
Кому интересен данный опыт, далее будет описано следующее:
- Опыт эксплуатации ПО StarWind Virtual SAN (VSAN).
- Как сделать маленькое Enterprise СХД.
- История разгона IOPS(практика).
- Шпаргалка по развертыванию и эксплуатации СХД EMC ScaleIO (VxFlexOS) (при отсутствии технической поддержки силами специалистов «НЕ Linux-guru») 1 часть.
1. Опыт эксплуатации ПО StarWind Virtual SAN (VSAN)
StarWind Virtual SAN (VSAN) – в решении Activ- Activ (синхронная репликация на 3-х серверах), в эксплуатации с 2009 -2016 год в разных редакциях(Starwind ISCSI SAN HA-3) на основании серверов с аппаратными RAID массивами.
Плюсы:
- Легко и быстро, устанавливается даже не профессионалом;
- MPIO по ISCSI Ethernet;
- HA (Activ-Activ);
- На новых (гарантийных) серверах (с новыми дисками) можно на несколько лет забыть об обслуживании СХД (пользователи не заметят даже выход из строя двух серверов из трех);
- RAM и SSD кэш томов;
- Быстрая Fast-синхронизация при мелких сбоях в сети.
Минусы:
- Ранее существовала только версия под Windows платформу;
- При длительной эксплуатации (более 3 лет) – трудно найти диск взамен вышедшего из строя (сняты с производства) для ремонта RAID массива (при разнородных дисках возможны сбои в массиве);
- Увеличение количества сетевых интерфейсов и занимаемых под них слотов PCI(дополнительно для синхронизации -сетевые карты, коммутаторы) ;
- При использовании LSFS- «журналируемой файловой системы», длительное выключение системы, которое может быть пагубно при срабатывании UPS при отключении питания;
- Очень длительное время полной синхронизации при большом томе.
Возможно уже вылеченные проблемы(ранее случившиеся при эксплуатации в нашем ЦОД):
- При развале RAID массива – сервер остается виден по каналу синхронизации и данных, но диск в Windows сервере вне сети, раздувается лог Starwind и пожирается память сервера, как следствие зависание сервера. Возможное лечение назначение контрольного файла и убирание из настроек логов не критичных сообщений.
- При выходе из строя коммутатора или сетевых интерфейсов – неоднозначный выбор ведущего сервера (иногда случалось- система не могла понять с кого синхронизировать).
Полезные новости(ещё не опробованные):
StarWind Virtual SAN for vSphere (гиперконвергентное решение), позволяет встраивать в кластер виртуализации Vmware без привязки к Windows серверам(на базе линукс виртуальных машин).
Резюме: Отказоустойчивое решение, при наличии нормальной программы замены аппаратных серверов по окончании гарантии и наличии технической поддержки StarWindSoftWare.
2. Как сделать маленькое Enterprise СХД
Постановка задачи:
Создать отказоустойчивую сеть хранения данных небольшого объема итого 4 TB-20TB, с гарантированным функционированием в среднесрочной перспективе без значительных дополнительных финансовых затрат.
- Cистема должна быть отказоустойчивой (спокойно переносить выход из строя, как минимум одного коммутатора, одного сервера, дисков и сетевых карт в сервере).
- По максимуму использовать все ресурсы имеющегося аппаратного парка серверов (3-10 летних серверов и коммутаторов).
- Обеспечивать функционирование томов разных уровней: All-Flash и HDD +SSD cache.
Исходные данные:
- ограниченный бюджет;
- оборудование поколения 3-10 летней давности;
- специалисты — «Не Linux- Guru».
Расчет характеристик
Чтобы избежать узкие мест в части производительности при использовании SSD дисков, которая будет срезаться, чем то из цепочки оборудования: сетевые карты ,RAID (HBA) контроллер, экспандер (корзина), диски.
Необходимо на момент создания предусмотреть исходя их требуемых характеристик определенную конфигурацию оборудования.
Можно конечно запустить на 1Gb/s сетях и 3G контроллерах конфигурация с SSD кешированием SAS HDD, но результат будет в 3-7 раз хуже, чем на 6Gb RAID и 10Gb/s сетях (проверено тестами).
В инструкции по тюнингу VxFlexOS описана простая инструкция по расчету необходимой пропускной способности, исходя из оценки SSD -450 МБ/C и HDD -100 МБ/C, при последовательной записи (на пример при ребалансе и ребильде серверов хранения).
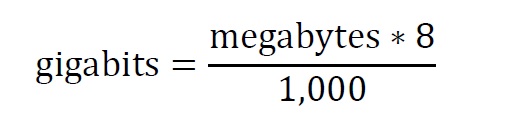
Например:
- (SSD кэш + 3 HDD), получаем ((450*1)+(3*100))*8/1000= 6Гб
- (ALL FLASH SSD) + (SSD кэш + 3 HDD) ((450*2)+(3*100))*8/1000= 9,6Гб
Для определения пропускной способности сети по IOPS (штатная нагрузка на серверах баз данных и нагруженных виртуальных серверах), есть ориентировочная таблица от StariWindSoftware
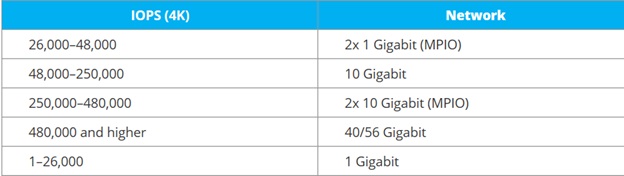
Итоговая конфигурация:
- ПО СХД, которое может не объединять диски в RAID-массивы, а передавать их СХД в виде отдельных дисков (чтоб не было проблем с заменой через определенный период дисков при выходе их из строя, а просто подбирать их по емкости);
- Сервера Поколения процессоров e55xx- x56xx и выше, шинами pci-express v 2.0 и выше, Raid (HBA) контроллерами 6G -12Gс памятью, корзинами экспандерами на 6-16 дисков;
- Коммутаторы SMB 10G Layer 2 (JUMBO FRAME, LACP).
Способ решения
На данный момент не найдено бюджетных вариантов «Аппаратных Enterprise СХД» маленького объема, с указанными выше требованиями.
Остановились на программных решениях, позволяющих пользоваться преимуществами Enterprise СХД, при варианте использования существующих серверов, которые при этом варианте имеют право умереть от старости без ущерба СХД.
- Сeph — не хватает Linux специалистов;
- EMC ScaleIO — за пару лет технической поддержки — можно обойтись существующими кадрами.
- (как оказалось, познания в Linux можно иметь минимальные, об это дальше в шпаргалке).
3. История разгона IOPS (бюджетная практика)
Для ускорение операций чтения, записи в систем хранения применялись SSD устройства:
3.1. Контролеры с функциями SSD кэширования.
В 2010 году появились RAID контролеры с функциями SSD кэширования Adaptec 5445 с MaxIQ диском(для ощутимого результата нужно было иметь хотя бы 10% MaxIQ диска от объема кэшируемого тома), результат есть но незначительный *проверено на себе;
Позже появились контролеры которые могут использовать произвольный SSD диск для кэширования, как у Adaptec серия Q, так и LSI CacheCade ( но там лицензирование отдельно);
3.2. Программное кэширование с использование дисков, типа Intel DC S3700, которые видит контроллер и экспандер брендовых серверов HP, IBM, FUJI ( большинство серверов их удачно опознает, для All-Flash дороговато, а вот для 10% на SSD cache — терпимо не выпуски их под партномерами IBM, HP, FUJI, а просто Intel). *Но сейчас есть более дешевые совместимые варианты(см.п. 3.5.);
3.3. Программное кэширование с использование адаптера PCIe- M.2, SSD Synology M.2 M2D18 , проверено, работает и в обычных серверах( не только в Synology), полезно когда RAID контроллер и корзина отказывается видеть SSD, которые не указал производитель в совместимых (н.п. HP D2700)? *;
3.4. Гибридные диски Seagate EXOS, н.п. 600Gb Seagate Exos 10E2400 (ST600MM0099) {SAS 12Gb/s, 10000rpm, 256Mb, 2.5"}, * проверено опознается серверами HP,IBM, FUJI (альтернатива вариантам 3.1.-3.3.);
3.5. Диски SSD c большим ресурсом и сопоставимой ценой с SAS корпоративного класса,
Crucial Micron 5200 MAX MTFDDAK480TDN-1AT1ZABYY, *проверено опознается серверами HP,IBM, FUJI
(альтернатива вариантам замены HDD дисков на совместимые по п.3.4 и совместимые со старыми серверами SAS диски: Жесткий диск SAS2.5" 600GB AL14SEB060N TOSHIBA*,
C10K1800 0B31229 HGST, ST600MM0099 SEAGATE ). Позволяет бюджетно перейти от HDD+SSD, к All-Flash томам.;
4. Шпаргалка по развертыванию и эксплуатации СХД EMC ScaleIO (VxFlexOS) 1часть
СХД EMC ScaleIO (VxFlexOS)
После тестирования решения до покупки, пришел к выводу, что для нормального функционирования системы необходимо более 3-х нод (при 3 нестабильно отработка отказа), для примера возьмет конфигурацию из 8 серверов (переживет без потери томов последовательный отказ 4 серверов).
Аппаратная часть:
FUJI CX2550M1 (E5-2xxx)– 3 шт. (основной кластер виртуализации серверов VmWare VSphere + ScaleIO клиент SDC и сервер SDS);
+5 серверов поколения HP G6(G7) или IBM M3 (e55xx-x56xx) — сервера ScaleIO SDS;
+ 2 коммутатора NetGear XS712T-100NES
На работающем СХД в режиме RFCache, удалось при помощи Iometer разогнать до 44KIops

Конфигурация СХД:
12TB сырой емкости(минимальная лицензия на момент когда еще продавалась как софт)
8 серверов SDS 28 дисков
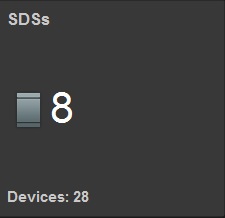
Read RAM cache 14 Gb
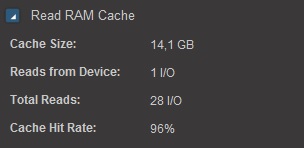
Read Flash cashe 1,27 TB (RFCashe)

В промежуточном варианте, где только 3 серверах 2х10Gb имеют сетевые карты, в остальных 2 х1Gb.

Наглядно видно, что даже при SSD кэшировании при 1Gb вместо 10Gb, идет потеря пропускной способности SDS в три раза и более, при идентичных носителях.
Без кеширования, если считать по данным «нормативам» то при 28 дисках HDD,
получим 28Х140=3920 IOPS, т.е. чтобы получить результат в 44000 IOPS нужно было бы в 11 раз больше дисков. Экономически выгодней при малых потребностях в объемах, не увеличивать количество дисков а, SSD кэш.
На вопрос, зачем такие скорости при маленьком объеме, отвечу сразу!
Есть такие маленькие организации(как наша), в которых есть большое количество электронных документов, которые в программном комплексе обрабатываются долго (контроли каждого реестр на отправку ПП до 1 часа, даже на этом разогнанном СХД). Все остальные варианты уже применены ранее (увеличение на РМ -ОЗУ, CPU i5, SSD, 1Gb- NET). Даже применение на СХД только связки SSD+SAS (пока без ALL-Flash) позволило использовать большую часть ресурсов серверов виртуализации, перенос нагруженных ВМ на ScaleIO — увеличил загрузку процессоров FUJI CX400M1 в два раза (ранее сдерживало хранилище).
Комментарии (18)

oller
01.08.2019 07:34Спасибо за статью.
У starwind со сплитбрейнами не сталкивались?
ScaleIO уже нет смысла показывать в статьях, он не желец, нельзя купить, хоть и хотелось бы… Лично мне присматривается система nutanix, больше адекватного пока не присмотрел, но ещё ищу
Ceph это поделка и не более того пока что, без lts, без стабильность, с потерей файлов…
Smilshu Автор
01.08.2019 09:45Из за сплитбрейна и перешел на ScaleIO там есть пара тибрекеров которые решают кто мастер MDM. У старвинда при проблемах на уработанных серверах не с сетью, а с рэйдами (рейд развалился, но сеть работает) были проблемы выбора — кто главный. При окончательном глюке приходилось убирать репликации и искать какой img позволял пересчитать сигнатуру без форматирования и с него реплицировал на соседние ноды.
На новых серверах работает аккуратно, а когда два из трех начинают глючит, тут без гемороев не обойтись.
ScaleIO купить нельзя, только вместе с железом, но даже новые версии открыты для скачивания (почему не знаю, только для скачивания нужно зарегистрироваться на EMC).
ScaleIO действительно хороший продукт, основной плюс — самолечится и количество отказавшего оборудования может быть большое, главное не одновременно — но это тоже регулируется архитектурой FS.
Но тренд ухода на программно -аппаратные комплексы везде, видно так производителям проще впаривать и обслуживать (кол-во вариантов причин сбоев резко уменьшается).
Программный только на свой страх и риск (или как тестирование перед закупкой железа ПАК). К тому же ScaleIO и без лицензии имеет тот же функционал, только без техподдержки.
Но повторюсь в второй части, если будет интерес опишу краткий словарь ( с примерами )как развернуть за день систему Linux-лоху.
В августе дособеру All-Flash pool 10G (доехали SSD и 10G Net) и опишу результат и затраты.
nutanix — не плохо, но если не хочется ломать существующий кластер Vmware, то не вариант.
Пусть народ простит, но я люблю 4V (Vmware, Veeam, VxFlexOS, Vodka), в отличии от остального еще никогда не подводили :)oller
01.08.2019 10:07Я прям сейчас в поисках решений SDS и поэтому ваши ответы мне очень сильно помогают в выборе
Скачивать нельзя вроде уже, если нет покупки-подписки, я не нашел откуда, кроме FTP открытого), там версия 2,5, и то кажется именно 2,5 не вся
А не подскажете, по прежнему ScleIO бесплатен и не требует активации на 3-4 ноды?
Мне нужен SDS для Proxmox, но внедрять Gluster и Ceph идеи так себе, нужна система сильно проще и надежнее, да и быстрее, поэтому ScleIO смотрел серьезно, все понравилось в ней вроде
10GB обязательны для любой SDS сейчас, с моими текущими Nexus, которые взял БУ могу сделать и 40GB(80 в итого), железо старое
И не подскажете, как ScaleIO живет с бедблоками?
Спасибо огромное за ответы!!!Smilshu Автор
01.08.2019 10:27У меня подписка кончилась (44-ФЗ :(), но допуск к обновлениям даже 3.01. остался, ранее они его закрывали, сейчас почему то нет.
ScаleIO бесплатен даже за 100 нод, без ключа работает также.
Proxmox (онже debian) не помню кажется нет в списке совместимого- но надо точно смотреть, выйду на работу гляну кажется НЕТ www.dell.com/community/ScaleIO/ScaleIO-for-Debian-Linux/td-p/7035485
10G рекомендуют — у меня в продакшене 1G пока, идет переход на 10G.
Бэдблоки беда как и партиции на дисках, перед сборкой я бы рекомендовал диагностами отбраковать даже предаварийные диски и убрать все партиции дисков.
Даже если диск пока жив — он будет снижать скорость за счет обхода битых секторов, по факту информация реплицируется только 1 раз — как зеркало и одновременный выход в момент ребильда еще какого то диска опасен. При отказе диска систем начинает интенсивно писать на все диски пула на всех нодах и не факт что битый диск получателя это переживет.
Arxitektor
01.08.2019 09:45Тоже возникла похожая задача.
По ней возник вопрос буду раз если сможет кто ответить.
Сервер Supermicro SuperServer SYS-2029U-E1CRTP на 24 диска.
Его планируется использовать как ноду в кластере под VSAN
На нем планируется сделать 4 дисковые группы по 5 SSD по 1.6 ТБ и 1 SSD NVME 800 ГБ
У сервера стоит Backplane BPN-SAS3-216EL1-N4 который позволяет сделать эту конфигурацию. У Backplane 1 Expander Daughter Card.
Вопрос можно ли к Expander Daughter Card подключить 2 HBA адаптера?
Для более полной утилизации пропускной способности SSD?Smilshu Автор
01.08.2019 09:552 HBA адаптера? Зачем, если не делать каскада то 1 контроллера 12G хватит за глаза
и кажетcя2-й разъем на Backplane как раз для каскада, а не второго HBA.
SuperServer SYS-2029U-E1CRTP позволяет еще больше губу раскатать на производительность за счет Intel® Optane™ DC Persistent Memory (процы 2-й генерации от 4215 и выше) вместо SSD NVME 800 ГБ.Но сетку нужно будет типа 25G и выше.
Но что то путное я лучше собрал бы не на supermicro :), дохнуть чаше чем бренды — я за 20 лет насмотрелся, дольше всех отжил Сименс — умер не физически, а морально(он сейчас фуджи), а российские на базе супермикро дохли постоянно -5 лет предел.
Arxitektor
01.08.2019 13:14Но что то путное я лучше собрал бы не на supermicro :)
Я бы тоже. Но такое ТЗ. )
Сетка будут 10G.
1 контроллера 12G хватит за глаза
А не упруться 4 дисковые группы с SSD дисками и SSD кешем в контроллер сидящий на pci-e 8x?.. Современным дискам pci-e 4x хватает но в упор.Smilshu Автор
01.08.2019 20:13при 10G что то много хотите массивов SSD — тогда уж 25G
Про кэш SSD для SSD томов не понял зачем, кэшируют обычно SAS HDD?
Про пропускную способность нужно уточнить какие массивы хотите, при HBA только RAID 1 или 0, про RAID контроллеры там можно и 5 и 50 и 6 и 60, но даже для организации более чем двух томов нужны контроллеры с памятью.
И так информация к размышлению:
По записи последовательной (от быстрых к медленным):
Intel® Optane™ DC Persistent Memory 3x от -> U.2 SSD 3000Mb-> SAS SSD 1000-2000MB ->SATA SSD 500Mb.
Если нужна скорость то можно вместо 4х SATA SSD — один SAS SSD
А если очень быстрое то Intel® Optane™ DC Persistent Memory, но процы должны быть gen2 от 4215 или 5222 ( но ПО Vmware EntPlus), для U.2 SSD Backplane другая чем SAS
Как вариант разных массивов при одном контроллере платы pci-exp то m.2 (правда большинство m2 DWPD <1) пойдут по другой шине чем контроллер.
Smilshu Автор
02.08.2019 07:59Кому интересно попробовать VxFlex_OS_3.0.0.1_134 4,29Gb
Документация
SupportMatrixoller
02.08.2019 13:30Думал, как бы попросить, а тут…
Спасибо огромное!!!Smilshu Автор
02.08.2019 14:27будет доступно для скачивания неделю, в качестве рекламы данного софта :)
3.0.0.1_134 еще не пробовал
2.0.1.4 который у меня в продакшене, выложу чуть позже.oller
02.08.2019 14:392.0 есть в свободном
ftp.ufanet.ru/pub/scaleio/Ubuntu/2.5.0.254/Ubuntu16.04
но документация и прочее — просто огромнейшее спасибо!!!
DmitriyTitov
Мне вспоминается аттракцион неслыханной щедрости от EMC, мол, ScaleIO можно качать бесплатно.
Я вроде его даже и скачал но упёрся в системные требования, которые были запредельны чтобы просто посмотреть.
Что-то изменилось, всё за деньги сейчас?
oller
Да изменилось
Теперь не просто за деньги, а за железки онли…
Есть пакеты в сливках, можно поставить, но все стремно
А в какие требования уперлись? В кол-во нод и дисков +10g?
Smilshu Автор
если хотите скорость (кучу кIOPS) то 10G обязательно, 1(2)Gb -хватит для режима RFCache.
К железу как раз не требовательно, для увеличения кол-ва нод подойдут бу сервера поколение 55-56xx стоимостью 20-30КР. Коммутаторы тоже простые Ethernet не FC.
Кроссплатформенность покрывает все варианты unix систем +MS +esx+xen
В том то и фишка что можно собрать из того что есть и вкладывать немного.
Но про это хотел рассказать во 2 части, если у людей бюджет интерес.
DmitriyTitov
Ну да, вроде в это, давно было дело.
А что сейчас есть из бесплатного? В последний раз я использовал какое-то свободное ПО от индусов, название которого уже не помню, но оно вполне прилично работало. Года три назад по нему были статьи на Хабре с хорошими отзывами.