
— Практически каждый день ко мне лично и к нашим разработчикам приходят с вопросами. А где достать сборку? А где взять такую-то ветку? А почему что-то упало? Где в моем коде проблема? Почему что-то работает неправильно? Для этого у нас в проекте есть много самописной инфраструктуры, плагинов, различных хаков и трюков, которые мы используем. С одной стороны — чтобы облегчить жизнь разработчика, с другой — чтобы реализовать конкретные бизнес-задачи.
И в какой-то момент у нас, конечно, используется в том числе и CI, и TeamCity. Мы заморочились — научили дружить TeamCity с Kotlin и вывели, можно сказать, весь CI и всю сборку на принципиально новый уровень.
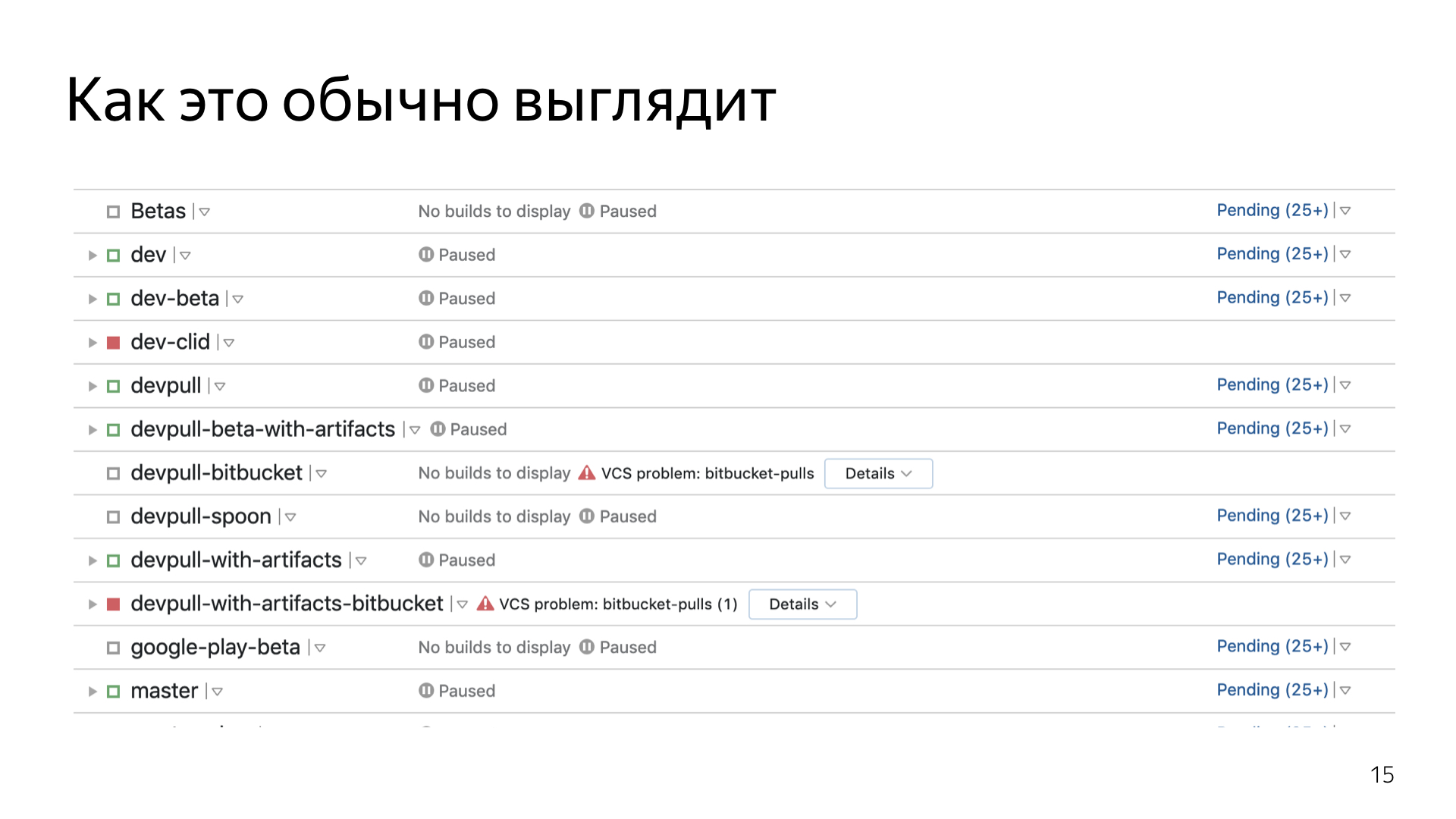
Но сначала немножко истории — чтобы понять, как мы к этому пришли и почему такой уровень я называю отдельным каноном. TeamCity в Яндексе существует уже много лет. Нам приходилось жить в этом общем сервере, где хостится весь бэкенд, весь фронтенд и, с недавнего времени, все мобильные приложения. Года два назад мы все съехались. И каждый разработчик настраивает каждый проект даже не как хочет, а как может или насколько понимает, насколько хочет разбираться в системе. И нет какого-то одного человека, который все знает и умеет. Мало кто хочет заморачиваться, изучать отдельно шаблоны, дебри TeamCity. Поэтому каждый пилит, кто во что горазд.
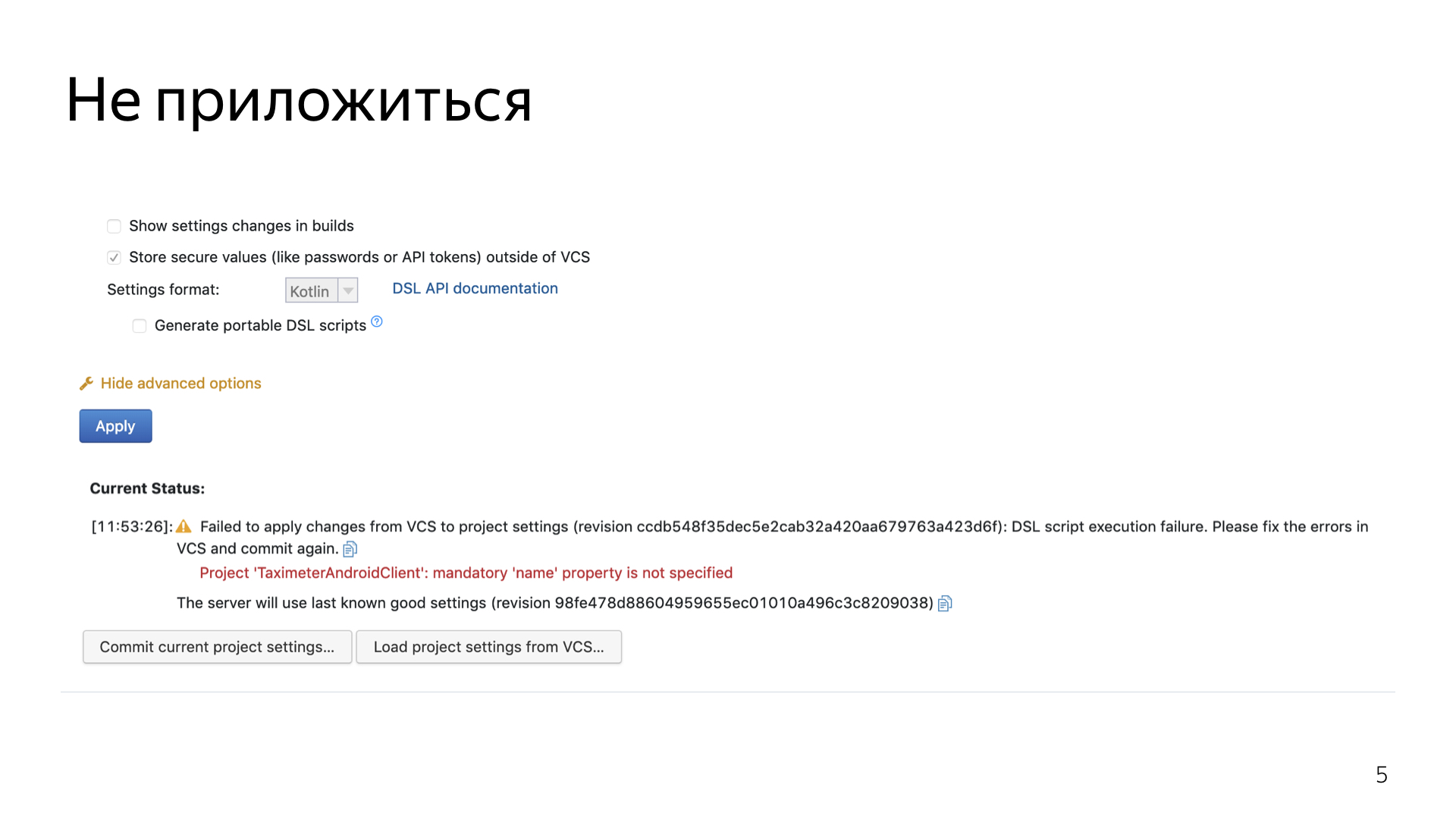
Мы жили в этом едином сервере, и в прошлом году у нас на TeamCity произошла авария. Около недели был полный простой. Сборки не собирались, тестирование постоянно жаловалось. Кто-то исхитрялся, собирал локально.
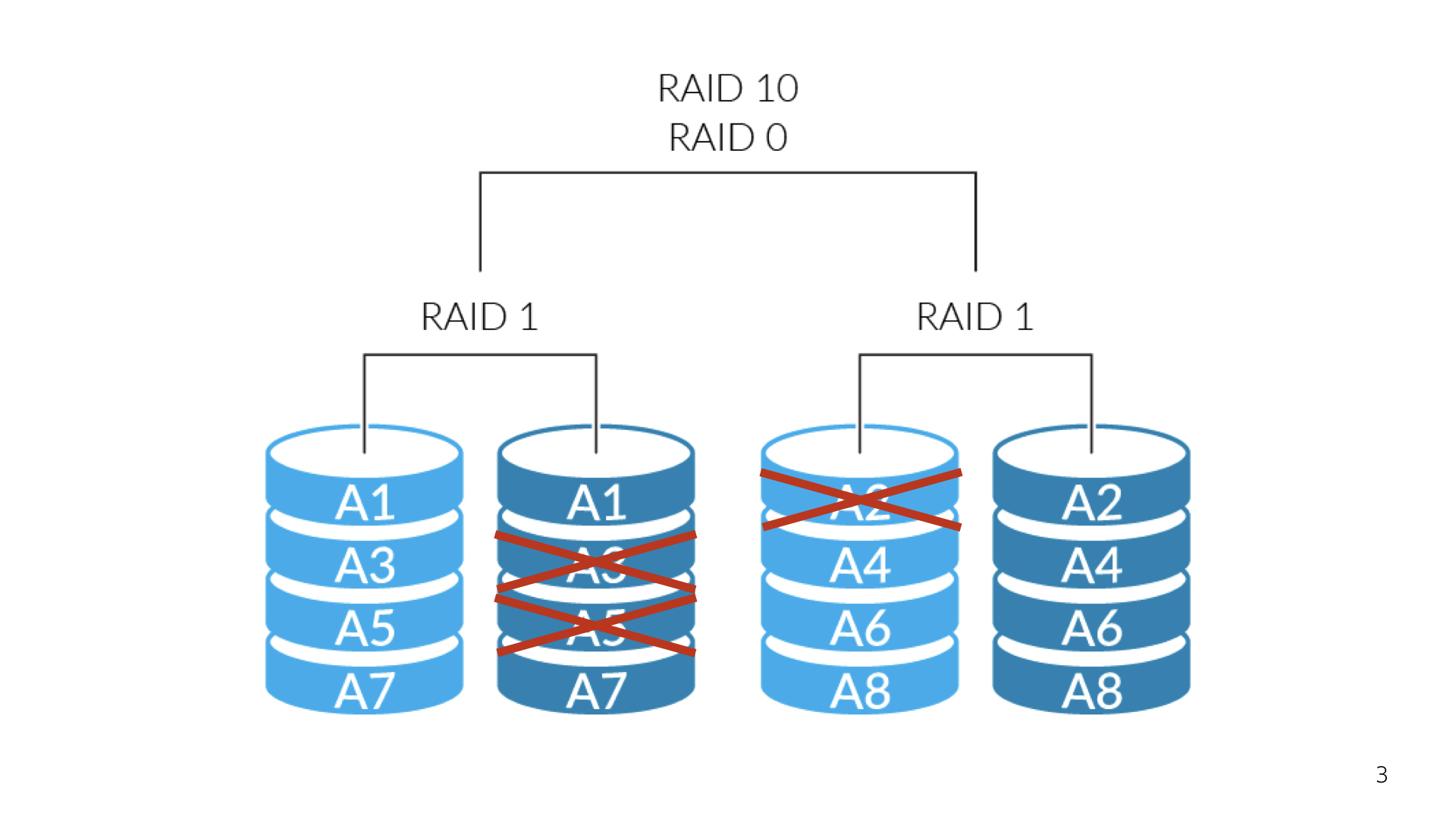
Всё из-за того, что наш TeamCity-сервер был, грубо говоря, наколеночным решением, которое внезапно выросло в большой сервис. Им пользуются тысячи разработчиков в Яндексе. Конечно же, там была какая-никакая отказоустойчивость, но она тоже отказала. При очередном обновлении TeamCity после рестарта обнаружилось, что несколько жестких дисков просто развалилось, и подняться заново мы уже не смогли. Пришлось выкручиваться.
Нужно делать выводы из всего, что произошло. И мы эти выводы, конечно, сделали: проанализировали, почему так случилось и как убедиться, что такого не произойдет снова.
В первую очередь важно то, что мы очень долго поднимались, восстанавливали наш сервис. Под сервисом я имею в виду как технический процесс, так и отчасти бизнес-процесс по банальной доставке релизов, по сборке пул-реквестов. Мы потеряли очень много артефактов, включая релизные сборки, потеряли очень много времени на пул-реквестах, на том, что тестирование не могло нормально заниматься своими делами. И конечно, мы потратили довольно много времени на то, чтобы восстановить проект с нуля, настроить заново всю структуру, всю систему сборки. И тогда мы поняли, что пора что-то менять и настроить свой собственный сервер.
Шли мы к этому долго. Не сказать, что только одна авария привела к этому выводу. В общем, мы решили, что пора идти к горе, делать всё это дело самим. Мы начали развертку сервиса. Это делается крайне быстро: пару дней и готово. Когда все это разворачиваешь уже сам и можешь покопаться во внутрянке, поадминить немножко, то бросаются в глаза интересные особенности. Одна из них — новый TeamCity позволяет настроить версионирование.
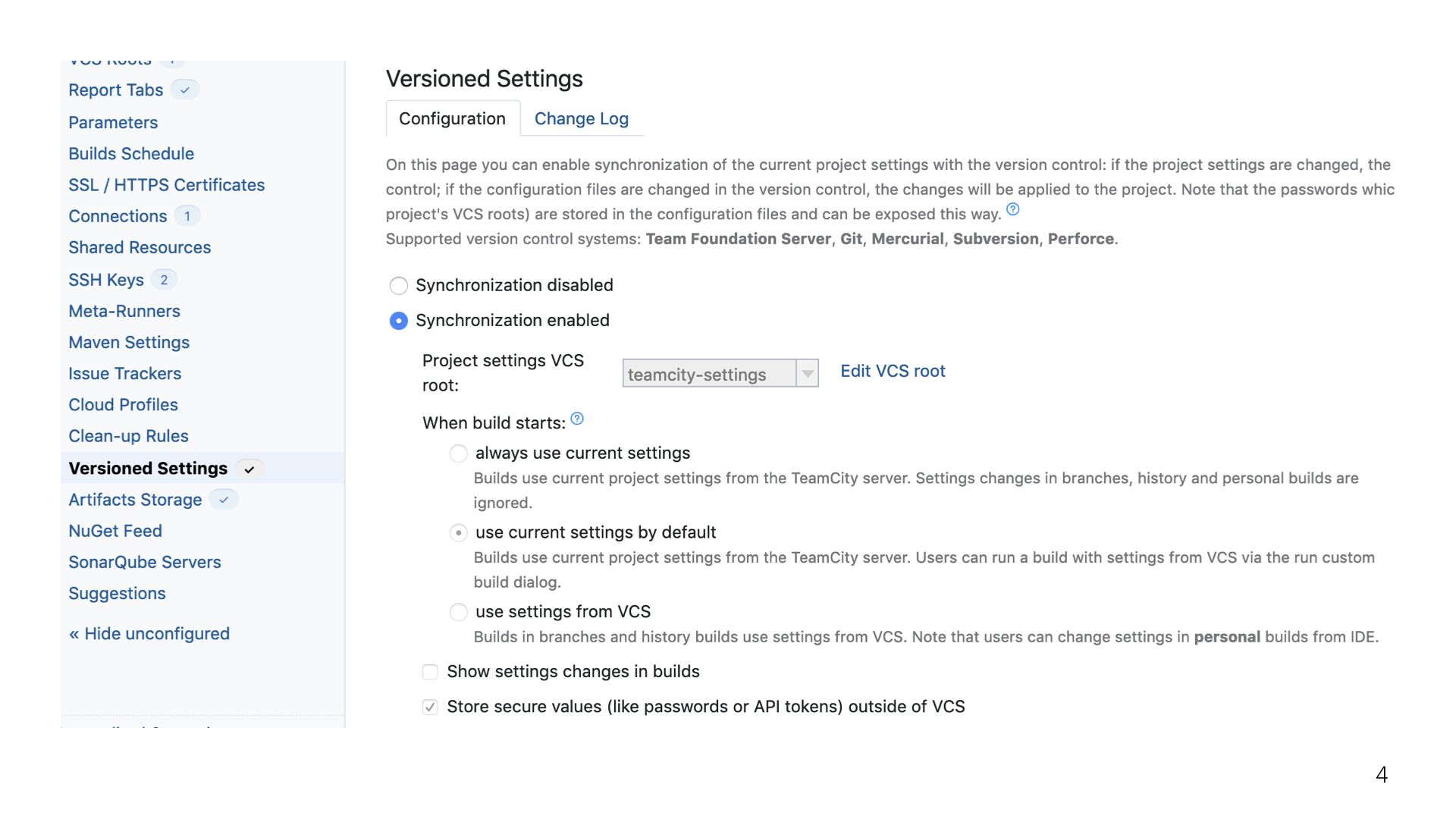
Версионирование налажено очень примитивно, но в то же время очень надежно, красиво и круто. Все, что хранится в TeamCity касательно вашего или любого другого проекта, можно спокойно отгрузить в Git, и сча?стливо жить на этом. Но есть пара проблем.
Первая проблема — все люди привыкли работать с TeamCity исключительно через интерфейс, и эту привычку тяжело искоренить. Здесь есть маленький лайфхак: можно просто запретить любые изменения из интерфейса и заставить всех людей переучиваться. В нашей команде 2000 разработчиков. Не очень хороший путь, правда?
На самом деле, на этом минусы заканчиваются. Самый главный минус — людям приходится переучиваться на что-то новое. А значит, им нужно дать почву для того, чтобы сделать личный вывод о том, зачем это вообще нужно. А нужно это затем, что TeamCity благодаря версионированию не позволяет применить изменения, которые так или иначе ломают систему. TeamCity сам фоллбэчит на последнюю стабильную ревизию.
В TeamCity можно каждый проект завести под это версионирование и настроить его достаточно гибко.
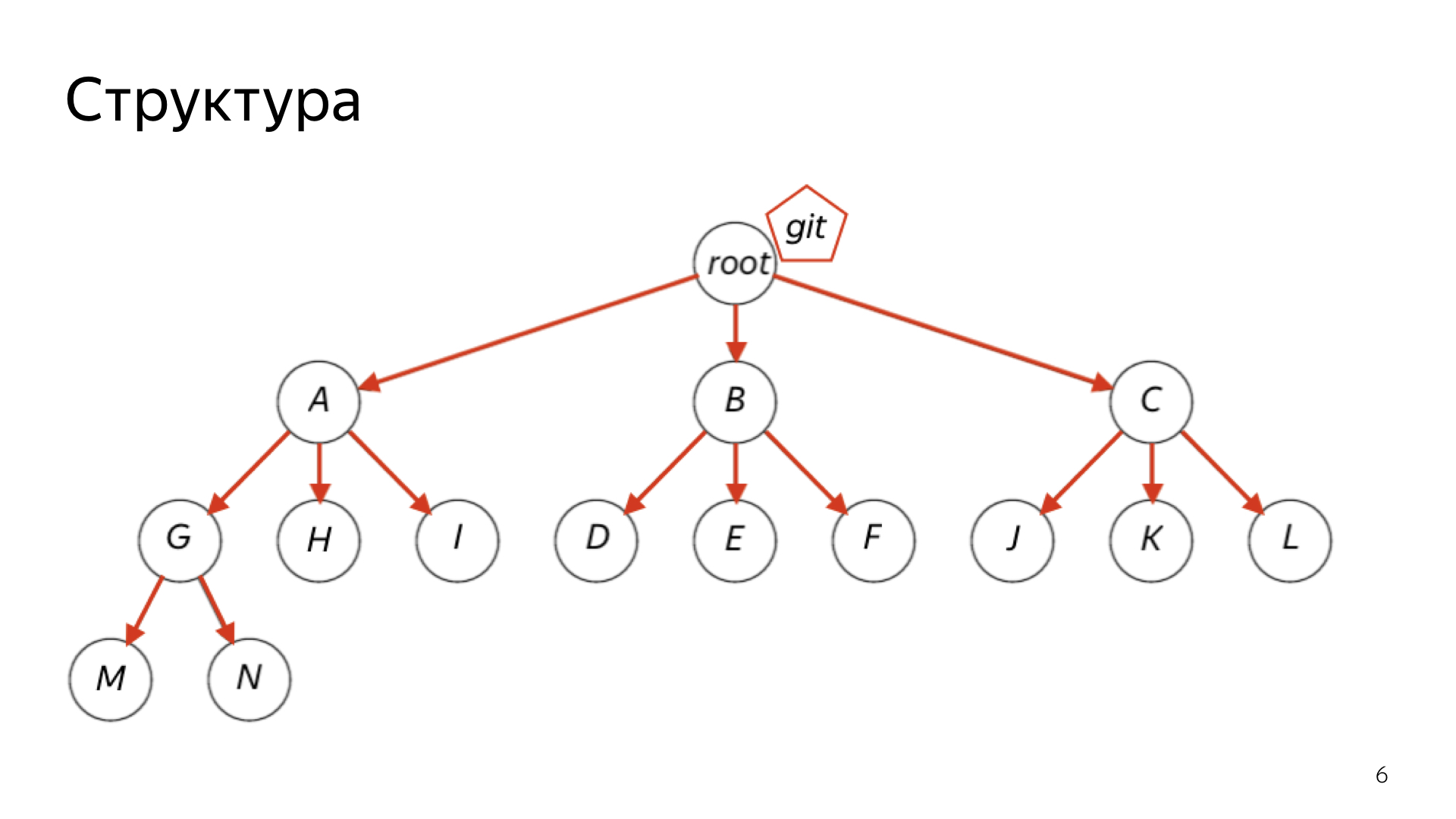
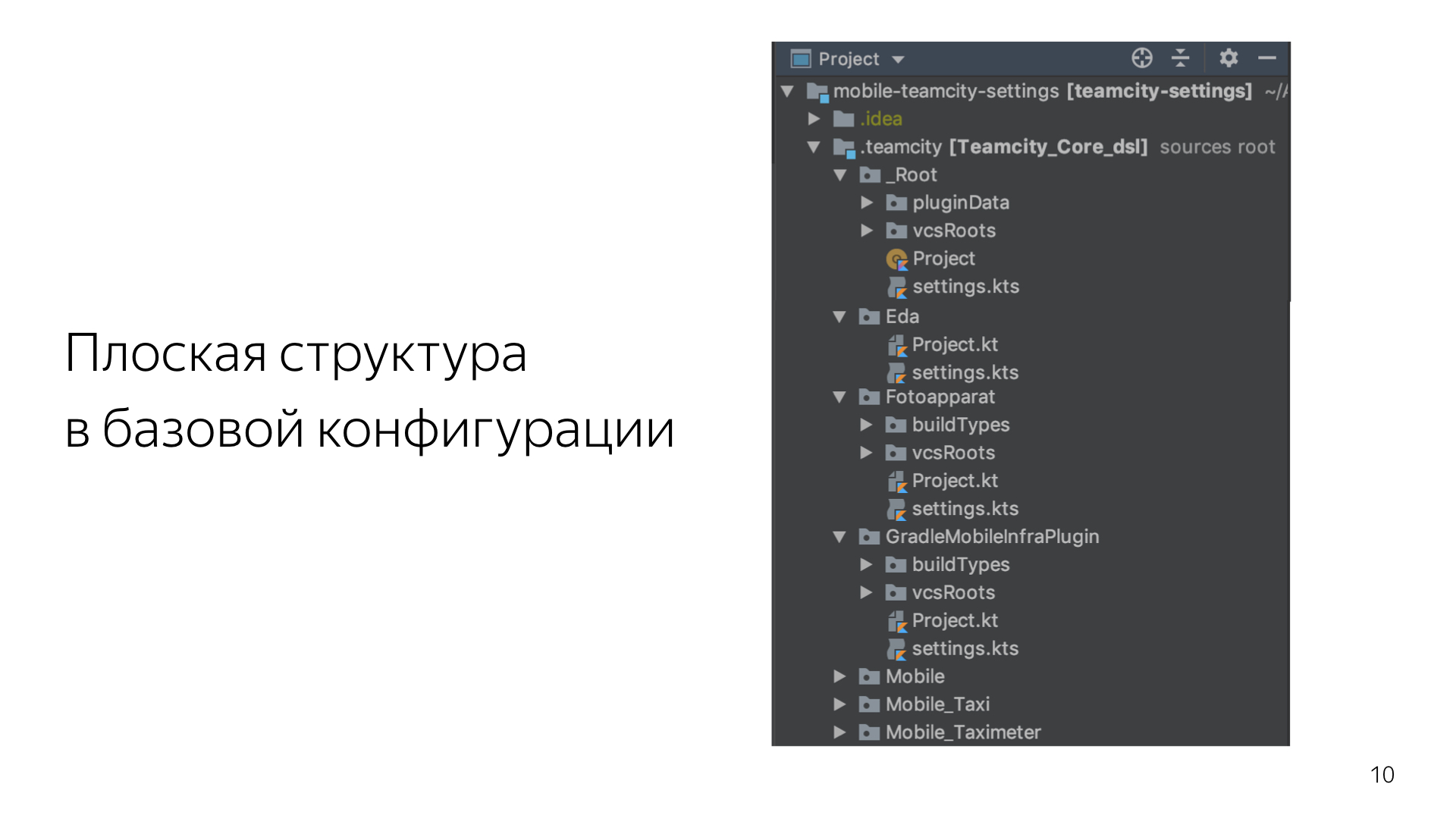
Чуть-чуть ликбеза. Все проекты в TeamCity устроены в виде дерева. Есть некий общий root, и дальше от него идет такая простая структура. Каждый проект — вершина этого графа. Он может выступать как неким набором конфигураций, которые что-то билдят, так и родителем для других проектов.
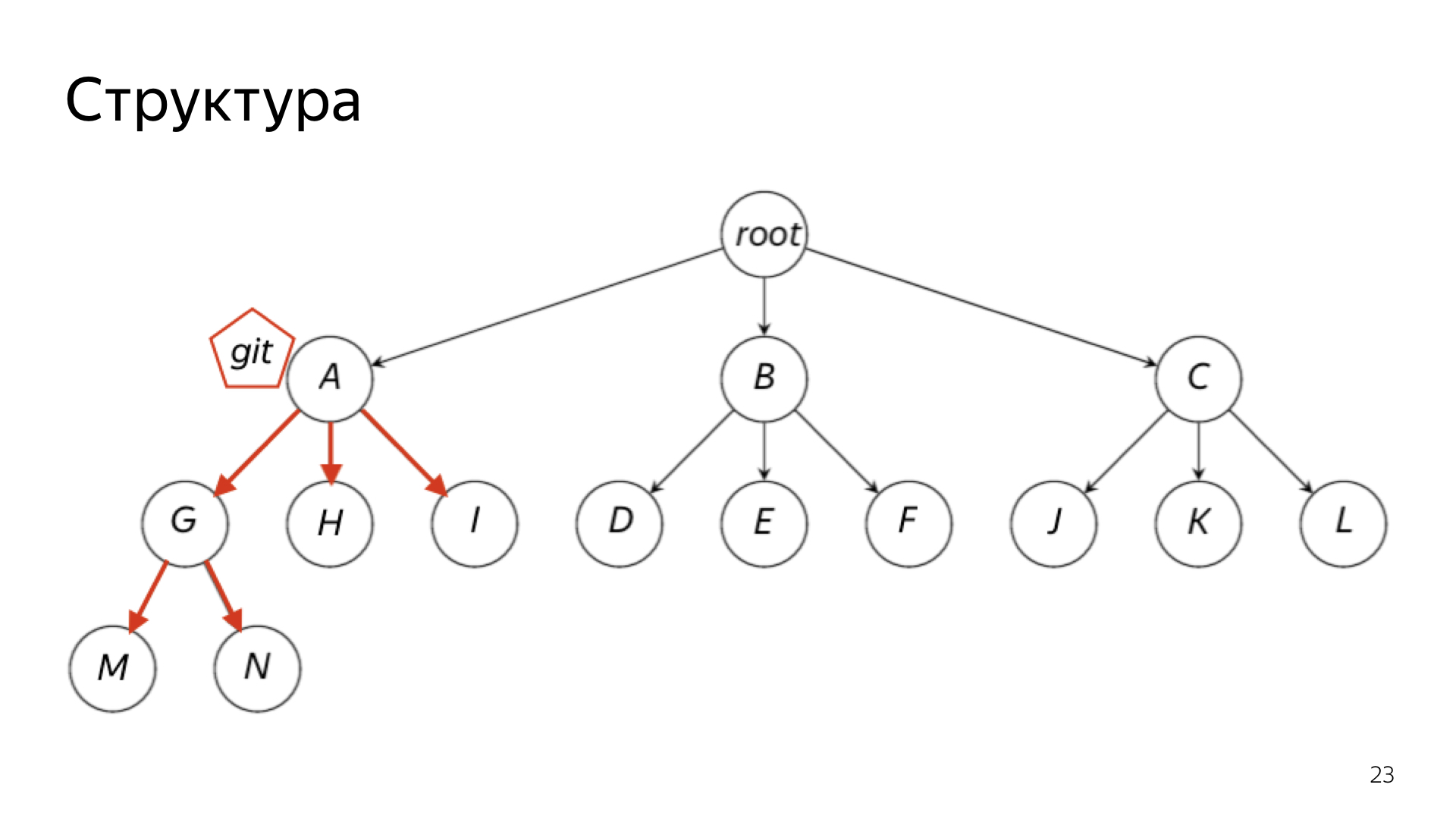
В Git можно отгрузить либо всё сразу, либо конкретный кусочек. Например, если коллеги из бэкенда с фронтендом не хотят пользоваться версионированием — пожалуйста, на них можно не рассчитывать, и просто обезопасить свой личный проект.
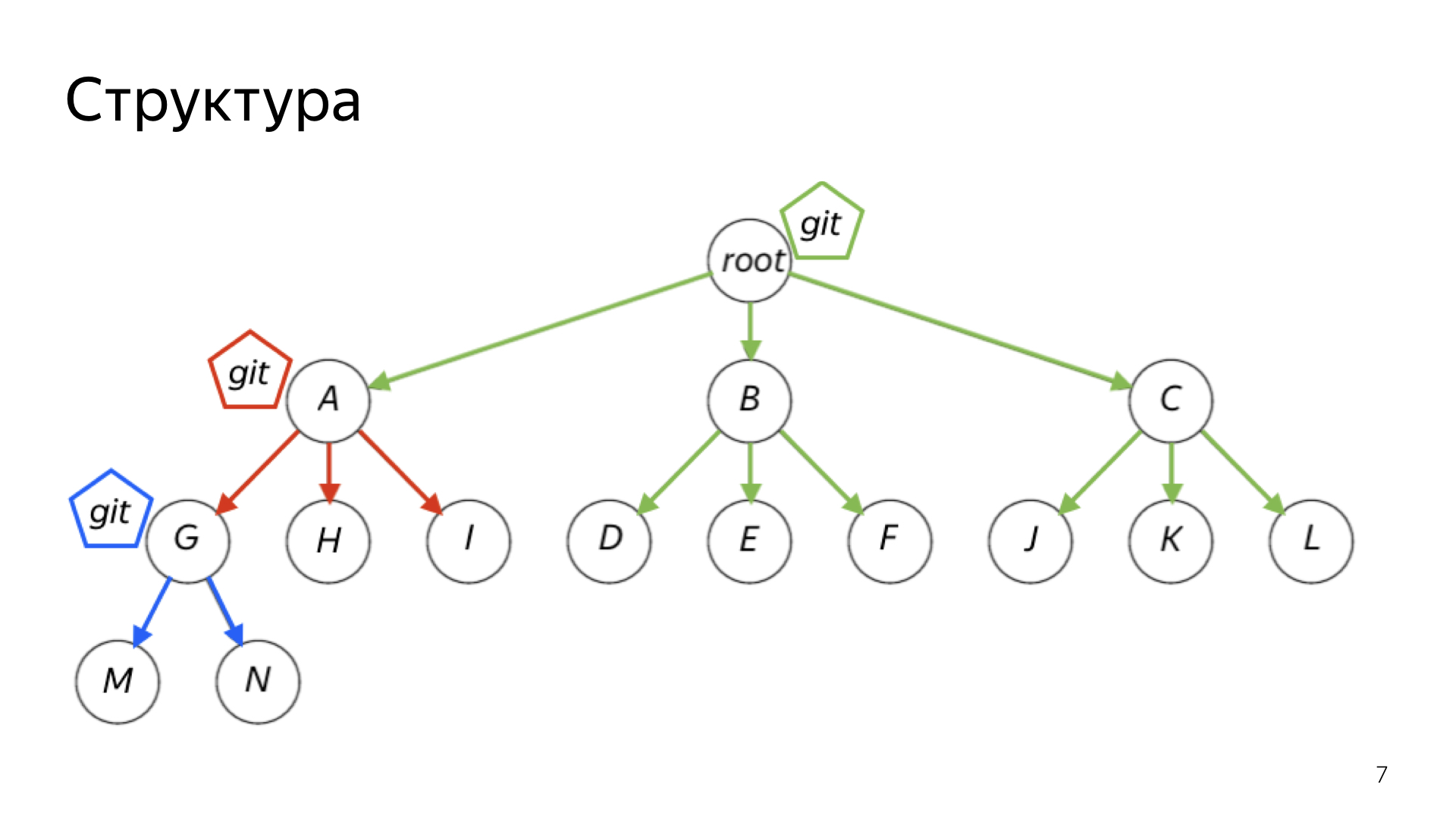
Можно настроить довольно сложную иерархическую систему, к которой в итоге пришла наша команда. У нас есть один общий большой root и несколько маленьких roots. Бэкенд, мобильная разработка, фронтенд, Яндекс.Еда — они все живут каждый в своем отдельном репозитории. В то же время информация о всех этих проектах хранится в большом общем репозитории — в корневом.
После того, как это версионирование наконец подключаешь, устаканиваешь со всеми коллегами, где кто и как будет жить, кто будет заниматься поддержкой, — после всего этого приходится сделать сложный выбор.

TeamCity поддерживает всего два формата конфигов. С XML, я подозреваю, никто работать не захочет, поэтому мы выбрали второй формат. Он позволяет сделать эти конфиги на Kotlin-скрипте.

ТeamCity создает maven-проект, некоторое подобие любого обычного проекта. С ним можно сделать одно из двух: либо загрузить в свой проект — Android, бэкенд, неважно, — либо оставить standalone-проектом. Тогда у вас будет независимый репозиторий с независимым проектом.
В чем плюс такого подхода? Лично меня и тех ребят, которые занимаются у нас инфраструктурой на бэкенде и фронтенде, кое-что подкупило сразу. И даже те, кто не знаком с Kotlin, кто услышал о нем впервые, пошли и начали его учить.
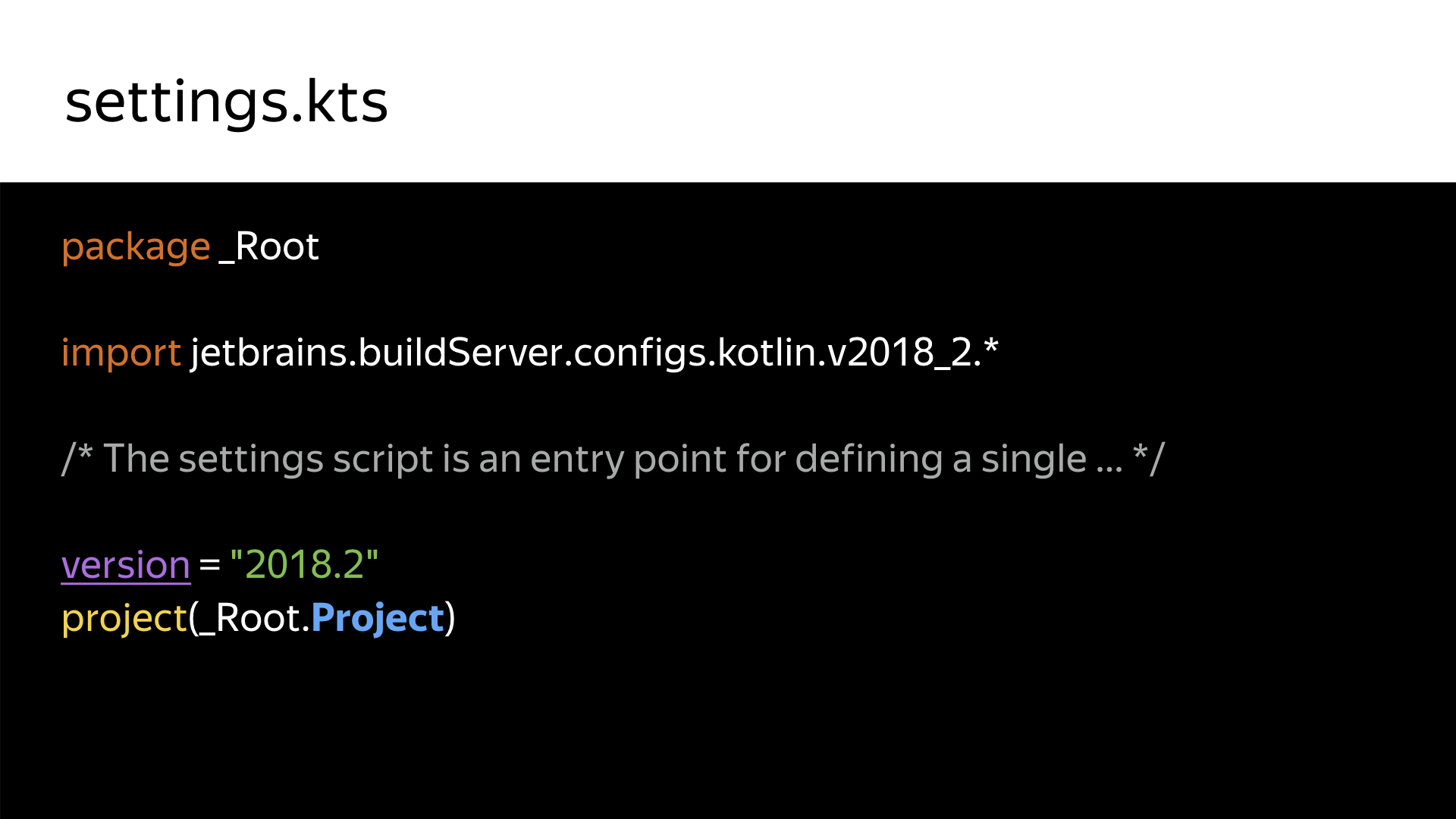
Эти две строчки создают весь проект. Здесь указывается диалект API TeamCity. API меняется каждую мажорную версию. Есть 2018-2, 2018-1, 2017 и т. д. Скоро, надеюсь, выйдет 2019-й.
Вторая строчка просто декларирует проект.

Вот сам проект. Это абсолютно реальный код. Именно так сейчас выглядит наш корневой репозиторий. Ничего лишнего, ничего сложного. Единственная ручная работа, которая здесь потребуется — это создать самому вручную UUID. TeamCity требует, чтобы каждый объект, каждый проект имел свой уникальный идентификатор. Написать туда можно что угодно. Я просто пользуюсь стандартной никсовой командой uuidgen.
Здесь начинаются приключения в Kotlin DSL. Думаю, это совершенно несложный для освоения язык. Загрузив его в IDEA, в Eclipse или в любой другой IDE, можно получить всю документацию, highlighting, autocomplete, подсказки. На самом деле, многих из них не хватает в интерфейсе. Поэтому лично мой опыт говорит, что работать с кодом гораздо удобнее, проще и интуитивнее. Мы же все-таки разработчики.

Примерно так выглядит настоящий существующий сейчас и работающий в это самое время конфиг, поддерживающий сами конфиги TeamCity. То есть TeamCity билдит свои собственные конфиги в своем собственном окружении. Если все хорошо и все сбилдилось, он это спокойно отгружает in memory и реплицирует изменения в PostgreSQL. База коннектится уже в сам сервис. И здесь будет грешно не использовать все возможности Kotlin.

В данном случае, в отличие от XML, эти конфиги можно описать с использованием полиморфизма, наследования — разрешены любые фичи языка Kotlin. Единственный важный момент — все это в итоге может превратиться в хаос, который существовал у нас до того, как мы ввели версионирование конфигов на Kotlin-скрипте.
Но, как ни странно, такого хаоса стало гораздо меньше. Потому что раньше было не совсем очевидно, как сделать то, что я хочу, как добиться той или иной фичи? Из кода, на моей практике, гораздо проще понять, как реализовать какую-либо фичу.
Здесь начинаются самые интересные приключения: а как мы реализовываем какие-то вещи и как в принципе сделать взаимодействие проекта с TeamCity проще?
Все здесь присутствующие в том или ином виде готовят релиз, участвуют в его сборке, в публикации. Мы публикуем свои релизы в разные каналы в Google Play.
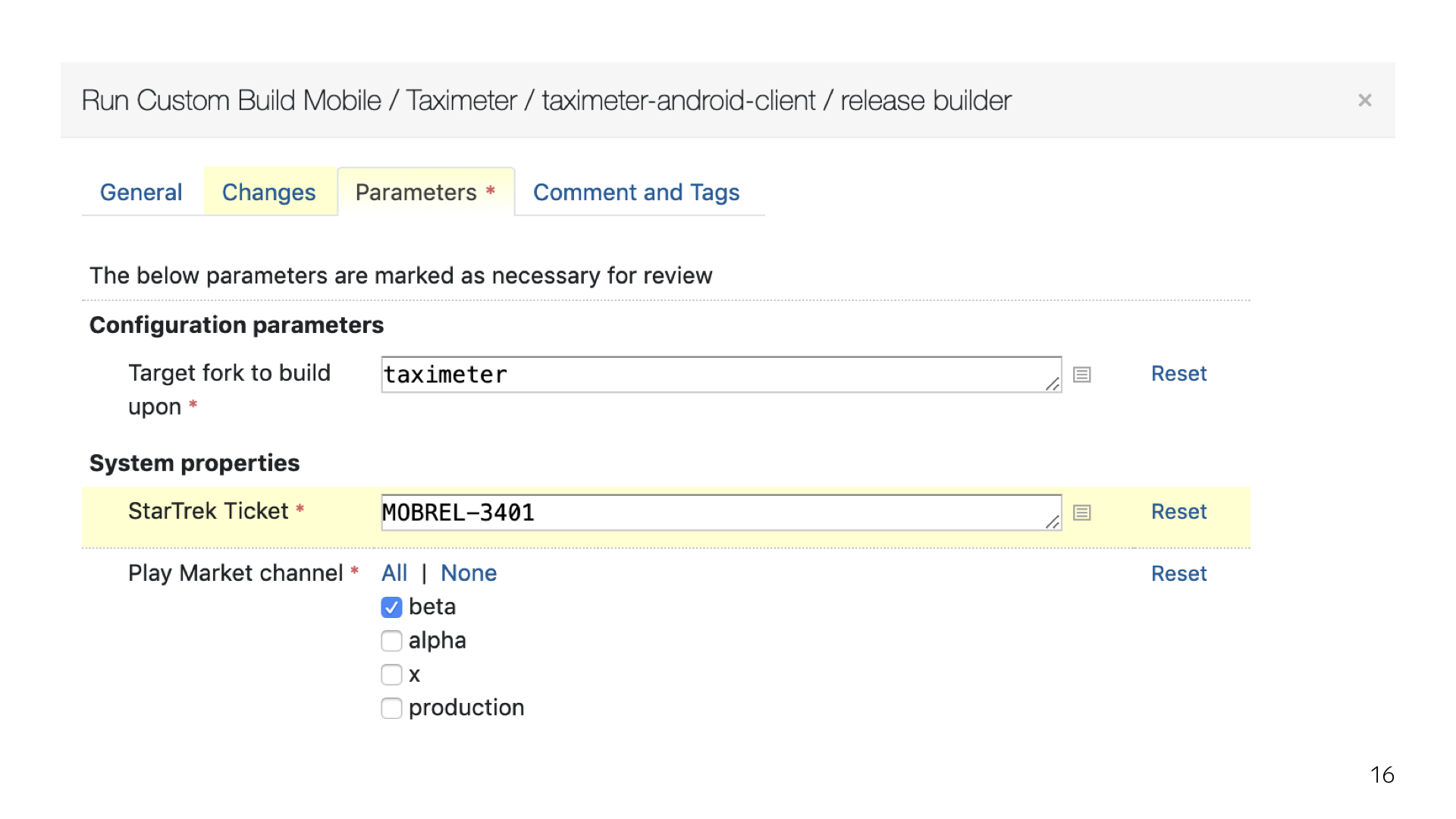
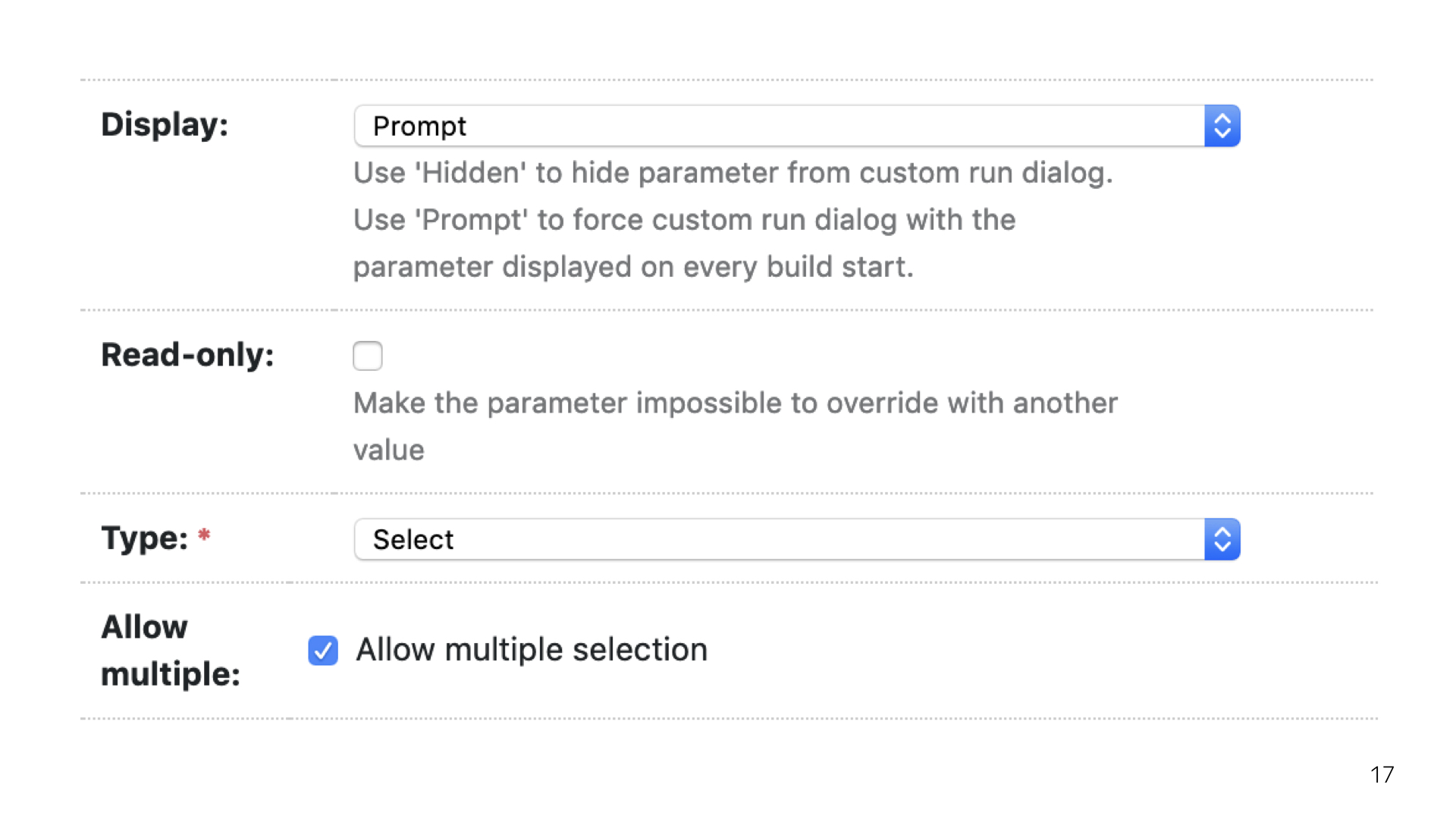
У нас есть бета, есть эксперименты, есть stable. У нас используется специальный плагин с роботом, который постит комментарии с отчетом о релизной сборке в релизный тикет. И все это настраивается таким красивым окошком. Оно появляется, как только ты пытаешься собрать релиз. От этих вопросов никуда не уйти.
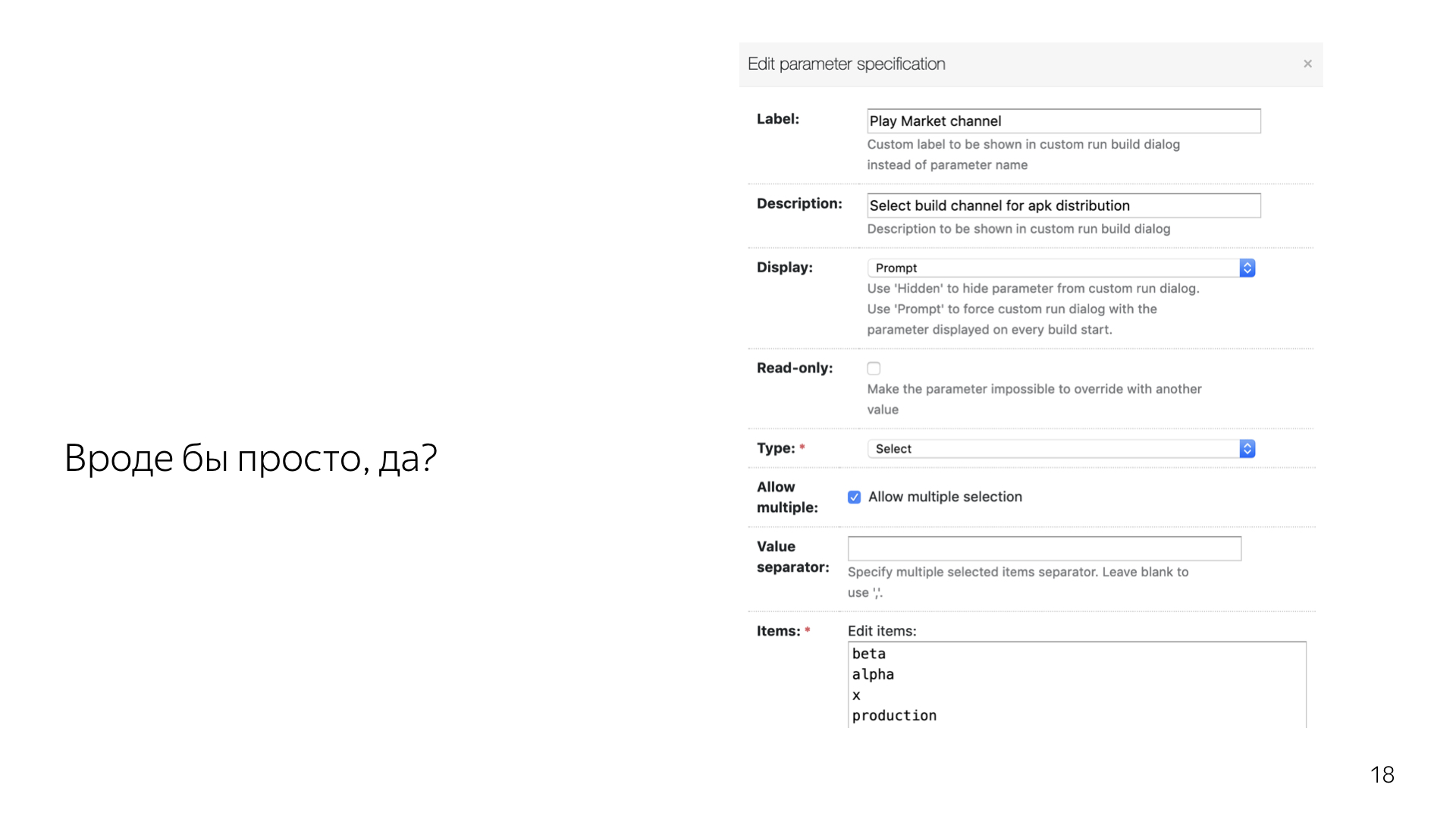
Из интерфейса TeamCity это выглядит примерно так. Чтобы сходу понять, что, где, куда и как, нужно вчитываться в каждый параметр, нужно экспериментировать. Из документации, кроме того, что видно на экране, больше ничего не почерпнуть.

В коде это выглядит так. По крайней мере до сих пор, за полгода, еще никто не пришел и не спросил — а как мне сделать какую-то фичу? Чаще всего из кода это все интуитивно понятно.
В то же время некоторые вещи сделаны довольно просто, но спрятаны за несколькими слоями интерфейса. Приходится погулять, походить туда-сюда.
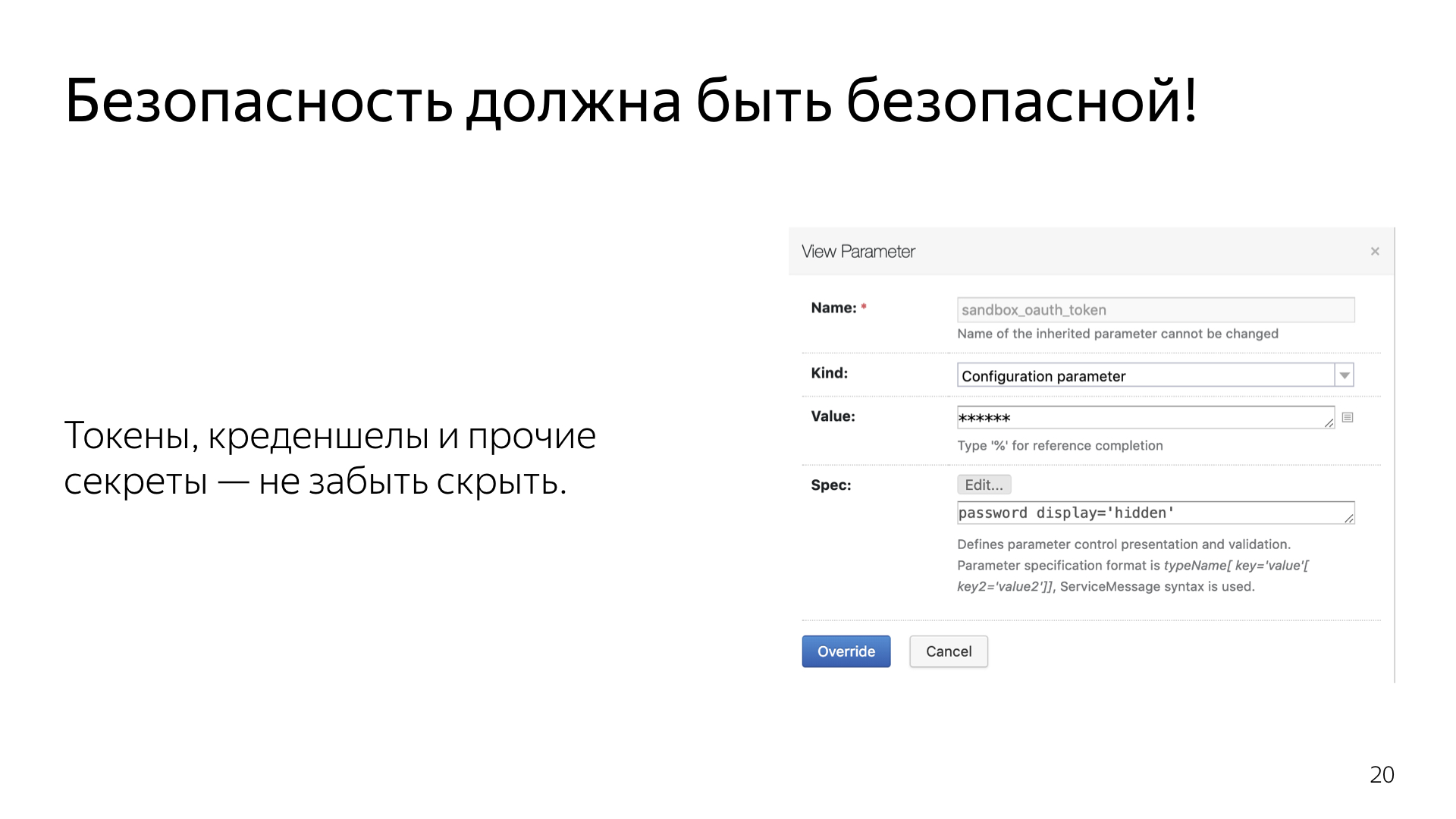
Вот пример, как в TeamCity реализовывается security. На моей практике, TeamCity у большинства людей представляется достаточно простой холодной системой, которая из коробки не поддерживает интеграцию, например, с сервисами безопасности. Поэтому все токены, все ключи, все credentials у нас чаще всего торчали наружу в открытом виде. Почему бы и нет?
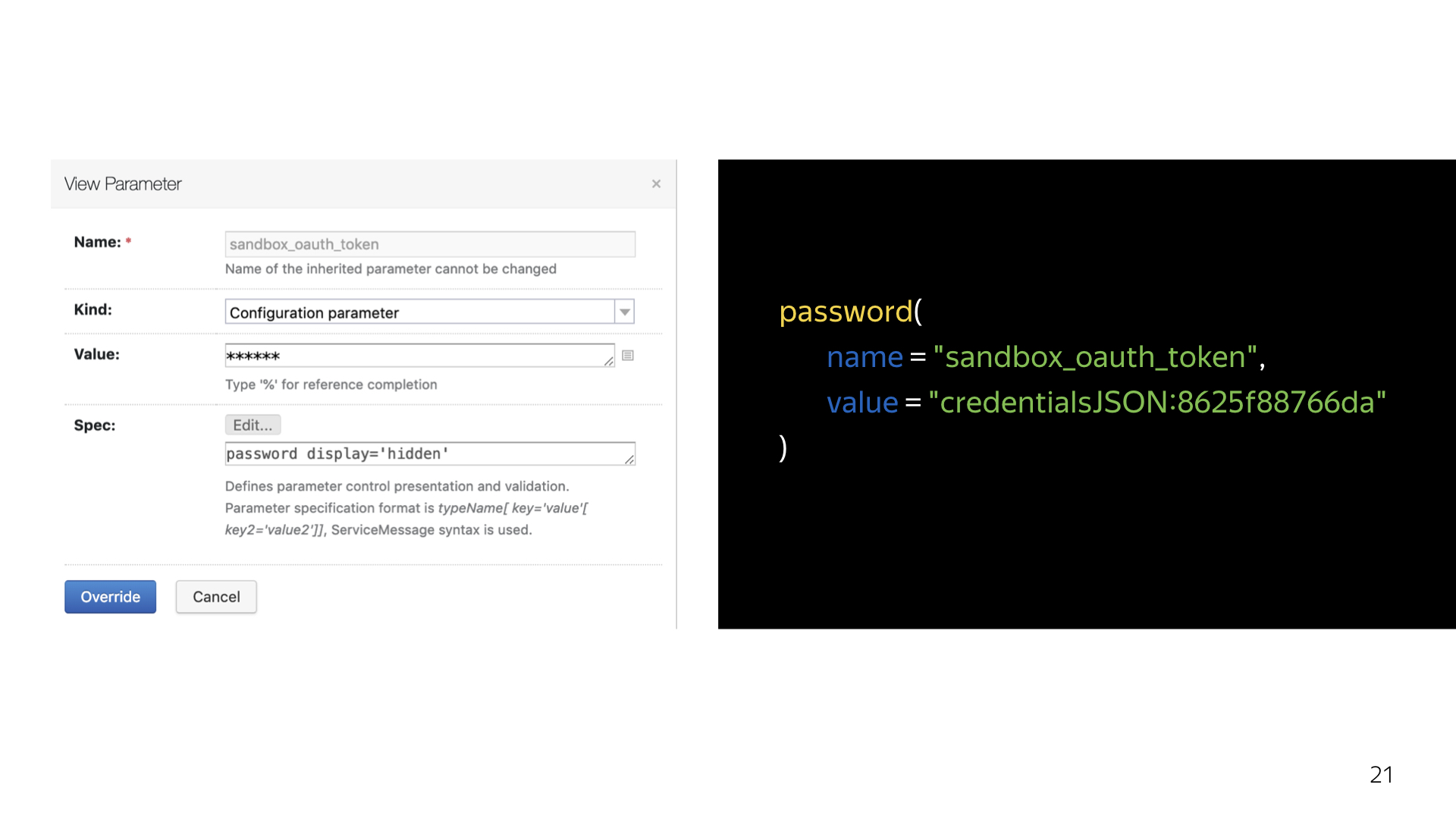
На самом деле, TeamCity умеет в безопасность. Он умеет создавать на своем сервере собственный специальный файлик, который так и называется — credential json, как показано. И он создает для каждого токена, для каждого credential, который мы специальным образом генерируем через интерфейс, такой ключик. Его уже можно положить в код и быть уверенным, что этот credential никогда не всплывет наружу ни в логах TeamCity, ни в интерфейсе TeamCity. Система умеет вырезать эти ключи буквально отовсюду. Весь интерфейс проходит, грубо говоря, некое декорирование.
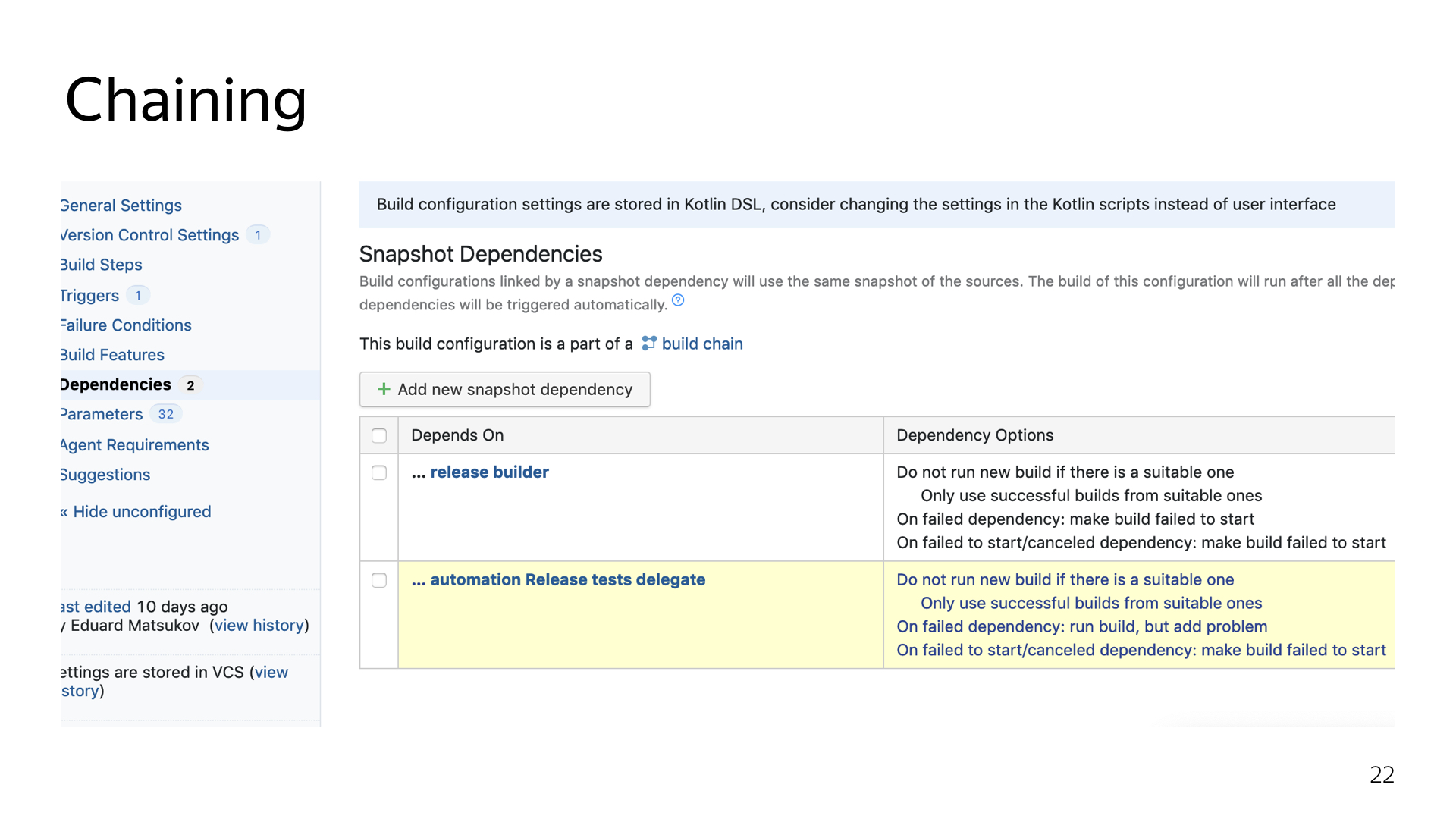
Окей, мы настроили какие-то свои параметры, сделали проброс обязательных параметров, допустим, для сборки релиза. Но что если мы хотим пойти дальше? А мы хотели пойти дальше. У нас при сборке запускается очень много разных steps. Мы запускаем несколько вложенных библиотек, которые билдятся из совершенно других репозиториев. И мы хотели подтягивать просто свежие изменения. Всё, что есть сейчас. Не заморачиваться — например, не собирать для пул-реквестов вспомогательную библиотеку, не заливать ее в maven-репозиторий, не внесить дополнительные телодвижения в пул-реквест.
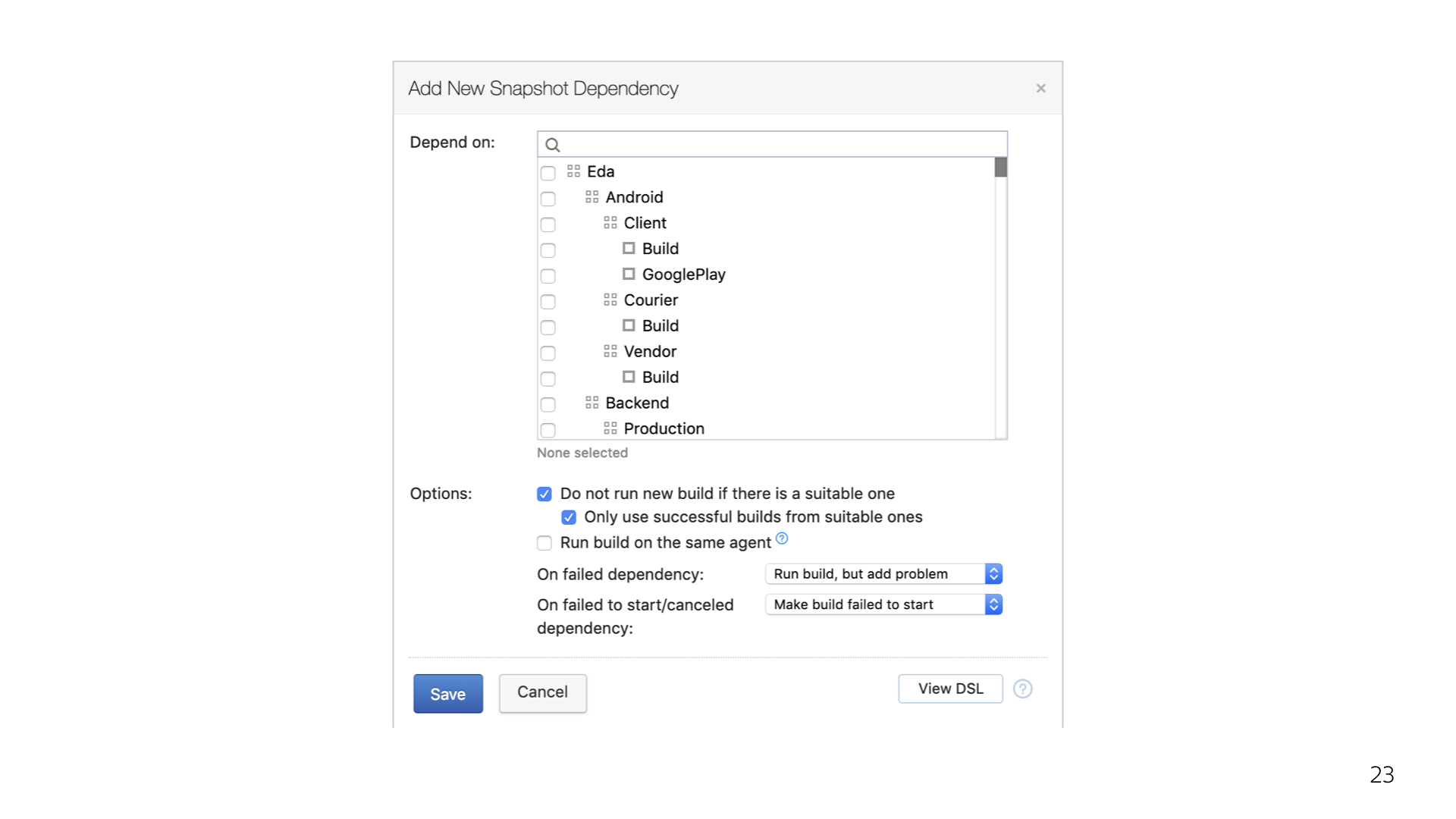
Мы просто настроили chain-сборку. Я буду до конца показывать, насколько неочевидно и неудобно это делать из интерфейса, на мой личный взгляд. А там уже сами судите.
Примерно так выглядит chain-сборка в интерфейсе.

Примерно так она выглядит в коде. Простоуказываем, какая именно конфигурация является зависимой и что делать, если какая-то из конфигураций не отработала либо была отменена пользователем снаружи. В данном случае я не хочу, чтобы сборка вообще стартовала. Потому что какой в ней смысл, если мы не собрали все зависимые библиотеки?
Примерно в таком же духе делаются и все остальные вещи. И весь проект в TeamCity занимает буквально 500 строк кода.

Оказывается, можно и пробросить какой-нибудь интересный параметр через все зависимости. Я показал chaining не просто так. Сhains — это удобно, но их тяжело готовить в интерфейсе. И TeamCity не документирует такую важную особенность, как пробрасывание сквозных параметров. Для чего это нужно? Допустим, в нашей сборке в Gradle или еще где-то мы хотим завязаться на какое-нибудь специфическое поле, пробросить тот же адрес на релизный тикет. И хотим сделать это один раз, а не для каждой вложенной сборки.

У TeamCity есть не совсем очевидный и совершенно не документированный параметр — reverse.dep (reverse dependency). Он пробрасывает во все вложенные билды все эти параметры, которые идут после звездочки.
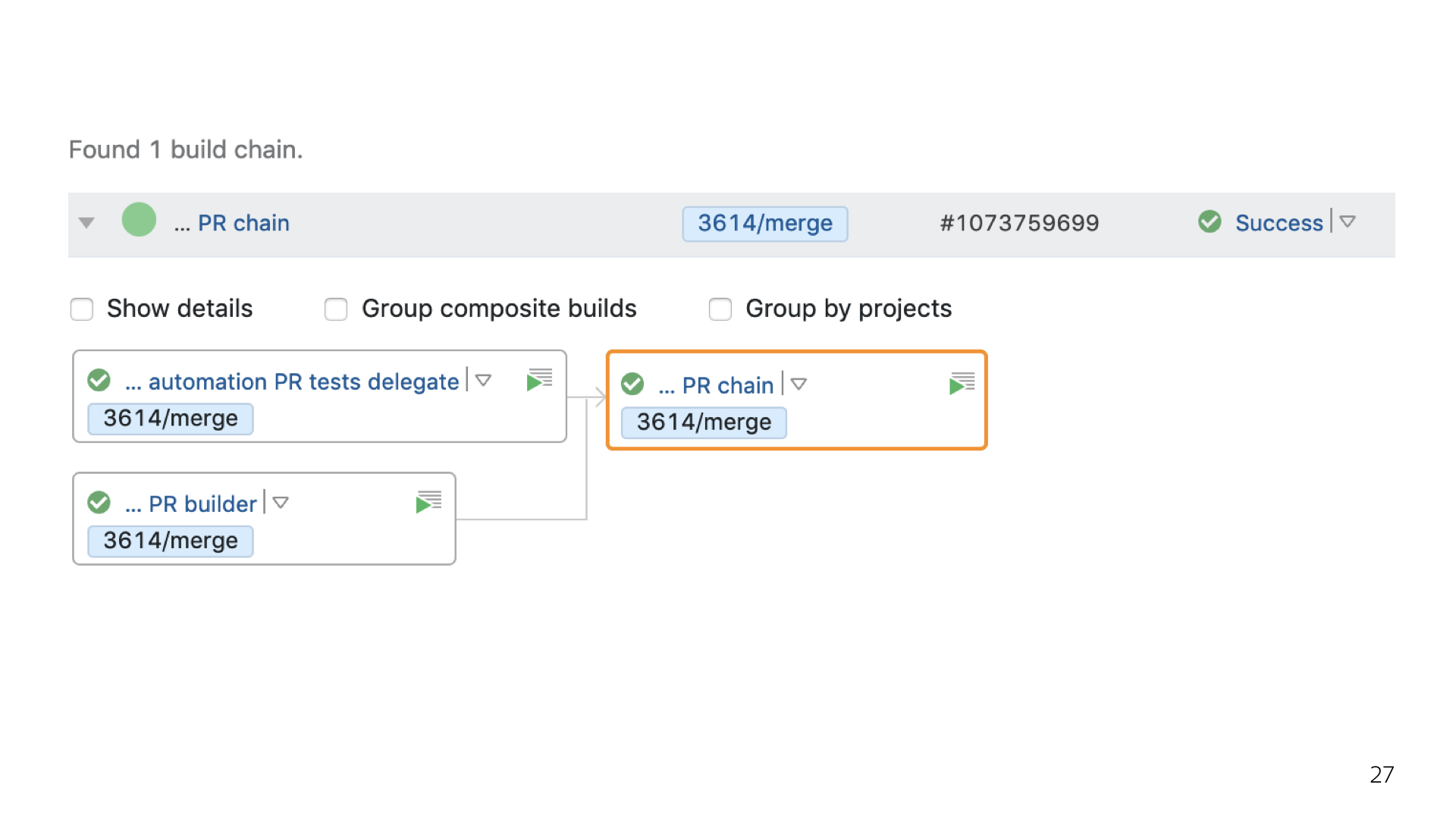
На выходе мы получаем примерно такую простую структуру. Можно ее усложнять и делать вложенности настолько глубоко, насколько хватит фантазии или потребностей. И быть уверенным, что во все эти зависимости, во все эти конфигурации будут проброшены все наши параметры, которые мы ожидаем на каждом шаге выполнения сборки. Готов ответить на ваши вопросы. Всем спасибо!
Комментарии (32)

cccco
08.09.2019 16:44На картинке RAID-10 вроде как ещё работоспособный.
Про версионирование настроек и security не знал. Спасибо за наводку!
tbl
08.09.2019 23:33На картинке RAID-10 вроде как ещё работоспособный.
Картинка модельная (из какой-нибудь презенташки по RAID 1+0), вряд ли именно так развалилась полка дисков.
Да и на их месте (раз они в Яндекс.Облаке поддерживают хранилище с API Amazon S3), я бы вместо выделенного хранилища всё хранение артефактов на S3 перенёс, благо, официальный плагин для teamcity давно есть.yataxi-dev Автор
09.09.2019 15:14На новом сервере именно на S3 и переехали :) Все артефакты принудительно в облако отгружаются, а локальное хранилище чистится каждые 2-3 дня от тонны логов.
nikizan
09.09.2019 07:12офтоп: включать опцию "5% чаевых" без предупреждения (!) при добавлении карты и моментальной последующей оплаты долга за предыдущую поездку такой себе маркетинговый ход...

gecube
09.09.2019 08:21Это не маркетинговый ход, а просто отсутствие проработки всех возможных сценариев.
И, да, мне всегда в этих случаях техподдержка рассказывает байки (что Я.Т, что Ситимобила), что нужно держать подключенную к такси карту, так ещё и с положительным балансом (WAT!?)
Terras
09.09.2019 09:12+1Давайка лучше на пикабу со своими оффтопиком. Тут достаточно интересный доклад, а не место жалоб на яндекс такси.

dmitryvolkovtaxi
09.09.2019 11:47Здравствуйте! Я из поддержки Яндекс.Такси. При привязке карты должно было появиться дополнительное окно, где можно выбрать размер чаевых по умолчанию. Напишите, пожалуйста, нам на почту blogs@taxi.yandex.ru — проверим, почему этого не произошло.

scruff
09.09.2019 08:05-2Немного не в топик, но пользуясь случаем расскажу.
На днях в мою стоячую машину «приехал» Яндекс.Такси (ЯТ) — не сильно, но обидно. Очень долго общались за ущерб. Из-за чего я опоздал на работу. Профакапил ряд тасков. Получил по башке от начальника. Перенервничал. Задержался на работе. В целом, негативный осадок от компании остался, т.к.:
а) нет входного теста на адекватность водил — берут кого попало.
б) нет телефона на бортах машины, куда можно обратиться в случае небрежного вождения водилы, чтобы его штрафанули хорошенько. А вообще ЯТ хоть в курсе как его водилы разъезжают или только денежку стрегут, а всё остальное «возле птицы»?
в) нет компенсационной политики со стороны ЯТ пострадавшей стороне.
г) возможно еще много чего, но к счастью пассажиром ЯТ пока не приходилось быть.gecube
09.09.2019 08:22А причем тут Яндекс? С тем же успехом мог приехать любой другой таксист.
Или не знаю… Любой небрежный офисный хомячок.
А в нас однажды вообще бензовоз приехал. Теперь все НПЗ клеймить, что ли ?
нет входного теста на адекватность водил — берут кого попало.
Насколько я понимаю, там достаточно хитрая система. Когда есть водители, которые напрямую с Я.Т работают, а есть партнёры. И есть подозрение, что предрейсовый контроль у партнёров как раз… Отсутствует. И вроде бы была опция в программе, которая позволяет отключить небрендированные машины и/или партнёров, или я с другой службой такси путаю ?
scruff
09.09.2019 09:34-2Яндекс тут именно при том, что это его неадекватный сотрудник приехал в меня, а не 3rd-party хомячок. По поводу партнёров вы правы. Скорее всего в моем городе какая-либо юр.структура от ЯТ отсутствует, а вместо него есть всякие однодневки типа Ашот-транспортэйшн или Дамшут-такси, отсюда и контроль соотвествующий. Но внимание — машины брендованные в стиле Яндекса! В любом случае — написать телефон для жалоб и организовать отдел в ЯТ по работе с жалобами считаю просто необходимым, т.к. ДТП совершил именно сотрудник ЯТа, и не важно сколько там фирм-прослоек от Яндекса до самого водилы — это его человек и его ответственность. Ведь основную прибыль гребёт именно ЯТ, не так ли? А следовательно и основная ответственность за подобные инциденты должна быть его.

antonarhipov
09.09.2019 17:30+1UUID на самом деле необязателен. Если UUID не задать, то он генерируется из обычного id, который получается из имени объекта.
Другое дело, что иногда может придти мысль «порефакторить» конфигурации и переименовать объект. А так как истолия сборок связана через этот id, то при переименовании объекта история вдруг может оказаться несвязанной с новом id. Но этого можно избежать — либо задать таки UUID, либо связать историю через UI.yataxi-dev Автор
10.09.2019 10:47Это так. На практике, лучше обязать всегда явно задавать уникальный UUID, в дальнейшем это сильно упростит всем жизнь :) И в плане рефакторинга, и в контексте внесения изменений через UI.

kemsky
11.09.2019 02:12Подскажите, как можно узнать uuid уже существующих обьектов?
yataxi-dev Автор
11.09.2019 12:41При создании репозитория Тимсити предложит экспортировать текущее дерево проектов в xml/kotlin конфиги. И там уже uuid каждого объекта будут.
Если пишите свой конфиг с нуля — можно просто создать самому любым удобным способом этот идентификатор. Я использую *nix команду в терминале — uuidgen.
cccco
09.09.2019 17:32+1Почитал доку про версионирование настроек. Правильно ли я понял, что любые изменения, сделанные в gui, придётся вручную вносить через патч, который TC сохранит в репе настроек? Выглядит не совсем удобным.
У нас один из шагов сборки сохраняет новое значение в переменную проекта (в ней хранится вычисляемый определённым образом номер версии приложения), и, соответсвенно, при следующей сборке уже используется это новое значение переменной (чтобы вычислить следующее значение и т.д.). Выглядит это как изменения внесённые через gui, т.е. в gui после сборки отображается новое значение переменной. Сборки запускаются автоматом при пуше в репу проекта.
Хотелось бы, чтобы TC репу настроек, соответственно, автоматом обновлял, при внесении изменений в gui. Т.к. в нашем случае вручную отслеживать поступление патчей сложно.
Понятно, что можно добавить ещё один степ сборки и накатывать автоматом этот патч. Но, во-первых, выглядит костыльно, а, во-вторых, пока не понятно, когда этот патч появляется в репе конфига.
Можете как-то прокомментировать или подсказать что-нибудь по этому поводу?yataxi-dev Автор
10.09.2019 10:57Распишу по-порядку.
* ТС создаёт патч на любое изменение из UI. Можно запретить вносить изменения из UI и тогда придётся всё делать через пулл реквесты в репозиторий с настройками.
* Применять или не применять патч — дело личное, но со временем кучка патчей превратится в свалку и разобрать их будет сложно. Поэтому лучше не допускать этого. Либо, см. пункт выше :)
* Изменение переменной проекта при сборке — моветон, лучше избегать подобных манипуляций. Храните переменную в гите вместе с проектом (можно ведь сделать коммит/пуш прямо с билд-агента от лица какого-нибудь сервисного пользователя), либо в удалённой БД. Если уж очень-очень надо — напишите простенький плагин для ТС и делайте это через механизм property-file. Есть подобный плагин — autoincrement. Если по-простому — он позволяет определить монотонно-возрастающую числовую переменную для нескольких билд-конфигураций и/или проектов.
* Отдельным степом сборки применять патчи не кошерно, но может помочь на больших проектах справиться с патч-штормом. Лучше избегать таких подходов, по возможности)cccco
10.09.2019 22:25Спасибо за комментарии!
Глянул, TC патчи тоже версионирует. Т.е. появилось по одному патчу на настроенную сборку (где были изменения конфига), которые перезаписываются и коммитется. Если не важна история изменения конфига (а в случае, когда изменяется только одна переменная проекта TC, она наверное, не важна), можно и руками периодически применять текущие патчи.
На самом деле, у нас так и есть — переменная с версией приложения хранится в гите (правда, в отдельном проекте). Но также есть зеркальная ей переменная проекта в TC. Разработчику удобно видеть в gui TC текущую версию приложения. Плюс, переменная нужна для плагина, который в Слаку отправляет сообщения, а этот плагин оперирует только переменными проекта TC. От плагина можно отказаться, т.к. в Слаку легко слать сообщения и без плагина. Наверное, можно, пожертвовав удобством разработчиков, вообще отказаться от этой переменной проекта в TC. Тогда и патчей, связанных с изменениями этой переменной, не будет.
Да, согласен, надо не патч применять степом сборки, а сам конфиг изменять. Мне кажется, если одним степом изменить конфиг (значение переменной проекта TC), а следующим — саму переменную проекта TC, то патча не будет, т.к переменная будет соответствовать конфигу. Надо проверить.yataxi-dev Автор
11.09.2019 12:39Можно оставить переменную в ТС, только сделать её по-другому :) Я выше показал на примере плагина автоинкремента, как это делается. Условно, при каждой сборке некая переменная пробрасывается прямо в файлик на ФС сервера (средствами плагина). Таким образом, никаких изменений в конфигах проекта не происходит, а значение переменной обновляется на каждом билде.
antonarhipov
10.09.2019 15:57Автоматически применить патч можно только переписав полностью настройки. Ведь в коде могут быть заведены какие-нибудь свои абстракции про которые ТС не знает. ТС работает с внутренней моделью проекта и патч генерируется относительно этой модели.
cccco
10.09.2019 22:35Патч руками в таком случае, наверное, тоже не тривиально будет применить, т.к. не будет однозначного соответствия между изменениями в патче и файлами конфига.
antonarhipov
11.09.2019 13:24Зависит, на сколько развесистую абстракцию вы себе придумаете. Если не вводить свои абстракции, то достаточно легко. Наверное, даже можно было бы автоматически, т.к. даже если перезаписать настройки то они не будут отличаться от того, что было бы написано напрямую в коде.
gecube
Мне вот интересно 2 момента:
QtRoS
Я не от имени Яндекса говорю, но если уж одна из самых крупных российских контор себе не сможет позволить купить лицензию, то кто тогда? А несколько я знаю в целом продукт достаточно популярен в России.
gecube
Насчет Яндекса — они тоже деньги считают. Я понимаю, что есть разные кейсы, но вот, например, с оракла они переехали на постгрес. Даже при учете того, что постгрес потребовал х3 железа — все равно получилось дешевле.
splix
Постгрес действительно потребовал в 3 раза больше железа? Это в случае яндекса или средняя разница по потребляемым ресурсам?
gecube
Речь не про облако, а про это: https://m.habr.com/ru/post/321756/
yataxi-dev Автор
Агентов ~100 штук только в такси. На мобильную команду хватает 10 агентов.
Стоимость ТС не такая уж большая, если пересчитать трудозатраты на реализацию и поддержку своей системы.
Почему ТС? Так исторически сложилось. Это означает багаж уже написанного кода и инфраструктуры, который нельзя просто так взять и дропнуть :) Это и плагины, и бэкенд сервисы (аналитика, мониторинги, интеграции). Слишком золотой вышел бы переезд на новую систему. Плюс, оперативный саппорт из коробки :)
gecube
Спасибо. Т.е. я правильно понял, что
yataxi-dev Автор
1. Есть и своя, и ТС.
2. В Такси все проекты всегда жили в ТС.
3. На текущий момент это так) Да и железа ТС ест мало — две средне-упитанные серверные ноды + виртуалки для билд-агентов.
И называть ТС системой сборки не совсем корректно (да, я зануда) — это сервис для непрерывной сборки :) Система сборки у каждого проекта осталась неизменной.