
Так получилось, что я провожу довольно много собеседований на должность веб-программиста. Один из обязательных вопросов, который я задаю — это чем отличается INNER JOIN от LEFT JOIN.
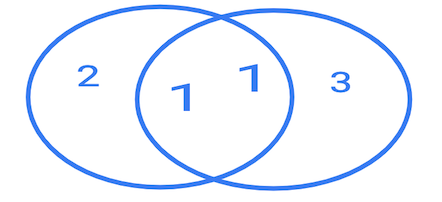
Чаще всего ответ примерно такой: "inner join — это как бы пересечение множеств, т.е. остается только то, что есть в обеих таблицах, а left join — это когда левая таблица остается без изменений, а от правой добавляется пересечение множеств. Для всех остальных строк добавляется null". Еще, бывает, рисуют пересекающиеся круги.
Я так устал от этих ответов с пересечениями множеств и кругов, что даже перестал поправлять людей.
Дело в том, что этот ответ в общем случае неверен. Ну или, как минимум, не точен.
Давайте рассмотрим почему, и заодно затронем еще парочку тонкостей join-ов.
Во-первых, таблица — это вообще не множество. По математическому определению, во множестве все элементы уникальны, не повторяются, а в таблицах в общем случае это вообще-то не так. Вторая беда, что термин "пересечение" только путает.
(Update. В комментах идут жаркие споры о теории множеств и уникальности. Очень интересно, много нового узнал, спасибо)
INNER JOIN
Давайте сразу пример.
Итак, создадим две одинаковых таблицы с одной колонкой id, в каждой из этих таблиц пусть будет по две строки со значением 1 и еще что-нибудь.
INSERT INTO table1
(id)
VALUES
(1),
(1)
(3);
INSERT INTO table2
(id)
VALUES
(1),
(1),
(2);Давайте, их, что ли, поджойним
SELECT *
FROM table1
INNER JOIN table2
ON table1.id = table2.id;Если бы это было "пересечение множеств", или хотя бы "пересечение таблиц", то мы бы увидели две строки с единицами.
На практике ответ будет такой:
| id | id | | --- | --- | | 1 | 1 | | 1 | 1 | | 1 | 1 | | 1 | 1 |
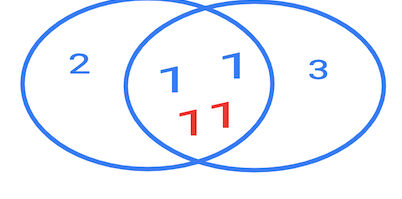
Но как??
Для начала рассмотрим, что такое CROSS JOIN. Вдруг кто-то не в курсе.
CROSS JOIN — это просто все возможные комбинации соединения строк двух таблиц. Например, есть две таблицы, в одной из них 3 строки, в другой — 2:
select * from t1;id ---- 1 2 3
select * from t2;id ---- 4 5
Тогда CROSS JOIN будет порождать 6 строк.
select *
from t1
cross join t2; id | id ----+---- 1 | 4 1 | 5 2 | 4 2 | 5 3 | 4 3 | 5
Так вот, вернемся к нашим баранам.
Конструкция
t1 INNER JOIN t2 ON condition— это, можно сказать, всего лишь синтаксический сахар к
t1 CROSS JOIN t2 WHERE conditionТ.е. по сути INNER JOIN — это все комбинации соединений строк с неким фильтром condition. В общем-то, можно это представлять по разному, кому как удобнее, но точно не как пересечение каких-то там кругов.
Небольшой disclaimer: хотя inner join логически эквивалентен cross join с фильтром, это не значит, что база будет делать именно так, в тупую: генерить все комбинации и фильтровать. На самом деле там более интересные алгоритмы.
LEFT JOIN
Если вы считаете, что левая таблица всегда остается неизменной, а к ней присоединяется или значение из правой таблицы или null, то это в общем случае не так, а именно в случае когда есть повторы данных.
Опять же, создадим две таблицы:
insert into t1
(id)
values
(1),
(1),
(3);
insert into t2
(id)
values
(1),
(1),
(4),
(5);Теперь сделаем LEFT JOIN:
SELECT *
FROM t1
LEFT JOIN t2
ON t1.id = t2.id;Результат будет содержать 5 строк, а не по количеству строк в левой таблице, как думают очень многие.
| id | id | | --- | --- | | 1 | 1 | | 1 | 1 | | 1 | 1 | | 1 | 1 | | 3 | |
Так что, LEFT JOIN — это тоже самое что и INNER JOIN (т.е. все комбинации соединений строк, отфильтрованных по какому-то условию), и плюс еще записи из левой таблицы, для которых в правой по этому фильтру ничего не совпало.
LEFT JOIN можно переформулировать так:
SELECT *
FROM t1
CROSS JOIN t2
WHERE t1.id = t2.id
UNION ALL
SELECT t1.id, null
FROM t1
WHERE NOT EXISTS (
SELECT
FROM t2
WHERE t2.id = t1.id
)Сложноватое объяснение, но что поделать, зато оно правдивее, чем круги с пересечениями и т.д.
Условие ON
Удивительно, но по моим ощущениям 99% разработчиков считают, что в условии ON должен быть id из одной таблицы и id из второй. На самом деле там любое булево выражение.
Например, есть таблица со статистикой юзеров users_stats, и таблица с ip адресами городов.
Тогда к статистике можно прибавить город
SELECT s.id, c.city
FROM users_stats AS s
JOIN cities_ip_ranges AS c
ON c.ip_range && s.ipгде && — оператор пересечения (см. расширение посгреса ip4r)
Если в условии ON поставить true, то это будет полный аналог CROSS JOIN
"table1 JOIN table2 ON true" == "table1 CROSS JOIN table2"Производительность
Есть люди, которые боятся join-ов как огня. Потому что "они тормозят". Знаю таких, где есть полный запрет join-ов по проекту. Т.е. люди скачивают две-три таблицы себе в код и джойнят вручную в каком-нибудь php.
Это, прямо скажем, странно.
Если джойнов немного, и правильно сделаны индексы, то всё будет работать быстро. Проблемы будут возникать скорее всего лишь тогда, когда у вас таблиц будет с десяток в одном запросе. Дело в том, что планировщику нужно определить, в какой последовательности осуществлять джойны, как выгоднее это сделать.
Сложность этой задачи O(n!), где n — количество объединяемых таблиц. Поэтому для большого количества таблиц, потратив некоторое время на поиски оптимальной последовательности, планировщик прекращает эти поиски и делает такой план, какой успел придумать. В этом случае иногда бывает выгодно вынести часть запроса в подзапрос CTE; например, если вы точно знаете, что, поджойнив две таблицы, мы получим очень мало записей, и остальные джойны будут стоить копейки.
Кстати, Еще маленький совет по производительности. Если нужно просто найти элементы в таблице, которых нет в другой таблице, то лучше использовать не 'LEFT JOIN… WHERE… IS NULL', а конструкцию EXISTS. Это и читабельнее, и быстрее.
Выводы
Как мне кажется, не стоит использовать диаграммы Венна для объяснения джойнов. Также, похоже, нужно избегать термина "пересечение".
Как объяснить на картинке джойны корректно, я, честно говоря, не представляю. Если вы знаете — расскажите, плиз, и киньте в коменты. А мы обсудим это в одном из ближайших выпусков подкаста "Цинковый прод". Не забудьте подписаться.
Update. Кто минусует — отпишитесь плиз, почему. Спасибо за фидбэк.
Комментарии (190)

SerafimArts
17.04.2019 22:21+1А можно, пожалуйста, для тех кто в танке, что означает вот это условие, что вы привели в качестве примера?
JOIN cities_ip_ranges AS c ON c.ip_range && s.ip
Я, конечно, посмотрел по ссылочке но всё равно не понял прикола. Мне казалось, что "&&" — это обычный алиас на AND, а значит, перефразируя на русский ON условие звучит так: «где c.ip_range кастуется в true И s.ip кастуется в true», т.е. что-то вроде такого:
... ON CAST(c.ip_range AS BOOLEAN) AND CAST(s.ip AS BOOLEAN)
А дальше моя логическая цепочка привела в тупик, так что решил всё же спросить.
varanio Автор
17.04.2019 22:33+4В postgresql можно делать свои расширения. По сути, расширение — это набор инструкций, определяющих новые типы данных и операторы для работы со значениями типов
В данном случае в расширении ip4r определены типы ip4 и ip4r, т.е. ip адрес и диапазон ip адресов. А также оператор &&, который для этих типов определен как "пересечение". То есть, если диапазоны пересекаются, то результат операции будет true
В данном случае && не имеет отношения к and
Завтра запилю более подробный пример, щас с телефона неудобно
SerafimArts
17.04.2019 22:36+1Понял, это что-то вроде
WHERE s.ip IN c.ip_rangeполучается. Спасибо за объяснение.

Melkij
18.04.2019 09:54+1Мне казалось, что "&&" — это обычный алиас на AND
Этого нет в стандарте. Поэтому поведение необходимо уточнять для каждой СУБД. Где-то это будет алиас для AND, где-то вообще не будет. В postgresql — оператор строго зависит от типов данных операндов. Есть create operator и можете сами на некоторую последовательность символов приклеить любую логику, в том числе можно даже переопределить штатные операторы (операторы ищутся тоже в порядке search_path если не указаны через pg_operator синтаксис).
Например, в чистом postgresql 11 есть 8 разных операторов &&, для разных типов данных операндов.

MarazmDed
17.04.2019 22:32+13Во-первых, таблица — это вообще не множество.
Во первых, множество.
По математическому определению, во множестве все элементы уникальны, не повторяются
Кто вам сказал такую глупость? Множество — это просто совокупность элементов. КАКИХ — зависит от того, что вам надо. В первом приближении всё можно считать множествами.
а в таблицах в общем случае это вообще-то не так. Вторая беда, что термин «пересечение» только путает.
Во вторых, есть такая штука — реляционная алгебра. И пересечение двух отношений в терминах реляционной алгебры, это и есть inner join. Да, это не про голые множества: отношение — это множество с особыми свойствами, пересечение — вводится именно для отношений, а не как операция над множествами. Но выглядит это не более чем придиркой.
t1 CROSS JOIN t2 WHERE condition
можно еще короче: t1, t2 where condition
Также, похоже, нужно избегать термина «пересечение».
Не стоит избегать термина пересечение. Если уж докапываться до терминологии, то следует уточнять, что речь не про множества, а про отношения и реляционную алгебру.
Диаграммы Венна — просто наглядны. Да, не точно, но не смертельно. Не вижу, чем их можно заменить, не теряя наглядности.asilischev
17.04.2019 22:38+4Кто вам сказал такую глупость? Множество — это просто совокупность элементов. КАКИХ — зависит от того, что вам надо. В первом приближении всё можно считать множествами.
Ну если разбираться глубже, а не поверхностно, то совокупность всё-таки уникальных элементов. Например, вот определение — economic_mathematics.academic.ru/2630/%D0%9C%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%BE
Могу ещё ссылок накидать.MarazmDed
17.04.2019 22:45+1Ну если разбираться глубже, а не поверхностно, то совокупность всё-таки уникальных элементов
Все дело в том, что считать уникальным. Если вы можете различить единицы, то, например {1, 1, 1, 1, 1} — спокойно может быть множеством. Все что вам нужно — это уметь различать эти единички. Например, по индексу. Вся математика — это по сути надстройка над теорией множеств. Всё есть множества.mayorovp
17.04.2019 23:42+2Но даже в этом случае пересечение двух множеств по два элемента не может дать множество из 4х элементов.
MarazmDed
17.04.2019 23:50+1Но даже в этом случае пересечение двух множеств по два элемента не может дать множество из 4х элементов.
Пересечение МНОЖЕСТВ действительно не может. А пересечение ОТНОШЕНИЙ, как операция, определенная в реляционной алгебре, может запросто.
mikeus
18.04.2019 00:08+1Вы конечно можете придумывать себе какую угодно математику с обоснованием «я так вижу», «смотря что под этим понимать», «смотря как считать». Но в общепринятом математическом определении: если элемент уже принадлежит некоторому множеству, то добавление его ещё раз в это же самое множество, не меняет это множество.
MarazmDed
18.04.2019 00:42+1Ок, дайте тогда определение матрицы, например. Вас сильно смущает, к примеру нулевая матрица? Там одни нули. Но вы их можете различить.
Вы не путайте, что относится к самой математике, а что — к ее применению. В определении множества есть требование к различимости элементов. Но нет требования к равенству. Накладываю на множества дополнительное свойство: упорядоченность. И спокойно так различаю одинаковые, на первый взгляд, элементы.mikeus
18.04.2019 01:06+1Ок, дайте тогда определение матрицы, например. Вас сильно смущает, к примеру нулевая матрица? Там одни нули. Но вы их можете различить.
Вы хотите сказать что вы лично различаете например значение ноль элемента (1,1) и ноль в элементе (2,2) матрицы?
vladkorotnev
18.04.2019 04:18+1Видимо имеется в виду, что если представить, что каждый элемент матрицы на самом деле не просто число, а что-то типа
struct {
long val;
uint x;
uint y;
} mat_el_t
от которого «на бумагу» выведен только val, то таки да, каждый из этих mat_el_t элементов будет уникальным.
Или, например, можно это представить как матрицу
A = [ x11 x12 x13; x21 x22 x23; x31 x32 x33 ] где x11 = x12 = x13 = x21 = x22 = x23 = x31 = x32 = x33 = 0;mikeus
19.04.2019 00:08Просто из этого ничего не следует, что можно применить по отношению к определению множества.
Если мы возьмем нулевую матрицу 3х3, то множество значений val будет V={0}, множество элементов mat_el_t, определяющих эту матрицу будет A={x11, x12, x13, x21, x22, x23, x31, x32, x33}.
Добавив ещё один ноль в множество V={0} никто не получит какое-то иное множество, оно останется таким же = {0}. Точно также, добавив ещё один элемент х11 в множество A, даже если начать теперь всегда скрупулёзно выписывать, что A={x11, x11, x12, x13, x21, x22, x23, x31, x32, x33}, никто не получит множество, определяющее какую-то другую матрицу чем та, что определялась до этого.
Ок, дайте тогда определение матрицы, например. Вас сильно смущает, к примеру нулевая матрица? Там одни нули. Но вы их можете различить.
Если теперь в множестве A={x11, x11, x12, x13, x21, x22, x23, x31, x32, x33} начать различать один x11 от другого, то мы получим что на самом деле в множество был добавлен элемент, который отличается от всех остальных элементов, которые были в нём до этого, т.е. что был добавлен не x11, что противоречит изначальному действию.
Вы не путайте, что относится к самой математике, а что — к ее применению. В определении множества есть требование к различимости элементов. Но нет требования к равенству. Накладываю на множества дополнительное свойство: упорядоченность. И спокойно так различаю одинаковые, на первый взгляд, элементы.

0xd34df00d
18.04.2019 04:31+1Если вы можете различить единицы, то, например {1, 1, 1, 1, 1} — спокойно может быть множеством.
Значит, это будет не очень корректной записью.
Если вы хотите различать элементы, значит, в вашей нотации вы потеряли информацию, которую вы используете для различения.
Если вы различаете элементы по индексу, то у вас не множество S, а функция Nat > S (ну или I > S для произвольных индексирующих множеств, чего мы как первоклассники). А вы выписали её кодомен и теперь удивляетесь, что вас не понимают.
Если вы не различаете элементы по индексу, но умеете считать их количество (мультимножество, ага), то у вас функция S > Nat (или S > Nat\{0}, есть варианты).
Да, если вспомнить, что такое функция из A в B (подмножество A?B с очевидным дополнительным условием), то да, это тоже множества, конечно же. Но другие.
Вся математика — это по сути надстройка над теорией множеств. Всё есть множества.
Даже классы объектов в категориях, не являющихся малыми, или Hom-классы в категориях, не являющихся локально малыми?
badunius
18.04.2019 11:08значит, в вашей нотации вы потеряли информацию, которую вы используете для различения.
Позвольте, но ведь последовательность записи (положение в списке) — это информация, и она никуда не терялась.Fenzales
18.04.2019 16:13+1Если последовательность записи имеет значение, то это уже не одинаковые элементы множества, а запись просто некорректна.
badunius
18.04.2019 16:37-1Хм, нет, простите, у меня на уме был пример индексного буфера. То есть, если я рендерю «ромашку» отдельными треугольниками, то я передаю массив вершин, которые уникальны и массив индексов, которые уже не уникальны, но при этом положение индекса в массиве имеет решающую роль.
mayorovp
18.04.2019 16:51Ваш пример всего лишь означает, что индексный буфер не является множеством индексов, и его математически некорректно нельзя записывать в форме множества.
0xd34df00d
18.04.2019 16:17Фигурные скобки используются для того, чтобы подчеркнуть независимость от положения в списке. Понятие множества — действительно достаточно базовое для того, чтобы не догружать интерпретацию ещё какими-то индексами, положениями в списке (что вы будете делать с несчётными множествами, в конце концов?) и прочим подобным.
А так вы, тащем, вольны решить, что множество { 1, 2, 5 } вы записываете как { 1, 1, 3 } (надеюсь, идея такой записи понятна), но зачем, если есть общепринятая стандартно понимаемая нотация?badunius
18.04.2019 16:40Фигурные скобки используются для того, чтобы подчеркнуть независимость от положения в списке.
Каюсь, не знал. Спасибо, что прояснили.
LonelyDeveloper97
18.04.2019 16:57+1Для того, что вы пытаетесь описать, существует специальный термин — Кортеж.
Кортеж — это упорядоченный набор элементов.
Я попробую внести ясность во всю эту дискуссию.
Первое. Автор поста прав в утверждении, что множество не может содержать повторяющихся элементов. By defenition.
И запись {1,1,1} — действительно некорректна, если {} — обозначает множество, то это множество может быть ТОЛЬКО {1}
Второе, из того, что автор прав в предыдущем пункте не следует, что он сделал правильный вывод. Таблица — это множество. Но не совсем обычное.
На основе понятия «множество», можно построить другие объекты, которые так же будут являться множествами, но при этом иметь другие свойства. С их помощью и можно описать таблицу.
Например, уже упомянутое мультимножество, в котором элементы имеют кратность. Для нашей задачи оно не подойдет, в таблице важен порядок.
Однако, еще немного математических преобразований позволяют получить такой объект как "кортеж". Кортеж — это упорядоченная последовательность элементов. И да, он может быть выражен используя только определение множества, и сам является множеством. Обозначение: "()", и судя по всему это именно то, что вы пытались выразить своим примером. Правильная запись «различных единиц» будет выглядеть как: (1,1,1,1)
Частным случаем кортежа является такой объект как "пара" — это просто кортеж из двух элементов.
На примере пары можно показать как получается упорядоченность. Пара (a,b) выражается через множество как { {(a)}, {(a), b} }, где (x) = {{/}, {/, x}}, {/} — пустое множество. Соответственно пара (b, b) -> { {(b)}, {(b), b} }. В русской википедии на этом месте ошибка, но можно глянуть в английскую.
А теперь давайте выразим таблицу, с помощью элементов выше.
В таблице есть строки и столбцы.
У каждого столбца есть имя, например «id», «name». Если вы хотите взять значения столбцов по определенной строке то вы получите набор пар:
((id: 1), (name: «Vasya Pupkin»)) — строка таблицы.
Но разумеется, у нас много строк, и их порядок важен. Поэтому в целом таблицу можно выразить как кортеж кортежей пар (название столбца, значение):
(
((id: 1), (name: «Vasya Pupkin»)),
((id: 2), (name: «Nikita Twink»)),
((id: 10), (name: «Petya Petechkin»))
)
И да, этот кортеж все еще можно выразить с помощью одного только понятия «множество». Но правильная запись займет весьма значительный объем (почему — можно узнать в уже упомянутой статье Tuples, английской википедии).
Разумеется, это всего один из способов описать таблицу математически через теорию множеств, но он самый интуитивно понятный, на мой вкус.
0xd34df00d
18.04.2019 17:02+1Автор поста прав в утверждении, что множество не может содержать повторяющихся элементов. By defenition.
Чисто техническая ремарка: это не по определению множества, а по построению языка теоири множеств. Операции над множествами не умеют считать элементы, поэтому это просто бессмысленный вопрос.
Rsa97
18.04.2019 17:42+3Но разумеется, у нас много строк, и их порядок важен.
На момент выполнения запроса порядок строк неважен. Да и вообще, сам по себе SELECT без ORDER BY никакого определённого порядка не гарантирует.LonelyDeveloper97
18.04.2019 18:27Т.Е. у строк нет какого-нибудь rowNumber, по которому ее можно выбрать не зная о ее содержании?
Я просто очень давно не работал с таблицами.
Тогда вы правы и у них нет «порядка», но из этого будет следовать неразличимость двух строк с одинаковыми значениями. Если это так — описывать их кортежем избыточно, можно использовать мультимножество.
Если и для столбцов порядок избыточен, то и там не нужен кортеж. Можно описывать как множество пар, если названия столбцов уникальны — мы гарантируем уникальность каждой пары из набора.
Таким образом в случае когда порядок не важен (т.е. мы не можем сказать «столбец номер такой-то» и «строка номер такая-то») получим мультимножество множеств пар.Rsa97
18.04.2019 18:45+2Т.Е. у строк нет какого-нибудь rowNumber, по которому ее можно выбрать не зная о ее содержании?
Нету. Также, как нету отношений «следующая» или «предыдущая» строка и понятий «первая» и «последняя» строки. Это первая нормальная форма.
1. Нет упорядочивания строк сверху вниз (другими словами, порядок строк не несет в себе никакой информации).
2. Нет упорядочивания столбцов слева направо (другими словами, порядок столбцов не несет в себе никакой информации).
3. Нет повторяющихся строк.
4. Каждое пересечение строки и столбца содержит ровно одно значение из соответствующего домена (и больше ничего).
5. Все столбцы являются обычными (не скрыты от пользователя и не содержат каких-либо данных, доступных только по специальным функциям).
xitt
18.04.2019 18:10Таблица это множество, в реляционной модели. Точнее таблица это представление отношения данных, а отношения имеют все признаки множества. Копья люди ломают только потому что тн реляционные базы данных и язык SQL сам по себе не удовлетворяют этой модели в чистом виде.
varanio Автор
17.04.2019 22:48+1дело даже не в этом. Бог с ними со можествами. Больше бесит пересечение, особенно с кругами Венна
MarazmDed
17.04.2019 22:57+1Больше бесит пересечение, особенно с кругами Венна
Вот и стоит уточнить, слышал ли испытуемый про реляционную алгебру, и в каком смысле — пересечение.
ИМХО, круги Венна можно оставить, но внутри них допустимы только названия таблиц, а не элементы-цифирьки. Но только для inner join'а. Как наглядно и просто нарисовать в виде картинки, тот же left join — я не знаю.varanio Автор
18.04.2019 00:23+1Пересечение кругов и пересечение отношений в рел алгебре иллюстрируют sql-оператор INTERSECT, а не join
MarazmDed
18.04.2019 00:44+1Да, это так. Ну т.е. получается, что нет лаконичных способов нарисовать все джойны в виде кружочков. Только таблички из двух строк и двух столбцов.
Fezzo
18.04.2019 11:08+6Диаграмма Венна отлично показывает какие значения попадут в результат, а не сколько их будет. ИМХО именно в этом и состоит главное отличие этих видов джойна. Именно поэтому, первое что отвечают — это круги и пересечения. Если вас интересуют детали про дубликаты, никто не мешает задать дополнительный вопрос. Люди не склонны на простые вопросы типа «Что такое inner join» отвечать полной математической справкой по теме, а предоставлять самое важное и часто используемое.
По аналогии с вашим постом можно удивляться, что люди на вопрос «сколько будет 2х2?» отвечают «4» (в общем случае это, конечно же, не так), и говорить что «понимание умножения сломано»
Pro100Oleh
17.04.2019 22:55+1Кто вам сказал такую глупость? Множество — это просто совокупность элементов. КАКИХ — зависит от того, что вам надо. В первом приближении всё можно считать множествами.
Тогда что получается: даны множества A={a, a, b} и B={a, b}. Думаю не будете спорить что a принадлежит A. Также А принадлежит B, а B принадлежит A (потому что каждый елемент левого множества принадлежит правому). Отсюда A=B. Имхо бессмысленная возможность иметь множества с не уникальными элементами.MarazmDed
17.04.2019 23:01+2Отсюда A=B. Имхо бессмысленная возможность иметь множества с не уникальными элементами.
вопрос в том, можете ли вы в множестве A различить первую a и вторую. Если можете, то никаких парадоксов нет: A не является подмножеством B. И множества не равны.
Если не можете, то у вас, по факту, множество A={a, b}Pro100Oleh
17.04.2019 23:08+1Как только я начинаю «различать» элементы, то они перестают быть уникальными. Мы же продолжаем говорить о математике а не о своем понимании что такое уникальные элементы?
MarazmDed
17.04.2019 23:34+1Как только я начинаю «различать» элементы, то они перестают быть уникальными.
Бинго! :) В точку! И это сразу решает все проблемы.
а не о своем понимании что такое уникальные элементы?
А что такое «уникальные элементы» в математическом смысле?
khim
18.04.2019 03:41+2Господи, сколько шума из ничего. В математике есть понятие мультимножества. И да, вокруг них — тоже есть теория. Если хотите смотреть как работают JOIN'ы в таблицах с повторами — вам нужна теория мальтимножеств, а не множеств. Вот и всё.
mayorovp
18.04.2019 08:41Вот только пересечением мультимножеств {1, 1} и {1, 1} будет тоже {1, 1}, а не {1, 1, 1, 1} которые дает соединение
nfw
18.04.2019 09:26Множество — это просто совокупность элементов. КАКИХ — зависит от того, что вам надо. В первом приближении всё можно считать множествами.
И каким же образом в произвольном множестве вы будете отличать один элемент множества от другого, если они, буквально, одинаковые?
Во первых, множество.
Да, вот только таблица не простое множество, а упорядоченное, то есть, например, вот таблица {1,1,1} это не множество цифр, а множество двоек {[1,1],[2,1],[3,1]}.
Ndochp
18.04.2019 15:38У упорядоченных множеств {1, 2, 2, 2, 3} и {2,3,4} пересечение есть? если это множество двоек, то нету. Если пересечение {2, 3}, то я не знаю как это описать.
0xd34df00d
18.04.2019 16:20+1Если вы имели в виду мультимножества, то пересечение { 2, 3 }.
Если вы имели в виду множества с заданным на них отношением порядка, то тоже { 2, 3 } (независимо от этого отношения, естественно).
Druu
18.04.2019 11:21+1Если уж докапываться до терминологии, то следует уточнять, что речь не про множества, а про отношения и реляционную алгебру.
А в отношении одинаковых кортежей все равно не бывает.
devil_oper
18.04.2019 14:18-1пересечение двух отношений в терминах реляционной алгебры, это и есть inner join
Дед, ты в маразме. Для join в реляционной алгебре есть операция соединения (сюрприз-сюрприз!), которая эквивалентна операции выборки из декартова произведения двух отношений (то есть множеств кортежей).
MarazmDed
17.04.2019 22:40+4Если джойнов немного, и правильно сделаны индексы, то всё будет работать быстро. Проблемы будут возникать скорее всего лишь тогда, когда у вас таблиц будет с десяток в одном запросе. Дело в том, что планировщику нужно определить, в какой последовательности осуществлять джойны, как выгоднее это сделать.
Если чел — слабо разбирается в SQL и плохо представляет себе, что будет делать СУБД, а что такое план запроса — вообще не слышал. То в такой ситуации, как мне кажется, правильнее будет пихать все в джойны и считать, что СУБД умнее программера. Правило — эвристическое, но для новичков — работает :)
Это явно будет лучше, чем тысячи мелких запросов внутри цикла, или ручное склеивание таблиц средствами языка.
Ну а если чел знает что делать, то он разберется, как переписать запрос, чтобы ускорить его.littorio
18.04.2019 09:29-1Союз «если… то» вроде нельзя разбивать точкой на два предложения. Или я чего-то путаю?

pilot911
17.04.2019 22:44некоторые не знают, что после ON можно писать и AND, что, судя по опыту на Mysql, ускоряет в некоторых случаях запрос
```
SELECT s.id, c.city
FROM users_stats AS s
JOIN cities_ip_ranges AS c
ON c.ip_range && s.ip AND s.ip > 2
```
Neikist
18.04.2019 09:01+2Главное не забывать что это имеет смысл только в inner join чаще всего. Я по первости бывало забывался и в left join тоже внутрь join условие добавлял вместо where.
mayorovp
18.04.2019 09:05+2Этот опыт только на Mysql и переносим. СУБД с вменяемым оптимизатором запросов не видят разницы между условием в inner join и условием в where; одно из них ну никак не может работать быстрее другого.
Neikist
18.04.2019 10:21Хм, странно, сейчас замерять не смогу, с 1с больше не работаю, да и вообще с субд, но это вполне распространенная рекомендация среди 1сников для оптимизации. В их файловой субд скорее всего это будет работать, вряд ли там оптимизаторы хитрые есть, но вроде и для ms sql на которой в основном 1с запускают тоже советуют.
LMSn
18.04.2019 10:56Ничего странного. В MS SQL ничего подобного нет, там планировщику без разницы где указано условие. В больших запросах разница очень теоретически может возникнуть на этапе построения плана запроса (два немного разных запроса пойдут по немного разному пути и имеют шансы получить разные планы выполнения из-за ограничения времени на построение плана). Но тут никогда нельзя утверждать, что какая-то конструкция языка будет однозначно быстрее аналогичной. Что там в mysql творится — не знаю, говорю за Oracle, MS SQL.
kolu4iy
18.04.2019 10:58но вроде и для ms sql на которой в основном 1с запускают тоже советуют.
А зря. Там и MAXDOP=1 советуют, не вникая в суть. Что тоже зря (это вырожденный случай, годный для определённого количества ядер процессора).

Nashev
21.04.2019 00:32Это не так. Например, условие в join не считает поля отсутствующей записи правой таблицы равными null, потому что join на момент его работы ещё не выполнен, и условие примеряется к имеющимся строкам объединяемых джойном таблиц. А условие в where примененяется к сделанной выборке, после отработки всех join, то есть поля, выбранные из второй таблицы в тех строках, где подходящая строка во второй таблице не нашлась, заполнены значением null.
Это логика SQL, и любой оптимизатор, даже если он выполняет условия в другие моменты времени и в другом контексте, должен эту логику сохранять.
mayorovp
21.04.2019 08:36Это вы поведение left join описали, а тут исключительно inner join обсуждается. По крайней мере, я про него писал.

Hooters
17.04.2019 22:59По математическому определению, во множестве все элементы уникальны, не повторяются, а в таблицах в общем случае это вообще-то не так.
То есть, множество эквивалентных элементов — это уже не множество?
К вашему сожалению, в понятии множества нет такой характеристики, как уникальность.
Tzimie
17.04.2019 23:08+3Формально определение равенства множеств (в теории ZFC и других) не различает множества, имеющие поповторяющиеся элементы, то есть:
{ x } = { x, x }
Поэтому, хотя теория множеств явно не требует уникальности элементов (она даже об этом не упоминает) но с точки зрения выводов теории это не имеет практического смысла
MarazmDed
17.04.2019 23:39+1но с точки зрения выводов теории это не имеет практического смысла
Это имеет практический смысл с точки зрения построения других математических конструкций. Например, нуль-мерные пространства — тоже не имеют практического смысла, но тем не менее существуют. И что?Tzimie
17.04.2019 23:57+1Не имеет вообще никакого смысла, так как в отличие от нульмерных пространств никаких новых выводов в ZFC не появляется
Кстати, раз заинтересовались, теория множеств — это теория первого порядка без равенства (surprise, surprise)

eteh
17.04.2019 23:45+1с точки зрения БД уникальность кортежа это важное значение
MarazmDed
17.04.2019 23:54-1Хотите сказать, что СУБД БЕЗУСЛОВНО запрещает иметь таблицы с одинаковыми кортежами? Т.е. для этого не нужно определять первичные ключи, например? ;)
lorc
18.04.2019 14:50-1Первая нормальная форма реляционной БД. Одно из условий — нет повторяющихся строк. Так что да, теория запрещает совершенно одинаковые кортежи в таблице. Потому что непонятно как их отличать друг от друга.
Другое дело, что разработчики БД знают что человек слаб, поэтому часто вводят неявные поля типа ROWID.akryukov
18.04.2019 15:02Первая нормальная форма реляционной БД. Одно из условий — нет повторяющихся строк. Так что да, теория запрещает совершенно одинаковые кортежи в таблице.
1NF не про дубликаты кортежей, а про то, что в атрибутах мы не храним массивы данных.
lorc
18.04.2019 15:11+1Вы как-то узко понимаете 1NF:
According to Date's definition, a table is in first normal form if and only if it is «isomorphic to some relation», which means, specifically, that it satisfies the following five conditions:[12]
There's no top-to-bottom ordering to the rows.
There's no left-to-right ordering to the columns.
There are no duplicate rows.
Every row-and-column intersection contains exactly one value from the applicable domain (and nothing else).
All columns are regular [i.e. rows have no hidden components such as row IDs, object IDs, or hidden timestamps].
Плюс, нужно отличать 1NF для отношения ( на самом деле отношение всегда в первой нормальной форме) и 1NF для таблицы, как способа записывать отношения.mayorovp
18.04.2019 15:15Ну, определение отношения таки не мешает хранить в колонке структурированные данные, вроде массивов, объектов или таблиц, так что отношение не в 1NF тоже бывают.
lorc
18.04.2019 15:30Не совсем так. Вообще, с атомарностью возникают вопросы.
Например, тот же IP-адрес — это на самом деле структура из 4 октетов. Должны ли мы хранить их в отдельных колонках?
Если для в нашем домене какая-то структура рассматривается как атомарный объект — то его теоретически можно хранить в одной колонке. Например — мы в таблице логируем ответы от сервера. Сервер отвечает каким-то json-нами, но нам совершенно не интересно что внутри этого json. Поэтому мы запихиваем его в колонку и не паримся. И это не нарушает 1NF. Ровно до тех пор, пока мы не захотим обращаться к элементам внутри этого json.Melkij
18.04.2019 15:47Например, тот же IP-адрес — это на самом деле структура из 4 октетов.
Это одно 32-битное поле. См. структуру заголовка пакета.
Отображение в виде 4 октетов в десятичной записи сделано исключительно для чтения человеком.lorc
18.04.2019 16:22Да, согласен. Разделение на 4 октета — довольно таки условно.
Тогда вот вам другой подход — до введения CIDR из IP-адреса можно было однозначно выделить адрес сети и адрес хоста. Т.е. внутри IP-адреса все-таки была структура.
Ну или в качестве примера можно взять Ethernet MAC-адрес. Или GUID. С одной стороны для большинства применений — это просто цепочка октетов и пофиг что там внутри. Но с другой стороны — они таки имеют внутреннюю структуру. Соответственно, если применять 1NF бездумно и настаивать на полной атомарности данных — то их всегда надо хранить в отдельных полях.

funca
18.04.2019 00:24+1Уникальность это мутная штука когда значения не являются дискретными. Зато там есть аксиома выбора, которая обеспечивает подобное свойство.
0xd34df00d
18.04.2019 04:40+1Почему это мутная?
Уникальность мутная штука только тогда, когда вы начинаете говорить о равенстве ближе к теме исходного поста — в контексте равенства вычислимых чисел. Проверка двух чисел на равенство разрешима тогда и только тогда, когда они, э, не равны. Не существует алгоритма, который для двух равных чисел всегда бы успешно говорил, что они равны. Вот где муть!
Tzimie
18.04.2019 08:49Это зависит от того, как числа задаются
Вы наверное про бесконечнозначное представлениеmayorovp
18.04.2019 08:54Это ничего не меняет. Если у нас конечнозначное представление — то мы точно так же не можем понять равны числа на самом деле или нет.
Tzimie
18.04.2019 08:58Почему? Задаем число бесконечными строками где первый символ равен f, если число иррациональное (после него идут цифры)
f3.1415926…
или r если рациональное (далее идут a/b)
r100/777
Очевидно рациональные числа сравниваются за конечное время хотя в общем виде конечно это не такmayorovp
18.04.2019 09:06+1Ну вот и всё. Даже если забыть о том, что ваше представление требует бесконечной памяти, вы никак не сможете за конечное время доказать что f3.1415926… = f3.1415926…
funca
18.04.2019 22:36Вот поэтому вместо равенства используется аксиома выбора. Возможность отличать один элемент от другого и вытаскивать по одному просто постулируется. Как это будет реализовано для конкретных объектов уже ваша проблема.
0xd34df00d
18.04.2019 23:13Это не имеет отношения к вопросу о различении одинаковых вычислимых вещественных чисел.
Довольно легко показать, что если у вас есть такой алгоритм, то вы можете решать проблему останова, а аксиома выбора на неё не влияет никак.
funca
19.04.2019 19:06Влияет. Иначе нельзя было бы рассуждать о множествах вещественных и рациональных чисел, множествах бесконечных величин и т.п. не уперевшись на старте в то, о чем вы пишете. Аксиома абстрагирует множества от этих вот деталей.
0xd34df00d
20.04.2019 00:27А зачем для рациональных чисел аксиома выбора? Я просто беру целые числа с умножением (как моноид) и обозначаю рациональные, например, как группу Гротендика. Где она там вылезает?
Druu
20.04.2019 06:25Я просто беру целые числа с умножением (как моноид) и обозначаю рациональные, например, как группу Гротендика.
Нельзя так, ноль же.
mayorovp
19.04.2019 08:45Постулировать можно только само равенство, но не разрешимость проверки равенства.
0xd34df00d
18.04.2019 04:38+1Осталось определить понятие равенства.
Ща ещё немножко пообсуждаем и до гомотопической теории типов дойдём.
Tzimie
18.04.2019 08:48+1Оно давно определено
Я тут писал habr.com/ru/post/445904
(раздел «Малоизвестные факты»)
Сорри за занудство про теорию множеств, но сами понимаете, в интернете ктото неправ, я вынужден действовать)0xd34df00d
18.04.2019 16:31Ну, если говорить формально, то ZF — это просто набор формул в логике первого порядка. Как вы там интерпретируете значок
=— это просто вопрос, э, интерпретации.
При этом, естественно, легко придумать интерпретации, в которых интерпретация значка равенства не означает интуитивно понятное нам равенство — можно просто взять и размножить конструкцией типа той, что в теореме Левенгейма-Сколема о повышении мощности.
И это я ещё не говорю о вопросах равенства, если вы начинаете вводить в теорию некоторый вычислительный компонент и обмазываться definitional equality, propositional equality, extensional equality...
Tzimie
18.04.2019 23:10Это да, но так мы можем скатиться в формализм и воспринимать теорию как игру в значки. А ваш покорный слуга убежденный платонист, как Гедель)
0xd34df00d
18.04.2019 23:14От этого платонизма потом всякие парадоксы вылезают. Значки, только значки, ничего, кроме значков!
Хотя вдохновляться и затягиваться семантикой прикольно и приятно, кто ж спорит.

Pro100Oleh
17.04.2019 23:23+1Во-первых, таблица — это вообще не множество. По математическому определению, во множестве все элементы уникальны, не повторяются, а в таблицах в общем случае это вообще-то не так. Вторая беда, что термин «пересечение» только путает.
На сколько я помню, то теория рел. БД говорить что таблица — это множество кортежей. Разные кортежи могут хранить одинаковые значения и тогда это эквивалентные кортежи, но все же разные. Поэтому нет никакого противоречия, так как все элементы таблицы уникальны по определению.eteh
17.04.2019 23:50+1Ну в целом да — при значении кортежа =1, Ваша 1 условная тонна никак не превратится в условную единицу времени кроме алгебраических преобразований, если говорить проще.
funca
18.04.2019 00:07+1Что вас заставило сомневаться в том, что люди, приходящие на собеседования, могут быть образованнее вас?
Декартово произведение (Cartesian product, cross join) в реляционной алгебре и в теории множеств работают немного по-разному. Но на уровне логики (формальной) смысл операций один и тот же. Поэтому круги Венна читаются однозначно, даже на уровне деталей, если есть понимание в рамках какой модели строятся рассуждения.
asilischev
18.04.2019 00:25+1Что вас заставило сомневаться в том, что люди, приходящие на собеседования, могут быть образованнее вас?
Интересно, где вы это в статье увидели? Между строк?
Надо вдумываться в то, что говоришь на собеседовании, а не повторять бездумно заученные фразы. Inner Join явно не «пересечение 2-х множеств». Пример в статье это показывает.
varanio Автор
18.04.2019 00:34+1Вы с таким пафосом это написали.
Вот честно, не представляю, как кругами можно кому-то объяснить декартово произведение. Об этом и статья.
Кругами хорошо показывать пересечение отношений (intersect в sql), а не декартово произведение (join в sql)
koropovskiy
18.04.2019 15:09-1Как часто вам в работе нужно декартово произведение?
По моему опыту:
INNER и LEFT джойны нужны почти всегда.
RIGHT JOIN нужен редко.
FULL OUTER нужен редко.
CROSS не нужен почти никогда, даже NATURAL JOIN нужен чаще чем CROSS.akryukov
18.04.2019 15:24Декартово произведение нужно, например, чтобы в HIVE джойнить по битовой маске или по попаданию значения из одной таблицы в интервал, задаваемый колонками из другой таблицы. Из коробки не получается.
koropovskiy
18.04.2019 15:39Но подождите. В HIVE вообще не SQL. В SQL для интервала есть BETWEEN. для битовой маски сходу не придумаю, не сталкивался по работе с подобными JOIN, обычно это уже были обычные фильтры.
akryukov
18.04.2019 17:19В HIVE вообще не SQL.
В составе Apache HIVE есть SQL диалект, который может работать на одном из трех движков. Наличие движка, минорных особенностей синтаксиса вроде "нельзя применять опрацию > в ON" еще не значит, что там "вообще не SQL".
smbsmn
20.04.2019 22:08По опыту:
right join используется, когда раньше был inner, но ситуация изменилась
full join — реальная ситуация:
1. например, нужно для одного клиента с разных счетов суммы с баланса вывести
2. или взять остатки товара с розницы и со склада
cross join — есть банда кустомеров, для них есть 1 тариф и всё такое

a0fs
18.04.2019 00:21+2«И всё-таки она вертится»(с). Отношение есть множество картежей. Привёденная ссылка на определение это подтверждает. Приведённый пример — просто занятная штука для вопроса на сообразительность и глубину понимания процесса. Обычно в отношениях в БД не хранится хлам навалом, и отношение имеет первичный ключ, по которому происходит объединение. Попробуйте определить первичный ключ и провести свои опыты, вы удивитесь, но СУБД не даст завести два одинаковых значения для первичного ключа.
Да полностью согласен, что нужно СУБД довести до состояния строго учителя математики, который лупит по рукам железной линейкой за каждый шаг в неверном направлении, но люд нынче пошёл нежный, и он сразу взвопит, что его унижают, лишают свободы, а после этого развернёт знамёна и уйдёт на монгу… Нет ну правда, СУБД имеют дело именно с множествами, просто в случае плохо организованной базы, СУБД не может различить одну единицу от другой, поскольку она не в курсе, что делают одинаковые данные в разных записях одной таблицы. Она милостиво делает по этому безобразию декартово произведение и выдаёт это пользователю, в надежде, что тот сможет достучаться до печени DBA, с целью приведение схемы в божеский вид. Уважаемого автора устроило бы падение базы с дампом памяти по типу деления на ноль?mayorovp
18.04.2019 08:49JOIN идет далеко не всегда по первичному ключу, и не всегда есть возможность это исправить. Если точнее, то если у схемы данных различаются пятая и шестая нормальные формы — то как ни крутись, всегда будут запросы с соединением не по ключу.
MarazmDed
18.04.2019 10:59JOIN идет далеко не всегда по первичному ключу,
Я более того скажу — не всегда это нужно. Например, иногда я хочу, чтобы в результате джойна записи «размножились». Например, у меня есть таблица номенклатуры и характеристик. И я хочу по какому-нибудь правилу получить все допустимые пары номенклатура-характеристика.
Xandrmoro
18.04.2019 01:02+2Кстати, слегка отвлечённый вопрос, раз уж упоминались планы — есть ли какой-нибудь ресурс с задачами на оптимизации запросов? Прямую передачу опыта между сознаниями я пока не освоил, интересные кейсы из практики не записывал, а учить людей как-то надо.

Kant8
18.04.2019 01:54+1Так с задачами то проблемы, каждый запрос надо рассматривать отдельно. А в общем виде правило достаточно тривиально — всё, что проверяется в запросе и имеет высокую селективность, должно быть помазано индексом. Ну и что порядок колонок в индексе имеет основополагающее значение.
Дальше чаще всего оптимизатор сам разберется, разве что с покрывающими индексами по крайней мере SqlServer любит перебдеть сильно в своих хинтах о индексах.
dasFlug
18.04.2019 01:09+2Как мне кажется, не стоит использовать диаграммы Венна для объяснения джойнов. Также, похоже, нужно избегать термина «пересечение».
Круги Венна прекрасно объясняют суть, не надо от них отказываться. Но они про отношения в терминах реляционной алгебры, а не про некие абстрактные множества. Отношения конечно тоже множества, но с многими дополнительными свойствами. Если про это забыть то получается некий беспорядок про который вы пишете. Если же говорить про множества то Join это их умножение, а не пересечние. Остальное — inner, outer, on это, как вы правильно пишете, синтаксический сахар добавленный в язык SQL из практических соображений. Всетаки парсеры и оптимизаторы запросов не настолько умны чтобы эффективно превратить ветхозаветное но строго по Кодду
select t1.id,t2.id from t1,t2 where t1.id=t2.id union select id, null from t1 where id not in (select id from t2)
в красивое и которое еще и подскажет оптимизатору запросов чего программист на самом деле хочет
select t1.id,t2.id from t1 left join t2 on t1.id=t2.id
но лет 20 назад приходилось писать по первому варианту или использовать специфический синтаксис конкретной СУБД. Вот для Oracle например
select t1.id,t2.id from t1,t2 where t1.id=t2.id(+)

DimonSmart
18.04.2019 07:06+1В примерах в таблицах есть неуникальные значения поля id. IMHO, Неудачно выбрано название.
kznalp
18.04.2019 08:27Во-первых, таблица — это вообще не множество
А что же это? C математической точки зрения?
По математическому определению, во множестве все элементы уникальны, не повторяются, а в таблицах в общем случае это вообще-то не так
Интересен источник данного определения и был бы благодарен, если бы вам удалось то, что не удалось моему преподавателю математического анализа — дать строгое математическое определения понятия «множество».
kznalp
18.04.2019 08:42У вас ошибка в первой иллюстрации.
Должно быть так

varanio Автор
18.04.2019 08:45+2хорошая попытка, но нет )
дело в том, что если единичек будет по 3 штуки, то в пересечении должно быть 9 штук
а если по одной, то только однаkznalp
18.04.2019 08:47-2При чем тут попытка? Попытка чего?
У вас просто начальная посылка неверная, а из ложной просылки любой вывод ложен.
lany
18.04.2019 09:07+2Думал, это перевод старой статьи Лукаса. Оказалось, что нет.
arch1tect0r
18.04.2019 10:51Спасибо, кинул к себе в закладки. Для объяснений кому-то сделано идеально.

greabock
18.04.2019 09:52+2Но как??
Специально сейчас заморочился, поспрашивал. Я не знаю, кого вы там собеседуете, но ни у одного из опрошенным мной моих знакомых (кто хоть сколько-то имел практики в sql) не возникло сомнений, что записей будет четыре. И ни один из них даже не слышал про какие-то там "пересечения множеств".
inspector1985
18.04.2019 11:07-1Ни один не слышал про «какие-то там пересечения множеств»? Традиционно у программистов (сюда отнесем людей, пишущих на SQL) есть математическая подготовка. «Я не знаю, кого вы там собеседуете» :D
greabock
18.04.2019 12:59Мы же говорим понятии «пересечения множеств» применительно к соединению таблиц. Я думал, что из контекста это и так понятно.
P.S Минус не я поставил.
arch1tect0r
18.04.2019 10:46varanio, как же я тебя понимаю. Через меня прошло три десятка кандидатов с якобы знанием SQL. У нас это плюс, нежели прям требование, но если кандидат утверждает, что знает, то задаю буквально пару вопросов. Один из вопросов как раз про отличие LEFT от INNER и почти никто не отвечает, хоть с кругами, хоть без них.
Sunny-s
18.04.2019 19:59Плюсую. Знание SQL очень хромает. Редкий кандидат доживает до having. До оконных функций добираются единицы.
GooG2e
18.04.2019 10:53Может буду не прав, но если уходить от каких-то ассоциаций, то все join'ы так или иначе надо рассматривать как декартово произведение, на которое накладывается определённый набор условий в зависимости от типа.
Если использовать для объяснения, то мне кажется объяснить один термин «декартово произведение» на порядок проще чем объяснять отдельные типы join'овGritsuk
18.04.2019 18:44В гайде по SAS, например, оно прямо так и объясняется — сначала умножаем, потом фильтруем
konstantin_berkow
18.04.2019 11:07+3В начале подумал что это вольный пересказ Say NO to Venn Diagrams When Explaining JOINs. Там и визуализация джоинов есть.
Milein
18.04.2019 11:09+1Я про декартово произведение услышал раньше чем про джойны, поэтому объяснение диаграммами венна мне изначально не нравились.
Но есть же простое и корректное объяснение. Джойн это как таблица умножения (которая в виде квадрата), но результат записан в виде пары чисел. Ключ первой таблицы это строки, другой — столбцы.
Вся таблица это CROSS JOIN.
Таблица, где мы затем добавили условие и взяли только те комбинации где оно выполняется — INNER JOIN.
LEFT/RIGHT объяснить сложнее, но тоже можно. Из строки стираем значение и имеем строку, в которой есть пара число + пустое место. И мы берём результаты соответствующие фильтру и результату где с одной стороны пустое место.
После чего результаты в любом порядке выписываем подряд в один столбец и дописываем оставшиеся поля. Вуаля.
Вроде бы понятно должно быть и однокласснику, так что зачем городить диаграмы венна?

igrishaev
18.04.2019 11:14Ответ про множества действительно неверный, потому что джоины не удаляют дубликаты. Ну и странно, что кандидаты считаю возможным джион только по айдишкам.
Запрет на джоины бывает не от того, что они тормозят, а из-за шардинга базы. Часть таблицы на этой ноде, часть на другой.
Ну и добавлю, что у кандидатов действительно проблемы с сырым sql после всяких Джанго-ОРМ.
staticlab
18.04.2019 11:26+4Как объяснить на картинке джойны корректно, я, честно говоря, не представляю.
А если так?
INNER JOIN

VMichael
18.04.2019 11:42+2Эти картинки запутывают, на мой взгляд.
Понятнее давать две таблички на входе и результат на выходе.staticlab
18.04.2019 12:00А что именно запутывает?
VMichael
18.04.2019 14:08Не знаю как сюда картинки вставлять.
-1 что означает в квадратике?
или
1- это что значит?
Четыре квадратика 11 что означают?
В общем на вопрос, какой результат вернет INNER JOIN ответа эти квадратики не дают.
Нужно додумывать, придумывать, что для пояснения плохо.staticlab
18.04.2019 14:27В каждой ячейке данные в формате "[t1.id] [t2.id]", при этом прочерк означает NULL. Четыре квадратика "1 1" собственно дают 4 строки результата.
VMichael
18.04.2019 15:40Вот видите, нужно интерпретировать как то картинки, правила запоминать.
Гораздо проще просто показать примеры с результатом выполнения, можно с комментариями не очевидных мест.
Т.е. инструмент для объяснения не должен быть сложнее, чем объясняемый материал, как мне кажется.staticlab
18.04.2019 15:50Мне кажется, это скорее вопрос тщательности проработки картинки. Я всё-таки её просто за 5 минут накидал в Ворде. Во всяком случае она очевидно отвечает на вопрос: почему возвращается именно столько строк в ответе.
koropovskiy
18.04.2019 12:41Вообще вся статья исходит из изначально неверной предпосылки что «таблица — это вообще не множество.» Но дальше сводится к верному что JOIN это не INTERSECT.
Но зачем разработчикам знать нюансы терминологии теории множеств на собеседовании по SQL на стандартном базовом вопросе про SQL?!
Не знает отличий между INNER и LEFT — не писал в SQL запросы сложнее «дай список по таблице с фильтром» — надо учить или прощаться.
Знает разницу между INNER и LEFT — ок, даже кружочками (привет универ, или гугл, или 100500 других источников знаний по SQL). Хотите уточнить пределы знаний — задаете дальнейшие вопросы. Про не уникальность, про сравнение NULL, да про что угодно вплоть до оконных функций, и вставки в несколько таблиц одним INSERT запросом
задаете advanced вопросы? это точно изkoropovskiy
18.04.2019 13:21Я буду перечитывать текст перед отправкой. Я буду перечитывать текст перед отправкой. Я буду перечитывать текст перед отправкой. :(
Хотел дописать «Это точно не из из числа»

joyfolk
18.04.2019 12:47Есть подозрения, что причина в том, что в большинстве учебных заведений теорию БД преподают с точки зрения реляционной модели и недостаточно хорошо проговаривают ее отличие от модели, принятой в SQL. В классической реляционной модели, как она была описана Коддом, отношения содержат только уникальные кортежи, поэтому описанная проблема в принципе не существует.
spv32
18.04.2019 12:53+4Еще вариант картинки

koropovskiy
18.04.2019 13:28Статья как раз о том, что при условии не уникальных "*" вы получите больше строк ответа, чем ожидается на основании этой картинки.
mayorovp
18.04.2019 14:15Да нет. В отличии от истории с кругами обозначающими множества, на этой картинке ничего не говорится про пересечение.
koropovskiy
18.04.2019 14:19На картинке с кругами тоже ничего не говорится про пересечение. там только круги и заливка/штриховка.
mayorovp
18.04.2019 14:35Таки говорится. Там обычно первый круг подписывают как первую таблицу-множество, а второй круг — как вторую (и даже если этого не делают — все равно наблюдается явная отсылка к диаграмме Венна). В такой картинке пересечение кругов должно быть пересечением множеств-таблиц, что и ошибочно.
На этой картинке никто не подписывал какой-то конкретный набор строк как таблицу, все раскрашенные области явно относятся только к их соединениям.koropovskiy
18.04.2019 14:54-1Здесь явно подписан левый прямоугольник и правый. Inner join объединяет одинаковые элементы в обоих прямоугольниках.
Отличия от кругов скорее косметические.
Отсылка к диаграмме Венна имеет смыл только для тех кто помнит диаграммы Венна. Помнящих не так много как может показаться :D
Ни круги, ни прямоугольники не показывают наглядно почему будет 4 записи при наличии 2х единичек с каждой стороны и 6 записей при 2 к 3. Впрочем никакие картинки это нормально не показывают. При не уникальных записях мы получаем мультипликативный эффект. Чтобы его понять надо с другой стороны подходить к JOIN и построению запросов. Уж точно не пытаться это объяснять через cross join, использующийся примерно в 1 запросе из 10000.
По моему опыту проще заходит объяснение через вложенные циклы.
Но повторюсь, это уже гораздо дальше простого понимания когда надо ставить INNER, когда LEFT OUTER, а когда FULL OUTER, а именно на это нацелены картинки.
Neikist
18.04.2019 14:52При full outer join может получиться пустой результат если одна таблица пустая а другая нет, насколько помню.
koropovskiy
18.04.2019 15:03Нет. Вы получите все записи. Проверено на Pg10 и Ora11. В MySQL5.7 «FULL» еще нет =-)
Neikist
18.04.2019 15:05Или на cross join… Просто точно помню как то багу словил и наверно день ее выискивал, а дело оказалось в том что в одной таблице не было записей и из за этого вообще ничего не приходило.
menotal
18.04.2019 13:05Разницу джойна и пересечения множеств можно продемонстрировать уже хотя бы тем, что дословный перевод join = соединение, что не эквивалентно пересечение.

nikitasius
18.04.2019 16:27-2Кривая статья.
Таблица 1

Таблица 2

Вывод по
inner join:

Что собсна криво? 1 встречается в таблице 1 два раза, как и в таблице 2 два раза.
Далее 2х2 дает 4 результата.
Если я поменяю вот так вот данные в таблице 2:

То получу:

Где
ON table1.id = table2.id
Вот с табличками:

Vlad_fox
18.04.2019 16:31-1некоторые недалекие люди на собеседовании пишут 2*2 = 4
в этой статье вы узнаете правду, которая сломает ваш мозг и вам дальше с этим жить.
Это только в евклидовом пространстве 2*2=4, а в неевклидовом может быть и больше!
да, я знаю, что 99% не оперируют в неевклидовом пространстве ни в быту, ни на работе,
но у меня вот проектик — и там как раз оно — неевклидово.lorc
18.04.2019 16:40Кривая аналогия (уж не говоря о том, что 2*2 не зависит от типа пространства).
Проблема в том, что любой join — это декартово произведение (возможно с добавлением null, если это не inner join). Потом этот уже join фильтруется по условию. Если этого не понимать, то реальность может укусить за задницу в самый неожиданный момент.
ksbes
18.04.2019 16:532*2 = 11 в обычной троичной системе (0,1,2,10,11).
А с джоином и сам накалывался. Просто чаще всего его делают по PK/FK, и получают уникальность по определению. Но стоит отойти от «стандартной схемы» — бац и попал. (Я не датабейзник, но если настойчиво просят — куда деваться)0xd34df00d
18.04.2019 17:0111 в троичной равно 4 в десятичной, так что вы ничего принципиально нового не выигрываете, это вопрос нотации.
Вот куда интереснее рассмотреть циклическую группу порядка 3 или 4...
luck1ess
19.04.2019 12:29Ох, мой дорогой любитель неевклидовых пространств, пространства они про вектора, а не скаляры. Какое у вас было пространство, если не секрет?) Кстати вот вам задачка, 1*2=3, угадайте про какую геометрию, работает на вещественных числах.
eviland
18.04.2019 18:05Кстати, Еще маленький совет по производительности. Если нужно просто найти элементы в таблице, которых нет в другой таблице, то лучше использовать не 'LEFT JOIN… WHERE… IS NULL', а конструкцию EXISTS. Это и читабельнее, и быстрее.
Читабельность — ок. Но чем быстрее — можно подробнее? Во всех ли случаях одно будет быстрее другого и есть ли вообще разница? Если да, то в каких СУБД?mayorovp
18.04.2019 19:37В СУБД с полноценным оптимизатором не важно какой метод использовать.
Но если оптимизатор не в курсе что равенство Not Nullable-поля NULL равносильно отсутствию записи — то вариант с EXISTS и правда будет быстрее.
А если оптимизатор не умеет нормально работать с подзапросами — то быстрее может оказаться уже LEFT JOIN.eviland
18.04.2019 22:36+1Вот и я об этом. В общем виде, без привязки к конкретной СУБД и более того, без понимания какие у вас данные — этот совет скорее вредный, чем полезный. В одну копилку с «full scan — это плохо», «nested loop — это плохо», а так же классикой жанра «если нет индекса — надо создать». Нет времени объяснять, делайте как я говорю.

force
19.04.2019 19:16С помощью NOT EXISTS я в своё время убивал Access и MySql (мой любимый тест на оптимизатора базы), базы поумнее, конечно же себе такого не позволяли, но JOIN'ы отрабатывали правильно все. Так что, на мой взгяд во всех базах идёт оптимизация вначале на джойны, а не на EXISTS

Timyrlan
18.04.2019 18:09-2"-Доктор, когда я делаю вот так, у меня вот тут болит
-Неделайте так"
Не надо писать код, который не очевиден для 99% программистов. Это с высокой вероятностью приведет к тому, что в код будет внесен баг рано или поздно. Код, простите за баян, надо писать так, будто поддерживать его будет склонный к насилию маньяк.staticlab
18.04.2019 22:19Вы предлагаете не использовать джойны, потому что маньяк может не уметь ими пользоваться?
limassolsk
18.04.2019 22:22+1Понимание джойнов сломано. Это точно не пересечение кругов, честно
«пересечение кругов» — это не сам джойн, а только его условие.
Из всех вариантов «корректного объяснения джоинов на картинке» мне понравился вариант Evir:

Но на нём слишком много элементов, можно упростить просто взяв любую картинку с «пересечением» и добавить на неё знак умножения:

Тогда если у человека, проводящего собеседование, останутся вопросы, то можно легко объяснить, что «пересечение» таблиц будет происходить на основе «условия джойна», а дальше будет «декартово произведение» всех попавших под условие элементов.
Т.е. для примеров из статьи:
JOIN {1,1,2} и {1,1,3} = {1,1}x{1,1} = {(1,1), (1,1), (1,1), (1,1)}
LEFT JOIN {1,1,2} и {1,1,3} = {1,1}x{1,1} + {2}
RIGHT JOIN {1,1,2} и {1,1,3} = {1,1}x{1,1} + {3}
kurt_mt
19.04.2019 12:13-1dilukhin
19.04.2019 14:10-1Конечно, JOIN это не пересечение кругов, или по-научному это не конъюнкция. Это внезапно операция умножения. Да, она похожа на конъюнкцию, в том, что если где-то чего-то нет, то и в результат оно не попадает. Но в «середине» идёт перебор каждый к каждому, что для пересечения множеств несвойственно.

minamoto
19.04.2019 15:57В этом случае иногда бывает выгодно вынести часть запроса в подзапрос CTE; например, если вы точно знаете, что, поджойнив две таблицы, мы получим очень мало записей, и остальные джойны будут стоить копейки.
В общем случае это неверно. Не знаю, как там в Постгре, а вот в MS SQL, например, CTE (если не рекурсивный) — это просто синтаксический сахар для удобства написания, и при выполнении будет развернут в подзапросы, соответственно оптимизатор соединит их, как посчитает нужным, и вы сохраните все те же проблемы с множеством соединяемых таблиц.
Не раз и не два уже оптимизировал запросы именно за счет избавления от CTE и перевода их в лоб на временные таблицы, которые, действительно, будут выполняться последовательно, и для заполнения каждой временной таблицы будет свой отдельный план выполнения.varanio Автор
19.04.2019 16:19в посгре со следующей версии можно будет выбирать, как трактуется подзапрос cte — как временная таблица или как обычный подзапрос
В текущей 11 версии это всегда временная таблица

Anarchist
20.04.2019 05:05-1Во-первых, строки в таблицах таки уникальны с точки зрения БД. Другое дело, что эту уникальность «внешнему наблюдателю» можно и не увидеть.
Во-вторых, самое близкое к джойнам (в случае внутренних — так вообще точное определение) теоретико-множественное понятие — это отношения: ru.wikipedia.org/wiki/%D0%9E%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D0%B5_(%D1%82%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2)
Mikluho
20.04.2019 13:18Вот жежь заморочились на ровном месте :)
Множества, алгебра, картинки…
Я очень давно теорию изучал и нифига не помню определения, особенно теоретические. Но для себя оставил в голове практическое определение, через которое не мало раз объяснял селекты джунам…
Join объединяет записи из двух таблиц, при этом для каждой записи в одной таблице подбираются записи из другой. Вид джойна определяет способ отбора записей в объединённый результат. Left/Right Join — все записи из одной таблицы объединяются с найденными по условию из второй таблицы, а где не нашлось, подставляются пустые строки. Inner Join — то же самое, но без добавления пустых строк. Full — добавляются строки для обеих таблиц. Причём, если условие связи таблиц не определено — подходят все записи.
Ключевое тут — множественное число. Т.е. движок бд «постарается» вытащить всё, что сможет, ибо условия — это ограничения.
smbsmn
20.04.2019 21:16Джойны (inner-outer) объясняются просто — в 1 книжке читал, не помню, как называется.
Представьте, что вы на свадьбе.
INNER JOIN — если со свадьбы выходят только семейные пары.
LEFT JOIN — если со свадьбы выходят семейные пары и ещё любовницы мужей.
RIGHT JOIN — если со свадьбы выходят семейные пары и ещё любовники жён.
FULL OUTER JOIN — если со свадьбы выходят семейные пары и все любовники и любовницы жён и мужей из семейных пар.
CROSS JOIN — ну это вот…mayorovp
21.04.2019 08:39По логике, если соединялись таблицы мужчин и женщин по условию брака, то в left join должны добавляться неженатые мужчины, а в right join — незамужние женщины.
А каким должно быть соединение чтобы туда стали попадать любовники и любовницы — представить не могу.smbsmn
21.04.2019 11:24В контексте объяснения — для брака — это тоже НАЛЛ.
Ты прав — твой пример с неженатыми-незамужними лучше.
smbsmn
20.04.2019 21:52В постгресе вроде такого нет, но в оракле с 12-го наличествует.
Какой ответ ТС ожидает получить от собеседуемого об APPLY?
КАК это нужно показать на пальцах?
ЗЫ
Я, честно признаться, не очень понимаю валидность этих технических оффлайновых собеседований.
У меня на гитхабе выложен пет-проект по расчёту сальдооборотов для домашнего учёта.
Там всё ок.
Последние несколько лет работаю программистом БД, реально бизнес-логику пишу.
+ рефакторинг и оптимизация легаси.
НО.
Возможно, я интроверт. Или панические атаки случаются.
Последний раз на собеседовании я не смог на бумажке к схеме СКОТТ элементарный запрос написать.
Хотя на работе на доске я, бывает, примерно такие запросы пишу.
smbsmn
20.04.2019 22:15Кстати, насичёт синтаксического сахара и реляционной алгебры: ни разу в продакшне не видел EXCEPT или INTERSECT.
Кто-то видел???





little-brother
Потому что так оно и будет в 99% случаев использования (плюс возможно условия на поля, которые можно вынести в where).
Как впрочем и с дублированием строк. Очень редко нужны такие запросы, когда соединение проходит не по уникальному ключу.
kolu4iy
Опередили ) как раз хотел написать, что приличные люди джойнят по ключу, по возможности ) хотя, безусловно, бывает всякое.
varanio Автор
в целом согласен
Однако, к примеру join по пересечению диапазонов ip адресов в моей практике встречался очень часто. Так то зависит от специфики проекта.
В любом случае, надо знать возможности, а применять только там и где надо.
kolu4iy
И я с вами, безусловно, не спорю. У самого на работе самописная erp которой больше 20 лет: там физически невозможно все поддерживать красиво.
dimaaan
Прямо прочитали мои мысли :)
Вместо того, чтобы молча записывать человека в "неумехи", лучше задать наводящий вопрос.
Мол, что будет в случае с дубликатами?
И тогда уже делать выводы.
WinLin2
А откуда дубликаты id в обоих таблицах?
dimaaan
Просто id — это неправильное название в данном случае.
Сбивает с толку.
Считайте, там просто колонка с числами.
VMichael
Это проблема на самом деле, что люди считают, что раз в 99% случаев (хотя откуда такая статистика?) будет так, то и лепить можно так во всех случаях, не очень понимая правильно ли это.