
Не так давно я столкнулся с довольно простой и одновременно интересной задачей: реализация read-only терминала в веб приложении. Интереса задаче придавали три важных аспекта:
- поддержка основных ANSI Escape sequences
- поддержка минимум 50 000 строк данных
- отображение данных по мере их поступления.
В данной статье я расскажу о том, как это реализовывал и как потом всё это оптимизировал.
Disclaimer: я не являюсь опытным web разработчиком, поэтому некоторые вещи могут показаться вам очевидными, а выводы или решения ошибочными. За исправления и пояснения я буду благодарен.
Для чего это затевалось
Задача целиком выглядит следующим образом: на сервере работает скрипт (bash, python, и т.п.) и что-то пишет в stdout. И этот вывод нужно отображать на веб странице по мере его поступления. При этом он должен выглядеть как на терминале (с форматированием, переносами курсора и т.п.)
Сам скрипт и его выходные данные я никак не контролирую и отображаю в чистом виде.
Разумеется между веб интерфейсом и скриптом должен быть посредник — веб сервер. И если не лукавить — веб приложение и сервер у меня уже есть и худо-бедно работают. Схема выглядит примерно следующим образом:

Но раньше ответственным за обработку и форматирование был сервер. И хотелось это улучшить по большому ряду причин:
- двойная обработка данных — сперва разбор на сервере, потом трансформация в html компоненты на клиенте
- неоптимальность алгоритма из-за подготовки данных для клиента
- большая нагрузка на сервер — обработка вывода от одного скрипта могла полностью загрузить единственный поток на сервере
- неполная поддержка ANSI Escape sequences
- трудноуловимые баги
- клиент очень плохо справлялся с отображением даже 10к форматированных строк
Поэтому было решено всю логику парсинга перенести в веб приложение, а серверу оставить только потоковую отдачу необработанных данных
Постановка задачи
На клиент приходят части текста. Клиент должен их разобрать на составляющие: обычный текст, перенос строки, возвращение каретки и специальные ANSI команды. Гарантий в целостности частей нет — одна команда или слово может прийти в разных пакетах.
ANSI команды могут влиять на формат текста (цвет, фон, стиль), положение курсора (откуда должен выводиться последующий текст) или делать очистку части экрана.
Пример того, как это выглядит:

Кроме того, среди текста могут быть URL, которые также необходимо распознавать и подсвечивать.
Берём готовую библиотеку и ...
Я понимал, что правильная и быстрая обработка всех команд — это дело непростое. Поэтому решил поискать уже готовую библиотеку. И, о чудо, буквально сразу наткнулся на xterm.js. Готовый компонент терминала, который уже много где используется и, вдобавок, "is really fast, it even includes a GPU-accelerated renderer". Последнее было для меня самым важным, т.к. хотелось наконец получить очень быстрый клиент.
Несмотря на то, что я люблю писать собственные велосипеды, я был крайне рад, что могу не только сэкономить время, но и бесплатно получить кучу полезного функционала.
На попытки подключить терминал у меня ушло 2 вечера и я с этим не справился. Совсем.
Разная высота строк, кривое выделение, адаптивный размер терминала, очень странное API, отстутсвие вменяемой документации…
Но у меня ещё оставалось немного воодушевления и я верил, что смогу разобраться с этими проблемами.
Пока я не скормил в терминал свои тестовые 10к строк… Он умер. И похоронил с собой остатки моих надежд.
Описание итогового алгоритма
Первым делом, я скопипастил текущий алгоритм, реализованный на python, и адаптировал его под javascript (всего-то удаление фигурных скобок и другой синтакс у for).
Я знал все основные плюсы и минусы старого алгоритма, поэтому мне требовалось только улучшить неэффектиные места в нём.
После обдумывания, проб и ошибок, я остановился на следующем варианте: делим алгоритм на 2 составляющие:
- модель, для разбора текста и хранения текущего состояния "терминала"
- отображение, которое переводит модель в HTML
Модель (структура и алгоритм)
- Все строки хранятся в массиве (номер строки = индекс в массиве)
- Стили текста хранятся в отдельном массиве
- Текущее положение курсора хранится и может изменяться командами
- Сам алгоритм посимвольно проверяет входящие данные:
- Если это просто текст, добавляем в текущую строку
- Если перенос строки, то увеличиваем текущий индекс строки
- Если этот один из символов команды, то кладём его в буфер команды и ждём следующий символ
- Если буфер команды правильный, то запускаем эту команду, иначе пишем этот буфер как текст
- Модель оповещает слушателей о том, какие строки изменились после обработки входящего текста
В моей реализации сложность алгоритма получается O(n log n), где log n это подготовка измененных строк для оповещения (уникальность и сортировка). Во время написания этой статьи, я понял, что для частного случая можно избавиться от log n, поскольку строки чаще всего добавляются в конец.
Отображение
- Отображает текст в виде HTML элементов
- Если строка изменилась, полностью заменяет все элементы строки
- Разбивает каждую строку исходя из стилей: каждый стилизованный отрезок имеет свой элемент
При такой структуре тестирование это довольно простая задача — передаём текст в модель (единым пакетом или по частям) и просто проверяем текущее состояние всех строк и стилей в ней. А для отображения достаточно всего нескольких тестов, т.к. оно всегда перерисовывает изменившиеся строки.
Важным преимуществом также является некая ленивость отображения. Если в одном куске текста мы перезаписываем одну и ту же строку (например, прогресс бар), то после работы модели, для отображения это будет выглядеть как одна изменившаяся строка.
DOM vs Canvas
Хотелось бы немного остановиться на том, почему я выбрал DOM, хотя целью была производительность. Ответ прост — лень. Для меня отрисовка всего в Canvas самостоятельно выглядит довольно сложной задачей. При сохранении usability: выделение, копирование, изменение размера экрана, опрятного вида и т.п. Пример xterm.js мне наглядно показал, что это совсем непросто. Их отрисовка в canvas'е была далеко не идеальной.
Кроме того, отлаживаение DOM дерева в браузере и возможность покрытия юнит тестами — это немаловажное преимущество.
В конце концов, моей целью было 50к строк, и я знал, что DOM с этим должен был справиться, на основании работы старого алгоритма.
Оптимизации
Алгоритм был готов, отлажен и медленно, но верно работал. Пора было открывать профилировщик и оптимизировать. Забегая вперёд, скажу что большая часть оптимизаций была для меня сюрпризом (как это обычно и бывает).
Профилирование проводилось на 10к строк, каждая из которых содержала стилизованные элементы. Общее число DOM элементов около 100к.
Никаких специальных подходов и инструментов не использовалось. Только Chrome Dev Tools и пара запусков на каждый замер. На практике, в запусках отличались только абсолютные значения замеров (сколько секунд на выполнение), но не процентное соотношение между методами. Поэтому, считаю такую методику условно-достаточной.
Ниже хотелось бы подробнее остановиться на самых интересных улучшениях. И для начала график того, что было:

Все графики профилирования были построены уже после реализации, путём деоптимизации кода по-памяти.
string.trim
Первым делом я наткнулся на непонятный string.trim, который съедал очень заметное количество CPU (мне кажется это было в районе 10-20%)

trim() — это базовая функция языка. Почему для неё используется какая-то библиотека? И даже если это какой-то polyfill, то почему он включился на последней версии хрома?
Немного гугления и ответ найден: https://babeljs.io/docs/en/babel-preset-env. По-умолчанию он включает polyfill для довольно большого количества браузеров, и делает это на этапе компиляции. Решением для меня было указать 'targets': '> 0.25%, not dead'
Но в конечном этоге я удалил вызов trim совсем, за ненадобностью.
Vue.js
В прошлом году я перевел компонент терминала на Vue.js. Теперь пришлось перевести его обратно на ваниллу, причина на скриншоте ниже (смотреть количество строк с участием Vue.js):
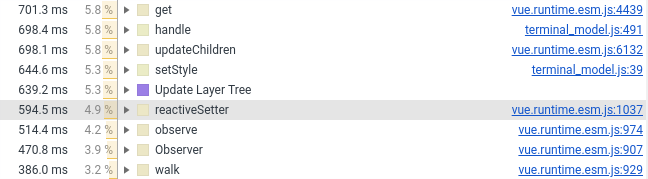
Я оставил во Vue компоненте только обертку, стили и обработку мыши. Всё что относится к созданию DOM элементов ушло в чистый JS, который подключается во Vue компонент как обычное поле (которое не отслеживается фреймворком).
created() {
this.terminalModel = new TerminalModel();
this.terminal = new Terminal(this.terminalModel);
},Я не считаю это минусом или недоработкой Vue.js. Просто фреймворки и перфоманс сами по себе плохо сочетаются. Ну а когда вы в реактивный фреймворк закидываете десятки и сотни тысяч объектов, очень трудно от него ожидать обработки в течении пары миллисекунд. И, честно говоря, я даже удивлен, что Vue.js довольно хорошо справился.
Добавление новых элементов
Тут всё просто — если у вас несколько тысяч новых элементов и вы хотите их добавить в родительский компонент, делать appendChild не самая удачная идея. Браузеру приходится чуть чаще делать обработку и больше времени тратить на отрисовку. Одним из побочных эффектов в моём случае было замедление автоскролла, т.к. он принудительно вызывает пересчет всех добавленных компонентов.

Чтобы решить проблему, существует DocumentFragment. Сперва добавляем все элементы в него, а потом его самого в родительский компонент. Браузер позаботится об инлайне входящих компонентов.
Данный подход снижает количество времени, которое браузер тратит на отрисовку и расположение элементов.
Я также пробовал и другие способы ускорения добавления элементов. Ни один из них не мог ничего добавить поверх DocumentFragment.
span vs div
На самом деле это можно было назвать display:inline (span) vs display:block (div).
Изначально у меня каждая строка была в span и оканчивалась символом переноса строки. Однако с точки зрения производительности это не очень эффективно: браузеру приходится рассчитывать где элемент начинается и заканчивается. С display:block такие подсчёты гораздо проще.
Замена на div ускорила отрисовку почти в 2 раза.
К сожалению, в случае display:block выделение нескольких строк текста выглядит хуже:

Я долго не мог решить, что лучше — лишние 2 секунды отрисовки или человеческое выделение. В итоге практичность победила красоту.
Мастер CSS 10-го уровня
Ещё ~10% времени отрисовки удалось срезать "оптимизацией" CSS, который у меня используется для форматирования текста.
Против меня сыграла неопытность в веб разработке и понимания основ. Я думал, что чем точнее селекторы, тем лучше, однако конкретно в моем случае это было не так.
Для форматирования текста в терминале я использовал такие селекторы:
#script-panel-container .log-content > div > span.text_color_green,Но (в хроме), следующий вариант немного шустрее:
span.text_color_greenТакой селектор мне не очень нравится, т.к. слишком глобальный, но производительность дороже.
string.split
Если у вас возникло дежавю из-за одного из предыдущих пунктов, то оно ложное. На этот раз речь не о polyfill, а о стандартной реализации в хроме:

(я обернул string.split в defSplit, чтобы функция показывалась в профилировщике)
1% это мелочи. Но велосипедист-идеалист во мне не давал покоя. В моём случае split всегда делается по одному символу и без каких-либо регулярок. Поэтому я реализовал простой вариант. Вот результат:

function fastSplit(str, separatorChar) {
if (str === '') {
return [''];
}
let result = [];
let lastIndex = 0;
for (let i = 0; i < str.length; i++) {
const char = str[i];
if (char === separatorChar) {
const chunk = str.substr(lastIndex, i - lastIndex);
lastIndex = i + 1;
result.push(chunk);
}
}
if (lastIndex < str.length) {
const lastChunk = str.substr(lastIndex, str.length - lastIndex);
result.push(lastChunk);
}
return result;
}Я считаю, что после такого, меня обязаны брать в команду Google Chrome без собеседования.
Оптимизация, послесловие
Оптимизация это процесс без конца и можно что-то улучшать до бесконечности. Особенно учитывая, что разные use case требуют различных (и противоречивых) оптимизаций.
Для моего случая, я выбрал основной use case и оптимизировал его время работы с 15 сек до 5 сек. На этом я решил остановиться.

Осталась ещё пара мест, которые я планирую улучшить, но это уже благодаря полученному опыту.
Бонус. Мутационное тестирование.
Так получилось, что за последние несколько месяцев я часто сталкивался с термином "мутационное тестирование". И решил, что данная задача это отличный способ попробовать этого зверя. Особенно после того, как у меня не завелся code coverage в Webstorm, для тестов на карме.
Поскольку и техника и библиотека для меня новы, я решил обойтись малой кровью: тестировать только один компонент — модель. В таком случае явно можно указать какой файл тестируем, и какой набор тестов для него предназначен.
Но как ни крути, пришлось немало повозиться, чтобы добиться интеграции с кармой и вебпаком.
В конце концов всё завелось и спустя полчаса я увидел печальные результаты: около половины мутантов выжило. Часть я убил сразу, часть оставил на будущее (когда реализовывал недостающие ANSI команды).
После этого лень победила, и на текущий момент результаты выглядят следующим образом (для 128 тестов):
Ran 79.04 tests per mutant on average.
------------------|---------|----------|-----------|------------|---------|
File | % score | # killed | # timeout | # survived | # error |
------------------|---------|----------|-----------|------------|---------|
terminal_model.js | 73.10 | 312 | 25 | 124 | 1 |
------------------|---------|----------|-----------|------------|---------|
23:01:08 (18212) INFO Stryker Done in 26 minutes 32 seconds.В целом данный подход мне показался очень полезным (явно лучше, чем code coverage) и забавным. Единственный минус это жутко долгое время работы — 30 минут на один класс это перебор.
И самое главное — этот подход заставил меня ещё раз задуматься о 100% покрытии и стоит ли абсолютно всё покрывать тестами: теперь моё мнение ещё ближе к "да", при ответе на этот вопрос.
Заключение
Оптимизация производительности, на мой взгляд, это хороший способ узнать что-то глубже. А также это неплохая разминка для мозга. И очень жаль, что это редко когда действительно нужно (по крайней мере в моих проектах).
И как всегда подход "сперва профилирование, потом оптимизация" работает гораздо лучше, чем интуиция.
Ссылки
Старая реализация:
Новая реализация:
К сожалению демо веб-компонента нет, поэтому просто так его потыкать у вас не получится. Так что заранее извиняюсь
Спасибо за уделённое время, буду рад замечаниям, предложениям и разумной критике!
Комментарии (20)

dmitryredkin
15.04.2019 16:24А почему бы не использовать уже готовые средства проброса консоли или ssh в web (shellinabox, GateOne, guacamole etc)?
bugy Автор
15.04.2019 16:56Вы, скорее всего, имеете ввиду весь инструмент целиком: включая вызов скрипта на сервере, веб сервер и клиентскую часть. Это немного отдельная тема (данная статья исключительно о реализации read-only терминала на JS/HTML).
Если говорить об инструменте целиком, то проброс консоли это для админов. Мой инструмент для нетехнических пользователей, которым нужно в красивом виде дать доступ к заранее подготовленным скриптам. Максимально ограничив доступ и возможности пользователей.
Использовать же эти компоненты исключительно как UI библиотеку, вряд ли есть смысл. Например, GateOne также подготавливает данные на сервере и, я подозреваю, отображает всё в режиме терминала (т.е. 80x25 символов), что не очень удобно для просмотра и работы пользователя.
LEXA_JA
15.04.2019 17:08А вы пробовали спользовать виртуализацию скролла? Должно помочь с производительностью в случае такого количества строк.
bugy Автор
15.04.2019 17:16Спасибо за совет. Я рассматривал такой подход, но при этом теряется возможность выделить и копировать весь текст.
В будущем я планирую добавить такую функциональность, но сделать её опциональной (для вывода в более чем 10к строк, например) или настраиваемой.
berg_aa
16.04.2019 09:57Браузер читает CSS селекторы справа-налево. Чем глубже вложенность селекторов, тем «тяжелее» браузеру парсить стили.

abar
16.04.2019 11:01Буквально вчера надо было проглядывать большое количество логов с нашего сервера, которое у нас реализовано очень просто: вот тебе ссылка на plain text в браузере, листай как хочешь. Приходилось копировать в Sublime что бы хоть как-то беречь глаза.
Интересно, можно ли приспособить это решение (или существует ли что-то, что хорошо сочеталось бы со Spring-ом) для удобного просмотра логов?bugy Автор
16.04.2019 11:21Если брать Script server целиком (для которого я делал отображение в веб), то его можно использовать в том числе и для этой задачи. Но что-то более специализированное будет более удобным, скорее всего.
Вот, например, гугл предлагает такое: http://logio.org/

amarao
16.04.2019 15:52Список того, что должно работать в консоли. Мы как-то писали server-side renderer с дифференциальными апдейтами на клиенте (https://github.com/selectel/pyte) так что говорю по больному.
1. mc (особое внимание на диалоги и меню)
2. aptitude (и другие dialog)
3. adom (консольная версия)
4. nethack
5. mplayer в ascii режиме
В частности, благодаря adom'у я узнал, что «ярко-чёрный по чёрному» — это вполне различимо (горы и всё такое).bugy Автор
16.04.2019 17:17У меня пока не стоит задача делать полноценный терминал (с режимами отображения, разрешением и т.п.), а только основные команды для потокового вывода, т.е. лог работы скрипта.
Причина тому — я сфокусирован на инструменте для нетехнических пользователей, и, терминал, по-моему мнению им не очень нужен.
Из-за отсутствия поддержки размеров окна, режимов отображения и т.п., mc и mplayer у меня отображаются криво: они указывают размер терминала и потом делают перевод курсора исходя из размера окна. Но у меня переход вне предела уже выведенного текста невозможен.


CoolCmd
ээээ а какой из этих вариантов хуже? :)
bugy Автор
Для меня правый (display:block) вариант хуже, т.к. появляется зазор между выделяемыми строками.
По крайней мере такое выделение я наблюдаю в текстовых редакторах и в десктоп терминалах.
Но вы конечно правы, это может быть делом вкуса :)
CoolCmd
откуда у div берется этот зазор?
bugy Автор
Я так понимаю это фича браузера — показывать, что два разных div это совершенно независимые блоки
beetleinweb
Увеличьте высоту строки и сократите межстрочное расстояние до нуля. Если не ошибаюсь, получите справа примерно то же самое, что и слева.
bugy Автор
Спасибо за совет, я пробовал, но не получилось сохранить межстрочное расстояние (для облегчения читаемости) и убрать зазор.
Может быть недостаточно пробовал
CoolCmd
нет. если margin и line-height не задирать, то и зазора не будет.
bugy Автор
В том-то и дело, что с помощью margin/line-height можно добиться отсутствия зазора, однако это именно добиться: для этого нужно их сделать достаточно низкими, чтобы выделения строк пересекались.
Т.е. таким способом оставить большое межстрочное расстояние и одновременно убрать зазор в выделении не получится.
А у span'ов, благодаря их inline структуре, такой же line-height работает как следует.
Пример:
https://jsfiddle.net/wxg0dn39/