
— Всем привет, меня зовут Кирилл. Я буду сегодня рассказывать про Dependency Injection.
Мы начнем с того, как у меня называется доклад. «В некотором царстве, не в «спринговом» государстве». Мы поговорим, конечно, про Spring, но также хочется посмотреть на все, что есть помимо него. О чем конкретно поговорим?

Я сделаю небольшое отступление — расскажу, над чем я работаю, какой у меня проект, зачем мы используем Dependency Injection. Потом расскажу, что это вообще такое, сравню Inversion of Control и Dependency Injection, и расскажу о его реализации в трех самых известных библиотеках.
Я работаю в команде Яндекс.Трекера. Мы делаем продуктовый аналог Jira или Trello. [...] Мы решили сделать собственный продукт, который сначала был внутренним. Сейчас мы его продаем наружу. Каждый из вас может зайти, создать себе собственный Трекер и делать задачи — например, учебные или бизнесовые.
Посмотрим на интерфейс. В примерах я буду использовать некоторые термины из моей области. Мы попробуем создать тикет и в нем посмотрим на комментарии, которые будут мне оставлять другие коллеги.
Начну с того, что вообще такое Dependency Injection. Это такой паттерн программирования, который отвечает старой американской поговорке, Hollywood principle: «Не звони нам, мы тебе сами позвоним». Сами зависимости приходят к нам. Это в первую очередь паттерн, не библиотека. Поэтому в принципе такой паттерн распространен почти везде. Можно даже сказать, что все приложения так или иначе используют Dependency Injection.

Посмотрим, как вообще Dependency Injection можно придумать самому, если мы начнем с нуля. Допустим, я решил разработать такой небольшой класс, в котором я буду создавать тикет через наш API. Создадим, например, инстанс класса TrackerApi. В нем есть метод createTicket, в который мы передадим мой имейл. Мы будем создавать тикет из-под моего аккаунта и с таким названием: «Подготовить доклад к Java Meetup».

Посмотрим реализацию TrackerApi. Здесь мы, например, можем сделать так: создаем инстанс httpClient. Если говорить простым языком, то мы будем создавать объект, через который будем ходить в API. Через этот объект мы будем вызывать у него метод execute.

Например, пользовательский какой-нибудь. Я написал внешний код от этих классов, и он будет его использовать примерно так. Я создаю новый TicketCreator и вызываю у него метод createTicket.

Здесь есть проблема — мы каждый раз при создании тикета будем создавать заново и заново httpClient, хотя вообще говоря, в этом нет никакой нужды. httpClients бывают очень серьезными для создания.

Давайте попробуем это вынести. Здесь можно увидеть самый первый пример Dependency Injection в нашем коде. Обратите внимание, что мы сделали. Мы вынесли нашу переменную в поле и заполняем его в конструкторе. Тот факт, что мы заполняем его в конструкторе, означает, что к нам приходят зависимости. Это первый Dependency Injection.

Мы переложили ответственность на пользователей кода, поэтому теперь мы должны создавать httpClient, передавая его, например, в TicketCreator.
Здесь это тоже не очень хорошо, потому что теперь мы, вызывая этот метод, опять будем каждый раз создавать httpClient.

Поэтому снова вынесем его в поле. И здесь, кстати, есть неочевидный пример Dependency Injection. Мы можем сказать, что мы всегда создаем из-под меня (или из-под кого-то) тикеты. Мы каждый отдельный объект TicketCreator будем создавать из-под разных пользователей.
Например, этот будет создавать из-под меня, когда мы его создадим. И строка, которую мы передаем в конструктор, — это тоже Dependency Injection.

Как мы будем делать теперь? Создаем новый инстанс TrackerTicketCreator и вызываем метод. Теперь мы можем даже создать какой-нибудь кастомный метод, который будет создавать нам тикет с кастомным текстом. Например, создадим тикет «Нанять нового стажера».

Теперь попробуем посмотреть, как бы выглядел наш код, если бы мы хотели читать комментарии в этом тикете точно так же, из-под меня. Это примерно такой же код. Мы бы вызывали метод getComments у этого тикета.
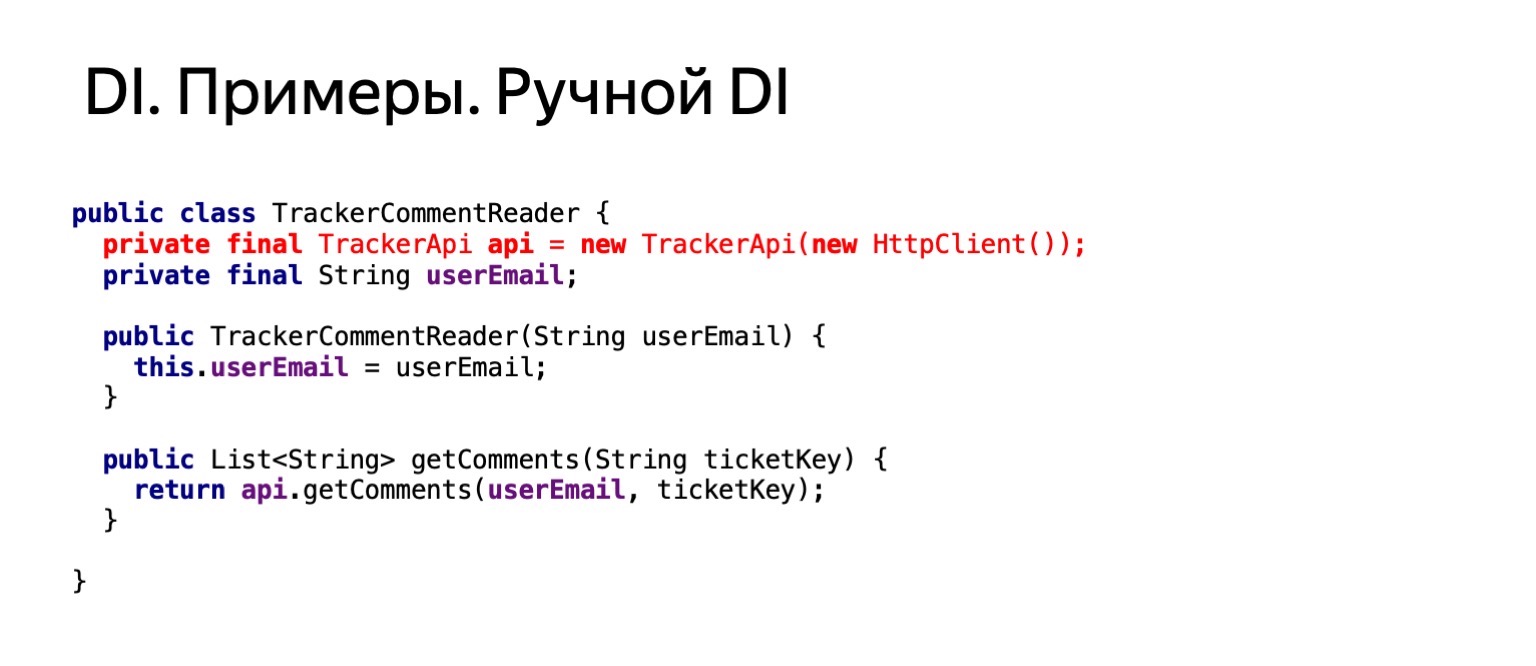
Как бы он выглядел? Если мы берем и дублируем эту функциональность в ридере комментариев, мы дублируем создание httpClient. Нам такое не подходит. Мы хотим от этого избавиться.

Хорошо. Теперь давайте пробросим все эти параметры как Dependency Injection, как параметры конструктора.

Какая здесь проблема? Мы всё прокинули, но в пользовательском коде мы теперь пишем «бойлерплейт». Это какой-то ненужный код, который обычно должен написать пользователь, чтобы сделать относительно небольшое действие с точки зрения логики. Здесь мы постоянно должны будем создавать httpClient, API для него и выбирать user email. Каждый пользователь TicketCreator должен будет делать это сам. Это не ок. Мы сейчас попробуем посмотреть, как это будет выглядеть в библиотеках, когда мы попытаемся этого избежать.
А сейчас немного отклонимся в сторону и посмотрим, что такое Inversion of Control, потому что многие связывают Dependency Injection ровно с ним.

Inversion of Control — принцип программирования, при котором используемые нами объекты создаются не нами. Мы вообще никак не влияем на их lifecycle. Обычно сущность, создающая эти объекты, называется IoC-контейнером. Многие из вас уже здесь слышали про Spring. Spring-документация говорит, что IoC так же известны, как Dependency Injection. Они считают, что это одно и то же.

Какие есть основные принципы? Объекты создает не прикладной код, а какой-то IoC-контейнер. Мы как пользователи библиотеки ничего не делаем, к нам все само приходит. Конечно, IoC относительно. Сам IoC-контейнер создает эти объекты, и к нему это уже не применимо. Можно подумать о том, что IoC реализует не только DI-библиотеки. Известны библиотеки Java Servlets и Akka Actors, которые сейчас используются в Scala и в Java-коде.

Поговорим про библиотеки. Вообще говоря, библиотек для Java и Kotlin уже написано достаточно много. Я перечислю основные:
— Spring, большой фреймворк. Его основная часть — Dependency Injection или, как они говорят, Inversion of Control.
— Guice — библиотека, которая была написана примерно между вторым и третьим Spring, когда Spring переходил от XML к кодовому описанию. То есть когда Spring еще был не таким красивым.
— Dagger — то, чем обычно пользуются люди на Android.
Давайте попробуем переписать пример наш на Spring.

У нас был наш TrackerApi. Я здесь не стал включать пользователя для краткости. Допустим, мы попытаемся в Dependency Injection сделать для httpClient. Для этого нам потребуется объявить его с аннотацией. Component, весь класс, и конкретно конструктор объявить с аннотацией Autowired. Что это означает для Spring?

У нас в коде есть такая конфигурация, она обозначена аннотацией ComponentScan. Она означает, что мы попытаемся пройти по всему дереву наших классов в package, в котором он содержится. И дальше вглубь попытаемся найти все классы, которые размечены в аннотации Component.
Эти компоненты попадут в IoC-контейнер. Для нас важно, что все попадет за нас. Мы только размечаем, что мы хотим объявить. Чтобы к нам что-то пришло, мы должны объявить это с помощью аннотации Autowired в конструкторе.

TicketCreator мы размечаем точно так же.

И CommentReader тоже.
Теперь посмотрим обратно на конфигурацию. Как мы уже говорили, Component Scan положит все в IoC-контейнер. Но здесь есть один момент, так называемый factory method. У нас есть метод httpClient, который мы создаем не в виде класса, потому что httpClient к нам приходит из библиотеки. У него нет никакого понимания, что такое Spring и т. д. Мы его создадим напрямую в конфигурации. Для этого мы пишем метод, который обычно билдит его один раз, и размечаем его аннотацией Bean.

Какие есть плюсы и минусы? Главный плюс — Spring очень распространен в мире. Следующим плюсом и одновременно минусом является автосканирование. Мы нигде не должны явно прописывать, что мы хотим добавить в IoC контейнер помимо аннотаций над самими классами. Достаточно аннотаций. И минус точно такой же: если мы, наоборот, хотим контроля над этим, то Spring нам этого не предоставляет. Разве что мы можем у себя в команде сказать: «Нет, мы так делать не будем. Мы должны явно что-то где-то прописать. Только так, в конфигурации, как мы сейчас делали с бинами.
Также из-за этого происходит медленный старт. Когда стартует приложение, Spring должен пройтись по всем этим классам и понять, что же положить в IoC-контейнер. Это замедляет его. Самым большим минусом Spring, как мне кажется, является дерево зависимостей. Оно проверяется не на этапе компиляций. Когда в определенный момент Spring запускается, ему надо понять, есть ли такая зависимость у меня внутри. Если потом окажется, что в дереве зависимостей его нет, то вы получите ошибку в runtime. А мы в Java не хотим ошибки в runtime. Мы хотим, чтобы код нам можно было скомпилировать. Это означает, что он работает.

Давайте посмотрим на Guice. Это библиотека, которая, как я уже говорил, была сделана между вторым и третьим Spring. Той красоты, которую мы видели, не было. Были XML. Чтобы исправить эту проблему, и был написан Guice. А здесь видно, что, в отличие от конфигурации, мы пишем модуль. В нем мы объявляем явно, какие классы мы хотим положить в этот модуль: TrackerAPI, TrackerTicketCreator и все остальные бины. Аналогом Bean-аннотации здесь служит Provides, который создает httpClient в той же манере.

Нам нужно объявить каждый из этих бинов. Мы назовем пример Singleton. Но конкретно Singleton скажет, что такой бин будет создан ровно один раз. Мы не будем его постоянно пересоздавать. А Inject, соответственно, является аналогом Autowired.

Небольшая табличка с тем, что к чему относится.

Какие есть плюсы и минусы? Плюсы: он более простой, как мне кажется, и понятный, чем XML-вариант Spring. Более быстрый запуск. И отсюда минусы: он требует явного объявления используемых бинов. Мы должны были написать Bean. Но с другой стороны, это и плюс, как мы уже говорили. Это является зеркальным отражением того, что есть в Spring. Конечно, он менее распространен, чем Spring. Это его естественный минус. И есть точно такая же проблема — дерево зависимостей проверяется не на этапе компиляции.
Когда ребята начали использовать Guice для Android, они поняли, что им все равно не хватает скорости запуска. Поэтому они решили написать более простой и примитивный Dependency Injection-фреймворк, который позволит им сделать быстрый старт приложения, потому что для Android это очень важно.

Здесь терминология та же. У Dagger есть точно такие же модули, как у Guice. Но они уже размечаются аннотациями, не как в случае наследования от класса. Поэтому принцип сохраняется.
Единственный минус — мы внутри модуля всегда должны явно указывать, каким образом создаются бины. В Guice мы могли отдать создание бинов внутрь самого бина. Нам не надо было говорить, какие зависимости куда нужно куда пробросить. А здесь нам нужно это явно сказать.

В Dagger из-за того, что не хочется делать слишком ручной ввод, есть понятие компонента. Компонент — это нечто, что связывает модули, когда мы хотим один бин из одного модуля объявить, чтобы его можно было взять в другом модуле. Это другая концепция. Бин из одного модуля может «заинжектить» бин из другого модуля с помощью компонента.

Здесь примерно такая же сводная табличка — что на что поменялось либо не поменялось в случае Inject или модулей.

Какие плюсы? Он еще более простой, чем Guice. Запуск происходит еще быстрее, чем у Guice. И он уже, наверное, не станет более быстрым, потому что в Dagger полностью отказались от reflection. Это именно та часть библиотеки в Java, которая отвечает за то, чтобы посмотреть на состояние объекта, на его класс и методы. То есть получить состояние в runtime. Поэтому он не использует reflection. Он не идет и не сканирует, какие у кого зависимости. Но из-за этого он и стартует очень быстро.
Как он это делает? С помощью кодогенерации.
Если мы посмотрим назад, то увидим компонент интерфейса. Мы не сделали никакую реализацию этого интерфейса, Dagger сам за нас ее делает. И можно будет дальше использовать интерфейс в приложении.
Естественно, он очень сильно распространен в мире Android за счет этой скорости. Дерево зависимостей проверяется сразу на компиляции, потому что нет ничего, что мы отложенно будем проверять в runtime.
Какие здесь минусы? У него меньше возможностей. Он более многословный, чем Guice и Spring.

В рамках этих библиотек в Java возникла инициатива — так называемый JSR-330. JSR — это запрос на то, чтобы сделать изменение в спецификации языка либо дополнить его какими-то дополнительными библиотеками. Такой стандарт предложили на основе Guice, и аннотации Inject были внесены в эту библиотеку. Соответственно, Spring и Guice его поддерживают.
Какие можно сделать выводы? В Java очень много разных библиотек для DI. И надо понимать, для чего мы берем конкретную из них. Если мы берем Android, то тут уже выбора нет, используем Dagger. Если мы идем в мир бэкенда, то уже смотрим, что нам больше подходит. И для первого изучения Dependency Injection, как мне кажется, Guice подходит лучше, чем Spring. В нем нет ничего лишнего. Можно посмотреть, как это работает, пощупать.
Для дальнейшего изучения я предлагаю ознакомиться с документацией всех этих библиотек и составом JSR:
— Spring
— Guice
— Dagger 2
— JSR-330
Спасибо!
Комментарии (14)



sved
11.12.2019 14:39-1В статье много ошибок:
- Аналогом IoC при «ручном» варианте является известный миллион лет паттерн Service Locator (хотя с другой стороны IoC движок можно рассматривать как вариант сервис локатора). Но по какой-то причине этот паттерн не приведен в «ручных» фрагментах кода
- Нет сравнения по библиотекам плагинов, позволяющим внедрять сквозную функциональность в код (кэширование, логирование, права доступа, транзакции, повтор операций при ошибках и пр. пр. ), из-за которых спринг собственно и применяется
- Никто не заставляет использовать в спринге автосканирование (по-умолчанию оно вообще выключено), поэтому все дальнейшие рассуждения о «медленности» запуска не выдерживают никакой критики. С отключенным автосканированием спринг стартует быстро

PqDn
11.12.2019 15:16Если говорить про типичное современное приложение на спринге (без xml), то в нем как раз автосканирование включено.
Вполне возможно, что у вас используется бины из библиотеки какие-нибудь, а там автоскан.
Ничего в этом плохого не вижу.
Статья носит обзорный характер и ориентирована на джунов. В видео явно сказано, что из спринга расcматривается только DIsved
11.12.2019 16:52Наличие или отсутствие XML на автоскан никак не влияет. Точно так же как и наличие зависимостей.
Типичное современное приложение без автоскана встречается намного чаще, чем Guice и Dagger вместе взятые.
Спринг — это обширная экосистема. Рассматривать только DI — нет никакого смысла. Так же как и нет смысла рассматривать спринг в контексте мобильной разработки.
То что статья ориентирована на джунов не значит, что надо искажать факты и натягивать сову на глобус.
PqDn
11.12.2019 14:40Это получается даггер, как и Lombok, использует препроцессор аннотаций для кодо генерации?
ChiefPilot
Скажите, пожалуйста, кто знает почему так: я не подписан ни на один хаб, указанный в списке под заголовком статьи, не подписан на саму компанию Яндекс, но почему-то я вижу эту статью в своей ленте. Как мне такое всё-таки не видеть? У меня нет никакого негатива, не подумайте ничего такого, но это как-то странно, что я её вижу.
BarakAdama
Лента «По подписке»?
Загадка. Можно спросить у Boomburum
ChiefPilot
Да, лента точно «по подписке» (проверил сейчас ещё раз) и всё равно видно.
Boomburum
Хм, вижу что у поста есть хаб OpenSource, на который вы подписаны. Изначально у поста не было этого хаба, поэтому, вероятно, он появился с задержкой — изучим.
ChiefPilot
Да, спасибо, теперь я вижу в списке хаб OpenSource и теперь понятно почему я вижу эту статью. Но изначально его не было видно. Это точно, так как я даже специально прошёл по ссылкам во все присутствовавшие тогда хабы и удостоверился, что не подписан на них (там везде была активна кнопка «Подписаться»).
Boomburum
Вот сейчас пытаюсь сопоставить действия по ревизиям поста — когда появился хаб, когда появился комментарий, какой таймлаг возможен и почему..)