
В электронных таблицах вроде Excel нарастающий итог вычисляется очень просто: результат в первой записи совпадает с её значением:
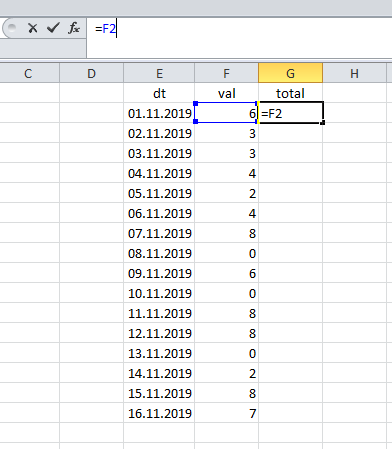
… а затем мы суммируем текущее значение и предыдущий итог.

Иными словами,
… или:
Появление в таблице двух и более групп несколько усложняет задачу: теперь мы считаем несколько итогов (для каждой группы отдельно). Впрочем, и здесь решение лежит на поверхности: необходимо каждый раз проверять, к какой группе принадлежит текущая запись. Click and drag, и работа выполнена:
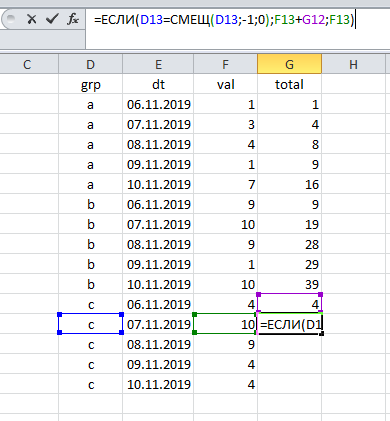
Как можно заметить, подсчёт нарастающего итога связан с двумя неизменными составляющими:
(а) сортировкой данных по дате и
(б) обращением к предыдущей строке.
Но что SQL? Очень долго в нём не было нужного функционала. Необходимый инструмент – оконные функции – впервые появился только стандарте SQL:2003. К этому моменту они уже были в Oracle (версия 8i). А вот реализация в других СУБД задержалась на 5-10 лет: SQL Server 2012, MySQL 8.0.2 (2018 год), MariaDB 10.2.0 (2017 год), PostgreSQL 8.4 (2009 год), DB2 9 для z/OS (2007 год), и даже SQLite 3.25 (2018 год).
-- создание таблиц и наполнение их данными --
-- простейший случай
create table test_simple (dt date null,
val int null
);
-- используем формат дат своей СУБД (или меняем настройки, напр. через NLS_DATE_FORMAT в Oracle)
insert into test_simple (dt, val) values ('2019-11-01', 6);
insert into test_simple (dt, val) values ('2019-11-02', 3);
insert into test_simple (dt, val) values ('2019-11-03', 3);
insert into test_simple (dt, val) values ('2019-11-04', 4);
insert into test_simple (dt, val) values ('2019-11-05', 2);
insert into test_simple (dt, val) values ('2019-11-06', 4);
insert into test_simple (dt, val) values ('2019-11-07', 8);
insert into test_simple (dt, val) values ('2019-11-08', 0);
insert into test_simple (dt, val) values ('2019-11-09', 6);
insert into test_simple (dt, val) values ('2019-11-10', 0);
insert into test_simple (dt, val) values ('2019-11-11', 8);
insert into test_simple (dt, val) values ('2019-11-12', 8);
insert into test_simple (dt, val) values ('2019-11-13', 0);
insert into test_simple (dt, val) values ('2019-11-14', 2);
insert into test_simple (dt, val) values ('2019-11-15', 8);
insert into test_simple (dt, val) values ('2019-11-16', 7);
-- случай с группами
create table test_groups (grp varchar null, -- varchar2(1) in Oracle
dt date null,
val int null
);
-- используем формат дат своей СУБД (или меняем настройки, напр. через NLS_DATE_FORMAT в Oracle)
insert into test_groups (grp, dt, val) values ('a', '2019-11-06', 1);
insert into test_groups (grp, dt, val) values ('a', '2019-11-07', 3);
insert into test_groups (grp, dt, val) values ('a', '2019-11-08', 4);
insert into test_groups (grp, dt, val) values ('a', '2019-11-09', 1);
insert into test_groups (grp, dt, val) values ('a', '2019-11-10', 7);
insert into test_groups (grp, dt, val) values ('b', '2019-11-06', 9);
insert into test_groups (grp, dt, val) values ('b', '2019-11-07', 10);
insert into test_groups (grp, dt, val) values ('b', '2019-11-08', 9);
insert into test_groups (grp, dt, val) values ('b', '2019-11-09', 1);
insert into test_groups (grp, dt, val) values ('b', '2019-11-10', 10);
insert into test_groups (grp, dt, val) values ('c', '2019-11-06', 4);
insert into test_groups (grp, dt, val) values ('c', '2019-11-07', 10);
insert into test_groups (grp, dt, val) values ('c', '2019-11-08', 9);
insert into test_groups (grp, dt, val) values ('c', '2019-11-09', 4);
insert into test_groups (grp, dt, val) values ('c', '2019-11-10', 4);
-- проверяем данные --
select * from test_simple order by dt;
select * from test_groups order by grp, dt;
1. Оконные функции
Оконные функции – вероятно, самый простой способ. В базовом случае (таблица без групп) мы рассматриваем данные, отсортированные по дате:
order by dt… но нас интересуют только строки до текущей:
rows between unbounded preceding and current rowВ конечном итоге, нам нужна сумма с этими параметрами:
sum(val) over (order by dt rows between unbounded preceding and current row)А полный запрос будет выглядеть так:
select s.*,
coalesce(sum(s.val) over (order by s.dt
rows between unbounded preceding and current row),
0) as total
from test_simple s
order by s.dt;В случае нарастающего итога по группам (поле
grp) нам требуется только одна небольшая правка. Теперь мы рассматриваем данные как разделённые на «окна» по признаку группы:
Чтобы учесть это разделение необходимо использовать ключевое слово
partition by :partition by grpИ, соответственно, считать сумму по этим окнам:
sum(val) over (partition by grp order by dt
rows between unbounded preceding and current row)Тогда весь запрос преобразуется таким образом:
select tg.*,
coalesce(sum(tg.val) over (partition by tg.grp order by tg.dt
rows between unbounded preceding and current row),
0) as total
from test_groups tg
order by tg.grp, tg.dt;Производительность оконных функций будет зависеть от специфики вашей СУБД (и её версии!), размеров таблицы, и наличия индексов. Но в большинстве случаев этот метод будет самым эффективным. Тем не менее, оконные функции недоступны в старых версиях СУБД (которые ещё в ходу). Кроме того, их нет в таких СУБД как Microsoft Access и SAP/Sybase ASE. Если необходимо вендоро-независимое решение, следует обратить внимание на альтернативы.
2. Подзапрос
Как было сказано выше, оконные функции были очень поздно введены в основных СУБД. Эта задержка не должна удивлять: в реляционной теории данные не упорядочены. Куда больше духу реляционной теории соответствует решение через подзапрос.
Такой подзапрос должен считать сумму значений с датой до текущей (и включая текущую): .
Что в коде выглядит так:
select s.*,
(select coalesce(sum(t2.val), 0)
from test_simple t2
where t2.dt <= s.dt) as total
from test_simple s
order by s.dt;
Чуть более эффективным будет решение, в котором подзапрос считает итог до текущей даты (но не включая её), а затем суммирует его со значением в строке:
select s.*,
s.val + (select coalesce(sum(t2.val), 0)
from test_simple t2
where t2.dt < s.dt) as total
from test_simple s
order by s.dt;
В случае нарастающего итога по нескольким группам нам необходимо использовать коррелированный подзапрос:
select g.*,
(select coalesce(sum(t2.val), 0) as total
from test_groups t2
where g.grp = t2.grp
and t2.dt <= g.dt) as total
from test_groups g
order by g.grp, g.dt;
Условие
g.grp = t2.grp проверяет строки на вхождение в группу (что, в принципе, сходно с работой partition by grp в оконных функциях).3. Внутреннее соединение
Поскольку подзапросы и джойны взаимозаменяемы, мы легко можем заменить одно на другое. Для этого необходимо использовать Self Join, соединив два экземпляра одной и той же таблицы:
select s.*,
coalesce(sum(t2.val), 0) as total
from test_simple s
inner join test_simple t2
on t2.dt <= s.dt
group by s.dt, s.val
order by s.dt;
Как можно заметить, условие фильтрации в подзапросе
t2.dt <= s.dt стало условием соединения. Кроме того, чтобы использовать агрегирующую функцию sum() нам необходима группировка по дате и значению group by s.dt, s.val.Точно также можно сделать для случая с разными группами
grp:select g.*,
coalesce(sum(t2.val), 0) as total
from test_groups g
inner join test_groups t2
on g.grp = t2.grp
and t2.dt <= g.dt
group by g.grp,
g.dt,
g.val
order by g.grp,
g.dt;
4. Декартово произведение
Раз уж мы заменили подзапрос на join, то почему бы не попробовать декартово произведение? Это решение потребует только минимальных правок:
select s.*,
coalesce(sum(t2.val), 0) as total
from test_simple s,
test_simple t2
where t2.dt <= s.dt
group by s.dt,
s.val
order by s.dt;
Или для случая с группами:
select g.*,
coalesce(sum(t2.val), 0) as total
from test_groups g,
test_groups t2
where g.grp = t2.grp
and t2.dt <= g.dt
group by g.grp,
g.dt,
g.val
order by g.grp,
g.dt;
Перечисленные решения (подзапрос, inner join, cartesian join) соответсвуют SQL-92 и SQL:1999, а потому будут доступны практически в любой СУБД. Основная проблема всех этих решений в низкой производительности. Это не велика беда, если мы материализуем таблицу с результатом (но ведь всё равно хочется большей скорости!). Дальнейшие методы куда более эффективны (с поправкой на уже указанные специфику конкретных СУБД и их версий, размер таблицы, индексы).
5. Рекурсивный запрос
Один из более специфических подходов – это рекурсивный запрос в common table expression. Для этого нам необходим «якорь» – запрос, возвращающий самую первую строку:
select dt,
val,
val as total
from test_simple
where dt = (select min(dt) from test_simple)
Затем к «якорю» с помощью
union all присоединяются результаты рекурсивного запроса. Для этого можно опереться на поле даты dt, прибавляя у нему по одному дню:select r.dt,
r.val,
cte.total + r.val
from cte
inner join test_simple r
on r.dt = dateadd(day, 1, cte.dt) -- + 1 день в SQL Server
Часть кода, добавляющая один день, не универсальна. Например, это
r.dt = dateadd(day, 1, cte.dt) для SQL Server, r.dt = cte.dt + 1 для Oracle, и т.д.Совместив «якорь» и основной запрос, мы получим окончательный результат:
with cte (dt, val, total)
as
(select dt, val, val as total
from test_simple
where dt = (select min(dt) from test_simple)
union all
select r.dt, r.val, cte.total + r.val
from cte
inner join test_simple r
on r.dt = dateadd(day, 1, cte.dt) -- r.dt = cte.dt + 1 в Oracle, и т.п.
)
select dt, val, total
from cte
order by dt;
Решение для случая с группами будет ненамного сложнее:
with cte (dt, grp, val, total)
as
(select g.dt, g.grp, g.val, g.val as total
from test_groups g
where g.dt = (select min(dt) from test_groups where grp = g.grp)
union all
select r.dt, r.grp, r.val, cte.total + r.val
from cte
inner join test_groups r
on r.dt = dateadd(day, 1, cte.dt) -- r.dt = cte.dt + 1 в Oracle, и т.п.
and cte.grp = r.grp
)
select dt, grp, val, total
from cte
order by grp, dt;
6. Рекурсивный запрос с функцией row_number()
Предыдущее решение опиралось на непрерывность поля даты
dt с последовательным приростом на 1 день. Мы избежать этого, используя оконную функцию row_number(), которая нумерует строки. Конечно, это нечестно – ведь мы собрались рассматривать альтернативы оконным функциям. Тем не менее, это решение может быть своего рода proof of concept: ведь на практике может быть поле, заменяющее номера строк (id записи). Кроме того, в SQL Server функция row_number() появилась раньше, чем была введена полноценная поддержка оконных функций (включая sum()).Итак, для рекурсивного запроса с
row_number() нам понадобится два СТЕ. В первом мы только нумеруем строки:with cte1 (dt, val, rn)
as (select dt,
val,
row_number() over (order by dt) as rn
from test_simple)
… и если номер строки уже есть в таблице, то можно без него обойтись. В следующем запросе обращаемся уже к
cte1:cte2 (dt, val, rn, total)
as
(select dt, val, rn, val as total
from cte1
where rn = 1
union all
select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val
from cte2
inner join cte1
on cte1.rn = cte2.rn + 1
)
А целиком запрос выглядит так:
with cte1 (dt, val, rn)
as (select dt,
val,
row_number() over (order by dt) as rn
from test_simple),
cte2 (dt, val, rn, total)
as
(select dt, val, rn, val as total
from cte1
where rn = 1
union all
select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val
from cte2
inner join cte1
on cte1.rn = cte2.rn + 1
)
select dt, val, total
from cte2
order by dt;
… или для случая с группами:
with cte1 (dt, grp, val, rn)
as (select dt, grp, val,
row_number() over (partition by grp order by dt) as rn
from test_groups),
cte2 (dt, grp, val, rn, total)
as
(select dt, grp, val, rn, val as total
from cte1
where rn = 1
union all
select cte1.dt, cte1.grp, cte1.val, cte1.rn, cte2.total + cte1.val
from cte2
inner join cte1
on cte1.grp = cte2.grp
and cte1.rn = cte2.rn + 1
)
select dt, grp, val, total
from cte2
order by grp, dt;
7. Оператор CROSS APPLY / LATERAL
Один из самых экзотических способов расчёта нарастающего итога – это использование оператора
CROSS APPLY (SQL Server, Oracle) или эквивалентного ему LATERAL (MySQL, PostgreSQL). Эти операторы появились довольно поздно (например, в Oracle только с версии 12c). А в некоторых СУБД (например, MariaDB) их и вовсе нет. Поэтому это решение представляет чисто эстетический интерес.Функционально использование
CROSS APPLY или LATERAL идентично подзапросу: мы присоединяем к основному запросу результат вычисления:cross apply (select coalesce(sum(t2.val), 0) as total
from test_simple t2
where t2.dt <= s.dt
) t2
… что целиком выглядит так:
select s.*,
t2.total
from test_simple s
cross apply (select coalesce(sum(t2.val), 0) as total
from test_simple t2
where t2.dt <= s.dt
) t2
order by s.dt;
Похожим будет и решение для случая с группами:
select g.*,
t2.total
from test_groups g
cross apply (select coalesce(sum(t2.val), 0) as total
from test_groups t2
where g.grp = t2.grp
and t2.dt <= g.dt
) t2
order by g.grp,
g.dt;
Итого: мы рассмотрели основные платформо-независимые решения. Но остаются решения, специфичные для конкретных СУБД! Поскольку здесь возможно очень много вариантов, остановимся на нескольких наиболее интересных.
8. Оператор MODEL (Oracle)
Оператор
MODEL в Oracle даёт одно из самых элегантных решений. В начале статьи мы рассмотрели общую формулу нарастающего итога: MODEL позволяет реализовать эту формулу буквально один к одному! Для этого мы сначала заполняем поле total значениями текущей строкиselect dt,
val,
val as total
from test_simple
… затем рассчитываем номер строки как
row_number() over (order by dt) as rn (или используем готовое поле с номером, если оно есть). И, наконец, вводим правило для всех строк, кроме первой: total[rn >= 2] = total[cv() - 1] + val[cv()].Функция
cv() здесь отвечает за значение текущей строки. А весь запрос будет выглядеть так:select dt, val, total
from
(select dt,
val,
val as total
from test_simple) t
model
dimension by (row_number() over (order by dt) as rn)
measures (dt, val, total)
rules (total[rn >= 2] = total[cv() - 1] + val[cv()])
order by dt;
9. Курсор (SQL Server)
Нарастающий итог – один из немногих случаев, когда курсор в SQL Server не только полезен, но и предпочтителен другим решениям (как минимум до версии 2012, где появились оконные функции).
Реализация через курсор довольно тривиальна. Сначала необходимо создать временную таблицу и заполнить её датами и значениями из основной:
create table #temp
(dt date primary key,
val int null,
total int null
);
insert #temp (dt, val)
select dt, val
from test_simple
order by dt;
Затем задаём локальные переменные, через которые будет происходить обновление:
declare @VarTotal int,
@VarDT date,
@VarVal int;
set @VarTotal = 0;
После этого обновляем временную таблицу через курсор:
declare cur cursor local static read_only forward_only
for select dt, val from #temp order by dt;
open cur;
fetch cur into @VarDT, @VarVal;
while @@fetch_status = 0
begin
set @VarTotal = @VarTotal + @VarVal;
update #temp
set total = @VarTotal
where dt = @VarDT;
fetch cur into @VarDT, @VarVal;
end;
close cur;
deallocate cur;
И, наконец, получем нужный результат:
select dt, val, total
from #temp
order by dt;
drop table #temp;
10. Обновление через локальную переменную (SQL Server)
Обновление через локальную переменную в SQL Server основано на недокументированном поведении, поэтому его нельзя считать надёжным. Тем не менее, это едва ли не самое быстрое решение, и этим оно интересно.
Создадим две переменные: одну для нарастающих итогов и табличную переменную:
declare @VarTotal int = 0;
declare @tv table
(dt date null,
val int null,
total int null
);
Сначала заполним
@tv данным из основной таблицыinsert @tv (dt, val, total)
select dt, val, 0 as total
from test_simple
order by dt;
Затем табличную переменную
@tv обновим, используя @VarTotal:update @tv
set @VarTotal = total = @VarTotal + val
from @tv;
… после чего получим окончательный результат:
select * from @tv order by dt;
Резюме: мы рассмотрели топ 10 способов расчёта нарастающего итога в SQL. Как можно заметить, даже без оконных функций эта задача вполне решаема, причём механику решения нельзя назвать сложной.
Комментарии (40)

ypastushenko
15.11.2019 23:34Спасибо, хорошая справочная подборка.
Только, насколько я знаю cte есть только в sql server, а 4 практически эквивалентно 3.
oxff
16.11.2019 00:19Wikipedia утверждает следующее:
Common table expressions are supported by Teradata, DB2, Firebird, Microsoft SQL Server, Oracle (with recursion since 11g release 2), PostgreSQL (since 8.4), MariaDB (since 10.2), MySQL (since 8.0), SQLite (since 3.8.3), HyperSQL and H2 (experimental).

miksoft
15.11.2019 23:56Необходимый инструмент – оконные функции
Вы же сами ниже показываете, что оконные функции не являются необходимым инструментом.
А вариант, названный «Декартово произведение», не является таковым, в нем просто условие соединения таблиц перенесено в секцию WHERE, что для большинства СУБД никак не влияет на выполнение запроса. Декартовым произведением это было бы, если бы условия соединения таблиц не было совсем или оно было постоянно истинным (например, 1=1).
Добавлю, что решение с переменными в MySQL является документированным и применяется уже давным давно.maksim_R
16.11.2019 15:55+1Вполне можно считать это декартовым произведением, ведь соединение проиходит не по равенству, а по неравенству. Условие только ограничивает высоту таблицы для каждого ряда. Для последней строки будет самое настоящее декартово произведение.

nitrosbase
16.11.2019 02:48Нарастающий (накопительный) итог долго считался одним из вызовов SQL.
Что удивительно, поскольку Кодд в рамках «Великого спора» 1974 года победил Бахмана как раз на всяких бухгалтерских задачках (где-то у Дейта есть эта история).
Но я однажды написал расчет нарастающего итога на SPARQL и сам удивился, как все просто. Требуются только базовые конструкции, нет даже подзапросов.
Примерно такINSERT DATA { ex:st ex:order 1 ; ex:value 1 . ex:nd ex:order 2 ; ex:value 1 . ex:rd ex:order 3 ; ex:value 2 . }
SELECT (SAMPLE(?v1) AS ?v) (SUM(?v2) AS ?acc) { ?e1 ex:order ?o1 ; ex:value ?v1 . ?e2 ex:order ?o2 ; ex:value ?v2 . FILTER (?o1 >= ?o2) } GROUP BY ?e1 ORDER BY ASC(SAMPLE(?o1))
Или так:
INSERT DATA { ex:data ex:values (1 1 2) }
SELECT (SAMPLE(?v2) AS ?v) (SUM(?v1) AS ?acc) { ex:data ex:values/rdf:rest* ?e1 . ?e1 rdf:first ?v1 . ?e1 rdf:rest* ?e2 . ?e2 rdf:first ?v2 . } GROUP BY (?e2) ORDER BY(COUNT(?e1))
apapacy
16.11.2019 20:58+1Что удивительно, поскольку Кодд в рамках «Великого спора» 1974 года победил Бахмана как раз на всяких бухгалтерских задачках (где-то у Дейта есть эта история).
Не уверен что для бухгалтеров важен нарастающий итог. Скорее он использовался в ручном варианте для облегчения расчетов и используется в Excel чтобы проверить что не промахнулся в диапазоне ячеек для итогов.
Что касается вызова — полностью согласен, что нарастающий итог чисто синтаксически легко реализуется подзапросом даже без дополнительных фич на чистом sql. Хотя это будет очень непроизводительно.
Если говорить о том что не решено в sql и важно для бухгалтера — 1) быстрое получение оборотов и остатков без перелопачивания всех данных от 1970 года и по сегодняшний день (есть же индексы, почему по аналогии не сделать сумматоры?:
2) для наименований товаров, материалов обычно есть назовем его "основное" наименование, такое как оно прописывается в технической документации или в стандартах, и назовем его "текущее" название — которое указано в документах: договорах, накладных и т.п. Так вот бухгалтеру важны оба наименования, а sql по правилам нормализации стремиться их свести к одному
3) данные с "историей" — цены, нормы расхода материалов, трудовые нормативы обычно изменяются во времени
Конечно, все это можно раелизовать на уровне приложения, однако такая реализация резко увеличивает (в разы) структуру данных. Поэтому я с большим уважением отношусь к 1с, которая за кадром реализовала как раз механизмы нужные для бухгалтера (регистры, исторические данные)
dss_kalika
18.11.2019 17:051. А где то это делается быстро и нативно без предрасчёта?
2. Никто же не заставляет нормализировать в край. Да и да — если два поля не сводятся к одному то SQL не будет к этому стремиться. Или я неправильно понял задачу?
3. В чём проблема? )
nitrosbase
18.11.2019 21:20ОК, спасибо, интересно!
Я же, возможно, что-то напутал, и как «бухгалтерская» задача мне запомнилась вот эта:
Описание данныхThe sample data base includes information about persons (an identification number, name, birth-date, and salary), medical histories (identification number of person, absent-from-date, absent-to-date, disease, and comment), education (identification number of person, degree, name of university, start-date at university, stop-date at university), jobs (job number, identification number of person who did the job, actual start-date, actual stop-date, and performance rating), machines (machine number, machine type), schedules (job number, identification number of person assigned, scheduled start-date, scheduled stop-date), skills (skill number, skill description), the possession of skills by persons (identification number of person, skill number), the alternative skills needed to operate machines (machine number, skill number).
dss_kalika
19.11.2019 10:24Составление расписаний всегда весёлая задача )
…
я бы добавил ещё «данные вводятся вручную» (соответственно не всегда консистентные) и «забирать данные надо из трёх дублирующих систем», проверяя валидность другими системами.
BlessYourHeart
16.11.2019 06:08Основная проблема всех этих решений в низкой производительности. Это не велика беда, если мы материализуем таблицу с результатом (но ведь всё равно хочется большей скорости!). Дальнейшие методы куда более эффективны
От синтаксиса в декларативном языке не так уж много зависит. Оконные функции — это вариант синтаксиса. Почему вы думаете тут возможна значительная разница в производительности? Сдается мне планы выполнения должны быть выбраны оптимизатором очень похожие.
Производительность запроса определяется узкими местами базы, и в основном самым тяжелым — поднятием данных с хранилища. Как бы вы не написали свой запрос, коррелированными подзапросами ли, оконными функциями ли, сте и тп, table scan/seek будет первой и наиболее дорогостоящей операцией, стоимость которой мало зависит от синтаксиса, а в основном от грамотной фильтрации, индексов и прочей структуры хранения данных.
gleb_l
16.11.2019 09:16+2К сожалению, выполняющий энджин имеет конечную прозорливость, поэтому способ, которым декларируется множество данных, подлежащих выборке или изменению, все ещё имеет значение (и часто решающее)
dss_kalika
18.11.2019 17:00Проблема в том, что половина из описанных способов повторно обращается к данным, из-за чего работает очень не очень (особенно если таблицы не такие простые и маленькие).
И весь смысл, обычно, сводится к тому, что бы как можно меньше обращаться к таблицам, как можно больше использовать данные из индексов и как можно ближе писать запросы к тому, что система сможет понять и правильно интерпретировать. =)

Saamm
16.11.2019 11:39-2Не счёт Oracle (версия 8i), что раньше появилось, — хорошо подмечено.
Так переходи уже на PL\SQL и используй циклы (loop, for, if), если до курсоров дошёл

musicriffstudio
16.11.2019 11:51Цель SQL — описать запрос который можно выполнить на данных с кучей таблиц с миллонами записей и получить результат за доли секунды.
Цель Excel — предоставить пользователю возможность красиво оформить данные (в том числе и с нарастающим итогом или другими формулами, но этим 99% не пользуются)
Сматры не пэрэпутай! (с)
tmin10
16.11.2019 18:37Не уверен насчёт долей секунд для SQL: сложные аналитические запросы вполне могут выполняться долго. Это тоже нужно.
max1gu
16.11.2019 20:53Не льстите себе.
Во первых, большинство серьезных проектов на Экселе очень тяжено переносятся в базы данных. По причине их ограниченности. «Красивое представление данных» в экселе — это самое не очевидное его использование. Вы просто не знаете эксель. Он позволяет объёдинить данные и бизнес-логику и озбавиться от самого тормозного, дорогого и бесполезного звена в разработке — программиста.
Во-вторых, мастодонты типа Микрософт зачем-то выпиливают сводные таблицы из баз данных (Аксес) и делают продукты типа Пауэер БИ, которые объёдиняют язык запросов, курсоры, формулы экселя и сводные таблицы. Это опять же чтобы отдать обработку данных пользователям, которые понимают что данные из себя представляют и зачем они нужны и избавиться от программистов (в виду их крайней бесполезности).musicriffstudio
17.11.2019 12:28В реальности сейчас эксел используется для красивой раскраски таблицы отпусков и вставки логотипов в прайс-лист для печати.
Формулы и расчётные колонки появились в предшественниках эксела (https://en.wikipedia.org/wiki/VisiCalc) 30 лет назад и произвели революцию в офисных приложениях. Сам эксел был killer-feature ради которой покупали компьютер с предустановленной Windows 3.11
Но это было 30 лет назад.
Нарастающий итог в SQL это яркий пример использования систем для быстрой обработки данных не по назначению — для удобного в восприятии человеком оформления данных.
Такие задачи обычно говорят о полном непонимании принципов работы с базами данных.
max1gu
17.11.2019 23:19Простейшая для экселя и просто человека с бумажкой задача разворачивания дебиторской и кредиторской задолженности по документам расчетов делается для базы данных крайне трудоемкой задачей именно по причине невозможности расчета запросом наростающего итога.
Решения 2 — либо как в 1С, проставлять вручную (что может позволить только маленькое предприятие, на больших вменяемых эту возможность отключают), либо пересчет итогов по каждой операции при каких-либо изменениях (а это связка тригеров и курсора, что многие считают богомерзкой ересью).
А вот запросом — только академический интерес, как в этой статье. В рабочей базе, где группировка не одна, а минимум две: контаргент, договор + документ операции, запрос зависает наглухо.
Drunik
16.11.2019 15:55По последнему варианту — если использовать временную таблицу, первичный ключ, with(index(1)) и option(maxdop(1)) в update, то результат будет гораздо более стабилен и предсказуем.
kuzmvs
16.11.2019 22:34Почему не рассмотрели lag? С помощью этого как раз и можно элегантно решить вопрос. По факту, рассмотрели все, кроме оптимального варианта...

demche Автор
16.11.2019 22:35Через
LAGпопросту нет элегантного решения. Понадобится CTE или процедура с циклом (и у меня есть сомнения, что это даст ускорение в сравнении сSUM() OVER …).
akamap
16.11.2019 22:45собственно, а почему бы не посчитать так же, как в excel`е:
select dt, val, @total:= val + @total total from test_simple, (select @total:=0)t;demche Автор
17.11.2019 16:30Даже если оставить за скобками синтаксис (этот код нерабочий), в Excel мы используем заранее отсортированный список. К расчёту «как в Еxcel» ближе всего способ с
MODELв Oracle.akamap
17.11.2019 16:41
А если добавить в код «order by dt»?demche Автор
17.11.2019 17:09СУБД – это важное уточнение (в SQL Server, Oracle, и других синтаксис не такой как в MariaDB).
Могу предположить, чтоSELECTвывел записи в порядке их добавления в базу. Без сортировки это поведение не должно быть гарантированнымakamap
17.11.2019 17:12Прошу прощения, я думал это очевидно. Своим кодом просто хотел продемонстрировать подход…
vzhicharra
17.11.2019 12:49from functools import reduce vals = [6, 3, 3, 4, 2, 4, 8, 0, 6, 0, 8, 8, 0, 2, 8, 7] result = reduce(lambda x, y: x + y, vals)
я победил?
где приз забирать?demche Автор
17.11.2019 16:27Ваше решение считает итог только для последней записи. Кроме того, можно обойтись и без
functools:
vals = [6, 3, 3, 4, 2, 4, 8, 0, 6, 0, 8, 8, 0, 2, 8, 7] total = [vals[0]]; [total.append(total[i] + val) for i, val in enumerate(vals[1:])]
А приз выдадут довольные клиенты (когда увидят perform вычислений на уровне приложения)

shushu
17.11.2019 14:44Условие
> where t2.dt < s.dt
Нельзя назвать надёжным, и полностью зависит от данных. Собственно такой подход работать не будет если есть данные с двумя одинаковыми датами.
Про это вы написали в 6м пункте.
В том же пункте есть «вариант решения проблемы»:
> Тем не менее, это решение может быть своего рода proof of concept: ведь на практике может быть поле, заменяющее номера строк (id записи).
Ну и здесь таже картина (мы делаем какое то предположение о данных, которое не всегда будет верным), ид полностью независим от даты. Представьте что вам надо добавить в таблицу какие то данные за прошлую неделю… В результате будет какой-то кошмар.demche Автор
17.11.2019 16:28В большинстве случаев у нас будет поле, которое позволяет сортировать записи (будь то дата и время, id записи, и т.д. и т.п.). Дата в моих примерах – всего лишь упрощение, достаточное для туториала. Если нужного поля нет, то и нарастающий итог post-factum не посчитать никак.
maksim_R
17.11.2019 17:51+1Что есть нарастающий итог при двух и более одинаковых идентификаторах? Если две одинаковые даты, то какую из записей считатать первой? Либо надо считать обе одновременно?
Такая постановка вопроса противоречит принципам аналитики, и не зависит от технологии — будь то sql, excel или листок бумаги.
Очевидно, что надо чтобы данные были либо сгруппированы по идентификатору (дате, в данном случае), либо нужны дополнительные параметры для сортировки.

sanchovy
17.11.2019 22:03Накопительную сумму в Экселе можно посчитать и одной формулой — протянуть формулу с закреплённой ссылкой на первую ячейку диапазона:
=СУММ($A$1:A1)
dss_kalika
18.11.2019 16:53select tg.*,
coalesce(sum(tg.val) over (partition by tg.grp order by tg.dt
rows between unbounded preceding and current row),
0) as total
from test_groups tg
order by tg.grp, tg.dt;
rows between unbounded preceding and current row
Не обязателен — оконная функция суммы с order by будет показывать нарастающий итог по текущее значение по умолчанию.
10. Обновление через локальную переменную (SQL Server)
За это респект. Редкое знание но самое быстрое из перечисленных решений, в случае если нужно не просто накопительную сумму искать, а, к примеру, переходы через нули или более сложные условные накопительные изменения.
Но есть нюанс — UPDATE таблицы может происходить (строго говоря) в любом порядке, из-за чего накопительный итог не будет иметь смысла.
Поэтому рекомендуется заливать данные во временную таблицу (SELECT * INTO #TMP FROM ....), а потом построить по ней кластерный индекс по необходимой сортировке (CREATE CLUSTERED INDEX IX_SOME_INDEX ON #TMP1 (Sort_field).
В этом случае последовательность нарастающего итога гарантированно пойдёт по сортировке кластерного индекса.maksim_R
18.11.2019 20:19+1По умолчанию во всех оконных функциях стоит rows between unbounded preceding and unbounded following.
Если это условие не дописать, то получится одинаковое значение для всех рядов (или для всего окна по партишну, как в данном случае).miksoft
18.11.2019 22:41+1ORDER BY меняет это умолчание на RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
dev.mysql.com/doc/refman/8.0/en/window-functions-frames.html
In the absence of a frame clause, the default frame depends on whether an ORDER BY clause is present:
With ORDER BY: The default frame includes rows from the partition start through the current row, including all peers of the current row (rows equal to the current row according to the ORDER BY clause). The default is equivalent to this frame specification:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
Without ORDER BY: The default frame includes all partition rows (because, without ORDER BY, all partition rows are peers). The default is equivalent to this frame specification:
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
docs.oracle.com/cd/E11882_01/server.112/e41084/functions004.htm#SQLRF06174
If you omit the windowing_clause entirely, then the default is RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
maksim_R
18.11.2019 23:13+1Да, действительно. В Postgre и MS Server тоже так.
Oracle: http://www.sqlfiddle.com/#!4/73b847/1
PostgreSQL: http://www.sqlfiddle.com/#!17/73b84/1
MS SQL Server: http://www.sqlfiddle.com/#!18/73b847/1
gleb_l
Подзапросы и джойны в общем случае невзаимозаменяемы.
Наиболее близким функциональным аналогом подзапроса является кросс-апплай, который, как и все апплаи, имеет в области видимости уже подвыбранные данные, но при этом: а) как бы сплющивает запрос по количеству уровней вложенности, и главное б) даёт возможность выбрать сразу несколько скаляров одним подзапросом
Приведённые примеры не эквивалентны с точки зрения вариантов использования — все, что требует T-SQL-конструкций, нельзя использовать внутри SQL-статементов (например, во вьюхах, инлайн-TVF итд)
И ещё — накладные расходы могут быть существенно нелинейными — надо понимать, какой метод лучше для 10, 1000, 1000000 записей — лидеры и аутсайдеры на разных размерах могут коренным образом поменяться (вплоть до полного зависания)
gleb_l
Ошибся, не кросс, а outer apply