
Меня зовут Илья Ирхин, я руководитель отдела машинного обучения и анализа данных Яндекс.Такси.
Коронавирус и самоизоляция, безусловно, повлияли на наши ML-проекты. Из моего доклада вы узнаете, как изменились модели, метрики и процессы. Вторая часть доклада тоже связана с нынешней ситуацией. Я рассказал о проектах-бумерангах — мы делаем их не потому, что они улучшают метрики в моменте, а потому, что верим: эти проекты будут полезны в будущем. Например — в такое время, как сейчас.

— Сначала мы с вами познакомимся, затем я расскажу, какие вообще задачи решает наша команда и какие области ML-проектов мы покрываем. После этого я расскажу уже непосредственно о конкретных кейсах и примерах, о том, как проекты видоизменились в условиях коронавируса. И в финальной части я расскажу о проектах-бумерангах. Это когда мы давно сделали что-то, что нам казалось очень классным, потому что верили в это во имя всего хорошего. И сейчас, в коронавирус, этот проект к нам вернулся и помог сделать классную фичу. Итак, давайте начнем.

Давайте знакомиться. Что же мы за команда ML такая? Мы решаем ML-задачи для трех сервисов: Такси, Еды и Лавки. Можно выделить четыре основных направления оптимизации нашей деятельности: оптимизация бюджета, бизнес-процессов, системы в целом и продукта.
Теперь подробнее об этих направлениях.

Оптимизация бюджета, как следует из названия, связана с бюджетом. У нас есть некий объем денежных средств или других ресурсов и есть целевые действия, которые мы с помощью этих ресурсов хотим получить. Например, мы хотим дать пользователям скидки, чтобы стимулировать их больше ездить на такси или заказывать в Еде или Лавке. Или же мы хотим дать какую-нибудь субсидию водителю, чтобы стимулировать спрос. Или же мы хотим спрогнозировать, какой будет спрос в регионе, чтобы запланировать смены курьеров и вывести их таким образом, чтобы доставить все заказы вовремя.
В этих задачах мы с помощью ML либо прогнозируем бизнес, либо решаем задачу таргетирования, чтобы достичь наибольшего эффекта от воздействия.

Следующее направление — оптимизация бизнес-процессов. В Такси, Еде и Лавке достаточно много больших систем. Например, поддержка пользователей. Кроме того, еть фотоконтроль автомобиля и его качество: не битая ли машина, не грязная ли, чистый ли салон и т. п. Или, например, контроль того, что водитель не устал и с ним все хорошо.
Во всех этих задачах можно увеличивать долю автоматизации, автоматизировать какие-то части процессов именно за счет ML-моделей. Например, предсказывать, в чем состоит обращение пользователя, по тексту обращения. Или классифицировать картинку на предмет удовлетворения требованиям сервиса.
Следующее направление — оптимизация системы в целом. В Такси есть большое направление, отвечающее за эффективность платформы, то есть за то, как правильно балансировать спрос и предложение с помощью цены, как назначать машину на заказ, чтобы было максимально эффективно, и другие алгоритмы, которые влияют на эффективность систем. Здесь мы с помощью ML-методов помогаем коллегам делать эти алгоритмы еще более классными.
Например, можно прогнозировать, где машина будет находиться через пять или десять секунд и назначать машину не с учетом текущей позиции, а с учетом того, где она будет через несколько секунд, когда водитель физически будет принимать этот заказ. Тем самым можно избежать ситуации, когда машина назначена, но водитель, принимая заказ, проехал поворот к пользователю, ему приходится разворачиваться и время подачи резко вырастает по сравнению с обещанным.

Следующее направление — оптимизация продукта. Мы хотим, чтобы наше приложение было максимально удобным, функциональным и максимально полезным для пользователя.
Например, мы подсказываем точки Б, чтобы он мог выбрать пункт назначения в один клик. Или советуем удобные точки посадки, чтобы пользователю и водителю было максимально легко встретиться друг с другом. Или ранжируем рестораны согласно истории заказов пользователя, чтобы он мог заказать там, где ему больше всего понравилось, либо там, где ему будет интересно попробовать что-то новое.
Помимо рекомендаций есть задачи предсказания разных статистик на будущее, чтобы пользователь мог узнать, через сколько приедет машина или когда доставят еду.
Мы с вами познакомились, и сейчас я уже на конкретных проектах расскажу, как они изменились в условиях коронавируса.
Начну с проекта по предсказания спроса в Яндекс.Лавке. Коротко, в чем суть проекта? Чтобы выводить курьеров в разные районы и делать это наиболее эффективно, хочется понимать, какой будет спрос в том или ином районе. Где нужно больше курьеров, где будет меньше курьеров? Поэтому появляется задача — для каждой Лавки предсказывать, какой будет спрос в ее районе в будущем.
К этой модели есть набор требований. Например, чтобы она была максимально интерпретируема, потому что если что-то идет не так и модель ошибается, то нам нужно понимать, почему так получилось.
Кроме того, мы хотели бы, чтобы модель была максимально устойчивой, поскольку спрос — это все-таки довольно чувствительная величина, которая активно во времени меняется. И чтобы сделать модель более устойчивой, мы, во-первых, решили использовать линейную модель, такая устойчивость и интерпретируемость.
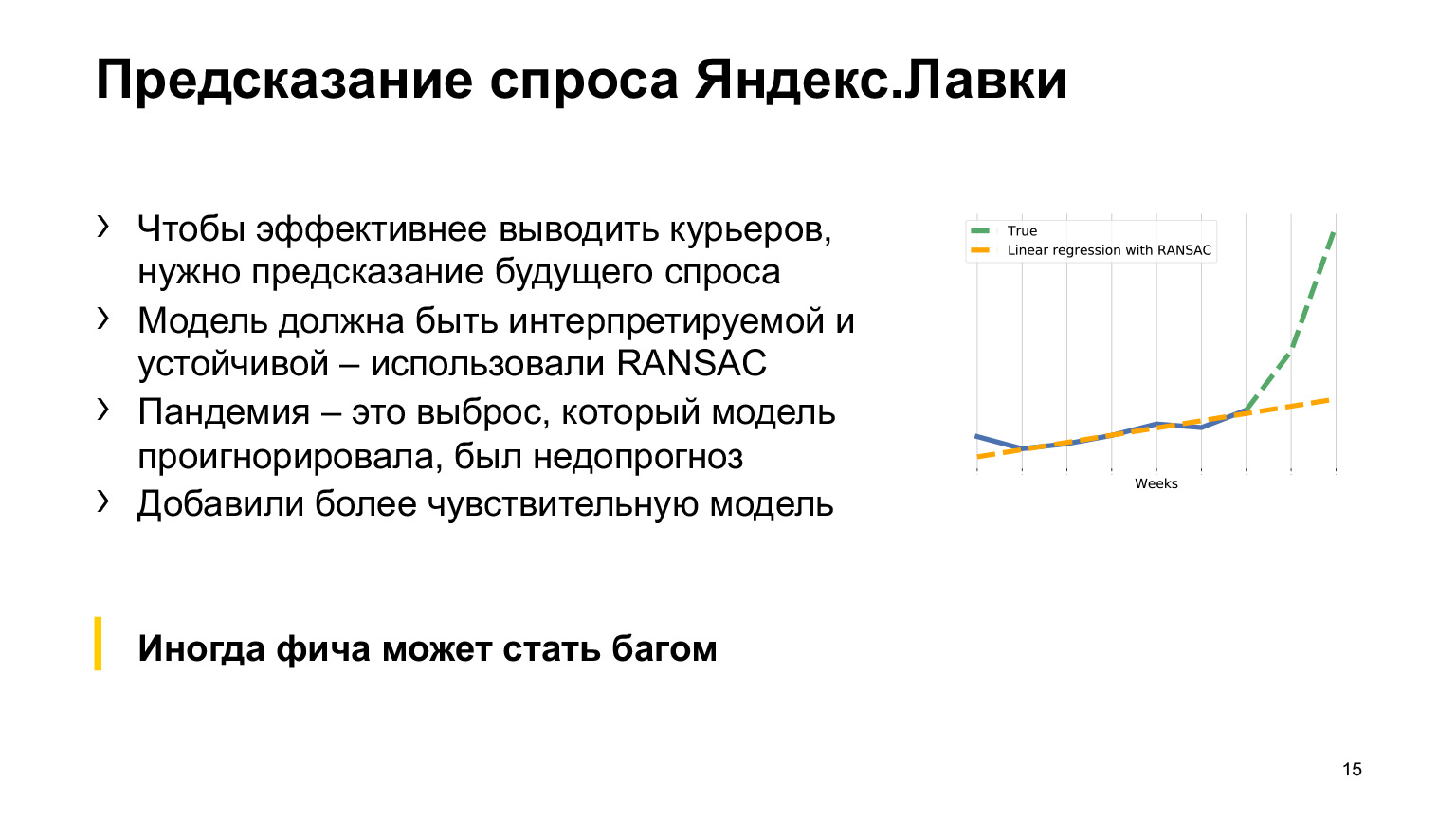
Во-вторых, чтобы сделать ее более устойчивой, мы решили использовать метод RANSAC, и это очень положительно повлияло на качество. Даже уменьшило ошибку на несколько процентов. В общем, все было прекрасно.
Но в условиях коронавируса все-таки случилось нечто неожиданное. Можете высказать ваши гипотезы, что же пошло не так во всей этой схеме, а после этого я расскажу и можно будет сверить.
Вывод: иногда фича, которая вам казалась очень хорошей, может внезапно стать багом, и с ней нужно будет бороться.
Следующая история, а именно UpSale, тоже касается Яндекс.Лавки. Чтобы улучшить продукт, мы сделали рекомендательный блок на корзине, в котором на основании содержимого корзины рекомендуем пользователю различные дополнительные товары, которые могли бы быть ему интересны.
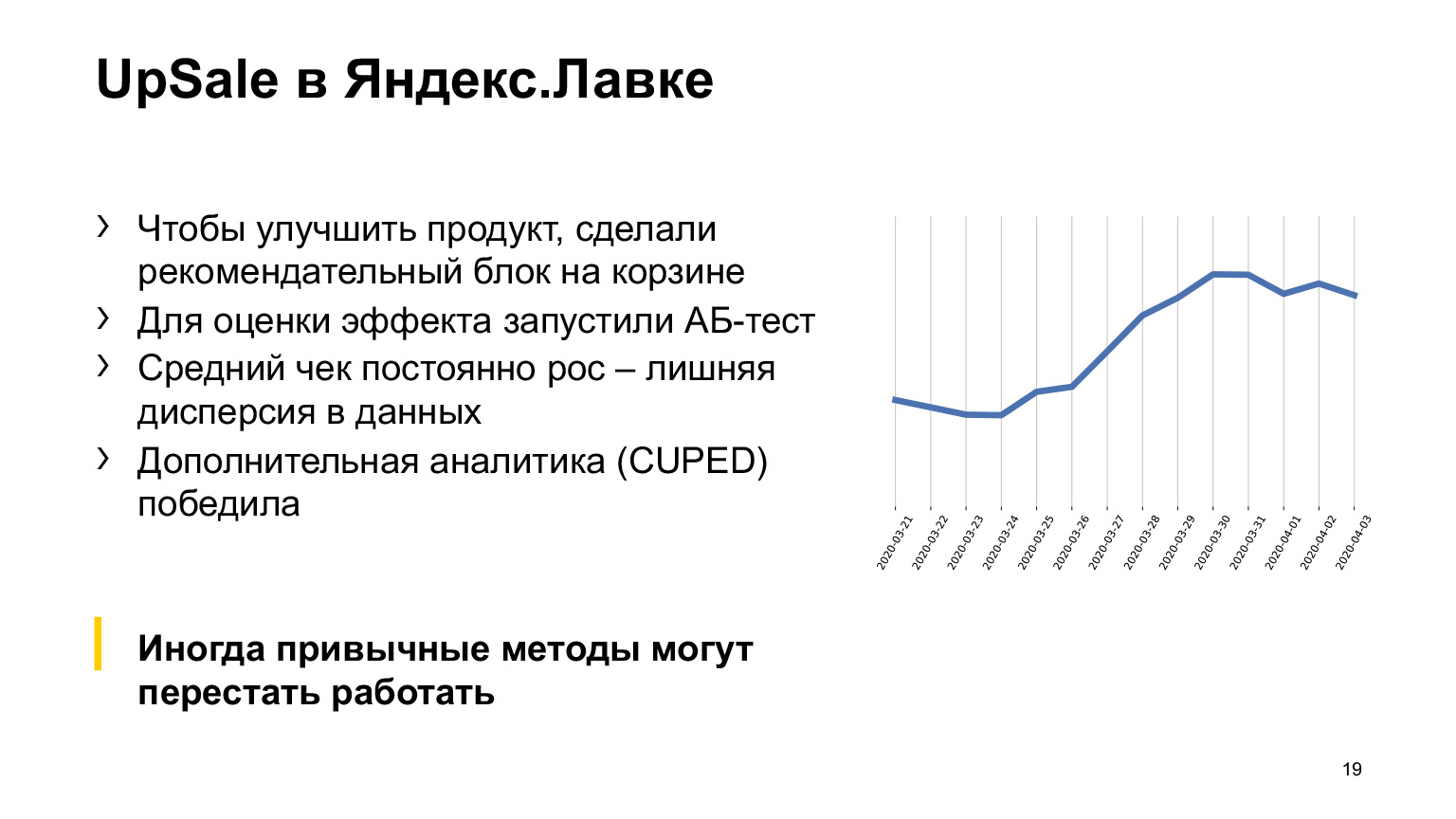
Чтобы оценить эффект от этого, мы запустили A/Б-тест, которым решили измерить средний чек — как он меняется при наличии рекомендательного блока и при его отсутствии.
Что тут могло произойти? Поскольку спрос очень активно рос и, более того, люди начинали заказывать все больше и больше, то в ходе A/Б-теста четко выделился постоянный линейный тренд роста, в рамках которого средний чек рос. И это создавало лишнюю дисперсию в данных, в итоге стандартные методы обсчетов статзначимости могли детектировать, что изменение статзначимо, именно из-за этой дополнительной дисперсии, связанной с ростом.
Чтобы побороться с этой проблемой, пришлось вложиться в дополнительную аналитику. Если конкретно, метод для оценки статзначимости называется CUPED, крайне рекомендую подробнее про него прочитать, очень классный и полезный метод.
С его помощью мы смогли учесть этот линейный тренд, побороться с ним и получить уже более точную оценку статзначимости, сделав наши метрики более чувствительными за счет уменьшения дисперсии.
Вывод: иногда привычные методы могут перестать работать, и нужно быть к этому готовым хотя бы морально.

Следующая история касается автоматизации поддержки в Яндекс.Такси. Как я уже сказал, поддержка — достаточно большое направление в нашей деятельности. Как оптимизировать траты на поддержку за счет ее максимальной автоматизации?
Для этого мы очень многие сообщения обрабатываем с помощью ML-модели. Мы сделали достаточно большую систему и начали ее переносить с клиентской поддержки на водительскую поддержку. Но в условиях коронавируса, во-первых, очень сильно увеличился поток сообщений, потому что ситуация менялась, водители стали чаще писать.
Во-вторых, смысл этих сообщений тоже изменился, потому что, как минимум, добавились новые ситуации, например, в связи с появлением пропусков с QR-кодами.
Из-за этих двух факторов доля автоматизации, то есть доля запросов, на которые мы отвечаем ML-моделью, упала примерно в два раза. Чтобы побороться с этой ситуацией, мы заново составили новое дерево тематик, по которым обращаются водители. Переобучили под них новую модель, тем самым отыграли падение в этой доле автоматизации не до исходного уровня, но бoльшую часть вернуть получилось.
Вывод: приоритет задачи может очень активно вырасти, потому что выросли объемы. Но при этом основной KPI может сильно упасть.
Бывает и наоборот. Вот, например, задача, связанная с прогнозом изменения цены в Яндекс.Такси. Давайте коротко расскажу, в чем здесь суть.
С точки зрения системы невыгодно, когда спрос начинает резко превалировать над предложением, поскольку это создает дисбаланс, мешающий эффективно назначать водителей на заказы, и приходится повышать цену, чтобы привлечь водителей в зону дисбаланса.
Вы могли столкнуться с этим эффектом, когда у вас «фиолетовые» цены в приложении.
Чтобы это происходило чуть реже, мы уведомляем пользователя, что в ближайшее время цена может измениться. Мы надеемся, что за счет этого часть пользователей уедут чуть раньше, чем они изначально планировали, и спрос как бы размажется во времени. Не будет такого резкого эффекта превалирования спроса над предложением.
Но, в условиях коронавируса спрос на такси очень сильно изменил свой характер. Теперь «фиолетовых» цен практически не бывает в системе. То есть спрос и предложение более-менее всегда совпадают. Поэтому нотификации в этой текущей ситуации стали излишни, функциональность — не востребованной, и мы решили ее отключить.
Таким образом, приоритет задачи может очень резко упасть, хотя ее основной KPI очень сильно вырос. Это как в данном случае, когда мы действительно добились эффекта, что спрос и предложение стали более-менее одинаковыми.
Давайте перейдем к следующему кейсу — к запуску SuperApp Яндекс.Такси.

Идея объединить Еду, Лавку и Такси в единую экосистему, чтобы пользователю было удобно решать сразу несколько задач, планировалась достаточно давно. В условиях коронавируса актуальность Еды и Лавки резко возросла. Более того, поскольку у очень многих ресторанов, скажем так, пропала возможность напрямую продавать свои услуги и товары, то чтобы предоставить им дополнительную площадку, где они могли бы продолжить свою работу, приоритет запуска SuperApp резко возрос.
За счет того, «Посколькуто приоритет очень сильно повысился, скорость внутренних процессов по разработке SuperApp выросла просто в разы. Что касается ML, появилось очень много новых задач, обычно рекомендаций. Например, бейджики, которые вы можете видеть на экране, называются шорткатами. И нужно рекомендовать в том числе шорткат с точкой поездки, предлагая пользователю куда-то поехать на такси. Или же шорткат разных ресторанов, где можно подбирать рестораны, которые ему понравятся, категории Лавки и т. д.
Отдельная задача — все это смешать в единое целое, чтобы, с одной стороны, самое релевантное было наверху, а с другой, чтобы все достаточно красиво уложилось на сеточку?
Вывод: иногда кризис может выступить катализатором проекта, повысить его приоритеты, гораздо силнее ускорить его запуск, повлиять и на другие проекты.
О влиянии на другие проекты я хотел бы рассказать на примере предсказания популярных локаций.
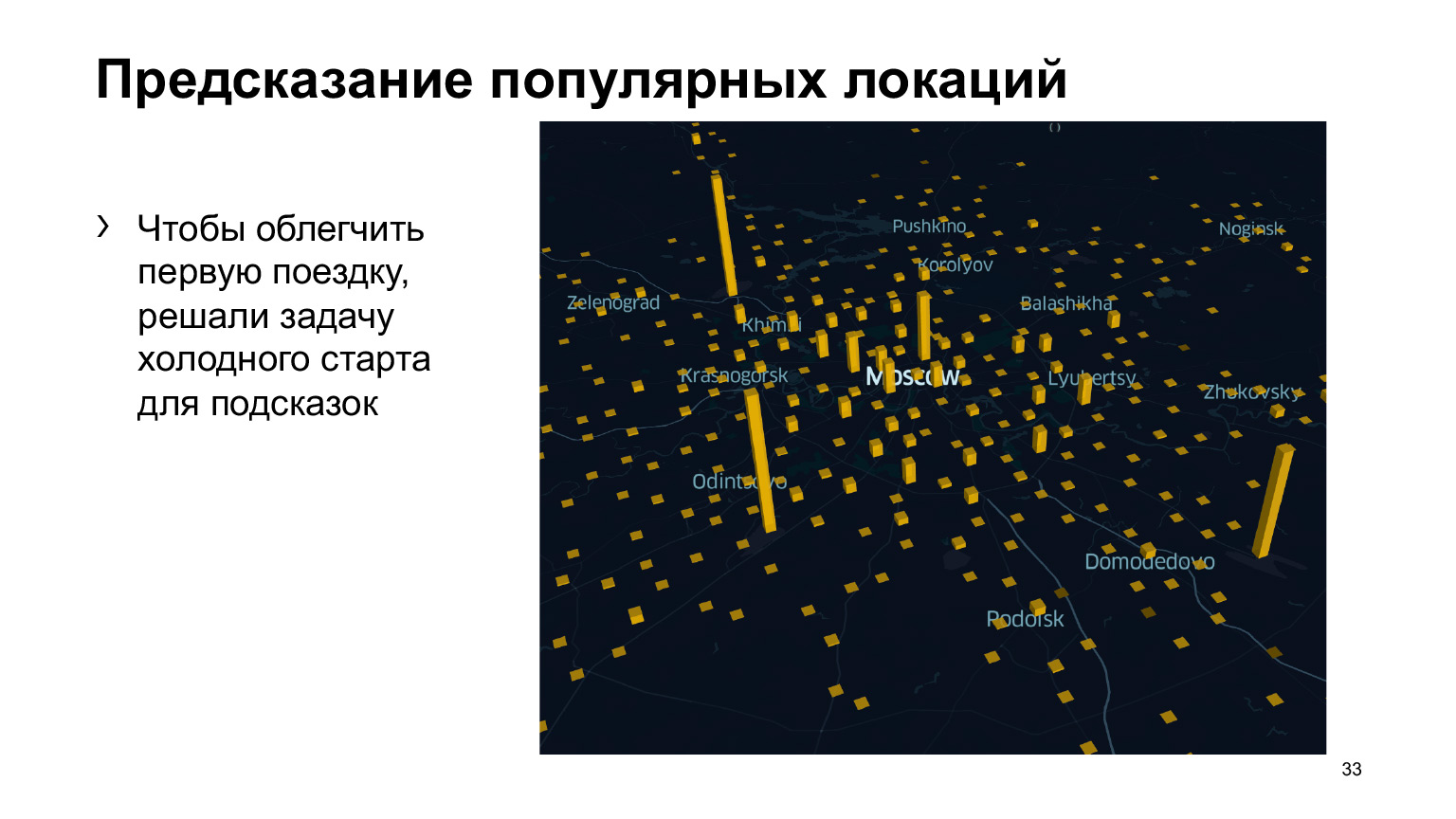
Изначально задача решалась за счет подсказки точки прибытия, с целью облегчить жизнь новых пользователей приложения Яндекс.Такси. Но они еще не пользовались сервисом, поэтому у нас нет историй их поездок. Но мы можем выделить популярные локации в том городе или районе, где они находятся, и порекомендовать им. То есть мы решаем задачу холодного старта новых пользователей.
Кстати, на слайде вы можете видеть гистограмму распределения точек Б у пользователей в Москве. Самые большие пики — это аэропорты, что достаточно ожидаемо. И да, конечно, эта гистограмма сделана еще до коронавируса.
Предлагаю придумать гипотезу того, что является пиками в центре Москвы, то есть какие еще точки достаточно популярны на фоне остальных, но не являются аэропортами. Сделайте ваши гипотезы, и после этого я скажу правильный ответ.
Но что же произошло с запуском SuperApp? Конечно, запуская SuperApp в приложении Такси, хочется сохранить у пользователя ощущение, что он все еще в приложении Такси. Поэтому важным требованием становится то, что в выдаче должны присутствовать шорткаты Такси. Иначе у пользователя может быть неудобство: он открывает приложение Такси, а такси там нет, зато есть рестораны и Лавка.
Решая эту задачу холодного старта, мы в 16 раз уменьшили долю ситуаций, когда в выдаче не было шортката Такси. Тем самым мы раньше получили удовлетворительную версию SuperApp и, в частности, выкатили его раньше.
Вывод: акценты в KPI проекта могут очень сильно измениться, к этому тоже стоит быть готовым.

Резюмируя. Про фичу-баг это не просто переделка знаменитой фразы, а реальность, которую стоит иметь в виду. Привычные методы, которыми мы пользуемся, могут перестать работать. Надо быть к этому морально готовым, и желательно иметь план Б для ваших основных инструментов.
Приоритеты задач могут очень сильно меняться, причем в обратную сторону по сравнению с KPI этих задач. Финальный вывод: кризис может быть катализатором проектов и менять акценты даже в KPI других проектов.
Теперь мы с вами перейдем к следующей части, в которой я расскажу про проекты-бумеранги, то есть про те проекты, которые мы когда-то сделали, но они к нам вернулись и принесли добро.
Когда-то давно люди утром ездили на работу, а вечером возвращались домой. И делали это на такси, на основании историй поездок можно было бы предсказать, где у пользователей дом, а где работа. Тем более что очень многие люди добавляли точки поездок в избранное и подписывали, что это дом, а это работа. На основе таких данных можно было бы обучить модель.
Изначально это планировалось для того, чтобы предлагать пользователю добавить в избранное новые адреса. Однако в итоге для изначальной цели это не пригодилось. Но оказалось, что знание, где человек живет и где работает, может быть полезным, поэтому модель довели до продакшен-состояния и сохранили, чтобы в будущем использовать.
И это будущее, конечно, настало. А именно, это очень активно использовалось в пушах о том, что открывается новый ресторан в окрестностях. Или что зона Лавки расширилась, и теперь в эту точку она тоже доставляет.
Не хотелось бы, конечно, спамить всех в округе. Поэтому такие пуши отсылались только тем, кто, например, живет в этом районе или у кого в нем потенциально была работа, пока не ввели самоизоляцию.
Такое решение позволило получить десятки процентов дополнительных заказов в A/Б-тесте, что было очень приятно.
Вывод: изначально ваши ML-предсказания могут не иметь места использования. Но если не будет легкого способа использовать эти предсказания, то такое место может никогда и не появиться. Получается проблема курицы и яйца. В общем, иногда делается просто клевая модель, потом на нее находится потребитель и все от этого становятся чуть счастливее.
Похожая ситуация связана с офлайн-посещением организаций. Когда-то мы с коллегами пошли в кафе. Когда мы из него вышли, одному из нас пришел пуш в приложение: вот вы побывали в кафе, не хотите ли оставить отзыв? И тут у нас родилась идея, что некоторые люди отмечают, где они побывали, в Яндекс.Картах можно эту информацию получить. И тем самым не просто узнать историю заказов пользователя, но получить знания об офлайн-ресторанах, которые могут быть потенциально интересны. На основе этих данных можно точно так же находить дополнительных людей, которых стоит уведомить. И это тоже дало дополнительные проценты заказов.
Вывод: ML-модели — это, конечно, круто, но иногда работа со специфичными данными может быть не менее ценной, чем ML-модель, и тоже приносить профит.
Следующая история связана с проактивной поддержкой. Как я уже сказал, мы занимаемся автоматизацией поддержки с помощью ML-модели.

Но возникает интересная мысль: чтобы оптимизировать расходы на поддержку, не обязательно оптимизировать саму поддержку. Давайте раскрою эту мысль чуть подробнее.
У нас есть телеметрические данные о поездке. Это данные с акселерометра, то есть если будет много резких поворотов, то, возможно, что-то в поездке происходило не так. И можно на основании телеметрических данных определять вероятность обращения в поддержку. Предположим, нам кажется, что эта вероятность большая. Тогда можно заранее коммуницировать с пользователем, тем самым предотвращая случай, когда он сам пишет в саппорт. Это во-первых.
Во-вторых, мы можем взаимодействовать с водителем, если у него часто встречаются такие моменты и на основании этих данных нам кажется, что на него могли бы часто жаловаться. Мы убиваем сразу двух зайцев — улучшаем сервис фидбеком от водителя и получаем дополнительный источник оптимизации: уменьшаем количество обращений в поддержку.
Вывод: не стоит ограничиваться изначальными рамками, которые мы себе в задаче поставили. Стоит из них выходить, чтобы находить что-то клевое и новое.
Следующая история более техническая. Все мы дата-саентисты, очень любим Python, любим обучать модельки на нем, потому что удобно, приятно и, вообще, язык хороший. Но, конечно, если вы обучили модельку на каком-то языке, у вас может возникнуть естественное желание на этом же языке ее в продакшене и применять.
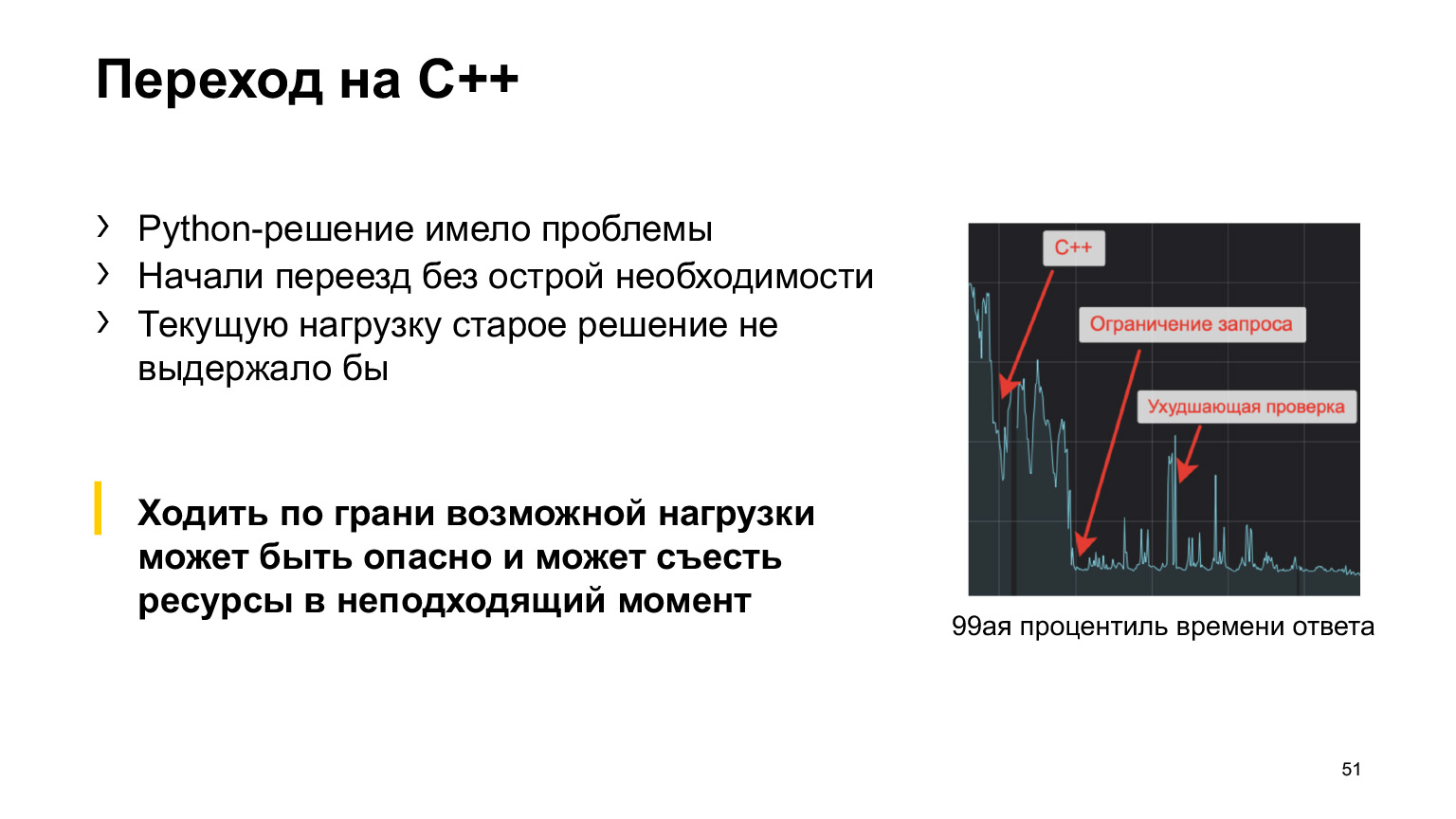
У нас часть применения этих моделей была написана на Python. Был Python-сервис и был ряд, скажем так, проблем, обычно связанных с производительностью и нагрузкой, которую сервис способен выдержать.
Чтобы «подстелить соломки» и успокоить душу, мы решили переписать сервис на C++ в начале года. Мы это сделали. Добавили дополнительные ограничения на запрос и увидели, что время ответа очень сильно уменьшилось, все стало отлично. И нагрузку мы стали держать более высокую, в разы. Все сделали, забыли, живем.
А сейчас, в условиях коронавируса, нагрузка очень сильно выросла, но мы этого не особо заметили. Никаких технических проблем не возникло и это ценно, когда нужно делать новые клевые фичи, исправлять и учитывать особенности ситуации в моделях. Мы могли заниматься именно этим, а не чинить и масштабировать сервис.
Вывод: не нужно забывать о техническом масштабировании ваших решений. Потому что, когда они сломаются, вам придется чинить их, вместо того чтобы делать важные изменения в сервисе.

Резюмируя эту часть, стоит понимать: есть взаимосвязь между клевыми вещами, которые вы делаете, и их использованием. Если вы руководствуетесь только принципом, что классные штуки не стоит делать, пока не появится конкретный заказчик на проект и желаемый KPI от этого проекта, то вы какую-то часть крутых вещей упускаете — хотя могли бы их сделать.
Второе: стоит помнить, что ML-данные тоже важны. И то, как вы их обработаете, структурируете и дадите возможность другим людям их переиспользовать, может быть не менее ценным.
Следующая мысль: не нужно ограничивать себя в решении проблемы. Возможно, ваш новый подход может вывести вас на принципиально новый уровень.
И такой, немножко занудный пункт: при всем при этом не стоит забывать, что ваши решения должны работать. Можно сколь угодно классную модельку обучить в Jupyter Notebook и порадоваться, какое у нее классное качество. Но если вы не сможете довести ее до продакшена или она не будет работать — к сожалению, этот мир вы не улучшите.
В конце хотелось бы сказать следующее. Паднемия коронавируса — подходящее время для того, чтобы критически взглянуть на ваши проекты и процессы и поменять их при необходимости. Главное — стараться быть объективным, делать выводы из ваших наблюдений и не бояться изменений, стараться всё сделать лучше.
Это всё. Было очень приятно рассказать про наши наблюдения и выводы. Спасибо.
Коронавирус и самоизоляция, безусловно, повлияли на наши ML-проекты. Из моего доклада вы узнаете, как изменились модели, метрики и процессы. Вторая часть доклада тоже связана с нынешней ситуацией. Я рассказал о проектах-бумерангах — мы делаем их не потому, что они улучшают метрики в моменте, а потому, что верим: эти проекты будут полезны в будущем. Например — в такое время, как сейчас.
— Сначала мы с вами познакомимся, затем я расскажу, какие вообще задачи решает наша команда и какие области ML-проектов мы покрываем. После этого я расскажу уже непосредственно о конкретных кейсах и примерах, о том, как проекты видоизменились в условиях коронавируса. И в финальной части я расскажу о проектах-бумерангах. Это когда мы давно сделали что-то, что нам казалось очень классным, потому что верили в это во имя всего хорошего. И сейчас, в коронавирус, этот проект к нам вернулся и помог сделать классную фичу. Итак, давайте начнем.
Давайте знакомиться. Что же мы за команда ML такая? Мы решаем ML-задачи для трех сервисов: Такси, Еды и Лавки. Можно выделить четыре основных направления оптимизации нашей деятельности: оптимизация бюджета, бизнес-процессов, системы в целом и продукта.
Теперь подробнее об этих направлениях.
Оптимизация бюджета, как следует из названия, связана с бюджетом. У нас есть некий объем денежных средств или других ресурсов и есть целевые действия, которые мы с помощью этих ресурсов хотим получить. Например, мы хотим дать пользователям скидки, чтобы стимулировать их больше ездить на такси или заказывать в Еде или Лавке. Или же мы хотим дать какую-нибудь субсидию водителю, чтобы стимулировать спрос. Или же мы хотим спрогнозировать, какой будет спрос в регионе, чтобы запланировать смены курьеров и вывести их таким образом, чтобы доставить все заказы вовремя.
В этих задачах мы с помощью ML либо прогнозируем бизнес, либо решаем задачу таргетирования, чтобы достичь наибольшего эффекта от воздействия.
Следующее направление — оптимизация бизнес-процессов. В Такси, Еде и Лавке достаточно много больших систем. Например, поддержка пользователей. Кроме того, еть фотоконтроль автомобиля и его качество: не битая ли машина, не грязная ли, чистый ли салон и т. п. Или, например, контроль того, что водитель не устал и с ним все хорошо.
Во всех этих задачах можно увеличивать долю автоматизации, автоматизировать какие-то части процессов именно за счет ML-моделей. Например, предсказывать, в чем состоит обращение пользователя, по тексту обращения. Или классифицировать картинку на предмет удовлетворения требованиям сервиса.
Следующее направление — оптимизация системы в целом. В Такси есть большое направление, отвечающее за эффективность платформы, то есть за то, как правильно балансировать спрос и предложение с помощью цены, как назначать машину на заказ, чтобы было максимально эффективно, и другие алгоритмы, которые влияют на эффективность систем. Здесь мы с помощью ML-методов помогаем коллегам делать эти алгоритмы еще более классными.
Например, можно прогнозировать, где машина будет находиться через пять или десять секунд и назначать машину не с учетом текущей позиции, а с учетом того, где она будет через несколько секунд, когда водитель физически будет принимать этот заказ. Тем самым можно избежать ситуации, когда машина назначена, но водитель, принимая заказ, проехал поворот к пользователю, ему приходится разворачиваться и время подачи резко вырастает по сравнению с обещанным.
Следующее направление — оптимизация продукта. Мы хотим, чтобы наше приложение было максимально удобным, функциональным и максимально полезным для пользователя.
Например, мы подсказываем точки Б, чтобы он мог выбрать пункт назначения в один клик. Или советуем удобные точки посадки, чтобы пользователю и водителю было максимально легко встретиться друг с другом. Или ранжируем рестораны согласно истории заказов пользователя, чтобы он мог заказать там, где ему больше всего понравилось, либо там, где ему будет интересно попробовать что-то новое.
Помимо рекомендаций есть задачи предсказания разных статистик на будущее, чтобы пользователь мог узнать, через сколько приедет машина или когда доставят еду.
Изменившиеся проекты
Мы с вами познакомились, и сейчас я уже на конкретных проектах расскажу, как они изменились в условиях коронавируса.
Начну с проекта по предсказания спроса в Яндекс.Лавке. Коротко, в чем суть проекта? Чтобы выводить курьеров в разные районы и делать это наиболее эффективно, хочется понимать, какой будет спрос в том или ином районе. Где нужно больше курьеров, где будет меньше курьеров? Поэтому появляется задача — для каждой Лавки предсказывать, какой будет спрос в ее районе в будущем.
К этой модели есть набор требований. Например, чтобы она была максимально интерпретируема, потому что если что-то идет не так и модель ошибается, то нам нужно понимать, почему так получилось.
Кроме того, мы хотели бы, чтобы модель была максимально устойчивой, поскольку спрос — это все-таки довольно чувствительная величина, которая активно во времени меняется. И чтобы сделать модель более устойчивой, мы, во-первых, решили использовать линейную модель, такая устойчивость и интерпретируемость.
Во-вторых, чтобы сделать ее более устойчивой, мы решили использовать метод RANSAC, и это очень положительно повлияло на качество. Даже уменьшило ошибку на несколько процентов. В общем, все было прекрасно.
Но в условиях коронавируса все-таки случилось нечто неожиданное. Можете высказать ваши гипотезы, что же пошло не так во всей этой схеме, а после этого я расскажу и можно будет сверить.
Проблема и решение
Пандемия — некоторый выброс, в рамках которого спрос резко растет. Но поскольку наша модель максимально устойчива к этим выбросам, то она продолжает прогнозировать изменения спроса таким, каким он был бы раньше на периоде до, полностью игнорируя последние точки. Из-за этого случается недопрогноз.
Чтобы полечить эту проблему, мы помимо основного долгосрочного хорошего предсказания добавили другое предсказание, более чувствительное к последним дням. И уже в совокупности этих двух предсказаний все работало хорошо. Комбинируя их, мы решили задачу.
Чтобы полечить эту проблему, мы помимо основного долгосрочного хорошего предсказания добавили другое предсказание, более чувствительное к последним дням. И уже в совокупности этих двух предсказаний все работало хорошо. Комбинируя их, мы решили задачу.
Вывод: иногда фича, которая вам казалась очень хорошей, может внезапно стать багом, и с ней нужно будет бороться.
Следующая история, а именно UpSale, тоже касается Яндекс.Лавки. Чтобы улучшить продукт, мы сделали рекомендательный блок на корзине, в котором на основании содержимого корзины рекомендуем пользователю различные дополнительные товары, которые могли бы быть ему интересны.
Чтобы оценить эффект от этого, мы запустили A/Б-тест, которым решили измерить средний чек — как он меняется при наличии рекомендательного блока и при его отсутствии.
Что тут могло произойти? Поскольку спрос очень активно рос и, более того, люди начинали заказывать все больше и больше, то в ходе A/Б-теста четко выделился постоянный линейный тренд роста, в рамках которого средний чек рос. И это создавало лишнюю дисперсию в данных, в итоге стандартные методы обсчетов статзначимости могли детектировать, что изменение статзначимо, именно из-за этой дополнительной дисперсии, связанной с ростом.
Чтобы побороться с этой проблемой, пришлось вложиться в дополнительную аналитику. Если конкретно, метод для оценки статзначимости называется CUPED, крайне рекомендую подробнее про него прочитать, очень классный и полезный метод.
С его помощью мы смогли учесть этот линейный тренд, побороться с ним и получить уже более точную оценку статзначимости, сделав наши метрики более чувствительными за счет уменьшения дисперсии.
Вывод: иногда привычные методы могут перестать работать, и нужно быть к этому готовым хотя бы морально.
Следующая история касается автоматизации поддержки в Яндекс.Такси. Как я уже сказал, поддержка — достаточно большое направление в нашей деятельности. Как оптимизировать траты на поддержку за счет ее максимальной автоматизации?
Для этого мы очень многие сообщения обрабатываем с помощью ML-модели. Мы сделали достаточно большую систему и начали ее переносить с клиентской поддержки на водительскую поддержку. Но в условиях коронавируса, во-первых, очень сильно увеличился поток сообщений, потому что ситуация менялась, водители стали чаще писать.
Во-вторых, смысл этих сообщений тоже изменился, потому что, как минимум, добавились новые ситуации, например, в связи с появлением пропусков с QR-кодами.
Из-за этих двух факторов доля автоматизации, то есть доля запросов, на которые мы отвечаем ML-моделью, упала примерно в два раза. Чтобы побороться с этой ситуацией, мы заново составили новое дерево тематик, по которым обращаются водители. Переобучили под них новую модель, тем самым отыграли падение в этой доле автоматизации не до исходного уровня, но бoльшую часть вернуть получилось.
Вывод: приоритет задачи может очень активно вырасти, потому что выросли объемы. Но при этом основной KPI может сильно упасть.
Бывает и наоборот. Вот, например, задача, связанная с прогнозом изменения цены в Яндекс.Такси. Давайте коротко расскажу, в чем здесь суть.
С точки зрения системы невыгодно, когда спрос начинает резко превалировать над предложением, поскольку это создает дисбаланс, мешающий эффективно назначать водителей на заказы, и приходится повышать цену, чтобы привлечь водителей в зону дисбаланса.
Вы могли столкнуться с этим эффектом, когда у вас «фиолетовые» цены в приложении.
Чтобы это происходило чуть реже, мы уведомляем пользователя, что в ближайшее время цена может измениться. Мы надеемся, что за счет этого часть пользователей уедут чуть раньше, чем они изначально планировали, и спрос как бы размажется во времени. Не будет такого резкого эффекта превалирования спроса над предложением.
Но, в условиях коронавируса спрос на такси очень сильно изменил свой характер. Теперь «фиолетовых» цен практически не бывает в системе. То есть спрос и предложение более-менее всегда совпадают. Поэтому нотификации в этой текущей ситуации стали излишни, функциональность — не востребованной, и мы решили ее отключить.
Таким образом, приоритет задачи может очень резко упасть, хотя ее основной KPI очень сильно вырос. Это как в данном случае, когда мы действительно добились эффекта, что спрос и предложение стали более-менее одинаковыми.
Давайте перейдем к следующему кейсу — к запуску SuperApp Яндекс.Такси.
Идея объединить Еду, Лавку и Такси в единую экосистему, чтобы пользователю было удобно решать сразу несколько задач, планировалась достаточно давно. В условиях коронавируса актуальность Еды и Лавки резко возросла. Более того, поскольку у очень многих ресторанов, скажем так, пропала возможность напрямую продавать свои услуги и товары, то чтобы предоставить им дополнительную площадку, где они могли бы продолжить свою работу, приоритет запуска SuperApp резко возрос.
За счет того, «Посколькуто приоритет очень сильно повысился, скорость внутренних процессов по разработке SuperApp выросла просто в разы. Что касается ML, появилось очень много новых задач, обычно рекомендаций. Например, бейджики, которые вы можете видеть на экране, называются шорткатами. И нужно рекомендовать в том числе шорткат с точкой поездки, предлагая пользователю куда-то поехать на такси. Или же шорткат разных ресторанов, где можно подбирать рестораны, которые ему понравятся, категории Лавки и т. д.
Отдельная задача — все это смешать в единое целое, чтобы, с одной стороны, самое релевантное было наверху, а с другой, чтобы все достаточно красиво уложилось на сеточку?
Вывод: иногда кризис может выступить катализатором проекта, повысить его приоритеты, гораздо силнее ускорить его запуск, повлиять и на другие проекты.
О влиянии на другие проекты я хотел бы рассказать на примере предсказания популярных локаций.
Изначально задача решалась за счет подсказки точки прибытия, с целью облегчить жизнь новых пользователей приложения Яндекс.Такси. Но они еще не пользовались сервисом, поэтому у нас нет историй их поездок. Но мы можем выделить популярные локации в том городе или районе, где они находятся, и порекомендовать им. То есть мы решаем задачу холодного старта новых пользователей.
Кстати, на слайде вы можете видеть гистограмму распределения точек Б у пользователей в Москве. Самые большие пики — это аэропорты, что достаточно ожидаемо. И да, конечно, эта гистограмма сделана еще до коронавируса.
Предлагаю придумать гипотезу того, что является пиками в центре Москвы, то есть какие еще точки достаточно популярны на фоне остальных, но не являются аэропортами. Сделайте ваши гипотезы, и после этого я скажу правильный ответ.
Правильный ответ
Если аэропорты отвечают за воздушное сообщение, то вторым по популярности является железнодорожное сообщение. И точки в центре карты — это вокзалы.
Но что же произошло с запуском SuperApp? Конечно, запуская SuperApp в приложении Такси, хочется сохранить у пользователя ощущение, что он все еще в приложении Такси. Поэтому важным требованием становится то, что в выдаче должны присутствовать шорткаты Такси. Иначе у пользователя может быть неудобство: он открывает приложение Такси, а такси там нет, зато есть рестораны и Лавка.
Решая эту задачу холодного старта, мы в 16 раз уменьшили долю ситуаций, когда в выдаче не было шортката Такси. Тем самым мы раньше получили удовлетворительную версию SuperApp и, в частности, выкатили его раньше.
Вывод: акценты в KPI проекта могут очень сильно измениться, к этому тоже стоит быть готовым.
Резюмируя. Про фичу-баг это не просто переделка знаменитой фразы, а реальность, которую стоит иметь в виду. Привычные методы, которыми мы пользуемся, могут перестать работать. Надо быть к этому морально готовым, и желательно иметь план Б для ваших основных инструментов.
Приоритеты задач могут очень сильно меняться, причем в обратную сторону по сравнению с KPI этих задач. Финальный вывод: кризис может быть катализатором проектов и менять акценты даже в KPI других проектов.
Теперь мы с вами перейдем к следующей части, в которой я расскажу про проекты-бумеранги, то есть про те проекты, которые мы когда-то сделали, но они к нам вернулись и принесли добро.
Проекты-бумеранги
Когда-то давно люди утром ездили на работу, а вечером возвращались домой. И делали это на такси, на основании историй поездок можно было бы предсказать, где у пользователей дом, а где работа. Тем более что очень многие люди добавляли точки поездок в избранное и подписывали, что это дом, а это работа. На основе таких данных можно было бы обучить модель.
Изначально это планировалось для того, чтобы предлагать пользователю добавить в избранное новые адреса. Однако в итоге для изначальной цели это не пригодилось. Но оказалось, что знание, где человек живет и где работает, может быть полезным, поэтому модель довели до продакшен-состояния и сохранили, чтобы в будущем использовать.
И это будущее, конечно, настало. А именно, это очень активно использовалось в пушах о том, что открывается новый ресторан в окрестностях. Или что зона Лавки расширилась, и теперь в эту точку она тоже доставляет.
Не хотелось бы, конечно, спамить всех в округе. Поэтому такие пуши отсылались только тем, кто, например, живет в этом районе или у кого в нем потенциально была работа, пока не ввели самоизоляцию.
Такое решение позволило получить десятки процентов дополнительных заказов в A/Б-тесте, что было очень приятно.
Вывод: изначально ваши ML-предсказания могут не иметь места использования. Но если не будет легкого способа использовать эти предсказания, то такое место может никогда и не появиться. Получается проблема курицы и яйца. В общем, иногда делается просто клевая модель, потом на нее находится потребитель и все от этого становятся чуть счастливее.
Похожая ситуация связана с офлайн-посещением организаций. Когда-то мы с коллегами пошли в кафе. Когда мы из него вышли, одному из нас пришел пуш в приложение: вот вы побывали в кафе, не хотите ли оставить отзыв? И тут у нас родилась идея, что некоторые люди отмечают, где они побывали, в Яндекс.Картах можно эту информацию получить. И тем самым не просто узнать историю заказов пользователя, но получить знания об офлайн-ресторанах, которые могут быть потенциально интересны. На основе этих данных можно точно так же находить дополнительных людей, которых стоит уведомить. И это тоже дало дополнительные проценты заказов.
Вывод: ML-модели — это, конечно, круто, но иногда работа со специфичными данными может быть не менее ценной, чем ML-модель, и тоже приносить профит.
Следующая история связана с проактивной поддержкой. Как я уже сказал, мы занимаемся автоматизацией поддержки с помощью ML-модели.
Но возникает интересная мысль: чтобы оптимизировать расходы на поддержку, не обязательно оптимизировать саму поддержку. Давайте раскрою эту мысль чуть подробнее.
У нас есть телеметрические данные о поездке. Это данные с акселерометра, то есть если будет много резких поворотов, то, возможно, что-то в поездке происходило не так. И можно на основании телеметрических данных определять вероятность обращения в поддержку. Предположим, нам кажется, что эта вероятность большая. Тогда можно заранее коммуницировать с пользователем, тем самым предотвращая случай, когда он сам пишет в саппорт. Это во-первых.
Во-вторых, мы можем взаимодействовать с водителем, если у него часто встречаются такие моменты и на основании этих данных нам кажется, что на него могли бы часто жаловаться. Мы убиваем сразу двух зайцев — улучшаем сервис фидбеком от водителя и получаем дополнительный источник оптимизации: уменьшаем количество обращений в поддержку.
Вывод: не стоит ограничиваться изначальными рамками, которые мы себе в задаче поставили. Стоит из них выходить, чтобы находить что-то клевое и новое.
Следующая история более техническая. Все мы дата-саентисты, очень любим Python, любим обучать модельки на нем, потому что удобно, приятно и, вообще, язык хороший. Но, конечно, если вы обучили модельку на каком-то языке, у вас может возникнуть естественное желание на этом же языке ее в продакшене и применять.
У нас часть применения этих моделей была написана на Python. Был Python-сервис и был ряд, скажем так, проблем, обычно связанных с производительностью и нагрузкой, которую сервис способен выдержать.
Чтобы «подстелить соломки» и успокоить душу, мы решили переписать сервис на C++ в начале года. Мы это сделали. Добавили дополнительные ограничения на запрос и увидели, что время ответа очень сильно уменьшилось, все стало отлично. И нагрузку мы стали держать более высокую, в разы. Все сделали, забыли, живем.
А сейчас, в условиях коронавируса, нагрузка очень сильно выросла, но мы этого не особо заметили. Никаких технических проблем не возникло и это ценно, когда нужно делать новые клевые фичи, исправлять и учитывать особенности ситуации в моделях. Мы могли заниматься именно этим, а не чинить и масштабировать сервис.
Вывод: не нужно забывать о техническом масштабировании ваших решений. Потому что, когда они сломаются, вам придется чинить их, вместо того чтобы делать важные изменения в сервисе.
Резюмируя эту часть, стоит понимать: есть взаимосвязь между клевыми вещами, которые вы делаете, и их использованием. Если вы руководствуетесь только принципом, что классные штуки не стоит делать, пока не появится конкретный заказчик на проект и желаемый KPI от этого проекта, то вы какую-то часть крутых вещей упускаете — хотя могли бы их сделать.
Второе: стоит помнить, что ML-данные тоже важны. И то, как вы их обработаете, структурируете и дадите возможность другим людям их переиспользовать, может быть не менее ценным.
Следующая мысль: не нужно ограничивать себя в решении проблемы. Возможно, ваш новый подход может вывести вас на принципиально новый уровень.
И такой, немножко занудный пункт: при всем при этом не стоит забывать, что ваши решения должны работать. Можно сколь угодно классную модельку обучить в Jupyter Notebook и порадоваться, какое у нее классное качество. Но если вы не сможете довести ее до продакшена или она не будет работать — к сожалению, этот мир вы не улучшите.
В конце хотелось бы сказать следующее. Паднемия коронавируса — подходящее время для того, чтобы критически взглянуть на ваши проекты и процессы и поменять их при необходимости. Главное — стараться быть объективным, делать выводы из ваших наблюдений и не бояться изменений, стараться всё сделать лучше.
Это всё. Было очень приятно рассказать про наши наблюдения и выводы. Спасибо.

dom1n1k
kdmitrii
Так оно еще и абсалютно бесполезно если к такси привязан иностранный номер.