
Всем доброго времени суток. Сегодня хочу с вами поговорить об оптимизации. Что это такое, зачем она нужна, и самое главное, как сделать так, чтобы потом не было мучительно больно.
Первым делом разберёмся, что такое оптимизация в целом, и, что такое оптимизация в JS. Итак, оптимизация — это улучшение чего-либо по какой-либо количественной характеристике. У JS для себя выделил четыре количественные характеристики:
Объем кода — принято считать, что чем меньше написано строк кода, тем он производительнее и лучше. Мое мнение кардинально отличается, поскольку, написав одну строчку кода можно создать такую утечку памяти или вечный цикл, что браузер просто умрет.
Быстродействие (производительность) — это так называемая сложность вычислений, то есть количество действий, которое потребуется совершить парсеру для выполнения инструкции.
Скорость сборки — ни для кого не секрет, что сейчас практически ни один из проектов не обходится без сборщиков вроде Webpack или Gulp, поэтому данная характеристика отображает правильность настройки сборщика проекта. Поверьте, когда сервер чуть умнее кофемолки это становится важным.
Переиспользоваемость кода — данная характеристика показывает насколько грамотно построена архитектура для переиспользования функций, компонентов, модулей.
Рассмотрим каждую из категорий подробнее, разберём какие характеристики в неё входят и от чего зависят.
Объем кода:
- Дубляж. Сколько однотипного кода было написано в разных местах;
- Комментарии. Комментарии в коде — это хорошо, но мне встречались проекты, в которых комментариев было больше, чем кода;
- Отсутствие унификации. Наглядным примером такой проблемы являются схожие функции, имеющие нюансы в зависимости от какого-то свойства.
- Наличие мертвого кода. Довольно часто в проектах встречаются отладочные функции или функции, которые и вовсе не используются.
Быстродействие:
- Использование механизма кэширования браузера;
- Оптимизация кода в расчёте на те среды, в которых он будет выполняться;
- Наличие утечек памяти;
- Использование веб-воркеров;
- Использование ссылок на элементы DOM –дерева;
- Использование глобальных переменных;
- Наличие рекурсивных вызовов;
- Упрощение математических вычислений.
Скорость сборки:
- Количество внешних зависимостей;
- Преобразования кода. Имеется в виду количество чанков и их размер, преобразования css, склейка файлов, оптимизация графики и много чего еще.
Переиспользование кода:
- Количество компонентов;
- Повторяемость компонентов;
- Гибкость и кастомизация.
Как говорил в предыдущих статьях, чтобы что-то изменить необходимо определить отправную точку и разобраться на сколько все плохо. С чего начать столь объемный процесс? Начинайте с самого простого: ускорьте время сборки и выпиливания лишнего из проекта. Вы спросите почему стоит начать именно с этого? Из-за того, что они зависят друг от друга. Уменьшение объемов кода приведет к увеличению скорости сборки билдов, а, следовательно, увеличению вашей производительности.
Оптимизация времени сборки неминуемо знакомит нас с понятием «Холодный» билд – это процесс, когда проект стартует с нуля и вплоть до того, что затрагиваются все зависимости и целиком перекомпилируется код. Не путайте с Ребилдом — это пересборка клиентского кода без подтягивания внешних зависимостей и прочей мишуры.
Увеличить скорость сборки билда поможет:
- Использование современных сборщиков. Технологии не стоят на месте, и если у вас первый webpack, то при переезде на четвертый вы увидите приятный прирост уже ничего не делая;
- Избавление от всех мертвых зависимостей. Периодически разработчики, в попытках нащупать истину на дне банки с серной кислотой, забывают прибрать за собой после собственных экспериментов.Мой коллега, как то спросил: «Разве зависимости, которые прописаны в package.json, но не импортирующиеся нигде в коде, попадают в сбилженный бандл?». Да, в саму сборку они не будут включены, но пакет будет выкачен. Вопрос, зачем?
- Разделить сборку на несколько профилей в зависимости от потребностей. Минимально на два: prod и dev. Показательный пример: обфускация кода. На prod это обязательно к исполнению, так как меньший вес = быстрой загрузке, а вот на dev обфускация только мешает и тратит время сборки на ненужные манипуляции;
- Распараллеливания отдельных этапов сборки;
- Использование npm-клиентов, которые умеют кешировать.
Ускорение ребилда и «холодного» билда потребуют выпилить лишние комментарии и мертвые куски кода. Однако, что делать если у вас огромный проект и самому его проинспектировать не представляется возможным? В таких случаях приходят на помощь код анализаторы.
Лично я периодически использую SonarQube, не самый лучший, но гибкий. Его можно научить особенностям проекта, если таковые имеются. Периодически он вытворяет такое, что хоть стой, хоть падай, но, как и любым инструментом, им надо уметь пользоваться, и не забывать скептически относиться к его замечаниям. Несмотря на все его минусы, с поиском мертвого кода, комментариев, наличия копипаста и мелочевки, вроде отсутствия строгого сравнения, он справляется на ура.
Кардинальное отличие SonarQube от ESlint/TSLint/Prettier и иже с ними, в том, что он проверяет именно качество кода, вычленяет дубляж, сложность вычисления, а также выдаёт рекомендации по необходимым изменениям. Аналоги же просто проверяют код на ошибки, синтаксис и форматирование.
На практике сталкивался с codacy, неплохой сервис с бесплатной и платной подпиской. Он будет полезен, если надо что-то проверить на стороне, при этом не разворачивая у себя этот ‘комбайн’. Имеет интуитивно понятный интерфейс, подробное указание что не так с кодом и многое другое.
В данной статье не буду затрагивать тему настройки билда, чанков и остального, ибо все зависит от потребностей проекта и установленного сборщика. Возможно, расскажу об этом в других статьях.
Проделанные манипуляции помогли ускорить сборку — профит, но что дальше? Поскольку анализаторы умеют находить дубляж кода, то будет полезным вынести его в отдельные модули или компоненты, тем самым увеличив переиспользование кода.
Остался единственный раздел, к которому мы не прикасались — быстродействие самого кода. Сам механизм приведения в чувство производительности оного, называется всеми ненавистным словом рефакторинг. Давайте разберемся поподробнее с тем, что стоит делать при рефакторинге, а чего нет.
Жизненное правило: если работает — не трогай, не должно руководить вами в этом процессе. Первое правило в IT: сделай backup, потом сам себе скажешь спасибо. На фронте перед началом каких-либо изменений, сделайте тесты, чтобы не потерять функциональность в будущем. Затем спросите себя — как определять время загрузки и утечки памяти?
В этом поможет DevTool. Он не только покажет утечку памяти, подскажет время загрузки страницы, просадку по анимации, а если повезёт — проведет аудит за вас, но это не точно. Так же DevTools обладает приятной особенностью, такой как ограничение скорости загрузки, что позволит вам спрогнозировать скорость загрузки страницы при плохом интернете.
Мы смогли определить проблемы, теперь давайте их решать!
Для начала уменьшим время загрузки, используя механизм кэширования браузера. Браузер может все закэшировать и в дальнейшем предоставлять пользователю данные из кэша. Localstorage и sessionstorage никто у вас не отнимал. Они позволяют хранить часть данных, содействующие в ускорении SPA при последующих загрузках и сократить лишние запросы к серверу.
Считается необходимым оптимизировать код в расчёте на те среды, в которых он будет выполняться, но как показывает практика, это съедает достаточно много времени и сил, при этом не приносит ощутимого прироста. Предлагаю рассматривать это только как рекомендацию.
Естественно желательно устранить все утечки памяти. Заострять на этом внимание не стану, как их устранить думаю все знают, а если нет, то just google it.
Еще один наш помощник — веб-воркеркер. Веб-воркеры — это потоки, принадлежащие браузеру, которые можно использовать для выполнения JS-кода, без блокировки цикла событий. Веб-воркеры позволяют выполнять тяжёлые в вычислительном плане и длительные задачи без блокировки потока пользовательского интерфейса. На самом деле, при их использовании вычисления выполняются параллельно. Перед нами настоящая многопоточность. Существует три типа веб-воркеров:
- Выделенные воркеры (Dedicated Workers) — Экземпляры выделенных веб-воркеров создаются главным процессом. Обмениваться данными с ними может только сам процесс.
- Разделяемые воркеры (Shared Workers) — Доступ к разделяемому воркеру может получить любой процесс, имеющий тот же источник, что и воркер (например, разные вкладки браузера, iframe, и другие разделяемый воркеры).
- Сервис-воркеры (Service Workers) — это воркеры, управляемые событиями, зарегистрированные с использованием источника их происхождения и пути. Они могут контролировать веб-страницу, с которой связаны, перехватывая и модифицируя команды навигации и запросы ресурсов, и выполняя кэширование данных, которым можно очень точно управлять. Всё это даёт нам отличные средства управления поведением приложения в определённой ситуации (например, когда сеть недоступна).
Как с ними работать можно без проблем найти на просторах интернета.
С подходами и сторонними приблудами мы вроде разобрались, теперь предлагаю поговорить о самом коде.
Первым делом постарайтесь избавиться от прямых обращений к DOM–дереву, поскольку это трудоемкая операция. Давайте представим, что у вас в коде постоянно происходит какая-то манипуляция с каким-либо объектом. Вместо того, чтобы работать с этим объектом по ссылке, вы постоянно дергаете DOM-дерево для поиска данного элемента и работы с ним, а так мы реализуем паттерн кэширования в коде.
Вторым шагом избавьтесь от глобальных переменных. ES6 подарил нам замечательное изобретение человечества под названием блочные переменные (если перевести на простой язык — объявления переменных с var на let и const).
Ну и напоследок самое вкусное. Тут, к сожалению, не у всех хватает опыта понять нюанс. Я против использования рекурсивных функций. Да, они сокращают объем написанного кода, но, не обходится без подвоха: часто такие рекурсивные функции не имеют условий выхода, про них просто-напросто забывают. Как в присказке “молотком можно палец разбить, но это проблема не молотка, а владельца пальца” или анекдоте про кошек: рекурсивные функции — это не плохо, их надо уметь готовить.
Несмотря на всю мощь современных front-end приложений, не надо забывать об основах. Явным примером расточительства и иррациональности служит добавление в начало массива новых элементов. Кто знает, тот понял, а тот, кто нет — сейчас расскажу. Всем известно, что у элементов массива есть свой индекс, и когда мы собираемся добавить новый элемент массива в его начало, то последовательность действий будет такова:
- Определение длины массива
- Нумерация каждого из элементов
- Сдвиг каждого из элементов массива
- Вставка нового элемента в массив
- Повторная индексация элементов массива.
Итоги:
Пора закругляться, а для тех кому удобен формат памяток, держите перечень шагов, благодаря которым вы сможете понять на каком вы сейчас этапе оптимизации и что делать дальше:
- Определяем на сколько все хорошо/плохо, снимаем метрики.
- Выпиливаем все лишнее: неиспользуемые зависимости, мертвый код, ненужные комментарии.
- Настраиваем и ускоряем время сборки, настраиваем разные профили для контуров.
- Анализируем код и решаем какие части будем оптимизировать и переписывать.
- Пишем тесты, чтобы не допустить потерю функциональности.
- Запускаем рефакторинг, избавляемся от глобальных переменных, утечек памяти, дубляжа кода и прочего мусора, и не забываем про кэширование.
- Упрощаем сложность вычислений и выносим всё возможное в веб-воркер.
Все не так сложно, как кажется на первый взгляд. Ваша последовательность наверняка будет отличаться от моей, хотя бы потому что у вас своя голова на плечах. Вы добавите новые пункты или, наоборот, сократите их количество, но основа списка будет похожей. Я специально описал деление так, чтобы данную активность можно было запустить в параллель с основной работой. Зачастую заказчик не готов платить за переделки, согласны?
И напоследок.
Я верю в вас, и в то, что у вас всё получится. Считаете меня наивным? Полагаю, вы удивитесь, но раз вы нашли эту статью, прочитали ее до конца, значит (у меня для вас есть хорошие новости) у вас есть мозги, и вы стараетесь развивать их. Успехов в столь нелегком начинании, как оптимизация фронта!
Комментарии (13)

vintage
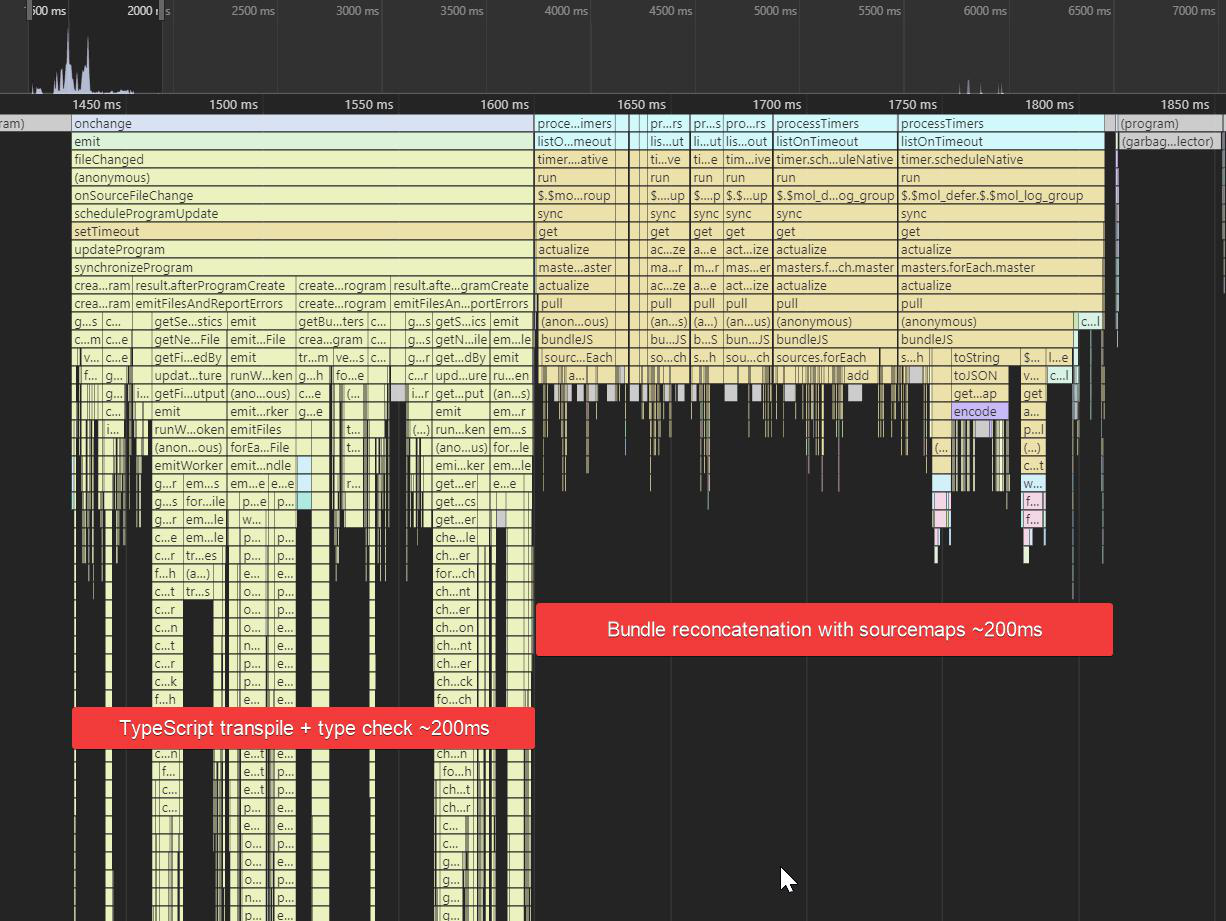
27.09.2019 12:43Скорость сборки — ни для кого не секрет, что сейчас практически ни один из проектов не обходится без сборщиков вроде Webpack или Gulp, поэтому данная характеристика отображает правильность настройки сборщика проекта.
Как же классно использовать сборщик, который не требует настройки. И уж тем более угадывания его "правильных" параметров в тьюринг-полном конфиге.
Вот, например, я взял реализацию простенького приложения realworld на react+redux+typescript, который основан на create-react-app, который использует webpack@4. И вижу такую картину при изменении исходника: где-то за пол секунды ребилдится бандл, но типы при этом не чекаются, в результате чего приложение стартует, благополучно падает и только через 2 секунды по вебсокетам прилетает результат тайпчека:

В сумме весь процесс от изменения до сообщения об ошибке занимает 4 секунды. Как это всё настроить так, чтобы тайпчекалось оно всё сразу за те же пол секунды и время до вывода ошибки было не более секунды, как тут:

bgnx
27.09.2019 14:50Ну и напоследок самое вкусное. Тут, к сожалению, не у всех хватает опыта понять нюанс. Я против использования рекурсивных функций. Да, они сокращают объем написанного кода, но, не обходится без подвоха: часто такие рекурсивные функции не имеют условий выхода, про них просто-напросто забывают.
Если у рекурсии не будет условий выхода то она будет выполняться бесконечно. И статический анализатор мог бы проверить что условий выхода нет и подсветить ошибку в редакторе.
Вообще у меня есть мнение что для высокоуровневого языка программирования надо запрещать как раз таки циклы и оставить рекурсию как единственное средство для итераций. Суть такого решения в том что не нужно для языка программирования иметь несколько способов сделать одно то же — раз мы одну и ту же задачу можем решить и с помощью рекурсии и с помощью циклов то очевидно что одно их этих средств является избыточным. И появляется вопрос что убрать — циклы или рекурсию. Очевидно что рекурсия это более высокий уровень абстракции (рекурсия сводится к циклам через стек) — а значит более мощный и удобный инструмент. А что касается производительности то это уже задача компилятора (или статического анализатора с транспиляцией) преобразовать tail-call рекурсию в цикл без стека или провести кучу других оптимизаций. Что же касается циклов то мало того что в том же js для них есть разные избыточные синтаксические конструкции (while, do-while, for) да еще и с кучей нюансов и вопросов на который не каждый js-миддл ответит правильно (https://www.youtube.com/watch?v=Nzokr6Boeaw)vintage
27.09.2019 17:25Как компилятору соптимизировать такой код?
function fib(n) { return n <= 1 ? n : fib(n - 1) + fib(n - 2); }bgnx
27.09.2019 19:57Не знаю насколько сейчас продвинулись компиляторы в анализе но если человек будет оптимизировать код вручную то с рекурсией он получит аналогичную производительность (если конечно поддерживается базовая оптимизация хвостовой рекурсии)
Например n-ное значение последовательности фибоначчи
function fib(n) { return n <= 1 ? n : fib(n - 1) + fib(n - 2); }
человек заоптимизирует через цикл так
function fib (n){ if(n <= 1) return n; let fib = [0, 1]; for (let i = 2; i <= n; i++) { fib[i] = fib[i - 2] + fib[i - 1]; } return fib[fib.length - 1]; }
но с рекурсией можно записать так
function fib (n){ if(n <= 1) return n; let fib = [0, 1]; let i = 1; let recur = () => { i++; fib[i] = fib[i - 2] + fib[i - 1]; if(i < n) recur(); }; recur(); return fib[fib.length - 1]; }
И любой компилятор который умеет в хвостовую рекурсию будет выполнять этот код так же быстро как и с циклом.
Что касается удобства — да, получается на пару строчек больше но сейчас и так мало где можно встретить ручные циклы (обычно всякие .map(), .filter и т.д) так что экономия пары строчек для кода который будет занимать меньше 1 процента от всего проекта не имеет смысла. Зато мы избавились от кучи лишних синтаксический конструкций в языке (for, while, break, continue и labels) и упростили не только язык но и работу статическому анализатору (так как ему теперь нужно будет заняться анализом только рекурсии а не учитывать еще кучу кейсов и контрукций обычных циклов)
Evil_Evis Автор
27.09.2019 20:12Я не утверждаю что анализатор кода панацея, но когда большей проект и написан не вами а файлов очень много то он будет неплохим подспорьем. Так же анализатор можно обучать.То есть написать свои правила.
Evil_Evis Автор
27.09.2019 20:17Я и не говорю что рекурсия плоха, я говорю о том что в не особо умелых руках она может сыграть плохую шутку со своим создателем. И да анализатор такому можно научить, по поводу IDE не встречал что бы они такое подсвечивали.

JamesJGoodwin
29.09.2019 17:59>Еще один наш помощник — веб-воркеркер
Не забывайте, что в Воркер нужно передавать только сериализованные данные или строки. Запихнуть туда json-объект для обработки не выйдет, перед этим его нужно превратить в строку, а на другом конце распарсить, что уже будет в разы сложнее для браузера по сравнению с оригинальным алгоритмом.
vintage
Ну и представьте себе, что будет, если вы напишете 10 таких строчек кода.
Evil_Evis Автор
Не совсем понял вас, вы со мной не согласны или что имеете ввиду?
vintage
Я указываю на ошибку в логике рассуждений.
Evil_Evis Автор
В чем ошибка, критерий есть но я с ним не согласен о чем и сообщаю. что если одна строка может повесить браузер то 10 и подавно.
vintage
10 сделают это в 10 раз быстрее.
Evil_Evis Автор
я с этим и не спорю, я собственно и привел этот пример для наглядности что достаточно одной строчки что бы сделать бяку.