
Привет. Хочу вам рассказать, как мы шли по дороге понимания производительности нашей системы Set Retail 10. А именно, как мы учились измерять производительность, и какими способами отслеживали ее изменения.
Для тестирования мы построили стенд производительности, и теперь на несколько дней запускаем на нём нагрузочные тесты. На этапе проработки тестового стенда мы сломали много копий о щиты ожесточённых споров. Но нам удалось найти ответы на самые главные вопросы — что и как делать, и в какой последовательности. Буду рад, если наш опыт станет полезен и вам.
Несколько слов о сервере Set 10. Это Enterprise Java-приложение на 500 бинов, которые разбиты примерно на 100 модулей. Каждый из бинов более или менее связан с остальными. Эта небольшая армия (точнее, батальон) бинов обслуживает 20-30 потоков данных. Логически они не зависят друг от друга, однако, так как все крутится на одной машине, когда начинает литься поток данных это сказывается и на остальных процессах. Я бы сравнил эту систему с котлом где “варятся” бины, и который может “переварить” все, что в него кинут.
До недавнего времени вопросы производительности сервера Set 10 решались «набегами». Мы смотрели места, которые с нашей точки зрения работали не совсем оптимально. Для таких мест писались разовые скрипты, нагружающие эти места и как-то показывающие их «проходимость». Далее выполнялись работы по оптимизации таких «проблемных мест», и снова запускались скрипты «нагрузи и померь». По результатам смотрелась разница, делались выводы, насколько увеличилась скорость в этом месте. Потом докладывали начальству, все радовались, но на один вопрос мы никак не могли ответить (а нам его часто задавали): «ОК, вы вот это оптимизировали, и что это дало в целом системе? Насколько она стала быстрее работать?»
Так продолжалось бы и дальше, однако нам потребовалось выработать систематический подход к вопросу производительности. Толчком для этого стала необходимость выдвинуть системные требования для железа, на котором будет крутиться наша сложная система. А сложность тут кроется в том, что модулей много, и потоков данных много. Каждый пользователь системы может использовать одни модули и не использовать другие. К примеру, один клиент может пользоваться внешней системой лояльности, и это никак не будет нагружать большую часть модулей нашего сервера, а другой будет использовать ее активно, имея миллионы клиентских карт и активно выдавать им бонусы, купоны, подарки и т.д.
Один клиент может генерировать по 1 чеку в полчаса с 300 касс, а другой может вести активную торговлю скоростью чек в минуту на каждой из 20 касс. Получается, что одна и та же версия такой «сложной системы» может иметь разные требования у разных клиентов. Вот тут-то и пришло понимание, что система «набегов» не помогает решить эту задачу. Мы не можем выставить требования для всей системы в целом. Нужно знать, какая конфигурация у клиента, и это первая зависимость, которую мы обнаружили.
Чтобы ответить на этот вопрос требуется взять некоторый набор оборудования m1, m2, …. и некоторый набор конфигураций k1, k2 … и найти для каждой такой конфигурации ki оборудование mj — на котором эта конфигурация будет справляться с задачами клиента, а именно с обслуживанием продаж. Сразу скажу, что мы отдельно выделили 3-4 конфигурации, которые взяли за базовые (чтоб хоть как-то сократить количество вариантов), и для которых будем искать требования. Так вот, основной вопрос в том, насколько хорошо работает конкретный сервер на конкретной машине? То есть, взяв конфигурацию Ki на оборудовании Mj, как определить хорошо ли работает система?
Логически — это функция сопоставления работающего под нагрузкой сервера числу:
F(x)->y
Запрограммировав такую функцию в виде кода/скрипта/стенда — мы получим мощный инструмент, который поможет нам ответить на все поставленные перед нами вопросы. Но обо всем по порядку.
F(x): что это за функция и от каких переменных она считается?
Эта функция считает, насколько «хорошо» работает наша сложная система. Не вдаваясь в реализацию, сразу можно сказать, что она зависит как минимум от железа (на быстрых машинках система будет работать лучше, чем на медленных), конфигурации сложной системы (то, о чем я уже говорил выше, кто-то использует одни модули, кто-то другие), версии кода (с выпуском новых версий системы, ее производительность может увеличиваться, или наоборот уменьшаться). Тут можно придумать еще что-то специфичное для вас, но в нашей компании мы договорились, что эти параметры хорошо отражают зависимости производительности. Итого получилась функция от 3-х переменных.
->y: что за значение?
Числовой показатель, хорошо ли работает сервер. Если число большое — сервер работает хорошо. Если число маленькое — сервер работает недостаточно хорошо. Это число может быть как чем-то абстрактным (очки производительности) или же очень конкретным (скорость в конкретных единицах). Важно, чтоб это было одно число, далее станет ясно, почему. Мы в компании договорились, что у нас это будет процентное выражение от достигнутых на этом прогоне бизнес-требований. То есть если мы получили результат F(x)=84%, это означает, что система отвечает требованиям бизнеса на 84%.
Итого, мы получили описание функции как:
F(железо, конфигурация, версия) -> % от бизнес требований
Если мы сможем реализовать эту функцию программно, то мы как раз и получим наш стенд тестирования производительности, который сможет по конфигурации выдать подходящее железо, а на основе железа, сказать, на какую конфигурацию системы можно рассчитывать. Помимо прочего, на таком стенде можно будет (зафиксировав железо и конфигурацию) мерить производительности от версии к версии, а если зафиксировать железо и версию, то можно выделять параметры внутри конфигурации, которые более чем другие влияют на производительность.
Конфигурация
Из 3-х параметров нашей функции производительности только конфигурация вызывает вопросы. Действительно, запуская один и тот же тест на разном оборудовании, мы получим разные значения функции производительности, это понятно и не вызывает особых вопросов. С версией тоже проблем нет — запуская тест на разных версиях, мы так же имеем свободную размерность и можем её менять, как хотим. Но с конфигурацией у нас были большие вопросы. К примеру, какие параметры должны входить в конфигурацию? Как их комбинировать? Кто их должен формулировать — программисты или бизнес? Что в конкретном случае мерить?
После долгих споров мы пришли к следующим выводам:
1. Разработчики составляют список факторов внутри системы, влияющих на производительность (т.к. разработчики более осведомлены в этом вопросе). Каждый такой фактор должен быть понятен для всех разработчиков и бизнеса, должна быть возможность его нагрузить и померить. Список факторов должен быть отсортирован в порядке влияния на производительность по мнению разработчиков (реальные тесты могут подтвердить или опровергнуть это предположение).
2. Далее бизнес выставляет требование к каждому фактору по списку. Требование не должно зависеть ни от других частей системы, ни от железа, ни от прочих факторов. Эти требования мы еще использовали для выставления количественной оценки: требование выполнено — 100%, требование выполнено наполовину — 50% и т.д.
3. Так как система работает на одной машине, то нельзя их проверять по очереди (все по очереди они могут работать быстро, но все вместе у реального заказчика — тормозить), поэтому нагружать нужно все и сразу.
Пример:
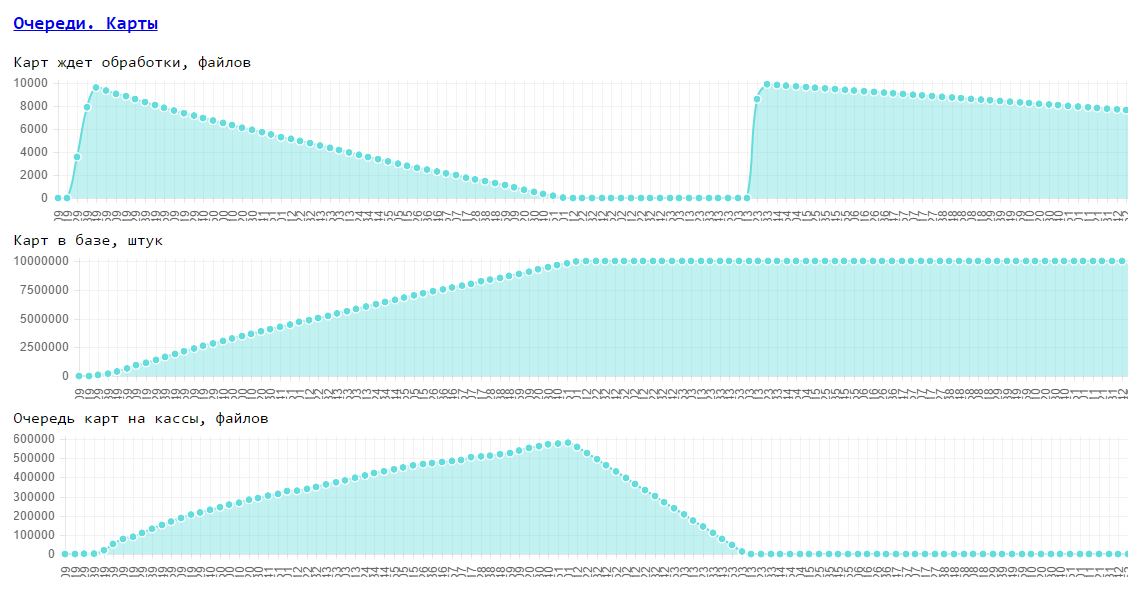
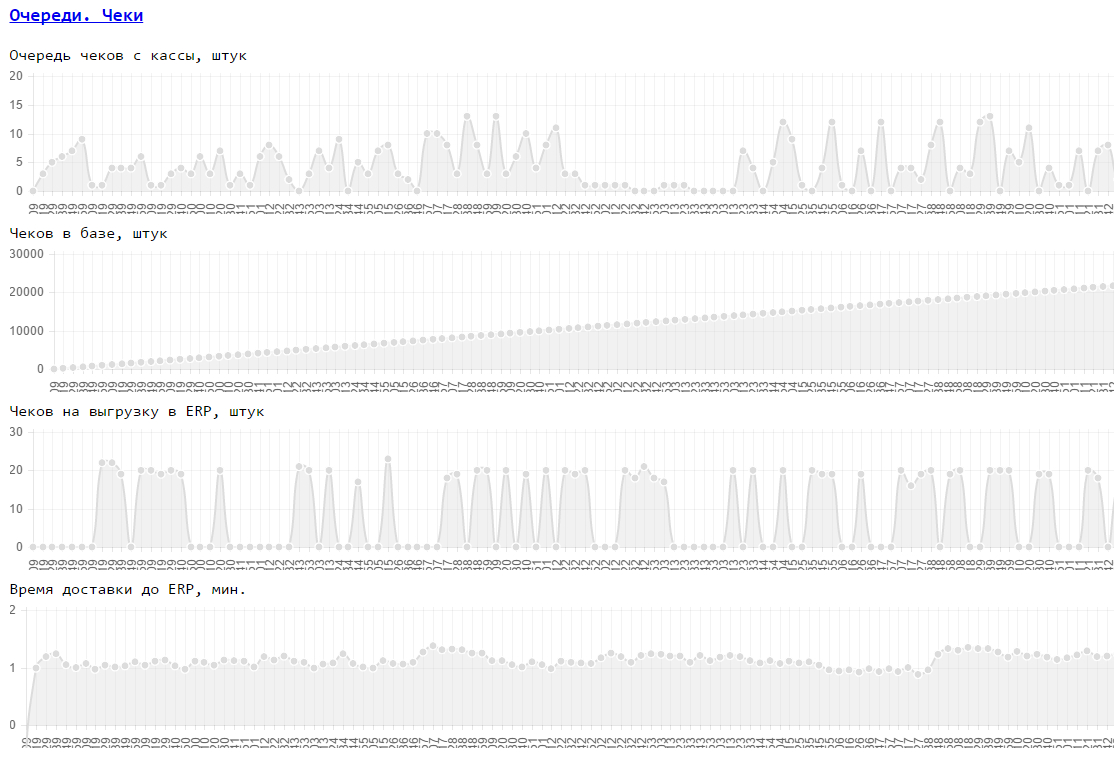
Примеры таких факторов в системе автоматизации продаж ритейлера: Скорость прогрузки товаров, карт, скорость доставки чеков с касс, Скорость формирования отчетов,...
Пример бизнес требований: скорость товаров — 100 товаров/сек на все кассы, скорость карт 100 карт/сек на все кассы, время доставки чека не должно превышать 5 минут.
Пример конфигурации из этих факторов (средний магазин): товаров прогружать — 300 000, карт 10 000 000, касс — 20, чеки шлются с касс — 1 чек/касса/минута.
Реализация
Для реализации стенда производительности мы просмотрели несколько готовых решений, на которых можно было основывать подобный стенд.
Требования были довольно простыми:
1. Возможность запускать sh/bat скрипты, для установки и настройки системы на удаленной машине перед нагрузкой
2. Возможность запускать Java-код для нагрузки системы на удаленной машине
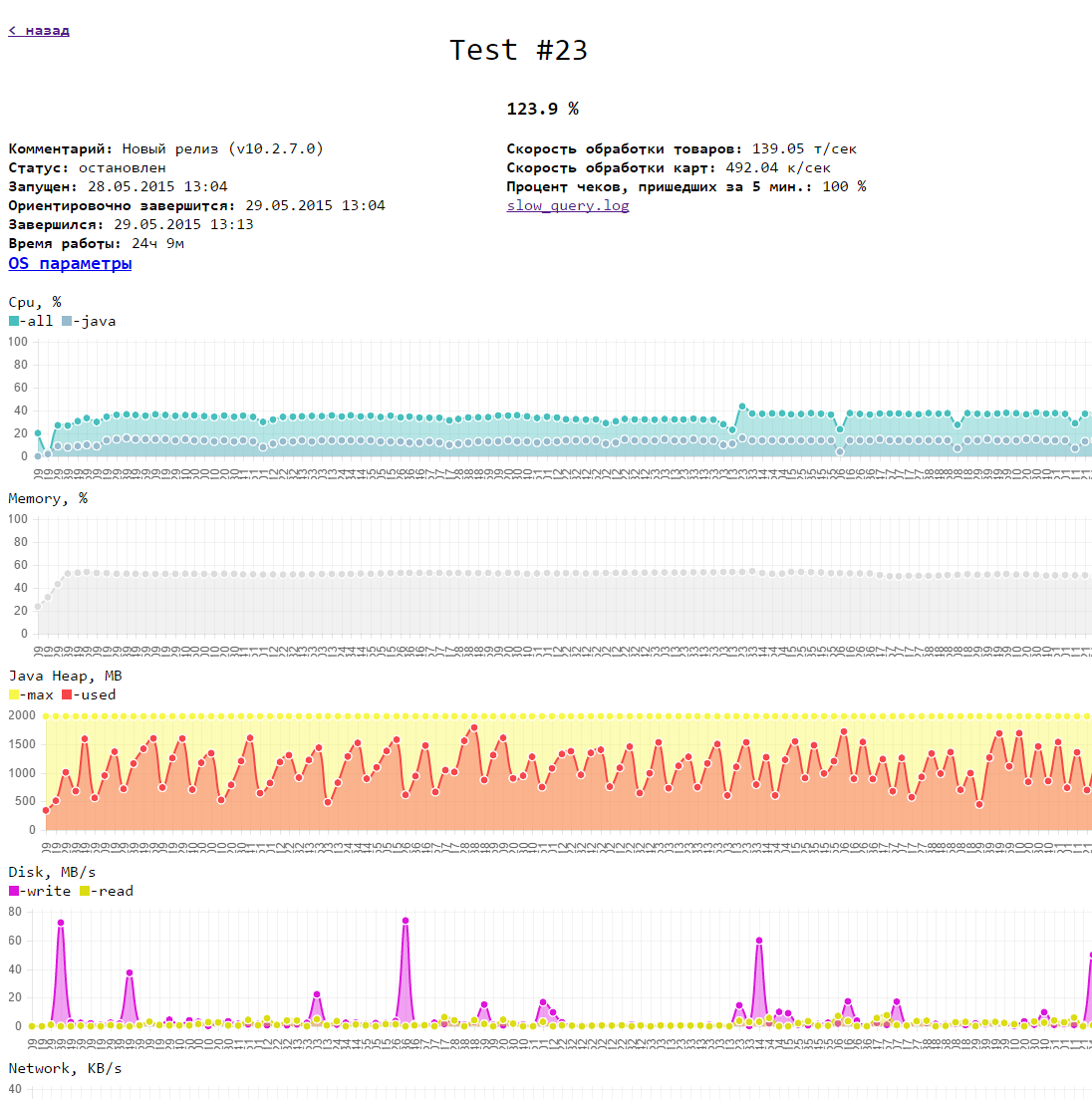
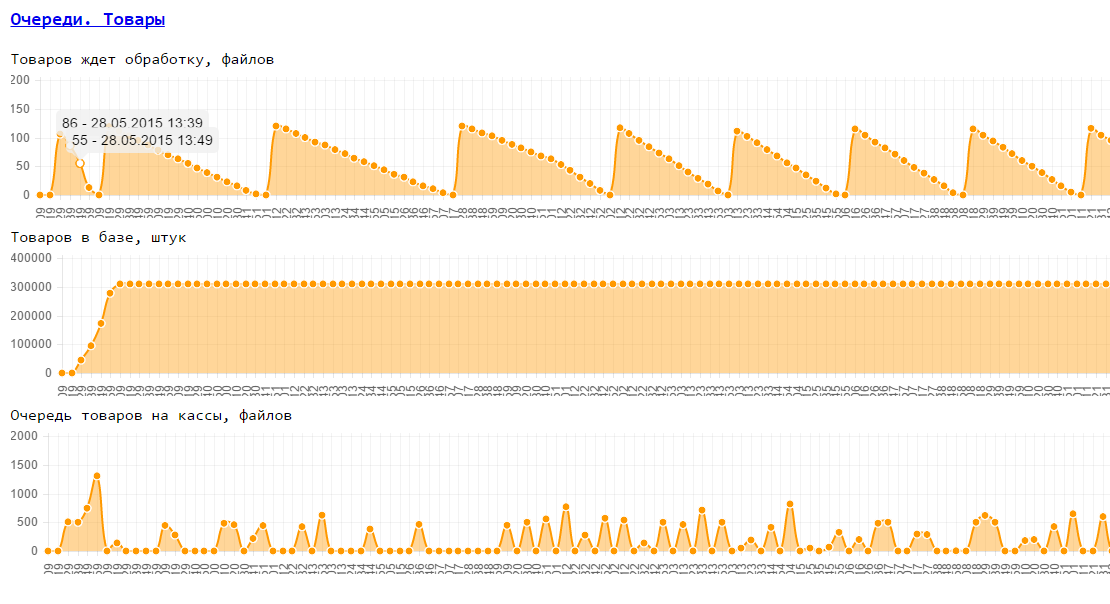
3. Возможность снятия как базовых метрик машины (память, диск, процессор, сеть) так и наших внутренних метрик (доступность по HTTP, внутренние очереди в БД) в процессе теста
4. Возможность все полученные данные теста вывести на 1 странице в виде графиков. Тут могут быть дополнительные данные теста (лог медленных запросов, результаты анализа памяти ...).
Что мы пробовали:
1. JMeter — система нагрузочного тестирования. Очень специфичный инструмент. Изначально разрабатывался для нагрузки WEB-приложений, и это чувствуется. Достаточно сложно реализовать произвольный тест производительности, чтобы потоки нагрузки создавались в определенном месте теста, чтобы был этап ПРЕ-теста и ПОСТ-теста. Много проблем с визуализацией результатов теста (встроены некоторые графики и можно генерить картинки по ним, но все равно генерация общей страницы предполагается делать за пределами JMeter). В общем, написать свой алгоритм теста проще оказалось на Java, чем разбираться с многообразием нодов JMeter и их последовательностью и ограничениями.
2. Zabbix — система мониторинга. Умеет запускать скрипты и мониторить любые метрики. Рассматривалась возможность логику теста зашить в скрипты (не очень хотелось так делать) или вынести в Java. Огромный плюс zabbix’a — он уже умеет мониторить основные параметры системы и можно легко дописывать свои параметры для мониторинга. Плюс есть наглядные графики. Но мы нашли еще более простое решение.
3. Glances — система мониторинга. Позволяет мониторить основные параметры удаленной машины. Легко устанавливается, запускается в виде сервера и имеет API по HTTP/Json. Все очень просто и удобно.
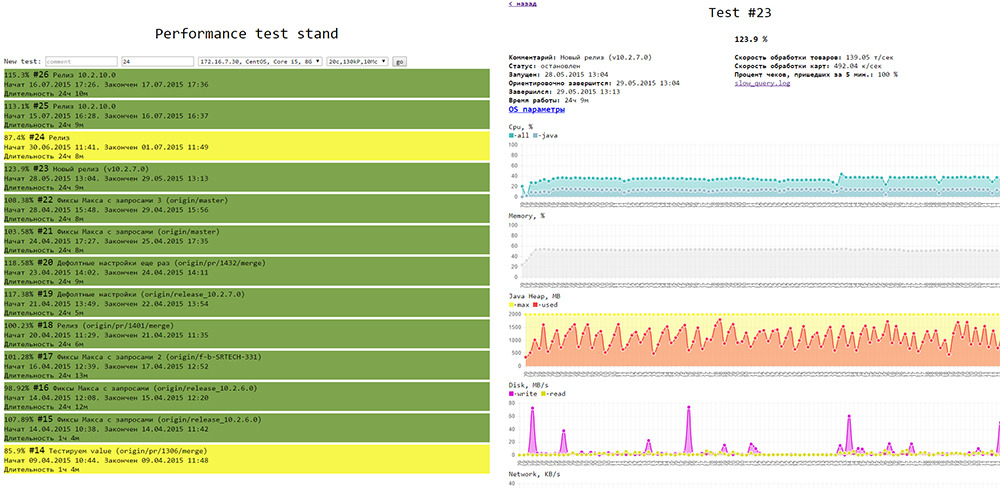
В итоге, логику теста мы реализовали на Java, мониторинг работает на glances, небольшой веб-сервис умеет запускать тесты и показывать их результаты (html, js), для графиков использовали chartJS
Выглядит это так: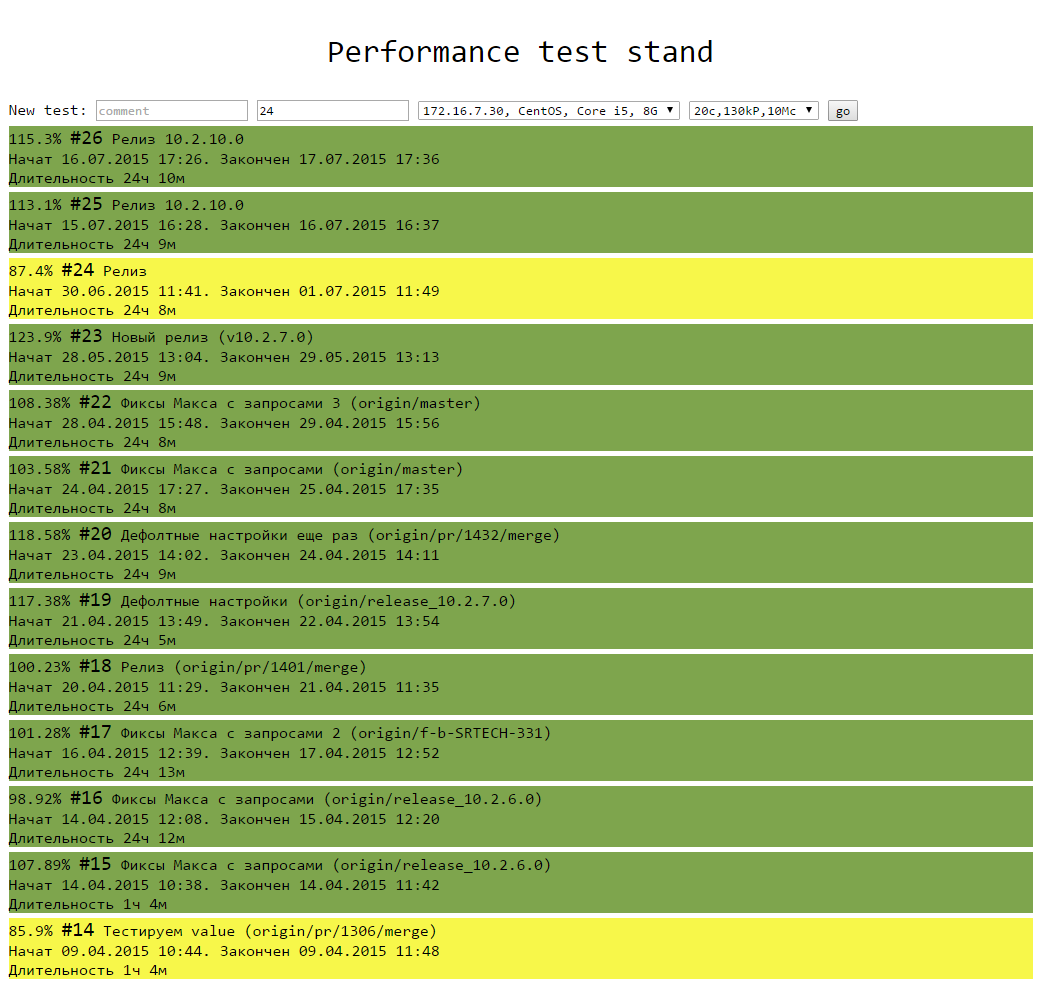
Maklaut
Повествование как-то неожиданно заканчивается.
Получилось ли в итоге реализовать все что было изначально задумано?
Очень интересно увидеть реальную формулу F(x).
nikolaikopernik Автор
F(x) -по факту не имеет формулы, это конкретный прогон стенда на определенном железе, настройках и версии продукта. После такого прогона есть результаты (пишем F(x)=y, где y- результаты).
Поясню на нашем конкретном примере. В нашем случае проверяются 3 показателя системы — скорость обработки карт ©, скорость обработки товаров(T) и запаздывание чеков более, чем на 5 минут(P). Далее, каждый прогон (F(x) выдает конкретные цифры этих показателей(C_real,T_real,P_real), сравнивая их с бизнес требованиями для этих показателей (C_expect,T_expect,R_expect) получим числовой результат прогона.
Т.е. что-то вроде F(x)= min(C_real/C_expect*100,T_real/T_expect*100,P_real/P_expect*100) — наихудший показатель в процентром соотношении
это и есть результат. Сейчас созданный стенд дал нам возможность следить за этим результатом. Можно посмотреть как железо или настройки меняют этот результат. Ну а далее, мы будем увеличивать число параметров, по которым считается результат прогона.