
«Мне надо сконвертировать 714 147 TIFF-файлов в PDF в один прогон. Может ли какая-то из ваших программ это сделать?», — пишет нам Дэвид Шэнтон, старший инженер-разработчик из компании TSI Healthcare.
Часто ли вы сталкиваетесь с файл-процессингом такого масштаба? Вот и мы не часто. Сначала не всё получилось, но в итоге (не без помощи самого клиента) мы победили. Надеюсь, эта история будет полезна тем, кто разрабатывает десктопные и серверные приложения под Windows.
TLDR: два важных фикса позволили нам:
У клиента уже был установлен DocuFreezer. Это программа для конвертации картинок и документов. Только загрузка списка из 714 тысяч файлов занимала целый день! И скорость добавления новых файлов (генерация списка) снижалась по мере увеличения этого списка.
Возникли проблемы с оперативной памятью — загруженность иногда достигала 5-7 Гб. При нажатии паузы или манипуляциях с окном программы, оперативная память вновь высвобождалась, но это не решало проблему.
Мы предложили клиенту утилиту командной строки 2PDF. Судя по первым тестам, 2PDF чуть лучше справлялся с задачей, но возникла проблема, схожая с работой DocuFreezer. В начале обработка шла быстро, но затем замедлялась.
Изначально время обработки 104 000 TIFF-файлов у клиента занимало 50 часов и 15 часов с помощью 2PDF и DocuFreezer соответственно. При обработке из командной строки не было проблем с созданием списка документов, но процесс конвертации замедлялся со временем. А DocuFreezer замедлял работу при генерации списка документов, однако конвертировал файлы с примерно постоянной скоростью (около 7000 в час). Тем не менее, обработка в обоих случаях была очень долгая, что неприемлемо.
Сначала мы предположили, что «бутылочным горлышком» в случае с обеими программами является Microsoft .NET Framework. Представьте, что у вас в обычной папке Windows лежит не 10, не 100, а 700 000 файлов. И попробуйте что-нибудь простое с ними сделать, например, отсортировать их по имени в Windows File Explorer или Total Commander. Здесь примерно то же самое.
Но главные проблемы скрывались в другом.
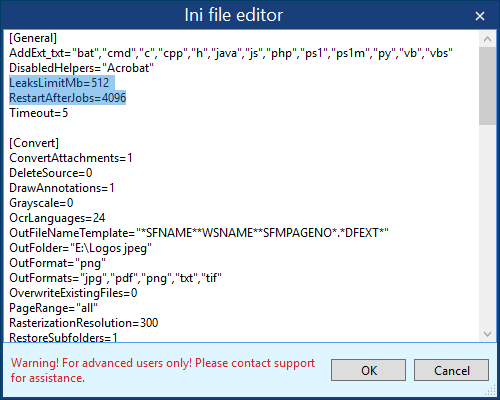
Исполнительная часть программы, работающая в отдельном процессе, теряет производительность из-за накопления memory & resource leaks. Из-за этого падение производительности становится заметным после 120-тысячного файла. В итоге мы внедрили решение, благодаря которому программа перезапускала «движок» при таких вот утечках памяти и ресурсов, при этом не останавливая общую работу приложения. Мы задали лимит в 512Mb и «тихий» рестарт через каждые 4096 файлов:
Другой проблемой стало то, что на стадии формирования списка программа проверяла каждый файл на уникальность в списке. В итоге, определение уникальности файла занимало ресурсы и время. Мы заменили последовательный поиск пути к файлу в списке на использование хеш-таблицы. Таким образом, проверка уникальности имени файла стала происходить за постоянное время.

Заказчик получил обновленные версии программ. Он очень круто всё потестировал и прислал нам такой отчет:

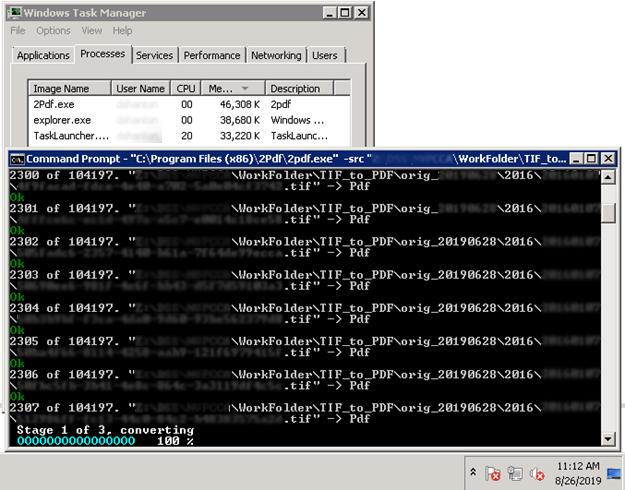
Через командную строку за один прогон получилось обрабатывать в среднем 172 файла в минуту. Неплохо.
В итоге, заказчику больше подошел вариант с использованием 2PDF, так как, благодаря интерфейсу командной строки, он сможет затем встроить функционал 2PDF в свою С# программу. Кроме того, 2PDF лучше подходит для применения на сервере.
«Сухой остаток» этого кейса:
Часто ли вы сталкиваетесь с файл-процессингом такого масштаба? Вот и мы не часто. Сначала не всё получилось, но в итоге (не без помощи самого клиента) мы победили. Надеюсь, эта история будет полезна тем, кто разрабатывает десктопные и серверные приложения под Windows.
TLDR: два важных фикса позволили нам:
- ускорить импорт списка с 1 дня до 53 секунд
- научить программу на ходу перезапускать «движок» при утечках памяти
- выйти на скорость конвертирования около 10 300 файлов в час
1. Пробуем через GUI-приложение
У клиента уже был установлен DocuFreezer. Это программа для конвертации картинок и документов. Только загрузка списка из 714 тысяч файлов занимала целый день! И скорость добавления новых файлов (генерация списка) снижалась по мере увеличения этого списка.
Возникли проблемы с оперативной памятью — загруженность иногда достигала 5-7 Гб. При нажатии паузы или манипуляциях с окном программы, оперативная память вновь высвобождалась, но это не решало проблему.
2. Пробуем через командную строку
Мы предложили клиенту утилиту командной строки 2PDF. Судя по первым тестам, 2PDF чуть лучше справлялся с задачей, но возникла проблема, схожая с работой DocuFreezer. В начале обработка шла быстро, но затем замедлялась.
3. Повышаем производительность
Изначально время обработки 104 000 TIFF-файлов у клиента занимало 50 часов и 15 часов с помощью 2PDF и DocuFreezer соответственно. При обработке из командной строки не было проблем с созданием списка документов, но процесс конвертации замедлялся со временем. А DocuFreezer замедлял работу при генерации списка документов, однако конвертировал файлы с примерно постоянной скоростью (около 7000 в час). Тем не менее, обработка в обоих случаях была очень долгая, что неприемлемо.
Сначала мы предположили, что «бутылочным горлышком» в случае с обеими программами является Microsoft .NET Framework. Представьте, что у вас в обычной папке Windows лежит не 10, не 100, а 700 000 файлов. И попробуйте что-нибудь простое с ними сделать, например, отсортировать их по имени в Windows File Explorer или Total Commander. Здесь примерно то же самое.
Но главные проблемы скрывались в другом.
Исполнительная часть программы, работающая в отдельном процессе, теряет производительность из-за накопления memory & resource leaks. Из-за этого падение производительности становится заметным после 120-тысячного файла. В итоге мы внедрили решение, благодаря которому программа перезапускала «движок» при таких вот утечках памяти и ресурсов, при этом не останавливая общую работу приложения. Мы задали лимит в 512Mb и «тихий» рестарт через каждые 4096 файлов:
Основная выявленная проблема — накопительный эффект добавления большого количества файлов
Другой проблемой стало то, что на стадии формирования списка программа проверяла каждый файл на уникальность в списке. В итоге, определение уникальности файла занимало ресурсы и время. Мы заменили последовательный поиск пути к файлу в списке на использование хеш-таблицы. Таким образом, проверка уникальности имени файла стала происходить за постоянное время.
В результате, добавление 714 тысяч файлов в список заняло всего 7 минут 53 секунд (на машине с Intel Core i7)
Финальные результаты тестирования
Заказчик получил обновленные версии программ. Он очень круто всё потестировал и прислал нам такой отчет:
Через командную строку за один прогон получилось обрабатывать в среднем 172 файла в минуту. Неплохо.
В итоге, заказчику больше подошел вариант с использованием 2PDF, так как, благодаря интерфейсу командной строки, он сможет затем встроить функционал 2PDF в свою С# программу. Кроме того, 2PDF лучше подходит для применения на сервере.
«Сухой остаток» этого кейса:
- Если у вас действительно много файлов в очереди, то утечки памяти будут обязательно. Избежать этого можно только не используя чужих компонентов (GDI Plus, NET Framework, и т. д.). Написать весь код с чистого листа и отладить его — это очень долго и дорого. Гораздо эффективнее, если движок вашей программы реализован в виде отдельного EXE, и вы его перезапускаете, например, после обработки каждых 4000 файлов.
- Используйте словарь для контроля уникальности списка файлов. «Доморощенные проверки» списка файлов на уникальность — это как песок в смазку двигателя сыпать!
Комментарии (3)

nerudo
03.10.2019 07:21Когда до программирования дорвались люди, у которых бесконечный ресурс виртуальной памяти и машинные часы за спиной лаборант никогда не считал.
intelligentpotato
Стабильно раз в месяц, иногда чаще. Сотни тысяч файлов и десятки-сотни гигабайт. Разные форматы: bmp, tiff, djvu,… Всегда использовал ImageMagick. Недавно столкнулся с датасетом в формате cgm, который ralcgm, используемый Меджиком, почему-то не переваривал, и я был вынужден погрузиться в пучину говноконвертеров, склёпанных на коленке, в которых из нормально работающей функциональности была только кнопка «купи меня», а память текла в точности, как у вас. К счастью, обнаружилось, что порядка 30% датасета вообще не соответствуют стандарту, и нормально читаются только той софтиной, которой были записаны. Смог обосновать закупку, пихнуть всё в неё и забыть.
Если кому интересно, вот однострочник на Баше, который просто берёт и конвертирует практически всё, не заставляя ждать ни день, ни 7 минут 53 секунд. Бесплатно, без регистрации и смс. Сравнивать по скорости с вашем софтом лень, будет вам идеей для новой статьи.
Форматы подставите, какие надо: imagemagick.org/script/formats.php
HerrDirektor
Мне вообще показалось, что это «ненавязчивая» реклама этих убогих (ну а как еще назвать танцы с «тихим рестартом»?) конвертеров.