
Представим типичную ситуацию на первом курсе: вы прочитали про алгоритм Диница, реализовали, а он не заработал, и вы не знаете, почему. Стандартное решение — это начать отлаживать по шагам, каждый раз рисуя текущее состояние графа на листочке, но это жутко неудобно. Я попробовала исправить положение в рамках семестрового проекта по Software Engineering, а в посте расскажу, как у меня в итоге получился плагин для Visual Studio. Скачать можно тут, исходный код и документацию можно посмотреть тут. Вот скриншот графа, который получился для алгоритма Диница.
Меня зовут Ольга, я закончила третий курс направления «Прикладная математика и информатика» в Питерской Вышке по специализации Software Engineering. До поступления в университет я не занималась программированием.
На нашем факультете практикуются ежесеместровые научно-исследовательские работы. Обычно это происходит так: в начале семестра происходит презентация НИРов — представители разных компаний предлагают всевозможные проекты. Потом студенты выбирают понравившиеся проекты, научные руководители выбирают понравившихся студентов и так далее. В конце концов, каждый студент находит себе проект.
Но есть и другой путь: вы можете самостоятельно найти научного руководителя и проект, а потом убедить куратора, что этот проект действительно может быть полноценным НИРом. Для этого нужно доказать, что:
Я выбрала второй путь. Первое, что нужно было сделать после того, как я договорилась с научным руководителем — это найти тему проекта. В списке идей были: code style checker для Lua, отладчик, позволяющий вычислять выражения по частям, и тул для олимпиадников / обучения программированию, который позволяет визуализировать, что происходит в коде. То есть визуализатор для произвольных структур данных, совмещённый с отладчиком. Например, пишет человек Декартово дерево, и в процессе рисуются вершины, рёбра, текущая вершина и прочее. В итоге я решила остановиться именно на этом варианте.
Моя работа над проектом состояла из следующих этапов:
Планирование я всегда осуществляла вместе со своим научным руководителем. Все возникающие по ходу дела идеи мы также всегда придумывали и обсуждали вместе. Помимо этого, научный руководитель давал мне советы по коду и помогал с time management'ом. Про все технические проблемы (непонятные баги и прочее) я тоже всегда докладывала, но чаще всего удавалось решить их самостоятельно.
Для начала, следовало убедить наше руководство, что эта тема достойна того, чтобы быть моим НИРом. И начать следовало с первого пункта: поиск аналогов.
Как оказалось, аналогов много. Но большинство из них были рассчитаны на визуализацию памяти. То есть они бы прекрасно справились с визуализацией Декартова дерева, но то, что кучу на массиве надо рисовать не как массив, а как дерево, они понять не могут. Среди этих аналогов были gdbgui, Data Display Debugger, плагин для Eclipse jGRASP и плагин под Visual Studio Data Structures Visualizer. Последний тоже создавался для задач олимпиадного программирования, но умел визуализировать только структуры данных на указателях.
Было ещё несколько тулов: Algojammer для питона (а мы хотели плюсы, как наиболее популярный язык у олимпиадников) и разработанный в 1994 году тул Lens. Последний, судя по описанию, делал почти то, что нужно, но, к сожалению, создавался под Sun OS 4.1.3 (операционную систему родом из 1992 года). Так что, несмотря на наличие исходников, было решено не тратить время на эту сомнительную археологию.
Итак, после некоторого исследования было установлено, что тула, который бы делал ровно то, чего нам хотелось, и при этом работал бы на современных машинах, в природе пока нет.
Вторым шагом нужно было доказать, что это задача достаточно сложная, но выполнимая. Для этого требовалось предложить что-то более конкретное, чем «хочу, чтобы была красивая картинка, и чтобы из неё всё сразу стало понятно».
В этом проекте мы решили сконцентрироваться на визуализации только графов: существует достаточно много алгоритмов на графах, которые могут быть по-разному реализованы, и даже будучи суженной, задача всё ещё остается нетривиальной.
Также более-менее очевидно, что тул должен быть как-то интегрирован с отладчиком. Нам надо уметь просматривать значения переменных и выражений, и по этим значениям рисовать готовую картинку.
После этого нужно было придумать некий язык, позволяющий по текущему состоянию программы строить граф так, как мы захотим. Кроме самого графа нужно было предусмотреть возможность менять цвет вершин и рёбер, добавлять к ним произвольные надписи и изменять прочие свойства. Соответственно, первой идеей было:
Прототип пользовательского интерфейса я нарисовала в NinjaMock. Это требовалось для лучшего понимания, как интерфейс будет выглядеть с точки зрения пользователя, и какие действия ему потребуется произвести. Если бы возникли проблемы с прототипом, мы бы поняли, что есть какие-то логические нестыковки, и эту идею следует отбросить. Для верности я взяла несколько алгоритмов. На картинке ниже примеры того, как я представляла себе настройки визуализации DFS и алгоритма Флойда.
Как я себе представляла настройки для DFS. Граф хранится как список смежности, поэтому ребро между вершинами i и j определяется условием
Я предполагала, что для алгоритма Флойда потребуется нарисовать чёрным настоящие рёбра, хранящиеся в массиве
Для следующего шага нужно было понять, как именно это всё делать. В первую очередь, требовалась интеграция с отладчиком. Первое, что приходит в голову при слове «отладчик» — это gdb, но тогда пришлось бы создавать весь графический интерфейс с нуля, что действительно сложно сделать студенту за семестр. Вторая очевидная идея — сделать плагин к какой-нибудь существующей среде разработки. В качестве вариантов я рассматривала QTCreator, CLion и Visual Studio.
Вариант с CLion отбросили почти сразу, потому что у него, во-первых, закрытый исходный код, а во-вторых, всё очень плохо с документацией (а дополнительные сложности никому не нужны). QTCreator, в отличие от Visual Studio, кроссплатформенный и имеет открытый исходный код, и поэтому вначале мы решили остановиться на нём.
Оказалось, однако, что QTCreator плохо приспособлен для расширения при помощи плагинов. Первый шаг при создании плагина для QTCreator — это сборка из исходников. У меня это заняло полторы недели. В итоге я отправила два баг-репорта (вот и вот), касающиеся процесса сборки. Да, вот столько усилий было потрачено на сборку QTCreator только для того, чтобы обнаружить, что отладчик в QTCreator не имеет публичного API. Я вернулась к другому варианту, а именно к Visual Studio.
И это оказалось верным решением: у Visual Studio не просто прекрасное API, но и отличная документация к нему. Вычисление выражений упрощалось до вызова
Разумеется, не предполагалось, что я буду заниматься визуализацией графов с нуля — для этого есть куча специальных библиотек. Самая знаменитая из них — Graphviz, и именно её мы и планировали вначале использовать. Но для плагина под Visual Studio логичнее было бы использовать библиотеку для C#, так как я собиралась писать именно на нём. Я немножко погуглила и нашла библиотеку MSAGL: она обладала всей требующейся функциональностью и имела простой и понятный интерфейс.
Теперь, имея механизм для вычисления произвольных выражений с одной стороны и библиотеку для визуализации графов с другой, требовалось сделать прототип. Первый прототип был сделан для DFS, потом в качестве примеров были взяты алгоритм Диница, алгоритм Куна, поиск компонент двусвязности, Декартово дерево, СНМ. Я брала свои старые реализации этих алгоритмов с первого-второго курса, создавала новый плагин, в нём рисовала граф, соответствующий этой задаче (все имена переменных были захардкожены). Вот пример графа, который у меня получился для алгоритма Куна:
На этом графе текущие рёбра паросочетания показаны фиолетовым, текущая вершина dfs — красным, посещенные вершины — серым, ребра чередующейся цепи не из паросочетания — красным.
Я считала допустимым немного менять код алгоритма, чтобы было проще визуализировать. Например, в случае Декартового дерева оказалось, что проще складывать все созданные node’ы в вектор, чем обходить дерево внутри плагина.
Неприятным открытием стало то, что отладчик в Visual Studio не поддерживает вызов методов и функций из STL. Это означало, что проверить наличие элемента в контейнере при помощи
В моих пробных плагинах происходило примерно следующее (если граф хранился как список смежности):
На тот момент я писала код «как придётся», не пытаясь ни придумать общую схему для всех алгоритмов, ни писать код хоть сколько-то красиво. Создание каждого нового плагина начиналось с копипаста предыдущего.
После проведённых исследований нужно было составить общую схему, которую можно было бы применить для всех алгоритмов. Первое, что было введено — это индексы для вершин и рёбер. У каждого индекса есть уникальное имя и концы диапазона, вычисляемые при помощи
Для каждой вершины или ребра подставляются значения индексов, и после этого оно вычисляется в отладчике. Шаблоны использовали, чтобы отфильтровать некоторые значения индексов (если граф хранится как матрица смежности
В графе могут быть разные типы вершин и рёбер. Например, в случае поиска максимального паросочетания в двудольном графе каждая доля может индексироваться отдельно. Поэтому было введено понятие семейства для вершин и рёбер. Для каждого семейства индексация и все свойства определяются независимо. При этом ребра могут соединять вершины из разных семейств.
Семейству вершин или рёбер можно приписать определённые свойства, которые будут выборочно применяться к элементам в семействе. Свойство применяется, если выполняется условие. Условие состоит из шаблона, который вычисляется в
Свойства бывают самые разнообразные. Для вершин: лейбл, цвет заливки, цвет границы, ширина границы, форма, стиль границы (например, пунктир). Для рёбер: лейбл, цвет, ширина, стиль, ориентация (можно задать две стрелки — от начала в конец или наоборот; при этом могут быть две стрелки одновременно).
Важно, что каждый раз граф рисуется с нуля, и предыдущее состояние никак не учитывается. Это может быть проблемой, если граф динамически меняется в процессе алгоритма — вершины и рёбра могут резко менять своё положение, и тогда сложно понять, что происходит.
Подробное описание конфигурации графа можно почитать тут.
С интерфейсом я решила особо не заморачиваться. Основное окно с настройками (ToolWindow) содержит textarea для сериализованного в JSON конфига и список семейств вершин и рёбер. Каждому семейству соответствует своё окошко с настройками, и каждому свойству в семействе — ещё одно окошко (получается три уровня вложенности). Сам граф рисуется в отдельном окошке. Поместить его в ToolWindow не получилось, поэтому я отправила bug report разработчикам MSAGL, но мне ответили, что это не является целевым сценарием использования. Ещё один bug report был отправлен в Visual Studio, так как в дополнительных окошках с настройками иногда подвисали TextBox’ы.
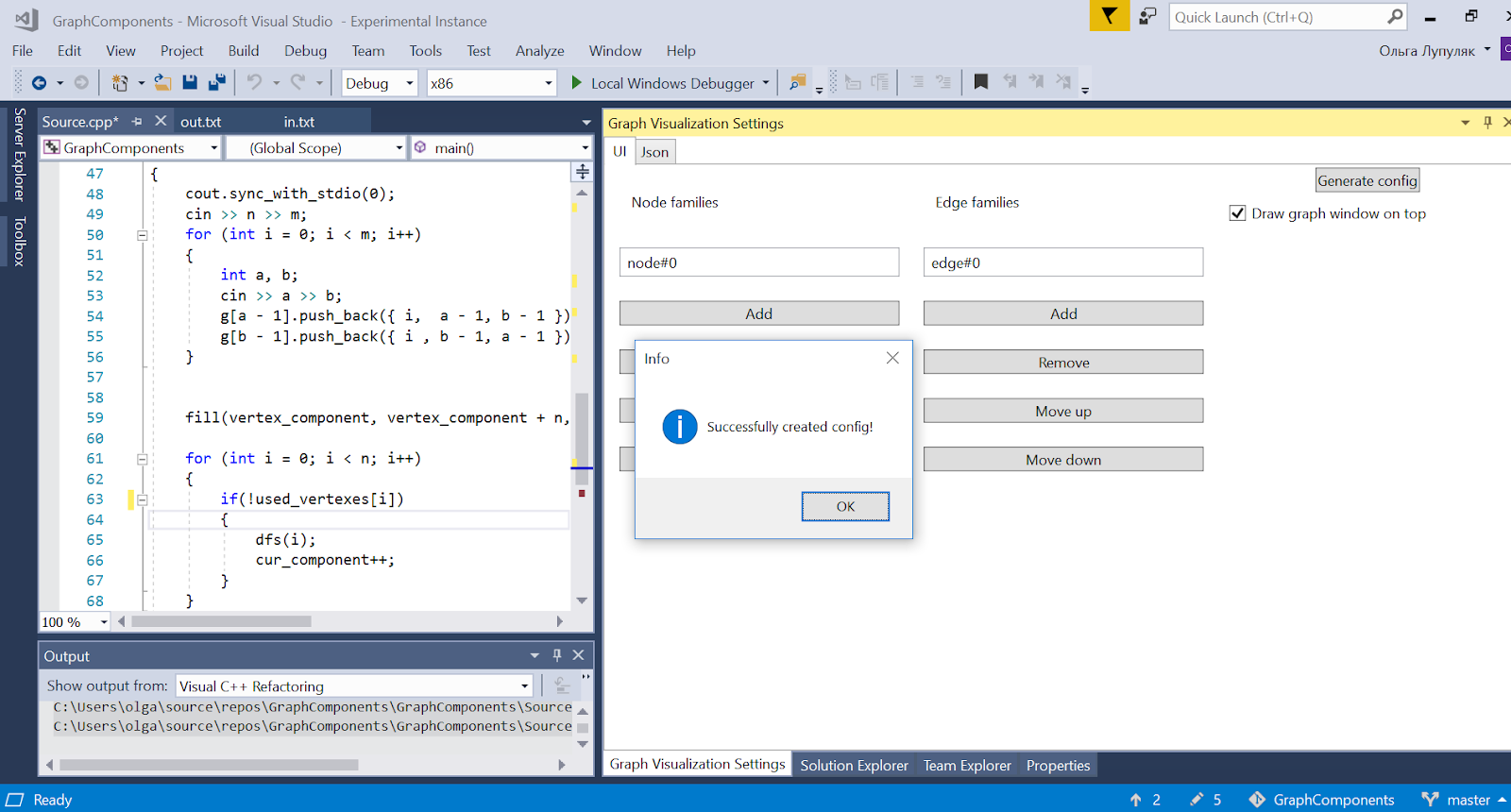
Для того, чтобы задать конфигурацию графа, плагин имеет пользовательский интерфейс и возможность (де)сериализации конфига в JSON. Общая схема взаимодействия всех компонент выглядит следующим образом:
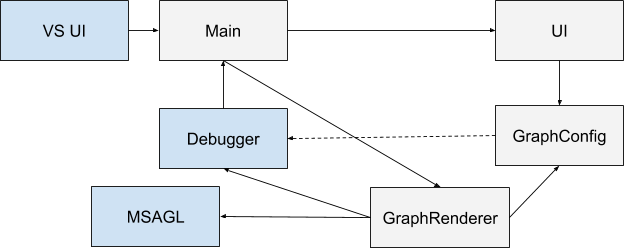
Голубым показаны компоненты, которые существовали исходно, серым — которые создала я. При старте Visual Studio расширение инициализируется (здесь основной компонент обозначен как Main). Пользователь получает возможность задать конфигурацию через интерфейс. При каждом изменении контекста отладчика основной компонент получает уведомление. Если конфигурация определена и отлаживаемая программа выполняется, запускается GraphRenderer. Он получает на вход конфиг и при помощи отладчика строит по нему граф, который после этого отображается в специальном окошке.
В итоге я создала инструмент, позволяющий визуализировать графовые алгоритмы и требующий небольших изменений в коде. Он был опробован на восьми различных задачах. Вот несколько получившихся картинок:
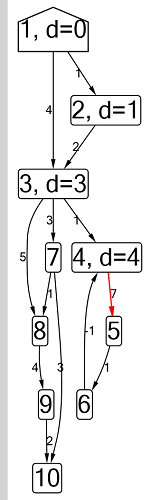
Алгоритм Форда-Беллмана: вершина, до которой мы считаем кратчайшие пути, обозначена домиком, текущее найденное кратчайшое расстояние для вершин равно d, красным обозначено ребро, вдоль которого проходит релаксация.
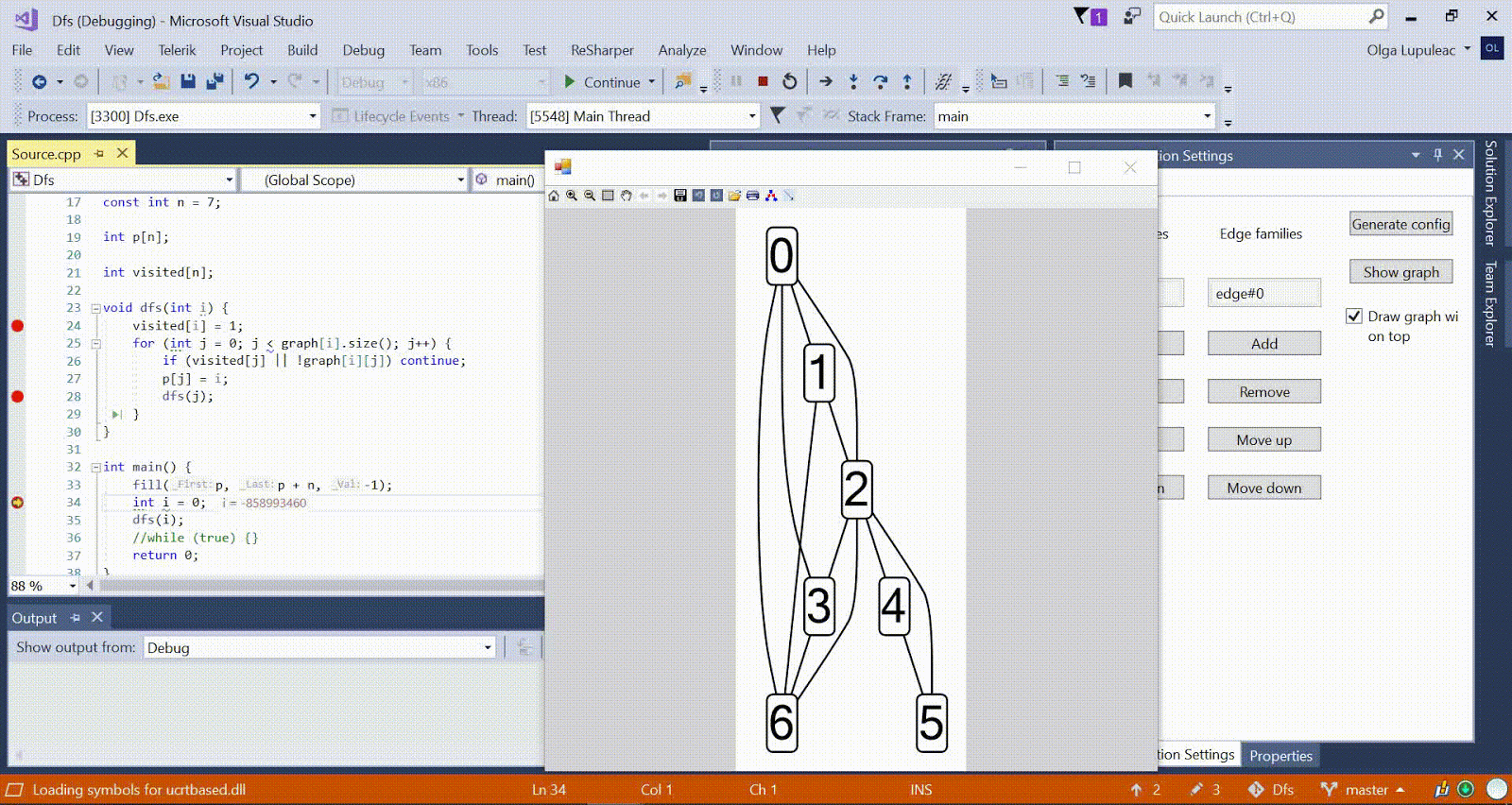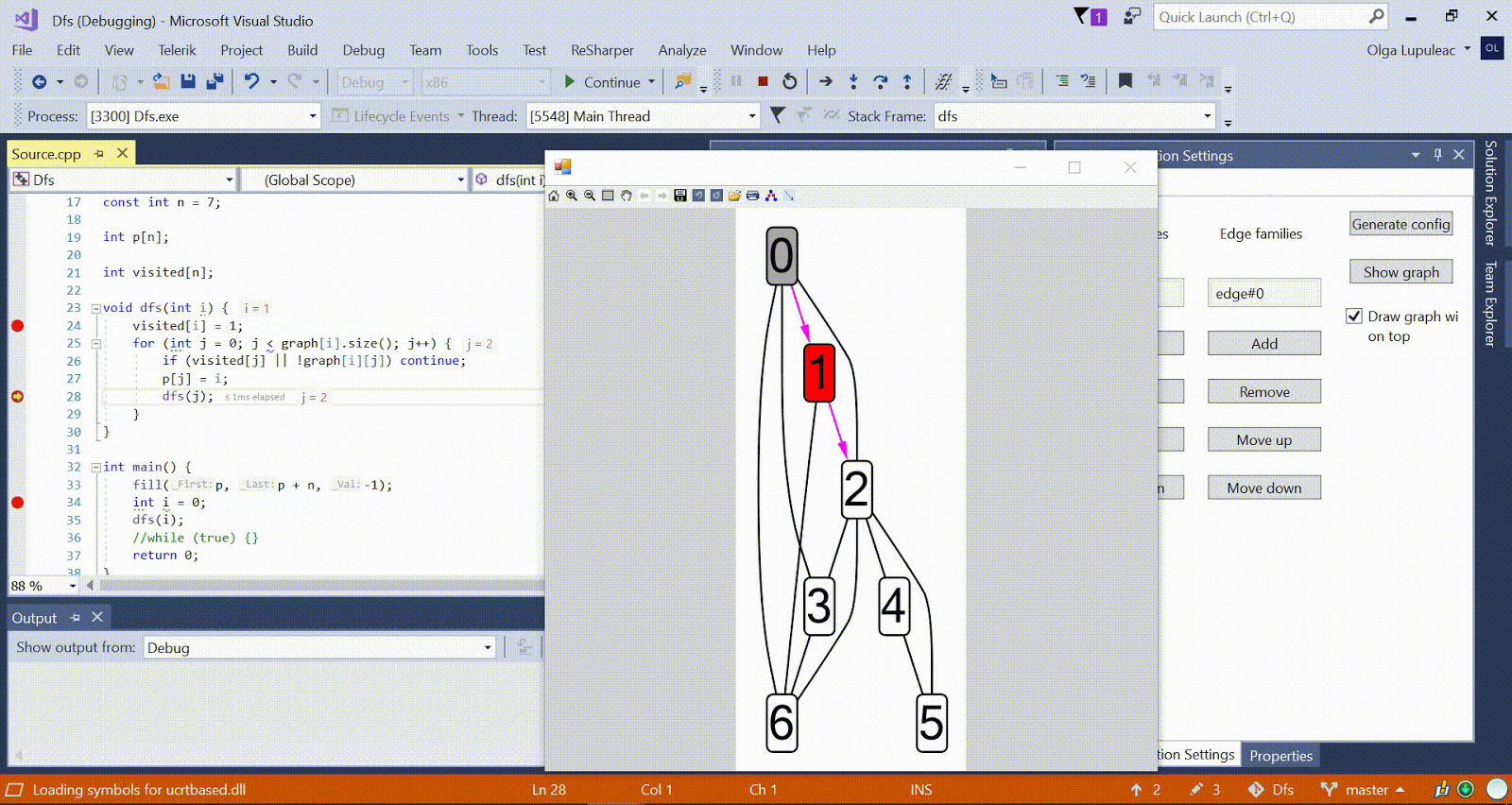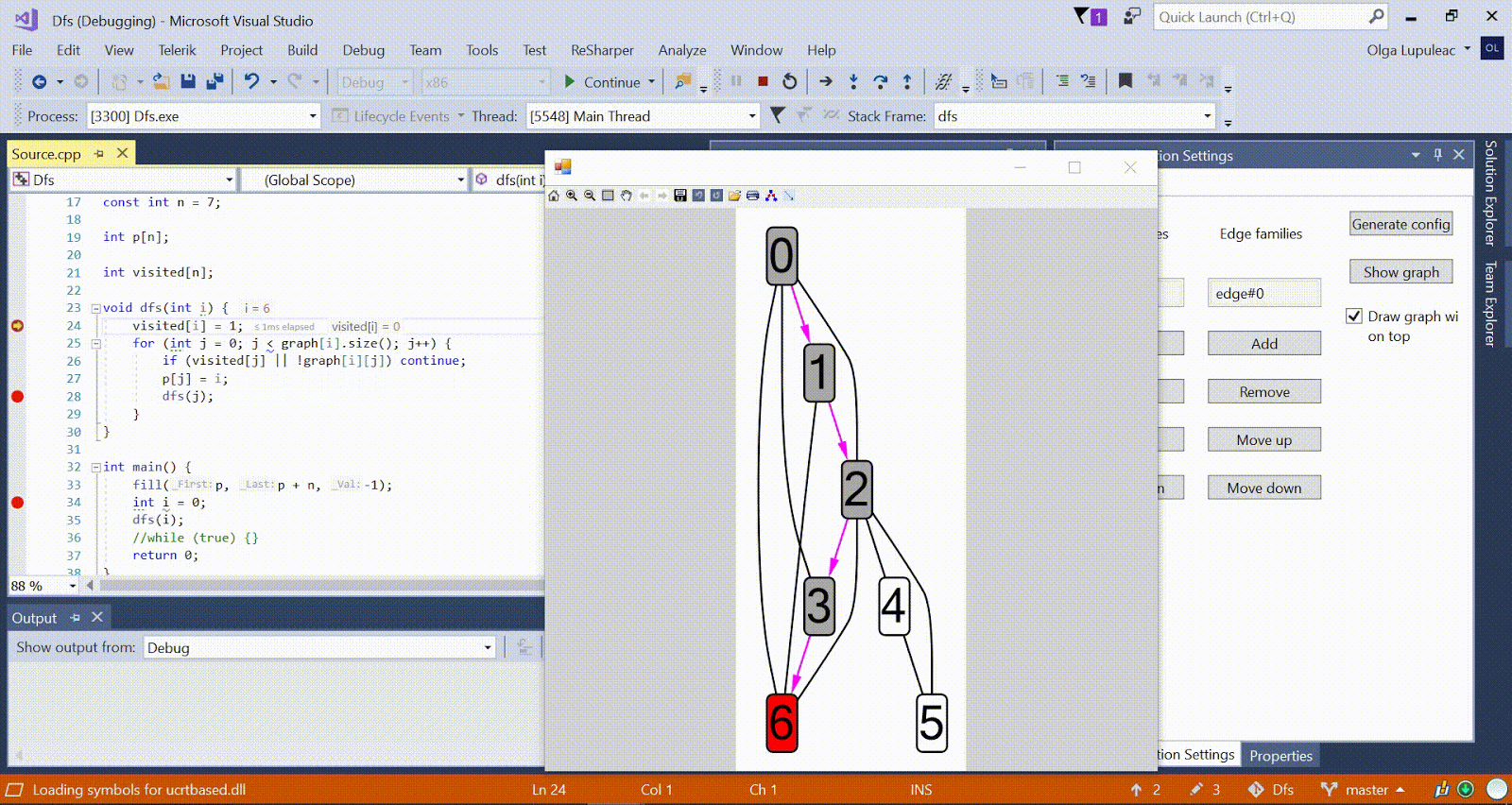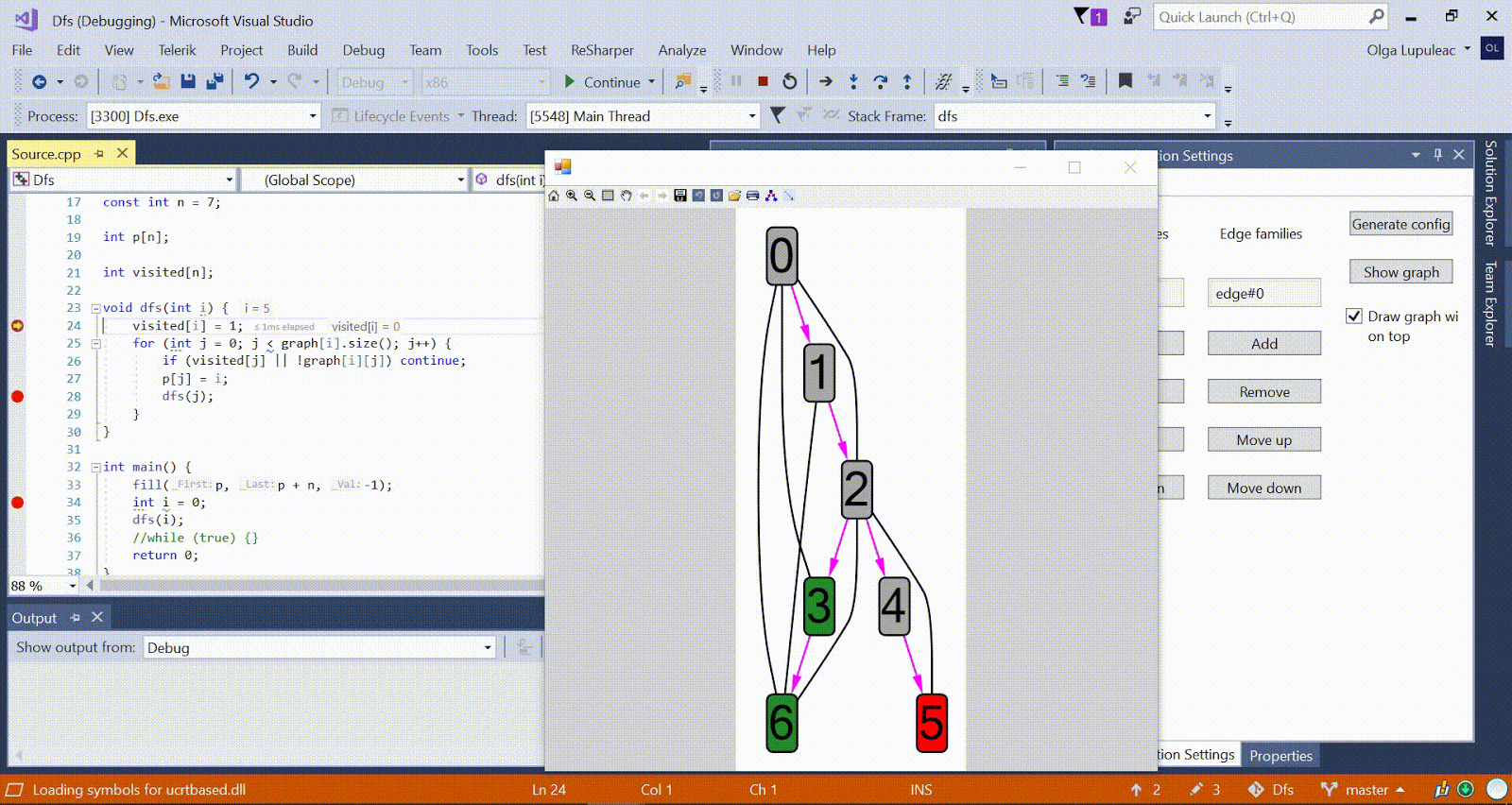
Анимация с DFS — красным показана текущая вершина, серым — вершины в стеке, зелёным — прочие посещённые вершины. Малиновые рёбра показывают направление обхода.
Больше примеров алгоритмов доступно тут
На защите НИРов студентам требуется за семь минут рассказать о своей работе за семестр. При этом, вне зависимости от того, была ли тема предложена в рамках презентации НИРов или студент нашёл её самостоятельно, требуется уметь отвечать обосновывать, почему тема проекта попадает под требования, описанные вначале. Обычно доклад строится следующим образом: сначала идёт мотивация, после этого — обзор аналогов, говорится про то, почему они нас не устраивают, потом формулируются цели и задачи, и дальше про каждую из задач рассказывается, как она была решена. В конце идёт слайд с результатами, где ещё раз говорится, что поставленная цель достигнута и все задачи решены.
Так как с мотивацией и обзором аналогов я определилась уже на начальном этапе, мне требовалось просто собрать всю информацию воедино и сжать до семи минут. В итоге мне это удалось, защита прошла гладко, за НИР мне поставили максимальный балл.
О себе
Меня зовут Ольга, я закончила третий курс направления «Прикладная математика и информатика» в Питерской Вышке по специализации Software Engineering. До поступления в университет я не занималась программированием.
НИР: требования
На нашем факультете практикуются ежесеместровые научно-исследовательские работы. Обычно это происходит так: в начале семестра происходит презентация НИРов — представители разных компаний предлагают всевозможные проекты. Потом студенты выбирают понравившиеся проекты, научные руководители выбирают понравившихся студентов и так далее. В конце концов, каждый студент находит себе проект.
Но есть и другой путь: вы можете самостоятельно найти научного руководителя и проект, а потом убедить куратора, что этот проект действительно может быть полноценным НИРом. Для этого нужно доказать, что:
- Вы собираетесь сделать что-то новое. Разумеется, у проекта могут быть аналоги, но ваш вариант должен иметь перед ними какие-то преимущества.
- Задача должна быть достаточно сложной, то есть работы там должно быть на семестр, а не на день. При этом необходимо, чтобы проект реально было сделать за семестр.
- Ваш проект должен быть чем-то полезен миру. То есть на вопрос, для чего это нужно, вы не должны отвечать: «Ну, мне надо сделать какой-то НИР».
Я выбрала второй путь. Первое, что нужно было сделать после того, как я договорилась с научным руководителем — это найти тему проекта. В списке идей были: code style checker для Lua, отладчик, позволяющий вычислять выражения по частям, и тул для олимпиадников / обучения программированию, который позволяет визуализировать, что происходит в коде. То есть визуализатор для произвольных структур данных, совмещённый с отладчиком. Например, пишет человек Декартово дерево, и в процессе рисуются вершины, рёбра, текущая вершина и прочее. В итоге я решила остановиться именно на этом варианте.
План работы над проектом
Моя работа над проектом состояла из следующих этапов:
- Исследование предметной области требовалось для понимания, не решена ли уже эта задача (тогда тему проекта пришлось бы менять), какие есть аналоги, какие у них есть преимущества и недостатки, которые я могла бы учесть в своей работе.
- Определение конкретной функциональности, которой будет обладать созданный инструмент. Тема проекта была заявлена достаточно абстрактно, и это нужно было для того, чтобы убедиться, что задача достаточно сложная, но при этом её реально выполнить за семестр.
- Создание прототипа пользовательского интерфейса требовалось для наглядной демонстрации того, как созданным инструментом можно будет пользоваться. Оно добавляло ещё больше конкретики, чем набор фичей, описанный словами.
- Выбор зависимостей — нужно понять, как всё будет устроено с точки зрения разработчика и определиться с инструментами, которые будут применяться в процессе написания кода.
- Создание прототипа (proof-of-concept), то есть минимального примера, в котором большая часть была бы захардкожена. На этом примере я должна была разобраться со всеми инструментами, которые я собиралась использовать, а также научиться решать все возникающие трудности, которые возникли по ходу дела, чтобы окончательную версию уже писать «начисто».
- Работа над содержательной частью, то есть разработка и реализация логики инструмента.
- Защита проекта требуется для того, чтобы быстро рассказать о проделанной работе и дать возможность оценить её всем, даже людям, которые не шарят в теме. Является тренировкой перед защитой диплома. При этом хорошо сделанный проект не гарантирует того, что доклад получится хорошим, так как там требуются другие навыки, например, умение выступать перед публикой.
Планирование я всегда осуществляла вместе со своим научным руководителем. Все возникающие по ходу дела идеи мы также всегда придумывали и обсуждали вместе. Помимо этого, научный руководитель давал мне советы по коду и помогал с time management'ом. Про все технические проблемы (непонятные баги и прочее) я тоже всегда докладывала, но чаще всего удавалось решить их самостоятельно.
Исследование предметной области
Для начала, следовало убедить наше руководство, что эта тема достойна того, чтобы быть моим НИРом. И начать следовало с первого пункта: поиск аналогов.
Как оказалось, аналогов много. Но большинство из них были рассчитаны на визуализацию памяти. То есть они бы прекрасно справились с визуализацией Декартова дерева, но то, что кучу на массиве надо рисовать не как массив, а как дерево, они понять не могут. Среди этих аналогов были gdbgui, Data Display Debugger, плагин для Eclipse jGRASP и плагин под Visual Studio Data Structures Visualizer. Последний тоже создавался для задач олимпиадного программирования, но умел визуализировать только структуры данных на указателях.
Было ещё несколько тулов: Algojammer для питона (а мы хотели плюсы, как наиболее популярный язык у олимпиадников) и разработанный в 1994 году тул Lens. Последний, судя по описанию, делал почти то, что нужно, но, к сожалению, создавался под Sun OS 4.1.3 (операционную систему родом из 1992 года). Так что, несмотря на наличие исходников, было решено не тратить время на эту сомнительную археологию.
Итак, после некоторого исследования было установлено, что тула, который бы делал ровно то, чего нам хотелось, и при этом работал бы на современных машинах, в природе пока нет.
Определение функциональности
Вторым шагом нужно было доказать, что это задача достаточно сложная, но выполнимая. Для этого требовалось предложить что-то более конкретное, чем «хочу, чтобы была красивая картинка, и чтобы из неё всё сразу стало понятно».
В этом проекте мы решили сконцентрироваться на визуализации только графов: существует достаточно много алгоритмов на графах, которые могут быть по-разному реализованы, и даже будучи суженной, задача всё ещё остается нетривиальной.
Также более-менее очевидно, что тул должен быть как-то интегрирован с отладчиком. Нам надо уметь просматривать значения переменных и выражений, и по этим значениям рисовать готовую картинку.
После этого нужно было придумать некий язык, позволяющий по текущему состоянию программы строить граф так, как мы захотим. Кроме самого графа нужно было предусмотреть возможность менять цвет вершин и рёбер, добавлять к ним произвольные надписи и изменять прочие свойства. Соответственно, первой идеей было:
- Определить, что у нас является вершинами, например, числа от 0 до n.
- Определить наличие ребра между вершинами при помощи булевского условия. При этом рёбра бывают разных типов, и у каждого типа есть свой набор свойств.
- Далее, мы можем определить такие свойства вершины, как цвет, тоже при помощи булевского условия.
- Пройтись по шагам отладчиком: все выражения вычисляются, все условия проверяются, и, в зависимости от этого, рисуется граф.
Создание прототипа пользовательского интерфейса
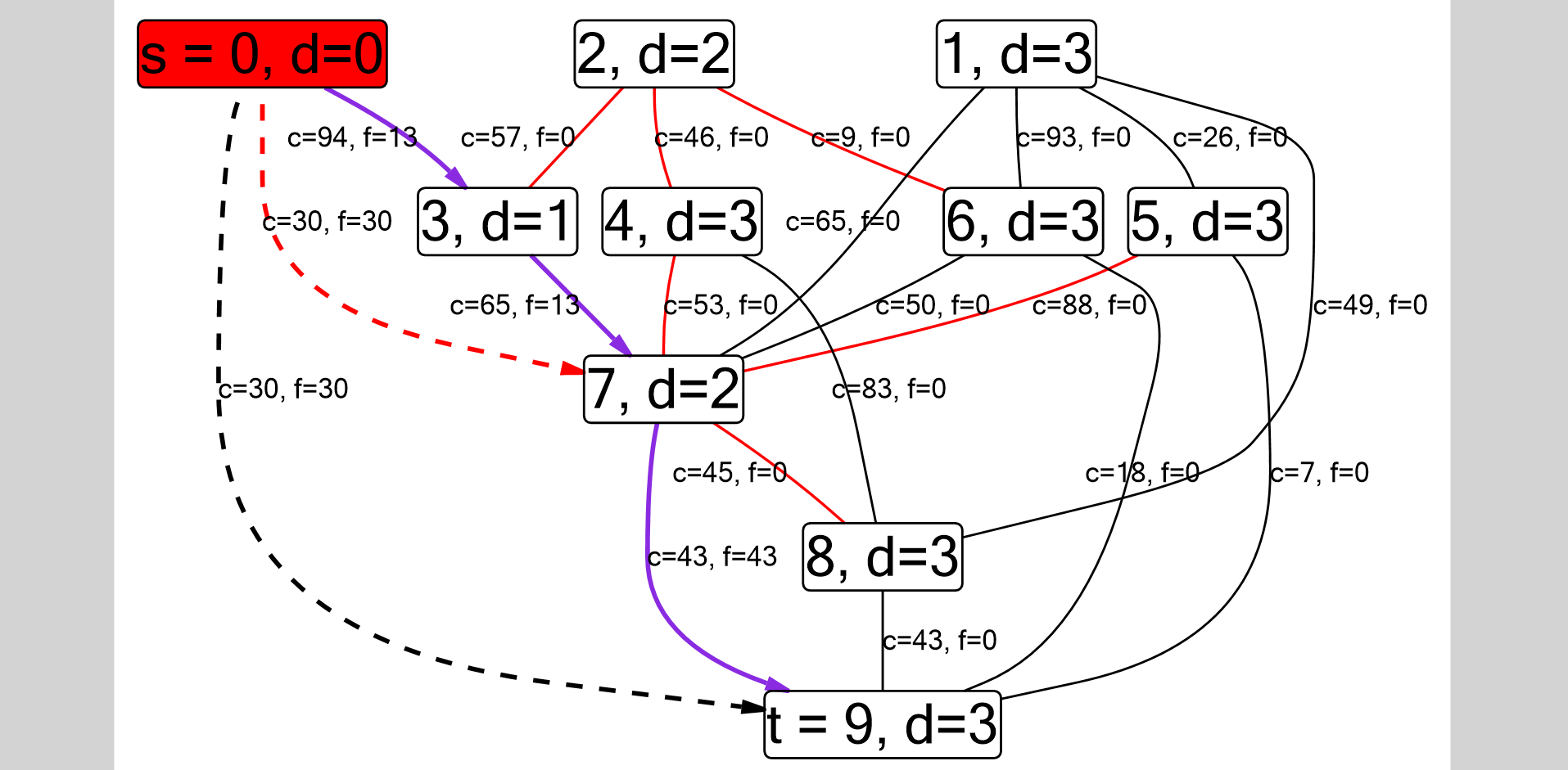
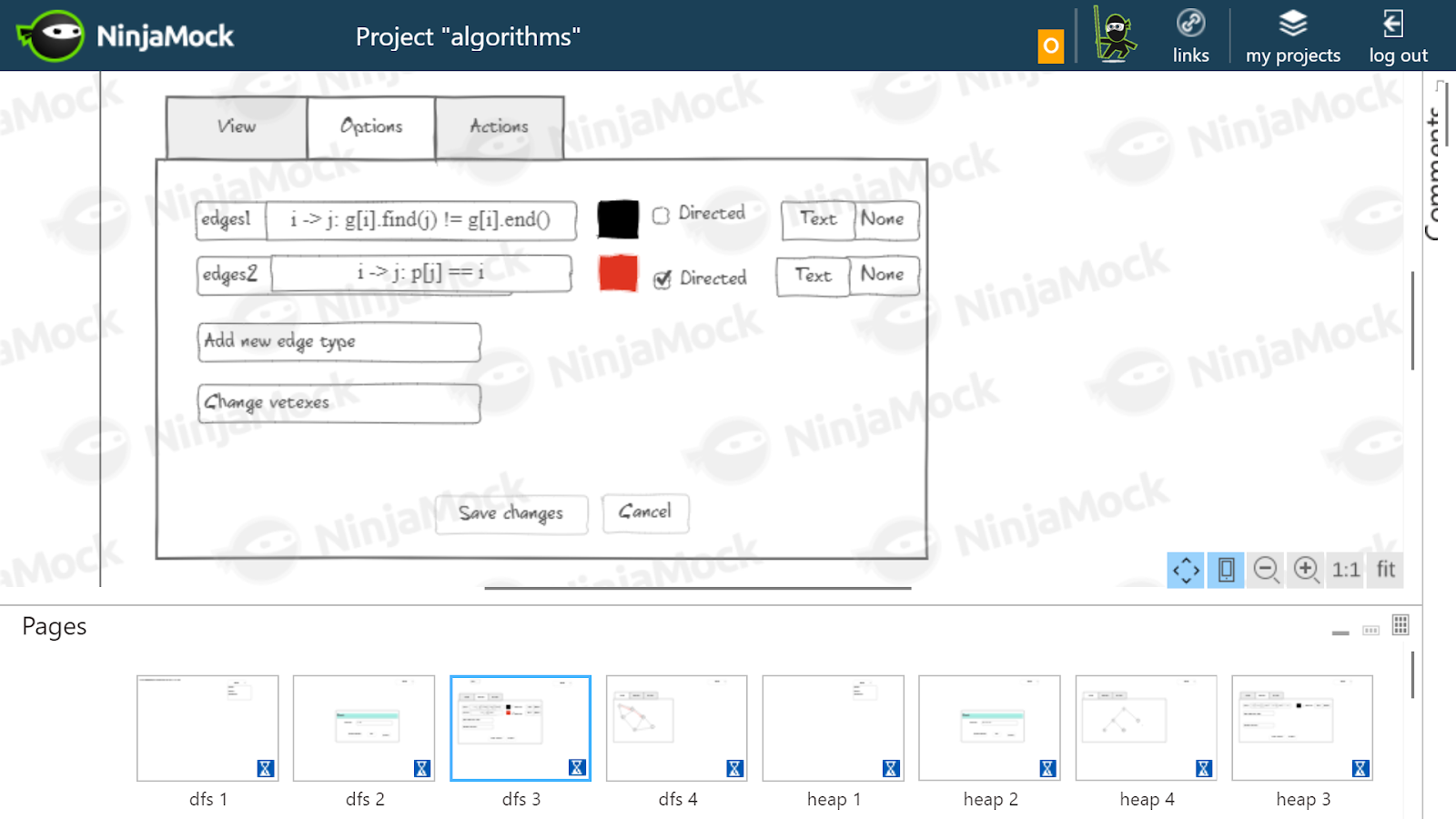
Прототип пользовательского интерфейса я нарисовала в NinjaMock. Это требовалось для лучшего понимания, как интерфейс будет выглядеть с точки зрения пользователя, и какие действия ему потребуется произвести. Если бы возникли проблемы с прототипом, мы бы поняли, что есть какие-то логические нестыковки, и эту идею следует отбросить. Для верности я взяла несколько алгоритмов. На картинке ниже примеры того, как я представляла себе настройки визуализации DFS и алгоритма Флойда.
Как я себе представляла настройки для DFS. Граф хранится как список смежности, поэтому ребро между вершинами i и j определяется условием
g[i].find() != g[i].end() (на самом деле, чтобы не дублировать рёбра, надо проверить, что i <= j). Отдельно показан путь DFS: p[j] == i. Эти рёбра будут ориентированными.Я предполагала, что для алгоритма Флойда потребуется нарисовать чёрным настоящие рёбра, хранящиеся в массиве
c, а серым — найденные на данном этапе кратчайшие пути, хранящиеся в массиве d. Для каждого ребра и кратчайшего пути написан его вес. Выбор зависимостей
Для следующего шага нужно было понять, как именно это всё делать. В первую очередь, требовалась интеграция с отладчиком. Первое, что приходит в голову при слове «отладчик» — это gdb, но тогда пришлось бы создавать весь графический интерфейс с нуля, что действительно сложно сделать студенту за семестр. Вторая очевидная идея — сделать плагин к какой-нибудь существующей среде разработки. В качестве вариантов я рассматривала QTCreator, CLion и Visual Studio.
Вариант с CLion отбросили почти сразу, потому что у него, во-первых, закрытый исходный код, а во-вторых, всё очень плохо с документацией (а дополнительные сложности никому не нужны). QTCreator, в отличие от Visual Studio, кроссплатформенный и имеет открытый исходный код, и поэтому вначале мы решили остановиться на нём.
Оказалось, однако, что QTCreator плохо приспособлен для расширения при помощи плагинов. Первый шаг при создании плагина для QTCreator — это сборка из исходников. У меня это заняло полторы недели. В итоге я отправила два баг-репорта (вот и вот), касающиеся процесса сборки. Да, вот столько усилий было потрачено на сборку QTCreator только для того, чтобы обнаружить, что отладчик в QTCreator не имеет публичного API. Я вернулась к другому варианту, а именно к Visual Studio.
И это оказалось верным решением: у Visual Studio не просто прекрасное API, но и отличная документация к нему. Вычисление выражений упрощалось до вызова
_debugger.GetExpression(...).Value. Также Visual Studio предоставляет возможность итерироваться по стекфреймам, и вычислять выражение в контексте любого из них. Для этого надо поменять property CurrentStackFrame на требуемый. Ещё можно отслеживать обновления контеста отладчика, чтобы при изменении перерисовывать картинку.Разумеется, не предполагалось, что я буду заниматься визуализацией графов с нуля — для этого есть куча специальных библиотек. Самая знаменитая из них — Graphviz, и именно её мы и планировали вначале использовать. Но для плагина под Visual Studio логичнее было бы использовать библиотеку для C#, так как я собиралась писать именно на нём. Я немножко погуглила и нашла библиотеку MSAGL: она обладала всей требующейся функциональностью и имела простой и понятный интерфейс.
Proof-of-concept
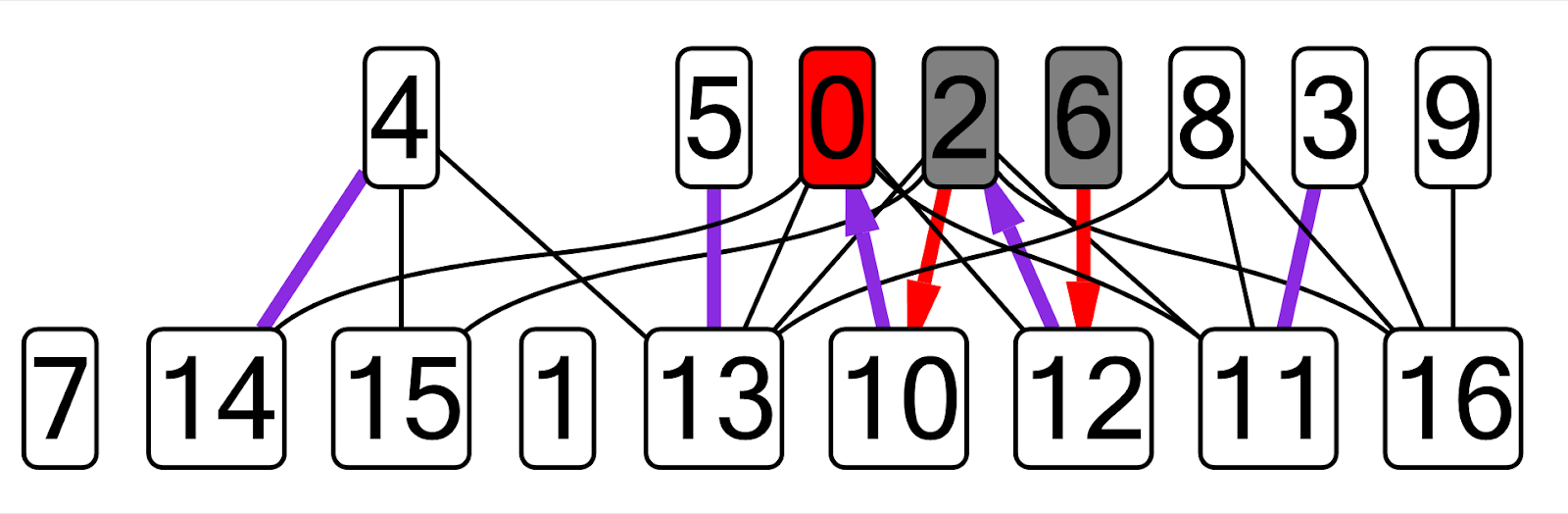
Теперь, имея механизм для вычисления произвольных выражений с одной стороны и библиотеку для визуализации графов с другой, требовалось сделать прототип. Первый прототип был сделан для DFS, потом в качестве примеров были взяты алгоритм Диница, алгоритм Куна, поиск компонент двусвязности, Декартово дерево, СНМ. Я брала свои старые реализации этих алгоритмов с первого-второго курса, создавала новый плагин, в нём рисовала граф, соответствующий этой задаче (все имена переменных были захардкожены). Вот пример графа, который у меня получился для алгоритма Куна:
На этом графе текущие рёбра паросочетания показаны фиолетовым, текущая вершина dfs — красным, посещенные вершины — серым, ребра чередующейся цепи не из паросочетания — красным.
Я считала допустимым немного менять код алгоритма, чтобы было проще визуализировать. Например, в случае Декартового дерева оказалось, что проще складывать все созданные node’ы в вектор, чем обходить дерево внутри плагина.
Неприятным открытием стало то, что отладчик в Visual Studio не поддерживает вызов методов и функций из STL. Это означало, что проверить наличие элемента в контейнере при помощи
std::find, как предполагалось изначально, было нельзя. Эту проблему можно решить либо созданием пользовательской функции, либо дублированием свойства «элемент содержится в контейнере» в булевском массиве. В моих пробных плагинах происходило примерно следующее (если граф хранился как список смежности):
- Сначала идёт цикл
forот0до_debugger.GetExpression("n").Value, который добавлял в граф все вершины, каждую со своим номером.
- Потом идут два вложенных цикла
for, первый поi— от0доn, второй поj— от0до_debugger.GetExpression($"g[{i}].size()").Value, и в граф добавлялось ребро{i, _debugger.GetExpression($"g[{i}][{j}]").Value}.
- Если требовалось, к лейблам вершин и рёбер добавлялась какая-нибудь дополнительная информация. Например, значение массива
d, отвечающего за расстояние до выделенной вершины.
- Если в основе алгоритма был dfs, то после этого шёл цикл по всем стекфреймам, и все вершины в стеке (
stackFrame.FunctionName.Equals("dfs") && stackFrame.Arguments.Item(1) == v) подсвечивались серым.
- Потом для каждого
iот0доn, обозначающего номера вершин, проверялись некоторые условия, и если они выполнялись, то у вершины менялись какие-то свойства, чаще всего цвет.
На тот момент я писала код «как придётся», не пытаясь ни придумать общую схему для всех алгоритмов, ни писать код хоть сколько-то красиво. Создание каждого нового плагина начиналось с копипаста предыдущего.
Конфигурация графа
После проведённых исследований нужно было составить общую схему, которую можно было бы применить для всех алгоритмов. Первое, что было введено — это индексы для вершин и рёбер. У каждого индекса есть уникальное имя и концы диапазона, вычисляемые при помощи
_debugger.GetExpression. Для обращения к значению индекса используют его имя, окружённое __ (то есть __x__). Выражения с местами для подстановки значений индексов, а также имени текущей функции (__CURRENT_FUNCTION__) и значений её аргументов (__ARG1__, __ARG2__, …), называются шаблонами. Для каждой вершины или ребра подставляются значения индексов, и после этого оно вычисляется в отладчике. Шаблоны использовали, чтобы отфильтровать некоторые значения индексов (если граф хранится как матрица смежности
c, то индексы будут a и b от 0 до n, а шаблон для валидации c[__a__][__b__]). Границы диапазона индекса тоже являются шаблонами, так как могут содержать предыдущие индексы. В графе могут быть разные типы вершин и рёбер. Например, в случае поиска максимального паросочетания в двудольном графе каждая доля может индексироваться отдельно. Поэтому было введено понятие семейства для вершин и рёбер. Для каждого семейства индексация и все свойства определяются независимо. При этом ребра могут соединять вершины из разных семейств.
Семейству вершин или рёбер можно приписать определённые свойства, которые будут выборочно применяться к элементам в семействе. Свойство применяется, если выполняется условие. Условие состоит из шаблона, который вычисляется в
true или false, и регулярного выражения для имени функции. Условие проверяется либо только для текущего стекфрейма, либо для всех стекфреймов (и тогда оно считается выполненным, если оно выполнено хотя бы для одного).Свойства бывают самые разнообразные. Для вершин: лейбл, цвет заливки, цвет границы, ширина границы, форма, стиль границы (например, пунктир). Для рёбер: лейбл, цвет, ширина, стиль, ориентация (можно задать две стрелки — от начала в конец или наоборот; при этом могут быть две стрелки одновременно).
Важно, что каждый раз граф рисуется с нуля, и предыдущее состояние никак не учитывается. Это может быть проблемой, если граф динамически меняется в процессе алгоритма — вершины и рёбра могут резко менять своё положение, и тогда сложно понять, что происходит.
Подробное описание конфигурации графа можно почитать тут.
Пользовательский интерфейс
С интерфейсом я решила особо не заморачиваться. Основное окно с настройками (ToolWindow) содержит textarea для сериализованного в JSON конфига и список семейств вершин и рёбер. Каждому семейству соответствует своё окошко с настройками, и каждому свойству в семействе — ещё одно окошко (получается три уровня вложенности). Сам граф рисуется в отдельном окошке. Поместить его в ToolWindow не получилось, поэтому я отправила bug report разработчикам MSAGL, но мне ответили, что это не является целевым сценарием использования. Ещё один bug report был отправлен в Visual Studio, так как в дополнительных окошках с настройками иногда подвисали TextBox’ы.
Плагин
Для того, чтобы задать конфигурацию графа, плагин имеет пользовательский интерфейс и возможность (де)сериализации конфига в JSON. Общая схема взаимодействия всех компонент выглядит следующим образом:
Голубым показаны компоненты, которые существовали исходно, серым — которые создала я. При старте Visual Studio расширение инициализируется (здесь основной компонент обозначен как Main). Пользователь получает возможность задать конфигурацию через интерфейс. При каждом изменении контекста отладчика основной компонент получает уведомление. Если конфигурация определена и отлаживаемая программа выполняется, запускается GraphRenderer. Он получает на вход конфиг и при помощи отладчика строит по нему граф, который после этого отображается в специальном окошке.
Примеры
В итоге я создала инструмент, позволяющий визуализировать графовые алгоритмы и требующий небольших изменений в коде. Он был опробован на восьми различных задачах. Вот несколько получившихся картинок:
Алгоритм Форда-Беллмана: вершина, до которой мы считаем кратчайшие пути, обозначена домиком, текущее найденное кратчайшое расстояние для вершин равно d, красным обозначено ребро, вдоль которого проходит релаксация.
Анимация с DFS — красным показана текущая вершина, серым — вершины в стеке, зелёным — прочие посещённые вершины. Малиновые рёбра показывают направление обхода.
Больше примеров алгоритмов доступно тут
Защита НИРа
На защите НИРов студентам требуется за семь минут рассказать о своей работе за семестр. При этом, вне зависимости от того, была ли тема предложена в рамках презентации НИРов или студент нашёл её самостоятельно, требуется уметь отвечать обосновывать, почему тема проекта попадает под требования, описанные вначале. Обычно доклад строится следующим образом: сначала идёт мотивация, после этого — обзор аналогов, говорится про то, почему они нас не устраивают, потом формулируются цели и задачи, и дальше про каждую из задач рассказывается, как она была решена. В конце идёт слайд с результатами, где ещё раз говорится, что поставленная цель достигнута и все задачи решены.
Так как с мотивацией и обзором аналогов я определилась уже на начальном этапе, мне требовалось просто собрать всю информацию воедино и сжать до семи минут. В итоге мне это удалось, защита прошла гладко, за НИР мне поставили максимальный балл.
Ссылки
Комментарии (6)

Victor_D
29.07.2019 23:05Отличный проект, достаточно хорошая реализация. Поздравляю с успешной защитой!
zerocool056
29.07.2019 23:05Круто! молодец! после таких примеров обучения, вспоминая свой институт, все таки начинаешь верить, что процесс обучения развивается. Пусть не везде, но меняется.
asi81
29.07.2019 23:05+1Есть ли какой то практический смысл в вашем плагине для более реальных графов? До нескольких миллионов узлов.

hse_spb Автор
29.07.2019 23:27Нет, так как мы не ставили перед собой такой цели. Плагин рассчитан на отладку классических алгоритмов на графах, и в олимпиадах тест стараются минимизировать. Для реальных задач есть более профессиональные инструменты:)
Mingun
Чтобы граф не прыгал при перерисовках, можно сохранять позиции всех узлов и восстанавливать их перед перерисовкой. Уникальный идентификатор узла у вас уже есть и, по всей видимости, не меняется. Появившиеся новые узлы (если такие бывают), уже получают новые координаты от лайоута
hse_spb Автор
Это было одной из наших идей, но показалось, что граф обычно либо не меняется вообще, либо меняется настолько сильно, что если сохранять положение вершин, то граф получится чересчур кривым. Например, в случае Декартова дерева, которое строится с нуля и должно иметь древовидную форму, сохранять положение вершин вообще не получится — они постоянно прыгают между поддеревьями. С другой стороны, отслеживать, что происходит с существующими вершинами, тоже сложно :)