

Мое текущее понимание:
1) KVM
KVM (Kernel-based Virtual Machine) – гипервизор (VMM – Virtual Machine Manager), работающий в виде модуля на ОС Linux. Гипервизор нужен для того, чтобы запускать некий софт в несуществующей (виртуальной) среде и при этом, скрывать от этого софта реальное физическое железо, на котором этот софт работает. Гипервизор работает в роли «прокладки» между физическим железом (хостом) и виртуальной ОС (гостем).
Поскольку KVM является стандартным модулем ядра Linux, он получает от ядра все положенные ништяки (работа с памятью, планировщик и пр.). А соответственно, в конечном итоге, все эти преимущества достаются и гостям (т.к. гости работают на гипервизоре, которые работает на/в ядре ОС Linux).
KVM очень быстрый, но его самого по себе недостаточно для запуска виртуальной ОС, т.к. для этого нужна эмуляция I/O. Для I/O (процессор, диски, сеть, видео, PCI, USB, серийные порты и т.д.) KVM использует QEMU.
2) QEMU
QEMU (Quick Emulator) – эмулятор различных устройств, который позволяет запускать операционные системы, предназначенные под одну архитектуру, на другой (например, ARM –> x86). Кроме процессора, QEMU эмулирует различные периферийные устройства: сетевые карты, HDD, видео карты, PCI, USB и пр.
Работает это так:
Инструкции/бинарный код (например, ARM) конвертируются в промежуточный платформонезависимый код при помощи конвертера TCG (Tiny Code Generator) и затем этот платформонезависимый бинарный код конвертируется уже в целевые инструкции/код (например, x86).
ARM –> промежуточный_код –> x86
По сути, вы можете запускать виртуальные машины на QEMU на любом хосте, даже со старыми моделями процессоров, не поддерживающими Intel VT-x (Intel Virtualization Technology) / AMD SVM (AMD Secure Virtual Machine). Однако в таком случае, это будет работать весьма медленно, в связи с тем, что исполняемый бинарный код нужно перекомпилировать на лету два раза, при помощи TCG (TCG – это Just-in-Time compiler).
Т.е. сам по себе QEMU мега крутой, но работает очень медленно.
3) Protection rings
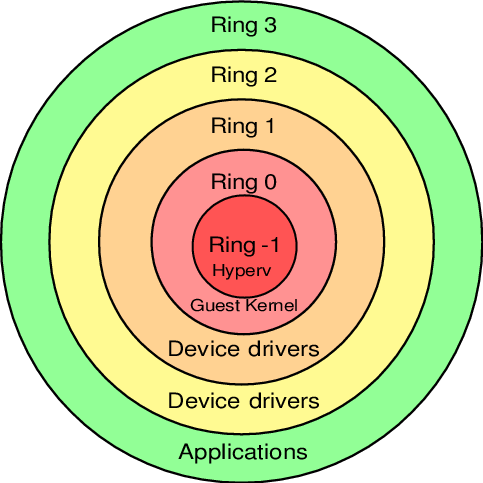
Бинарный программный код на процессорах работает не просто так, а располагается на разных уровнях (кольцах / Protection rings) с разными уровнями доступа к данным, от самого привилегированного (Ring 0), до самого ограниченного, зарегулированного и «с закрученными гайками» (Ring 3).
Операционная система (ядро ОС) работает на Ring 0 (kernel mode) и может делать с любыми данными и устройствами все, что угодно. Пользовательские приложения работают на уровне Ring 3 (user mode) и не в праве делать все, что захотят, а вместо этого каждый раз должны запрашивать доступ на проведение той или иной операции (таким образом, пользовательские приложения имеют доступ только к собственным данным и не могут «влезть» в «чужую песочницу»). Ring 1 и 2 предназначены для использования драйверами.
До изобретения Intel VT-x / AMD SVM, гипервизоры работали на Ring 0, а гости работали на Ring 1. Поскольку у Ring 1 недостаточно прав для нормального функционирования ОС, то при каждом привилегированном вызове от гостевой системы, гипервизору приходилось на лету модифицировать этот вызов и выполнять его на Ring 0 (примерно так, как это делает QEMU). Т.е. гостевой бинарный код НЕ выполнялся напрямую на процессоре, а каждый раз на лету проходил несколько промежуточных модификаций.
Накладные расходы были существенными и это было большой проблемой и тогда производители процессоров, независимо друг от друга, выпустили расширенный набор инструкций (Intel VT-x / AMD SVM), позволяющих выполнять код гостевых ОС НАПРЯМУЮ на процессоре хоста (минуя всякие затратные промежуточные этапы, как это было раньше).
С появлением Intel VT-x / AMD SVM, был создан специальный новый уровень Ring -1 (минус один). И теперь на нем работает гипервизор, а гости работают на Ring 0 и получают привилегированный доступ к CPU.
Т.е. в итоге:
- хост работает на Ring 0
- гости работают на Ring 0
- гипервизор работает на Ring -1
4) QEMU-KVM
KVM предоставляет доступ гостям к Ring 0 и использует QEMU для эмуляции I/O (процессор, диски, сеть, видео, PCI, USB, серийные порты и т.д., которые «видят» и с которыми работают гости).
Отсюда QEMU-KVM (или KVM-QEMU) :)
CREDITS
Картинка для привлечения внимания
Картинка Protection rings
P.S. Текст этой статьи изначально был опубликован в Telegram канале @RU_Voip в качестве ответа на вопрос одного из участников канала.
Напишите в комментариях, в каких местах я не правильно понимаю тему или если есть, что дополнить.
Спасибо!
Комментарии (8)

Lirein
07.09.2019 08:09Ещё забыли упомянуть, что фактически любая ОС после запуска гипервизора становится гостем, в «правляющем дмене». Интересен так же порядок загрузки кипервизора, используемые инструкции процессора для перехода в ring-1, маскировка ввода-вывода, таблицы трансляции, обработка прерываний уровня гипервизора. Больше хардкора в ядре KVM (игра слов).

AllexIn
07.09.2019 20:36KVM это божественно.
Не могу себе представить нормальное существование без него.

Cryptosoft
07.09.2019 21:18-3Напишите в комментариях, в каких местах я не правильно понимаю тему или если есть, что дополнить.
Уважаемый автор. Ваше понимание принципов работы гипервизора неправильное почти полностью. Трудно написать, где вы ошибаетесь, поскольку для этого придётся написать новую статью.vladislav_starkov Автор
07.09.2019 21:42+1Напишите пожалуйста обоснованно и внятно, с чем конкретно Вы не согласны по тексту статьи и что хотели бы добавить.
Cryptosoft
07.09.2019 23:531. В 64-разрядном режиме современных процессоров нет 4 колец защиты. Есть только System и User. 32-разрядный режим стремительно уходит в прошлое, поэтому кольца защиты это прошлый век.
2. Внутри виртуальной машины полностью воссоздаются те же самые режимы System и User. (либо Ring0 + Ring3 в 32-разрядном режиме). То есть на рисунке это должно выглядеть не в виде колец, а как два рисунка в виде двух вселенных, соединённых чёрными дырами VMEXIT-ов и VMRESUME-ов.
3. Ring -1 это такое больше «поэтическое» сравнение для гипервизора, чтобы как-то объяснить на пальцах его преимущественное право обработки аппаратных прерываний с непосредственным VMEXIT.
4. При выключенном EPT гипервизор строит таблицу трансляции виртуальных адресов ВМ в физические адреса хоста и ловит обращения к памяти виртуальных устройств по #PF. При включенном EPT гипервизор строит таблицу трансляции физических адресов ВМ в физические адреса хоста и ловит обращения к памяти виртуальных устройств по EPT Violation. Далее идёт эмуляция в текущем режиме работы гипервизора, коим является режим System (Ring0 для 32-разрядных систем). Если тут же рядышком крутится ядро хостовой интерактивной ОС, то такой гипервизор называется II-типа. Если же всё работает через SR-IOV, которым управляет гипервизор, то драйверы таких устройств можно погрузить в начальную ВМ, как это делает Hyper-V и KVM и это называется гипервизором I-типа, что резко увеличивает требования к аппаратуре.
5,6,7,8 итд рассказывать просто лень, сорри.rogoz
08.09.2019 03:331. В 64-разрядном режиме современных процессоров нет 4 колец защиты. Есть только System и User. 32-разрядный режим стремительно уходит в прошлое, поэтому кольца защиты это прошлый век.
Вынужден пошатнуть вашу уверенностьIn IA-32e mode, the CS descriptor’s DPL is used for execution privilege checks (as in legacy 32-bit mode)
© Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C & 3D):System Programming Guide

Cryptosoft
08.09.2019 23:52Да, только вот базового адреса и предела нет. А без них ценность DPL уходит полностью. При отсутствующей сегментации невозможно в одном адресном пространстве создать градации привилегий, кроме как через таблицы страниц.
Но вообще пример прикольный! Я про этот DPL забыл напрочь.
Cenzo
Хорошая вводная шпаргалка получилась, но "маловато будет" :) Раскрывайте тему, как эмулируются аппаратные устройства, как работает паравиртуализация на KVM, устройства virtio-net, -blk, -balloon. Проброс реальных устройств с помощью IO-MMU. Получится замечательная серия.