
Всем привет, недавно мы писали о том, как учились быть Data Driven с Симулятором GoPractice! В этом выпуске продолжим тему анализа данных и поговорим о выстраивании процесса работы с аналитикой в команде Plesk.
Plesk — сложный продукт с 20-летним бэкграундом и эффективно собирать необходимую статистику мы умели не всегда. В течение долгого времени мы смотрели на данные только ретроспективно, а решения принимали на основе субъективных ощущений «как должно быть». В прошлом у нас уже были печальные последствия такого подхода, — в 2012 году мы поменяли дизайн, желая сделать как лучше, а получили волну негативного фидбека, отказ обновляться на последнюю версию продукта и отток клиентов.
Осмыслив этот печальный опыт, мы сделали выводы и приняли решение двигаться в сторону становления Data Driven company. На этом пути нас ждали трудности разного характера. Крупномасштабно их можно разделить на две основные группы – системные и процессные, и в этой статье я сфокусируюсь именно на задаче выстраивания процесса работы с аналитикой.

Системные проблемы, связанные со спецификой коробочного продукта, достойны отдельной статьи, поэтому подробно останавливаться на них здесь я не буду, лишь перечислю наиболее значительные.
О процессных болях поговорим более подробно. До недавнего времени процесс сбора аналитики у нас был полностью оторван от процесса разработки — про отслеживание и метрики вспоминали в конце, прикручивали одноразовое решение, и так до следующей фичи. Кроме того, за долгие годы в Plesk накопилась куча источников данных – что влекло за собой затраты на поддержание консистентности, актуальности данных, необходимость держать в голове, откуда что берется, по каким условиям попадает в базу и почему одни и те же метрики в разных местах отличаются (например, количество лицензионных ключей и физических инсталляций). В эти источники писалось много информации (ежемесячные срезы с базы в 270 тысяч ключей и прилетающие в два раза чаще репорты с 300 тысяч серверов), но работать с этими данными умели и находили время всего несколько человек. Я пришла в Plesk в 2015 году, и мои первые задачи были как раз связаны с вытаскиванием разнородных статистических данных из OLAP-куба и базы MongoDB. 'How To' к этой базе представляло собой страничку с логином и паролем от хоста и текстовым файликом с js-скриптом от последнего популярного запроса.
Куча источников подразумевала кучу инструментов и сервисов, каждым из которых должен уметь пользоваться каждый Program Manager. Ощущения в первые дни работы были примерно такими:

Что же мы сделали?
Решение было следующим: около полутора лет назад мы начали тотальную перестройку процесса сбора данных – теперь мы разрабатываем аналитику так же, как саму фичу, на каждом этапе задействована вся команда (фиче-crew), от ПМа и разраба до QA-инженера.
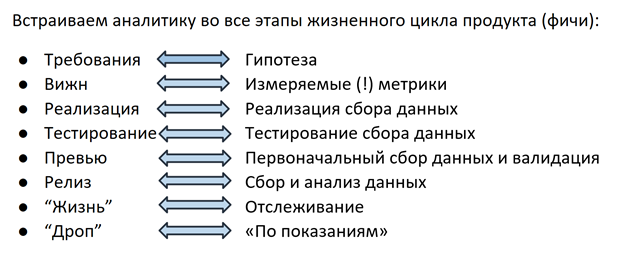
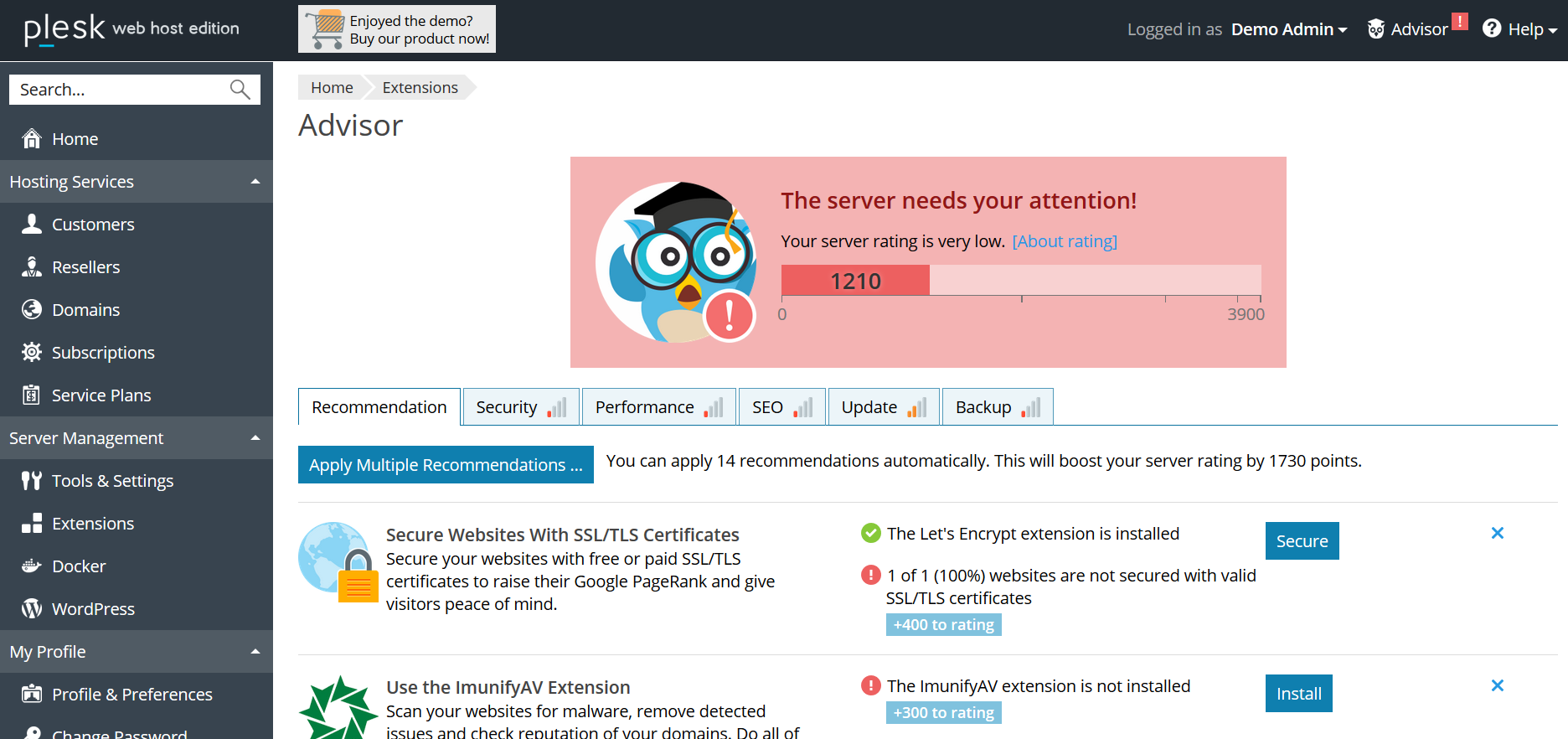
Всё начинается на этапе планирования фичи: ПМ формулирует гипотезу, на основе которой на следующем шаге будет выбираться метрика. Например: в Plesk есть система рекомендаций Advisor, помогающая пользователю улучшить состояние сервера, выполнив предложенные действия (добавить ssl-сертификат, включить обновления, обновить версию PHP и т.д.). Выпуская Advisor, мы предполагаем, что пользователь будет следовать рекомендациям, рейтинг «здоровья» сервера будет расти, а благодаря геймифицированным «ачивкам» пользователь будет вовлечен во взаимодействие с Advisor-ом на постоянной основе.
На следующем шаге для каждой гипотезы выбирается метрика: для Advisor-а это количество переходов по ссылкам в рекомендациях, процент сайтов, защищенных сертификатами, показатель рейтинга и т.д. Вся эта информация (гипотеза+метрики) заносится в вижн — документ с требованиями к фиче. На этом месте в процесс вовлекаются дата-аналитики — их задача помочь сделать метрику измеряемой, удобной для сбора и однозначной. Важны даже такие детали, как структура будущего поля в базе данных или отчёте — поскольку обращаться к этой информации чаще всех будет ответственный за фичу ПМ, в его интересах определить, как это удобнее сделать, вплоть до желаемой структуры запроса к базе. Благодаря такому подходу, кстати, всем стало легче еще и в том смысле, что необходимость лазить в 100500 источников значительно снизилась — теперь ты сам решаешь, в каком формате будут собираться данные и как тебе удобнее их доставать. Фиксируя логику подсчета в вижне, ПМ также получает возможность в любой момент вернуться к документу и вспомнить, по каким критериям происходит попадание в базу/увеличение счетика/факт отправки и т.д. Так решается проблема понимания логики отчетов.
Когда гипотеза сформулирована, а метрика выбрана, очередь за реализацией. Разработчики воплощают в жизнь одновременно саму фичу и механизм сбора ее статистики. Как уже говорилось, использование готовых решений подобных GA для нас по разным причинам затруднено, поэтому 2 года назад наши инженеры реализовали собственный механизм отслеживания действий пользователя в панели. Кроме действий пользователя, интерес могут представлять и разного рода технические детали, настройки конфигурации и т.д. — всё это отправляется в уже упомянутую базу MongoDB.
Как и любой продукт, механизм сбор данных должен быть протестирован — в нашем случае, QA инженер проверяет, что рекомендации показываются и открываются, рейтинг отслеживается, а в базу собирается информация обо всех этих событиях. Зачастую сценарии использования, выбранные для отслеживания и анализа, становятся новыми тест-кейсами для проверки функционирования самой фичи.
После того, как QA-инженер проверил все сценарии, ПМ вместе с разработчиком посмотрел на первые данные и убедился, что фича 1) ничего не сломала и 2) работает как ожидалось, а статистика собирает то, что его интересовало — всё готово к выпуску в релиз.
Когда фича запущена в релиз, начинается самое интересное — ее «жизнь» в продукте. Больше нет метаний: «вы случайно не знаете, какое поле у нас в базе хранит инфу о показе рекомендаций? никакое? блиин...». Дата-аналитик не получает сообщений в слак: «а можешь еще раз посчитать, сколько показов на последней версии?» — для этого есть графики на дашбордах с настроенными алертами, которые шлют письма, если отслеживаемое значение резко упало/возросло/поменялось/в базе не найдено записей. Но это еще не всё. Понимания, что счетчик вырос или упал на n%, не всегда достаточно для того, чтобы с уверенностью сказать, что это значимое изменение, а не сезонный скачок или колебание в пределах погрешности. Один из членов нашей команды занимается тем, что разрабатывает фреймворк для измерения статистической значимости изменения метрики. С помощью аппарата математической статистики он рассчитывает минимальную выборку (количество пользователей/инсталляций/событий), необходимую для оценки значимости изменений, выбирает сегменты, между которыми можно проводить сравнение и определяет доверительный интервал, с наиболее высокой вероятностью содержащий реальное значение интересующей нас метрики. Этот фреймворк уже был опробован и дал интересные результаты буквально на прошлой неделе: мы выяснили, что после того, как начали показывать цены в каталоге расширений внутри панели Plesk-a, люди стали реже покупать годовые и чаще – месячные лицензионные ключи для этих продуктов. Прямо сейчас наши коллеги рассчитывают прогноз LTV, после которого станет ясно, что несут для нас эти изменения в долгосрочной перспективе и какой вариант нам стоит продвигать в логике показа цен.
Итогом жизни любого продукта или фичи является прекращение ее поддержки в случае, когда это обусловлено невостребованностью или другими причинами (например, соображениями безопасности в случае прекращения поддержки устаревшей операционной системы или версии PHP). Здесь аналитика также приходит нам на помощь: например, когда мы приняли решение стимулировать пользователей к переходу на новые версии PHP, первым делом мы собрали статистику использования версий среди пользователей Plesk. Мы узнали, что процент использующих PHP 7 достигает всего 20% пользователей и поняли, что потенциальные издержки от принудительного переключения в виде миллионов сломавшихся сайтов перевешивают риски от возможных уязвимостей старых версий. В итоге мы приняли решение о более мягких мерах воздействия и начали с оповещения о желательности апгрейда в панели. Другим примером могут стать многочисленные истории с прекращением поддержки операционных систем — в случае, когда мы обнаруживали, что определенной ОС пользуется кто-то из крупных клиентов, имеющий десятки тысяч инсталляций Plesk, мы адресно коммуницировали с этим партнером и в случае невозможности быстрого перехода предлагали ему так называемый lazy drop — прекращение поддержки для новых инсталляций и возможность продолжать работу на имеющихся после апгрейда на последнюю версию Plesk-а.
Подводя итог, хочется еще раз озвучить то, что мы считаем самым важным — теперь работа с аналитикой для нас является неотъемлемой частью работы на каждой фичей. Но и выстроенный процесс — это еще не финал. На собственном опыте мы убедились, что не менее самого процесса важен контроль за качеством данных. Всё теряет смысл, если на любом из этапов сбора данные потерялись или были искажены. Чтобы этого не случилось, на каждом этапе мы стремимся добавить проверки на полноту и корректность данных, а также логируем каждый шаг обработки.

И последнее. Не стоит обвешиваться метриками просто потому, что вы можете :) четко формулируйте, для чего вам эта информация, а когда она получена – спросите себя, несет ли она вывод, ведущий к действию. Ведь понимание, что делать – это именно то, ради чего всё и было затеяно :)
Plesk — сложный продукт с 20-летним бэкграундом и эффективно собирать необходимую статистику мы умели не всегда. В течение долгого времени мы смотрели на данные только ретроспективно, а решения принимали на основе субъективных ощущений «как должно быть». В прошлом у нас уже были печальные последствия такого подхода, — в 2012 году мы поменяли дизайн, желая сделать как лучше, а получили волну негативного фидбека, отказ обновляться на последнюю версию продукта и отток клиентов.
Осмыслив этот печальный опыт, мы сделали выводы и приняли решение двигаться в сторону становления Data Driven company. На этом пути нас ждали трудности разного характера. Крупномасштабно их можно разделить на две основные группы – системные и процессные, и в этой статье я сфокусируюсь именно на задаче выстраивания процесса работы с аналитикой.
Системные проблемы, связанные со спецификой коробочного продукта, достойны отдельной статьи, поэтому подробно останавливаться на них здесь я не буду, лишь перечислю наиболее значительные.
- Много событий, большие объемы использования. Если мы говорим только об отслеживании действий пользователя в панели, по нашим подсчетам это 60m событий в месяц, а 150k$ за Advanced Google Analytics отдавать жалко. Другая сложность состоит в том, что для работы с GA необходимо каждое кастомное действие обрабатывать явно, мы же хотели получить унифицированный механизм, не требующий вручную размечать события или действия для каждой новой фичи.
- Из-за объемов и формата коробки (раскатка любых изменений занимает время) аналитику не получается сделать real-time. Пользователи сидят на 8 разных версиях продукта, причем 4 из них уже EOLed. Даже на последних версиях в первые две недели после выпуска новые изменения приезжают только к 60% пользователей.
- Сложный продукт. Plesk поддерживает 14 операционных систем семейства Linux, 4 OC Windows, 150 3rd-party компронент, несколько веб-серверов, мейл-серверов, вебмейл клиентов, визуализаторов статистики, антивирусных решений и тд. Большое количество возможных конфигураций влияет прежде всего на сложность и объемы тестирования и делает практически невозможным использование A/B тестов.
- B2B2C специфика. Лицо принимающее решение – не всегда равно «реальный пользователь панели».
- GDPR — необходимость соответствовать букве закона требует дополнительных усилий на анонимизацию данных и затрудняет задачи сегментации пользователей, а также лишает нас возможности легко и быстро связаться с клиентами, используя их контактные данные.
О процессных болях поговорим более подробно. До недавнего времени процесс сбора аналитики у нас был полностью оторван от процесса разработки — про отслеживание и метрики вспоминали в конце, прикручивали одноразовое решение, и так до следующей фичи. Кроме того, за долгие годы в Plesk накопилась куча источников данных – что влекло за собой затраты на поддержание консистентности, актуальности данных, необходимость держать в голове, откуда что берется, по каким условиям попадает в базу и почему одни и те же метрики в разных местах отличаются (например, количество лицензионных ключей и физических инсталляций). В эти источники писалось много информации (ежемесячные срезы с базы в 270 тысяч ключей и прилетающие в два раза чаще репорты с 300 тысяч серверов), но работать с этими данными умели и находили время всего несколько человек. Я пришла в Plesk в 2015 году, и мои первые задачи были как раз связаны с вытаскиванием разнородных статистических данных из OLAP-куба и базы MongoDB. 'How To' к этой базе представляло собой страничку с логином и паролем от хоста и текстовым файликом с js-скриптом от последнего популярного запроса.
Куча источников подразумевала кучу инструментов и сервисов, каждым из которых должен уметь пользоваться каждый Program Manager. Ощущения в первые дни работы были примерно такими:
Что же мы сделали?
Решение было следующим: около полутора лет назад мы начали тотальную перестройку процесса сбора данных – теперь мы разрабатываем аналитику так же, как саму фичу, на каждом этапе задействована вся команда (фиче-crew), от ПМа и разраба до QA-инженера.
Гипотеза
Всё начинается на этапе планирования фичи: ПМ формулирует гипотезу, на основе которой на следующем шаге будет выбираться метрика. Например: в Plesk есть система рекомендаций Advisor, помогающая пользователю улучшить состояние сервера, выполнив предложенные действия (добавить ssl-сертификат, включить обновления, обновить версию PHP и т.д.). Выпуская Advisor, мы предполагаем, что пользователь будет следовать рекомендациям, рейтинг «здоровья» сервера будет расти, а благодаря геймифицированным «ачивкам» пользователь будет вовлечен во взаимодействие с Advisor-ом на постоянной основе.
Метрика
На следующем шаге для каждой гипотезы выбирается метрика: для Advisor-а это количество переходов по ссылкам в рекомендациях, процент сайтов, защищенных сертификатами, показатель рейтинга и т.д. Вся эта информация (гипотеза+метрики) заносится в вижн — документ с требованиями к фиче. На этом месте в процесс вовлекаются дата-аналитики — их задача помочь сделать метрику измеряемой, удобной для сбора и однозначной. Важны даже такие детали, как структура будущего поля в базе данных или отчёте — поскольку обращаться к этой информации чаще всех будет ответственный за фичу ПМ, в его интересах определить, как это удобнее сделать, вплоть до желаемой структуры запроса к базе. Благодаря такому подходу, кстати, всем стало легче еще и в том смысле, что необходимость лазить в 100500 источников значительно снизилась — теперь ты сам решаешь, в каком формате будут собираться данные и как тебе удобнее их доставать. Фиксируя логику подсчета в вижне, ПМ также получает возможность в любой момент вернуться к документу и вспомнить, по каким критериям происходит попадание в базу/увеличение счетика/факт отправки и т.д. Так решается проблема понимания логики отчетов.
Реализация
Когда гипотеза сформулирована, а метрика выбрана, очередь за реализацией. Разработчики воплощают в жизнь одновременно саму фичу и механизм сбора ее статистики. Как уже говорилось, использование готовых решений подобных GA для нас по разным причинам затруднено, поэтому 2 года назад наши инженеры реализовали собственный механизм отслеживания действий пользователя в панели. Кроме действий пользователя, интерес могут представлять и разного рода технические детали, настройки конфигурации и т.д. — всё это отправляется в уже упомянутую базу MongoDB.
Тестирование и превью
Как и любой продукт, механизм сбор данных должен быть протестирован — в нашем случае, QA инженер проверяет, что рекомендации показываются и открываются, рейтинг отслеживается, а в базу собирается информация обо всех этих событиях. Зачастую сценарии использования, выбранные для отслеживания и анализа, становятся новыми тест-кейсами для проверки функционирования самой фичи.
После того, как QA-инженер проверил все сценарии, ПМ вместе с разработчиком посмотрел на первые данные и убедился, что фича 1) ничего не сломала и 2) работает как ожидалось, а статистика собирает то, что его интересовало — всё готово к выпуску в релиз.
Жизнь фичи
Когда фича запущена в релиз, начинается самое интересное — ее «жизнь» в продукте. Больше нет метаний: «вы случайно не знаете, какое поле у нас в базе хранит инфу о показе рекомендаций? никакое? блиин...». Дата-аналитик не получает сообщений в слак: «а можешь еще раз посчитать, сколько показов на последней версии?» — для этого есть графики на дашбордах с настроенными алертами, которые шлют письма, если отслеживаемое значение резко упало/возросло/поменялось/в базе не найдено записей. Но это еще не всё. Понимания, что счетчик вырос или упал на n%, не всегда достаточно для того, чтобы с уверенностью сказать, что это значимое изменение, а не сезонный скачок или колебание в пределах погрешности. Один из членов нашей команды занимается тем, что разрабатывает фреймворк для измерения статистической значимости изменения метрики. С помощью аппарата математической статистики он рассчитывает минимальную выборку (количество пользователей/инсталляций/событий), необходимую для оценки значимости изменений, выбирает сегменты, между которыми можно проводить сравнение и определяет доверительный интервал, с наиболее высокой вероятностью содержащий реальное значение интересующей нас метрики. Этот фреймворк уже был опробован и дал интересные результаты буквально на прошлой неделе: мы выяснили, что после того, как начали показывать цены в каталоге расширений внутри панели Plesk-a, люди стали реже покупать годовые и чаще – месячные лицензионные ключи для этих продуктов. Прямо сейчас наши коллеги рассчитывают прогноз LTV, после которого станет ясно, что несут для нас эти изменения в долгосрочной перспективе и какой вариант нам стоит продвигать в логике показа цен.
Прекращение поддержки
Итогом жизни любого продукта или фичи является прекращение ее поддержки в случае, когда это обусловлено невостребованностью или другими причинами (например, соображениями безопасности в случае прекращения поддержки устаревшей операционной системы или версии PHP). Здесь аналитика также приходит нам на помощь: например, когда мы приняли решение стимулировать пользователей к переходу на новые версии PHP, первым делом мы собрали статистику использования версий среди пользователей Plesk. Мы узнали, что процент использующих PHP 7 достигает всего 20% пользователей и поняли, что потенциальные издержки от принудительного переключения в виде миллионов сломавшихся сайтов перевешивают риски от возможных уязвимостей старых версий. В итоге мы приняли решение о более мягких мерах воздействия и начали с оповещения о желательности апгрейда в панели. Другим примером могут стать многочисленные истории с прекращением поддержки операционных систем — в случае, когда мы обнаруживали, что определенной ОС пользуется кто-то из крупных клиентов, имеющий десятки тысяч инсталляций Plesk, мы адресно коммуницировали с этим партнером и в случае невозможности быстрого перехода предлагали ему так называемый lazy drop — прекращение поддержки для новых инсталляций и возможность продолжать работу на имеющихся после апгрейда на последнюю версию Plesk-а.
Заключение
Подводя итог, хочется еще раз озвучить то, что мы считаем самым важным — теперь работа с аналитикой для нас является неотъемлемой частью работы на каждой фичей. Но и выстроенный процесс — это еще не финал. На собственном опыте мы убедились, что не менее самого процесса важен контроль за качеством данных. Всё теряет смысл, если на любом из этапов сбора данные потерялись или были искажены. Чтобы этого не случилось, на каждом этапе мы стремимся добавить проверки на полноту и корректность данных, а также логируем каждый шаг обработки.
И последнее. Не стоит обвешиваться метриками просто потому, что вы можете :) четко формулируйте, для чего вам эта информация, а когда она получена – спросите себя, несет ли она вывод, ведущий к действию. Ведь понимание, что делать – это именно то, ради чего всё и было затеяно :)