
Что это такое?
Полностью гомоморфное шифрование (Fully Homomorphic Encryption) очень долго было самым ярким открытием в молодой и бурно развивающейся области Computer Science — криптографии. Вкратце, такой тип шифрования позволяет делать произвольные вычисления на зашифрованных данных без их расшифровки. Например, гугл может осуществлять поиск по запросу не зная, что это за запрос, можно фильтровать спам, не читая писем, подсчитывать голоса, не вскрывая конверты с голосами, делать DNA тесты, не читая DNA и многое, многое другое.

То есть, человек/машина/сервер, производящий вычисления, делает механические операции с шифрами, исполняя свой алгоритм (поиск в базе данных, анализ на спам, и т.д.), но при этом не имеет никакого понятия о зашифрованной внутри информации. Только пользователь зашифровавший свои данные может расшифровать результат вычисления.
Здорово, правда? И это не из области фантастики — это то, что уже можно «теоретически» воплотить в жизнь.
От теории до практики не всегда, правда, рукой подать и иногда на это уходят десятилетия. Операции в современных схемах гомоморфного шифрования гораздо медленнее обычных и по закону Мура станут сравнимы со скоростью вычислений на сегодняшний день лет через 40. Но с каждым годом схемы становятся проще и быстрее, так что, кто знает, может уже не за горами новая веха в развитии IT технологий.
История создания

История создания первой схемы довольно необычна: профессор стэнфордского университета Dan Boneh взял за правило всем новоприбывшим аспирантам предлагать «Automatic PhD problem». Как правило, это очень сложная (но не гробовая) задача по криптографии, над которой ученые бьются хотя бы вот уже с десяток лет. В 2006 году Dan предложил придумать схему для Fully Homomorphic Encryption своему новому студенту, Craig Gentry. Через два года Craig ее решил. Dan сдержал обещание и Craig стал одним из первых студентов кто так быстро получил доктора наук. Имея давнюю страсть к математике, Craig получил вначале юридическое образование и некоторое время работал юристом, пока в довольно сознательном возрасте не решил вновь вернуться к математике и поступил в аспирантуру Стэнфорда.
Простая идея
Схемы для полностью гомоморфного шифрования были вначале доступны для понимания только специалистам в теории чисел, но за последние 5 лет они настолько упростились, что их основную идею можно объяснить школьнику.
Итак, представьте, что вы хотите зашифровать число x (может быть это всего лишь очередной бит ваших данных, может быть небольшое натуральное число). Выберите себе произвольный вектор v (он будет вашим секретным ключом). Возможно найти такую матрицу A, что будет верно Av ~= xv, т.е. произведение A на v даст примерно вектор v умноженный на число x (для тех кто помнит немножко алгебру, v будет «примерным» собственным вектором, а x «примерным» собственным числом матрицы A). Если вы захотите зашифровать новое число y, то опять же можно будет найти матрицу B, такую что Bv ~= yv. Таким образом вы можете, имея только один секретный ключ v, зашифровать сколько угодно чисел, где шифром каждого числа будет матрица. Чтобы расшифровать число, мы умножим матрицу на секретный вектор v.
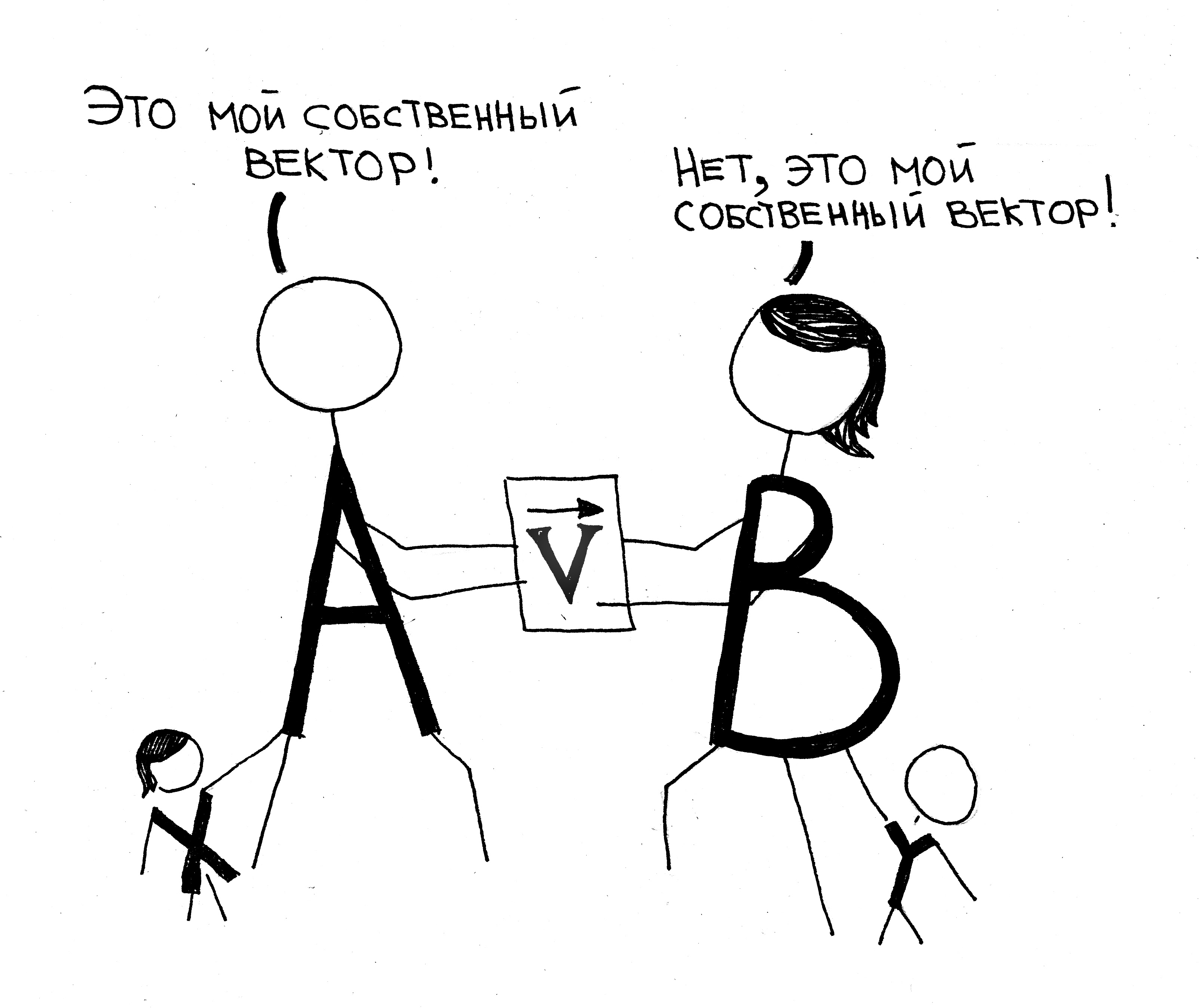
Можно доказать, предполагая сложность одной архаической задачи про поиск короткого вектора в решетке, что также сложно, имея матрицы A и B, со значимой вероятностью (отличимой от случайного угадывания) сказать какие числа x и y они шифруют (не зная, разумеется, секретного вектора v).
Таким образом, это действительно шифровальная схема, но она также является гомоморфной! Т.е., оперируя с матрицами A и B, а именно умножая и складывая их, мы будем умножать и складывать те числа, которые они шифруют. Действительно, посмотрим, что даст расшифровка произведения A и B:
(AB)v = A (Bv) ~= A xv = x (Av) ~= (xy)v, она дает произведение x и y!
А расшифровка суммы A и B даст
(A + B)v = Av + Bv ~= xv + yv ~= (x + y)v, сумму x и y!
Конечно, здесь требуется более точный анализ, чтобы убедиться, что примерное равенство сохраняется. Также, нахождение шифрующей матрицы не совсем тривиальная задача, но во всем этом вполне реально разобраться, если ненадолго погрузиться в несколько хороших статей, как например вот эта:
[GSW'13] «Homomorphic Encryption from Learning with Errors: Conceptually-Simpler, Asymptotically-Faster, Attribute-Based» (pdf)

Окно в новый мир
Craig открыл дверцу в своего рода новый мир. Сегодня мы имеем огромное количество вариаций гомоморфного шифрования и самое интересное, что одна из вариаций может дать лучший из возможных, теоретически самый стойкий способ обфускации программ, а это откроет еще больше возможностей для фантазии! Но об этом в другой раз. Если вам интересна текущая задача, за решение которой Dan дает PhD автоматически, пишите в комментариях ;)
Комментарии (70)


Anton_Menshov
09.04.2015 01:18+3«Примерный» все же советую заменить на слово «приближенный» — это более научный термин.
Очень бы советовал заменить «x» и «y» на "?1" и "?2". Обычно под x и y в линейной алгебре (и в принципе), понимаются вектора, а не скаляры. Тогда как, ?'бды традиционно используются для обозначения собственного значения матрицы (пусть и безотносительно приближения).
Надо будет обязательно прочитать оригинальную статью, но с приближенными собственными значениями и векторами действительно не все так просто. Скорее всего, нужно придумывать алгоритм, генерирующий хорошо обусловленные матрицы A и B (имеется ввиду, что отношение максимального и минимального собственного значения матрицы не зашкаливает). В этом случае, небольшие пертурбации в «приближении» не должны значительно сильно сказаться на конечном результате.

Duduka
09.04.2015 07:08а если взять унитарную матрицу смасштабировать на на собственное значение, прибавить случайный делитель нуля?

valerini Автор
09.04.2015 07:43Да, матрицы действительно должны быть «хорошими» в том смысле о котором вы говорите, но этого не так сложно достигнуть, они генерируются довольно просто…
Я не использую ?'бды, потому что их не используют в литературе по этой теме. Обычно используют ? или просто m, x и y удобно использовать, потому что мы вычисляем f(x, y) и на этом фокусируемся, абстрагируясь от того, что это собственные числа шифров. Но обозначения не так важны, я надеюсь.

k1b0rg
09.04.2015 06:52+1А как насчет частотного анализа? Ведь налицо шифр замена — символы заменяются матрицами «a»->?1, «b»->?2...«z»->?28.

dtestyk
09.04.2015 23:12вроде, заменяются не символы, а числа
одному числу может соответствовать несколько матриц
valerini Автор
09.04.2015 23:36+1Шифрование вероятностное (шифрующий алгоритм пользуется случайными числами), поэтому зашифровав символ «a» -> ?1 два раза вы получите две разных матрицы.
Грубо говоря, для одного раза это будет матрица A, такая что Av=?1v + e1 (где e1 это один маленький вектор), а во второй раз, шифром будет матрица B, такая что Bv=?1v + e2 (где e2 это ДРУГОЙ маленький вектор). Но имея эти A и B (и не имея вектора v) вы не сможете понять даже, шифруют ли эти две матрицы один и тот же символ (или одно и то же «примерное» собственное число) или нет.

bazzilic
09.04.2015 08:03+4Надо заметить, что схема Крэйга Джентри работает страшно медленно и для практического применения не годится вообще. Джентри вместе с сотрудниками IBM работал над созданием чуть более быстрой схемы, но серьезного улучшения получить не удалось. Если кому интересно, то можете посмотреть на HELib — реализация схемы Джентри написанная на C.
В статье не совсем правильно написано, что такое гомоморфное шифрование. Вообще говоря, гомоморфное шифрование сохраняет одну операцию — это может быть умножение, сложение, XOR, умножение на незашифрованную константу, возведение в степень, что угодно. Таких схем вагон и маленькая тележка. Всем известный RSA (без пэддинга) сохраняет операцию умножения. Схема ElGamal гомоморфна относительно умножения, схема Paillier — относительно сложения. Схема Джентри — это первая полностью гомоморфная схема: она сохраняет и умножение, и сложение. Впрочем, есть схема Boneh-Goh-Nissim (тот самый Boneh, научник Крэйга Джентри), которая умеет делать много сложений и затем одно умножение.
А огромный коэффициент экспансии характерен для всех гомоморфных схем.valerini Автор
09.04.2015 08:29Да, вы правы, схемы, которые могут делать обе операции называются Fully Homomorphic Encryption.

MichaelBorisov
09.04.2015 13:20+2Нда, любопытно. Получается, что любой блочный шифр в режиме CTR сохраняет операцию XOR, т.е. тоже является гомоморфным.
bazzilic
10.04.2015 10:17Хорошее наблюдение, но XOR сохранять дело нехитрое :) Еще надо уточнить, что когда мы говорим «сохраняет операцию» это не значит, что сама операция остается неизменной. Более формально, шифр (E,D) сохраняет n-арную операцию f, если существует операция g такая, что для любых значений a_1, ..., a_n из области определения f
f(a_1, ..., a_n) = D(g(E(a_1), ..., E(a_n)))
Скажем, в шифре Paillier для гомоморфного сложения зашифрованных значений, нужно их перемножить.
valerini Автор
09.04.2015 22:12+1Я исправлю это в посте. Спасибо что заметили. Сейчас уже часто просто говорят Homomorphic, но термин Fully Homomorphic, конечно, точнее.

Volmontovich
09.04.2015 09:03+1Могу порекомандовать вот эту статью:
Xiao L., Bastani O., Yen I. L. An Efficient Homomorphic Encryption Protocol for Multi-User Systems //IACR Cryptology ePrint Archive. – 2012. – Т. 2012. – С. 193.
В ней описывает так же гомоморфное шифрование на матрицах но, кажется, более эффективное с плане скорости и производительности. К сожалению, я уже около года не особенно слежу за этой областью, поэтому не знаю, были ли найдены какие-то уязвимости у нее, но выглядит она интереснее.
valerini Автор
09.04.2015 09:35Но эта статья не опубликована ни в каком авторитетном источнике (на сколько я понимаю), а это скорее всего означает, что она имеет какие-то проблемы с правильностью доказательств или результатов.
ivlis
09.04.2015 17:10Да у математиков это нормально закинуть на arxiv и считать, что опубликовано :)
valerini Автор
09.04.2015 20:29+1Статьи по ГШ обычно публикуются (по крайней мере на конференциях), тем более у этой статьи только 8 сомнительных цитирований, а у статьи на которую дана ссылка в посте — 83. И статьи по ГШ обычно публикуются на архиве eprint.iacr.org.
Но это ничего не значит, возможно, авторы действительно просто поленились :) Хотя статью написать это бОльшая часть дела, так что уж грех не послать ее хоть куда-то.

Master_Dante
09.04.2015 13:38+1Удивительно я никогда не слышал про такой тип шифрования. Я так понимаю складывать числа из разных шифров нельзя, тогда каким образом можно определить спам? К примеру мы должны обнаружить в письме слово «реклама», как это сделать если мы не знаем шифра?
valerini Автор
09.04.2015 20:47+2Очень хороший вопрос! Допустим, есть алгоритм/программа, она ищет в тексте слово «реклама» (простой поиск подстроки). Этот алгоритм можно представить в виде набора бинарных операций (используя «или» и «и») или даже с помощью одной операции NAND (Штрих Шеффера), «не и» (то, что собственно вычисляет каждый транзистор). Это будет называется представлением алгоритма в виде булевой схемы.
Этот NAND(x, y) в свою очередь можно представить как набор арифметических операций: NAND(x, y) = (1 — xy) (если входы бинарны — выход будет бинарным), эти операции может делать гомоморфная схема — это просто вычитание и умножение. Т.е. весь алгоритм поиска подстроки можно осуществить гомоморфными операциями.
Но все не совсем так просто: вы, наверное, подумали, «а что же делать с циклами и ветвлениями (if/else)? Ведь если переводить это в лоб, то надо будет раскрывать/линеаризировать эти циклы и ветвления.» На этот счет есть ряд потрясающих результатов, которые говорят что это можно очень эффективно сделать, спровоцировав увеличение длины программы только в логарифмическое число раз. Т.е. была программа длины n, а стала схема размера n log n. (Число атомов во вселенной 2^300, а поэтому логарифм можно считать константой… это шутка :) )Master_Dante
10.04.2015 16:10Я так и не понял главного. Буква «Р» в utf16 это число 1056. И что бы узнать искомая ли это буква, нужно сделать что то типа
if (cur_char — 1056 == 0)
Как гугл сможет это сделать не зная шифра? Для этого он у нас должен попросить, зашифровать букву «Р» да и все слово и отослать ему. Однако это в свою очередь, компрометирует сам шифр, так как со временем гугл соберет весь алфавит, и будет читать наши сообщения.
>> Ведь если переводить это в лоб, то надо будет раскрывать/линеаризировать
Похоже я не понимаю еще кое что… Почему нельзя использовать классический алгоритм если каждый символ исходного текста отдельная матрица? Ведь именно такой пример вы показали в статье…
И еще один вопрос. Справедливо ли что если a < b до шифрования, то Ma — Mb < Mb — Ma после шифрования? Тут станет вопрос о корректности сравнения матриц, однако если при вычитании двух матриц, в результате мы получаем неотрицательную матрицу (когда все элементы матрицы больше или равны 0), то можно однозначно сказать, что одна матрица больше другой. Нельзя ли провести частотный анализ сравнивая матрицы таким образом? Действительно ли такое преобразование скрывает отношения исходного ряда чисел. Проводилось ли какое нибудь исследование криптостойкости?mayorovp
10.04.2015 19:47+2А «гугл» этого никогда и не узнает. Все, что он будет знать — это зашифрованную разность. Потом «гуглу» надо будет исполнить обе ветви алгоритма и получить зашифрованные результаты — после чего применить гомоморфный тернарный оператор для получения шифрованного ответа.
При использовании гомоморфного шифрования «гугл» сам не знает, что именно он нашел, где и нашел ли вообще.

alexeykuzmin0
09.04.2015 19:21+1Не вполне понятно, насколько это применимо. Да, мы можем сложить два сообщения или перемножить их, но зачем?
А если кто-то может найти в моем сообщении слово «спам» (и любое другое), то зачем мне такое шифрование?
vics001
09.04.2015 20:36Особенно непонятно с поиском по запросу, гугл ведь знает какие результаты возвращаются, а результаты важнее самого поиска, ведь по ним понятно интересны они человеку или нет.
valerini Автор
09.04.2015 20:52+1Гугл не знает, какие результаты возвращаются, поскольку они возвращаются в зашифрованном виде.
Я посылаю: pk, Enc(pk, «query»), Гугл вычисляет Enc(pk, search(«query»)) — вычисляет алгоритм «search» на моих данных (на «query») и посылает мне результат обратно. Посколько я знаю sk, я могу дешифровать:
Dec(sk, Enc(pk, search(«query»))) -> search(«query») и узнать результаты поиска.vics001
09.04.2015 23:40Не хочу вас расстраивать, но результаты невозможно получить арифмитическим преобразованием запроса. Результаты надо прочитать из БД данных, возможно вы даже можете получить индекс или хеш запроса, по которому гугл вычитает их с диска. Тут-то гугл и узнает ваш запрос или хеш, но это уже не важно.
valerini Автор
10.04.2015 02:25Да, не в один тык, разумеется, гомоморфное шифрование изменит то, как работает гугл, тем более что размеры его баз данных огромны, а алгоритмы очень трудоемки.
Но самый простой метод делать поиск с ГШ это написать функцию поиска, которая будет просматривать всю базу данных. Это можно сделать арифметическим преобразованием: это можно сделать с помощью NAND операций (что и делают транзисторы в любом компьютере), а NAND(x,y) = 1-xy. Но, естественно, просматривать всю базу данных никто не будет для одного запроса, для этого потребуются оптимизации: может быть агрегация запросов многих пользователей, методами Oblivious RAM или Multi-Party-Computations. Но пока это от нас далеко. Поиск по какой-нибудь небольшой базе, например, сотрудников компании, вполне осуществим простым методом просмотра всей базы.
valerini Автор
09.04.2015 20:50+3Нет-нет. Алгоритм ищет слово «спам», но он не получает ответ в чистом виде — только вы можете расшифровать ответ алгоритма. Т.е. вам придут все ваши письма, после фильтра на спам, вы их дешифруете и узнаете (на стороне клиента), какие письма были помечены как спам, а какие нет. И ваш почтовый клиент может их уже локально отсортировать. Бонус в том, что вам не надо будет исполнять потенциально сложный алгоритм проверки на спам самому.

Chamie
10.04.2015 08:29Проблема в том, что если алгоритм знает, что он ищет, то это, фактически, равнозначно дешифровке. А если не знает — то это равнозначно «антиспаму» на самом клиенте.

lostmsu
11.04.2015 02:03+1Идея гомоморфного шифрования в том, что у вас нет миллиона серверов, вам нужно посчитать что-то сложное, а свои входные и выходные данные никому давать не хочется. Вы платите Гуглу, Гугл для вас считает. Входные данные и результаты есть только у вас.
Chamie
13.04.2015 15:11+1Да, но конкретный функционал «антиспам» — он не работает (с приемлемой эффективностью) без общей для множества пользователей базы. Т.е. по эффективности такой «гомоморфный антиспам» —
это равнозначно «антиспаму» на самом клиенте.
zvic
09.04.2015 22:43+1Кстати, упомянутый в топике Dan Boneh ведет на Coursera очень неплохие курсы по криптографии.
valerini Автор
09.04.2015 23:39+2Да, это очень интересный курс и Dan Boneh очень увлекательный лектор, вот видеолекции с этого курса:
class.coursera.org/crypto-preview/lecture

xmm0
23.04.2015 23:18Тут надо бы уточнить, что ценность работы Craig Gentry в именно в том, что он придумал Fully Homomorphic схему, то есть такую, в которой есть гомоморфизм относительно сложения и умножения.
А так легко заметить, что даже textbook RSA является гомоморфной относительно умножения:
(m_1)^e * (m_2)^e = (m_1*m_2)^e (mod N)
xmm0
23.04.2015 23:26Тоже самое, что и в комментарии habrahabr.ru/post/255205/#comment_8368569, не обращайте внимания
ivlis
Что значит «примерно собственный вектор»?
Имея матрицу A в чём проблема найти все собственные числа?
saluev
Смотря какого она порядка!
К тому же, придётся выбирать одно из многих, и непонятно, как.
ivlis
Какая разница какого порядка, там же сложность <O(n^3). Всего n собственных чисел, все перебрать это ещё O(n). А для шифрования нужно O(2^n).
saluev
Ну возьмите матрицу порядка 2^(n/3), будет O(2^n).
Потом, O(n^3) — это если у вас матрица вещественная или комплексная. А если над конечным полем, то не так всё просто.
ivlis
Ага, а шифровать оно сколько будет? Тоже O(2^n)? Круто.
Вся компьютерная аглебра она над конечным полем, и ничего вроде.
fshp
Над множеством, а не полем. Если результат операции не помещается в переменную (что в компьютерной алгебре имеет место быть), то это уже не элемент множества. А значит и множество не является конечным полем.
fshp
Хотя, если не обращать внимание на перенос и переполнение, то да, конечное поле.
mayorovp
Если не обращать внимания на переполнение — то конечное кольцо.
fshp
Вы правы, не для всех есть обратные элементы.
Duduka
А в поле Галуа незя??? Мы же сравниваем в нем.
fshp
Конечное поле и поле Галуа — это одно и тоже. Поле Галуа — это не конкретная структура, а целый класс.
Duduka
как-бы в курсе ) К.О.
saluev
Ну вот расскажите, как вы будете быстро над большим конечным полем корни характеристического многочлена степени выше четырёх находить.
ivlis
Может ещё детерминант по определению посчитать со сложностью o(n!)?
Во, отличная идея, шифровать детерминантом! det(AB) = det(A) det(B). Где можно получить мою PhD про математике?
Естественно, никто не находит собственные числа, находя корни характеристического многочлена.
saluev
Да, очевидно. Ну а какой метод для нахождения собственных чисел над простыми полями вы можете посоветовать?
Потом, не ищут корни многочленов не потому, что это дорого, а потому, что это неустойчиво. Что опять-таки проблема только для поля с нулевой характеристикой.
ivlis
QR разложение, разве нет? Корни многочленов не ищут, потому что непонятно как это делать численно.
saluev
Вот это поворот! И как же QR-разложение помогает вычислять собственные значения, м?
С корнями многочленов очень даже понятно, как это делать численно — запускаете любимый алгоритм минимизации для |f(x)|2 и всё. См. также Root-finding algorithms.
ivlis
Наверное, как-то вот так: en.wikipedia.org/wiki/QR_algorithm
Ну и, естественно, корни многочленов не ищут алгоритмами минимизации, есть намного более эффективные методы (через то же QR разложение). По своему опыту скажу, что если где-то встретилась задача типа det(M(x)) = 0 и M больше чем 4x4 и зависит от x не как полином, то это хана, сливай воду.
saluev
Вы QR-разложение от QR-алгоритма хорошо отличаете? Вы мне приводите ссылку на итерационный алгоритм. Как вы будете его использовать в конечных полях, где и сходимости-то как таковой не существует?
ivlis
Тогда расскажите в чём особенность этого конечного поля. Вот есть у меня матрица double'ов, я могу найти собственные числа с известной точностью за время O(n^3). Это всем известно, все этим пользуются. Вы можете объяснить для обычной публики, без ссылок на Галуа, почему этого нельзя сделать в представленной задаче?
saluev
Ну, например, потому, что у вас не будет в распоряжении понятия «точность».
Рассмотрите для простоты итерационный метод решения системы какой-нибудь. Вот вы итерируете, итерируете, и по величине невязки ||Axn-b|| и числу обусловленности вашей матрицы можете прикинуть, насколько вы уже близки к решению. А теперь представьте, что вы итерируете над GF(2) (поле из нуля и единицы). Вы считаете невязку, и это вектор из нулей и единиц. В нём может быть только одна единица, но вы можете быть сколь угодно далеки от решения (по Хэммингу, например). Он может быть весь из единиц, а итерационный метод — взять и сойтись на следующей итерации.
При этом, например, итерационные методы для линейных систем, основанные на подпространствах Крылова (тот же метод Ланцоша), у вас всё равно приведут к решению — поскольку это в глубине души прямые методы: за n итераций метод Ланцоша гарантированно сходится. Он считается итерационным, потому что в вещественном случае итерации можно оборвать на пол-пути, когда достигнута необходимая точность. Но для собственных чисел таких прямых алгоритмов не существует. Например, если бы вы построили такой прямой алгоритм, использующий только арифметические операции и взятие корней, вы бы пришли к нахождению корней многочленов в радикалах (потому что любому многочлену соответствует матрица, для которой он является характеристическим), что гарантированно невозможно.
Все существующие алгоритмы поиска собственных значений матриц общего вида — какими бы быстрыми и надёжными они ни были — итерационные, а это значит, что вы не можете просто взять и применить их над конечным полем. Поэтому ваше утверждение о сложности в O(n3) в конечном поле голословно и нуждается либо в ссылке, либо (что более вероятно) в широкомасштабном исследовании.
ivlis
Если точность которая меня интересует меньше машинной точности, то в чём проблема? То что вы написали, это значит, что нельзя найти собственные значения точнее машинной точности. Ну да, только как это спасает схему шифрования я не понимаю.
mayorovp
В конечных полях вообще нет понятия точности.
saluev
Нет, то, что я написал, значит другое. Чем вы читаете? Я говорю, что вы не можете найти собственные значения матрицы над конечным полем, используя существующие итерационные алгоритмы для вещественных/комплексных матриц. (На всякий случай: они не совпадают с собственными значениями этих же матриц, рассмотренных как вещественных.) Не можете ни с какой точностью, повторяю это специально для вас, хотя для меня это звучит как бессмыслица — поскольку в конечном поле нет понятия приближения.
ivlis
>>На всякий случай: они не совпадают с собственными значениями этих же матриц, рассмотренных как вещественных
С этого надо было начинать, теперь все понятно.
mayorovp
Рискну прославиться как родственник Капитана, но в конечном поле конечное число элементов — а потому многие привычные закономерности не работают.
К примеру, отношение «больше-меньше» на таких полях ввести нельзя (поля неупорядоченные). Так, в Z7 6+1=0.
Или вот еще равенство, в том же поле: 1/3 = 5. А 3/5 = 2.
MichaelBorisov
Получается, что размер шифротекста квадратично зависит от размера исходного текста?
А что насчет схемы обфускации программ? Напишите о ней, очень интересная тема. И особенно — как доказывается, что эта схема теоретически самая стойкая?
saluev
Не квадратично. Матрица n x n сопоставляется каждому биту (или более длинной «цифре»). Размер шифротекста = размер исходного текста, умноженный на n2, n — параметр.
greenkaktus
— Эй, чувак у меня есть секретный скрин моей кредитки!
— Ок, сохрани его вон туда на петабайтный винчестер.
valerini Автор
Да, примерно так =)
valerini Автор
'v' «примерно собственный вектор» матрицы 'A', если существует такой вектор 'e' с маленькими коэффициентами, что Av = ?v + e. Проблемы найти собственные числа за полиномиальное время нет, есть проблема сначала угадать вектор 'e', т.е. если в этом векторе n элементов, каждый из который +1 или -1, то надо будет перебрать 2^n возможных значений для этого вектора.
ivlis
Как я должен был догадаться об этом из текста? В таком случае на каждой операции с шифротекстом будет накапливаться ошибка, потому что это не совсем собственные числа и через какое-то количество операций деградирует до неузнаваемости.
valerini Автор
Да, совершенно верно, очень хорошее наблюдение! Именно поэтому эта простая идея работает для конечного числа перемножений. А чтобы добиться произвольного числа перемножений надо делать то что называется «bootstrapping», т.е. зашифровать секретный ключ гомоморфной схемой (предполагая «circular security», т.е. что можно зашифровать секретный ключ его публичным ключом и что это его не выдаст) и исполнить дешифрующий алгоритм используя гомоморфное шифрование. Это перешифрует информацию, уменьшив в ней шум до размеров исходного.
Выглядеть это будет так примерно:
Гомоморфное шифрование позволяет сделать преобразование: E(pk, x) -> E(pk, f(x))
Boostrapping, соответственно, будет выглядеть так: допустим у вас есть шифр ct, в котором вы хотите уменьшить шум, допустим ct шифрует y, тогда
[ct, Enc(pk, sk)] => Enc(pk, Dec(sk, ct)) ct воспринимается как константа или набор констант, т.е. гомоморфная функция, которую мы считаем параметризована ct: f_{ct}(sk) = Dec(sk, ct). Перешифровка уменьшит шум.