
Сегодня вашему вниманию предлагается перевод вдумчиво написанной статьи об одной из базовых проблем Java — изменяемости, и о том, как она сказывается на устройстве структур данных и на работе с ними. Материал взят из блога Николая Парлога (Nicolai Parlog), чей блестящий литературный стиль мы очень постарались сохранить в переводе. Самого Николая замечательно характеризует отрывок из блога компании JUG.ru на Хабре; позволим себе привести здесь этот отрывок целиком:

Николай Парлог — такой масс-медиа чувак, который делает обзоры на фичи Java. Но он при этом не из Oracle, поэтому обзоры получаются удивительно откровенными и понятными. Иногда после них кого-то увольняют, но редко. Николай будет рассказывать про будущее Java, что будет в новой версии. У него хорошо получается рассказывать про тренды и вообще про большой мир. Он очень начитанный и эрудированный товарищ. Даже простые доклады приятно слушать, всё время узнаёшь что-то новое. При этом Николай знает за пределами того, что рассказывает. То есть можно приходить на любой доклад и просто наслаждаться, даже если это вообще не ваша тема. Он преподаёт. Написал «The Java Module System» для издательства Manning, ведёт блоги о разработке ПО на codefx.org, давно участвует в нескольких опенсорсных проектах. Прямо на конференции его можно нанять, он фрилансер. Правда, очень дорогой фрилансер. Вот доклад.
Читаем и голосуем. Кому пост особенно понравится — рекомендуем также посмотреть комментарии читателей к оригиналу поста.
Изменяемость – это плохо, так? Соответственно, неизменяемость – это хорошо. Основные структуры данных, при использовании которых неизменяемость оказывается особенно плодотворной, это коллекции: в Java это список (
List), множество (Set) и словарь (Map). Однако, хотя JDK поставляется с неизменяемыми (или немодифицируемыми?) коллекциями, системе типов об этом ничего не известно. В JDK нет ImmutableList, и этот тип из Guava кажется мне совершенно бесполезным. Но почему же? Почему просто не добавить Immutable... в эту смесь и не сказать, что так и надо?Что такое неизменяемая коллекция?
В терминологии JDK значения слов «неизменяемый» (immutable) и «немодифицируемый» (unmodifiable) за последние несколько лет изменились. Изначально «немодифицируемым» называли экземпляр, не допускавший изменяемости (мутабельности): в ответ на изменяющие методы он выбрасывал
UnsupportedOperationException. Однако, его можно было менять по-другому – может быть, потому что он был просто оберткой вокруг изменяемой коллекции. Данные представления отражены в методах Collections::unmodifiableList, unmodifiableSet и unmodifiableMap, а также в их JavaDoc.Поначалу термином "неизменяемые" обозначались коллекции, возвращаемые фабричными методами коллекций Java 9. Сами коллекции никаким образом нельзя было изменить (да, есть рефлексия, но она не считается), поэтому, представляется, что они оправдывают свое название. Увы, часто из-за этого возникает путаница. Допустим, есть метод, выводящий на экран все элементы из неизменяемой коллекции – всегда ли он будет давать один и тот же результат? Да? Или нет?
Если вы сходу не ответили нет – значит, вас только что озарило, какая именно путаница здесь возможна. «Неизменяемая коллекция тайных агентов» – казалось бы, звучит чертовски похоже на «неизменяемая коллекция неизменяемых тайных агентов», но две эти сущности могут быть неидентичны. Неизменяемая коллекция не поддается редактированию с применением операций вставки/удаления/очистки и т.д., но, если тайные агенты являются изменяемыми (правда, проработка характеров в шпионских фильмах такая плохая, что в это не очень верится), то это еще не значит, что и вся коллекция тайных агентов является неизменяемой. Поэтому, теперь наблюдается сдвиг в сторону именования таких коллекций немодифицируемыми, а не неизменяемыми, что закреплено и в новой редакции JavaDoc.
Неизменяемые коллекции, рассматриваемые в этой статье, могут содержать изменяемые элементы.
Лично мне не нравится такой пересмотр терминологии. На мой взгляд, термин «неизменяемая коллекция» должен означать лишь то, что сама коллекция не поддается изменениям, но никак не должен характеризовать содержащиеся в ней элементы. В таком случае есть и еще один положительный момент: термин «неизменяемость» в экосистеме Java не превращается в полную бессмыслицу.
Так или иначе, в этой статье мы поговорим о неизменяемых коллекциях, где…
- Экземпляры, содержащиеся в коллекции, определяются на этапе работы конструктора
- Этих экземпляров – ровное количество, ни убавить, ни прибавить
- Не делается никаких утверждений относительно изменяемости этих элементов
Остановимся на том, что теперь мы поупражняемся в добавлении неизменяемых коллекций. Если быть точным – неизменяемого списка. Все, что будет сказано о списках, в той же степени применимо и к коллекциям других типов.
Приступаем к добавлению неизменяемых коллекций!
Создадим интерфейс
ImmutableList и сделаем его, относительно List, эээ…, чем? Супертипом или субтипом? Давайте остановимся на первом варианте. 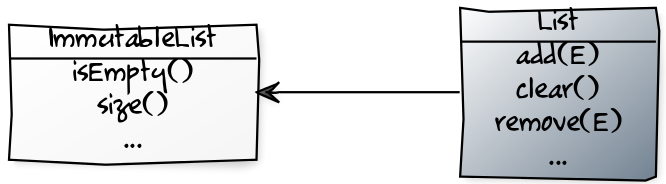
Красиво, у
ImmutableList нет изменяющих методов, поэтому использовать его всегда безопасно, так? Так?! Нет-с.List<Agent> agents = new ArrayList<>();
// компилируется, поскольку `List` расширяет `ImmutableList`
ImmutableList<Agent> section4 = agents;
// ничего не выводит
section4.forEach(System.out::println);
// теперь давайте изменим `section4`
agents.add(new Agent("Motoko");
// выводит "Motoko" – обождите, через какую дырку она сюда вкралась?!
section4.forEach(System.out::println);В этом примере показано, что можно передать такой не совсем неизменяемый список в API, работа которого может быть построена на неизменяемости и, соответственно, обнулять все гарантии, на которые может намекать название этого типа. Вот вам рецепт, который может привести к катастрофе.
Хорошо, тогда
ImmutableList расширяет List. Может быть?
Теперь, если API ожидает неизменяемый список, то именно такой список он и получит, но здесь есть два недостатка:
- Неизменяемые списки все равно должны предлагать изменяющие методы (так как они определены в супертипе), а единственная возможная реализация приводит к выбросу исключения
- Экземпляры
ImmutableListтакже являются экземплярамиListи при присвоении такой переменной, передаче в виде такого аргумента или возвращении такого типа логично предположить, что изменяемость разрешена.
Таким образом, получается, что использовать
ImmutableList можно только локально, поскольку он передает границы API как List, что требует от вас сверхчеловеческого уровня предосторожности, либо взрывается во время исполнения. Это не так плохо, как List, расширяющий ImmutableList, но такое решение все равно далеко от идеала.Именно это я и имел в виду, говоря, что тип
ImmutableList из Guava практически бесполезен. Это отличный образчик кода, очень надежный при работе с локальными неизменяемыми списками (поэтому я им активно пользуюсь), но, прибегая к нему, очень легко выйти за пределы неприступной, гарантированно компилируемой цитадели, стены который были сложены из неизменяемых типов – и только в таком виде неизменяемые типы могут полностью раскрыть свой потенциал. Это лучше, чем ничего, но неэффективно в качестве решения на уровне JDK.Если
ImmutableList не может расширять List, а обходной путь все равно не работает, то как вообще предполагается заставить все это работать?Неизменяемость – это фича
Проблема, с которой мы столкнулись при первых двух попытках добавить неизменяемые типы, заключалась в нашем заблуждении, будто неизменяемость – это просто отсутствие чего-то: берем
List, удаляем из него изменяющий код, получаем ImmutableList. Но, на самом деле, все это не так работает.Если просто удалить изменяющие методы из
List, то у нас получится список, доступный только для чтения. Либо, придерживаясь сформулированной выше терминологии, его можно назвать UnmodifiableList – он все-таки может меняться, просто менять его будете не вы.Теперь мы можем добавить к этой картине еще две вещи:
- Мы можем сделать его изменяемым, добавив соответствующие методы
- Мы можем сделать его неизменяемым, добавив соответствующие гарантии
Неизменяемость – это не отсутствие изменяемости, а гарантия, что никаких изменений не будет
В данном случае важно понять, что в обоих случаях мы говорим о полноценных фичах – неизменяемость является не отсутствием изменений, а гарантией, что изменений не будет. Имеющаяся фича не обязательно может быть чем-то, что используется во благо, она также может гарантировать, что в коде не произойдет чего-то плохого – в данном случае подумайте, например, о потокобезопасности.
Очевидно, изменяемость и неизменяемость конфликтуют друг с другом, и поэтому мы не можем одновременно задействовать две вышеупомянутые иерархии наследования. Типы наследуют возможности от других типов, поэтому, как их ни нарезай, если один из типов наследует от другого, то будет содержать обе фичи.
Итак, хорошо,
List и ImmutableList не могут расширять друг друга. Но нас привела сюда работа с UnmodifiableList, и действительно оказывается, что оба типа имеют один и тот же API, доступный только для чтения, а значит – должны его расширять.
Хотя, я и не называл бы вещи именно этими именами, сама иерархия такого рода разумна. В Scala, например, практически так и делается. Разница заключается в том, что разделяемый супертип, который мы назвали
UnmodifiableList, определяет изменяющие методы, возвращающие модифицированную коллекцию, а исходную оставляющие нетронутой. Таким образом, неизменяемый список получается персистентным и дает изменяемому варианту два набора изменяющих методов – унаследованный для получения модифицированных копий и свой собственный для изменений на месте.Что же насчет Java? Можно ли модернизировать подобную иерархию, добавив в нее новые супертипы и сиблинги?
Можно ли усовершенствовать немодифицируемые и неизменяемые коллекции?
Разумеется, нет никакой проблемы в том, чтобы добавить типы
UnmodifiableList и ImmutableList и создать такую иерархию наследования, которая описана выше. Проблема в том, что в краткосрочной и среднесрочной перспективе это будет практически бесполезно. Давайте я объясню.Самое классное в том, чтобы иметь
UnmodifiableList, ImmutableList и List в качестве типов – в таком случае API смогут четко выражать, что им требуется, и что они предлагают.public void payAgents(UnmodifiableList<Agent> agents) {
// изменяющие методы для платежей не требуются,
// но и и неизменяемость не является необходимым условием
}
public void sendOnMission(ImmutableList<Agent> agents) {
// миссия опасна (много потоков),
// и важно, чтобы команда оставалась стабильной
}
public void downtime(List<Agent> agents) {
// во время простоя члены команды могут уходить,
// и на их место могут наниматься новые сотрудники, поэтому список должен быть изменяемым
}
public UnmodifiableList<Agent> teamRoster() {
// можете просмотреть команду, но не можете ее редактировать,
// а также не можете быть уверены, что ее не редактирует кто-нибудь еще
}
public ImmutableList<Agent> teamOnMission() {
// если команда на задании, то ее состав не изменится
}
public List<Agent> team() {
// получение изменяемого списка подразумевает, что список можно редактировать,
// а затем просмотреть изменения в этом объекте
}Однако, если только вы не начинаете проект с нуля, такой функционал, скорее всего, уже у вас будет, и выглядеть он будет примерно так:
// есть хорошие шансы, что `Iterable<Agent>`
// будет достаточно, но давайте предположим, что нам на самом деле нужен список
public void payAgents(List<Agent> agents) { }
public void sendOnMission(List<Agent> agents) { }
public void downtime(List<Agent> agents) { }
// лично мне больше нравится возвращать потоки,
// так как они немодифицируемые, но `List` все равно более распространен
public List<Agent> teamRoster() { }
// аналогично, это уже может быть `Stream<Agent>`
public List<Agent> teamOnMission() { }
public List<Agent> team() { }Это нехорошо, так как, чтобы новые коллекции, только что введенные нами, были полезны, нам как бы нужно с ними работать! (уф). То, что приведено выше, напоминает код приложения, поэтому здесь напрашивается рефакторинг в сторону
UnmodifiableList и ImmutableList, и осуществить его можно, как было показано в вышеприведенном листинге. Это может быть большой кусок работы, сопряженный с путаницей, когда нужно организовать взаимодействие старого и обновленного кода, но, как минимум, он кажется осуществимым.Что же насчет фреймворков, библиотек и самого JDK как такового? Здесь все выглядит безрадостно. Попытка изменить параметр или возвращаемый тип с
List на ImmutableList приведет к несовместимости с исходным кодом, т.e. существующий исходный код не скомпилируется с новой версией, так как эти типы не связаны друг с другом. Аналогично, при изменении возвращаемого типа с List на новый супертип UnmodifiableList приведет к ошибкам компиляции.При введении новых типов потребуется вносить изменения и проводить перекомпиляцию в масштабах всей экосистемы.
Однако, даже если расширить тип параметра с
List до UnmodifiableList, мы столкнемся с проблемой, поскольку такое изменение вызывает несовместимость на уровне байт-кода. Когда исходный код вызывает метод, компилятор преобразует этот вызов в байт-код, ссылающийся на целевой метод по:- Имени того класса, в качестве экземпляра которого объявлена цель
- Имени метода
- Типам параметров метода
- Возвращаемому типу метода
Любое изменение в параметре или возвращаемом типе метода приведет к тому, что байт-код будет при ссылке на метод указывать неверную сигнатуру; в результате во время исполнения возникнет ошибка
NoSuchMethodError. Если вносимое изменение совместимо с исходным кодом – например, если речь идет о сужении возвращаемого типа или расширения типа параметра – то перекомпиляции должно быть достаточно. Однако, при далеко идущих изменениях, например, при введении новых коллекций, все не так просто: чтобы такие изменения закрепились, нужно перекомпилировать всю экосистему Java. Это пропащее дело.Единственный мыслимый способ воспользоваться такими новыми коллекциями, не нарушив совместимости – продублировать существующие методы каждый под новым именем, изменить API, после чего пометить старый вариант как нежелательный. Вы можете себе представить, насколько монументальной и фактически бесконечной была бы такая задача?!
Рефлексия
Конечно, неизменяемые типы коллекций – отличная штука, которую очень хотелось бы иметь, но мы вряд ли увидим что-то подобное в JDK. Грамотные реализации
List и ImmutableList никогда не смогут расширять друг друга (на самом деле, оба они расширяют один и тот же списковый тип UnmodifiableList, доступный только для чтения), что затрудняет внедрение таких типов в существующие API.Вне контекста каких-либо специфических отношений между типами изменение существующих сигнатур методов всегда сопряжено с проблемами, так как такие изменения несовместимы с байт-кодом. При их внесении требуется как минимум перекомпиляция, а это разрушительное изменение, которое отразится на всей экосистеме Java.
Поэтому я считаю, что ничего подобного не произойдет – ни за что и никогда.
Комментарии (106)

qw1
04.10.2019 17:46+1Дельная мысль вынесена в заголовок статьи: неизменяемые коллекции не нужны. Нужны аннотации, что какой-то метод не меняет коллекцию.
В .NET с этим разобрались через интерфейсы (IReadOnlyList, IReadOnlyCollection и т.п.). Если не хочешь, что-то кто-то твой List менял, отдаёшь его всем потребителям как IReadOnlyList. Все ф-ции, которым не надо менять список, принимают IReadOnlyList, в них можно легко передать любой List. Таким образом, программист сам следит, где данные можно менять, а система типов ему помогает.
lam0x86
04.10.2019 18:17+3Так в статье как раз и написано про IReadOnlyList, только называют его UnmodifiableList.
qw1
04.10.2019 19:23Идея в том, что нет такой коллекции IReadOnlyList, это всего лишь интерфейс, который реализует в том числе обычный List. C интерфейсом нет протечки абстракций (если не делать cast к List, который в общем случае может выкинуть исключение, никто же не гарантирует что при передаче IReadOnlyList мы передали объект List).
lam0x86
04.10.2019 19:25Так и в джаве List — это интерфейс.
qw1
04.10.2019 19:31Но UnmodifiableList — нет.
lam0x86
04.10.2019 19:34Такого типа в джаве просто нет. Собственно, его автор и предлагает ввести.
qw1
04.10.2019 19:38-1Не спец в java, но в Collections есть такой код
public static <T> List<T> unmodifiableList(List<? extends T> list) { return (list instanceof RandomAccess ? new UnmodifiableRandomAccessList<>(list) : new UnmodifiableList<>(list)); }lam0x86
04.10.2019 19:40Ну, это внутренний враппер. Я имел в виду публичный класс или интерфейс, который может использовать программист.

igormich88
04.10.2019 21:41Проблема в том что у этих классов все методы которые модифицируют коллекцию кидают UnsupportedOperationException, но они есть.

mayorovp
04.10.2019 18:22+2Вообще-то, неизменяемые коллекции как раз нужны. Будучи применёнными в нужном месте, они позволяют избежать многократного защитного копирования.
qw1
04.10.2019 19:35Тут я согласен с комментатором ниже: immutable и readonly — разные вещи. Readonly это как const в C++ и делать их отдельным классами не нужно (в разных частях программы к ним может быть разный доступ, так и const-ность можно снять всякими трюками).
А вот immutable, гарантирующие что при изменении коллекции будет создана копия, а по старой ссылке останется прежнее содержимое, дадут гарантии ненужности защитного копирования.
Поэтому ваше возражение немного мимо: я говорю, что отдельные классы для ReadOnly-коллекций не нужны, а вы говорите, что Immutable-коллекции нужны.
math_coder
04.10.2019 18:39+3ReadOnly коллекции и Immatable коллекции — это принципиально разные вещи для разных применений. В .NET есть и то, и другое (System.Collections.Immutable).

zzzzzzzzzzzz
04.10.2019 20:11Сомневаюсь в полезности UnmodifiableList в случае наличия ImmutableList. В вашем примере:
public UnmodifiableList<Agent> teamRoster()— вот получили список, начали его на экран выводить, а он в это время поменялся из другой нити. Единственный вариант придумался, когда нужен именно UnmodifiableList без «стрельбы в ногу» — метод, циклически опрашивающий объекты на предмет какого-то события (пропустили один объект — ничего, на следующем цикле опросим; опросили один объект два раза за цикл — тоже ничего).
А вот что мешает изготовить свой ImmutableList и использовать в своих проектах? Не обязательно же всю экосистему менять. Получили от библиотеки List — скопировали сразу же содержимое в свой ImmutableList и дальше его гоняете. Лишнее копирование неприятно, но без него не обойтись.lam0x86
04.10.2019 20:28+1Смысл UnmodifiableList'а не в том, что он не может измениться извне, а в том, что передавая его в какой-то метод, ты можешь быть уверен, что после выхода из метода лист останется тем же.
zzzzzzzzzzzz
04.10.2019 22:23Ну так и зачем он нужен, если есть ImmutableList? За исключением варианта с несколькими нитями, различий ImmutableList и UnmodifiableList не вижу.
lam0x86
04.10.2019 22:31+1Допустим, у вас есть класс A, который часто модифицирует некую коллекцию и иногда вызывает API для подсчёта статистики по этой коллекции. По хорошему, API должен гарантировать неизменность коллекции. Для этого, на вход следует принимать UnmodifiableList, чтобы декларировать неизменяемость.
ImmutableList в данном случае будет оверхэдом с точки зрения класса A, т.к. приводит к копированию массива или перестроению дерева (в зависимости от внутренней реализации ImmutableList-а) при каждой модификации коллекции.zzzzzzzzzzzz
05.10.2019 00:04Если, как предложено в статье,
Listявляется наследникомUnmodifiableList, то получим ту же проблему, что в начале статьи описана: в API на входеUnmodifiableList, вызывают его с экземпляромList, тогда реализация API внутри может спокойно сделать приведение типов кListи менять, что захочет. Альтернативы — либо копирование, либо обёртка (как сейчас и сделано вCollections.unmodifiableList()). В обоих случаях оверхеда не избежать. Обёртка на первый взгляд кажется меньшим оверхедом, но если вспомнить про сборку мусора, то разница может оказаться совсем небольшой.lam0x86
05.10.2019 00:24+1Ну мы же говорим про программирование, а не про то, как можно хакнуть систему. Если разработчики API опустились до того, чтобы кастить интерфейсы к конкретной имплементации (это должно быть уголовно наказуемо), то что им стоит через рефлекшн изменить private поля ImmutableList'а и добавить туда свой элемент?
Конечно, UnmodifiableList — более слабая абстракция, чем ImmutableList, но, учитывая накладные расходы и здравый смысл разработчиков, она всё же имеет место быть. Как уже было отмечено выше, в .NET-е уже давно есть IReadOnlyList, а относительно недавно появился и IImmutableList, и они отлично уживаются вместе, и никакие API не требуют строго IImmutableList на входе — чаще всего, ограничиваются IReadOnlyList (или ещё более ослабляют контракт до IReadOnlyCollection или даже до IEnumerable). Если вы не доверяете тому API, что вызываете, то всегда можно передать туда не ArrayList, а ImmutableList, и тогда этот злой API не сможет его скастить в List.zzzzzzzzzzzz
05.10.2019 09:23Бывают неприятные случаи, когда приходится хакать. Для этих случаев есть рефлекшены. Но к ним обычно и отношение соответствующее: «это ружьё рано или поздно стрельнёт в ногу». А приведение типов — вполне штатная операция, выполняемая на каждом углу, её легко можно написать, не особо задумываясь или «временно для тестов, потом поправлю». И когда код читаешь, оно не особо в глаза бросается. А если уж сначала UnmodifiableList станет, например, переменной типа Object (всякое в жизни бывает), то в другом месте кастинг в List будет выглядеть вообще абсолютно невинно.

Neikist
05.10.2019 11:45+1приведение типов — вполне штатная операция, выполняемая на каждом углу
Стараюсь всегда избегать в своем коде, как раз по причине того что в результате получаем нарушение контрактов. Да и код обрастает костылями в виде (kotlin)
when(obj) { is ClassA -> ... is ClassB -> ... is ClassC -> ... }
Да, иногда бывает что без каста не обойтись, но это то еще.zzzzzzzzzzzz
05.10.2019 12:36Ну это понятно, что по возможности стоит избегать. Но согласитесь, что привычный к написанию equals программист обычно воспринимает каст гораздо менее болезненно, чем рефлекшены.
lam0x86
06.10.2019 05:16Бывают неприятные случаи, когда приходится хакать. Для этих случаев есть рефлекшены.
Согласен, бывают. Но за всю мою 12-летнюю практику разработки софта мне лишь однажды пришлось хакнуть чужой софт через рефлекшн, и то лишь из-за того, что библиотека отрисовки графиков, которую использовали в моем проекте, не поддерживалась уже больше 5 лет, да и контора та давно закрылась.
Но мы всё же говорим о высоком. О языковых концепциях, и всё такое.zzzzzzzzzzzz
06.10.2019 10:02Так про то и речь, рефлекшены — это костыль для крайних случаев, и программисты (обычно) это понимают. А «штатными» средствами, считаю, не должно быть даже потенциальной возможности всё испортить. То есть, приведения типов MutableList <-> ImmutableList просто скомпилироваться не должны.
JordanoBruno
05.10.2019 00:14Честно говоря, не понимаю, почему некоторые видят в неизменяемых концепциях хоть какие-то плюсы. Большинство реализаций неизменяемой концепции будет медленнее изменяемой, иногда значительно. Так зачем тогда так упарываться и применять эту концепцию? А хорошему разработчику вообще пофик, изменяемые у него объекты или нет.
lam0x86
05.10.2019 00:27Неизменяемые типы гораздо удобнее в использовании в многопоточных приложениях. Меньше багов — дешевле поддержка. А хорошие программисты сами решат, где им лучше использовать (im-)mutable коллекции.
JordanoBruno
05.10.2019 00:32Чем удобней-то? Это все равно как сказать — вставать утром лучше с левой ноги.
lam0x86
05.10.2019 00:39Не надо локов. Все операции делаются через Interlocked.(Compare)Exchange, а значит, нет дедлоков. Я вообще забыл этот термин уже. Считаю, это плюс. Минус — memory footprint и время на GC. Поэтому, умные разработчики совмещают оба подхода.
JordanoBruno
05.10.2019 00:57— Как не поругаться с женой?
— Перестаньте с ней общаться.
— Минус: жена начинает готовить не то, что я хотел.lam0x86
05.10.2019 01:00Да я уж понял, что вы больше про развитие стартапов, а не про программирование…
Извините, если не прав. Но с вашей стороны вообще никакой аргументации нет.
math_coder
05.10.2019 01:32+1Увеличение определённости и ясности кода — это хорошо. Если вы видите в коде неизменяемую сущность, вам больше не надо думать, что произойдёт, если она изменится. Понимание кода упрощается, уменьшается вероятность ошибки.
JordanoBruno
05.10.2019 01:45«Понимание кода упрощается, уменьшается вероятность ошибки.»
Что-то сомнительно, чтобы это было бы хоть немного заметно у более-менее опытного dev'а. А сама парадигма неизменяемости грозит жесткой просадкой скорости, потреблению памяти, лишним циклам GC.lam0x86
05.10.2019 01:53Давайте начнём сначала и забудем ту дискуссию в соседней ветке. Вы можете привести какие-то доказательства жесткой просадки скорости? Есть какие-то статистические данные?
Кроме того, Вы, похоже, не поняли того, о чём сказал math_coder. Он не об Immutable объектах, а об усилении контракта.JordanoBruno
05.10.2019 02:09доказательства жесткой просадки скорости
Так сама концепция неизменяемости тащит за собой накладные расходы в виде копирования объектов или лишних циклов оптимизатора, это все не бесплатно, чай не в сказке живете.
Есть даже какие-то бенчмарки по таким объектам из Guava, правда старенькие:
github.com/google/guava/issues/1268
об усилении контракта
Что за контракт такой?lam0x86
05.10.2019 02:33Это всё происходит из-за того, что JVM не знает, какие объекты изменяемы, а какие нет. Из-за этого, GC обязан пройти по всем объектам, чтобы понять, какие из них ещё живы (классический Mark and Sweep + текущие модификации). В языках типа Haskell, которые заточены на работу с неизменяемыми данными, GC работает совсем по-другому: если он видит корневой объект, и знает, что этот объект immutable, он не будет проходить по дереву, т.к. и так понятно, что дочерние объекты тоже immutable. .NET сейчас тоже вводит т.н. record types, или readonly structs. Когда-нибудь, возможно, подтюнят и GC, чтобы не обходил всё дерево, если видит, что структура readonly.
Возможно, и до джавы дотянется тренд.
Что за контракт такой?
Есть такое понятие: контракт класса/интерфейса.
Обычно под контрактом подразумевается публичный контракт, хотя есть и контракты для дочерних классов, для классов внутри одного пакета, и ещё много разных вариантов.
Так вот, публичный «контракт» — это, условно, API класса. Когда класс говорит:
у меня есть метод Foo, который на вход принимает SomeWeakInterface, то это контракт.
А когда этот класс говорит, что метод Foo теперь принимает SomeStrongInterface, где SomeStrongInterface наследуется от SomeWeakInterface, то это называется «усиление контракта».qw1
05.10.2019 08:46В языках типа Haskell, которые заточены на работу с неизменяемыми данными, GC работает совсем по-другому: если он видит корневой объект, и знает, что этот объект immutable, он не будет проходить по дереву, т.к. и так понятно, что дочерние объекты тоже immutable
Допустим, у меня 2 immutable словаря и по 5000 бакетов в каждом, т.е. всего в куче 10002 объектов. Каким образом при попадании в мусор первого словаря (потери на него всех ссылок), GC сможет выделить его 5000 бакетов, не проходя по дереву второго словаря? Если корневая ссылка ровно одна — объекты второго, ещё живого, словаря.
0xd34df00d
05.10.2019 17:54Я не до конца понял задачу. Как эти два словаря связаны? Один является версией другого?
qw1
06.10.2019 00:57Словари никак не связаны. Задача — объяснить, как работает механизм
если GC видит корневой объект, и знает, что этот объект immutable, он не будет проходить по дереву, т.к. и так понятно, что дочерние объекты тоже immutable
0xd34df00d
06.10.2019 01:01Он не будет проходить по его дочерним объектам, пока корневой объект ещё живой (потому что ссылки из этого корневого объекта не могли измениться, и если жив корневой объект, то живы и все дочерние).
Пусть теперь первый корень умер. Если второй словарь был создан раньше, чем первый (который с умершим корнем), то ссылки из него тоже заведомо не могут указывать на первый, поэтому первый можно прибивать.
qw1
06.10.2019 10:08А как узнать, какие объекты первого словаря можно прибить, не проходя по всем объектам второго? Обычная сборка мусора — это прохождение по всем корням до листьев, и всё, что не посещено, удаляется.
0xd34df00d
06.10.2019 16:42Узнать, э, логически.
Если упрощать и не рассматривать пару граничных случаев (которые не влияют на вывод), то при создании объекта A он может указывать только на то, что уже существовало при его создании (это очевидно). А так как объект A иммутабельный, он не может внезапно изменить один из своих указателей и начать указывать на то, что было создано после него.
qw1
06.10.2019 20:57Я не понимаю, что вы хотите сказать.
Было 2 иммутабельных словаря. Совершенно разных, никак не связанных. На один словарь теряем ссылку и все его объекты становятся мусором.
Может ли GC при удалении этих объектов как-то использовать факт, что словари были иммутабельными? Как мне кажется, нет. GC должен пройти по всем объектам второго, ещё живого, словаря, пометить их как живые, после чего всё непомеченное удалить. Иммутабельность тут никак не помогает.0xd34df00d
06.10.2019 21:00Может ли GC при удалении этих объектов как-то использовать факт, что словари были иммутабельными?
Да. Ему не надо проходить по всем объектам ещё живого словаря, а достаточно, условно, сравнить таймстамп корня ещё живого словаря с корнем удаляемого словаря. Если ещё живой словарь старше удаляемого словаря, то он гарантированно не может [транзитивно] ссылаться на что-либо из более молодого словаря, и по нему обходить не надо.
Чтобы получить чуть более хорошую интуицию, попробуйте придумать ситуацию, в которой этого недостаточно.
qw1
06.10.2019 21:14Вот граф объектов в памяти:
Скрытый текст
0xd34df00d
06.10.2019 21:20Давайте рассмотрим предельный случай: с прошлой сборки мусора не было создано никаких объектов, кроме
dict2и его детей (hashtable2, b1, b2). В таком случае мы знаем, что никакие объекты, кроме dict2, не могут ссылаться на объекты, транзитивно доступные из dict2.
Говоря чуть аккуратнее и точнееМы знаем, что в подграф объектов, являющийся транзитивным замыканием отношения «имеет указатель на» и содержащий вершину
dict2, нет рёбер из объектов вне этого подграфа.qw1
06.10.2019 21:28Поэтому мы просто берём и рекурсивно удаляем все объекты, доступные из dict2.
В какой именно момент?
Программа например, выполняет
dict2 = new hashtable; // создан hashtable2
dict2 = new hashtable; // создан hashtable3
dict2 = new hashtable; // создан hashtable4
dict2 = new hashtable; // создан hashtable5
… упс, тут память кончилась, запускается GC
как GC получит ссылки на все созданные hashtable2,3,4,5, чтобы их удалить?0xd34df00d
06.10.2019 21:34-1Я ж сказал, давайте рассмотрим предельный случай, когда кроме dict2 не было создано объектов, а у вас их тут целых три лишних.
Тем не менее, хороший пример, давайте рассмотрим.
Во-первых, в этом виде hashtable5 удалять нельзя, на него ещё dict2 ссылается. Я предположу, что вы там дальше написали
dict2 = null(хотя тут уже от иммутабельности ничего не осталось, раз вы в одну и ту же переменную что-то присваиваете, но закроем глаза на это и будем считать, что вы просто 5 раз вызвали одну и ту же функцию).
Во-вторых, как не сканировать всю кучу даже в этом случае? Начинаем с самого молодого объекта, это hashtable5. После него ничего не создано, на него ничего не ссылается, поэтому его можно рекурсивно удалить целиком и не ходить по другим объектам. Какой дальше самый молодой объект? hashtable4. Моложе него (теперь) никого нет, поэтому его тоже можно спокойно рекурсивно удалять.
Ну и так далее.
Кстати, заметим, что в этом случае мы просто могли бы сделать обычный copying GC из нулевого поколения (в котором все эти hashtableN, N = { 2… 5 } предположительно живут) в более старшее поколение (и не скопировалось бы ровным счётом ничего, так как все сдохли), но даже это, как мы видим, не нужно.
qw1
06.10.2019 22:33То есть, предлагается все аллокации записывать в некий стек, чтобы знать, что последний выделенный объект был hashtable5?
Хорошо. Берём со стека последний аллоцированный объект. И как мы узнаем, что его можно удалять? Нужно походить от всех корней, и если мы к нему не пришли, то можно удалять. Затем выталкикаем со стека следующий объект и снова от всех корней делаем обход? А не слишком ли большая сложность?
А если hashtable5, как в моём примере, ещё доступен? Всё, оптимизированный алгоритм останавливается? hashtable4 мы со стека не берём, чтобы удалить его вместе со всеми под-объектами, не проверяя ссылки? Нет гарантий, что из hashtable5 нет ссылок на внутренности hashtable4.0xd34df00d
06.10.2019 22:52И как мы узнаем, что его можно удалять? Нужно походить от всех корней, и если мы к нему не пришли, то можно удалять.
Зачем? Только от корней, созданных после него. В объектах с корнями, созданными до него, ссылок на него быть не может.
А если hashtable5, как в моём примере, ещё доступен? Всё, оптимизированный алгоритм останавливается? hashtable4 мы со стека не берём, чтобы удалить его вместе со всеми под-объектами, не проверяя ссылки? Нет гарантий, что из hashtable5 нет ссылок на внутренности hashtable4.
Тогда делаем copying GC из gen0 в более старое поколение.
qw1
06.10.2019 22:35заметим, что в этом случае мы просто могли бы сделать обычный copying GC из нулевого поколения (в котором все эти hashtableN, N = { 2… 5 } предположительно живут) в более старшее поколение (и не скопировалось бы ровным счётом ничего, так как все сдохли)
Но если в это же поколение попал hashtable1, он и все его под-объекты нужно копировать. Для этого их надо рекурсивно обойти, что противоречит тезису, что обход по внутренностям живых объектов не нужен.0xd34df00d
06.10.2019 22:55Для этого их надо рекурсивно обойти, что противоречит тезису, что обход по внутренностям живых объектов не нужен.
Обход по внутренностям всех живых объектов не нужен. В общем случае вы обходите только корни объектов, живущие в nursery (хаскель-специфичное название для gen0) и тупо рекурсивно копируете оттуда в gen1. После такого копирования весь чанк памяти, выделенный под nursery, можно удалять одним вызовом
free()(или не удалять, а переиспользовать под следующий цикл). И это оказывается чертовски быстро, потому что nursery специально делают размером с кеш L2, и разные ядра могут иметь разные nursery.
В языках с мутабельностью вы себе такого позволить не можете — объекты из более старших поколений внезапно могут начать указывать на более молодые.
qw1
06.10.2019 23:10Тогда корректно сказать: Обход по внутренностям всех живых объектов нужен не на каждой итерации GC.
При перемещении gen0 в gen1 — не нужен. Но при сборке мусора в gen1 от него не избавишься.0xd34df00d
07.10.2019 00:39Да, именно так. По опыту в среднем приходится 500-10000 gen0-сборок на одну gen1-сборку. Ну и ещё есть compact regions, но то совсем отдельная история.
Но, тем не менее, надеюсь, это всё равно показывает, какие оптимизации возможны в случае иммутабельности.
qw1
07.10.2019 10:24+1Оптимизации интересные, но они подразумевают, что мы знаем, какой объект (не только в куче, ещё и корни) создан раньше, какой позже. Если назначать версии из какого-то глобального счётчика, он будет узким местом в многопоточной среде.
lam0x86
06.10.2019 01:20Вот отличная статья про оптимизации GC. В том числе, оптимизации, связанные с Immutable Objects. www.ibm.com/developerworks/library/j-jtp01274
qw1
06.10.2019 10:24Там нет ответа на вопрос ))) Если словарь (неважно, mutable или immutable) размещён в новом поколении GC, он будет обойден полностью. Если размещён в старом поколении и умер, то для освобождения памяти все словари того же поколения тоже будет обойдены полностью, но это делается реже (и это тоже одинаково для mutable или immutable).
Мусор, создаваемый immutable объектами лучше группируется по поколениям, из-за чего его проще собирать. Но самого мусора создаётся больше. Наверное, то на то и выходит.
qw1
06.10.2019 10:37Также легко представить ситуацию, когда mutable коллекция при изменении вообще не даёт нагрузку на GC: если по ключу меняется не ссылка, а примитивное поле (например, Integer) — граф объектов не меняется никак и объекты уходят в старое поколение и больше не требуют внимания GC.
И ту же ситуацию, с immutable коллекцией: при изменении коллекции будут создаваться новые копии, а старые элементы, которые давно лежали в старом поколении, превращаются в мусор и требуется уборка старого поколения.
JordanoBruno
05.10.2019 10:49Это всё происходит из-за того, что JVM не знает, какие объекты изменяемы, а какие нет.
Так дело даже не в этом. Чтобы оно хоть как-то шевелилось с приемлемой скоростью, Immutable должно быть базовой концепцией, как в том же Erlang. Микшировать два подхода в одном языке заранее обречено. Ну и для большинства применений(без такой жесткой многопоточности) концепция Immutable совершенно избыточна и бесполезна.
math_coder
05.10.2019 03:45+2Что-то сомнительно, чтобы это было бы хоть немного заметно у более-менее опытного dev'а.
Ага, видел я такое воочию и не раз.
Сначала опытный dev не хочет озаботиться выражением контракта в коде. ("Ведь любому более-менее опытному разработчику должно быть понятно, что этот объект надо склонировать, а не менять внутреннее состояние существующего.")
А потом менее опытный dev, или даже опытный, но сосредоточенный мыслями на совсем других проблемах, допускает ошибку. А потом, через пару лет, обнаруживается баг, и оказывается, что важная система работает чудом, усиленно мутируя объекты, от которых этого не ожидалось. Ну и, соответственно, работает это всё плохо, а как исправлять теперь уже непонятно.
0xd34df00d
05.10.2019 17:53А сама парадигма неизменяемости грозит жесткой просадкой скорости, потреблению памяти, лишним циклам GC.
Эм, нет. Начиная от того, что GC теперь реализовать сильно легче (не надо перепроверять указатели из уже просмотренных в прошлых запусках объектов), и заканчивая автоматическим (или не очень, см. линейные типы) выводом того, что объект можно менять инплейс.
VolCh
05.10.2019 07:33Почему они будут медленнее? Медленней они будут только в случае попыток "имитировать" мутабельность через возврат "сеттерами" нового значения. А вот в случае необходимости детектирования изменений оно будет на порядки быстрее — только ссылку сравнить, чтобы убедиться, что ничего не менялось.
А хороший разработчик знает, что чаще всего есть вещи важнее скорости.
JordanoBruno
05.10.2019 10:54+1На простом примере:
есть гиг данных, Вы заменяете в нем пару байтов. В случае Immutable объекта, он будет закопирован в новый, вместо того, чтобы просто поменять пару байтов. А если таких операций миллионы?Neikist
05.10.2019 11:51Immutable вообще не должен предоставлять возможности себя менять имхо(пусть и с копированием в другой объект), если объект менять нужно — так и делайте его изменяемым. А если прям вот хочется — то пусть разработчик сам извне создает новый объект, ясно осознавая что он копирует к себе данные из старого.
qw1
05.10.2019 12:52Это плохой пример, как делать не надо. Точно также можно говорить, что массивы не нужны, потому что вставка в середину требует копирования остатка массива.
Применение immutable оправдано, когда стоимость изменения посчитана (например, для дерева из N вершин модификация любой вершины потребует только log(N) копирований), и эта стоимость ниже альтернативного решения (например, блокировок потоков).
0xd34df00d
05.10.2019 18:06Тогда вы неправильно выбрали структуру данных (либо ЯП, либо уровень абстракций).
Тут есть два варианта:
- Вам нужна предыдущая версия, и тогда и в мутабельном мире нужно копировать, а в иммутабельном есть вещи типа таких посмотрите на сложности, они там интересные.
- Вам не нужна предыдущая версия. Тогда вы можете либо рассчитывать на оптимизацию этого компилятором (если он это увидит), либо же просто иметь локальную мутабельность (например, в ST), предоставляя наружу чистый иммутабельный интерфейс.
VolCh
05.10.2019 22:50- ну и что, если это решает другие проблемы более важные чем гиг оперативки, например позволяет неограниченно горизонтально масштабироваться?
- многие такие случаи реальные трансляторы хорошо поддерживающие иммутабельность оптимизирующий под капотом в мутабельность. Грубо говоря, бинарники одинаковые, но программист лишён возможности случайно мутировать объект, а потом, например, забыть сохранить изменения потому что сравнивал по ссылке, а не по значениям.

Pand5461
05.10.2019 13:23Плюсы не в неизменяемости как таковой, а в возможности отделения неизменяемых данных и чистых функций от изменяемых данных и деструктивных функций.
Апелляция к "хорошим разработчикам" ничем тут не отличается от истории про "настоящих шотландцев".JordanoBruno
05.10.2019 14:38Пока я увидел только плюсы, описанные как «Понимание кода упрощается, уменьшается вероятность ошибки.» Вы же понимаете, что если человек не может писать простой код и с минимумом ошибок, то ему далеко еще до опытного разработчика? До появления в guava неизменямых объектов же как-то писали многопоточный код?
Pand5461
05.10.2019 15:50Я понимаю, что я не слышал о людях, которые могут писать код совсем без ошибок. Если с добавлением в язык какой-то концепции класс ошибок можно будет отлавливать в ходе компиляции, а не на тестах / в продакшене — это же хорошо.
Если понимание кода упрощается — и опытные разработчики будут быстрее его понимать и могут потратить больше времени на добавление фичи. Если уменьшается вероятность ошибки — и опытный разработчик с меньшей вероятностью допустит ошибку (что вдвойне ценно, поскольку цена ошибки опытного разработчика обычно выше, чем цена ошибки неопытного).
Pand5461
05.10.2019 16:13+1Да, ещё момент — для иллюстрации исторической перспективы.
В каких-то первых версиях Фортрана можно было написать что-то вроде2 = 3, после чего в программе дальше 2 было равно 3, потому что числовые константы связывались намертво с какой-то ячейкой памяти, и её можно было переписать.
Потом, если посмотреть старые фортрановские программы, там часто одна и та же переменная внутри функции имеет разный смысл на разных этапах — экономили память.
Сейчас первое вообще сложно вообразить, а за второе можно отхватить канделябром.
Иммутабельность и явные пометки, на каких переменных предполагаются изменения, а какие программист не собирается трогать — это естественный следующий шаг.
Throwable
05.10.2019 14:02А почему автор прицепился именно к ImmutableList, если изменяемые методы есть уже у Collection? Что насчет UnmodifiableSet? Поэтому вместо UnmodifiableList нужен суперинтерфейс UnmodifiableCollection:
interface Collection extends UnmodifiableCollection
> // есть хорошие шансы, что `Iterable`
> // будет достаточно, но давайте предположим, что нам на самом деле нужен список
> public void payAgents(List agents)
Кстати, Iterable, от которой наследуется Collection не является immutable, т.к. возвращаемый Iterator содержит метод remove().
Вобщем, сделать можно, но при этом придется перелопатить всю java util, добавляя Unmodifiable-суперинтерфейсы. Наиболее интересен будет детальный анализ того, что при этом отвалится.
> // лично мне больше нравится возвращать потоки,
> // так как они немодифицируемые, но `List` все равно более распространен
> public List teamRoster() { }
Я видел, как многие так делают, но это ОООчень плохая идея, ибо потоки предназначены для единственного «прогона». При повторном «прогоне» вылезет:
java.lang.IllegalStateException: stream has already been operated upon or closed
> Однако, при далеко идущих изменениях, например, при введении новых коллекций, все не так просто: чтобы такие изменения закрепились, нужно перекомпилировать всю экосистему Java. Это пропащее дело.
Можно например сделать как поступили в Kotlin-е: в байткоде оперировать исключительно старыми добрыми коллекциями, а immutable сделать фичей исключительно компилятора.
> Вы можете себе представить, насколько монументальной и фактически бесконечной была бы такая задача?!
Вот не факт. Как только в Java введут новые коллекции, фреймворки быстро возьмут их на вооружение. Со стримами же как-то разобрались…
Prototik
05.10.2019 14:24По поводу байт-кода — его можно переделывать при загрузке в jvm. Я так менял доступ к полю на вызов геттера, переделывал иерархию наследования, даже выносил методы в отдельные независимые интерфейсы… Так что это просто ещё одна решаемая проблема, а не какой-то стоп-фактор.
VolCh
05.10.2019 22:53Скорее это просто дополнительные расходы, а не проблема. Причём чем популярнее будет такой подход, тем меньше расходы.
zzzzzzzzzzzz
05.10.2019 22:27+1По мотивам навеянных статьёй мыслей поигрался с кодом и написал статью-ответ.
SharplEr
06.10.2019 11:17+1В нашем проекте мы решаем эту проблему как в питоне — джентльменским соглашением. Считается что List всегда неизменяемый, если только он не создан локально в текущем методе и тогда лучше пользоваться явным типом ArrayList например. Стараемся не передавать в методы изменяемые коллекции, но если очень надо передаём лямбду List::add а принимаем консьюмер. Конечно хуже, чем в Rust, но кажется самый адекватный выход.
eirnym
06.10.2019 17:59в Python есть
tupleиfrozenset. Насколько я знаю, второй используется значительно реже, но его применение всё-таки оправдано (я сам его использовал крайне редко). Соглашения о совместимости есть в соглашенияхcollections.abc, если нужна проверка типов.

Semenych
06.10.2019 13:36Все написано правильно. Но говоря по прикладном программировании я очень настороженно отношусь к реализации своих надстроек над стандартными классами. Причин тут несколько
1. Через 4 года, когда создатель этой надстройки окэшит опцион и пойдет работать в другую компанию — пришедшему программисту достанется еще одна загадка виде «зачем это все придуманно?». Статью на хабе он гарантированно не прочитает и будет использовать фичу как Бог на душу положит
2. Надстройка гарантированно не будет применяться консистентно в течении времени жизни проекта, что добавить +1 к запутанности проекта.
3. Имутабельность списков важна, и минимизация контрактов между методами и классами тоже крайне важна. Но часто компактный и простой код, который можно легко изменить значительно важнее. Т.е. если можно сделать код в 3 раза меньше за счет использования bare Java + одной/двух абсолютно стандартных библиотек, то я предпочту меньше кода.
UPD В текущем проекте вижу библиотечный класс FastByteArray2 созданный в 2004 году — все никак не соберусь с духом заглянуть, что внутри

sergey-b
06.10.2019 19:11Затронута очень важная тема. Она касается не только коллекций, а любых сложных объектов. Вроде, сам объект сделать иммутабельным легко, но как только среди его полей появляется коллекция или другая сложная структура, то возникает вопрос, что делать с ее иммутабельностью.
На мой взгляд, в статье также не упомянут важный момент, что иммутабельные объекты не всегда могут быть иммутабельными сразу, ведь их же еще надо как-то собрать, и в процессе сборки они будут и должны быть изменяемыми.
Например, как сделать иммутабельным XML-документ?
var xml = xmlParser.parse(input); var immutableXml = something(xml); // ??? где-нибудь такое есть?qw1
06.10.2019 21:01не упомянут важный момент, что иммутабельные объекты не всегда могут быть иммутабельными сразу, ведь их же еще надо как-то собрать
Это минимальная проблема. Все данные сделать приватными, передавать их в параметры конструктора. Методов на запись полей (кроме конструктора) не создавать.
mayorovp
Что-что он делает с границами API?
mk2
passes API boundaries as a List — переходит через границы API как List
lam0x86
Вот да, если перевод книги будет как в посте, то он нафиг не сдался. Пост на Хабре, наверняка, прошёл рецензирование редакторами.
Neikist
Раньше приобретал у них книги и норм было, но вот по андроиду книжка (не сказать что прям новая, но и не древняя) — переведена очень странно. Например класс А субклассирует класс Б — означает что А унаследован от Б. И еще много подобного было. Несмотря на всю мою нелюбовь к чтению на английском — иногда подгорает и задумываешься о том чтобы в оригинале читать.
math_coder
Так может в оригинале было "A subclasses B"?
Neikist
Вполне возможно. Вот только вопрос, кто то в реальной жизни говорит на русском «А субклассирует Б»?
math_coder
Это вообще не аргумент. В реальной жизни много чего не говорят. Если устоявшегося перевода у термина нет, бывает, что приходится и новый термин вводить в оборот.
Переводить "subclasses" как "наследует" было бы можно, если бы не существовало английского термина "inherits". Но он есть, так что "наследует" уже занято. "Субклассирует" — единственный вариант.
franzose
«является подклассом»?
math_coder
Всё равно отсебятина с потерей смысла. Если бы авторы хотели сказать, что "А является подклассом Б", то написали бы "A is a subclass of B". Но они написали иначе.
math_coder
Но если добавить "прим. перев." с указанием, что в оригинале было "subclasses", то я готов такой перевод принять как допустимый.
VolCh
А вы знаете смысл?
math_coder
Точный смысл, позволяющий отличить один синоним от другого? Нет, но мне не трубуется знать в чём именно разница между волшебником и магом, чтобы быть уверенным, что "wizard" нельзя переводить как "маг", а "mage" — как "волшебник".
VolCh
Вы вот уверены, а составители различных словарей — нет. Вот например https://www.multitran.com/m.exe?s=wizard&l1=2&l2=1
math_coder
Потому что словарь не специализированный. Специализированный для этой области скорее всего не существует.
sergey-b
Литературный перевод без некоторой доли отсебятины невозможен, иначе получится простой дословный перевод.
math_coder
Мне кажется, это как минимум не очевидно. Я думаю, дословный литературный перевод вполне возможен.
Безусловно, есть особые ситуации, когда либо литературный перевод, либо дословность: некоторые шутки, специфический культурный контекст и т. д. Есть также известные затруднительные ситуации, когда есть разные "системы" перевода (пример — перевод англоязычных ругательств на русский язык). Но как только одна из конкурирующих систем выбрана, возможности для творчества остаётся немного.
Но это всё же особые случаи. В общем случае, повторю, неочевидно, почему литературность должна исключать дословность.
qw1
А есть техническая разница между subclasses и inherits?
math_coder
Ну, по-идее "inherits" может применять и к интерфейсу. Но вообще это не важно. Я не уверен, есть ли разница между волшебником и магом, но если там, где в оригинале стоит "wizard", в переводе "маг", я говорю — в топку такой перевод.
VolCh
Из того, что автор оригинала использует один из многих синонимов в своём языке, вовсе не следует, что переводчик должен вводить новый термин в целевом языке из-за того, что в нём число синонимов для понятия меньше.
math_coder
Если хочет сохранить смысл оригинала — должен. Если хочет нести отсебятину — тогда он может вообще оставить только название, а остальное написать сам.
franzose
Ну согласитесь, что нет такого слова «субклассирует» в русском языке. И звучит оно странно. А если повторить пять раз, то как-то даже смешно :) Думаю, что калька уместна в отсутствие слова или фразы, столь же полно передающих смысл исходного выражения.
VolCh
Смысл оригинала переводчик не знает обычно. Только догадывается, как говорится, что хотел сказать автор.
lam0x86
Техническую литературу должен переводить специализированный переводчик со знанием предметной области. Если это не так, я бы не стал покупать такие книги.
netch80
Я изредка таки слышу вживую «A сабклассит B». Все понимают, что это жестокий жаргон, но для простоты и скорости… есть любители такого.
Но не «субклассирует», это перебор :\