
Всем привет. Все меньше времени остается до запуска курса «Безопасность информационных систем», поэтому сегодня мы продолжаем делиться публикациями, приуроченными к запуску данного курса. Кстати, нынешняя публикация является продолжением вот этих двух статей: «Основы движков JavaScript: общие формы и Inline кэширование. Часть 1», «Основы движков JavaScript: общие формы и Inline кэширование. Часть 2».
В статье описаны ключевые основы. Они являются общими для всех движков JavaScript, а не только для V8, над которым работают авторы (Бенедикт и Матиас). Как JavaScript разработчик могу сказать, что более глубокое понимание того, как работает движок JavaScript поможет разобраться в том, как писать эффективный код.

В предыдущей статье мы обсуждали то, как движки JavaScript оптимизируют доступ к объектам и массивам с помощью форм и Inline кэшей. В этой статье мы рассмотрим оптимизацию компромиссов пайплайна и ускорение доступа к свойствам прототипа.
Уровни оптимизации и компромиссы при выполнении
В прошлый раз мы выяснили, что все современные движки JavaScript, по сути, имеют один и тот же пайплайн:
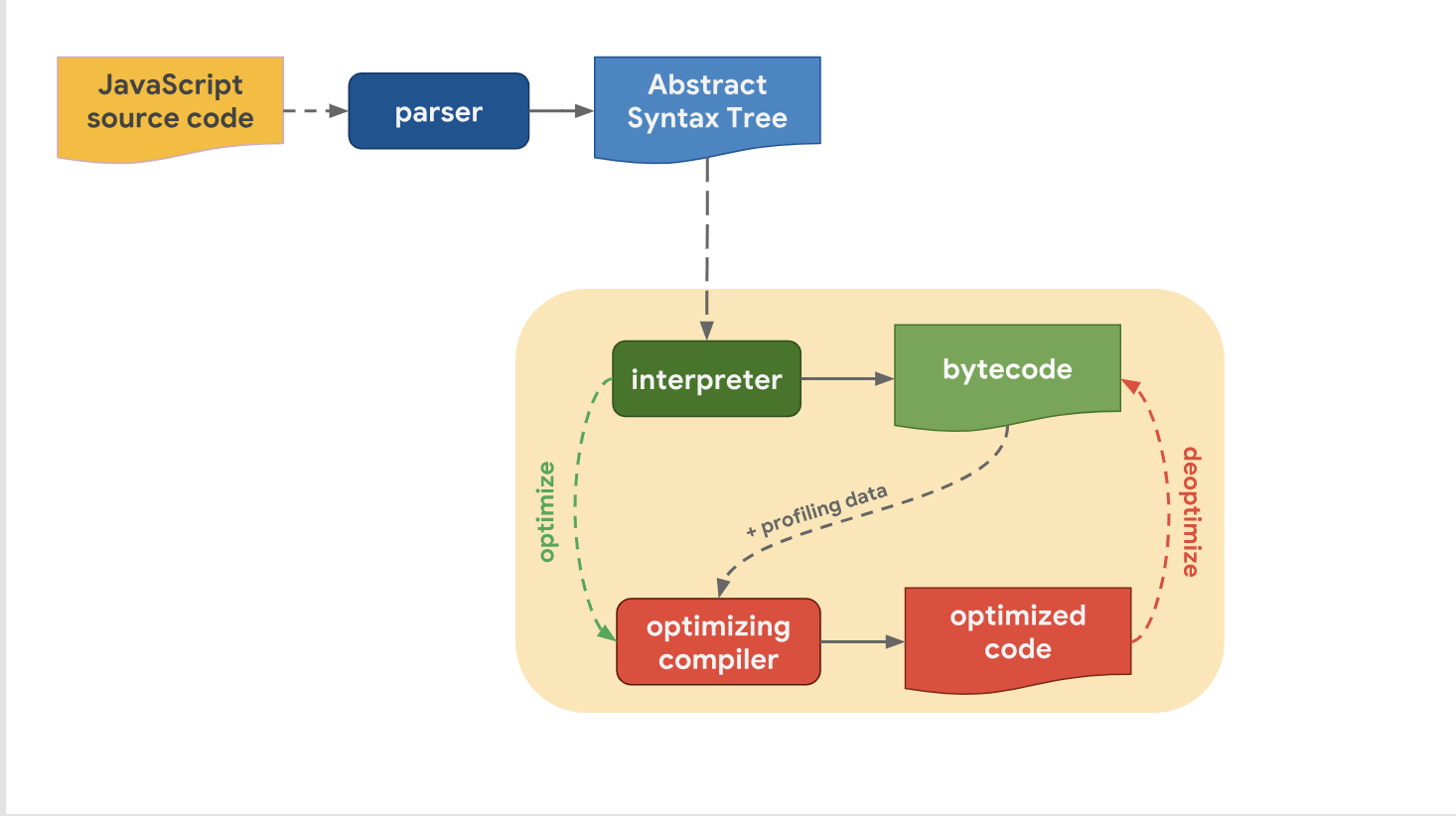
Мы также поняли, что несмотря на то, что пайплайны высокого уровня от движка к движку схожи по своей структуре, существует разница в пайплайне оптимизации. Почему так получается? Почему в некоторые движки имеют больше уровней оптимизации, чем другие? Все дело в принятии компромиссного решения между быстрым переходом к этапу исполнения кода или тратой еще небольшого количества времени на то, чтобы выполнять код с оптимальной производительностью.

Интерпретатор может быстро генерировать байткод, но сам по себе байткод недостаточно эффективен в плане быстродействия. Вовлечение в этот процесс оптимизирующего компилятора тратит некоторое количество времени, но позволяет получить более эффективный машинный код.
Давайте посмотрим на то, как с этим справляется V8. Вспомним, что в V8 интерпретатор называется Зажиганием (Ignition) и он считается самым быстрым интерпретатором среди существующих движков (в вопросах скорости выполнения сырого байткода). Оптимизирующий компилятор в V8 зовется Турбовентилятором (TurboFan) и именно он генерирует высокооптимизированный машинный код.

Компромисс между задержкой запуска и скоростью выполнения является причиной того, почему некоторые движки JavaScript предпочитают добавлять дополнительные уровни оптимизации между этапами. Например, SpiderMonkey добавляет базовый уровень (Baseline tier) между своим интерпретатором и полным оптимизирующим компилятором IonMonkey:
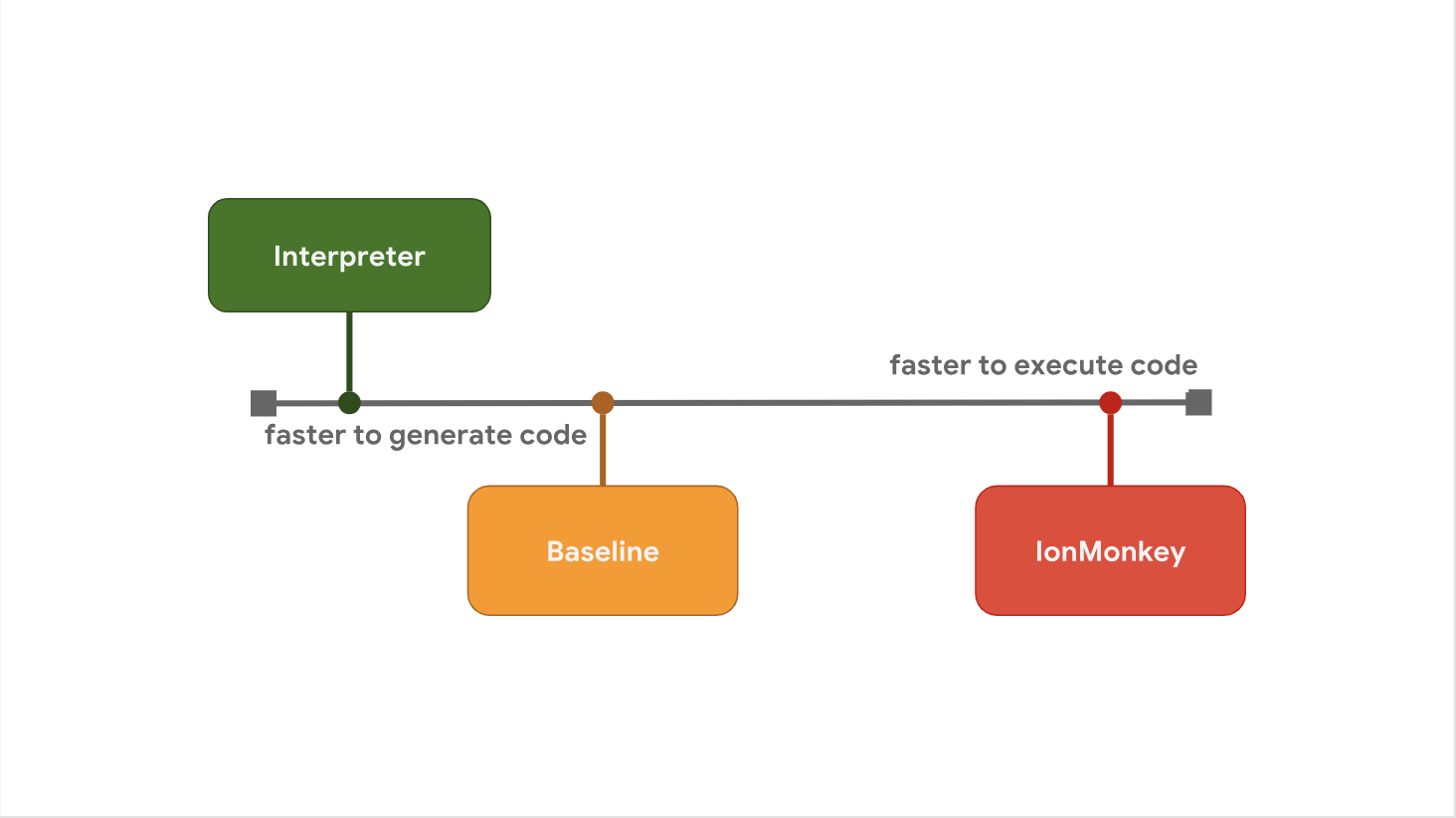
Интерпретатор быстро генерирует байткод, но сам по себе байткод выполняется относительно медленно. Baseline немного дольше генерирует код, но обеспечивает улучшение производительности во время выполнения. Наконец, оптимизирующий компилятор IonMonkey тратит больше всего времени на генерацию машинного кода, но такой код выполняется крайне эффективно.
Давайте посмотрим на конкретный пример и посмотрим, как с этим вопросом разбираются пайплайны различных движков. Здесь в горячем цикле часто повторяется один и тот же код.
V8 начинает с запуска байткода в интерпретаторе Ignition. В какой-то момент движок определяет, что код горячий и запускает интерфейс TurboFan, который занимается интеграцией данных профилирования и построением базового машинного представления кода. Затем он отправляется в оптимизатор TurboFan в другом потоке для дальнейшего улучшения.

Пока происходит оптимизация V8 продолжает выполнять код в Ignition. В какой-то момент, когда оптимизатор закончил и мы получили исполняемый машинный код, он сразу переходит на этап выполнения.
SpyderMonkey также начинает выполнение байткода в интерпретаторе. Но у него есть дополнительный Baseline уровень, а это значит, что горячий код сначала отправляется туда. Baseline компилятор генерирует Baseline код в основном потоке и продолжает исполнение по окончанию его генерации.

Если Baseline код выполняется в течение некоторого времени, SpiderMonkey в конечном итоге запускает интерфейс IonMonkey (IonMonkey frontend) и запускает оптимизатор, процесс очень похож на V8. Все это продолжает работать одновременно в Baseline, пока IonMonkey занимается оптимизацией. Наконец, когда оптимизатор заканчивает свою работу, оптимизированный код выполняется вместо Baseline кода.
Архитектура Chakra очень похожа на SpiderMonkey, но Chakra пытается запустить больше процессов одновременно, чтобы избежать блокировки основного потока. Вместо того, чтобы запускать какую-либо часть компилятора в основном потоке, Chakra копирует байткод и данные профилирования, которые понадобятся компилятору и отправляет их в выделенный процесс компилятора.

Когда сгенерированный код готов, движок выполняет этот SimpleJIT код вместо байткода. То же самое происходит и с FullJIT. Преимуществом такого подхода является то, что пауза, которая происходит при копировании, обычно намного короче по сравнению с запуском полноценного компилятора (frontend). С другой стороны, у этого подхода есть недостаток. Он заключается в том, что эвристика копирования (copy heuristic) может пропустить какую-то информацию, которая потребуется для оптимизации, поэтому можно сказать, что в некоторой степени качество кода жертвуется ради ускорения работы.
В JavaScriptCore все оптимизирующие компиляторы работают полностью параллельно с основным выполнением JavaScript. Здесь отсутствует фаза копирования. Вместо этого основной поток просто запускает компиляцию в другом потоке. Затем компиляторы используют сложную схему блокировки для доступа к данным профилирования из основного потока.

Преимущество такого подхода заключается в том, что он уменьшает количество мусора, появившегося после оптимизации в основном потоке. Недостатком подхода является то, что он требует решения сложных задач многопоточности и некоторых затрат на блокировку для различных операций.
Мы говорили о компромиссах между быстрой генерацией кода при работе интерпретатора и генерацией быстро работающего кода с помощью оптимизирующего компилятора. Но есть еще один компромисс, и он касается использования памяти. Чтобы наглядно показать его, я написал простую программу на JavaScript, которая складывает два числа.
Посмотрите на байткод, который генерируется для функции add интерпретатором Ignition в V8.
Не волнуйтесь о байткоде, вам не обязательно уметь читать его. Здесь надо обратить внимание на то, что в нем всего 4 инструкции.
Когда код становится горячим, TurboFan генерирует высокооптимизированный машинный код, который представлен ниже:
Здесь действительно очень много команд, особенно в сравнении с теми четырьмя, которые мы видели в байткоде. В общем случае байткод гораздо более емкий, чем машинный код, а в особенности оптимизированный машинный код. С другой стороны, байткод исполняется интерпретатором, тогда как оптимизированный код может исполняться непосредственно процессором.
Это одна из причин, почему движки JavaScript не просто «все оптимизируют». Как мы уже видели раньше, генерация оптимизированного машинного кода занимает много времени, а следовательно, ему требуется больше памяти.

Подведем итог: Причина, по которой движки JavaScript имеют разные уровни оптимизации – это поиск компромиссного решения между быстрой генерацией кода с помощью интерпретатора и генерацией быстрого кода с помощью оптимизирующего компилятора. Добавление большего количество уровней оптимизации позволяет принимать более взвешенные решения, основываясь на стоимости дополнительной сложности и накладных расходах при выполнении. Кроме того, существует компромисс между уровнем оптимизации и использованием памяти. Именно поэтому движки JavaScript пытаются оптимизировать только горячие функции.
Оптимизация доступа к свойствам прототипа
В прошлый раз мы говорили о том, как движки JavaScript оптимизируют загрузку свойств объекта используя формы и Inline кэши. Вспомним, что движки хранят формы объектов отдельно от значений объекта.
Формы позволяют использовать оптимизацию с помощью Inline кэшей или сокращенно ICs. При совместной работе формы и ICs могут ускорить повторный доступ к свойствам из одного и того же места в вашем коде.
Вот и подошла к концу первая часть публикации, а о классах и прототипном программировании можно будет узнать во второй части, которую мы опубликуем уже в ближайшие дни. Традиционно ждем ваши комментарии и бурные рассуждения, а также приглашаем на день открытых дверей по курсу «Безопасность информационных систем».
В статье описаны ключевые основы. Они являются общими для всех движков JavaScript, а не только для V8, над которым работают авторы (Бенедикт и Матиас). Как JavaScript разработчик могу сказать, что более глубокое понимание того, как работает движок JavaScript поможет разобраться в том, как писать эффективный код.
В предыдущей статье мы обсуждали то, как движки JavaScript оптимизируют доступ к объектам и массивам с помощью форм и Inline кэшей. В этой статье мы рассмотрим оптимизацию компромиссов пайплайна и ускорение доступа к свойствам прототипа.
Внимание: если вам больше нравится смотреть презентации, чем читать статьи, тогда посмотрите это видео. Если же нет, тогда пропустите его и читайте дальше.
Уровни оптимизации и компромиссы при выполнении
В прошлый раз мы выяснили, что все современные движки JavaScript, по сути, имеют один и тот же пайплайн:
Мы также поняли, что несмотря на то, что пайплайны высокого уровня от движка к движку схожи по своей структуре, существует разница в пайплайне оптимизации. Почему так получается? Почему в некоторые движки имеют больше уровней оптимизации, чем другие? Все дело в принятии компромиссного решения между быстрым переходом к этапу исполнения кода или тратой еще небольшого количества времени на то, чтобы выполнять код с оптимальной производительностью.
Интерпретатор может быстро генерировать байткод, но сам по себе байткод недостаточно эффективен в плане быстродействия. Вовлечение в этот процесс оптимизирующего компилятора тратит некоторое количество времени, но позволяет получить более эффективный машинный код.
Давайте посмотрим на то, как с этим справляется V8. Вспомним, что в V8 интерпретатор называется Зажиганием (Ignition) и он считается самым быстрым интерпретатором среди существующих движков (в вопросах скорости выполнения сырого байткода). Оптимизирующий компилятор в V8 зовется Турбовентилятором (TurboFan) и именно он генерирует высокооптимизированный машинный код.
Компромисс между задержкой запуска и скоростью выполнения является причиной того, почему некоторые движки JavaScript предпочитают добавлять дополнительные уровни оптимизации между этапами. Например, SpiderMonkey добавляет базовый уровень (Baseline tier) между своим интерпретатором и полным оптимизирующим компилятором IonMonkey:
Интерпретатор быстро генерирует байткод, но сам по себе байткод выполняется относительно медленно. Baseline немного дольше генерирует код, но обеспечивает улучшение производительности во время выполнения. Наконец, оптимизирующий компилятор IonMonkey тратит больше всего времени на генерацию машинного кода, но такой код выполняется крайне эффективно.
Давайте посмотрим на конкретный пример и посмотрим, как с этим вопросом разбираются пайплайны различных движков. Здесь в горячем цикле часто повторяется один и тот же код.
let result = 0;
for (let i = 0; i < 4242424242; ++i) {
result += i;
}
console.log(result);V8 начинает с запуска байткода в интерпретаторе Ignition. В какой-то момент движок определяет, что код горячий и запускает интерфейс TurboFan, который занимается интеграцией данных профилирования и построением базового машинного представления кода. Затем он отправляется в оптимизатор TurboFan в другом потоке для дальнейшего улучшения.
Пока происходит оптимизация V8 продолжает выполнять код в Ignition. В какой-то момент, когда оптимизатор закончил и мы получили исполняемый машинный код, он сразу переходит на этап выполнения.
SpyderMonkey также начинает выполнение байткода в интерпретаторе. Но у него есть дополнительный Baseline уровень, а это значит, что горячий код сначала отправляется туда. Baseline компилятор генерирует Baseline код в основном потоке и продолжает исполнение по окончанию его генерации.
Если Baseline код выполняется в течение некоторого времени, SpiderMonkey в конечном итоге запускает интерфейс IonMonkey (IonMonkey frontend) и запускает оптимизатор, процесс очень похож на V8. Все это продолжает работать одновременно в Baseline, пока IonMonkey занимается оптимизацией. Наконец, когда оптимизатор заканчивает свою работу, оптимизированный код выполняется вместо Baseline кода.
Архитектура Chakra очень похожа на SpiderMonkey, но Chakra пытается запустить больше процессов одновременно, чтобы избежать блокировки основного потока. Вместо того, чтобы запускать какую-либо часть компилятора в основном потоке, Chakra копирует байткод и данные профилирования, которые понадобятся компилятору и отправляет их в выделенный процесс компилятора.
Когда сгенерированный код готов, движок выполняет этот SimpleJIT код вместо байткода. То же самое происходит и с FullJIT. Преимуществом такого подхода является то, что пауза, которая происходит при копировании, обычно намного короче по сравнению с запуском полноценного компилятора (frontend). С другой стороны, у этого подхода есть недостаток. Он заключается в том, что эвристика копирования (copy heuristic) может пропустить какую-то информацию, которая потребуется для оптимизации, поэтому можно сказать, что в некоторой степени качество кода жертвуется ради ускорения работы.
В JavaScriptCore все оптимизирующие компиляторы работают полностью параллельно с основным выполнением JavaScript. Здесь отсутствует фаза копирования. Вместо этого основной поток просто запускает компиляцию в другом потоке. Затем компиляторы используют сложную схему блокировки для доступа к данным профилирования из основного потока.
Преимущество такого подхода заключается в том, что он уменьшает количество мусора, появившегося после оптимизации в основном потоке. Недостатком подхода является то, что он требует решения сложных задач многопоточности и некоторых затрат на блокировку для различных операций.
Мы говорили о компромиссах между быстрой генерацией кода при работе интерпретатора и генерацией быстро работающего кода с помощью оптимизирующего компилятора. Но есть еще один компромисс, и он касается использования памяти. Чтобы наглядно показать его, я написал простую программу на JavaScript, которая складывает два числа.
function add(x, y) {
return x + y;
}
add(1, 2);Посмотрите на байткод, который генерируется для функции add интерпретатором Ignition в V8.
StackCheck
Ldar a1
Add a0, [0]
ReturnНе волнуйтесь о байткоде, вам не обязательно уметь читать его. Здесь надо обратить внимание на то, что в нем всего 4 инструкции.
Когда код становится горячим, TurboFan генерирует высокооптимизированный машинный код, который представлен ниже:
leaq rcx,[rip+0x0]
movq rcx,[rcx-0x37]
testb [rcx+0xf],0x1
jnz CompileLazyDeoptimizedCode
push rbp
movq rbp,rsp
push rsi
push rdi
cmpq rsp,[r13+0xe88]
jna StackOverflow
movq rax,[rbp+0x18]
test al,0x1
jnz Deoptimize
movq rbx,[rbp+0x10]
testb rbx,0x1
jnz Deoptimize
movq rdx,rbx
shrq rdx, 32
movq rcx,rax
shrq rcx, 32
addl rdx,rcx
jo Deoptimize
shlq rdx, 32
movq rax,rdx
movq rsp,rbp
pop rbp
ret 0x18Здесь действительно очень много команд, особенно в сравнении с теми четырьмя, которые мы видели в байткоде. В общем случае байткод гораздо более емкий, чем машинный код, а в особенности оптимизированный машинный код. С другой стороны, байткод исполняется интерпретатором, тогда как оптимизированный код может исполняться непосредственно процессором.
Это одна из причин, почему движки JavaScript не просто «все оптимизируют». Как мы уже видели раньше, генерация оптимизированного машинного кода занимает много времени, а следовательно, ему требуется больше памяти.
Подведем итог: Причина, по которой движки JavaScript имеют разные уровни оптимизации – это поиск компромиссного решения между быстрой генерацией кода с помощью интерпретатора и генерацией быстрого кода с помощью оптимизирующего компилятора. Добавление большего количество уровней оптимизации позволяет принимать более взвешенные решения, основываясь на стоимости дополнительной сложности и накладных расходах при выполнении. Кроме того, существует компромисс между уровнем оптимизации и использованием памяти. Именно поэтому движки JavaScript пытаются оптимизировать только горячие функции.
Оптимизация доступа к свойствам прототипа
В прошлый раз мы говорили о том, как движки JavaScript оптимизируют загрузку свойств объекта используя формы и Inline кэши. Вспомним, что движки хранят формы объектов отдельно от значений объекта.
Формы позволяют использовать оптимизацию с помощью Inline кэшей или сокращенно ICs. При совместной работе формы и ICs могут ускорить повторный доступ к свойствам из одного и того же места в вашем коде.
Вот и подошла к концу первая часть публикации, а о классах и прототипном программировании можно будет узнать во второй части, которую мы опубликуем уже в ближайшие дни. Традиционно ждем ваши комментарии и бурные рассуждения, а также приглашаем на день открытых дверей по курсу «Безопасность информационных систем».
MaxRokatansky Автор
Хотелось бы узнать мнение тех, кто минусует статью. Напишите пожалуйста, чем именно она вам не зашла?
Nikulio
Спасибо большое за ваш цикл статей!
Бывают неточности в переводе, но в целом на твёрдую четверку!)
MaxRokatansky Автор
Большое спасибо. Приятно читать положительные отзывы. Над качеством переводов мы работаем и стараемся свести все неточности к минимуму. Но всегда присутствует человеческий фактор, который, конечно, нельзя исключать.