
Здесь будет предложен «новый» метод выделения тренда — простой, очевидный и пригодный для очень сложных видов тренда.
Под трендом обычно понимают сверхнизкочастотную негармоническую компоненту, резко нарушающую стационарность процесса. Наиболее частой причиной тренда в экспериментально полученных данных является «дрейф нуля» регистрирующей аппаратуры. Интегрирование данных и некоторые другие виды обработки также могут стать причиной появления тренда. Наличие тренда сильно искажает результаты последующей обработки данных (спектральное оценивание и т.п.), поэтому удаление тренда является необходимым. В ряде случаев сам тренд является ценным источником информации (например, при анализе долгосрочных тенденций в экономических или метео- процессах).
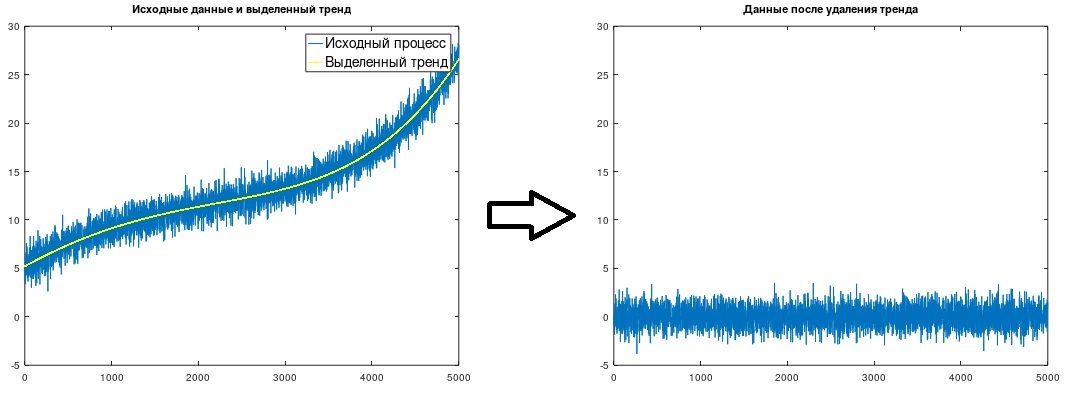
Рис. 1. Выделение и удаление тренда
Обычно тренд моделируют с помощью линейных или степенных (2-го или 3-го порядка) функций, коэффициенты которых вычисляют, умножая процесс на определенные последовательности и применяя затем довольно сложные формулы, выведенные на основании метода наименьших квадратов. (см., например, Дж.Бендат, А. Пирсол, «Прикладной анализ случайных данных», М., Мир, 1989.) Ниже предлагается несколько модифицированный метод, также основанный на методе наименьших квадратов, который очень прост в понимании и освоении, и не требует ни обращения к справочникам, ни самостоятельных сложных символьных выкладок для получения необходимых зависимостей, при этом позволяет моделировать тренд функциями любого вида. Этот модифицированный метод настолько прост и очевиден (освоив однажды, скрипты можно потом писать по памяти), что наверняка уже не раз «изобретался» разными исследователями, но мне пока что-то не попадался ни в каких источниках.
Для выделения тренда производится аппроксимация исходного процесса x[i], состоящего из N+1 отсчетов, с помощью малого количества k составляющих тренд функций uj[i]:
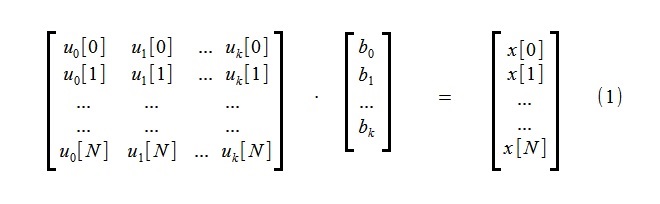
(Обычно в качестве функций uj[i] выбирают степенные функции,

но для данного метода это абсолютно непринципиально)
Система линейных алгебраических уравнений (1) включает k неизвестных bj и N+1 уравнений.
Принимая обозначения:

записываем более компактно

Применение метода наименьших квадратов при поиске приближенного решения переопределенной системы, в матричной форме записывается так:

При написании скрипта: Естественно, никакой необходимости хранить целиком большую матрицу U нет, элементы матрицы UT U и вектора UTx можно «накапливать» пошагово.
Система (4) из k уравнений и k неизвестных решается очевидными методами -ну, например, запишем так:

после чего, по найденным bj, можно построить тренд ?[i] в виде
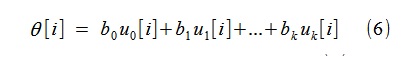
Для примера был смоделирован случайный процесс x[i] вида
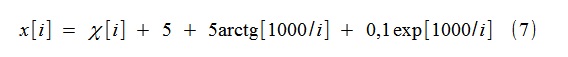
где ?[i]- гауссов белый шум с единичной дисперсией. Тренд смоделирован функциями типа(2) (точнее,(8)), до 4-го порядка включительно (k=4).
При использовании для моделирования тренда степенных функций следует заметить, что матрица UT U (4) теоретически всегда обратима в силу линейной независимости этих функций, однако при высоких порядках k (либо очень длинных реализациях N, что менее критично) определенные ее элементы могут быть очень велики по абсолютной величине. При высоких порядках k в случае вычислительных затруднений рекомендуется использовать понижающие коэффициенты, например, такие (8):

(?t=1), что и было сделано в рассмотренном примере. Получен тренд, показанный на рис.1.
После выделения тренда его, естественно, следует просто вычесть из исходных данных.
Замечание. Обычно авторитетные источники не рекомендуют работать с моделями тренда порядка выше k=2 (квадратной параболы). Связано ли это со сложностью определения «амплитудных» коэффициентов bj традиционными методами, или с упомянутым выше исчерпанием порядков машинных переменных, или с ложным отнесением к тренду информативных составляющих процесса, не очень понятно. В приведенном примере тренд 4-го порядка выделен вроде бы довольно правдоподобно (правда, не намного отличаясь от тренда 3-го порядка). Для особо сложных случаев источники рекомендуют использовать иной метод — низкочастотную фильтрацию (здесь не рассматривался).
Выделение тренда, как показано выше — процедура не столь уж и сложная, позволяет либо выделить и проанализировать «медленные» тенденции, либо, что чаще, помогает получить «на выходе» качественные данные — центрированный стационарный случайный процесс, пригодный для дальнейшего анализа.
Комментарии (19)

ktod
21.04.2019 21:14Вы не могли бы пояснить, чем для экспериментальных данных предложенный метод лучше того же простейшего ФНЧ «скользящего среднего» с нужным ядром? В чем «цимус» то?

Tereshkov
22.04.2019 04:35Метод лучше тем, что даёт уравнение тренда. Это очень полезно, например, для компенсации температурных трендов датчиков. Однако то, что у автора получилось, — это обычный метод наименьших квадратов (см. мой комментарий ниже).
crowncork Автор
22.04.2019 09:32Прикиньте, какого порядка (размера) понадобится такой нерекурсивный фильтр, чтобы «выловить» линейный или «квадратный» тренд (ширину главного «горба» этого ядра Дирихле, чтобы частота отсечения соответствовала периоду, скажем, в две длины реализации сигнала). Тренды обычно очень «медленные» по сравнению с длиной реализации. Фильтруя длинным фильтром, придется потерять значительную часть реализации в начале и в конце (или «достраивать нулями», что привнесет свои ощутимые искажения), и при этом, скорее всего, все равно в «тренд» будут включены (и вместе с ним впоследствии исключены) ценные низко- и даже среднечастотные составляющие.
Tereshkov
22.04.2019 04:29Странный текст. Так и остаётся непонятным, в чём заслуга автора. Либо я всё неверно понял, либо этот метод обсуждается в стандартных учебных курсах.
- Возможности представления тренда базисными функциями соответствуют обычному МНК. В МНК вовсе не требуется выбирать полиномы 1, 2, 3 степени; функции могут быть любыми. У Лапласа, который изобрёл МНК, это был, например, квадрат синуса. Желательно лишь, чтобы коэффициенты b входили в x(t) линейно. Здесь это требование не поколеблено. Если степень полинома и ограничивают, то только из-за очень высокой чувствительности более высоких степеней к ошибкам и плохой предсказательной способности. Это ограничение здесь тоже в силе.
- Автор желает избавить нас от необходимости «умножать процесс на определенные последовательности». Однако именно это умножение он и делает неявно в уравнении (4). Смысл в самой неявности? Но никто и не требует делать это явно (свидетельствует ссылка выше).
crowncork Автор
22.04.2019 09:59Почему «это умножение он делает неявно»? Явно. Явно находите UTx. Коэффициенты UTU, которые далее понадобятся, легко и очевидно (о чем и речь) находятся средствами матричной алгебры. А не так, как, например, в указанном очень авторитетном источнике (и не только) — приравниванием нулю частных производных. Явным приравниванием.
Tereshkov
22.04.2019 12:25+1Моё замечание означало, что вначале вы будто бы желаете исключить «умножение процесса на определённые последовательности». А затем сами делаете то же самое умножение, только не говорите об этом. Оно у вас скрыто в уравнении (4).
Однако всё это второстепенно. Главное — хочется понять, чем же ваш метод отличается от приведённого мною по ссылке, найденной за пять минут в Гугле. Неупоминание метода в отдельно взятой книге — ей-богу, не аргумент. Любая книга ограничена в объёме.crowncork Автор
22.04.2019 17:23Он не «отличается», он «применен к...» :))), чего не наблюдалось не только в «отдельно взятой книге», но и среди «некоторых» практикующих исследователей — им это могло бы быть интересно. А вот тех, кто его применял на практике (а наверняка есть такие), интересно было бы услышать — а их вот чего-то и нет пока что. А ведь «подводные камни» могут быть и кроме упомянутого — опыт наработан с таким методом очень небольшой — поэтому и интересно услышать. А пока вот только теоретики.
Tereshkov
22.04.2019 18:21+1Странно: сначала вы анонсируете «новый» метод, а затем признаёте, что он ничем не отличается от старого и лишь «применён к...». Кстати, к чему применён? О применении у вас практически ничего нет.

Refridgerator
22.04.2019 19:56Ну, если вам интересно, то я этим тоже занимался. На реальных, а не синтезированных данных — в частности, аппроксимацией импульсной характеристики. И кстати, удаление тренда при спектральном анализе не помогает, а скорее наоборот. И даже самостоятельно выводил формулы для аппроксимации синусом и косинусом, чтобы спектральную интерполяцию можно было делать, типа такого:

Здесь гарантированно нет частот выше заданной.

Livid
22.04.2019 10:55Я тоже что-то не вкуриваю в чём заслуга автора. Регрессионный анализ методом наименьших квадратов — штука хорошо и давно известная, и базисные функции допускает любые достаточно гладкие. И даже совсем несложная, первокурсники успешно справляются.

IgorPie
22.04.2019 15:12Хм, слишком сложно. Не всякий МК с таким справится, а если справится, то все ресурсы изведет.
На мой взгляд, лучше обычный HPF, подобные тем, что стоят в звуковых картах и отсекают дрейф входного смещения и частот 5Гц и ниже (экспоненциальное скользящее средее, по сути, имитация RC цепочки).Refridgerator
22.04.2019 15:22Вы говорите о фильтре с бесконечной импульсной характеристикой. Здесь он не подойдёт, потому что приведёт к фазовому сдвигу и как следствие — изменению формы экспериментальных данных. Есть принципиальная разница между трендом и низкочастотной составляющей. Если и применять низкочастотную фильтрацию, то только фазолинейным КИХ-фильтром.
IgorPie
22.04.2019 17:29-1Это в универсальном случае, а в частном (термометры), вполне себе вариант. С практически нулевой ресурсоемкостью.
Daddy_Cool
Важная тема для экспериментаторов. Кое что непонятною
Так вот в чем здесь суть/особенность аппроксимации-то?
Я так понимаю, что нужно задаться некоторой функцией, скажем полиномом, из МНК получить коэффициенты, дальше вычесть из исходных данных наш полином — и готово,
или задать несколько аппроксимирующих полиномов на разных участках — причем желательно позаботиться о гладкости на границах.
Это всё очевидно и на поверхности, у вас видимо есть какой-то изюм, но я его не могу навскидку уловить, а очень хочется.
Refridgerator
Насколько я понял, идея автора в том, что он не рассматривает высокочастотные составляющие как шум — а значит, что и при нахождении тренда условие минимизации среднеквадратичного отклонения вовсе необязательно. В матричной форме полиномиальной регрессии он просто обнулил вектор ошибок.
mayorovp
Как же оно необязательно, когда он на шаге (4) применяет МНК?
Refridgerator
Метод наименьших квадратов — не единственный способ решения переопределённой системы уравнений, и из формулы (4) оно вовсе не следует — можно минимизировать и сумму высших (чётных) степеней — 4, 6 и т.д. Как я понял, у автора решение находится за счёт просто обнуления суммы отклонений от тренда. Но я не математик, могу ошибаться.
mayorovp
Переход от формулы (3) к формуле (4) — это вполне конкретный переход, и он соответствует тому что предлагает МНК.
Refridgerator
Ну в таком случае тем более непонятно, чем же метод автора «новый».