
 Вот уже 16 лет как открытая массивно-параллельная СУБД Greenplum помогает самым разным предприятиям принимать решения на основе анализа данных.
Вот уже 16 лет как открытая массивно-параллельная СУБД Greenplum помогает самым разным предприятиям принимать решения на основе анализа данных.За это время Greenplum проник в различные сферы бизнеса, в числе которых: ритейл, финтех, телеком, промышленность, e-commerce. Горизонтальное масштабирование до сотен узлов, отказоустойчивость, открытый исходный код, полная совместимость с PostgreSQL, транзакционность и ANSI SQL — трудно представить более удачное сочетание свойств для аналитической СУБД. Начиная от громадных кластеров в мировых компаниях-гигантах, как, например, Morgan Stanley (200 узлов, 25 Пб данных) или Tinkoff (>70 узлов), и заканчивая маленькими двух-нодовыми инсталляциями в уютных стартапах — всё больше компаний выбирают Greenplum. Особенно приятно наблюдать этот тренд в России — за последние два года количество крупных отечественных компаний, использующих Greenplum, выросло втрое.
Осенью 2019 года вышел очередной мажорный релиз СУБД. В этой статье я коротко расскажу об основных новых возможностях GP 6.
Предыдущий мажорный релиз Greenplum версии 5 вышел в свет в сентябре 2017 года, подробности можно узнать в этой статье. Если вы ещё не знаете, что такое Greenplum, краткое представление можно получить из этой статьи. Она старая, но архитектуру СУБД отражает верно.
Нынешний релиз, по праву, может называться коллективным детищем: в разработке участвовало несколько компаний со всего света — среди них Pivotal, Arenadata (где трудится автор этой статьи), Alibaba.
Итак, что нового в Greenplum 6?
Replicated tables
Напомню, в Greenplum существовало два типа распределения таблиц по кластеру:
- Случайное равномерное распределение
- Распределение по одному или нескольким полям
В большинстве случаев соединение двух таблиц (JOIN) выполнялось с перераспределением данных между сегментами кластера в процессе выполнения запроса, и только если обе таблицы были изначально распределены по ключу соединения JOIN происходил локально на сегментах без передачи данных между сегментами.
GP 6 даёт архитекторам новый инструмент оптимизации схемы хранения — реплицированные таблицы. Такие таблицы дублируются в полном объёме на всех сегментах кластера. Любое соединение с такой таблицей в правой части будет выполняться локально, без перераспределения данных. В основном фича предназначена для хранения объёмных справочников.
CREATE TABLE expand_replicated
…
DISTRIBUTED REPLICATED;
CREATE TABLE expand_random
…
DISTRIBUTED RANDOMLY;
explain select * from expand_rnd a2 left join expand_replicated a3 on a2.gen = a3.gen
#Соединение происходит локально, в плане нет redistribute/broadcast
Limit (cost=0.00..1680.04 rows=1 width=22)
-> Gather Motion 144:1 (slice1; segments: 144) (cost=0.00..1680.04 rows=2 width=22)
-> Hash Left Join (cost=0.00..1680.04 rows=1 width=22)
Hash Cond: (expand_rnd.gen = expand_replicated.gen)
-> Seq Scan on expand_rnd (cost=0.00..431.00 rows=1 width=10)
-> Hash (cost=459.60..459.60 rows=2000000 width=12)
-> Seq Scan on expand_replicated (cost=0.00..459.60 rows=2000000 width=12)
Алгоритм компрессии Zstandard (ZSTD)
Представленный в 2016-ом году разработчиками Facebook алгоритм сжатия без потерь практически сразу запал в душу нашей команде Arenadata, ведь по сравнению с Zlib (используется в Greenplum по-умолчанию) он имеет более высокие коэффициенты сжатия при меньшем времени, необходимом на компрессию и декомпрессию:
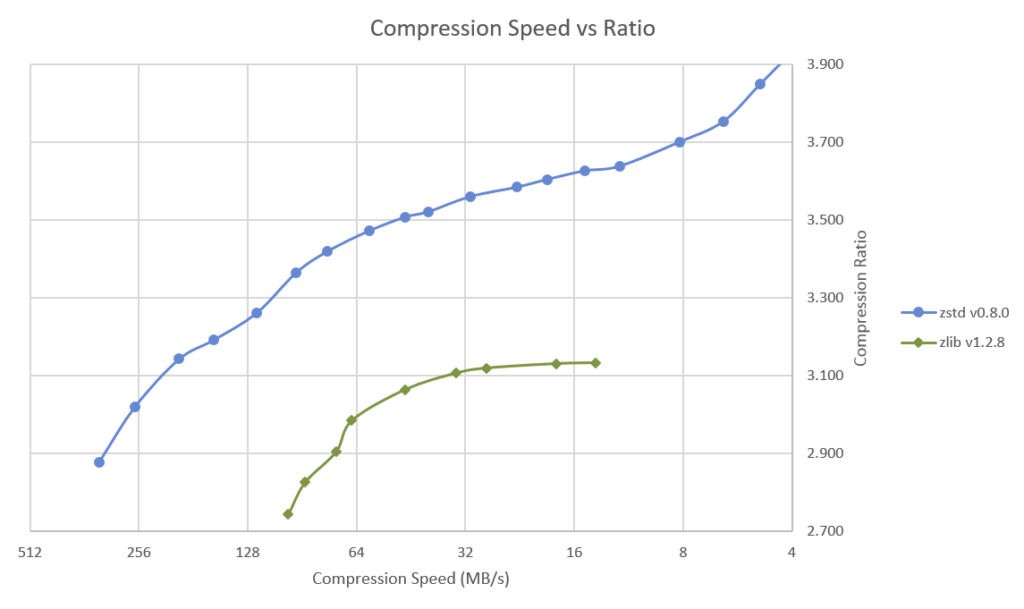
Источник: cnx-software.com
Эффективность компрессии — один из самых важных параметров современных аналитических СУБД. Фактически она позволяет уменьшить нагрузку на сравнительно дорогую дисковую подсистему кластера, загрузив относительно дешёвые CPU. При последовательном чтении и записи больших объёмов данных это даёт сильное уменьшение TCO системы.
В 2017 году наша команда добавила поддержку ZSTD для колоночных таблиц в Greenplum, однако, согласно релизной политике, в официальные минорные релизы Greenplum эта доработка не попала. До сегодняшнего дня она была доступна только коммерческим заказчикам Arenadata, а с выходом 6.0 её могут использовать все желающие.
Оптимизация расширения кластера (expand)
В предыдущих версиях GP горизонтальное расширение кластера (добавление новых узлов) имело некоторые ограничения:
- Даже при том, что перераспределение данных происходило в фоновом режиме без даунтайма, при добавлении новых узлов был необходим перезапуск системы
- Алгоритм хеширования и распределения данных требовал полного перераспределения всех таблиц при расширении — фоновый процесс распределения данных мог занимать часы или даже дни для особо крупных кластеров
- Во время работы фонового распределения таблиц любой джойн выполнялся только распределённо
Greenplum 6 привнёс абсолютно новый алгоритм экспанда кластеров, благодаря чему:
- Расширение теперь происходит без перезапуска системы — даунтайм не нужен
- Алгоритм consistent hashing позволяет при добавлении узлов перераспределять только часть блоков, то есть, фоновое перераспределение таблиц работает в разы быстрее
- Изменилась логика изменения системных каталогов — теперь даже в процессе экспанда все соединения (JOIN) работают как обычно — как локально, так и распределённо
Теперь расширение Greenplum — это дело минут, а не часов, это позволит кластерам неотрывно следовать за всё растущими аппетитами бизнес-подразделений.
Column-level security
Теперь есть возможность раздавать права на конкретные колонки в таблицах (фича приехала из PostgreSQL):
grant all (column_name) on public.table_name to gpadmin;JSONB
Двоичное, оптимальное хранение объектов типа JSON теперь доступно в GP. Подробнее о формате здесь.
Auto Explain
Ещё одно отличнейшее расширение, пришедшее в GP из PostgreSQL. Было модифицировано для работы в распределённом режиме на кластере Greenplum командой Arenadata.
Позволяет автоматически для каждого (или отдельно взятого) запроса в СУБД сохранять информацию о:
- плане запроса;
- потреблённых ресурсах на каждом этапе выполнения запроса на каждом сегменте (ноде);
- затраченном времени;
- количестве строк, обработанных на каждом этапе выполнения запроса на каждом сегменте (ноде).
Diskquota
Расширение PostgreSQL, позволяющее ограничивать доступный объём дискового хранилища, доступный отдельным пользователям и схемам:
select diskquota.set_schema_quota('schema_name', '1 MB');
select diskquota.set_role_quota('user_name', '1 MB');Новые фичи дистрибутива Arenadata DB
Disclaimer — дальше будет пара строчек рекламы :)
Напомню, мы, Arenadata, разрабатываем, внедряем и поддерживаем нашу платформу хранения данных на основе технологий с открытым исходным кодом — Greenplum, Kafka, Hadoop, Clickhouse. Наши клиенты — крупнейшие российские компании в сферах ретейл, телеком, финтех и других. С одной стороны, мы являемся контрибуторами самих open-source проектов (комитим изменения в ядро), с другой стороны мы разрабатываем дополнительный функционал, доступный только нашим коммерческим заказчикам. Дальше речь пойдёт про основные такие фичи.
Tkhemali Connector aka коннектор Greenplum -> Clickhouse
В проектах мы часто используем связку Greenplum + Clickhouse — с одной стороны, это позволяет использовать лучшие классические модели построения хранилищ данных (от источников до витрин данных), требующие множество соединений, развитый синтаксис ANSI SQL, транзакционность и другие фишки, которые есть в Greenplum, с другой — предоставлять доступ к построенным широким витринам с максимальной скоростью значительному числу пользователей — а в этом у Clickhouse нет конкурентов.
Для эффективного использования такой связки мы разработали специальный параллельный коннектор, который транзакционно (то есть консистентно даже в случае отката транзакции) позволяет переносить данные из GP в KH. Вообще, архитектура этого коннектора заслуживает отдельной сугубо технической статьи — по факту внутри нам пришлось реализовать параллельные асинхронные очереди с системой динамического выбора числа потоков на вставку и мёрджем данных.
Результат — фантастическая скорость взаимодействия: в наших тестах на типовых SATA-дисках мы получаем до 1 Гб/с на вставку на одну пару серверов Greenplum — Clickhouse. С учётом того, что средний кластер GP у наших заказчиков состоит из 20+ серверов, скорость взаимодействия более чем достаточная.
Kafka Connector
Аналогично мы поступили и с интеграцией с брокером сообщений Kafka — мы очень часто сталкиваемся с задачей перегружать данные из Kafka в Greenplum в режиме near real-time (секунды или десятки секунд). Однако, архитектура коннектора для Kafka другая. Коннектор представляет собой кластер из отдельных синхронизированных процессов (запущены в Docker) с auto-discovery, которые, с одной стороны, являются консьюмерами Kafka, а с другой — вставляют данные напрямую в сегменты Greenplum. Коннектор умеет работать с Kafka Registry и обеспечивает полную консистентность переносимых данных даже в случае аппаратных сбоев.
Система управления и мониторинга
Эксплуатация системы в production предъявляет высокие требования к системе деплоя, обновления и мониторинга кластера. Важно, чтобы всё, что происходит в СУБД было прозрачно для специалистов operations и DBA.
Наша система управления и мониторинга Arenadata Cluster Manager (ADCM) даёт специалистам эксплуатации все необходимые для этого инструменты. Фактически, деплой и обновление кластера Greenplum делаются по нажатию кнопки в графическом интерфейсе (при этом все настройки ОС, сервисов, монтирование дисков и настройка сети производятся автоматически), кроме того, вы получаете полностью настроенный стек мониторинга, готовый к интеграции с вашими корпоративными системами. Кстати, Arenadata Cluster Manager умеет управлять не только Greenplum, но и Hadoop, Kafka, Clickhouse (требуются наши сборки этих сервисов. Их бесплатные версии, как и сам ADCM, можно абсолютно свободно скачать на нашем сайте, всего лишь заполнив pop-up).
Заключение
Если вы используете Greenplum 5.X, рекомендую рассмотреть обновление вашего кластера на актуальную версию 6.Х в ближайшие 2-3 месяца.
Если вы ещё не используете Greenplum — присоединяйтесь! Мы, Arenadata, всегда готовы вам в этом помочь.
Ссылки
Greenplum на github
Telegram-канал Greenplum Russia — задайте свои вопросы напрямую пользователям Greenplum
Документация Greenplum 6
Комментарии (6)

TimonKK
14.11.2019 17:05Скажите, правильно ли я понимаю архитектуру Greenplum в плане утилизации CPU: если сейчас нужно утилизировать 6 ядер из 16 — создаем 6ть сегментов. А если в будущем понадобиться 12 ядер — нужно создать ещё 6 сегментов и перешардировать?

kapustor Автор
14.11.2019 17:10В целом, правильно, но есть нюанс: один запрос утилизирует максимум одно ядро на один сегмент. То есть, если, например, в вашем примере 6 сегментов и 16 ядер на сегмент-сервер, то один запрос утилизирует максимум 6 ядер, два запроса — 12 ядер, и так далее. Так как обычно в аналитической СУБД работает 20-100 запросов, то проблем с утилизацией не возникает почти никогда (если, конечно, совсем не жестить и не делать по одному сегменту на сервер).

gatt
14.11.2019 17:06Каждый раз, когда вижу статью про greenplum не могу понять, почему не упоминается сжатие rle, хотя в тестах сжатие вроде выше?
Добавление сегментов на gp5 требует не только перезапуска, но так же синхронизации метаданных. При большом объеме метаданных это может давать часы простоя.
Про переход на gp6: так и не доделан gp_upgrade. А бэкап-рестор может быть очень долгим, это могут быть сутки простоя. Что подойдёт далеко не всем.kapustor Автор
14.11.2019 17:17О, с RLE ситуация интересная. Действительно, RLE даёт фантастическую степень сжатия (в моей практике доходило до 60-70 раз). Иногда. Если быть точным, при соблюдении нескольких условий:
1. Дельта между данными (строками) небольшая и одинаковая
2. Таблица отсортирована (в случае с ГП это INSERT… SELECT… ORDER BY… )
На практике RLE выстреливает ОЧЕНЬ редко. Всегда надо пробовать и смотреть, что оно даст. Обычно получается использовать RLE для подневных витрин или таблиц фактов.
Про метаданные — всё так. Другой вопрос, что если у вас настолько много метаданных, что они реплецируются по интерконнекту часами, то, возможно, стоит пересмотреть модель? В нашей практике есть только один заказчик с действительно раздутыми каталогами.
gp_upgrade — да, пока не доделан. Кстати, наша команда (Arenadata) принимала активное участие в его разработке этим летом, надеемся к нему вернуться. Минусы бекапа и рестора понятны, но есть разные методики, ускоряющие миграцию, мы в том числе и этим помогаем нашим заказчикам.
vovik0134
> Теперь есть возможность раздавать права на конкретные колонки в таблицах (фича приехала из PostgreSQL)
Видимо я что-то упустил, когда это в PostgreSQL появилась такая функциональность? Можно ссылку на документацию?
kapustor Автор
Так вот же в официальной документации PostgreSQL 9.4:
GRANT { { SELECT | INSERT | UPDATE | REFERENCES } ( column_name [, ...] )[, ...] | ALL [ PRIVILEGES ] ( column_name [, ...] ) }
ON [ TABLE ] table_name [, ...]
И там же пример:
GRANT SELECT (col1), UPDATE (col1) ON mytable TO miriam_rw;