
Мы продолжаем цикл статей про Cisco Hyperflex. В этот раз мы познакомим вас с работой Cisco Hyperflex в условиях высоконагруженных СУБД Oracle и Microsoft SQL, а также сравним полученные показатели с конкурентными решениями.
Кроме того, мы продолжаем показывать возможности Hyperflex в регионах нашей страны и с радостью приглашаем вас посетить очередные демонстрации решения, которые на этот раз пройдут в городах Москва и Краснодар.
Москва – 28 мая. Запись по ссылке.
Краснодар – 5 июня. Запись по ссылке.
Гиперконвергентные решения до недавнего времени являлись не очень подходящим решением для СУБД, тем более с высокой нагрузкой. Однако, благодаря использованию в качестве аппаратной платформы для Cisco Hyperflex фабрики UCS, за 10 лет доказавшей свою надежность и производительность, уже сегодня эта ситуация изменилась.
Хотите узнать больше? Тогда добро пожаловать под кат.
На текущий момент есть два подхода к организации гиперконвергентных решений. Первый подход основан на Software-defined решениях, которые поставляются как программное обеспечение, а оборудование заказчики подбирают самостоятельно. Второй подход основан на решениях «под ключ», то есть содержащих и ПО, и оборудование, и техническую поддержку. Мы в компании Cisco придерживаемся второго подхода и поставляем уже готовые решения нашим заказчикам, поскольку только таким образом можно гарантировать стабильное поведение системы, качественную техническую поддержку от одного производителя и высокую производительность.
Именно высокая производительность системы является одним ключевых факторов при принятии решения об использовании того или иного продукта в mission-critical задачах.
Сегодня организации, как правило, размещают критически важные задачи на классических решениях трехуровневой архитектуры (СХД > сеть хранения > серверы). При этом большинство организаций стремиться упростить и удешевить ИТ-инфраструктуру, не снизив при этом её стабильность и производительность. По этой причине, все чаще и чаще заказчики обращают внимание на гиперконвергентные решения.
В рамках этой статьи мы расскажем о последних тестах (февраль 2019 года), которые выполняла независимая лаборатория ESG (Enterprise Strategy Group). При тестировании эмулировалась работа высоконагруженных СУБД Oracle и MS SQL (OLTP тесты), что является одним из самых критичных компонентов ИТ-инфраструктуры в реальном продуктивном окружении.
Данная нагрузка выполнялась на трёх решениях: Cisco Hyperflex, а также двух software-defined решениях, которые устанавливались на те же серверы, что используются в Hyperflex, то есть на серверы Cisco UCS.

В системе вендора А не используется кэш, поскольку конфигурация с кэшем не поддерживается разработчиком решения. По этой причине были использованы диски для хранения большего объема.
OLTP тесты выполнялись с четырьмя виртуальными машинами и рабочим набором данных в 3,2 ТБ. Перед выполнением каждого теста каждая ВМ заполнялась записанными данными с помощью инструмента тестирования. Это гарантирует, что тест считывает «реальные» данные и записывает их в существующие блоки, а не просто возвращает нулевые блоки или нулевые значения непосредственно из памяти. Это происходит, когда данные не заполнены, поэтому было важно убедиться, что тест точно отражает, как данные считываются и записываются в среде приложения. Заполнение этого большого рабочего комплекта заняло продолжительное время, но на наш взгляд — это продуктивное вложение времени, поскольку позволяет получить более точные данные о производительности.
Тестирование проводилось с использованием инструмента HCI Bench (на основе Oracle Vdbench) и профилей ввода-вывода, предназначенных для эмуляции сложных критически важных рабочих нагрузок OLTP с использованием бэкэндов Oracle и SQL Server. Размеры блоков были назначены в соответствии с эмулируемыми приложениями со 100% случайным доступом к данным (full random).
Первым был выполнен OLTP тест, разработанный для эмуляции среды Oracle. Vdbench использовался для создания рабочей нагрузки с различными соотношениями чтения и записи. Тест проводился на четырех виртуальных машинах. В течение четырехчасового теста HyperFlex удалось показать более 420 000 IOPS с задержкой всего 4.4 милисекунды. Программные решения A и B смогли показать только 238 000 и 251 000 IOPS соответственно.

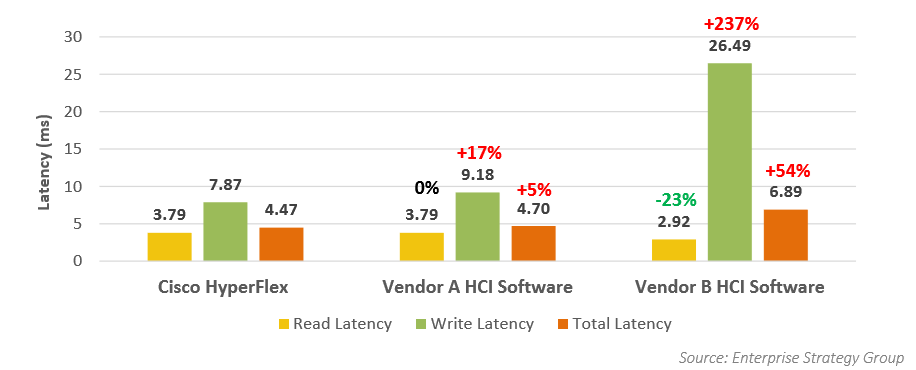
Уровень задержек в разных системах был примерно одинаков, за исключением задержки записи для вендора B, которое в среднем составляло 26,49 мс, при очень хороших показателях задержек на чтение в 2,9 мс. Сжатие и дедупликация были активны во всех системах.
Затем была рассмотрена рабочая нагрузка OLTP, предназначенная для эмуляции СУБД Microsoft SQL Server.

В результате данного теста кластер Cisco HyperFlex примерно в два раза превзошёл обоих конкурентов А и B. 490 000 IOPS у Cisco против 200 000 и 260 000 у производителей A и B.

Результат по задержкам в Cisco HyperFlex не сильно отличался от теста Oracle, то есть он был на хорошем уровне 4,4 мс. При этом производители A и B показали результаты значительно хуже, чем в тесте для Oracle. Единственный положительный момент для конкурентного решения B – это стабильно низкий уровень задержек при чтении на уровне 2,9 мс, по всем остальным показателям Hyperflex опередил конкурентные решения в два раза и более.
Тестирование, проведенное независимой лабораторией ESG не только в очередной раз подтвердило достойный уровень производительности решения Cisco Hyperflex, но и доказало, что гиперконвергентные системы уже готовы для повсеместного использования в задачах уровня mission-critical.
Гиперконвергентные системы долгое время считались более подходящими для некритичных нагрузок. В 2016 году ESG провело опрос среди крупных компаний. Их спросили, почему они предпочли традиционную инфраструктуру, а не гиперконвергентную. 54% опрошенных ответили, что причина в производительности.
Перенесемся в 2018 год. Картина изменилась: повторный опрос ESG выявил уже только 24% опрошенных, которые до сих пор считают, что традиционные подходы все ещё лучше с точки зрения производительности.
Когда эволюция технологий меняет критерии выборы решения в отрасли, часто возникает несоответствие между тем, что хотят заказчики, и тем, что они могут получить. Производители, которые могут увидеть, чего не хватает и заполнить эту пустоту – получают преимущество. Cisco предлагает гиперконвергентное решение, которое обеспечивает простоту и экономичность, а также стабильно высокую производительность, которой не хватает и которая необходима заказчикам для критически важных рабочих нагрузок.
Компания Cisco поступательно двигается вперед в области гиперконвергентных систем, что подтверждается не только отличными характеристиками решения Cisco Hyperflex, но и присутствием на рынке. Поэтому осенью 2018 года компания Cisco заслуженно вошла в группу лидеров рынка HCI по версии Gartner.

Уже сейчас вы можете убедиться в том, что Hyperflex является превосходным решением для самых сложных и требовательных задач бизнеса, посетив наши демонстрации, которые пройдут в городах Москва и Краснодар.
Москва – 28 мая. Запись по ссылке.
Краснодар – 5 июня. Запись по ссылке.
Кроме того, мы продолжаем показывать возможности Hyperflex в регионах нашей страны и с радостью приглашаем вас посетить очередные демонстрации решения, которые на этот раз пройдут в городах Москва и Краснодар.
Москва – 28 мая. Запись по ссылке.
Краснодар – 5 июня. Запись по ссылке.
Гиперконвергентные решения до недавнего времени являлись не очень подходящим решением для СУБД, тем более с высокой нагрузкой. Однако, благодаря использованию в качестве аппаратной платформы для Cisco Hyperflex фабрики UCS, за 10 лет доказавшей свою надежность и производительность, уже сегодня эта ситуация изменилась.
Хотите узнать больше? Тогда добро пожаловать под кат.
Введение
На текущий момент есть два подхода к организации гиперконвергентных решений. Первый подход основан на Software-defined решениях, которые поставляются как программное обеспечение, а оборудование заказчики подбирают самостоятельно. Второй подход основан на решениях «под ключ», то есть содержащих и ПО, и оборудование, и техническую поддержку. Мы в компании Cisco придерживаемся второго подхода и поставляем уже готовые решения нашим заказчикам, поскольку только таким образом можно гарантировать стабильное поведение системы, качественную техническую поддержку от одного производителя и высокую производительность.
Именно высокая производительность системы является одним ключевых факторов при принятии решения об использовании того или иного продукта в mission-critical задачах.
Сегодня организации, как правило, размещают критически важные задачи на классических решениях трехуровневой архитектуры (СХД > сеть хранения > серверы). При этом большинство организаций стремиться упростить и удешевить ИТ-инфраструктуру, не снизив при этом её стабильность и производительность. По этой причине, все чаще и чаще заказчики обращают внимание на гиперконвергентные решения.
В рамках этой статьи мы расскажем о последних тестах (февраль 2019 года), которые выполняла независимая лаборатория ESG (Enterprise Strategy Group). При тестировании эмулировалась работа высоконагруженных СУБД Oracle и MS SQL (OLTP тесты), что является одним из самых критичных компонентов ИТ-инфраструктуры в реальном продуктивном окружении.
Данная нагрузка выполнялась на трёх решениях: Cisco Hyperflex, а также двух software-defined решениях, которые устанавливались на те же серверы, что используются в Hyperflex, то есть на серверы Cisco UCS.
Тестовые конфигурации
В системе вендора А не используется кэш, поскольку конфигурация с кэшем не поддерживается разработчиком решения. По этой причине были использованы диски для хранения большего объема.
Методология тестирования
OLTP тесты выполнялись с четырьмя виртуальными машинами и рабочим набором данных в 3,2 ТБ. Перед выполнением каждого теста каждая ВМ заполнялась записанными данными с помощью инструмента тестирования. Это гарантирует, что тест считывает «реальные» данные и записывает их в существующие блоки, а не просто возвращает нулевые блоки или нулевые значения непосредственно из памяти. Это происходит, когда данные не заполнены, поэтому было важно убедиться, что тест точно отражает, как данные считываются и записываются в среде приложения. Заполнение этого большого рабочего комплекта заняло продолжительное время, но на наш взгляд — это продуктивное вложение времени, поскольку позволяет получить более точные данные о производительности.
Тестирование проводилось с использованием инструмента HCI Bench (на основе Oracle Vdbench) и профилей ввода-вывода, предназначенных для эмуляции сложных критически важных рабочих нагрузок OLTP с использованием бэкэндов Oracle и SQL Server. Размеры блоков были назначены в соответствии с эмулируемыми приложениями со 100% случайным доступом к данным (full random).
Рабочая нагрузка Oracle Database
Первым был выполнен OLTP тест, разработанный для эмуляции среды Oracle. Vdbench использовался для создания рабочей нагрузки с различными соотношениями чтения и записи. Тест проводился на четырех виртуальных машинах. В течение четырехчасового теста HyperFlex удалось показать более 420 000 IOPS с задержкой всего 4.4 милисекунды. Программные решения A и B смогли показать только 238 000 и 251 000 IOPS соответственно.
Уровень задержек в разных системах был примерно одинаков, за исключением задержки записи для вендора B, которое в среднем составляло 26,49 мс, при очень хороших показателях задержек на чтение в 2,9 мс. Сжатие и дедупликация были активны во всех системах.
Рабочая нагрузка Microsoft SQL Server
Затем была рассмотрена рабочая нагрузка OLTP, предназначенная для эмуляции СУБД Microsoft SQL Server.
В результате данного теста кластер Cisco HyperFlex примерно в два раза превзошёл обоих конкурентов А и B. 490 000 IOPS у Cisco против 200 000 и 260 000 у производителей A и B.
Результат по задержкам в Cisco HyperFlex не сильно отличался от теста Oracle, то есть он был на хорошем уровне 4,4 мс. При этом производители A и B показали результаты значительно хуже, чем в тесте для Oracle. Единственный положительный момент для конкурентного решения B – это стабильно низкий уровень задержек при чтении на уровне 2,9 мс, по всем остальным показателям Hyperflex опередил конкурентные решения в два раза и более.
Выводы
Тестирование, проведенное независимой лабораторией ESG не только в очередной раз подтвердило достойный уровень производительности решения Cisco Hyperflex, но и доказало, что гиперконвергентные системы уже готовы для повсеместного использования в задачах уровня mission-critical.
Гиперконвергентные системы долгое время считались более подходящими для некритичных нагрузок. В 2016 году ESG провело опрос среди крупных компаний. Их спросили, почему они предпочли традиционную инфраструктуру, а не гиперконвергентную. 54% опрошенных ответили, что причина в производительности.
Перенесемся в 2018 год. Картина изменилась: повторный опрос ESG выявил уже только 24% опрошенных, которые до сих пор считают, что традиционные подходы все ещё лучше с точки зрения производительности.
Когда эволюция технологий меняет критерии выборы решения в отрасли, часто возникает несоответствие между тем, что хотят заказчики, и тем, что они могут получить. Производители, которые могут увидеть, чего не хватает и заполнить эту пустоту – получают преимущество. Cisco предлагает гиперконвергентное решение, которое обеспечивает простоту и экономичность, а также стабильно высокую производительность, которой не хватает и которая необходима заказчикам для критически важных рабочих нагрузок.
Компания Cisco поступательно двигается вперед в области гиперконвергентных систем, что подтверждается не только отличными характеристиками решения Cisco Hyperflex, но и присутствием на рынке. Поэтому осенью 2018 года компания Cisco заслуженно вошла в группу лидеров рынка HCI по версии Gartner.
Уже сейчас вы можете убедиться в том, что Hyperflex является превосходным решением для самых сложных и требовательных задач бизнеса, посетив наши демонстрации, которые пройдут в городах Москва и Краснодар.
Москва – 28 мая. Запись по ссылке.
Краснодар – 5 июня. Запись по ссылке.
shapa
И снова — на сцене цирка Cisco, под яркими лучами софитов :)
Коллеги, право — статьи писать на техническом ресурсе — все же IMHO не ваше.
«Гиперконвергентные решения до недавнего времени являлись не очень подходящим решением для СУБД, тем более с высокой нагрузкой.» — очень, очень смелое заявление.
Впрочем, учитывая любовь вендора к сравнению с какими-то мифическими «A» и «B» от (опять-же) любимой ESG Labs (Huawei и Pivot3?)…
Между тем как у реальных лидеров (их видно на приведенном вами-же MQ) — с поддержкой баз данных не просто все давно прекрасно, а стало обыденностью жизни.
Показывать на публику тесты на vdbench и делать столь громкие заявления о разрыве в «сотни процентов» — в целом расписаться в полном / вопиющем непрофессионализме.
Почему? Все просто — такие утилиты (iometer, vdbench, и тд) не рассчитаны на тестирование работы современных мультипоточных операционных систем. Они создавались для тестирования традиционных 3-tier архитектур / shared storage.
При тестировании HCI они покажут что угодно (вплоть до погоды на марсе), кроме реальной призводительности.
При реальных тестах баз данных (в том числе по отзывам клиентов) — производителеность SpringPath (компании приобретенной Cisco для «закрытия дыры» HCI) одна из худших на рынке.
Фактически, по результату чтения вашей «статьи», любой грамотный инженер должен вас не пустить ближе порога, ибо в русском языке это называется «голимый маркетинг».
Отсюда, видимо, и вытекает смешная доля Cisco на HCI рынке — около 2%.
Клиенты, к счастью, нынче пошли образованные и умные.
Чуть ликбеза:
«The reason we had to address this problem is because traditional workload generators like iometer, vdbench, and fio are brute force speed tests designed for traditional shared storage arrays. There's a lot of baggage that accompanies that:
They just read and write data.
They were created when the upper limits of storage performance really mattered.
They are leftovers of measuring spinning disks
Ultimately, they were built in a time when storage performance was the first order problem: the most likely limit to your application’s performance was its ability to access storage.
But that changed with SSDs.
Flash changed the storage performance conversation. Just a few SSDs can easily exceed application requirements. If you take advantage of SSDs the way hyperconverged infrastructures (HCI) do, you can move most application bottlenecks to waiting for CPU, not storage. This also changed the way systems scale.
HCI allows for incremental scale with workloads colacted on the same system as your storage. It removes the guesswork needed to evaluate the maximum a storage array can handle. Instead of buying one big instance of storage and adding workloads over time, you scale your storage as your needs increase. You should still understand the performance of a system but it changes to a broader sense, one that is more applicable to true datacenter operations rather than the unsophisticated drag race of the old workload generators.
Because most application requirements are easily met with flash, storage performance becomes a control variable in a more complete test of an entire system. X-ray will run a workload characterization and for most tests it will make the throughput requirement steady state. Instead of testing the limits of storage performance, we shift the focus to that of maintaining consistent and reliable performance in a number of scenarios that are encountered in data centers.
Some of these common scenario categories include:
Noisy Neighbors — Run a workload in one VM and add a new VM with new work. The application in the first VM should be unaffected.
Additional workload — Increase the rational workload of an application, there should be little effect on performance as work is added.
Rolling upgrades — There should be little effect seen at the application as hypervisor and virtual storage controllers are upgraded.
Node failures — Fail a node, there should be a slight pause (that’s probably not noticed by application or user) and then little effect to the application after the failure.
»
SvySor
Максим!
В целом согласен с вами о маркетинговом характере статьи Cisco, но по крайней мере ребята подошли к задачи со всей прямотой: взяли всем известные тесты и померили по явно описанной методике производительность своей и конкурирующих систем (правда, непонятно каких и на собственных серверах). А вот ваш комментарий вызывает некоторые вопросы:
1. «утилиты (iometer, vdbench, и тд) не рассчитаны на тестирование работы современных мультипоточных операционных систем»
Критикуя — предлагай! Приведите примеры альтернативных общепризнанных индустрией тестов (я не говорю о X-Ray, которым можно померить только вас самих и которые ни на что другое не ставится), которые адекватно показывали бы производительность HCI?
2. «Гиперконвергентные решения до недавнего времени являлись не очень подходящим решением для СУБД, тем более с высокой нагрузкой»
Покажите результаты работы хоть какой голой HCI системы на СУБД под высокой нагрузкой? Ни одной публикации в интернете нет. На Oracle, HANA, Hadoop? Да хотя бы попробуйте нагрузить свыше 500 пользователей 1С. Только не надо прислыать ссылки на признание производителей ПО. Мы не о совместимости, мы о производительности. Проблема есть и она заложена в самой архитектуре HCI.
3. the most likely limit to your application’s performance was its ability to access storage. But that changed with SSDs.
Никто не будет спорить, что SSD быстрее, чем HDD. Но так же никто не будет спорить, что скорость DDR4 существенно выше не только SSD дисков, но и Optane.
Мы сейчас вроде о высоконагруженных системах. Вы тоже вроде за реальных потребителей ратуете, а не о рекордах круглых коней в вакууме. Сколько реально в системе горячих данных, а сколько просто лежит? А о деньгах задумались?
Есть определенные плюсы в HCI технологии, но нужен сбалансированный подход к созданию архитектуры и приложений и предприятия в целом. Говорить сразу — у нас работает, а это не работает — не верно. Вы тогда тоже, простите, опускаетесь до уровня «голимого маркетинга».
Дайте ваши цифры и тесты!
shapa
Все смешалось в доме Облонских ;)
Для начала — спасибо за то, что как минимум — пытаешься разобраться в реальностях.
Но ты бы хотя бы погуглил чуток перед тем как писать.
1) X-Ray — внезапно — может тестировать что угодно. Нутаникс для него вообще не нужен. И исходники доступны, и параметры тестирования — все открыто. Можно запустить как VM на чем угодно, и далее тестировать хоть 3-tier.
github.com/nutanix/xray-scenarios
2) Насчет «хоть какой» — я так понимаю ты очень серьезно отстал от рынка. У нас масса внедрений огромных баз данных в мире — начиная от «Платона» в РФ (300TB насколько помню крутят на Постгрес) и InBev (70TB базы Oracle), заканчивая всякими Nintendo и прочими Toyota.
Идешь на nutanix.com и смотришь Best Practices.
Как намек — SAP сертифицировал Nutanix для SAP HANA (на 4-х сокетах в том числе), а так-же всех приложений Netweaver.
Которые по определению требуют business critical базу данных.
Или идешь и смотришь результаты CFT (ЦФТ) — на их АБС (которую они официально сертифицировали под Нутаникс) мы порвали даже ExaData (на старом железе результат был с Oracle RAC — около 7000TPS, сейчас я думаю раза в полтора будет выше). В РФ кроме Сбербанка даже нет банков которым столько нужно.
В общем откровенно ты удивил, замечание про «HCI архитектуру» крайне посмешило. HCI (за счет той-же data locality) по определению способен работать с БД намного быстрее и лучше чем традиционные архитектуры.
blog.in-a-nutshell.ru/nutanix-1-tier-business-critical-cft
pgconf.ru/2017/93499
www.reddit.com/r/NintendoNX/comments/51wo4s/whats_in_a_name_nitendo_utilising_nutanix_xtreme
4) Нутаникс поддерживает полноценный тиринг.
Горячие данные на SSD, холодные на SATA. Остальные HCI вендоры нормальный тиринг не умеют (как и большинство традиционных СХД), поэтому пихают All Flash.
Так-что да, Нутаникс о клиентах как раз позаботился.