

23-24 сентября в Санкт-Петербурге проходила конференция Saint TeamLead Conf 2019. «Флант» принял в ней активное участие: Игорь Цупко (наш директор по неизвестному) провел митап, на котором участники разобрались в способах поиска и выявления тайных знаний внутри организации, а Сергей Гончарук (менеджер проектов) выступил с докладом «Управление распределенной командой в режиме многопроектности». По традиции, мы публикуем обзор доклада и его видео (~37 минут).
«Распределенная команда» и «многопроектность»
Под распределенной командой разные компании понимают очень разные вещи — например, филиальную сеть или офис и удаленных работников… Но в нашем случае офиса в его «настоящем» понимании вообще нет.

Сейчас у нас работает более 80 сотрудников, которые живут в более чем 20 городах России и не только. Большинство из нас видит друг друга «в живую» только 2 дня в году, на дне рождения «Фланта».
В остальное время мы живем в Москве, Самаре, Тюмени, Нижнем Новгороде или любом другом городе, работаем под пение птиц или запах кофе. Вместо аренды места, инвестируем деньги во что-то действительно полезное. И так как все работают удаленно, у нас нет деления на «филиалы» или «касты».
А главное — мы нанимаем лучших, несмотря ни на какие границы! Вот что значит «распределенность» в нашем понимании.

Давайте теперь разберемся с многопроектностью, но для начала важно немного погрузиться в устройство «Фланта».
Мы инженерная компания, у нас много инженеров. Пять-семь инженеров под управлением тимлида и менеджера составляют команду. Таких команд несколько, и у каждой команды есть свой набор из проектов.

Проект для нас — это инфраструктура клиента для одного продукта либо одной команды разработки. То есть у проекта есть четкие границы, но нет ограничений по росту и развитию!

У каждого проекта есть свои потребности, которые нужно как-то донести до команды
Это делает менеджер. Таковы основы «многопроектности».
Теперь, когда у нас есть общее понимание терминов из названия доклада, вопрос: что нужно, чтобы в таких условиях всё не просто работало, а работало хорошо?
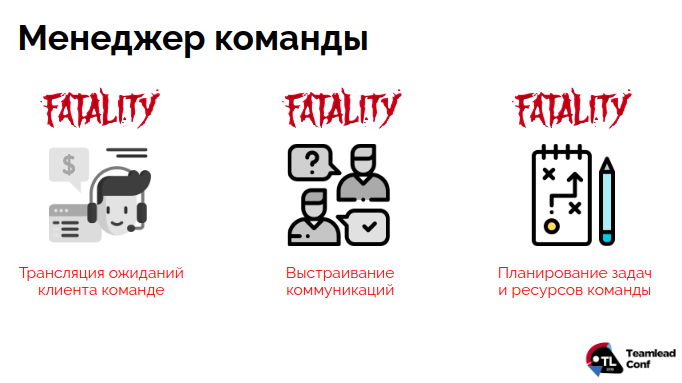
За решение этого вопроса отвечает менеджер команды. Быть «переводчиком» с клиентского на инженерный — это одна из его ключевых компетенций. Вторая — организация конструктивного общения внутри команды и с клиентами. А третья базовая компетенция — нахождение баланса между потоком дел и реальными возможностями инженеров:

Разберем подробнее каждую компетенцию.
1. Трансляция ожиданий
Даже у одного и того же клиента могут быть противоречивые ожидания. Например, бизнес клиента требует, чтобы приносящий деньги production был стабилен. И к тому же, постоянно пополнялся новыми функциями, которые помогают увеличить выручку.
Ну, а если уж и случится какая-то авария (бизнес готов к тому, что аварии бывают), то она будет устранена в максимально короткий срок. Звучит очень предсказуемо, не так ли?
Но у этого же клиента есть и разработчики. И их ожидания, оказывается, совсем иные! Для разработчиков dev важнее production’а (ведь на них тоже давит бизнес), а еще они ждут, что любая их просьба будет услышана и сделана прямо сейчас (обычно это описывается фразой «ведь там дел на 5 минут»).
Единственное, что объединяет и бизнес и разработчиков в требованиях, — и те, и другие ожидают, что плановые задачи будут сделаны точно и в обещанные сроки.

Посмотрим на картину в целом… Да тут же полно взаимоисключающих параграфов!
- Добавление новых фич всегда добавляет и новые точки отказа. Бабах! И production работает нестабильно после пятничного релиза.
- Наши инженеры максимально оперативно выполняли в течение дня всё, о чем просят разработчики, а плановые задачи так и остались нетронутыми из-за этого.
- Или вот такая история: стабильности какого окружения уделить больше внимания? Мы стабилизировали dev, выделив на это ресурсы, но у нас после очередного выката начал падать production!
- Частый кейс: сломался production и вся команда ушла его чинить. При этом, конечно, нет продвижения по плановым задачам, и даже разработчики из Индии в чате уже перешли на русский мат, потому что не могут дождаться ответа.
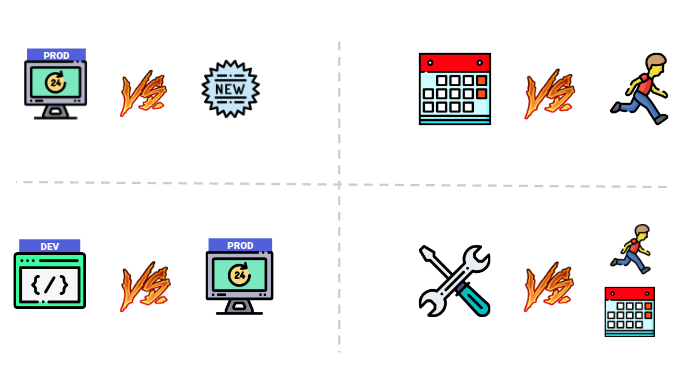
И мы понимаем, что сами требования противоречивы, а значит — напрямую транслировать их невозможно.
2. Коммуникации
В трансляции ожиданий действительно есть проблемы. Хорошо, может быть, тогда хотя бы с коммуникациями все проще?
Для общения между собой и с клиентами мы используем Slack для текста и Google Meet для митингов и случаев, когда сказать проще, чем написать. Но в чате мы часто получаем сообщения, которые не несут в себе полезного смысла или содержат столько ошибок, что смысл распознать сложно!

Почему мы обращаем на это внимание? Дело в том, что, например, только за июль 2019 года мы получили 1993 обращения от клиентов в Slack, требующих обязательной реакции. И, естественно, с ростом количества клиентов есть и устойчивый тренд по росту количества таких обращений. Около 165 инженеро-часов мы потратили в июле на реакцию на такие обращения. А ведь по каждому обращению требовалось еще и что-то сделать!
Нам очень жаль, когда время инженеров, которое могло бы быть инвестировано в плановые задачи, реакцию на другие обращения или даже на починку аварий, тратится впустую.
Проблема в чатах очевидна, но у видеоконференций наверняка нет проблем?
Мы говорили выше, что используем Google Meet для ежедневных командных митингов, а остальное время делаем задачи, которые разобрали на митинге. Каждый день мы тратим на митинги порядка часа. Мы стараемся тратить на непосредственную работу не менее семи часов в день, то есть на выполнение задач остается 6 часов. Но у нас очень разные по длительности задачи.
Вот и получается, что за час митинга мы могли бы завершить несколько небольших, но, вероятно, важных для наших клиентов задач. И нам надо понять, действительно ли нужны часовые митинги или все же лучше пойти и поработать это время?
Если попробовать собрать проблемы коммуникаций вместе, получаем, что чат генерирует бесполезные прерывания и регулярные митинги «отъедают» рабочее время.

Эффективные коммуникации не выстраиваются сами по себе.
3. Планирование
Что ж, нам надо решать проблемы в коммуникациях и трансляции ожиданий, но в планировании, наверное, нет никаких подводных камней? Давайте разберемся.
Каждый день создается большое количество новых задач. Хотелось бы, чтобы мы закрывали задачи так же быстро, как они растут. Но в жизни идеал редко бывает достижим. Во-первых, в инфраструктуре иногда что-нибудь да ломается. Во-вторых, всегда есть какие-то мелкие дела, которые проще сделать сразу. В-третьих, есть задачи, о решении которых мы договорились на командном митинге:

А иногда случается так, что из-за аварий и дерганий по мелочам до плановых вообще не удается добраться! При этом новые задачи не перестают прибывать — все обещанные сроки срываются.
Наш рецепт
Но на все проблемы с трансляцией ожиданий, с коммуникациями и планированием, методом набивания шишек удалось получить, как нам кажется, правильный ответ.

Одним из ключевых бизнес-процессов, затрагивающих все три базовые компетенции, является командный митинг. И у нас появилось предположение, что если сделать командный митинг эффективным мы сможем достигнуть 80% результата двадцатью процентами усилий? Мы проверили эту теорию.
Как вы помните, у нас есть команда, обслуживающая свой набор проектов. И у нее есть некий перечень требований от этих проектов. Но каждое требование, как правило, лишь одно в цепочке взаимосвязанных задач. И так в каждом проекте! И прежде, чем взять в работу новую задачу, нам надо понимать, сделали ли мы предыдущий этап?
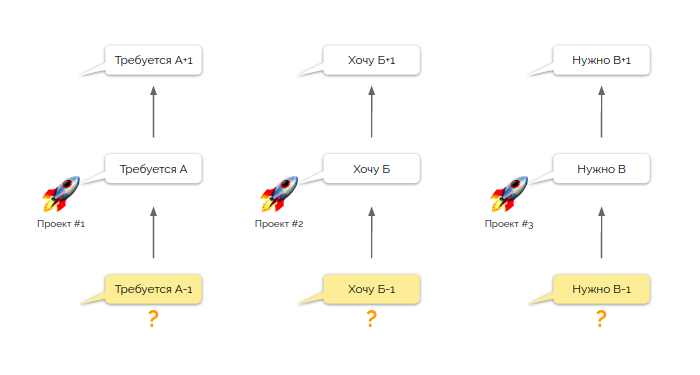
Вчера задачу А-1 выполнял Егор, задачу Б-1 — Семен, а задачу В-1 — Жанна. Но как нам погрузить всех инженеров во все проекты настолько глубоко, чтобы Егору удалось успешно справиться с задачей Б, а Семёну — с двумя небольшими задачами А и В. «Зачем все эти сложности?» — спросите вы. Да дело в том, что Жанна сегодня в отпуске и плановых задач выполнять не будет!
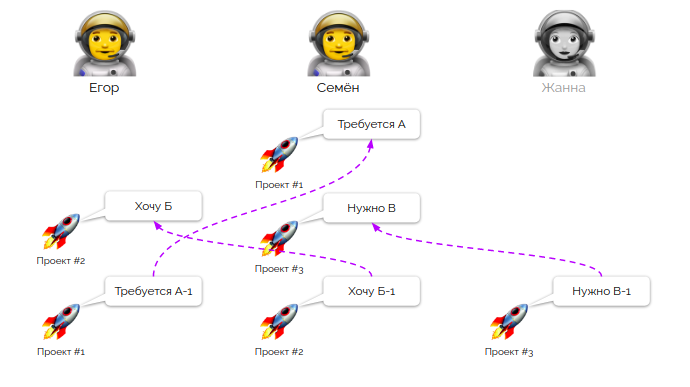
В нашем фокусе внимания много подобных задач. В среднем в каждую команду мы получаем около 25 новых задач каждый рабочий день. И так как задач много, связи между ними запутаны и нет понимания, выполнены ли все задачи предыдущего дня. Для того, чтобы распутывать все это, нужен командный митинг, причем каждый рабочий день, иначе мы не сможем управлять этим потоком.
Учитывая объемы потока, к митингу стоит заранее подготовиться. Мы на подготовке без инженеров не сможем понять, какие именно задачи сделаны полностью, а какие — нет. И, конечно, не сможем передать знания от инженера к инженеру. Но нам однозначно по силам определить приоритеты взятия новых задач в работу.
Приоритезация задач
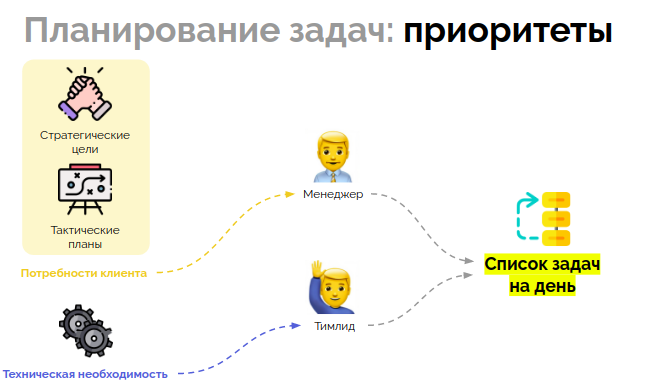
На чем мы основываемся при приоритезации задач? Во-первых, у нас есть стратегические договоренности с клиентом о целях, которые нужно достичь. Во-вторых, раз в неделю мы уточняем тактические планы на online-встрече с заказчиком. Потребности клиента при подготовке как раз отстаивает менеджер, а техническую необходимость и порядок выполнения той или иной задачи — тимлид команды. Именно так, на основании паритета мнений тимлида и менеджера, формируется список задач на день.
Культура проведения командных митингов
Как только список задач на день определили, чтобы уточнить, что сделано, и погрузить в подробности коллег, начинаем командный митинг, на котором каждый инженер должен подробно рассказать, что он сделал вчера, а вся команда — услышать и, главное, понять произошедшие изменения. Но это проще сказать, чем сделать.
Мы ввели ряд культурных особенностей проведения митинга, которые позволили достигнуть требуемого результата:

В начале митинга, пока все собираются, мы тратим 10-15 минут на разговоры о жизни. О новостях и событиях, не связанных с работой, об увлечениях коллег. Так инженеры, которые находятся в разных городах и почти не видятся, становятся приятелями или даже друзьями. И эти 10-15 минут в день помогают команде быть более сплоченной.
После тимбилдинг-беседы приступаем к содержательной части. Вернемся немного назад.
Помните вот эту иллюстрацию? Дело в том, что ни Семен, ни Егор до начала митинга не знают, какие задачи и в каких проектах они будут выполнять сегодня. По целому ряду причин: отпуска, командировки, болезнь, дежурства и т.п. — задача может менять исполнителей изо дня в день, пока не будет полностью решена. И каждый инженер понимает, что сегодня задача может быть назначена и на него, то есть все инженеры уже изначально заинтересованы вникнуть в подробности каждой задачи.
Мы разбираем на митинге всей командой возникшие блокировки. Мы настаиваем, чтобы в решении проблемы докладчика приняла участие вся команда. Так мы мотивируем погружаться в задачи и решать их вместе.
Если команда работает в офисе, неформальное общение часто происходит «у кулера». Но и в распределенной команде потребность в таком общении существует. Именно поэтому во время обсуждения задач разговор зачастую утекает куда-то не туда. Но мы пресекаем любые отвлечения. Как именно? Нам это удается довольно легко: ведь для отвлеченных разговоров есть специально выделенное время, а сейчас — время работы. Поэтому даже обычного устного «давайте по делу» хватает, чтобы все вернулись к деловой повестке. Пресекая отвлечения в процессе разбора задач, мы настраиваем команду на рабочий лад.
Мы стараемся контролировать время доклада каждого инженера. Порой для погружения в детали нам нужен длинный и подробный рассказ о задаче. Тем не менее, в большинстве случаев, мы стараемся не растянуть митинг.
Эффективные митинги — серебряная пуля?
Благодаря подготовке к митингу на основе паритета мнений тимлида и менеджера и нашим культурным особенностям проведения митинга мы действительно сделали их эффективными. Но получилось ли закрыть 80% по всем компетенциям? Не совсем.
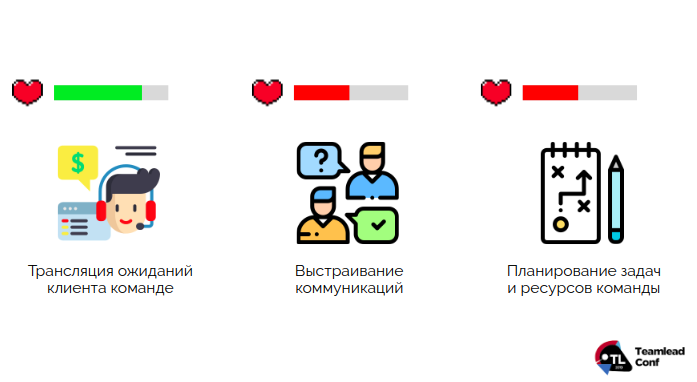
Мы хорошо поработали с трансляцией ожиданий, но в коммуникациях все еще проблемы с неинформативными сообщениями в чатах, а в планировании остались прерывания, которые не дают эффективно делать плановые задачи.
Да, но ведь и неинформативные сообщения в чате — тоже прерывания. И нам необходимо найти механизм, который поможет нам эффективно обрабатывать прерывания всех видов.
Борьба с прерываниями
Мы подумали, а что, если у нас будет отдельный человек, который будет «закрывать» собой команду, работающую над плановыми заданиями от потока прерываний?

Идея не новая и в общем хорошая, но кто именно будет это делать? Мы рассматривали два варианта: поиск и найм такой службы или использование уже имеющихся инженеров. Поиск новых людей требовал времени и финансовых ресурсов, а существующие инженеры уже были «проверены в бою» и погружены во все проекты команды. Поэтому вариант с наймом новых людей был отвергнут.
Осталось определиться с вопросом, как организовать такую службу из текущих инженеров. Тут решение было на поверхности: просто применили дежурства по графику, с ротацией инженеров из команды. Само расписание дежурств мы ведем в Google Calendar, плюс настроили уведомления в Slack о том, кто дежурит сегодня.
Казалось бы, все теперь должно быть отлично? Ура? Нет, на самом деле осталась проблема. Помните, чуть раньше мы говорили, что только в Slack получаем почти 2000 обращений в месяц, а это около 16 обращений в день в каждую команду. Но кроме Slack дежурный должен будет обработать сообщения и от систем мониторинга, а в день это:
- 112 — от Prometheus;
- 16 — от okmeter;
- 25 — от систем внешнего blackbox-мониторинга;
- 14 — от различных кастомных скриптов;
- и даже 2 телефонных звонка от клиентов.
Это же 198 прерываний каждый день из разных источников! Но на самом деле источников еще больше:
- Prometheus есть почти у каждого клиента;
- и Okmeter установлен у каждого клиента;
- а вот кастомных скриптов даже у одного клиента может быть сколько угодно…
Чтобы без волшебства и суперспособностей с этим справился любой инженер из команды, мы собрали алерты от всех источников прерываний в одном месте. Этот инструмент мы назвали Madison, а каждое сообщение в него — Инцидентом.
Но Madison лишь собирает инциденты и хранит состояние о них. Нам же нужно понимать, какой инцидент брать в работу первым, то есть произвести триаж, иметь четкий порядок обработки и эскалации, чтобы легко выполнить его в стрессовой ситуации.
Мы создали и такой инструмент — назвали его Polk:
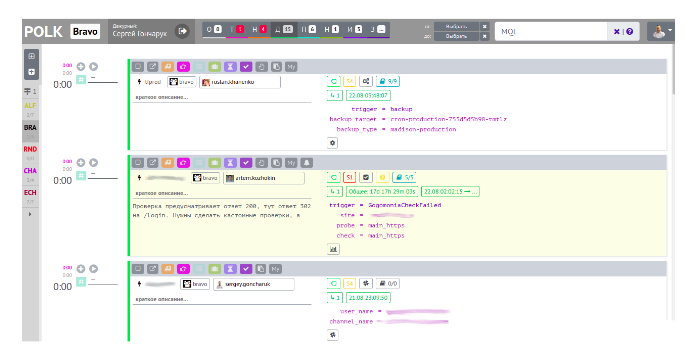
Polk — это рабочее место дежурного инженера. Он позволяет дежурному фокусироваться только на инцидентах, не отвлекаясь на плановые задачи, получать инциденты из всех источников в одном месте, помогает с определением критичности инцидента по заранее определенному Severity, имеет набор четко описанных статусов и алгоритм обработки, определяющий движение по этим статусам.
Технические и культурные особенности общения в чатах
Отлично: теперь дежурный, снабженный таким мощным инструментом, действительно закрывает команду от прерываний. Но даже с таким инструментарием дежурство выматывает, а бесполезные прерывания только подливают масло в огонь.

Для борьбы с бесполезными прерываниями в чате мы можем применить небольшой набор технических средств, но основное решение этой проблемы точно лежит в культурной плоскости.
С технической точки зрения в Slack мы разделили информацию по проектам, создав раздельно канал для общения с представителями заказчиков, и по каждому проекту — канал для обсуждения инженерами работ по нему. Еще мы написали бота
@flant, при обращении к которому в Polk автоматически создается инцидент, который обрабатывает дежурный.
Кроме того, мы рекомендовали клиентам использовать
@flant, а @channel (событие, оповещающее всех участников канала) и @here (событие, оповещающее всех участников канала, находящихся online) использовать только в тех редких и исключительных случаях, когда без них действительно нельзя обойтись (например, когда бот @flant недоступен).В первый день нашего сотрудничества с клиентом мы размещаем в канале подробную инструкцию по взаимодействию. И на первой же регулярной встрече обязательно обсуждаем взаимодействие, в том числе и разницу между
@channel, @here и @flant. В частности, мы акцентируем внимание на том, что обращение к
@flant для нас, в первую очередь, это действие с обязательной реакцией, а @channel и @here для большей части команды — просто прерывание, которое к тому же безадресно и может быть проигнорировано, отвлекая при этом всю команду от решения плановых задач, в том числе по данному проекту.
Но в чат приходят новые коллеги со стороны клиентов, которые не знают о боте. Другие просто забывают. Если так происходит, мы мягко напоминаем о его существовании.
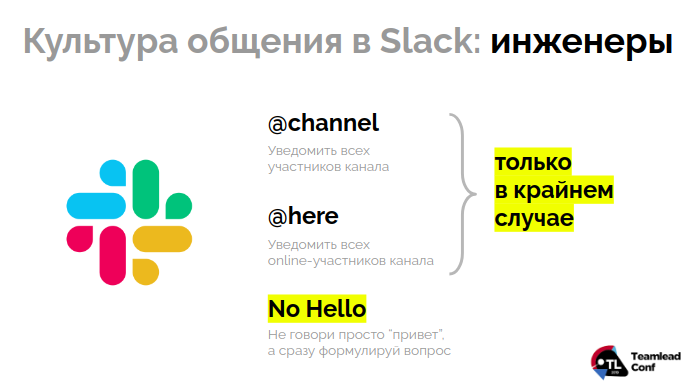
Для общения же между инженерами мы используем те же правила для
@channelи
@here: не использовать их без крайней необходимости. И еще, мы настаиваем на придерживании правила «Не говори просто „привет“ в чате — сразу сформулируй мысль». Это правило обязательно к прочтению всеми новичками. Тем, кто его забыл, об этом обязательно напомнят — если потребуется, развернуто.Итого: с введением дежурств и исправлением проблем общения в чате мы справились и с большей частью бесполезных прерываний и с влиянием прерываний на выполнение плановых задач.

Прокрастинация и блокировки
Мы проверили, как улучшились наши показатели после этого: действительно, они стали явно лучше, но все еще осталась проблема в планировании.
Когда командный митинг закончился, приходит время поработать. Но зачастую инженеры, особенно работающие удаленно, склонны прокрастинировать. Или, во время работы, упереться в проблему и ходить по кругу в попытке ее решить.
Давайте попробуем разобраться с прокрастинацией. Как ее побороть? Задач в Redmine (нашем трекере задач) слишком много — нужен фокус на тех, что будут в работе именно сегодня. И даже среди них нужно понять, какие задачи сделать в первую очередь, то есть — определить приоритеты. И идеально, если примерно запланировать время, которое мы готовы потратить на каждую задачу…

Мы создали инструмент, который помогает все это решить, и назвали его Ford:

Именно в нем инженер получает задание на рабочий день в виде карточек, расположенных в приоритетном порядке. У всех плановых задач мы проставляем примерное время, которого инженер должен придерживаться при их решении. Инженер учитывает время, которое он потратил на решение задачи. И если время примерно совпало, а задача не решена — это маркер того, что инженер зашел в тупик.

Что с этим можно сделать? Кроме приоритета, в котором расположены карточки,
мы ввели еще и категории приоритетов, выделили их цветами:
- Серое поле используется для обычных, плановых задач;
- Зеленое поле — для задач, которые в текущем дне стоит начинать делать, только если закончатся задачи во всех остальных полях;
- Желтое поле — для задач, которые вдруг внепланово возникли в течение дня;
- Красное поле — для задач, требующих решения до конца текущего рабочего дня.
Если инженер заблокировался по задаче в сером и зеленом полях, то он просто должен начать следующую задачу, а блокировку разобрать на следующем командном митинге.

Но очевидно, что если инженер заблокировался по задачам в желтой или красной зонах, то ждать следующей встречи не стоит: нужно звать на помощь команду в соответствующем канале для общения инженеров по проекту, в котором поставлена задача. И, в соответствии с нашей культурой, инженеры команды или тимлид обязательно придут на помощь.

Стоит оговориться, что возможности Ford значительно шире и мы затронули только «верхушку айсберга», которую вы можете реализовать с помощью других, открытых инструментов.
Итоги
Получается, что для борьбы с прокрастинацией и блокировками мы используем Ford как техническое решение и простые правила в командной культуре.
Помогли ли нам эти инструменты? Да! Но почему-то не на 100%?
Дело в том, что мир меняется и движется вперед. И мы в этих условиях тоже меняемся, стремимся к идеалу, но он, как известно, недостижим.
О достижении идеалов и роли менеджера
Всё великое, что создано человечеством за все время его существования, сделали команды профессионалов, у которых были крутые менеджеры.


Мы, «Флант», тоже команда профессионалов. И было бы классно, если бы крутых менеджеров в нашей команде стало больше. Приходите к нам работать и помогать делать наши процессы лучше:

Видео и слайды
Видео с выступления (~38 минут):
Презентация доклада:
P.S.
Читайте также в нашем блоге:
Комментарии (17)

maxim_ge
02.10.2019 12:28+1а @channel (событие, оповещающее всех участников канала) и here (событие, оповещающее всех участников канала, находящихся online) использовать только в тех редких и исключительных случаях, когда без них действительно нельзя обойтись
Интересно, как это сочетается с «безадресно и может быть проигнорировано»? Вот наступил редкий исключительный случай и как раз в этом случае сообщение может быть проигнорировано…
gserge Автор
02.10.2019 13:07+1тут «тонкий лёд»: может быть проигнорировано тем, кто занимается задачей, но не будет проигнорировано дежурным инженером. А вот прерывание будет создано всем (
maxim_ge
02.10.2019 12:31+1Задач в Redmine (нашем трекере задач) слишком много — нужен фокус на тех, что будут в работе именно сегодня. И даже среди них нужно понять, какие задачи сделать в первую очередь, то есть — определить приоритеты. И идеально, если примерно запланировать время, которое мы готовы потратить на каждую задачу…
Неужели нет такой базовой функциональности в Redmine? Или какая-то особенность ее реализации не устраивает?gserge Автор
02.10.2019 13:08+1К сожалению, реализация этого в redmine, по опыту, оказалась крайне неудобной. Изначально именно ею и пользовались.

JordanoBruno
03.10.2019 09:43+1Вообще-то есть, даже поле “приоритет” есть по умолчанию. А уж заставить исполнителей менять статус задачи на «in progress» — не самая сложная задача.
gserge Автор
03.10.2019 09:49Да все так, но неудобно релизованы эстимэйты, спенты. И вообще все неудобно. В общем, мы старались сделать так, чтобы инженер максимум отдавал сути задачи, а все, что связано с flow задачи было максимально просто и интуитивно.
JordanoBruno
03.10.2019 09:55-1Мне кажется, Вам просто хотелось создать свои
велосипедыинструменты для управления задачами, slack-бота без объективных на то причин и расчета стоимости создания, внедрения и поддержки данных решений.gserge Автор
03.10.2019 10:08Это ощущение появилось у вас от того, что вы увидели картину сейчас. Но инструменты появлялись эволюционно. И в то время мы пробовали жить в просто google docs, redmine, trello, etc… И в итоге пришли к тому, что нужно что-то своё, что будет укладываться в наш flow. Мы продолжаем использовать redmine, но наш redmine уже имеет интеграции с остальными инструментами. Slack-бот — это лишь инструмент для сбора инцидентов в одном месте.
JordanoBruno
03.10.2019 10:17Изобретение велосипедов — вполне понятный и объяснимый этап в жизни любого разработчика и даже менеджера. Сам такой этап прошел, каюсь. Велосипеды имеют право на жизнь, в некоторых ситуациях они вполне оправданы, но текущая ситуация — совершенно не тот случай и я бы сильно рекомендовал обойтись стандартным функционалом с минимальными доделками(веб-хуки и т.д.). Основная причина в этом — то, что велосипеды придется развивать и поддерживать кому-то, править там баги, проводить тесты, то есть это по сути еще одни затраты по деньгами и времени для компании. Впрочем, иногда из таких побочных продуктов вырастают весьма привлекательные стартапы(вспомним тот же Slack). Так же минус в том, что большинство новых сотрудников нужно обучать кастомным вещам — это затраты и время.

shurup
03.10.2019 10:25велосипеды придется развивать и поддерживать кому-то, править там баги, проводить тесты, то есть это по сути еще одни затраты по деньгами и времени для компании
Спасибо за совет, но я искренне удивлён, если вы думаете, что мы это всё не понимаем :-) Мы не первый год на рынке, да и разработкам этим уже далеко не один год. Так что не просто понимаем, а видим в конкретных цифрах (сколько времени уходит на их развитие и какую пользу они приносят бизнесу). Возможно, у вас просто неполное понимание конкретно нашей картины и/или другой опыт: другие масштабы разработок, компании, ещё что-то другое…JordanoBruno
03.10.2019 10:31Это хорошо, что у Вас есть цифры, если не сложно, сколько стоило создание данных инструментов и их поддержка в год. Думаю, такие цифры будут полезны всем, кто еще только думает создать свои
велосипедыинструменты.
shurup
03.10.2019 10:14Странное у вас представление о бизнесе («расчётах стоимости»), если автор выше уже написал, что изначально мы пользовались тем, что предоставляет тот же Redmine из коробки… а уж за 8+ лет его использования (я даже не поленился проверить дату первого issue в нашей базе) — и не из коробки тоже, поверьте :-))
У нас предостаточно более целевой (= приносящей прямые деньги) работы, чем разработка внутренних сервисов.
Мы, даже будучи большими любителями Open Source и обладая огромной компетенцией в администрировании, в своё время отказались от разновидностей чатов типа self-hosted в пользу платного(!) Slack. И за много лет ещё не передумали…
TL;DR: если какие-то внутренние разработки появляются — на то есть очень весомые бизнес-причины.JordanoBruno
03.10.2019 10:19если какие-то внутренние разработки появляются — на то есть очень весомые бизнес-причины.
Дело в том, что я даже прекрасно знаю, какие бывают бизнес-причины и какие последствия от таких решений. Впрочем, каждый волен идти своим путем, раз уже так желает )
JordanoBruno
03.10.2019 09:41+1Бабах! И production работает нестабильно после пятничного релиза.
Пятничный релиз… А Вы знаете, как разнообразить себе выходные )
UnnamedUA
Не нашел у вас на Github-е ни Polk ни Ford))
gserge Автор
Всё так, эти инструменты пока не готовы к публичному релизу.