
Накануне запуска курса «Backend-разработчик на PHP» мы провели традиционный открытый урок. В этот раз познакомились с концепцией Serverless, поговорили о её реализации в AWS, разобрали принципы работы, сборки и запуска, а также построили простой TG-бот на PHP на базе AWS Lambda.
Преподаватель — Александр Пряхин, технический директор компании Westwing Russia.

Краткий экскурс в историю

Как же мы докатились до жизни такой, что появились бессерверные вычисления? Конечно, они появились не просто так, а стали логическим продолжением существующих технологий виртуализации.

Что же мы вообще обычно виртуализируем? Например, процессор. Ещё можно виртуализировать память, выделив определённые области памяти и сделав их доступными для одних пользователей и недоступными для других. Можно виртуализировать сеть VPN. И так далее.

Виртуализация хороша тем, что у нас лучше утилизируются ресурсы и повышается производительность. Но есть и минусы, например, в своё время были проблемы с совместимостью. Однако сейчас практически нет архитектур, которые были бы несовместимы с современными виртуальными машинами.
Следующий минус заключается в том, что мы добавляем дополнительный слой абстракции, добавляем гипервизор, добавляем саму по себе виртуалку и, конечно же, можем немного потерять в скорости. Несколько усложняется и использование сервера.
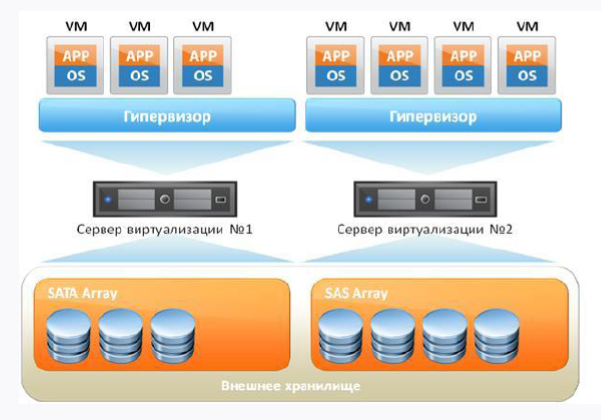
Если мы возьмём с вами стандартную виртуалку, она будет выглядеть примерно так:

Во-первых, у нас есть железный сервер, во-вторых — операционная система, на который будет крутиться наш гипервизор. И поверх всего этого добра крутятся наши виртуалки, в которых есть гостевая ОС, библиотеки и приложения. Если рассуждать логично, то мы видим некоторый overhead в наличии гостевой ОС, ведь по факту тратим лишние ресурсы.
Как можно решить проблему оверхеда? Отказавшись от виртуальных машин и поставив поверх основной операционной системы систему управления контейнерами. Разумеется, наиболее популярная сейчас система — Docker Engine. Тогда библиотеки внутри контейнера станут использовать ядро хоста операционной системы.

Таким образом мы уберём оверхед, однако ведь и Docker неидеален, и у него имеются свои проблемы и особенности работы, которые не всем нравятся.
Главное, что следует уяснить, — Docker и виртуалка — это разные подходы, и не нужно их приравнивать. Docker — это не микровиртуалка, с которой можно работать, как с виртуальной машиной, ведь контейнер на то и контейнер. Зато контейнер позволяет нам обеспечивать гибкость и совершенно иной подход к Continuous delivery, когда мы доставляем вещи до production и понимаем, что они уже протестированы и работают.
Облачные технологии
С дальнейшим развитием виртуализации начали развиваться и облачные технологии. Это неплохое решение, однако сразу стоит сказать, что облака — это не серебряная пуля и не панацея от всех бед. Здесь нельзя не вспомнить одну известную цитату:
«When I hear someone touting the cloud as a magic-bullet for all computing problems, I silently replace “cloud” with “clown” and carry on with a zen-like smile».
Amy Rich
Однако для компаний средней руки, которые желают получать определённый уровень сервиса и отказоустойчивости без огромных финансовых вливаний, облака — вполне себе вариант. И многим компаниям держать свой дата-центр с таким же SLA будет гораздо дороже, чем обслуживаться в облаке. Кроме того, мы можем использовать облака для своих нужд, ведь какие-то вещи они предоставляют буквально в несколько кликов мышки, что очень удобно. Например, возможность в несколько кликов поднять виртуальную машину или сеть.
Да, есть ограничения, например 152-й Федеральный закон, запрещающий хранить персональные данные за рубежом, поэтому тот же Amazon при аудите перестанет нам подходить. Не стоит забывать и про Vendor-lock. Многие облачные решения не портируются между собой, хотя те же S3-совместимые хранилища поддерживаются большинством провайдеров.
Облака предоставляют нам возможность без узконаправленных знаний получать разные уровни сервиса. Чем меньше нужно знаний, тем больше будем платить. На рисунке ниже Вы можете посмотреть на пирамиду, где снизу вверх отображено, образно говоря, убывание требований к техническим знаниям при использовании облака:

Serverless и FaaS (Function As A Service)
Serverless — достаточно молодой способ запуска скриптов в облаках, например, таких как AWS (в терминах AWS сервер реализуется в Lambda). Подходы *aaS, перечисленные на пирамиде выше, уже привычны: IaaS (EC2, VDS), PaaS (Shared Hosting), SaaS (Office 365, Tilda). Так вот, Serverless — это реализация подхода FaaS. И заключается данный подход в предоставлении пользователю готовой платформы для разработки, запуска и управления определённой функциональностью без необходимости самостоятельной подготовки и настройки.
Представьте, что у вас есть машина, которая занимается ночной обработкой документов, выполняя задачи с 00:00 до 6:00, а в остальные часы она простаивает. Спрашивается: зачем за неё платить днём? И почему бы не использовать свободные ресурсы на что-нибудь другое? Вот эта тяга к оптимизации и желание тратить деньги только на то, что реально используешь, и привела к появлению FaaS.
Serverless — это ресурс для выполнения кода и не более того. Это не означает, что за нашим скриптом нет сервера — он есть, но у нас, по сути, нет какого-либо конкретно выделенного ресурса, на котором будет запускаться наша Lambda. Когда мы запускаем наш скрипт, под него сразу же разворачивается микроинфраструктура, и это не ваша проблема в принципе — вы думаете лишь о том, чтобы у вас выполнился код, а больше вам ни о чём думать не надо.
Это требует, конечно же, определённого подхода к разработке вашего кода. Например, Вы ничего не можете хранить в этой среде, вам всё нужно выносить. Если это данные, то нужна внешняя БД, если это логи, то внешний сервис логов, если это файлы, то внешнее файловое хранилище. Благо, любой Serverless-провайдер предоставляет возможность соединения с внешними системами.
У Вас есть только код, вы работаете в парадигме Stateless, у вас нет состояния. Для того же мира PHP это означает, к примеру, что про стандартный механизм сессий можно забыть. В принципе, Вы можете построить даже свой Serverless, и недавно на Хабре была статья на эту тему.
Главная идея Serverless — инфраструктура не требует поддержки со стороны команды. Всё ложится на плечи платформы, за что Вы, собственно говоря, и платите деньги. Из минусов — Вы не контролируете среду выполнение и не знаете, где что выполняется.
Итак, Serverless:
- не означает физическое отсутствие сервера;
- не убийца виртуалок и Докера;
- не хайп «здесь и сейчас».
Serverless стоит включать в стек осознанно и обдуманно. Например, если Вам нужно быстренько проверить какую-нибудь гипотезу, не привлекая половину команды. Таким образом вы и получите Function As A Service. Функция будет реагировать на какие-то события, а поскольку есть реакция на события, эти события должны чем-то вызываться — для этого в том же AWS есть множество триггеров.
Особенности FaaS:
- инфраструктура не требует настройки;
- событийная модель «из коробки»;
- Stateless;
- масштабирование производится очень легко и выполняется автоматически под нужды пользователя.
AWS Lambda
Первая и общедоступная реализация FaaS — AWS Lambda. Если тезисно, то она имеет следующие особенности:
— доступна с 2014 года;
— поддерживает из коробки Java, Node.js, Python, Go и кастомные среды выполнения;
— мы платим за:
количество вызовов;
время выполнения.
AWS Lambda: зачем оно надо:
Утилизация. Вы платите только за то время, когда сервис работает.
Скорость. Сама по себе лямбда поднимается и работает очень быстро.
Функционал. Лямбда имеет много возможностей по интеграции с сервисами AWS.
Производительность. Положить лямбду довольно-таки сложно. Параллельно может выполняться в зависимости от региона максимально от 1000 до 3000 экземпляров. И при желании этот лимит можно повысить, написав в поддержку.
У нас есть тело лямбды, онлайн-редактор, VPC как виртуальная сетка вычислений, логирование, сам код, переменные окружения и триггеры, вызывающие лямбду (кстати, очень хорошо работает версионирование). Отлично анатомия Lambda расписана в этой статье.
Код хранится либо в теле (если это поддерживаемые из коробки языки), либо в слоях. У нас есть триггер, который вызывает лямбду, лямбда считывае птеременные окружения, подтягивает их к себе и выполняет наш код:

Если у нас есть кастомная среда выполнения, придётся размещать код в слое. Если вы работали с Докером, то Докер-слой очень похож на слой в лямбда — некое квази-хранилище, в котором размещается наша необходимая обвязка. Там у нас лежит исполняемый файл среды (если речь идёт о PHP, следует заранее разместить скомпилированный бинарник PHP), Bootstrap-файл лямбды (находится по умолчанию) и непосредственно вызываемые скрипты, которые будут выполняться.

С доставкой всё не так радужно:

То есть нам предлагают брать файлы с кодом, заливать в zip-архив, заливать в слой и запускать наш код. Совсем некруто, что такое предлагают в официальной документации Амазона.

Конечно, это не соответствует современным реалиям, и в воздухе запахло двухтысячными. Благо, добрые люди постарались и сделали несколько фреймворков, поэтому мы будем использовать Serverless framework, разработанный на Node.js и позволяющий управлять приложениями на базе AWS Lambda. Кроме того, когда мы говорим о деплое и разработке, то, конечно, вручную деплоить не очень хочется, а есть желание сделать что-то гибкое и автоматизированное.
Итак, нам понадобятся:
— AWS CLI — интерфейс командной строки для работы с сервисами AWS;
— уже упомянутый выше Serverless framework (версия для разработки бесплатна, а её функционала хватает за глаза);
— библиотека Bref, которая нужна для написания кода. Эта библиотека ставится посредством composer, поэтому код будет совместим с любым фреймворком. Прекрасное решение, особенно если учесть, что AWS Lambda не поддерживает вызов PHP-скриптов из коробки.

Настраиваем окружение и AWS
AWS CLI
Начнём с создания аккаунта и установки AWS CLI. Консольная оболочка от AWS основана на Python 2.7+ либо 3.4+. Так как в AWS рекомендуют 3 версию Python, спорить не будем.
Примеры ниже приводятся для Ubuntu.
sudo apt-get -y install python3-pipПотом устанавливаем непосредственно AWS CLI:
pip3 install awscli --upgrade --userПроверяем установку:
aws --versionТеперь надо подключить AWS CLI к аккаунту. Можно использовать имеющийся логин и пароль, но будет лучше, если вы создадите отдельного пользователя через AWS IAM, определив ему только нужные права доступа. Вызов конфигурации не вызовет проблем:
aws configureДалее вам потребуются AWS Secret и AWS Access Key. Их можно получить в ASW IAM во вкладке «Security credentials» (находится на странице нужного пользователя). Сгенерировать ключи доступа поможет кнопка «Create access key». Сохраните их у себя.

Чтобы зарегистрировать нового бота в Telegram, используем @BotFather и команду /newbot. В результате вам вернётся токен, необходимый для соединения с вашим ботом. Его также зафиксируйте.
Serverless Framework
Чтобы установить Serverless Framework, понадобится аккаунт на https://serverless.com/.
После выполнения регистрации перейдём к установке у себя на рабочей станции. Потребуется Node.js 6-й и выше версии.
sudo apt-get -y install nodejsЧтобы обеспечить корректный запуск в нашей среде, выполняем рекомендованные шаги:
mkdir ~/.npm-global
export PATH=~/.npm-global/bin:$PATH
source ~/.profile
npm config set prefix ‘~/.npm-global’Также добавляем:
~/.npm-global/bin:$PATHв файл /etc/environment.
Теперь ставим Serverless:
npm install -g serverlessAWS
Что же, пришла пора перейти в AWS-интерфейс и добавить доменное имя. Создаём в AWS Route 53 зону, DNS-запись, а также SSL-сертификат для неё.
Кроме того, потребуется ELB, который мы создаём в сервисе EC2 -> Load Balancers. Кстати, при создании ELB нужно пройти все шаги мастера, указав созданный сертификат.
Что касается балансировщика, то его можно создать через AWS CLI, используя следующую команду:
aws elb create-load-balancer --load-balancer-name my-load-balancer --listeners "Protocol=HTTP,LoadBalancerPort=80,InstanceProtocol=HTTP,InstancePort=80" "Protocol=HTTPS,LoadBalancerPort=443,InstanceProtocol=HTTP,InstancePort=80,SSLCertificateId=arn:aws:iam::123456789012:server-certificate/my-server-cert" --subnets subnet-15aaab61 --security-groups sg-a61988c3Балансировщик понадобится после первого деплоя. При этом нужно направить на него запросы к нашему домену. Чтобы это реализовать, в настройках DNS-записи (поле «Alias target») начните вводить название созданного ELB. В результате вы увидите выпадающий список, поэтому останется выбрать необходимую запись и сохранить её.

Теперь переходим к коду.
Пишем код
Для написания кода будем использовать Bref. Как упоминалось ранее, данная библиотека ставится посредством composer, поэтому код будет совместим с любым фреймворком. Кстати, разработчики уже описали процесс использования Bref с Laravel и Symfony. Но нам желательно поработать на «голом» PHP — это поможет лучше понять суть.
Начинаем с зависимостей:
{
"require": {
"php": ">=7.2",
"bref/bref": "^0.5.9",
"telegram-bot/api": "*"
},
"autoload": {
"psr-4": {
"App\": "src/"
}
}
}Писать будем на PHP 7.2 и выше, а для работы с Telegram нам подойдёт вот эта оболочка к API — https://github.com/TelegramBot/Api. Что касается самого кода, то он будет размещён в директории src.
Итак, бессерверная среда собирается через консольный диалог. Потребуется HTTP-приложение, а с точки зрения Lambda это будет значить, что вызов скриптов станет выполняться аналогично тому, как это осуществляет Nginx. Интерпретацию будем выполнять силами PHP-FPM. В целом это больше похоже на стандартный консольный вызов скрипта. Это важный момент, ведь без учёта данной особенности скрипты посредством HTTP вызывать у нас не получится.
Выполняем:
vendor/bin/bref initВ диалоге выбираем пункт «HTTP application» и не забываем указывать регион, так как приложение должно работать в том же регионе, в котором работает балансировщик.
После инициализации появятся 2 новых файла:
index.php — вызываемый файл;
serverless.yml — файл настройки деплоя.
Папку .serverless сразу необходимо будет добавить в .gitignore (она появится после 1-й попытки деплоя).
Раз у нас web-приложение, скинем index.php в папку public, сразу переключившись на serverless.yml. Вот как это может выглядеть в нашей реализации:
# имя lambda-приложения
service: app
# описание провайдера услуг
provider:
name: aws
# указываем регион балансировщика!
region: eu-central-1
# среда выполнения нестандартная
runtime: provided
# вообще, для bref рекомендуют 1024. Но для простого скрипта столько и не надо
memoryLimit: 256
# указываем окружение
stage: dev
# глобальные переменные окружения
environment:
BOT_TOKEN: ${ssm:/app/bot-token}
# подключаем bref
plugins:
- ./vendor/bref/bref
# описание Lambda-функций
functions:
# наша функция в итоге будет называться php-api-dev
# service-function-stage
api:
handler: public/index.php
description: ''
# in seconds (API Gateway has a timeout of 29 seconds)
timeout: 28
layers:
- ${bref:layer.php-73-fpm}
# возможные события вызова для API Gateway
events:
- http: 'ANY /'
- http: 'ANY /{proxy+}'
# локальные переменные окружения
environment:
MY_VARIABLE: ${ssm:/app/my_variable}Теперь разберём неочевидные строчки. В большей степени нам нужны переменные окружения. Мы не хотим хардкодить подключения к БД, внешним API и т. п. Если же мы подключаемся к Telegram, у нас будет свой токен, который получен от BotFather. И хранить этот токен в serverless.yml не рекомендуется, поэтому лучше отправим его в ssm-хранилище AWS:
aws ssm put-parameter --region eu-central-1 --name '/app/my_variable' --type String --value 'ТОКЕН_БОТА_ОТ_BOTFATHER'Кстати, как раз к нему мы и обращаемся в конфигурации.
Эти переменные доступны как переменные окружения, а получить к ним доступ в PHP можно посредством функции getenv. Если говорить о нашем примере, то давайте для простоты сохраним токен бота в глобальной области видимости. Также можем перенести токен в область видимости отдельно взятой функции, причём сам вызов от этого не изменится.
Идём дальше. Давайте теперь создадим простой класс BotApp — он будет отвечать за генерацию ответа для бота и будет реагировать на команды. Разработчики Telegram рекомендуют для всех ботов добавлять поддержку команд /help и /start. Давайте для интереса добавим ещё одну команду. Сам по себе класс довольно прост и даёт возможность реализовать в index.php Front Controller, не нагружая кодом сам файл вызова. Чтобы получить более сложную логику, архитектуру следует развивать и усложнять.
<?php
namespace App;
use TelegramBot\Api\Client;
use Telegram\Bot\Objects\Update;
class BotApp
{
function run(): void{
$token = getenv('BOT_TOKEN');
$bot = new Client($token);
// команда для start
$bot->command('start', function ($message) use ($bot) {
$answer = 'Добро пожаловать!';
$bot->sendMessage($message->getChat()->getId(), $answer);
});
// команда для помощи
$bot->command('help', function ($message) use ($bot) {
$answer = 'Команды:
/help - вывод справки';
$bot->sendMessage($message->getChat()->getId(), $answer);
});
// тестовая команда
$bot->command('hello', function ($message) use ($bot) {
$answer = 'Да-да, я - бот, работающий в Serverless окружении';
$bot->sendMessage($message->getChat()->getId(), $answer);
});
$bot->run();
}
}А вот как выглядит листинг index.php:
<?php
require_once('../vendor/autoload.php');
use App\BotApp;
try{
$botApp = new BotApp();
$botApp->run();
}
catch (Exception $e){
echo $e->getMessage();
print_r($e->getTrace(), 1);
}Это может показаться странным, но у нас уже всё готово, чтобы уехать на Production. Давайте сделаем это, выполнив команду в папке с serverless.yml:
sls deployВ штатном режиме serverless упакует файлы в zip архивы, создаст S3-bucket, куда положит их, потом создаст либо обновит AWS Application, привязанный к Lambda, и положит код и среду выполнения в отдельный слой.
Во время 1-го запуска будет создан API Gateway (мы его оставили, чтобы было проще потестировать вызовы, однако потом его желательно удалить). Также надо будет настроить вызов Lambda через ELB, для чего выбираем «Add trigger» в окне управления функцией и в выпадающем списке выбираем «Application Load Balancer». Нужно будет указать созданный ранее ELB, задать соединение через HTTPS, Host оставить пустым, а в Path указать путь, который будет вызывать Lambda (допустим, /lambda/mytgbot). В итоге ваша Lambda станет доступна по URL с указанием заданного пути.
Теперь можно регистрировать ответную часть бота в Telegram, чтобы мессенджер понимал, откуда брать сообщения. Для этого вызовите в браузере следующий URL, но не забудьте подставить в него собственные параметры:
https://api.telegram.org/botТОКЕН_БОТА/setWebhook?url=https://my-elb-host.com/lambda/mytgbotВ итоге API вернёт ответ «OK», после чего бот станет доступен.

Тестируем бота на локали
Бота можно потестировать и до деплоя. Дело в том, что Serverless Framework поддерживает запуск на локали, применяя для этого Docker-контейнеры. Команда вызова:
sls invoke local --docker -f myFunctionНе забывайте, что мы использовали переменные окружения, поэтому во время вызова их также следует задавать в формате:
sls invoke local --docker -f myFunction --env VAR1=val1Логи
По умолчанию вывод вызова будет логироваться в CloudWatch — он доступен в панели Monitoring соответствующей Lambda-функции. Тут же вы сможете почитать трейсы вызовов в случае отвала на стороне PHP. Кроме того, можно подключить и расширенные сервисы мониторинга, однако они обойдутся в дополнительные несколько центов ежемесячно.
Итого
В результате мы получили довольно быстрое, гибкое, скалируемое, а также относительно недорогое решение. Да, Lambda не всегда выигрывает по сравнению со стандартными ВМ и контейнерами, однако есть ситуации, когда Serverless-приложение помогает «выстрелить» быстро и эффективно. И пример созданного бота это как раз демонстрирует.
Полезные материалы по теме:
stanislav-belichenko
Интересная штука, но всегда в подобного рода сервисах удивляет, что достаточно высокий уровень экспертизы для их использования пересекается с предложением сэкономить на карандашах.
el_kex
На самом деле, за отсутствие экспертизы как раз и платятся деньги. По сути-то здесь надо один раз научиться это всё собирать воедино, поставить на рельсы и дальше пилить. А если не хочется, то платить за тот же API Gateway.
Дело не столько в экономии, сколько в быстром решении задач — serverless же как раз про это. А экономия вторична — в этом вебинаре я решил параллельно рассказать рецепт того, как платить меньше за практически ту же скорость решения.
stanislav-belichenko
Я пишу про экспертизу пользователя как разработчика, а не как администратора, DevOps'а и тп. Сложно в общем представить, насколько вообще востребован такой инструмент, он прям какую-то совсем узенькую нишу прикрывает, практически перекрываемую другими вариантами решений.
el_kex
Лично мне кажется, что Serverless сейчас несколько опережает время своего появления на рынке. Но с другой стороны это вариант вполне каноничного микросервиса. То есть, он развивает эту идею.
Если говорить про применимость здесь и сейчас, то я бы говорил о том, что serverless подход от облачных платформ хорош для быстрой сборки здесь и сейчас некоего продукта для проверки гипотезы, например, там, где совсем нет времени на работу с инфраструктурой. Даже настроенная по умолчанию виртуалка или дефолтный контейнер также потребуют какого-то мониторинга, организации логов. А тут это всё даётся с ходу.
stanislav-belichenko
Про опережение — согласен, может так и есть. Но в целом вы в итоге написали то, что пишу и я — ниша какая-то уж слишком призрачная. То есть я понимаю написанное вами в посте и согласен, что данный сервис имеет свой круг решаемых им задач, но задумавшись а когда мне это может пригодиться на практике, я понимаю, что скорее всего — никогда, как и большинству.
el_kex
Логично, как и для любой другой технологии. Тем не менее, когда я сам столкнулся с этим стеком (как и другие люди, интересующиеся serverless, я полагаю), я увидел большую нехватку «рецептов» в этой области и определенный недостаток документации. Что и побудило собрать все воедино.
stanislav-belichenko
И за это вам большое спасибо.
Не совсем понял, про что конкретно вы пишете. Есть масса технологий, которая востребована большинством, ну или по крайней мере чувствительной частью сообщества разработчиков.
el_kex
Прошу прощения, писал с мобильного. Забыл там указать слово «узконаправленной».
Всегда рад :)