как IaaS помогает развивать бизнес: три задачи, которые решит облако
- Тестирование дисковой системы в облаке: основы и советы
- 9 полезных советов для плавного перехода в облако
- IaaS: Первые шаги после аренды облачной инфраструктуры
Комментарии (6)

achekalin
07.04.2019 19:09Будем честны: затраты энергии учтены в бизнес-план ах и заложены в тарифы. А когда распределение улучшится, цены вниз не пойдут не только на 30%, но даже на копейку.
И, да, у больших игроков разгон виртуалок с хостов и выключение хостов, а затем включение их обратно давно реализованы. Вопрос только в алгоритме: новый может освобождать ещё больше хост-машин, полагаю.
Revertis
mediaman
Причем здесь выключение серверов? Система просто будет нагружать существующие машины более эффективно. И один и тот же набор задач можно выполнить на меньшем количестве серверов. А если адаптируют систему для глобальных систем, то можно будет дополнительно экономить на электричестве – сильнее нагружать дата-центры в тех регионах, где электричество дешевле. Собственно, MIT в этом направлении уже как-то работали
Revertis
Но так проблема сформулирована вот так:
А данный софт разработан не для управления серверами, а для управления ядрами процессора, ведь так?jaguard
>>Система просто будет нагружать существующие машины более эффективно
Т.е. простаивать будет уже не 30%, а 40% серверов, да?
fedorro
Нет, не так. При увеличении нагрузки можно или закупить еще серверов, которые тоже будут простаивать на 30%, или при помощи этого планировщика распихать возросшую нагрузку по этим 30%, и тогда простаивать будет 0% серверов, в идеале.
Ну или поставить этот планировщик и выключить 30% серверов, получим 0% простоя при той же нагрузке.