
Сегодня мы посмотрим на то, как из версий строк получаются согласованные снимки данных.
Что такое снимок данных
Физически в страницах данных могут находиться несколько версий одной и той же строки. При этом каждая транзакция должна видеть только одну (или ни одной) версию каждой строки так, чтобы вместе они составляли согласованную в ACID-смысле картину данных на определенный момент времени.
Изоляция в PostgreSQL строится на основе снимков данных (snapshot): каждая транзакция работает со своим снимком данных, который «содержит» данные, которые были зафиксированы до момента создания снимка, и не «содержит» еще не зафиксированные на этот момент данные. Мы уже видели, что изоляция при этом получается более строгая, чем требует стандарт, но не лишенная аномалий.
На уровне изоляции Read Committed снимок создается в начале каждого оператора транзакции. Такой снимок активен, пока выполняется оператор. На рисунке момент создания снимка (который, как мы помним, определяется номером транзакции) показан синим цветом.

На уровнях Repeatable Read и Serializable снимок создается один раз в начале первого оператора транзакции. Такой снимок остается активным до самого конца транзакции.
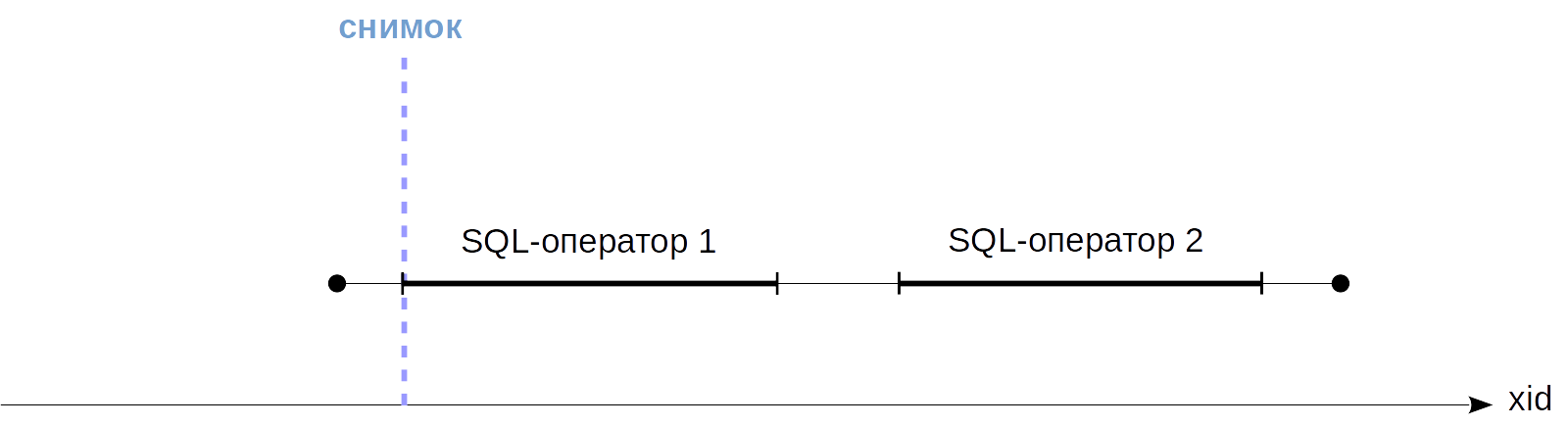
Видимость версий строк в снимке
Правила видимости
Конечно, снимок не является физической копией всех необходимых версий строк. Фактически снимок задается несколькими числами, а видимость версий строк в снимке определяется правилами.
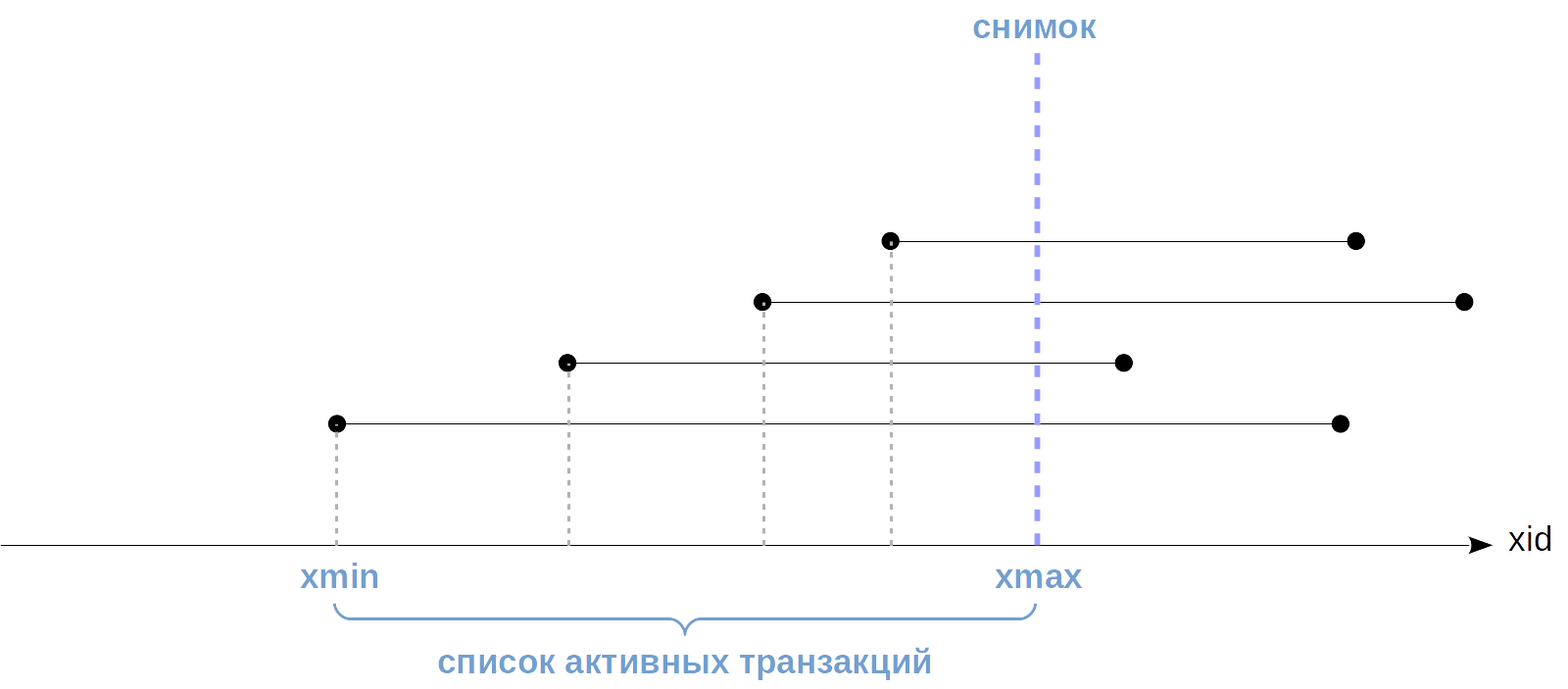
Будет или нет данная версия строки видна в снимке, зависит от двух полей ее заголовка — xmin и xmax, — то есть от номеров создавшей и удалившей транзакций. Такие интервалы не пересекаются, поэтому одна строка представлена в любом снимке максимум одной своей версией.
Точные правила видимости довольно сложны и учитывают множество различных ситуаций и крайних случаев.
В этом легко убедиться, заглянув в src/backend/utils/time/tqual.c (в версии 12 проверка переехала в src/backend/access/heap/heapam_visibility.c).
Упрощая, можно сказать, что версия строки видна, когда в снимке видны изменения, сделанные транзакцией xmin, и не видны изменения, сделанные транзакцией xmax (иными словами, уже видно, что версия строки появилась, но еще не видно, что ее удалили).
В свою очередь, изменения транзакции видны в снимке, если либо это та же самая транзакция, что создала снимок (она сама видит свои собственные изменения), либо транзакция была зафиксирована до момента создания снимка.
Можно изобразить транзакции графически в виде отрезков (от момента начала до момента фиксации):

Здесь:
- изменения транзакции 2 будут видны, потому что она завершились до создания снимка,
- изменения транзакции 1 не будут видны, потому что она была активна на момент создания снимка,
- изменения транзакции 3 не будут видны, потому что она начались позже создания снимка (не важно, закончилась она или нет).
К сожалению, момент фиксации транзакций неизвестен системе. Известен только момент ее начала (он определяется номером транзакции и отмечен на рисунках выше пунктирной линией), но факт завершения нигде не записывается.
Все, что мы можем — это узнать текущий статус транзакций при создании снимка. Эта информация есть в общей памяти сервера в структуре ProcArray, которая содержит список всех активных сеансов и их транзакций.
А постфактум мы уже не сможем понять, была ли какая-то транзакция активна в момент создания снимка или нет. Поэтому список всех текущих активных транзакций приходится запоминать в снимке.
Из сказанного следует, что в PostgreSQL нельзя создать снимок, показывающий согласованные данные по состоянию на произвольное время назад, даже если все необходимые для этого версии строк существуют в табличных страницах. Часто приходится слышать вопрос, почему в PostgreSQL нет ретроспективных (или темпоральных; в Oracle это называется flashback query) запросов — вот одна из причин.
Забавно, что изначально такая функциональность была, но позже ее убрали из СУБД. Про это можно прочитать в статье Джозефа Хеллерштейна.Итак, снимок данных определяется несколькими параметрами:
- моментом создания снимка, а именно, номером следующей, еще не существующей в системе, транзакции (snapshot.xmax);
- списком активных транзакций на момент создания снимка (snapshot.xip).
Для удобства и оптимизации отдельно сохраняется и номер самой ранней из активных транзакций (snapshot.xmin). Это значение имеет важный смысл, о котором мы поговорим ниже.
Также в снимке сохраняются еще несколько параметров, но они для нас не важны.
Пример
Чтобы посмотреть, как видимость определяется снимком, воспроизведем ситуацию с тремя транзакциями, рассмотренную выше. В таблице будут три строки, причем:
- первая добавлена транзакцией, которая началась до создания снимка, но завершилась позже,
- вторая добавлена транзакцией, которая началась и завершилась до создания снимка,
- третья была добавлена уже после создания снимка.
=> TRUNCATE TABLE accounts;
Первая транзакция (еще не завершилась):
=> BEGIN;
=> INSERT INTO accounts VALUES (1, '1001', 'alice', 1000.00);
=> SELECT txid_current();
=> SELECT txid_current();
txid_current
--------------
3695
(1 row)
Вторая транзакция (завершилась до создания снимка):
| => BEGIN;
| => INSERT INTO accounts VALUES (2, '2001', 'bob', 100.00);
| => SELECT txid_current();
| txid_current
| --------------
| 3696
| (1 row)
| => COMMIT;
Создаем снимок в транзакции в другом сеансе.
|| => BEGIN ISOLATION LEVEL REPEATABLE READ;
|| => SELECT xmin, xmax, * FROM accounts;
|| xmin | xmax | id | number | client | amount
|| ------+------+----+--------+--------+--------
|| 3696 | 0 | 2 | 2001 | bob | 100.00
|| (1 row)
Завершаем первую транзакцию после того, как создан снимок:
=> COMMIT;
И третья транзакция (появилась позже создания снимка):
| => BEGIN;
| => INSERT INTO accounts VALUES (3, '2002', 'bob', 900.00);
| => SELECT txid_current();
| txid_current
| --------------
| 3697
| (1 row)
| => COMMIT;
Очевидно, что в нашем снимке по-прежнему видна одна строка:
|| => SELECT xmin, xmax, * FROM accounts;
|| xmin | xmax | id | number | client | amount
|| ------+------+----+--------+--------+--------
|| 3696 | 0 | 2 | 2001 | bob | 100.00
|| (1 row)
Вопрос в том, как это понимает PostgreSQL.
Все определяется снимком. Посмотрим на него:
|| => SELECT txid_current_snapshot();
|| txid_current_snapshot
|| -----------------------
|| 3695:3697:3695
|| (1 row)
Здесь через двоеточие перечислены snapshot.xmin, snapshot.xmax и snapshot.xip (в данном случае один номер, но в общем — список).
По сформулированным выше правилам, в снимке должны быть видны изменения, сделанные транзакциями с номерами snapshot.xmin <= xid < snapshot.xmax, за исключением попавших в список snapshot.xip. Посмотрим на все строки таблицы (в новом снимке):
=> SELECT xmin, xmax, * FROM accounts ORDER BY id;
xmin | xmax | id | number | client | amount
------+------+----+--------+--------+---------
3695 | 0 | 1 | 1001 | alice | 1000.00
3696 | 0 | 2 | 2001 | bob | 100.00
3697 | 0 | 3 | 2002 | bob | 900.00
(3 rows)
Первая строка не видна — она создана транзакцией, которая входит в список активных (xip).
Вторая строка видна — она создана транзакцией, которая попадает в диапазон снимка.
Третья строка не видна — она создана транзакцией, которая не входит в диапазон снимка.
|| => COMMIT;
Собственные изменения
Несколько усложняет картину случай определения видимости собственных изменений транзакции. Здесь может потребоваться видеть только часть таких изменений. Например, курсор, открытый в определенный момент, ни при каком уровне изоляции не должен видеть изменений, сделанных после этого момента.
Для этого в заголовке версии строки есть специальное поле (которое отображается в псевдостолбцах cmin и cmax), показывающее порядковый номер операции внутри транзакции. Cmin представляет номер для вставки, cmax — для удаления, но для экономии места в заголовке строки это на самом деле одно поле, а не два разных. Считается, что вставка и удаление той же строки в одной транзакции выполняется редко.
Если же это все-таки происходит, то в то же самое поле вставляется специальный «комбо»-номер, про который обслуживающий процесс запоминает реальные cmin и cmax. Но это уже совсем экзотика.
Простой пример. Начнем транзакцию и добавим в таблицу строку:
=> BEGIN;
=> SELECT txid_current();
txid_current
--------------
3698
(1 row)
INSERT INTO accounts(id, number, client, amount) VALUES (4, 3001, 'charlie', 100.00);
Выведем содержимое таблицы вместе с полем cmin (но только для строк, добавленных нашей транзакцией — для других оно не имеет смысла):
=> SELECT xmin, CASE WHEN xmin = 3698 THEN cmin END cmin, * FROM accounts;
xmin | cmin | id | number | client | amount
------+------+----+--------+---------+---------
3695 | | 1 | 1001 | alice | 1000.00
3696 | | 2 | 2001 | bob | 100.00
3697 | | 3 | 2002 | bob | 900.00
3698 | 0 | 4 | 3001 | charlie | 100.00
(4 rows)
Теперь откроем курсор для запроса, возвращающего число строк в таблице.
=> DECLARE c CURSOR FOR SELECT count(*) FROM accounts;
И после этого добавим еще одну строку:
=> INSERT INTO accounts(id, number, client, amount) VALUES (5, 3002, 'charlie', 200.00);
Запрос вернет 4 — строка, добавленная после открытия курсора, не попадет в снимок данных:
=> FETCH c;
count
-------
4
(1 row)
Почему? Потому что в снимке учитываются только версии строк с cmin < 1.
=> SELECT xmin, CASE WHEN xmin = 3698 THEN cmin END cmin, * FROM accounts;
xmin | cmin | id | number | client | amount
------+------+----+--------+---------+---------
3695 | | 1 | 1001 | alice | 1000.00
3696 | | 2 | 2001 | bob | 100.00
3697 | | 3 | 2002 | bob | 900.00
3698 | 0 | 4 | 3001 | charlie | 100.00
3698 | 1 | 5 | 3002 | charlie | 200.00
(5 rows)
=> ROLLBACK;
Горизонт событий
Номер самой ранней из активных транзакций (snapshot.xmin) имеет важный смысл — он определяет «горизонт событий» транзакции. А именно, за своим горизонтом транзакция всегда видит только актуальные версии строк.
Действительно, неактуальную версию требуется видеть только в том случае, когда актуальная создана еще не завершившейся транзакцией, и поэтому пока не видна. Но за «горизонтом» все транзакции уже гарантированно завершились.
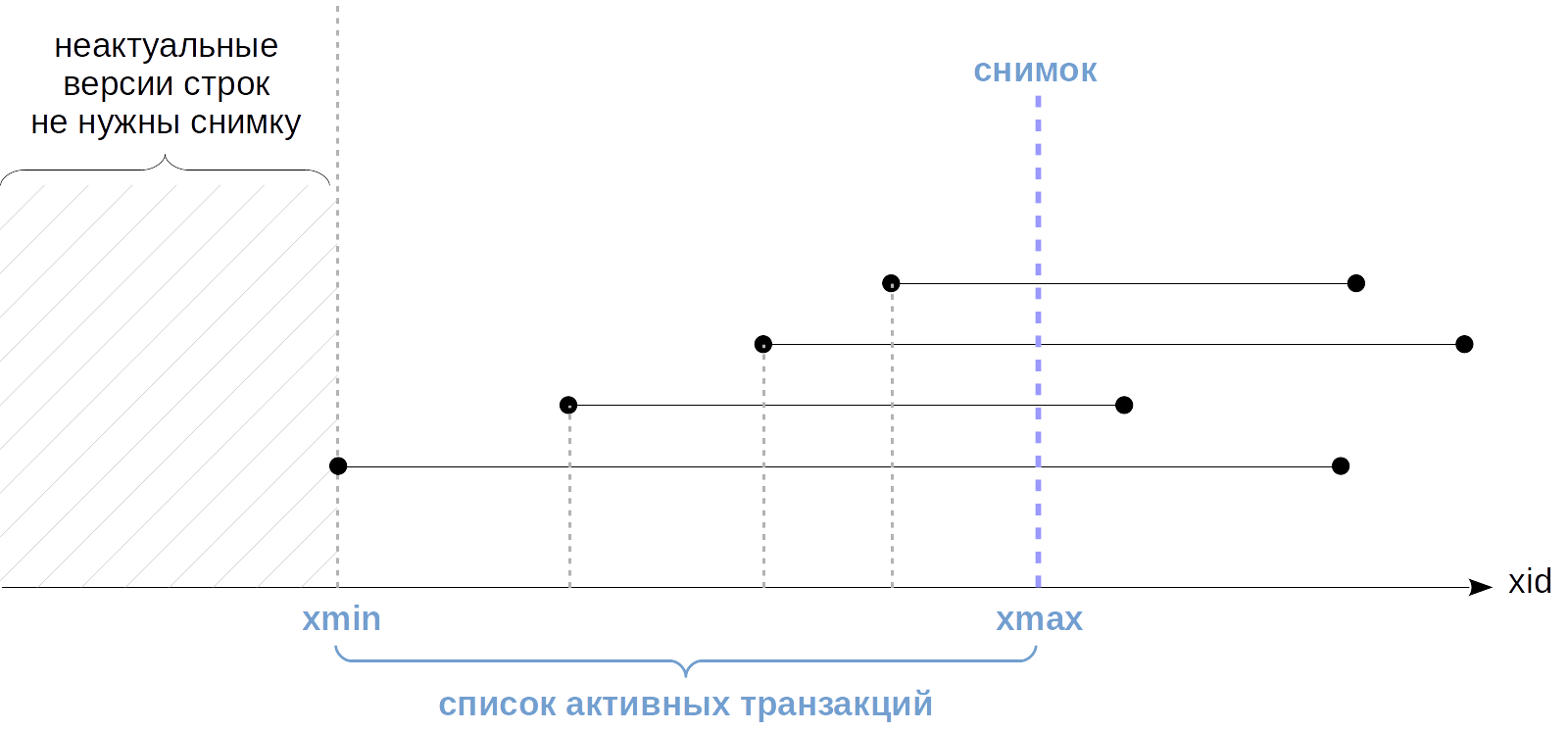
«Горизонт событий» транзакции можно увидеть в системном каталоге:
=> BEGIN;
=> SELECT backend_xmin FROM pg_stat_activity WHERE pid = pg_backend_pid();
backend_xmin
--------------
3699
(1 row)
Также можно определить и «горизонт событий» на уровне базы данных. Для этого надо взять все активные снимки и среди них найти наиболее старый xmin. Он и будет определять горизонт, за которым неактуальные версии строк в этой БД уже никогда не будут видны ни одной транзакции. Такие версии строк могут быть очищены — именно поэтому понятие горизонта так важно с практической точки зрения.
Если какая-либо транзакция будет удерживать снимок в течении долгого времени, она тем самым будет удерживать и горизонт событий базы данных. Более того, незавершенная транзакция будет удерживать горизонт самим фактом своего существования, даже если в ней не удерживается снимок.
А это означает, что неактуальные версии строк в этой БД не могут быть очищены. При этом «долгоиграющая» транзакция может никак не пересекаться по данным с другими транзакциями — это совершенно не важно, горизонт базы данных один на всех.
Если теперь в виде отрезка изобразить не транзакции, а снимки (от snapshot.xmin до snapshot.xmax), то ситуацию можно представить себе так:
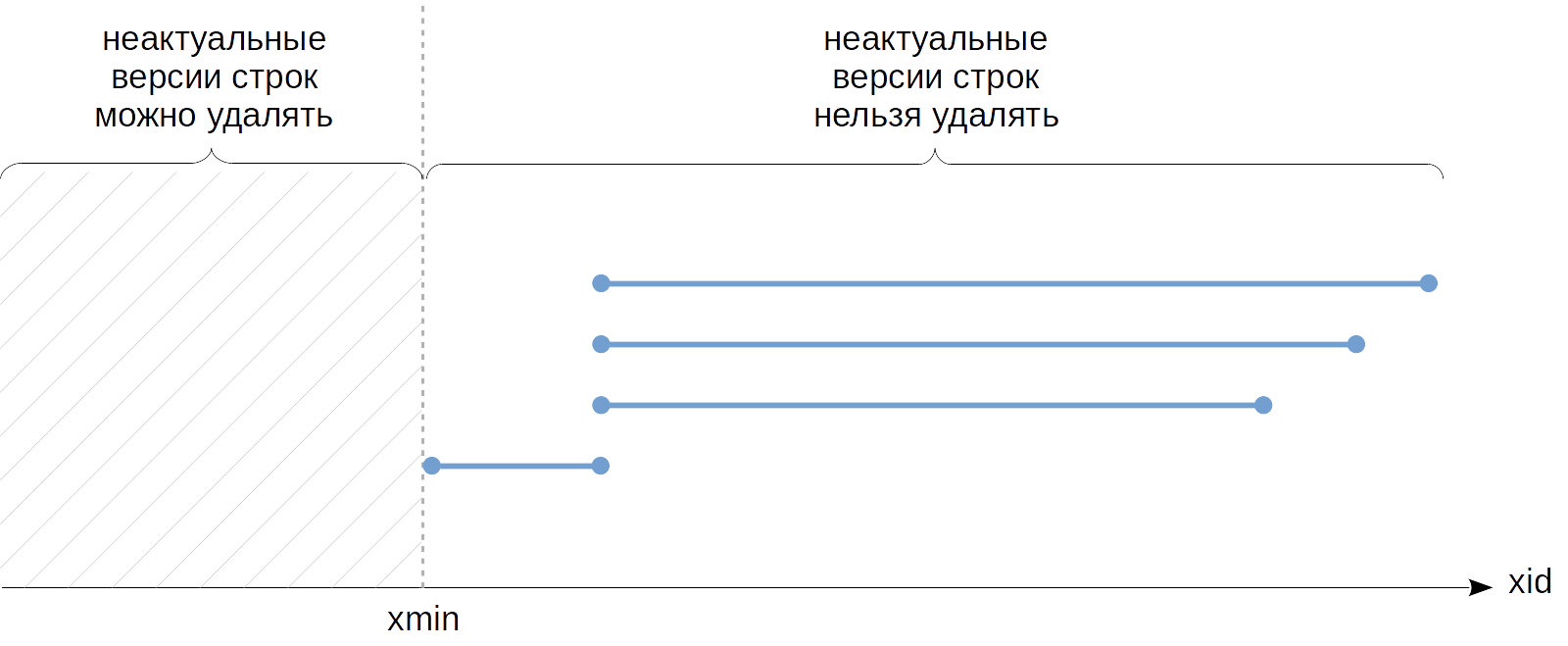
На этом рисунке самый нижний снимок относится к незавершенной транзакции, а в остальных снимках snapshot.xmin не может быть больше ее номера.
В нашем примере была начата транзакция с уровнем изоляции Read Committed. Даже несмотря на то, что в ней нет никакого активного снимка данных, она продолжает удерживать горизонт:
| => BEGIN;
| => UPDATE accounts SET amount = amount + 1.00;
| => COMMIT;
=> SELECT backend_xmin FROM pg_stat_activity WHERE pid = pg_backend_pid();
backend_xmin
--------------
3699
(1 row)
И только после завершения транзакции горизонт продвигается вперед, позволяя очищать неактуальные версии строк:
=> COMMIT;
=> SELECT backend_xmin FROM pg_stat_activity WHERE pid = pg_backend_pid();
backend_xmin
--------------
3700
(1 row)
Если описанная ситуация действительно создает проблемы и нет способа избежать ее на уровне приложения, то, начиная с версии 9.6, доступны два параметра:
- old_snapshot_threshold определяет максимальное время жизни снимка. После этого времени сервер получает право удалять неактуальные версии строк, а если они понадобятся «долгоиграющей» транзакции, но она получит ошибку snapshot too old.
- idle_in_transaction_session_timeout определяет максимальное время жизни бездействующей транзакции. После этого времени транзакция прерывается.
Экспорт снимка данных
Бывают ситуации, когда несколько параллельных транзакций должны гарантированно видеть одну и ту же картину данных. В качестве примера можно привести утилиту pg_dump, умеющую работать в параллельном режиме: все рабочие процессы должны видеть базу данных в одном и том же состоянии, чтобы резервная копия получилась согласованной.
Разумеется, нельзя полагаться на то, что картины данных совпадут просто из-за того, что транзакции запущены «одновременно». Для этого есть механизм экспорта и импорта снимка.
Функция pg_export_snapshot возвращает идентификатор снимка, который может быть передан (внешними по отношению к СУБД средствами) в другую транзакцию.
=> BEGIN ISOLATION LEVEL REPEATABLE READ;
=> SELECT count(*) FROM accounts; -- любой запрос
count
-------
3
(1 row)
=> SELECT pg_export_snapshot();
pg_export_snapshot
---------------------
00000004-00000E7B-1
(1 row)
Другая транзакция может импортировать снимок с помощью команды SET TRANSACTION SNAPSHOT до выполнения первого запроса в ней. Предварительно надо установить и уровень изоляции Repeatable Read или Serializable, потому что на уровне Read Committed операторы будут использовать собственные снимки.
| => DELETE FROM accounts;
| => BEGIN ISOLATION LEVEL REPEATABLE READ;
| => SET TRANSACTION SNAPSHOT '00000004-00000E7B-1';
Теперь вторая транзакция будет работать со снимком первой и, соответственно, видеть три строки (а не ноль):
| => SELECT count(*) FROM accounts;
| count
| -------
| 3
| (1 row)
Время жизни экспортированного снимка совпадает со временем жизни экспортирующей транзакции.
| => COMMIT;
=> COMMIT;
Продолжение следует.
Комментарии (11)

vladimirice
21.04.2019 15:04Егор, большое спасибо за статью!
Традиционно, несколько вопросов:
№1.
На уровне изоляции Read Committed снимок создается в начале каждого оператора транзакции. Такой снимок активен, пока выполняется оператор.
То есть имеем операции «создания»/«удаления» снимка. Их тем больше, чем больше операторов в транзакции
На уровнях Repeatable Read и Serializable снимок создается один раз в начале первого оператора транзакции. Такой снимок остается активным до самого конца транзакции.
То есть имеем всего одну операцию «создания»/«удаления» снимка.
Сам вопрос: Насколько затратны операции «создания»/«удаления»? Можно ли сказать, что уровни Repeatable Read и Serializable
значительно меньше нагружают сервер БД? Или разница ничтожно мала по сравнению с другими действиями для этих транзакций? Я имею ввиду порядки затрат, соизмеримые с порядками затрат оптимизатора, то есть микросекунды. Понятно, что по сравнению с IO операциями передачи данных по сети эти затраты будут ничтожно малы.
Имеется ввиду затратность по:
* RAM — насколько «тяжеловесна» информация о снимке.
* CPU/IO — насколько трудоемко создавать новые снимки (и видимо помечать неактивные к удалению).
№2.
На уровне изоляции Read Committed снимок создается в начале каждого оператора транзакции. Такой снимок активен, пока выполняется оператор.
Что означает понятие «снимок активен» в применении к Read Committed? Это означает, что при создании нового снимка, ранее созданный (например, на момент создания транзакции) уже никак не участвует в транзакции? Как удаляются такие снимки? Они помечаются к удалению или удаляются в рамках той же транзакции?
№3
такие интервалы не пересекаются, поэтому одна строка представлена в любом снимке максимум одной своей версией.
То есть невозможна ситуация, при которой xmin xmax одной и той же строки будут перезаписаны в разных транзакциях? То есть если xmin/xmax когда-либо были записаны — измениться они уже не могут (immutable). При условии, если транзакция изменившая их первой — зафиксировалась.
№4
А для DDL-запросов (тоже транзакционны) изоляции и снимки тоже используются? Насколько механизмы изоляций и снимков отличаются от уже описанных механизмов в этой и в предыдущих статьях?
RPG18
21.04.2019 22:55За Serializable Snapshot Isolation(SSI) мы расплачиваемся раздуванием таблиц и autovacuum.

erogov Автор
22.04.2019 01:58Ну, не совсем. Расплачиваемся мы не за SSI, а за SI (Serializable в этом смысле ничего нового не дает). И даже не за сам SI, а за его реализацию со сборкой мусора.
Есть реализации, которые этим не страдают (как в Оракле, или вот zheap). Но zheap — это пока эксперимент, о нем рановато говорить.
erogov Автор
22.04.2019 01:09Владимир, спасибо. По порядку.
1.
Разницу можно считать ничтожно малой. Это точно не повод задумываться о Repeatable Read (таким поводом должна быть изоляция).
Информация о снимке — это всего несколько чисел, ничего тяжелого. Самое неприятное, с чем там приходится иметь дело — это чтение ProcArray для того, чтобы запомнить список активных транзакций. Это требует блокировки, хоть и разделяемой. Так что при увеличении количества соединений (больше нескольких сотен) ProcArray начинает становиться узким местом, и надо думать о пуле соединений.vladimirice
22.04.2019 09:09Спасибо, а как пул соединений поможет в данном случае? Насколько я понял, источник информации о состоянии транзакций «один на всех»
erogov Автор
22.04.2019 15:06Просто соединений (и, следовательно, одновременных транзакций) будет меньше. Толкотня за ProcArray уменьшится.
erogov Автор
22.04.2019 01:192.
На каком-то уровне абстракции (достаточном для понимания происходящего) можно просто считать, что снимок живет столько, сколько запрос/транзакция, и потом исчезает.
Если влезать глубже, то начинаются всякие детали, в которых легко погрязнуть. Если прям хочется копнуть, то можно начинать сsrc/backend/utils/time/snapmgr.c. Но не уверен, что это сильно полезно.
erogov Автор
22.04.2019 01:263.
Одну и ту же строку две разные транзакции не могут изменять одновременно; одна из них будет заблокирована. Ну и в целом версии идут одна за другой — одна стала неактуальной, появилась другая актуальная, xmax одной будет равен xmin другой.
erogov Автор
22.04.2019 01:524.
DDL — это по сути изменение таблиц системного каталога. Для системного каталога тоже используется многоверсионность и снимки, это и дает нам транзакционный DDL. Но отличия все же есть.
Внешне все выглядит так, как будто для таблиц системного каталога всегда действует уровень Repeatable Read, даже на Read Committed.
Но я в это глубоко не влезал, а надо бы. Так что за этот вопрос отдельное спасибо, поизучаю.
DmitryOgn
Спасибо, интересно!
erogov Автор
Рад! Оставайтесь с нами (: