

Изображение лица пользователя снимается с помощью инфракрасной камеры, которая более устойчива к изменениям света и цвета окружающей среды. Используя глубокое обучение, смартфон способен распознать лицо пользователя в мельчайших деталях, тем самым “узнавая” владельца каждый раз, когда тот подхватывает свой телефон. Удивительно, но Apple заявила, что этот метод даже безопаснее, чем TouchID: частота ошибок 1:1 000 000.
В этой статье разобран принцип алгоритма, подобного FaceID, с использованием Keras. Также представлены некоторые окончательные наработки, созданные с помощью Kinect.
Понимание FaceID
“… нейронные сети, на которых основана технология FaceID, не просто выполняют классификацию.”
Первым шагом является анализ принципа работы FaceID на iPhone X. Техническая документация может помочь нам в этом. С TouchID пользователь должен был сначала зарегистрировать свои отпечатки, несколько раз нажав на датчик. После 10-15 различных касаний смартфон завершает регистрацию.
Аналогично с FaceID: пользователь должен зарегистрировать своё лицо. Процесс довольно прост: пользователь просто смотрит на телефон так, как делает это ежедневно, а затем медленно поворачивает голову по кругу, тем самым регистрируя лицо в разных позах. На этом регистрация заканчивается, и телефон готов к разблокировке. Эта невероятно быстрая процедура регистрации может рассказать многое об основных алгоритмах обучения. Например, нейронные сети, на которых основана технология FaceID, не просто выполняют классификацию.
Выполнение классификации для нейронной сети означает умение предсказывать, является ли лицо, которое она “видит” в данный момент, лицом пользователя. Таким образом, она должна использовать некоторые тренировочные данные для прогнозирования “истинного” или “ложного”, но в отличие от многих других случаев применения глубокого обучения, здесь этот подход не будет работать.
Во-первых, сеть должна тренироваться с нуля, используя новые данные, полученные с лица пользователя. Это потребовало бы много времени, энергии и множество данных разных лиц (не являющимися лицом пользователя), чтобы иметь отрицательные примеры. Кроме того, этот метод не позволит Apple тренировать более сложную сеть “оффлайн”, то есть в своих лабораториях, а затем отправлять её уже обученной и готовой к использованию в своих телефонах. Считается, что FaceID основан на сиамской свёрточной нейронной сети, которая обучается “оффлайн”, чтобы отображать лица в низкоразмерном скрытом пространстве, сформированном для максимизации различия между лицами разных людей, используя контрастную потерю. Вы получаете архитектуру, способную делать однократное обучение, как упоминалось в Keynote.

От лица к числам
Сиамская нейронная сеть в основном состоит из двух идентичных нейронных сетей, которые также разделяют все веса. Эта архитектура может научиться различать расстояния между конкретными данными, такими как изображения. Идея состоит в том, что вы передаёте пары данных через сиамские сети (или просто передаёте данные в два разных шага через одну и ту же сеть), сеть отображает их в низкоразмерных характеристиках пространства, как n-мерный массив, а затем вы обучаете сеть, чтобы сделать такое сопоставление, что данные точек из разных классов были как можно дальше, в то время как данные точек из одного и того же класса находились как можно ближе.
В конечном итоге сеть научится извлекать наиболее значимые функции из данных и сжимать их в массив, создавая изображение. Чтобы понимать это, представьте, как бы вы описали породы собак с помощью небольшого вектора так, что похожие собаки имели бы почти схожие векторы. Вероятно, один номер вы использовали бы для кодирования цвета собаки, другой – для обозначения размера собаки, третий – для длины шерсти и т. д. Таким образом, собаки, похожие друг на друга, будут иметь схожие векторы. Сиамская нейронная сеть может делать это за вас, подобно тому, как это делает автоэнкодер.
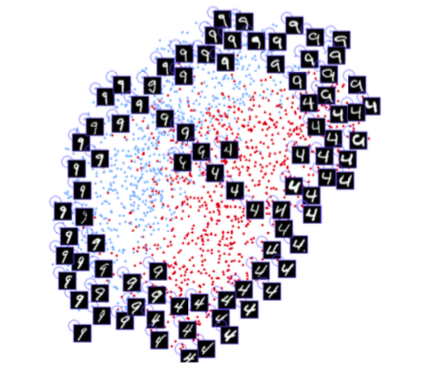
Используя эту технологию, необходимо большое количество лиц, чтобы обучить такую архитектуру распознавать наиболее схожие. Имея правильный бюджет и вычислительную мощность (как это делает Apple), можно также использовать более сложные примеры, чтобы сделать сеть устойчивой к таким случаям, как близнецы, маски и т. д.
В чём заключительное преимущество такого подхода? В том, что у вас, наконец, есть модель plug and play, которая может распознавать различных пользователей без какой-либо дополнительной подготовки, а просто вычислять, нахождение лица пользователя на скрытой карте лиц, образовавшейся после настройки FaceID. Кроме того, FaceID способен адаптироваться к изменениям в вашей внешности: как к внезапным (например, очки, шапка, макияж), так и к “постепенным” (растущие волосы). Это делается путём добавления опорных векторов лица, вычисленных на основе вашего нового внешнего вида, на карту.

Реализация FaceID с помощью Keras
Что касается всех проектов машинного обучения, первое, что нам нужно – данные. Создание собственного набора данных потребует времени и сотрудничества многих людей, поэтому с этим могут возникнуть сложности. Существует веб-сайт с набором данных RGB-D лиц. Он состоит из серии RGB-D фотографий людей, стоящих в разных позах и делающих разные выражения лица, как это произошло бы в случае использования iPhone X. Чтобы увидеть окончательную реализацию, вот ссылка на GitHub.
Создаётся свёрточная сеть на основе архитектуры SqueezeNet. В качестве входных данных сеть принимает как RGBD изображения пар лиц, так и 4-канальные изображения, и выводит различия между двумя вложениями. Сеть обучается со значительной потерей, которая минимизирует различие между изображениями одного и того же человека и максимизирует различие между изображениями разных лиц.
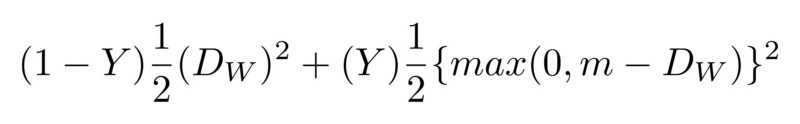
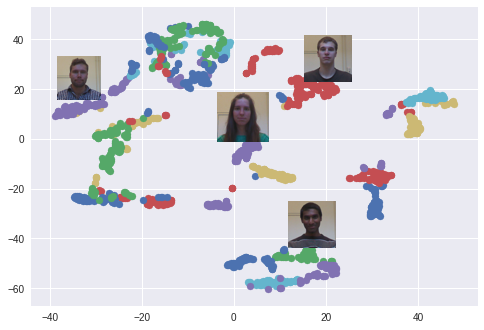
После обучения сеть способна конвертировать лица в 128-мерные массивы, так что фотографии одного и того же человека группируются вместе. Это означает, что для разблокировки устройства нейронная сеть просто вычисляет различие между снимком, который требуется во время разблокировки, с изображениями, сохранившимися на этапе регистрации. Если различие подходит под определённое значение, устройство разблокируется.
Используется алгоритм t-SNE. Каждый цвет соответствует какому-либо человеку: как вы можете заметить, сеть научилась группировать эти фотографии довольно плотно. Интересный график также возникает при использовании алгоритма PCA для уменьшения размерности данных.

Эксперимент
Теперь попытаемся увидеть, как работает эта модель, имитируя обычный цикл FaceID. Первым делом зарегистрируем лицо. Затем проведём разблокировку как от лица пользователя, так и от других людей, которые не должны разблокировать устройство. Как упоминалось ранее, различие между лицом, которые “видит” телефон, и лицом зарегистрированным имеет определённый порог.
Начнём с регистрации. Возьмём серию фотографий одного и того же человека из набора данных и смоделируем фазу регистрации. Теперь устройство вычисляет вложения для каждой из этих поз и сохраняет их локально.


Давайте посмотрим, что произойдет, если один и тот же пользователь попытается разблокировать устройство. Различные позы и выражения лица одного и того же пользователя достигают низкого различия, в среднем около 0,30.

С другой стороны, изображения от разных людей получают среднее различие около 1,1.

Таким образом, значение порога, установленное примерно в 0,4, должно быть достаточным для предотвращения разблокировки телефона незнакомцами.
В этом посте я показал, как реализовать проверочную концепцию механики разблокировки FaceID, основанную на встраивании граней и сиамских свёрточных сетях. Я надеюсь, что информация была для вас полезной. Вы можете найти здесь весь относительный код Python.
Больше разборов новых технологий — в Telegram канале.
Всем знаний!
Комментарии (10)

darkAlert
24.10.2019 21:52А есть какие-то пруфы что используется сиамская сеть? Чтобы не дообучать сеть на девайсе пользователя достаточно обучить классификатор на каком-нибудь loss из семейства SphereFace, а потом использовать предпоследний слой как Embedding. Либо я что-то не понял

Alexufo
24.10.2019 22:56Так, я что-то не понял. А где речь о 30 000 ик диодов в проекции на лицо?
Статья скорее про самсунговскую камеру, но у Apple абсолютно другая технология.
Вот более подробно
www.patentlyapple.com/patently-apple/2019/02/an-overview-of-apples-second-round-of-face-id-secrets-published-by-the-us-patent-office-this-week.html
А вот эта проекция. Там что-то типа по лазерному дальномеру в каждой точке. Отсюда получается точная карта глубины.

Alex_ME
25.10.2019 03:00Это камера глубины, наподобие Kinect, XTion и ряда других. В принципе, можно подать в аналогичную сеть карту глубины и RGB (разные подходы к совмещению RGB и данных глубины встречаются в разных задачах autonomous driving). Можно и с облаком точек работать, но такие сети я реже встречал
Alexufo
25.10.2019 03:14Не совсем верно. Кинект это стереометрия. Две и более камеры. Здесь же непосредственно маленькие ик дальномеры, снимающие каким-то образом расстояние до обьекта с большой точностью.Глубина высчитывается не свойствами машинного зрения, а датчиками измерения глубины нового типа для мобильных устройств.

15432
25.10.2019 08:58Как Kinect, так и FaceID используют миниатюрный ИК проектор, светящий облаком точек. По их расположению и вычисляется глубина объекта. Сами точки можно увидеть, например, через камеру ночного видения. Само устройство имеет дополнительную ИК камеру с германиевым фильтром для этих целей.
https://youtu.be/CEep7x-Z4wYAlexufo
25.10.2019 13:16-1Да, но проектор там иснимает глубину по некому structured light алгоритму. У FaceID каждая точка — маленький лазерный дальномер, ну, как я это понял)
15432
25.10.2019 14:45Я так понял, технология та же самая. Облако точек, обычная камера и ИК камера. Тысячи лазерных дальномеров в шапке экрана iPhone звучит слишком нереалистично.
Alexufo
25.10.2019 15:03+1Apple's patent claims point to two illumination modes are used in Face ID with the first using a flood illumination process followed by a second illumination mode that uses multiple discrete points of illumination using a vertical-cavity surface-emitting laser (VCSEL) to determine depth.
По ссылке выше.
onum
25.10.2019 09:27Ну так и в посте используют rgb-d датасет.
Но даже, если б и не было, принцип не поменялся бы, если бы добавился новый источник данных.
gleb_kudr
Если бы такая точность была с двух сторон, то я бы порадовался за технологию. Только вот ложно-негативные кейсы на много порядков чаще. У меня близорукость, на комфортной дистанции зрения в 15 см. распознавание срабатывает в 0% случаев. Видимо, потому что не все лицо попадает в кадр. Т.е. оно как минимум не инвариантно к количеству фич в кадре.