
В первой части статьи мы при помощи Ghidra провели автоматический анализ простой программы-крякми (которую мы скачали с сайта crackmes.one). Мы разобрались с тем, как переименовывать «непонятные» функции прямо в листинге декомпилятора, а также поняли алгоритм программы «верхнего уровня», т.е. что выполняется функцией main().
В этой части мы, как я и обещал, возьмемся за анализ функции _construct_key(), которая, как мы выяснили, как раз и отвечает за чтение переданного в программу двоичного файла и проверку прочитанных данных.
Давайте сразу посмотрим на полный листинг этой функции:
С этой функцией мы поступим так же, как и ранее с main() — для начала пройдемся по «завуалированным» вызовам функций. Как и ожидаось, все эти функции — из стандартных библиотек C. Описывать заново процедуру переименования функций не буду — вернись к первой части статьи, если нужно. В результате переименования «нашлись» следующие стандартные функции:
Соответствующие функции-обертки в нашем коде (те, что декомпилятор нагло прятал за словом _text) мы переименовали в эти, добавив индекс 2 (чтобы не возникало путаницы с оригинальными C-функциями). Почти все эти функции служат для работы с файловыми потоками. Оно и не удивительно — достаточно беглого взгляда на код, чтобы понять, что здесь производится последовательное чтение данных из файла (дескриптор которого передается в функцию в качестве единственного параметра) и сравнение прочитанных данных с неким двумерным массивом байтов local_14.
Давайте предположим, что этот массив содержит данные для проверки ключа. Назовем его, скажем, key_array. Поскольку Гидра позволяет переименовывать не только функции, но и переменные, воспользуемся этим и переименуем непонятный local_14 в более понятный key_array. Делается это так же, как и для функций: через меню правой клавиши мыши (Rename local) или клавишей L с клавиатуры.
Итак, сразу же за объявлением локальных переменных вызывается некая функция _prepare_key():
К _prepare_key() мы еще вернемся, это уже 3-й уровень вложенности в нашей иерархии вызовов: main() -> _construct_key() -> _prepare_key(). Пока же примем, что она создает и как-то инициализирует этот «проверочный» двумерный массив. И только в случае если этот массив не пуст, функция продолжает свою работу, о чем свидетельствует блок else сразу же после приведенного условия.
Далее программа читает первые 4 байта из файла и сравнивает с соответствующим участком массива key_array. (Код ниже — уже после произведенных переименований, в т.ч. переменную local_19 я переименовал в first_4bytes.)
Таким образом, дальнейшее выполнение происходит только в случае совпадения первых 4 байтов (запомним это). Дальше читаем 2 2-байтных блока из файла (причем в роли буфера для записи данных используется тот же key_array):
И вновь — дальше функция работает только в случае истинности очередного условия:
Нетрудно увидеть, что первый из прочитанных выше 2-байтных блока должно быть числом 5, а второй — числом 4 (тип данных short как раз занимает 2 байта на 32-разрядных платформах).
Дальше — вот это:
Здесь мы видим, что в массив local_30 (объявленный как char *local_30 [4]) заносятся смещения указателя key_array. То есть local_30 — это массив строк-маркеров, в который наверняка будут читаться данные из файла. По этому допущению я переименовал local_30 в markers. В этом участке кода немного подозрительной кажется только последняя строка, где присвоение последнего смещения (по индексу 0x430, т.е. 1072) выполняется не очередному элементу markers, а отдельной переменной local_20 (char*). Но с этим мы еще разберемся, а пока — давайте двигаться дальше!
Дальше нас ожидает цикл:
Т.е. всего 5 итераций от 0 до 4 включительно. В цикле сразу начинается чтение из файла и проверка на соответствие нашему массиву markers:
То есть читается следующий байт из файла в переменную c_marker (в оригинальном декомпилированном коде — local_35) и проверяется на соответствие первому символу i-го элемента markers. В случае несоответствия массив key_array обнуляется и возвращается пустой двойной указатель. Далее по коду мы видим, что такое проделывается всякий раз при несовпадении прочитанных данных с проверочными.
Но тут, как говорится, «зарыта собака». Давайте внимательнее посмотрим на этот цикл. В нем 5 итераций, как мы выяснили. Это можно при желании проверить, взглянув на ассемблерный код:


Действительно, команда CMP сравнивает значение переменной local_10 (у нас это уже i) с числом 4 и если значение меньше или равно 4 (команда JLE) производится переход к метке LAB_004017eb, т.е. начало тела цикла. Т.е. условие будет соблюдаться для i = 0, 1, 2, 3 и 4 — всего 5 итераций! Все бы хорошо, но markers также индексируется по этой переменной в цикле, а ведь этот массив у нас объявлен только с 4 элементами:
Значит, кто-то кого-то явно обмануть пытается :) Помните, я сказал, что эта строка наводит сомнения?
Еще как! Просто посмотрите на весь листинг функции и попробуйте отыскать еще хоть одну ссылку на переменную local_20. Ее нет! Отсюда делаем вывод: это смещение должно также сохраняться в массив markers, а сам массив должен содержать 5 элементов. Давайте исправим это. Переходим к объявлению переменной, ждем Ctrl + L (Retype variable) и смело меняем размер массива на 5:
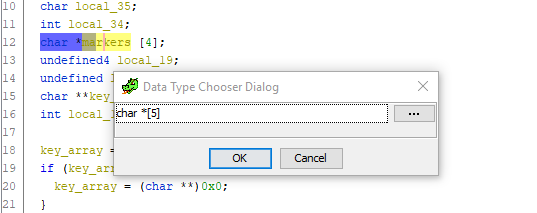
Готово. Скроллим ниже до кода присвоения смещений указателя элементам markers, и — о чудо! — исчезает непонятная лишняя переменная и все становится на свои места:
Возвращаемся к нашему циклу while (в исходном коде это, скорее всего, будет for, но нас это не волнует). Далее опять читается байт из файла и проверяется его значение:
ОК, этот n_strlen1 должен быть ненулевым. Почему? Сейчас увидишь, а заодно и поймешь, почему я присвоил этой переменной такое имя:
Я добавил комментарии, по которым должно быть все понятно. Из файла читается n_strlen1 байтов и сохраняется как последовательность символов (т.е. строка) в массив markers[i] — то есть после соответствующего «стоп-символа», которые там уже записаны из key_array. Сохранение значения n_strlen1 в markers[i] по смещению 0x104 (260) здесь не играет никакой роли (см. первую строку в коде выше). По факту этот код можно оптимизировать следующим образом (и наверняка так это и есть в исходном коде):
Также проводится проверка того, что длина прочитанной строки равна n_strlen1. Это может показаться излишним, с учетом что данный параметр передавался в функцию fread, но fread читает не более столько-то указанных байтов и может прочитать меньше, чем указано, например, в случае встречи маркера конца файла (EOF). То есть все строго: в файле указывается длина строки (в байтах), затем идет сама строка — и так ровно 5 раз. Но мы забегаем вперед.
Далее вод этот код (который я также сразу прокомментировал):
Здесь все еще проще: берем следующий байт из файла, прибавляем 7 и полученное значение сравниваем с текущей позицией курсора в файловом потоке, полученным функцией ftell(). Значение n_pos должно быть не меньше позиции курсора (т.е. смещения в байтах от начала файла).
Завершающая строка в цикле:
Т.е. переставляем курсор файла (от начала) на позицию, указанную n_pos функцией fseek(). ОК, все эти операции в цикле мы проделываем 5 раз. Завершается же функция _construct_key() следующим кодом:
Таким образом, последним блоком данных в файле должно быть 4-байтовое целочисленное значение и оно должно равняться значению в key_array[0][1340]. В этом случае нас ждет поздравительное сообщение в консоли. А в противном случае — все так же возвращается пустой массив без всяких похвал :)
У нас осталась только одна неразобранная функция — __prepare_key(). Мы уже догадались, что именно в ней формируется проверочные данные в виде массива key_array, который затем используется в функции _construct_key() для проверки данных из файла. Осталось выяснить, какие именно там данные!
Я не буду подробно разбирать эту функцию и сразу приведу полный листинг с комментариями после всех необходимых переименований переменных:
Единственное место, достойное рассмотрения, — это вот эта строка:
Как я понял, что здесь кроется строка «VOID»? Дело в том, что 0x404024 — это адрес в адресном пространстве программы, ведущий в секцию .rdata. Двойной клик на это значение позволяет нам как на ладони увидеть, что там находится:

Кстати, это же можно понять из ассемблерного кода для этой строки:
Данные, соответствующие строке «VOID», находятся в самом начале секции .rdata (по нулевому смещению от соответствующего адреса).
Итак, на выходе из этой функции должен быть сформирован двумерный массив со следующими данными:
Теперь можем приступить к синтезу двоичного файла. Все исходные данные у нас на руках:
1) проверочные данные («стоп-символы») и их позиции в проверочном массиве;
2) последовательность данных в файле
Давайте восстановим структуру искомого файла по алгоритму работы функции _construct_key(). Итак, последовательность данных в файле будет такова:
Для наглядности я сделал в Excel такую табличку с данными искомого файла:

Здесь в 7-й строке — сами данные в виде символов и чисел, в 6-й строке — их шестнадцатеричные представления, в 8-й строке — размер каждого элемента (в байтах), в 9-й строке — смещение относительно начала файла. Это представление очень удобно, т.к. позволяет вписывать любые строки в будущий файл (отмечены желтой заливкой), при этом значения длин этих строк, а также смещения позиции следующего стоп-символа вычисляются формулами автоматически, как это требует алгоритм программы. Выше (в строках 1-4) приведена структура проверочного массива key_array.
Саму эксельку плюс другие исходные материалы к статье можно скачать по ссылке.
Осталось дело за малым — сгенерировать искомый файл в двоичном формате и скормить его нашей крякми. Для генерации файла я написал простенький скрипт на Python:
Скрипт принимает единственным параметром путь к крякми, затем генерирует в этой же директории двоичный файл с ключом и вызывает крякми с соответствующим параметром, транслируя в консоль вывод программы.
Для конвертации текстовых данных в двоичные используется пакет struct. Метод pack() позволяет записывать двоичные данные по формату, в котором указывается тип данных («B» = «byte», «i» = int и т.д.), а также можно указать порядок следования (">" = «Big-endian», "<" = «Little-endian»). По умолчанию применяется порядок Little-endian. Т.к. мы уже определили в первой статье, что это именно наш случай, то указываем только тип.
Весь код в целом воспроизводит найденный нами алгоритм программы. В качестве строки, выводимой в случае успеха, я указал «I solved this crackme!» (можно модифицировать этот скрипт, чтобы возможно было указывать любую строку).
Проверяем вывод:

Ура, все работает! Вот так, немного попотев и разобрав пару функций, мы смогли полностью восстановить алгоритм программы и «взломать» ее. Конечно, это всего лишь простая крякми, тестовая программка, да и то 2-го уровня сложности (из 5 предлагаемых на том сайте). В реальности мы будем иметь дело со сложной иерархией вызовов и десятками — сотнями функций, а в некоторых случаях — шифрованными секциями данных, мусорным кодом и прочими приемами обфускации, вплоть до применения внутренних виртуальных машин и P-кода… Но это, как говорится, уже совсем другая история.
Материалы к статье.
В этой части мы, как я и обещал, возьмемся за анализ функции _construct_key(), которая, как мы выяснили, как раз и отвечает за чтение переданного в программу двоичного файла и проверку прочитанных данных.
Шаг 5 — Обзор функции _construct_key()
Давайте сразу посмотрим на полный листинг этой функции:
Листинг функции _construct_key()
char ** __cdecl _construct_key(FILE *param_1)
{
int iVar1;
size_t sVar2;
uint uVar3;
uint local_3c;
byte local_36;
char local_35;
int local_34;
char *local_30 [4];
char *local_20;
undefined4 local_19;
undefined local_15;
char **local_14;
int local_10;
local_14 = (char **)__prepare_key();
if (local_14 == (char **)0x0) {
local_14 = (char **)0x0;
}
else {
local_19 = 0;
local_15 = 0;
_text(&local_19,1,4,param_1);
iVar1 = _text((char *)&local_19,*(char **)local_14[1],4);
if (iVar1 == 0) {
_text(local_14[1] + 4,2,1,param_1);
_text(local_14[1] + 6,2,1,param_1);
if ((*(short *)(local_14[1] + 6) == 4) && (*(short *)(local_14[1] + 4) == 5)) {
local_30[0] = *local_14;
local_30[1] = *local_14 + 0x10c;
local_30[2] = *local_14 + 0x218;
local_30[3] = *local_14 + 0x324;
local_20 = *local_14 + 0x430;
local_10 = 0;
while (local_10 < 5) {
local_35 = 0;
_text(&local_35,1,1,param_1);
if (*local_30[local_10] != local_35) {
_free_key(local_14);
return (char **)0x0;
}
local_36 = 0;
_text(&local_36,1,1,param_1);
if (local_36 == 0) {
_free_key(local_14);
return (char **)0x0;
}
*(uint *)(local_30[local_10] + 0x104) = (uint)local_36;
_text(local_30[local_10] + 1,1,*(size_t *)(local_30[local_10] + 0x104),param_1);
sVar2 = _text(local_30[local_10] + 1);
if (sVar2 != *(size_t *)(local_30[local_10] + 0x104)) {
_free_key(local_14);
return (char **)0x0;
}
local_3c = 0;
_text(&local_3c,1,1,param_1);
local_3c = local_3c + 7;
uVar3 = _text(param_1);
if (local_3c < uVar3) {
_free_key(local_14);
return (char **)0x0;
}
*(uint *)(local_30[local_10] + 0x108) = local_3c;
_text(param_1,local_3c,0);
local_10 = local_10 + 1;
}
local_34 = 0;
_text(&local_34,4,1,param_1);
if (*(int *)(*local_14 + 0x53c) == local_34) {
_text("Markers seem to still exist");
}
else {
_free_key(local_14);
local_14 = (char **)0x0;
}
}
else {
_free_key(local_14);
local_14 = (char **)0x0;
}
}
else {
_free_key(local_14);
local_14 = (char **)0x0;
}
}
return local_14;
}
С этой функцией мы поступим так же, как и ранее с main() — для начала пройдемся по «завуалированным» вызовам функций. Как и ожидаось, все эти функции — из стандартных библиотек C. Описывать заново процедуру переименования функций не буду — вернись к первой части статьи, если нужно. В результате переименования «нашлись» следующие стандартные функции:
- fread()
- strncmp()
- strlen()
- ftell()
- fseek()
- puts()
Соответствующие функции-обертки в нашем коде (те, что декомпилятор нагло прятал за словом _text) мы переименовали в эти, добавив индекс 2 (чтобы не возникало путаницы с оригинальными C-функциями). Почти все эти функции служат для работы с файловыми потоками. Оно и не удивительно — достаточно беглого взгляда на код, чтобы понять, что здесь производится последовательное чтение данных из файла (дескриптор которого передается в функцию в качестве единственного параметра) и сравнение прочитанных данных с неким двумерным массивом байтов local_14.
Давайте предположим, что этот массив содержит данные для проверки ключа. Назовем его, скажем, key_array. Поскольку Гидра позволяет переименовывать не только функции, но и переменные, воспользуемся этим и переименуем непонятный local_14 в более понятный key_array. Делается это так же, как и для функций: через меню правой клавиши мыши (Rename local) или клавишей L с клавиатуры.
Итак, сразу же за объявлением локальных переменных вызывается некая функция _prepare_key():
key_array = (char **)__prepare_key();
if (key_array == (char **)0x0) {
key_array = (char **)0x0;
}
К _prepare_key() мы еще вернемся, это уже 3-й уровень вложенности в нашей иерархии вызовов: main() -> _construct_key() -> _prepare_key(). Пока же примем, что она создает и как-то инициализирует этот «проверочный» двумерный массив. И только в случае если этот массив не пуст, функция продолжает свою работу, о чем свидетельствует блок else сразу же после приведенного условия.
Далее программа читает первые 4 байта из файла и сравнивает с соответствующим участком массива key_array. (Код ниже — уже после произведенных переименований, в т.ч. переменную local_19 я переименовал в first_4bytes.)
first_4bytes = 0;
/* прочитать первые 4 байта из файла */
fread2(&first_4bytes,1,4,param_1);
/* сравнить с key_array[1][0...3] */
iVar1 = strncmp2((char *)&first_4bytes,*(char **)key_array[1],4);
if (iVar1 == 0) { ... }
Таким образом, дальнейшее выполнение происходит только в случае совпадения первых 4 байтов (запомним это). Дальше читаем 2 2-байтных блока из файла (причем в роли буфера для записи данных используется тот же key_array):
fread2(key_array[1] + 4,2,1,param_1);
fread2(key_array[1] + 6,2,1,param_1);
И вновь — дальше функция работает только в случае истинности очередного условия:
if ((*(short *)(key_array[1] + 6) == 4) && (*(short *)(key_array[1] + 4) == 5)) {
// выполняем дальше ...
}
Нетрудно увидеть, что первый из прочитанных выше 2-байтных блока должно быть числом 5, а второй — числом 4 (тип данных short как раз занимает 2 байта на 32-разрядных платформах).
Дальше — вот это:
local_30[0] = *key_array; // т.е. key_array[0]
local_30[1] = *key_array + 0x10c;
local_30[2] = *key_array + 0x218;
local_30[3] = *key_array + 0x324;
local_20 = *key_array + 0x430;
Здесь мы видим, что в массив local_30 (объявленный как char *local_30 [4]) заносятся смещения указателя key_array. То есть local_30 — это массив строк-маркеров, в который наверняка будут читаться данные из файла. По этому допущению я переименовал local_30 в markers. В этом участке кода немного подозрительной кажется только последняя строка, где присвоение последнего смещения (по индексу 0x430, т.е. 1072) выполняется не очередному элементу markers, а отдельной переменной local_20 (char*). Но с этим мы еще разберемся, а пока — давайте двигаться дальше!
Дальше нас ожидает цикл:
i = 0; // local_10 переименовал в i
while (i < 5) {
// ...
i = i + 1;
}
Т.е. всего 5 итераций от 0 до 4 включительно. В цикле сразу начинается чтение из файла и проверка на соответствие нашему массиву markers:
char c_marker = 0; // переименовал из local_35
/* прочитать след. байт из файла */
fread2(&c_marker, 1, 1, param_1);
if (*markers[i] != c_marker) {
/* здесь и далее - вернуть пустой массив при ошибке */
_free_key(key_array);
return (char **)0x0;
}
То есть читается следующий байт из файла в переменную c_marker (в оригинальном декомпилированном коде — local_35) и проверяется на соответствие первому символу i-го элемента markers. В случае несоответствия массив key_array обнуляется и возвращается пустой двойной указатель. Далее по коду мы видим, что такое проделывается всякий раз при несовпадении прочитанных данных с проверочными.
Но тут, как говорится, «зарыта собака». Давайте внимательнее посмотрим на этот цикл. В нем 5 итераций, как мы выяснили. Это можно при желании проверить, взглянув на ассемблерный код:
Действительно, команда CMP сравнивает значение переменной local_10 (у нас это уже i) с числом 4 и если значение меньше или равно 4 (команда JLE) производится переход к метке LAB_004017eb, т.е. начало тела цикла. Т.е. условие будет соблюдаться для i = 0, 1, 2, 3 и 4 — всего 5 итераций! Все бы хорошо, но markers также индексируется по этой переменной в цикле, а ведь этот массив у нас объявлен только с 4 элементами:
char *markers [4];
Значит, кто-то кого-то явно обмануть пытается :) Помните, я сказал, что эта строка наводит сомнения?
local_20 = *key_array + 0x430;
Еще как! Просто посмотрите на весь листинг функции и попробуйте отыскать еще хоть одну ссылку на переменную local_20. Ее нет! Отсюда делаем вывод: это смещение должно также сохраняться в массив markers, а сам массив должен содержать 5 элементов. Давайте исправим это. Переходим к объявлению переменной, ждем Ctrl + L (Retype variable) и смело меняем размер массива на 5:
Готово. Скроллим ниже до кода присвоения смещений указателя элементам markers, и — о чудо! — исчезает непонятная лишняя переменная и все становится на свои места:
markers[0] = *key_array;
markers[1] = *key_array + 0x10c;
markers[2] = *key_array + 0x218;
markers[3] = *key_array + 0x324;
markers[4] = *key_array + 0x430; // убежавшее было присвоение... мы поймали тебя!
Возвращаемся к нашему циклу while (в исходном коде это, скорее всего, будет for, но нас это не волнует). Далее опять читается байт из файла и проверяется его значение:
byte n_strlen1 = 0; // переименован из local_36
/* прочитать след. байт из файла */
fread2(&n_strlen1,1,1,param_1);
if (n_strlen1 == 0) {
/* значение не должно быть нулевым */
_free_key(key_array);
return (char **)0x0;
}
ОК, этот n_strlen1 должен быть ненулевым. Почему? Сейчас увидишь, а заодно и поймешь, почему я присвоил этой переменной такое имя:
/* записываем значение n_strlen1) в (markers[i] + 0x104) */
*(uint *)(markers[i] + 0x104) = (uint)n_strlen1;
/* прочитать из файла (n_strlen1) байт (--> некая строка?) */
fread2(markers[i] + 1,1,*(size_t *)(markers[i] + 0x104),param_1);
n_strlen2 = strlen2(markers[i] + 1); // переименован из sVar2
if (n_strlen2 != *(size_t *)(markers[i] + 0x104)) {
/* длина прочитанной строки (n_strlen2) должна == n_strlen1 */
_free_key(key_array);
return (char **)0x0;
}
Я добавил комментарии, по которым должно быть все понятно. Из файла читается n_strlen1 байтов и сохраняется как последовательность символов (т.е. строка) в массив markers[i] — то есть после соответствующего «стоп-символа», которые там уже записаны из key_array. Сохранение значения n_strlen1 в markers[i] по смещению 0x104 (260) здесь не играет никакой роли (см. первую строку в коде выше). По факту этот код можно оптимизировать следующим образом (и наверняка так это и есть в исходном коде):
fread2(markers[i] + 1, 1, (size_t) n_strlen1, param_1);
n_strlen2 = strlen2(markers[i] + 1);
if (n_strlen2 != (size_t) n_strlen1) { ... }
Также проводится проверка того, что длина прочитанной строки равна n_strlen1. Это может показаться излишним, с учетом что данный параметр передавался в функцию fread, но fread читает не более столько-то указанных байтов и может прочитать меньше, чем указано, например, в случае встречи маркера конца файла (EOF). То есть все строго: в файле указывается длина строки (в байтах), затем идет сама строка — и так ровно 5 раз. Но мы забегаем вперед.
Далее вод этот код (который я также сразу прокомментировал):
uint n_pos = 0; // переименован из local_3c
/* прочитать след. байт из файла */
fread2(&n_pos,1,1,param_1);
/* увеличить на 7 */
n_pos = n_pos + 7;
/* получить позицию файлового курсора */
uint n_filepos = ftell2(param_1); // переименован из uVar3
if (n_pos < n_filepos) {
/* n_pos должна быть >= n_filepos */
_free_key(key_array);
return (char **)0x0;
}
Здесь все еще проще: берем следующий байт из файла, прибавляем 7 и полученное значение сравниваем с текущей позицией курсора в файловом потоке, полученным функцией ftell(). Значение n_pos должно быть не меньше позиции курсора (т.е. смещения в байтах от начала файла).
Завершающая строка в цикле:
fseek2(param_1,n_pos,0);
Т.е. переставляем курсор файла (от начала) на позицию, указанную n_pos функцией fseek(). ОК, все эти операции в цикле мы проделываем 5 раз. Завершается же функция _construct_key() следующим кодом:
int i_lastmarker = 0; // переименован из local_34
/* прочитать последние 4 байт из файла (int32) */
fread2(&i_lastmarker,4,1,param_1);
if (*(int *)(*key_array + 0x53c) == i_lastmarker) {
/* это число должно == key_array[0][1340]
...тогда все ОК :) */
puts2("Markers seem to still exist");
}
else {
_free_key(key_array);
key_array = (char **)0x0;
}
Таким образом, последним блоком данных в файле должно быть 4-байтовое целочисленное значение и оно должно равняться значению в key_array[0][1340]. В этом случае нас ждет поздравительное сообщение в консоли. А в противном случае — все так же возвращается пустой массив без всяких похвал :)
Шаг 6 — Обзор функции __prepare_key()
У нас осталась только одна неразобранная функция — __prepare_key(). Мы уже догадались, что именно в ней формируется проверочные данные в виде массива key_array, который затем используется в функции _construct_key() для проверки данных из файла. Осталось выяснить, какие именно там данные!
Я не буду подробно разбирать эту функцию и сразу приведу полный листинг с комментариями после всех необходимых переименований переменных:
Листинг функции __prepare_key()
void ** __prepare_key(void)
{
void **key_array;
void *pvVar1;
/* key_array = new char*[2]; // 2 4-байтных указателя (char*) */
key_array = (void **)calloc2(1,8);
if (key_array == (void **)0x0) {
key_array = (void **)0x0;
}
else {
pvVar1 = calloc2(1,0x540);
/* key_array[0] = new char[1340] */
*key_array = pvVar1;
pvVar1 = calloc2(1,8);
/* key_array[1] = new char[8] */
key_array[1] = pvVar1;
/* "VOID" */
*(undefined4 *)key_array[1] = 0x404024;
/* 5 и 4 (2-байтные слова) */
*(undefined2 *)((int)key_array[1] + 4) = 5;
*(undefined2 *)((int)key_array[1] + 6) = 4;
/* key_array[0][0] = 'b' */
*(undefined *)*key_array = 0x62;
*(undefined4 *)((int)*key_array + 0x104) = 3;
/* 'W' */
*(undefined *)((int)*key_array + 0x218) = 0x57;
/* 'p' */
*(undefined *)((int)*key_array + 0x324) = 0x70;
/* 'l' */
*(undefined *)((int)*key_array + 0x10c) = 0x6c;
/* 152 (не ASCII) */
*(undefined *)((int)*key_array + 0x430) = 0x98;
/* последний маркер = 1122 (int32) */
*(undefined4 *)((int)*key_array + 0x53c) = 0x462;
}
return key_array;
}
Единственное место, достойное рассмотрения, — это вот эта строка:
*(undefined4 *)key_array[1] = 0x404024;
Как я понял, что здесь кроется строка «VOID»? Дело в том, что 0x404024 — это адрес в адресном пространстве программы, ведущий в секцию .rdata. Двойной клик на это значение позволяет нам как на ладони увидеть, что там находится:
Кстати, это же можно понять из ассемблерного кода для этой строки:
004015da c7 00 24 MOV dword ptr [EAX], .rdata = 56h V
40 40 00
Данные, соответствующие строке «VOID», находятся в самом начале секции .rdata (по нулевому смещению от соответствующего адреса).
Итак, на выходе из этой функции должен быть сформирован двумерный массив со следующими данными:
[0] [0]:'b' [268]:'l' [536]:'W' [804]:'p' [1072]:152 [1340]:1122
[1] [0-3]:"VOID" [4-5]:5 [6-7]:4
Шаг 7 — Готовим двоичный файл для крякми
Теперь можем приступить к синтезу двоичного файла. Все исходные данные у нас на руках:
1) проверочные данные («стоп-символы») и их позиции в проверочном массиве;
2) последовательность данных в файле
Давайте восстановим структуру искомого файла по алгоритму работы функции _construct_key(). Итак, последовательность данных в файле будет такова:
Структура файла
- 4 байта == key_array[1][0...3] == «VOID»
- 2 байта == key_array[1][4] == 5
- 2 байта == key_array[1][6] == 4
- 1 байт == key_array[0][0] == 'b' (маркер)
- 1 байт == (длина следующей строки) == n_strlen1
- n_strlen1 байт == (любая строка) == n_strlen1
- 1 байт == (+7 == следующий маркер) == n_pos
- 1 байт == key_array[0][0] == 'l' (маркер)
- 1 байт == (длина следующей строки) == n_strlen1
- n_strlen1 байт == (любая строка) == n_strlen1
- 1 байт == (+7 == следующий маркер) == n_pos
- 1 байт == key_array[0][0] == 'W' (маркер)
- 1 байт == (длина следующей строки) == n_strlen1
- n_strlen1 байт == (любая строка) == n_strlen1
- 1 байт == (+7 == следующий маркер) == n_pos
- 1 байт == key_array[0][0] == 'p' (маркер)
- 1 байт == (длина следующей строки) == n_strlen1
- n_strlen1 байт == (любая строка) == n_strlen1
- 1 байт == (+7 == следующий маркер) == n_pos
- 1 байт == key_array[0][0] == 152 (маркер)
- 1 байт == (длина следующей строки) == n_strlen1
- n_strlen1 байт == (любая строка) == n_strlen1
- 1 байт == (+7 == следующий маркер) == n_pos
- 4 байта == (key_array[1340]) == 1122
Для наглядности я сделал в Excel такую табличку с данными искомого файла:
Здесь в 7-й строке — сами данные в виде символов и чисел, в 6-й строке — их шестнадцатеричные представления, в 8-й строке — размер каждого элемента (в байтах), в 9-й строке — смещение относительно начала файла. Это представление очень удобно, т.к. позволяет вписывать любые строки в будущий файл (отмечены желтой заливкой), при этом значения длин этих строк, а также смещения позиции следующего стоп-символа вычисляются формулами автоматически, как это требует алгоритм программы. Выше (в строках 1-4) приведена структура проверочного массива key_array.
Саму эксельку плюс другие исходные материалы к статье можно скачать по ссылке.
Генерация двоичного файла и проверка
Осталось дело за малым — сгенерировать искомый файл в двоичном формате и скормить его нашей крякми. Для генерации файла я написал простенький скрипт на Python:
Скрипт для генерации файла
import sys, os
import struct
import subprocess
out_str = ['!', 'I', ' solved', ' this', ' crackme!']
def write_file(file_path):
try:
with open(file_path, 'wb') as outfile:
outfile.write('VOID'.encode('ascii'))
outfile.write(struct.pack('2h', 5, 4))
outfile.write('b'.encode('ascii'))
outfile.write(struct.pack('B', len(out_str[0])))
outfile.write(out_str[0].encode('ascii'))
pos = 10 + len(out_str[0])
outfile.write(struct.pack('B', pos - 6))
outfile.write('l'.encode('ascii'))
outfile.write(struct.pack('B', len(out_str[1])))
outfile.write(out_str[1].encode('ascii'))
pos += 3 + len(out_str[1])
outfile.write(struct.pack('B', pos - 6))
outfile.write('W'.encode('ascii'))
outfile.write(struct.pack('B', len(out_str[2])))
outfile.write(out_str[2].encode('ascii'))
pos += 3 + len(out_str[2])
outfile.write(struct.pack('B', pos - 6))
outfile.write('p'.encode('ascii'))
outfile.write(struct.pack('B', len(out_str[3])))
outfile.write(out_str[3].encode('ascii'))
pos += 3 + len(out_str[3])
outfile.write(struct.pack('B', pos - 6))
outfile.write(struct.pack('B', 152))
outfile.write(struct.pack('B', len(out_str[4])))
outfile.write(out_str[4].encode('ascii'))
pos += 3 + len(out_str[4])
outfile.write(struct.pack('B', pos - 6))
outfile.write(struct.pack('i', 1122))
except Exception as err:
print(err)
raise
def main():
if len(sys.argv) != 2:
print('USAGE: {this_script.py} path_to_crackme[.exe]')
return
if not os.path.isfile(sys.argv[1]):
print('File "{}" unavailable!'.format(sys.argv[1]))
return
file_path = os.path.splitext(sys.argv[1])[0] + '.dat'
try:
write_file(file_path)
except:
return
try:
outputstr = subprocess.check_output('"{}" -f "{}"'.format(sys.argv[1], file_path), stderr=subprocess.STDOUT)
print(outputstr.decode('utf-8'))
except Exception as err:
print(err)
if __name__ == '__main__':
main()
Скрипт принимает единственным параметром путь к крякми, затем генерирует в этой же директории двоичный файл с ключом и вызывает крякми с соответствующим параметром, транслируя в консоль вывод программы.
Для конвертации текстовых данных в двоичные используется пакет struct. Метод pack() позволяет записывать двоичные данные по формату, в котором указывается тип данных («B» = «byte», «i» = int и т.д.), а также можно указать порядок следования (">" = «Big-endian», "<" = «Little-endian»). По умолчанию применяется порядок Little-endian. Т.к. мы уже определили в первой статье, что это именно наш случай, то указываем только тип.
Весь код в целом воспроизводит найденный нами алгоритм программы. В качестве строки, выводимой в случае успеха, я указал «I solved this crackme!» (можно модифицировать этот скрипт, чтобы возможно было указывать любую строку).
Проверяем вывод:
Ура, все работает! Вот так, немного попотев и разобрав пару функций, мы смогли полностью восстановить алгоритм программы и «взломать» ее. Конечно, это всего лишь простая крякми, тестовая программка, да и то 2-го уровня сложности (из 5 предлагаемых на том сайте). В реальности мы будем иметь дело со сложной иерархией вызовов и десятками — сотнями функций, а в некоторых случаях — шифрованными секциями данных, мусорным кодом и прочими приемами обфускации, вплоть до применения внутренних виртуальных машин и P-кода… Но это, как говорится, уже совсем другая история.
Материалы к статье.
DrMefistO
Спасибо. Пропаганда бесплатных и в то же время не r2 инструментов для реверса заслуживает уважения!
Теперь моя очередь писать на тему реверса Гидрой чего-то не вин/лин/мак:)
S0mbre Автор
Да, было бы вообще круто! Вот кстати стрим про разбор андроидного приложения для синего зуба.