
Привет, Хабр! Представляю вашему вниманию перевод статьи «Envoy threading model» автора Matt Klein.
Данная статься показалась мне достаточно интересной, а так как Envoy чаще всего используется как часть «istio» или просто как «ingress controller» kubernetes, следовательно большинство людей не имеют с ним такого же прямого взаимодействия как например с типовыми установками Nginx или Haproxy. Однако если что-то ломается, было бы хорошо понимать как оно устроенно изнутри. Я постарался перевести как можно больше текста на русский в том числе и специальные слова, для тех кому больно на такое смотреть я оставил оригиналы в скобках. Добро пожаловать под кат.
Техническая документация низкого уровня по кодовой базе Envoy в настоящее время довольно скудная. Чтобы исправить это, я планирую сделать серию статей в блоге о различных подсистемах Envoy. Так как это первая статья, пожалуйста, дайте мне знать, что вы думаете и что вам могло быть интересно в следующих статьях.
Один из наиболее распространенных технических вопросов, которые я получаю о Envoy, это запрос на низкоуровневое описание используемой модели потоков (threading model). В этом посте я опишу как Envoy сопоставляет соединения с потоками, а также описание системы локального хранилища потоков (Thread Local Storage), которая используется внутри, чтобы сделать код более параллельным и высокопроизводительным.
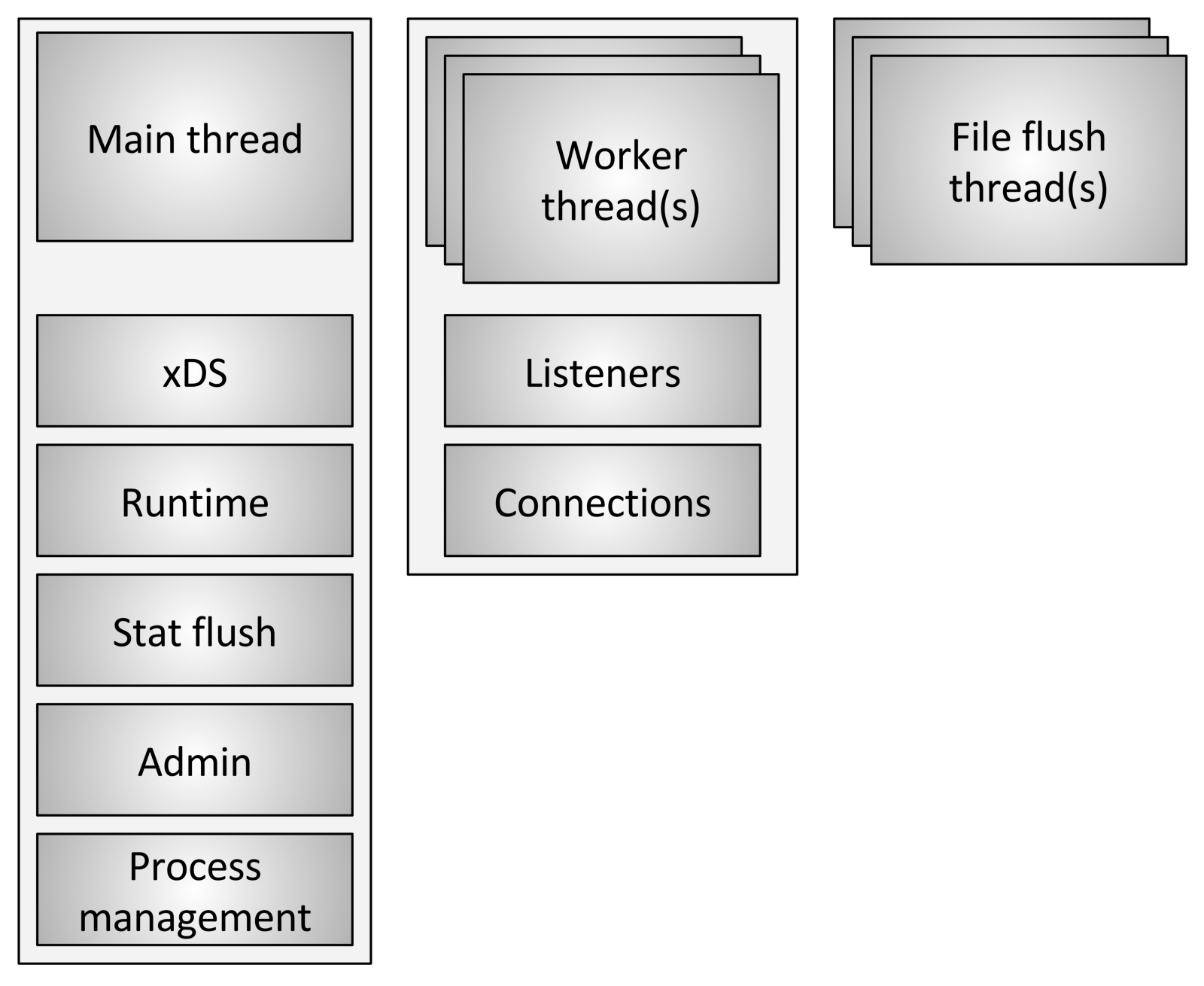
Envoy использует три различных типа потоков:
Как обсуждалось вкратце выше, все рабочие потоки прослушивают всех слушателей (listeners) без какого-либо сегментирования. Таким образом, ядро используется для грамотной отправки принятых сокетов в рабочие потоки. Современные ядра в целом очень хороши в этом, они используют такие функции, как повышение приоритета ввода-вывода (IO), чтобы попытаться заполнить поток работой, прежде чем начать использовать другие потоки, которые также прослушивают тот же сокет, а также не использовать циклическую блокировку (Spinlock) для обработки каждого запроса.
Как только соединение принято на рабочем потоке (worker thread), оно никогда не покидает этот поток (thread). Вся дальнейшая обработка соединения полностью обрабатывается в рабочем потоке (worker thread), включая любое поведение пересылки (forwarding behavior).
Это имеет несколько важных последствий:
Термин «неблокирующий» до сих пор использовался несколько раз при обсуждении того, как работают основной и рабочий потоки. Весь код написан при условии, что ничто никогда не блокируется. Однако, это не совсем верно (что не совсем верно?).
Envoy использует несколько длительных блокировок процесса:
Из-за способа, которым Envoy отделяет обязанности основного потока от обязанностей рабочего потока, существует требование, что сложная обработка может быть выполнена в главном потоке, а затем предоставлена каждому рабочему потоку с высокой степенью параллелизма. В этом разделе описана система Envoy Thread Local Storage (TLS) на высоком уровне. В следующем разделе я опишу, как он используется для управления кластером.

Как уже было описано, основной поток обрабатывает практически все функции управления (management) и функциональность плоскости управления (control plane) в процессе Envoy. Плоскость управления здесь немного перегружена, но если рассматривать ее в рамках самого процесса Envoy и сравнивать с пересылкой, которую выполняют рабочие потоки, это представляется целесообразным. По общему правилу процесс основного потока выполняет некоторую работу, а затем ему необходимо обновлять каждый рабочий поток в соответствии с результатом этой работы, при этом рабочему потоку не нужно устанавливать блокировку при каждом доступе.
Система TLS (Thread local storage) Envoy работает следующим образом:
Хотя это очень простая и невероятно мощная парадигма, которая очень похожа на концепцию блокировки RCU(Read-Copy-Update). По сути, рабочие потоки никогда не видят каких-либо изменений данных в слотах TLS во время выполнения работы. Изменение происходит только в период покоя между рабочими событиями.
Envoy использует это двумя разными способами:
В этом разделе я опишу, как TLS (Thread local storage) используется для управления кластером. Управление кластером включает обработку API xDS и / или DNS, а также проверку работоспособности (health checking).
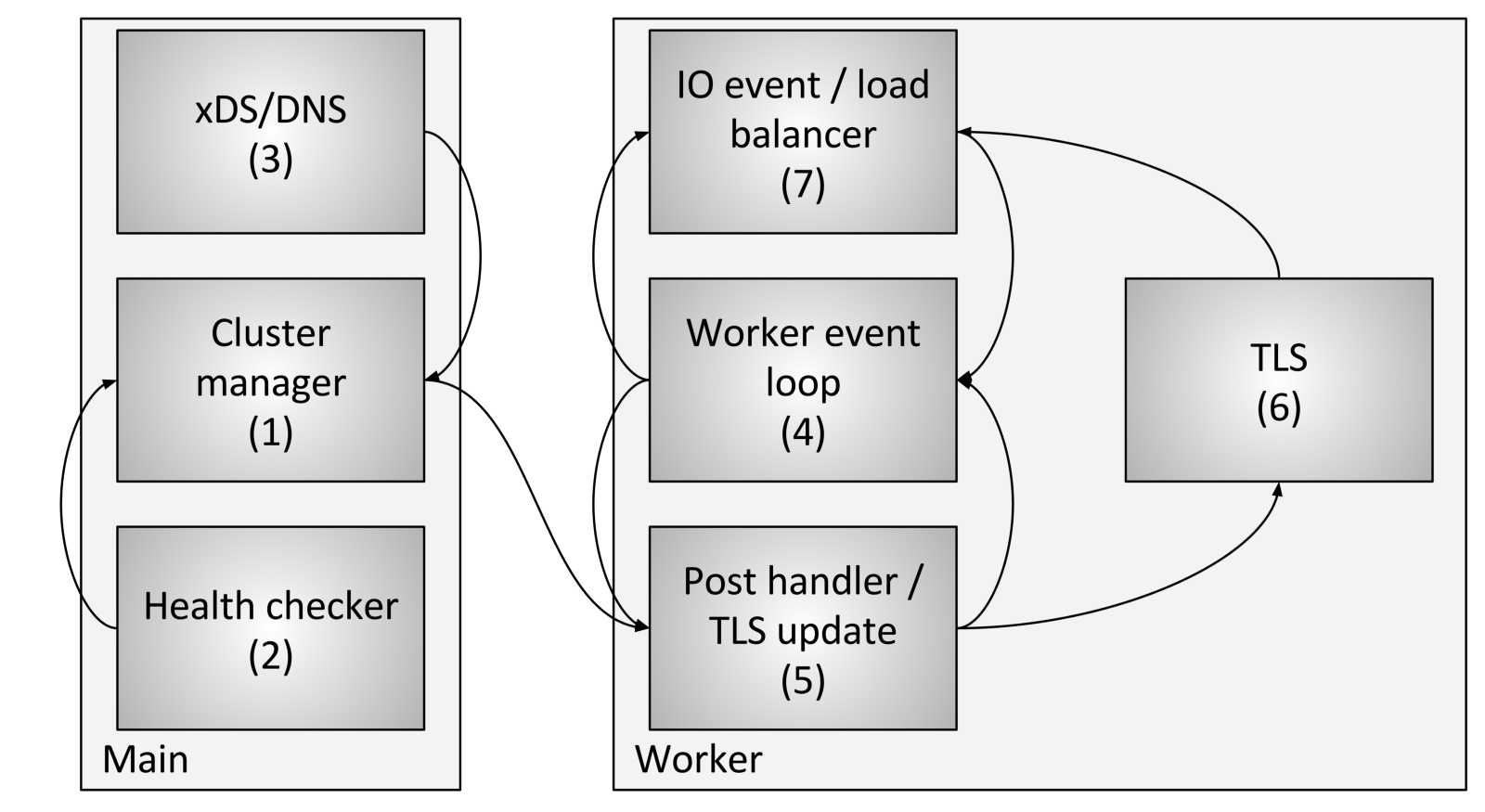
Управление потоками кластера включает в себя следующие компоненты и этапы:
Используя вышеописанную процедуру, Envoy может обрабатывать каждый запрос без каких-либо блокировок (кроме описанных ранее). Помимо сложности самого кода TLS, большей части кода не нужно понимать, как работает многопоточность, и он может быть написан в однопоточном режиме. Это облегчает написание большей части кода в дополнение к превосходной производительности.
TLS (Thread local storage) и RCU (Read Copy Update) широко используются в Envoy.
Примеры использования:
Есть и другие случаи, но предыдущие примеры должны обеспечить хорошее понимание того, для чего используется TLS.
Хотя в целом Envoy работает достаточно хорошо, есть несколько известных областей, которые требуют внимания, когда он используется с очень высоким параллелизмом и пропускной способностью:
Модель потоков Envoy разработана для обеспечения простоты программирования и массового параллелизма за счет потенциально расточительного использования памяти и соединений, если они не настроены правильно. Эта модель позволяет ему очень хорошо работать при очень высоком количестве потоков и пропускной способности.
Как я кратко упомянул в Твиттере, дизайн также может работать поверх полнофункционального сетевого стека в режиме пользователя, такого как DPDK (Data Plane Development Kit), что может привести к тому, что обычные серверы будут обрабатывать миллионы запросов в секунду при полной обработке L7. Будет очень интересно посмотреть, что будет построено в ближайшие несколько лет.
Один последний быстрый комментарий: меня много раз спрашивали, почему мы выбрали C ++ для Envoy. Причина по-прежнему заключается в том, что это все еще единственный широко распространенный язык промышленного уровня, на котором можно построить архитектуру, описанную в этом посте. C ++ определенно не подходит для всех или даже для многих проектов, но для определенных случаев использования это все еще единственный инструмент для выполнения работы (to get the job done).
Ссылки на файлы с интерфейсами и реализацией заголовков, обсуждаемые в этом посте:
Данная статься показалась мне достаточно интересной, а так как Envoy чаще всего используется как часть «istio» или просто как «ingress controller» kubernetes, следовательно большинство людей не имеют с ним такого же прямого взаимодействия как например с типовыми установками Nginx или Haproxy. Однако если что-то ломается, было бы хорошо понимать как оно устроенно изнутри. Я постарался перевести как можно больше текста на русский в том числе и специальные слова, для тех кому больно на такое смотреть я оставил оригиналы в скобках. Добро пожаловать под кат.
Техническая документация низкого уровня по кодовой базе Envoy в настоящее время довольно скудная. Чтобы исправить это, я планирую сделать серию статей в блоге о различных подсистемах Envoy. Так как это первая статья, пожалуйста, дайте мне знать, что вы думаете и что вам могло быть интересно в следующих статьях.
Один из наиболее распространенных технических вопросов, которые я получаю о Envoy, это запрос на низкоуровневое описание используемой модели потоков (threading model). В этом посте я опишу как Envoy сопоставляет соединения с потоками, а также описание системы локального хранилища потоков (Thread Local Storage), которая используется внутри, чтобы сделать код более параллельным и высокопроизводительным.
Описание потоков (Threading overview)
Envoy использует три различных типа потоков:
- Основной (Main): Этот поток управляет запуском и завершением процесса, всей обработкой XDS (xDiscovery Service) API, включая DNS, проверку работоспособности (health checking), общее управление кластером и процессом работы сервиса (runtime), сбросом статистики, администрирование и общее управление процессами — Linux сигналы, горячий перезапуск (hot restart) и т. д. Все, что происходит в этом потоке, является асинхронным и «неблокирующим». В целом основной поток координирует все критические процессы функциональности, для выполнения которых не требуется большого количества ЦПУ. Это позволяет большую часть кода управления писать так, как если бы он был однопоточным.
- Рабочий (Worker): По умолчанию Envoy создает рабочий поток(worker thread) для каждого аппаратного потока в системе, это можно контролировать с помощью опции
--concurrency. Каждый рабочий поток запускает «неблокирующий» цикл событий (event loop), который отвечает за прослушивание (listening) каждого прослушивателя (listener), на момент написания статьи (29 июля 2017 г.) нет сегментирования (sharding) прослушивателя (listener), прием новых соединений, создание экземпляра стека фильтров для подключения и обработку всех операций ввода-вывода (IO) за время существования соединения. Опять же, это позволяет большую часть кода обработки соединений писать так, как если бы он был однопоточным. - Файловый (File flusher): Каждый файл, который пишет Envoy, в основном журналы доступа (access logs), в настоящее время имеет независимый блокирующий поток. Это связано с тем, что запись в файлы кэшированные файловой системой даже при использовании
O_NONBLOCKиногда может блокироваться (вздох). Когда рабочим потокам необходимо записать в файл, данные фактически перемещаются в буфер в памяти, где они в конечном итоге сбрасываются через поток file flush. Это одна из областей кода, в которой технически все рабочие потоки (worker threads) могут блокировать (block) одну и ту же блокировку (lock), пытаясь заполнить буфер памяти.
Обработка соединений (Connection handling)
Как обсуждалось вкратце выше, все рабочие потоки прослушивают всех слушателей (listeners) без какого-либо сегментирования. Таким образом, ядро используется для грамотной отправки принятых сокетов в рабочие потоки. Современные ядра в целом очень хороши в этом, они используют такие функции, как повышение приоритета ввода-вывода (IO), чтобы попытаться заполнить поток работой, прежде чем начать использовать другие потоки, которые также прослушивают тот же сокет, а также не использовать циклическую блокировку (Spinlock) для обработки каждого запроса.
Как только соединение принято на рабочем потоке (worker thread), оно никогда не покидает этот поток (thread). Вся дальнейшая обработка соединения полностью обрабатывается в рабочем потоке (worker thread), включая любое поведение пересылки (forwarding behavior).
Это имеет несколько важных последствий:
- Все пулы соединений в Envoy относятся к рабочему потоку. Таким образом, хотя пулы соединений HTTP/2 делают только одно соединение с каждым вышестоящим хостом за раз, если есть четыре рабочих потока, будет четыре соединения HTTP/2 на вышестоящий хост в устойчивом состоянии.
- Причина, по которой Envoy работает таким образом, заключается в том, что, сохраняя все в одном рабочем потоке, почти весь код может быть написан без блокировок и как будто он однопоточный. Этот дизайн упрощает написание большого количества кода и невероятно хорошо масштабируется для почти неограниченного числа рабочих потоков.
- Однако, одним из основных выводов является то, что с точки зрения эффективности пула памяти и соединений на самом деле очень важно настроить параметр
--concurrency. Наличие большего количества рабочих потоков, чем необходимо, приведет к потере памяти, созданию большего количества бездействующих соединений и снижению скорости попадания в пул соединений. В Lyft наши envoy sidecar контейнеры работают с очень низким параллелизмом, так что производительность примерно соответствует службам, рядом с которыми они сидят. Мы запускаем Envoy в качестве пограничного прокси-сервера (edge) только при максимальном параллелизме (concurrency).
Что означает не блокирующий режим (What non-blocking means)
Термин «неблокирующий» до сих пор использовался несколько раз при обсуждении того, как работают основной и рабочий потоки. Весь код написан при условии, что ничто никогда не блокируется. Однако, это не совсем верно (что не совсем верно?).
Envoy использует несколько длительных блокировок процесса:
- Как уже говорилось, при записи журналов доступа все рабочие потоки получают одинаковую блокировку перед заполнением буфера журнала в памяти. Время удержания блокировки должно быть очень низким, но возможно, что эта блокировка будет оспариваться при высоком параллелизме и высокой пропускной способности.
- Envoy использует очень сложную систему для обработки статистики, которая является локальной для потока. Это будет тема отдельного поста. Тем не менее, я кратко упомяну, что как часть локальной обработки статистики потока иногда требуется получить блокировку для центрального «хранилища статистики». Эта блокировка не должна когда-либо требоваться.
- Основной поток периодически нуждается в координации со всеми рабочими потоками. Это делается путем «публикации» из основного потока в рабочие потоки, а иногда и из рабочих потоков обратно в основной поток. Для отправки требуется блокировка, чтобы опубликованное сообщение можно было поместить в очередь для последующей доставки. Эти блокировки никогда не должны подвергаться серьезному соперничеству, но они все равно могут технически блокироваться.
- Когда Envoy пишет журнал в системный поток ошибок (standard error), он получает блокировку всего процесса. В целом, локальное ведение журнала Envoy считается ужасным с точки зрения производительности, поэтому его улучшению не уделяется много внимания.
- Есть несколько других случайных блокировок, но ни одна из них не является критической для производительности и никогда не должна оспариваться.
Локальное хранилище потока (Thread local storage)
Из-за способа, которым Envoy отделяет обязанности основного потока от обязанностей рабочего потока, существует требование, что сложная обработка может быть выполнена в главном потоке, а затем предоставлена каждому рабочему потоку с высокой степенью параллелизма. В этом разделе описана система Envoy Thread Local Storage (TLS) на высоком уровне. В следующем разделе я опишу, как он используется для управления кластером.
Как уже было описано, основной поток обрабатывает практически все функции управления (management) и функциональность плоскости управления (control plane) в процессе Envoy. Плоскость управления здесь немного перегружена, но если рассматривать ее в рамках самого процесса Envoy и сравнивать с пересылкой, которую выполняют рабочие потоки, это представляется целесообразным. По общему правилу процесс основного потока выполняет некоторую работу, а затем ему необходимо обновлять каждый рабочий поток в соответствии с результатом этой работы, при этом рабочему потоку не нужно устанавливать блокировку при каждом доступе.
Система TLS (Thread local storage) Envoy работает следующим образом:
- Код, выполняющийся в основном потоке, может выделить слот TLS для всего процесса. Хотя это абстрагировано, на практике это индекс в векторе, обеспечивающий доступ O(1).
- Основной поток может устанавливать произвольные данные в свой слот. Когда это сделано, данные публикуются в каждом рабочем потоке как обычное событие цикла событий.
- Рабочие потоки могут читать из своего слота TLS и извлекать любые локальные данные потоков, доступные там.
Хотя это очень простая и невероятно мощная парадигма, которая очень похожа на концепцию блокировки RCU(Read-Copy-Update). По сути, рабочие потоки никогда не видят каких-либо изменений данных в слотах TLS во время выполнения работы. Изменение происходит только в период покоя между рабочими событиями.
Envoy использует это двумя разными способами:
- Сохраняя различные данные на каждом рабочем потоке, доступ к этим данным осуществляется без какой-либо блокировки.
- Сохраняя общий указатель на глобальные данные в режиме «только для чтения» на каждом рабочем потоке. Таким образом, каждый рабочий поток имеет счетчик ссылок на данные, который не может быть уменьшен во время выполнения работы. Только когда все работники успокоятся и загрузят новые общие данные, старые данные будут уничтожены. Это идентично RCU.
Поток обновления кластера (Cluster update threading)
В этом разделе я опишу, как TLS (Thread local storage) используется для управления кластером. Управление кластером включает обработку API xDS и / или DNS, а также проверку работоспособности (health checking).
Управление потоками кластера включает в себя следующие компоненты и этапы:
- Менеджер кластера — это компонент внутри Envoy, который управляет всеми известными апстримами (upstream) кластера, API-интерфейсом CDS (Cluster Discovery Service), API-интерфейсами SDS (Secret Discovery Service) и EDS (Endpoint Discovery Service), DNS и активными внешними проверками работоспособности (health checking). Он отвечает за создание в «конечном итоге согласованного» (eventually consistent) представления каждого апстрима (upstream) кластера, который включает обнаруженные хосты, а также состояние работоспособности (health status).
- Средство проверки работоспособности (health checker) выполняет активную проверку работоспособности и сообщает об изменениях состояния работоспособности диспетчеру кластера.
- CDS (Cluster Discovery Service) / SDS (Secret Discovery Service) / EDS (Endpoint Discovery Service) / DNS выполняются для определения принадлежности к кластеру. Изменение состояния возвращается менеджеру кластера.
- Каждый рабочий поток постоянно выполняет цикл обработки событий.
- Когда менеджер кластера определяет, что состояние для кластера изменилось, он создает новый снимок состояния кластера, доступный только для чтения, и отправляет его в каждый рабочий поток.
- В течение следующего периода покоя рабочий поток обновит снимок в выделенном слоте TLS.
- Во время события ввода-вывода, которое должно определить хост для балансировки нагрузки, балансировщик нагрузки будет запрашивать слот TLS (Thread local storage) для получения информации о хосте. Для этого не требуется блокировок. Обратите внимание также, что TLS может также инициировать события при обновлении, так что подсистемы балансировки нагрузки и другие компоненты могут пересчитывать кэши, структуры данных и т.д. Это выходит за рамки этого поста, но используется в различных местах кода.
Используя вышеописанную процедуру, Envoy может обрабатывать каждый запрос без каких-либо блокировок (кроме описанных ранее). Помимо сложности самого кода TLS, большей части кода не нужно понимать, как работает многопоточность, и он может быть написан в однопоточном режиме. Это облегчает написание большей части кода в дополнение к превосходной производительности.
Другие подсистемы, использующие TLS (Other subsystems that make use of TLS)
TLS (Thread local storage) и RCU (Read Copy Update) широко используются в Envoy.
Примеры использования:
- Механизм изменения функциональности в процессе выполнения: Текущий список включенного функционала вычисляется в основном потоке. Затем каждому рабочему потоку предоставляется снимок только для чтения с использованием семантики RCU.
- Замена таблиц маршрутов: для таблиц маршрутов, предоставляемых RDS (Route Discovery Service), таблицы маршрутов создаются в основном потоке. Снимок только для чтения в дальнейшем будет предоставлен каждому рабочему потоку с использованием семантики RCU (Read Copy Update). Это делает изменение таблиц маршрутов атомарно эффективным.
- Кэширование заголовков HTTP: Как выясняется, вычисление заголовка HTTP для каждого запроса (при выполнении ~25K+ RPS на ядро) довольно дорого. Envoy централизованно вычисляет заголовок примерно каждые полсекунды и предоставляет его каждому работнику через TLS и RCU.
Есть и другие случаи, но предыдущие примеры должны обеспечить хорошее понимание того, для чего используется TLS.
Известные подводные камни производительности (Known performance pitfalls)
Хотя в целом Envoy работает достаточно хорошо, есть несколько известных областей, которые требуют внимания, когда он используется с очень высоким параллелизмом и пропускной способностью:
- Как уже описано в этой статье, в настоящее время все рабочие потоки получают блокировку при записи в буфер памяти журнала доступа. При высоком параллелизме и высокой пропускной способности потребуется выполнить пакетирование журналов доступа для каждого рабочего потока за счет неупорядоченной доставки при записи в окончательный файл. Как альтернативу, можно создавать отдельный журнал доступа для каждого рабочего потока.
- Хотя статистика очень сильно оптимизирована, при очень высоком параллелизме и пропускной способности, вероятно, будет атомарная конкуренция на индивидуальной статистике. Решение этой проблемы — счетчики на один рабочий поток с периодическим сбросом центральных счетчиков. Это будет обсуждаться в последующем посте.
- Существующая архитектура не будет работать хорошо если Envoy развернут в сценарии, в котором очень мало соединений, требующих значительных ресурсов для обработки. Нет гарантии, что связи будут равномерно распределены между рабочими потоками. Это может быть решено путем реализации балансировки рабочих соединений, при которой будет реализована возможность обмена соединениями между рабочими потоками.
Заключение (Conclusion)
Модель потоков Envoy разработана для обеспечения простоты программирования и массового параллелизма за счет потенциально расточительного использования памяти и соединений, если они не настроены правильно. Эта модель позволяет ему очень хорошо работать при очень высоком количестве потоков и пропускной способности.
Как я кратко упомянул в Твиттере, дизайн также может работать поверх полнофункционального сетевого стека в режиме пользователя, такого как DPDK (Data Plane Development Kit), что может привести к тому, что обычные серверы будут обрабатывать миллионы запросов в секунду при полной обработке L7. Будет очень интересно посмотреть, что будет построено в ближайшие несколько лет.
Один последний быстрый комментарий: меня много раз спрашивали, почему мы выбрали C ++ для Envoy. Причина по-прежнему заключается в том, что это все еще единственный широко распространенный язык промышленного уровня, на котором можно построить архитектуру, описанную в этом посте. C ++ определенно не подходит для всех или даже для многих проектов, но для определенных случаев использования это все еще единственный инструмент для выполнения работы (to get the job done).
Ссылки на код (Links to code)
Ссылки на файлы с интерфейсами и реализацией заголовков, обсуждаемые в этом посте:
- github.com/lyft/envoy/blob/master/include/envoy/thread_local/thread_local.h
- github.com/lyft/envoy/blob/master/source/common/thread_local/thread_local_impl.h
- github.com/lyft/envoy/blob/master/include/envoy/upstream/cluster_manager.h
- github.com/lyft/envoy/blob/master/source/common/upstream/cluster_manager_impl.h
KIVagant
> В целом, локальное ведение журнала Envoy считается ужасным с точки зрения производительности, поэтому его улучшению не уделяется много внимания.
Имелось ввиду «уделяется»?
therb1 Автор
Нет, не имелось. Автор оригинальной статьи придерживается идеи что писать в stderr значительно лучше чем в локальный файл и он пока не видит путей к улучшению данного процесса. Эта проблема есть также и у nginx, так как если почитать рекомендации по настройке nginx как сервера раздающего статичные файлы в больших объемах то первое что вы увидите это "направьте логи в /dev/null". На данный момент времени эта задача не имеет рационального решения, поэтому автор статьи не уделяет ей много внимания.
KIVagant
Понятно, спасибо. Поддерживаю автора статьи про направление логов в стандартные потоки вывода.