
Введение
KCAPTCHA — это готовое решение, написанное на языке PHP, предлагающее программисту решение с одной стороны весьма защищенное, с другой — максимально малотребовательное к ресурсам и конфигурации хостинга.
В этой статье речь пойдет о простом, в некоторой степени универсальном способе распознавания капчи, на примере KCAPTCHA, с реализацией на C#. Стоит заметить, что я ограничился 6-символьным вариантом kcaptcha, но обязательно расскажу о капчах переменной длины в последующих публикациях.
Обзор задачи
Итак мы имеем такую капчу:



Особенности:
- Переменная длина
- Искажения
- Шумы
- Переменный цвет фона
- Латинские буквы и цифры, исключая похожие, всего 23
Слабые стороны:
- Малая длина капчи
- Недостаточные искажения
- Шумы практически не препятствуют распознаванию
- Смысл переменного цвета фона мягко говоря не понятен
- Общедоступность исходников
Впрочем многое можно исправить тонко настроив скрипт, но скажу честно, при желании и должном числе примеров, любая понятная [и не только] человеку капча поддается распознаванию.
Решение
Распознавание текста, в большинстве случаев, можно условно разделить на следующие этапы:
- Предварительная обработка
- Поиск расположения текста
- Сегментация
- Распознавание
Но в этот раз мы сделаем исключение, ведь большинство — не все.
Предварительная обработка
По цвету первого пикселя убираем фон:

Затем преобразуем изображение в оттенки серого.
Теперь каждый пиксель принимает значения от 0 до 255, однако подавать их в таком виде не рекомендуется.
Нормализуем входные данные:
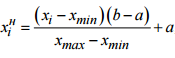
Где x — значения цвета пикселей, [a,b] – интервал допустимых значений входных сигналов. В нашем случае от 0 до 1.
Поиск расположения и сегментация текста
Никакой локации и сегментации текста не предусмотрено.
Имея должное число примеров мы просто отказываемся от этих этапов и переходим к самому интересному.
Распознавание
Для распознавания используется двухслойный персептрон.
Сеть обучалась попримерно (online), методом обратного распространения ошибки, с отказом от обучения на распознаваемых с требуемой точностью примерах.
Размер изображений поступающих на вход 100*50=5000 пикселей.
Первый слой обучаемый и состоит из 2000 нейронов.
Каждому нейрону выходного слоя соответствует буква/цифра на картинке, всего 6 символов по 23 варианта итого: 6*23=138 нейронов.
Обучающая и тестовая выборка составила 140,000 и 10,000 капч соответственно.
Итоги
После ночи обучения, точность распознавания каждого символа, на тестовой выборке, составила 61.4%, верно распознанных капч — 7.2%.
Мне этого оказалось более чем достаточно и обучение было остановлено.
Дальнейшего роста точности можно достичь предварительной обработкой изображения (даже простой отсев шумов наверняка будет иметь результат), дообучением, увеличением количества примеров (инвариантность по обучению) и изменением архитектуры (структурная инвариантность), в последнем случае я бы рекомендовал обратить внимание на Space Displacement Neural Network.
Исходники
Если желаете протестировать или разобраться в работе сети — добро пожаловать на GitHub.
P.S. Одной kcaptcha дело не ограничится, дальше будет много интересного :)
Комментарии (20)

HeisenbergP
20.07.2015 21:24Нормализуем входные данные
Здесь вы просто сжимаете / растягиваете изображение до нормализованной ширины? Что означают a и b?
Переменная длина.
всего 6 символов по 23 варианта итого: 6*23=138
А как вы обходитесь с 5 буквенными вариантами?
Один из 23 символов зарезервирован под пустой?
А нормализованное изображение не мешает в этом случае?

GNC Автор
20.07.2015 22:31+1Благодарю, соответствующий пункт немного дополнил.
Цвета принимают значения от 0 до 255. В таком виде подавать их на вход не рекомендуется.
Нормализация приводит входные данные в заданный интервал [a,b]. В нашем случае от 0 до 1.
Kcaptcha довольно широко применяется, поэтому в данном случае затронут только 6-символьный вариант, не хочется, что бы пример использовался с сомнительными целями.
Впрочем, при должном размере выборки, как Вы заметили, ничего не мешает зарезервировать один из символов под пустой.
Или же учитывая, что текущая сеть в целом справляется с 4-5 символьными вариантами, можно реализовать вторую сеть, распознающую длину капчи и зная длину уже отсеивать результаты последних нейронов.
Оба варианта (и не только) я затрону в последующих публикациях :)

VitaZheltyakov
21.07.2015 08:07Действительно хорошие результаты распознавания для такой капчи. Можно даже сказать что отличные

VokaMut
21.07.2015 10:02Я не против каптчи но и не сторонник, по мне так должна быть проверка на «человека» намного дружелюбнее, чем распознавание текста.
Ну и для хорошего настроения: www.youtube.com/watch?v=WqnXp6Saa8Yisden
21.07.2015 10:27Ну варианты есть, хоть те же honeypot или микроплатежи. Или более продвинутое, вроде поведенческого анализа (не так давно была статья вроде бы на ГТ, или даже здесь).

x2bool
21.07.2015 11:23Раз уж вы используете C#, то, возможно, в следующий раз вам будет интересно поработать с вот этой каптчой. В своё время, для этого проекта я взял за основу именно KCaptcha.

DmitryKoterov
21.07.2015 13:49Скажите, пожалуйста, есть ли сейчас весомые причины использовать «встраиваемые» каптчи (типа kcaptcha), в то время как есть reCaptcha от Гугла, которую пилят сотни людей уже несколько лет (и которую, кстати, часто даже не надо вводить, а достаточно просто нажать чекбокс «я не робот», т.к. Гугл и так знает многое о человеке, идентифицируя его по своим кукам)? Это правда интересно, вопрос не праздный, а сугубо практический (иногда встает вопрос выбора той или иной каптчи, хочется аргументов).
VokaMut
21.07.2015 14:01Плюс reCaptcha помогает распознавать текст в книгах/на зданиях/искать сару конор

mephistopheies
21.07.2015 16:32а где вы взяли 150к распознанных каптч?

Haoose
21.07.2015 17:42Исходники есть. Что мешает нагенерировать выборки?
mephistopheies
21.07.2015 17:46а ну да точно, сорцы жеж, туплю -)
я как то фрилансил подобную задачку, без сорцов, пришлось нанять ряд китайцев что бы трейн сет негенерили

minime
21.07.2015 17:54Вот если-бы кто-то написал про reCaptcha (новая от гугла), было-бы интересно почитать =)
jaguard
А расскажете, зачем вам это надо, пока рука еще только тянется к минусу? Я для распознавателей капчи вижу только одно применение — обходить защиту и создавать ботов, спамить на форумах и в комментариях. Но это потому что я темный такой, правда?
lostpassword
Можно спамить на форумах и в комментариях фоточки котиков.
Sergey6661313
уже очень давно понял, что капчю создают не для людей а для таких вот «решений»… И просто кликаю несколько раз на обновить до тех пор пока капча не становиться «человечной».
А если капча продолжает быть как вторая картинка пример, то вообще закрываю сайт. Именно для таких вот сайтов думаю очень бы пригодилась такая программа.
Согласитесь — сломанные глаза не стоят лишних 2 минут на поиски альтернативного сайта без капчи.
jaguard
>> И просто кликаю несколько раз на обновить до тех пор пока капча не становиться «человечной».
Вы путаете причину со следствием. Капча именно потому настолько сложна для чтение человеком, что автоматические алгоритмы распознавания столь эффективны. Я тоже далеко не фанат капчи, и именно поэтому против распространения инструментов по ее обходу для всех спаммеров-недоучек в мире (те что поумнее, и сами смогут их написать).
Чем умнее будут боты, тем сложнее капча.
>>Согласитесь — сломанные глаза не стоят лишних 2 минут на поиски альтернативного сайта без капчи.
На нормальном сайте при обычном использовании вы капчу и не увидите — она включается как защита от перебора пароля, например. А ненормальными зачем пользоваться?
Sergey6661313
>> Вы путаете причину со следствием.
Это вы путаете. Это потому боты столь эффективны — что сайты не позволяют простому человеку получить желаемое. И одно дело когда действительно желаемым является массовая рассылка рекламы — и совсем другое когда пользователь просто хочет спросить в комментарии о чём либо.
Я говорю о user friendly. Боты так или иначе всё равно будут продолжать появляться какие бы капчи не придумали. А вот количество пользователей будет только уменьшаться — когда на каждый чих нужно будет ввести капчу.
>> Капча потому сложна для чтение человеком, что алгоритмы столь эффективны…
А если они на порядки эффективнее человека — что тогда? Как быть если может распознать только робот?
А что по вашему делать если нужная информация находиться на «ненормальном» сайте?
Сколько сайтов вы знаете на которых для регистрации не нужно вводить капчу (или иной защиты)?
jaguard
>>Это вы путаете. Это потому боты столь эффективны — что сайты не позволяют простому человеку получить желаемое.
Что за ерунда? Боты эффективны потому что люди на взломе защиты зарабатывают деньги.
>> и совсем другое когда пользователь просто хочет спросить в комментарии о чём либо.
99.9% случаев «взлома» капчи — это не пользователь хочет спросить что-то, это спаммеры и ботоводы. Если бы последних не было, не было бы и капчи, ваш кэп.
>> А если они на порядки эффективнее человека — что тогда?
Тогда придется придумывать что-то другое. И может статься, вы будете вспоминать капчу добрым словом, на фоне тех новых методов защиты.
>>А что по вашему делать если нужная информация находиться на «ненормальном» сайте?
>>Сколько сайтов вы знаете на которых для регистрации не нужно вводить капчу (или иной защиты)?
Вы предлагаете оставлять сайты без защиты и потом руками чистить сотни спама в час?
Fedcomp
Можно автоматически смс отправлять себе например отгадывая капчу оператора.