
Давно была мысль посмотреть, что можно делать с ELK и подручными источниками логов и статистики. На страницах хабра планирую показать практический пример, как с помощью домашнего мини-сервера можно сделать, например, honeypot с системой анализа логов на основе ELK стека. В этой статье расскажу про простейший пример анализа логов firewall с помощью стека ELK. В дальнейшем хотелось бы описать настройку окружения для анализа Netflow трафика и pcap дампов инструментом Zeek.
Если у вас есть публичный IP-адрес и более-менее умное устройство в качестве шлюза/файрволла, вы можете организовать пассивный honeypot, настроив логирование входящих запросов на «вкусные» TCP и UDP порты. Под катом пример настройки маршрутизатора Mikrotik, но если у вас под рукой маршрутизатор другого вендора (или какая-то ещё security система), нужно просто немного разобраться с форматами данных и вендоро-специфичными настройками, и получится тот же результат.
Статья не претендует на оригинальность, здесь не рассматриваются вопросы отказоустойчивости сервисов, безопасности, лучших практик и т.д. Нужно рассматривать этот материал как академический, он подходит для ознакомления с базовым функционалом стека ELK и механизмом анализа логов сетевого устройства. Однако и не новичку может быть что-то интересно.
Проект запускается из docker-compose файла, соответственно развернуть своё подобное окружение очень просто, даже если у вас под рукой маршрутизатор другого вендора, нужно просто немного разобраться с форматами данных и вендоро-специфичными настройками. В остальном я постарался максимально подробно описать все нюансы, связанные с конфигурированием Logstash pipelines и Elasticsearch mappings в актуальной версии ELK. Все компоненты этой системы хостятся на github, в том числе конфиги сервисов. В конце статьи я сделаю раздел Troubleshooting, в котором будут описаны шаги по диагностике популярных проблем новичков в этом деле.
На самом сервере у меня установлена система виртуализации Proxmox, на ней в KVM машине запускаются Docker контейнеры. Предполагается, что вы знаете, как работает docker и docker-compose, благо примеров настройки о использования в интернете достаточно. Я не буду касаться вопросов установки Docker, про docker-compose немного напишу.
Идея запустить honeypot возникла в процессе изучения Elasticsearch, Logstash и Kibana. В профессиональной деятельности я никогда не занимался администрированием и вообще использованием этого стека, но у меня есть хобби проекты, благодаря которым сложился большой интерес изучить возможности, которые даёт поисковый движок Elasticsearch и Kibana, с помощью которых можно анализировать и визуализировать данные.
Моего не самого нового мини сервера NUC с 8GB RAM как раз хватает для запуска ELK стека с одной нодой Elastic. В продакшн окружениях так делать, конечно, не рекомендуется, но для обучения в самый раз. По поводу вопроса безопасности в конце статьи есть ремарка.
В интернете полно инструкций по установке и конфигурированию ELK стека для схожих задач (например, анализ brute force атак на ssh с помощью Logstash версии 2, анализ логов Suricata с помощью Filebeat версии 6), однако в большинстве случаев не уделяется должного внимания деталям, к тому же 90 процентов материала будет для версий от 1 до 6 (на момент написания статьи актуальная версия ELK 7.5.0). Это важно, потому что с 6 версии Elasticsearch решили убрать сущность mapping type, тем самым синтаксис запросов и структура мапингов изменились. Mapping template в Elastic вообще очень важный объект, и чтобы потом не было проблем с выборкой и визуализацией данных, советую не увлекаться копипастой и стараться понимать, что делаете. Дальше я постараюсь понятно объяснять, что значат описываемые операции и конфиги.
Для домашней сети в качестве маршрутизатора я использую Mikrotik, так что пример будет для него. Но на отправку syslog на удалённый сервер можно настроить почти любую систему, будь то маршрутизатор, сервер или ещё какая-то security система, которая умеет логировать.
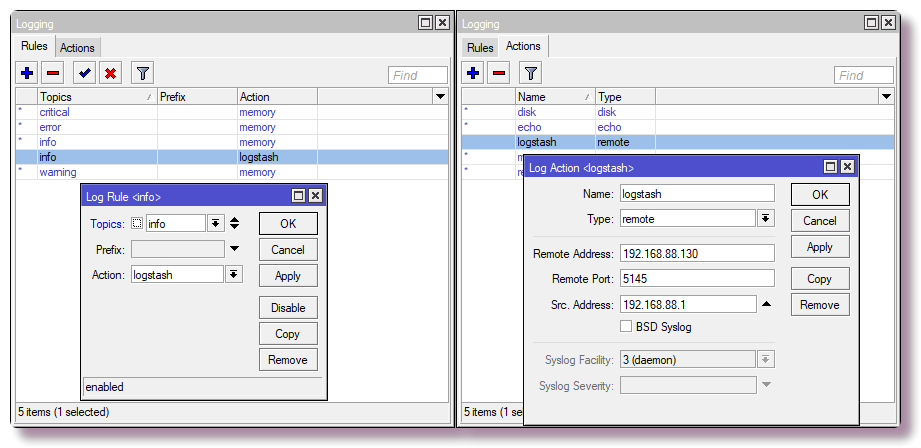
В Mikrotik для настройки логирования на удалённый сервер через CLI достаточно ввести пару команд:
Нас интересуют только определённые данные (hostname, ip-adress, username, url etc.), из которых можно получить красивую визуализацию или выборку. В самом простом случае, чтобы получить информацию о сканировании портов и попытке доступа, нужно настроить компонент firewall на логирование срабатываний правила. Я на Mikrotik настроил правила в таблице NAT, а не Filter, так как в дальнейшем собираюсь поставить ханипоты, которые будут эмулировать работу сервисов, это позволит исследовать больше информации о поведении ботнетов, но это уже более продвинутый сценарий и о нём не в этот раз.
Внимание! В конфигурации ниже стандартный TCP порт сервиса SSH (22) натится в локальную сеть. Если вы используете SSH для доступа к роутеру извне и в настройках стоит порт 22 (ip service print в CLI и ip > services в Winbox), стоит переназначить порт для management SSH, либо не вводить последнее правило в таблице.
Так же, в зависимости от названия WAN-интерфейса (если не используется WAN bridge), нужно поменять параметр in-interface на соответствующий.
В Winbox то же самое настраивается в разделе IP > Firewall > вкладка NAT.
Теперь роутер будет перенаправлять полученные пакеты на локальный адрес 192.168.88.201 и кастомный порт. Сейчас пока что никто не слушает на этих портах, так что коннекты будут обрываться. В дальнейшем в докере можно запустит honeypot, коих множество под каждый сервис. Если этого делать не планируется, то вместо правил NAT следует прописать правило с действием drop в цепочке Filter.
Дальше можно приступать к настройке компонента, который будет заниматься процессингом логов. Cоветую сразу заняться практикой и склонировать репозиторий, чтобы видеть конфигурационные файлы полностью. Все описываемые конфиги можно увидеть там, в тексте статьи я буду копировать только часть конфигов.
В тестовом или dev окружении удобнее всего запускать docker контейнеры c помощью docker-compose. В этом проекте я использую docker-compose файл последней на данный момент версии 3.7, он требует docker engine версии 18.06.0+, так что не лишним обновить docker, а так же docker-compose.
Так как в последних версиях docker-compose выпилили параметр mem_limit и добавили deploy, запускающийся только в swarm mode (docker stack deploy), то запуск docker-compose up конфигурации с лимитами приводит к ошибке. Так как я не использую swarm, а лимиты ресурсов иметь хочется, запускать приходится с опцией --compatibility, которая конвертирует лимиты из docker-compose новых версий в нон-сварм эквивалент.
Пробный запуск всех контейнеров (в фоновом режиме -d):
Придётся подождать, пока скачаются все образы, и после того как запуск завершится, проверить статус контейнеров можно командой:
Благодаря тому, что все контейнеры будут в одной сети (если явно не указывать сеть, то создаётся новый бридж, что подходит в этом сценарии) и в docker-compose.yml у всех контейнеров прописан параметр container_name, между контейнерами уже будет связность через встроенный DNS докера. Вследствие чего не требуется прописывать IP-адреса в конфигах контейнеров. В конфиге Logstash прописана подсеть 192.168.88.0/24 как локальная, дальше по конфигурации будут более подробные пояснения, по которым можно оттюнить пример конфига перед запуском.
Дальше будут пояснения по настройке функционала компонентов ELK, а также ещё некоторые действия, которые нужно будет произвести над Elasticsearch.
Для определения географических координат по IP-адресу потребуется скачать free базу GeoLite2 от MaxMind:
Основным файлом конфигурации является logstash.yml, там я прописал опцию автоматического релоада конфигурации, остальные настройки для тестового окружения не значительные. Конфигурация самой обработки данных (логов) в Logstash описывается в отдельных conf файлах, обычно хранящихся в директории pipeline. При схеме, когда используются multiple pipelines, файл pipelines.yml описывает активированные пайплайны. Пайплайн — это цепочка действий над неструктурированными данными, чтобы на выходе получить данные с определённой структурой. Схема с отдельно настроенным pipelines.yml не обязательная, можно обойтись и без него, загружая все конфиги из примонтированной директории pipeline, однако с определённым файлом pipelines.yml настройка получается более гибкая, так как можно не удаляя conf файлы из директории pipeline, включать и выключать необходимые конфиги. К тому же перезагрузка конфигов работает только в схеме multiple pipelines.
Дальше идёт самая важная часть конфига Logstash. Описание pipeline состоит из нескольких секций — в начале в секции Input указываются плагины, с помощью которых Logstash получает данные. Наиболее простой способ собирать syslog с сетевого устройства — использовать input плагины tcp/udp. Единственный обязательный параметр этих плагинов — это port, его нужно указать таким же, как и в настройках роутера.
Второй секцией идёт Filter, в которой прописываются дальнейшие действия с пока ещё не структурированными данными. В моём примере удаляются лишние syslog сообщения от роутера с определённым текстом. Делается это с помощью условия и стандартного действия drop, которое отбрасывает всё сообщение, если условие удовлетворяется. В условии проверяется поле message на наличие определённого текста.
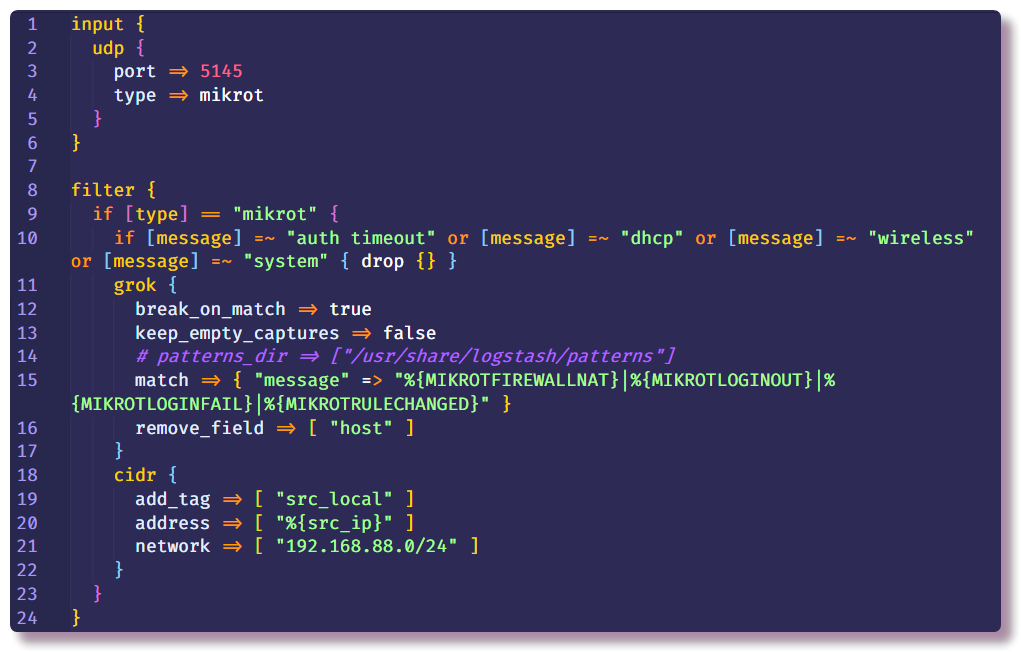
Если сообщение не дропнулось, оно идёт дальше по цепочке и попадает в фильтр grok. Как написано в документации, grok is a great way to parse unstructured log data into something structured and queryable. Этот фильтр применяют для обработки логов различных систем (linux syslog, веб-сервера, БД, сетевые устройства и т.д.). На основе готовых паттернов можно, не тратя много времени, составить парсер для любой более-менее повторяющейся последовательности. Для валидации удобно использовать онлайн парсер (в последней версии Kibana аналогичный функционал есть в разделе Dev Tools).
В docker-compose.yml прописан volume "./logstash/patterns:/usr/share/logstash/patterns", в директории patterns лежит файл со стандартными community-паттернами (просто для удобства, посмотреть если забыл), а так же файл с паттернами нескольких типов сообщений Mikrotik (модули Firewall и Auth), по аналогии можно дополнить своими шаблонами для сообщений другой структуры.
Стандартные опции add_field и remove_field позволяют внутри любого фильтра добавить или удалить поля из обрабатываемого сообщения. В данном случае удаляется поле host, которое содержит имя хоста, с которого было получено сообщение. В моём примере хост всего один, так что смысла в этом поле нет.
Дальше всё в той же секции Filter я прописал фильтр cidr, который проверяет поле с IP-адресом на соответствие условию вхождения в заданную подсеть и ставит тег. На основе тега в дальнейшей цепочке будут производиться или не производиться действия (если конкретно, то это для того, чтобы в дальнейшем не делать geoip lookup для локальных адресов).
Секций Filter может быть сколько угодно, и, чтобы было меньше условий внутри одной секции, в новой секции я определил действия для сообщений без тега src_local, то есть тут обрабатываются события файрволла, в которых нам интересен именно адрес источника.
Теперь надо немного подробнее рассказать про то, откуда Logstash берёт GeoIP информацию. Logstash поддерживает базы GeoLite2. Есть несколько вариантов баз, я использую две базы: GeoLite2 City (в которой есть информация о стране, городе, часовом поясе) и GeoLite2 ASN (информация об автономной системе, к которой принадлежит IP-адрес).

Плагин geoip и занимается добавлением GeoIP информации в сообщение. Из параметров надо указать поле, в котором содержится IP-адрес, используемую базу, и название нового поля, в которое будет прописана информация. У меня в примере тоже самое делается и для destination IP-адреса, но пока что в этом простом сценарии эта информация будет неинтересна, так как адрес назначения всегда будет являться адресом роутера. Однако в дальнейшем в этот пайплайн можно будет добавить логи не только с файрволла, но и с других систем, где актуально будет смотреть на оба адреса.
Фильтр mutate позволяет изменять поля сообщения и модифицировать сам текст в полях, в документации подробно написано много примеров того, что можно делать. В данном случае используется для добавления тега, переименования полей (для дальнейшей визуализации логов в Kibana требуется определённый формат объекта geo-point, дальше я ещё коснусь этой темы) и удаления ненужных полей.
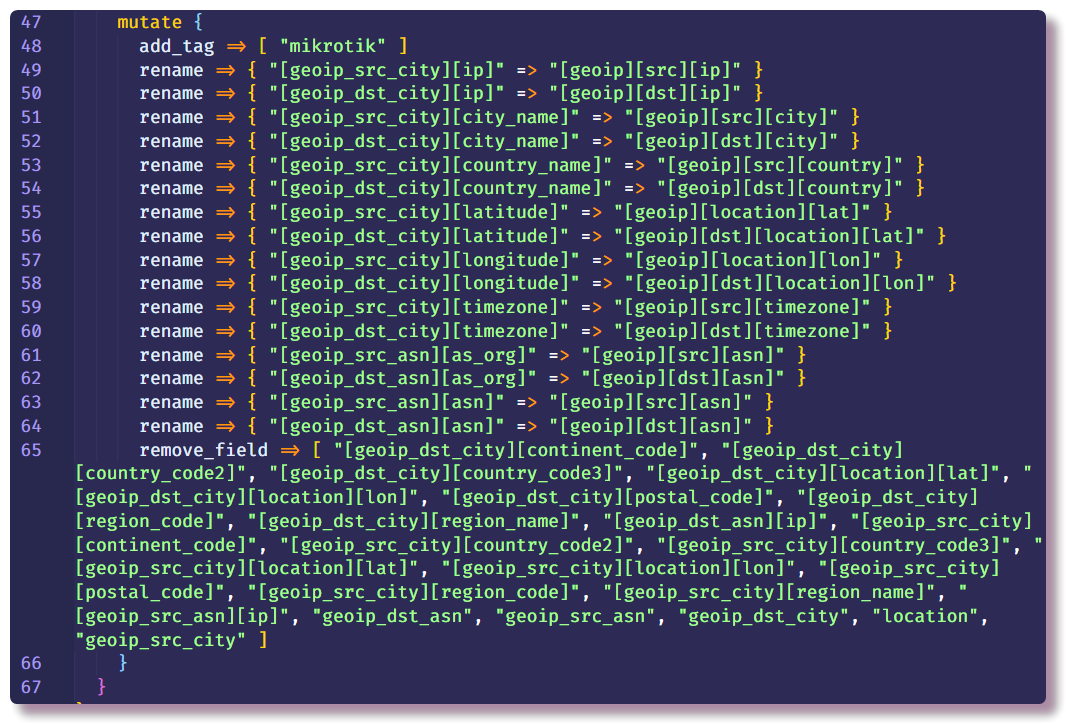
На этом секция обработки данных заканчивается и остаётся только обозначить, куда слать структурированное сообщение. В данном случае сбором данных будет заниматься Elasticsearch, нужно только ввести IP-адрес, порт и название индекса. Индекс рекомендуется вводить с variable полем даты, чтобы каждый день создавался новый индекс.
Возвращаемся к Elasticsearch. Для начала надо удостовериться, что сервер запущен и функционирует. С Elastic эффективнее всего взаимодействовать через Rest API в CLI. С помощью curl можно посмотреть состояние ноды (localhost заменить на ip-адрес докер хоста):
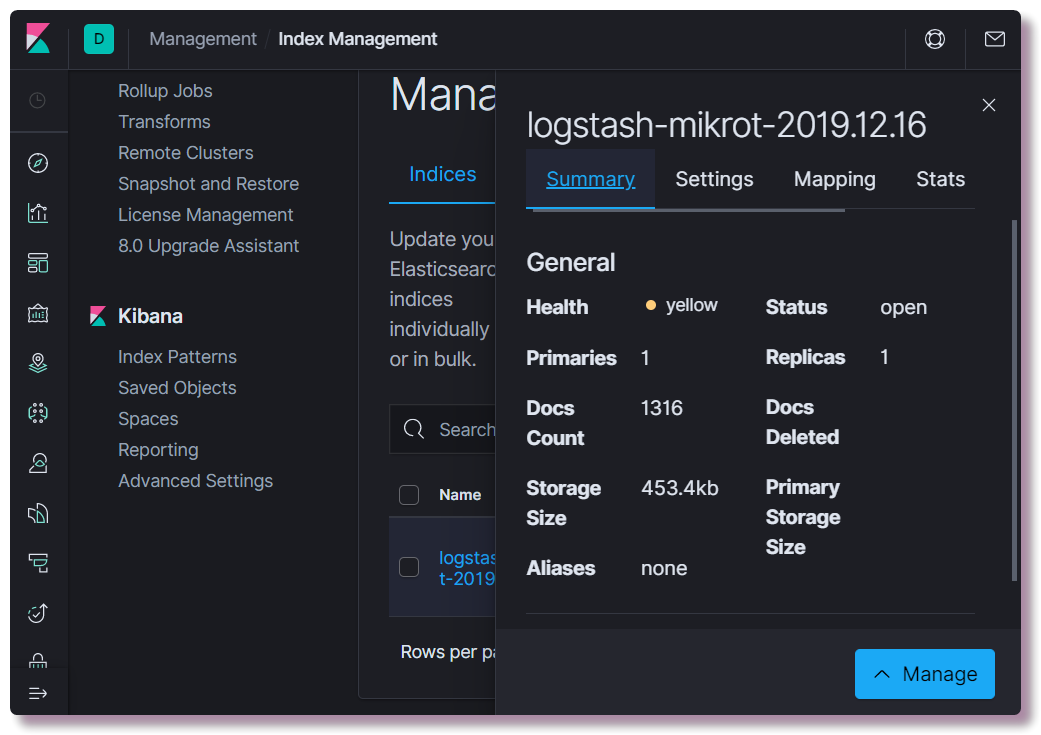
Дальше можно пробовать открыть Kibana по адресу localhost:5601. В веб-интерфейсе Kibana настраивать ничего нет необходимости (разве что поменять тему на тёмную). Нам интересно посмотреть, создался ли индекс, для этого нужно открыть раздел Management и слева вверху выбрать Elasticsearch Index Management. Здесь можно посмотреть, сколько документов заиндексировано, сколько это занимает места на диске, так же из полезного можно посмотреть информацию по мапингу индекса.
Как раз дальше нужно прописать правильный mapping template. Эта информация Elastic нужна для того, чтобы он понимал, к каким типам данных какие поля относить. Например, чтобы делать специальные выборки на основе IP-адресов, для поля src_ip нужно явно указать тип данных ip, а для определения географического положения нужно определить поле geoip.location в определённом формате и прописать тип geo_point. Все возможные поля описывать не надо, так как для новых полей тип данных определяется автоматически на основе динамических шаблонов (long для чисел и keyword для строк).
Записать новый template можно или с помощью curl, или прямо из консоли Kibana (раздел Dev Tools).
После изменения мапинга нужно удалить индекс:
Когда прилетит хотя бы одно сообщение в индекс, проверить мапинг:
Для дальнейшего использования данных в Kibana, нужно в разделе Management > Kibana Index Patternсоздать pattern . Index name ввести с символом * (logstash-mikrot*), чтобы матчились все индексы, выбрать поле timestamp в качестве поля с датой и временем. В поле Custom index pattern ID можно ввести ID паттерна (например, logstash-mikrot), в дальнейшем это может упростить обращения к объекту.
После того, как создали index pattern, можно приступать к самому интересному — анализу и визуализации данных. В Kibana есть множество функционала и разделов, но нам пока что будут интересны только два.
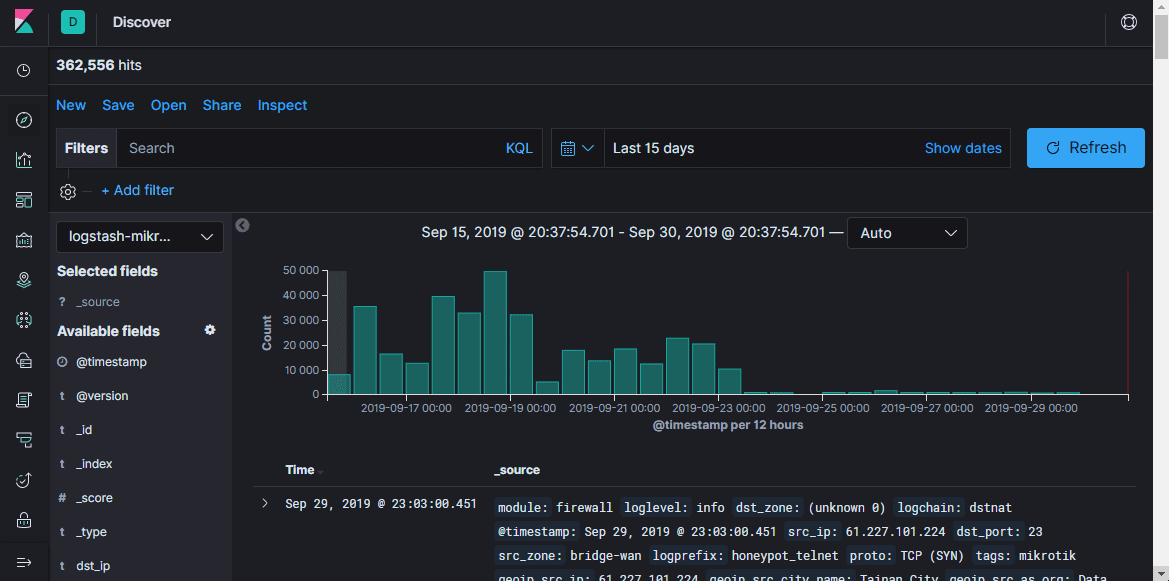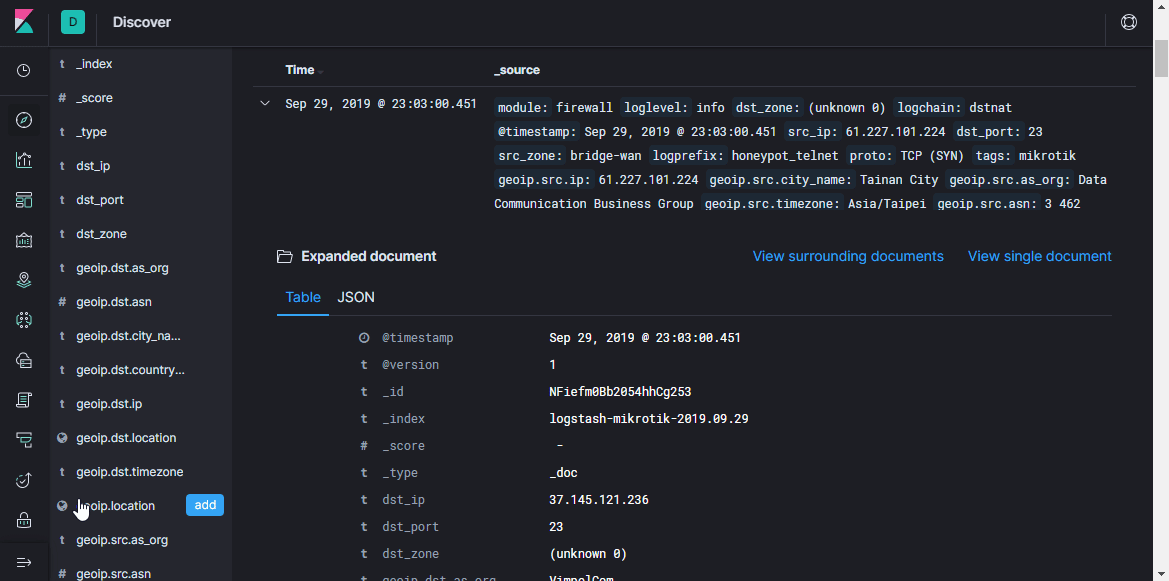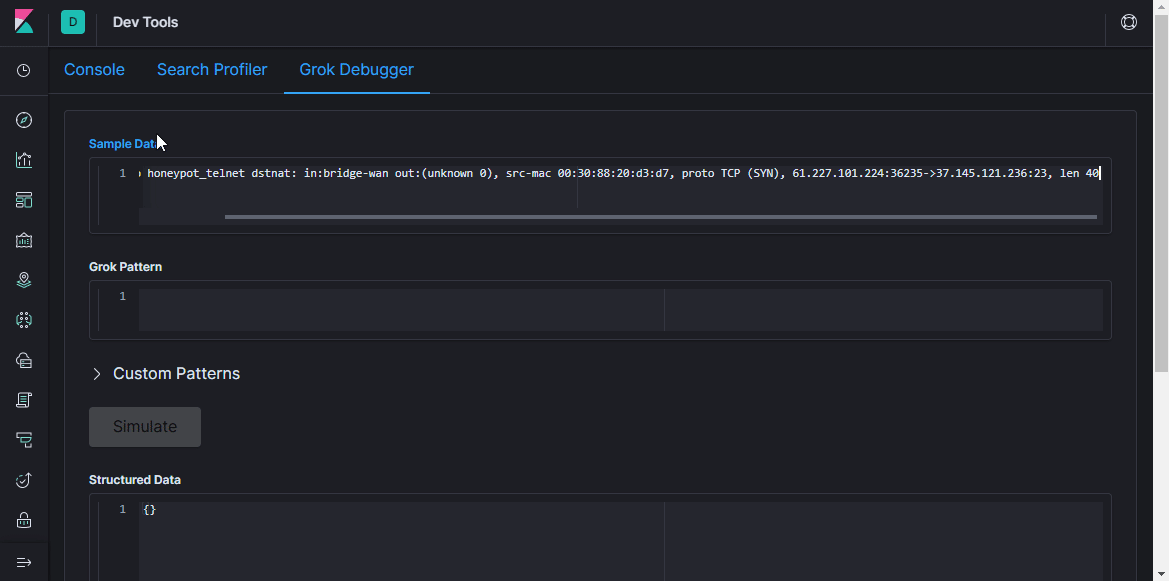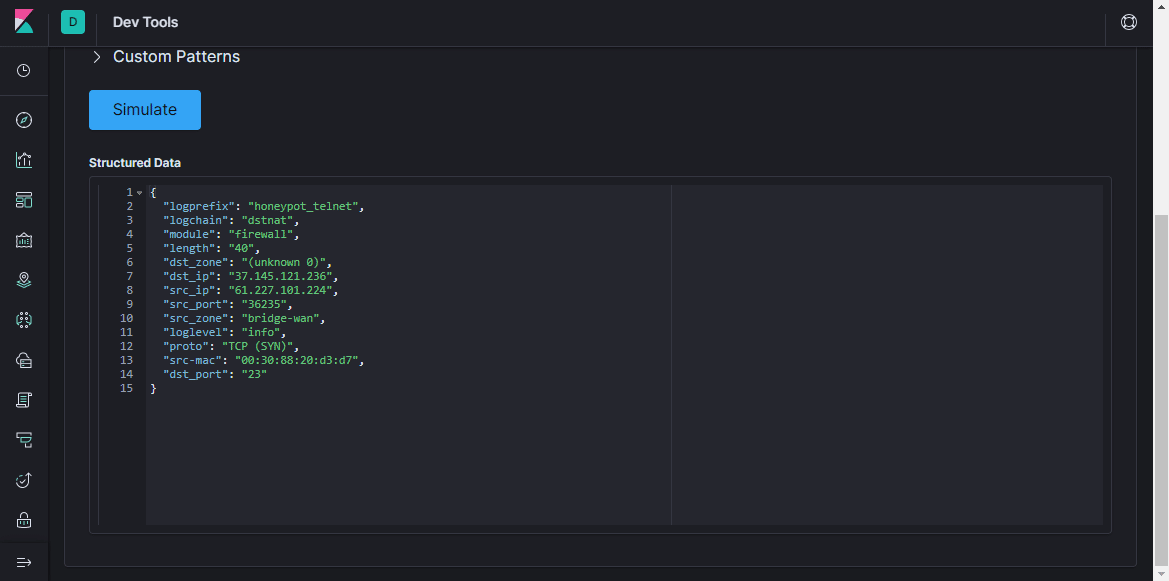
Здесь можно просматривать документы в индексах, фильтровать, искать и смотреть полученную информацию. Важно не забывать про шкалу времени, которая задаёт временные рамки в условиях поиска.
В этом разделе можно строить визуализацию на основе собранных данных. Самое простое — это отобразить источники сканирующих ботнетов на географической карте, точечно или в виде heatmap. Так же доступно множество способов построить графики, сделать выборки и т.д.
В дальнейшем я планирую рассказать подробнее про обработку данных, возможно визуализацию, может что-то ещё интересное. В процессе изучения буду стараться дополнять туториал.
В случае, если в Elasticsearch индекс не появляется, нужно в первую очередь смотреть логи Logstash:
Logstash не будет работать, если нет связности с Elasticsearch, или ошибка в конфигурации пайплайна — это основные причины и о них становится ясно после внимательного изучения логов, которые по умолчанию пишутся в json докером.
Если ошибок в логе нет, нужно убедиться, что Logstash ловит сообщения на своём настроенном сокете. Для целей дебага можно использовать stdout в качестве output:
После этого Logstash будет писать дебаг информацию при полученном сообщении прямо в лог.
Проверить Elasticsearch очень просто — достаточно сделать GET запрос curl`ом на IP-адрес и порт сервера, либо на определённый API endpoint. Например посмотреть состояние индексов в человекочитаемой таблице:
Kibana тоже не запустится, если не будет коннекта до Elasticsearch, увидеть это легко по логам.
Если веб-интерфейс не открывается, то стоит убедиться, что в Linux правильно настроен или отключён firewall (в Centos были проблемы с iptables и docker, решились по советам из топика). Также стоит учитывать, что на не очень производительном оборудовании все компоненты могут загружаться несколько минут. При нехватке помяти сервисы вообще могут не загрузиться. Посмотреть использование ресурсов контейнерами:
Если вдруг кто-то не знает, как корректно изменить конфигурацию контейнеров в файле docker-compose.yml и перезапустить контейнеры, это делается редактированием docker-compose.yml и с помощью той же команды с тем же параметрами перезапускается:
При этом в изменённых секциях старые объекты (контейнеры, сети, волюмы) стираются и пересоздаются новые согласно конфигу. Данные сервисов при этом не теряются, так как используется named volumes, которые не удаляются с контейнером, а конфиги монтируются с хостовой системы, Logstash так умеет даже мониторить файлы конфигов и перезапускать пайплайн конфигурацию при изменении в файле.
Перезапустить сервис отдельно можно командой docker restart (при этом не обязательно находиться в директории с docker-compose.yml):
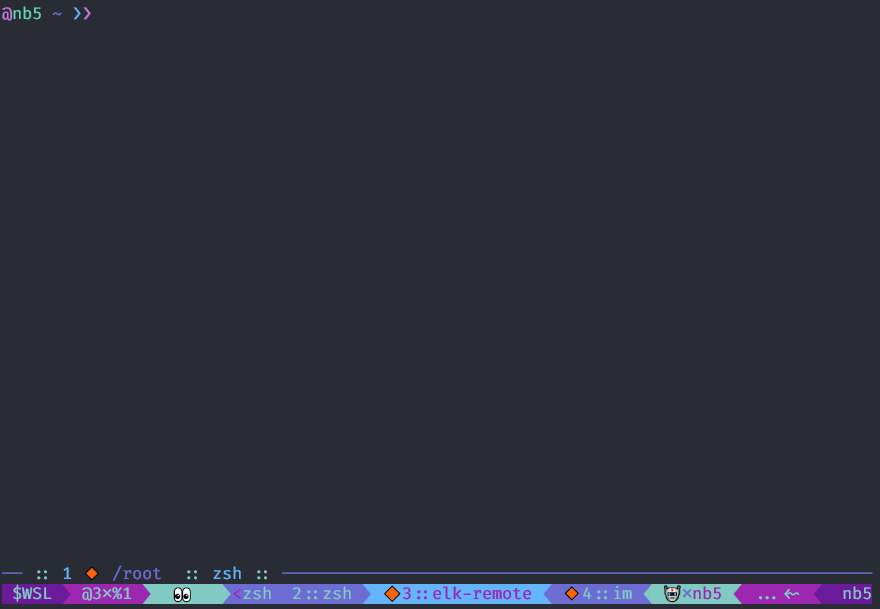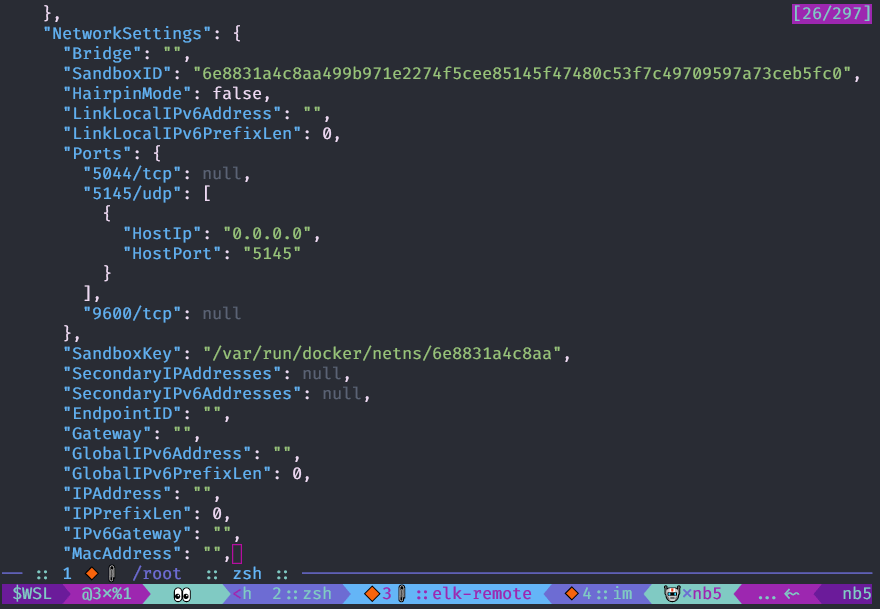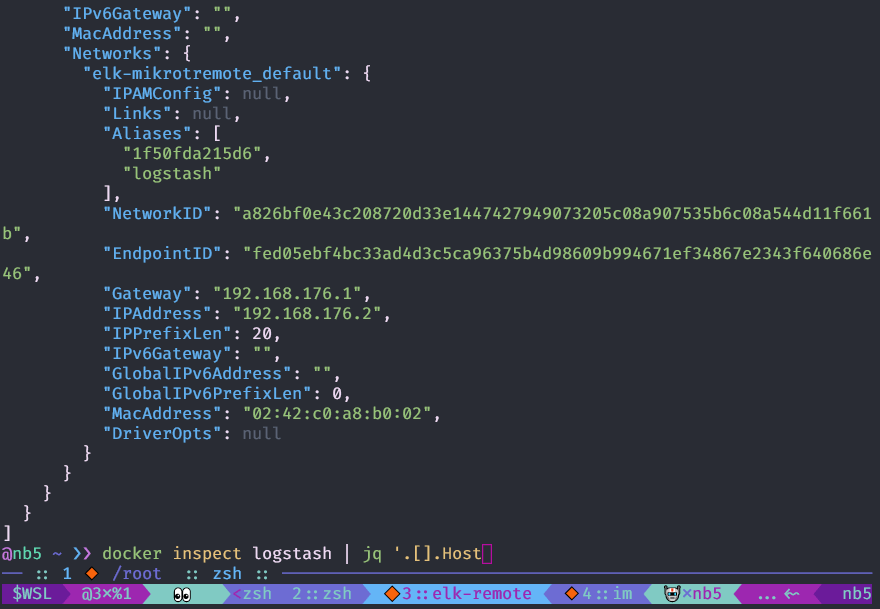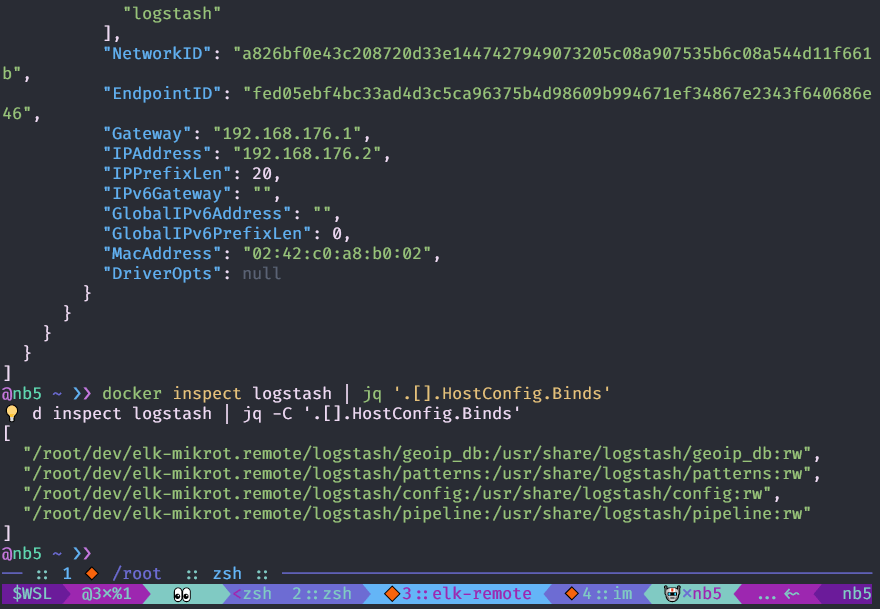
Посмотреть конфигурацию объекта докер можно командой docker inspect, совместно с jq использовать удобнее.
Хочу отметить, что security в этом проекте не доложено потому, что это тестовое (dev) окружение и не планируется выпуск наружу за пределы роутера. Если разворачивать для более серьёзного использования, то нужно следовать best practice, устанавливать сертификаты для HTTPS, делать резервирование, нормальный мониторинг (который запускается не рядом с основной системой). К слову, на моём сервере работает Traefik в докере, который является обратным прокси для некоторых сервисов, а так же терминирует TLS на себя и делает аутентификацию. То есть, благодаря настроенному DNS и reverse proxy, появляется возможность из интернета зайти в веб-интерфейс Kibana с ненастроенным HTTPS и паролем (насколько я понял, в комьюнити версии Kibana не поддерживает парольную защиту веб-интерфейса). Планирую в дальнейшем описать свой опыт настройки Traefik для использования в домашней сети с Docker.
Если у вас есть публичный IP-адрес и более-менее умное устройство в качестве шлюза/файрволла, вы можете организовать пассивный honeypot, настроив логирование входящих запросов на «вкусные» TCP и UDP порты. Под катом пример настройки маршрутизатора Mikrotik, но если у вас под рукой маршрутизатор другого вендора (или какая-то ещё security система), нужно просто немного разобраться с форматами данных и вендоро-специфичными настройками, и получится тот же результат.
Disclaimer
Статья не претендует на оригинальность, здесь не рассматриваются вопросы отказоустойчивости сервисов, безопасности, лучших практик и т.д. Нужно рассматривать этот материал как академический, он подходит для ознакомления с базовым функционалом стека ELK и механизмом анализа логов сетевого устройства. Однако и не новичку может быть что-то интересно.
Проект запускается из docker-compose файла, соответственно развернуть своё подобное окружение очень просто, даже если у вас под рукой маршрутизатор другого вендора, нужно просто немного разобраться с форматами данных и вендоро-специфичными настройками. В остальном я постарался максимально подробно описать все нюансы, связанные с конфигурированием Logstash pipelines и Elasticsearch mappings в актуальной версии ELK. Все компоненты этой системы хостятся на github, в том числе конфиги сервисов. В конце статьи я сделаю раздел Troubleshooting, в котором будут описаны шаги по диагностике популярных проблем новичков в этом деле.
Введение
На самом сервере у меня установлена система виртуализации Proxmox, на ней в KVM машине запускаются Docker контейнеры. Предполагается, что вы знаете, как работает docker и docker-compose, благо примеров настройки о использования в интернете достаточно. Я не буду касаться вопросов установки Docker, про docker-compose немного напишу.
Идея запустить honeypot возникла в процессе изучения Elasticsearch, Logstash и Kibana. В профессиональной деятельности я никогда не занимался администрированием и вообще использованием этого стека, но у меня есть хобби проекты, благодаря которым сложился большой интерес изучить возможности, которые даёт поисковый движок Elasticsearch и Kibana, с помощью которых можно анализировать и визуализировать данные.
Моего не самого нового мини сервера NUC с 8GB RAM как раз хватает для запуска ELK стека с одной нодой Elastic. В продакшн окружениях так делать, конечно, не рекомендуется, но для обучения в самый раз. По поводу вопроса безопасности в конце статьи есть ремарка.
В интернете полно инструкций по установке и конфигурированию ELK стека для схожих задач (например, анализ brute force атак на ssh с помощью Logstash версии 2, анализ логов Suricata с помощью Filebeat версии 6), однако в большинстве случаев не уделяется должного внимания деталям, к тому же 90 процентов материала будет для версий от 1 до 6 (на момент написания статьи актуальная версия ELK 7.5.0). Это важно, потому что с 6 версии Elasticsearch решили убрать сущность mapping type, тем самым синтаксис запросов и структура мапингов изменились. Mapping template в Elastic вообще очень важный объект, и чтобы потом не было проблем с выборкой и визуализацией данных, советую не увлекаться копипастой и стараться понимать, что делаете. Дальше я постараюсь понятно объяснять, что значат описываемые операции и конфиги.
Настройка роутера
Для домашней сети в качестве маршрутизатора я использую Mikrotik, так что пример будет для него. Но на отправку syslog на удалённый сервер можно настроить почти любую систему, будь то маршрутизатор, сервер или ещё какая-то security система, которая умеет логировать.
Отправка syslog сообщений на удалённый сервер
В Mikrotik для настройки логирования на удалённый сервер через CLI достаточно ввести пару команд:
/system logging action add remote=192.168.88.130 remote-port=5145 src-address=192.168.88.1 name=logstash target=remote
/system logging add action=logstash topics=infoНастройка правил firewall с логированием
Нас интересуют только определённые данные (hostname, ip-adress, username, url etc.), из которых можно получить красивую визуализацию или выборку. В самом простом случае, чтобы получить информацию о сканировании портов и попытке доступа, нужно настроить компонент firewall на логирование срабатываний правила. Я на Mikrotik настроил правила в таблице NAT, а не Filter, так как в дальнейшем собираюсь поставить ханипоты, которые будут эмулировать работу сервисов, это позволит исследовать больше информации о поведении ботнетов, но это уже более продвинутый сценарий и о нём не в этот раз.
Внимание! В конфигурации ниже стандартный TCP порт сервиса SSH (22) натится в локальную сеть. Если вы используете SSH для доступа к роутеру извне и в настройках стоит порт 22 (ip service print в CLI и ip > services в Winbox), стоит переназначить порт для management SSH, либо не вводить последнее правило в таблице.
Так же, в зависимости от названия WAN-интерфейса (если не используется WAN bridge), нужно поменять параметр in-interface на соответствующий.
/ip firewall nat
add action=netmap chain=dstnat comment="HONEYPOT RDP" dst-port=3389 in-interface=bridge-wan log=yes log-prefix=honeypot_rdp protocol=tcp to-addresses=192.168.88.201 to-ports=3389
add action=netmap chain=dstnat comment="HONEYPOT ELASTIC" dst-port=9200 in-interface=bridge-wan log=yes log-prefix=honeypot_elastic protocol=tcp to-addresses=192.168.88.201 to-ports=9211
add action=netmap chain=dstnat comment=" HONEYPOT TELNET" dst-port=23 in-interface=bridge-wan log=yes log-prefix=honeypot_telnet protocol=tcp to-addresses=192.168.88.201 to-ports=2325
add action=netmap chain=dstnat comment="HONEYPOT DNS" dst-port=53 in-interface=bridge-wan log=yes log-prefix=honeypot_dns protocol=udp to-addresses=192.168.88.201 to-ports=9953
add action=netmap chain=dstnat comment="HONEYPOT FTP" dst-port=21 in-interface=bridge-wan log=yes log-prefix=honeypot_ftp protocol=tcp to-addresses=192.168.88.201 to-ports=9921
add action=netmap chain=dstnat comment="HONEYPOT SMTP" dst-port=25 in-interface=bridge-wan log=yes log-prefix=honeypot_smtp protocol=tcp to-addresses=192.168.88.201 to-ports=9925
add action=netmap chain=dstnat comment="HONEYPOT SMB" dst-port=445 in-interface=bridge-wan log=yes log-prefix=honeypot_smb protocol=tcp to-addresses=192.168.88.201 to-ports=9445
add action=netmap chain=dstnat comment="HONEYPOT MQTT" dst-port=1883 in-interface=bridge-wan log=yes log-prefix=honeypot_mqtt protocol=tcp to-addresses=192.168.88.201 to-ports=9883
add action=netmap chain=dstnat comment="HONEYPOT SIP" dst-port=5060 in-interface=bridge-wan log=yes log-prefix=honeypot_sip protocol=tcp to-addresses=192.168.88.201 to-ports=9060
add action=dst-nat chain=dstnat comment="HONEYPOT SSH" dst-port=22 in-interface=bridge-wan log=yes log-prefix=honeypot_ssh protocol=tcp to-addresses=192.168.88.201 to-ports=9922В Winbox то же самое настраивается в разделе IP > Firewall > вкладка NAT.
Теперь роутер будет перенаправлять полученные пакеты на локальный адрес 192.168.88.201 и кастомный порт. Сейчас пока что никто не слушает на этих портах, так что коннекты будут обрываться. В дальнейшем в докере можно запустит honeypot, коих множество под каждый сервис. Если этого делать не планируется, то вместо правил NAT следует прописать правило с действием drop в цепочке Filter.
Запуск ELK с помощью docker-compose
Дальше можно приступать к настройке компонента, который будет заниматься процессингом логов. Cоветую сразу заняться практикой и склонировать репозиторий, чтобы видеть конфигурационные файлы полностью. Все описываемые конфиги можно увидеть там, в тексте статьи я буду копировать только часть конфигов.
?? git clone https://github.com/mekhanme/elk-mikrot.gitВ тестовом или dev окружении удобнее всего запускать docker контейнеры c помощью docker-compose. В этом проекте я использую docker-compose файл последней на данный момент версии 3.7, он требует docker engine версии 18.06.0+, так что не лишним обновить docker, а так же docker-compose.
?? curl -L "https://github.com/docker/compose/releases/download/1.25.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
?? chmod +x /usr/local/bin/docker-composeТак как в последних версиях docker-compose выпилили параметр mem_limit и добавили deploy, запускающийся только в swarm mode (docker stack deploy), то запуск docker-compose up конфигурации с лимитами приводит к ошибке. Так как я не использую swarm, а лимиты ресурсов иметь хочется, запускать приходится с опцией --compatibility, которая конвертирует лимиты из docker-compose новых версий в нон-сварм эквивалент.
Пробный запуск всех контейнеров (в фоновом режиме -d):
?? docker-compose --compatibility up -dПридётся подождать, пока скачаются все образы, и после того как запуск завершится, проверить статус контейнеров можно командой:
?? docker-compose --compatibility psБлагодаря тому, что все контейнеры будут в одной сети (если явно не указывать сеть, то создаётся новый бридж, что подходит в этом сценарии) и в docker-compose.yml у всех контейнеров прописан параметр container_name, между контейнерами уже будет связность через встроенный DNS докера. Вследствие чего не требуется прописывать IP-адреса в конфигах контейнеров. В конфиге Logstash прописана подсеть 192.168.88.0/24 как локальная, дальше по конфигурации будут более подробные пояснения, по которым можно оттюнить пример конфига перед запуском.
Настройка сервисов ELK
Дальше будут пояснения по настройке функционала компонентов ELK, а также ещё некоторые действия, которые нужно будет произвести над Elasticsearch.
Для определения географических координат по IP-адресу потребуется скачать free базу GeoLite2 от MaxMind:
?? cd elk-mikrot && mkdir logstash/geoip_db
?? curl -O https://geolite.maxmind.com/download/geoip/database/GeoLite2-City-CSV.zip && unzip GeoLite2-City-CSV.zip -d logstash/geoip_db && rm -f GeoLite2-City-CSV.zip
?? curl -O https://geolite.maxmind.com/download/geoip/database/GeoLite2-ASN-CSV.zip && unzip GeoLite2-ASN-CSV.zip -d logstash/geoip_db && rm -f GeoLite2-ASN-CSV.zipНастройка Logstash
Основным файлом конфигурации является logstash.yml, там я прописал опцию автоматического релоада конфигурации, остальные настройки для тестового окружения не значительные. Конфигурация самой обработки данных (логов) в Logstash описывается в отдельных conf файлах, обычно хранящихся в директории pipeline. При схеме, когда используются multiple pipelines, файл pipelines.yml описывает активированные пайплайны. Пайплайн — это цепочка действий над неструктурированными данными, чтобы на выходе получить данные с определённой структурой. Схема с отдельно настроенным pipelines.yml не обязательная, можно обойтись и без него, загружая все конфиги из примонтированной директории pipeline, однако с определённым файлом pipelines.yml настройка получается более гибкая, так как можно не удаляя conf файлы из директории pipeline, включать и выключать необходимые конфиги. К тому же перезагрузка конфигов работает только в схеме multiple pipelines.
?? cat logstash/config/pipelines.yml
- pipeline.id: logstash-mikrot
path.config: "pipeline/logstash-mikrot.conf"Дальше идёт самая важная часть конфига Logstash. Описание pipeline состоит из нескольких секций — в начале в секции Input указываются плагины, с помощью которых Logstash получает данные. Наиболее простой способ собирать syslog с сетевого устройства — использовать input плагины tcp/udp. Единственный обязательный параметр этих плагинов — это port, его нужно указать таким же, как и в настройках роутера.
Второй секцией идёт Filter, в которой прописываются дальнейшие действия с пока ещё не структурированными данными. В моём примере удаляются лишние syslog сообщения от роутера с определённым текстом. Делается это с помощью условия и стандартного действия drop, которое отбрасывает всё сообщение, если условие удовлетворяется. В условии проверяется поле message на наличие определённого текста.
Если сообщение не дропнулось, оно идёт дальше по цепочке и попадает в фильтр grok. Как написано в документации, grok is a great way to parse unstructured log data into something structured and queryable. Этот фильтр применяют для обработки логов различных систем (linux syslog, веб-сервера, БД, сетевые устройства и т.д.). На основе готовых паттернов можно, не тратя много времени, составить парсер для любой более-менее повторяющейся последовательности. Для валидации удобно использовать онлайн парсер (в последней версии Kibana аналогичный функционал есть в разделе Dev Tools).
В docker-compose.yml прописан volume "./logstash/patterns:/usr/share/logstash/patterns", в директории patterns лежит файл со стандартными community-паттернами (просто для удобства, посмотреть если забыл), а так же файл с паттернами нескольких типов сообщений Mikrotik (модули Firewall и Auth), по аналогии можно дополнить своими шаблонами для сообщений другой структуры.
Стандартные опции add_field и remove_field позволяют внутри любого фильтра добавить или удалить поля из обрабатываемого сообщения. В данном случае удаляется поле host, которое содержит имя хоста, с которого было получено сообщение. В моём примере хост всего один, так что смысла в этом поле нет.
Дальше всё в той же секции Filter я прописал фильтр cidr, который проверяет поле с IP-адресом на соответствие условию вхождения в заданную подсеть и ставит тег. На основе тега в дальнейшей цепочке будут производиться или не производиться действия (если конкретно, то это для того, чтобы в дальнейшем не делать geoip lookup для локальных адресов).
Секций Filter может быть сколько угодно, и, чтобы было меньше условий внутри одной секции, в новой секции я определил действия для сообщений без тега src_local, то есть тут обрабатываются события файрволла, в которых нам интересен именно адрес источника.
Теперь надо немного подробнее рассказать про то, откуда Logstash берёт GeoIP информацию. Logstash поддерживает базы GeoLite2. Есть несколько вариантов баз, я использую две базы: GeoLite2 City (в которой есть информация о стране, городе, часовом поясе) и GeoLite2 ASN (информация об автономной системе, к которой принадлежит IP-адрес).
Плагин geoip и занимается добавлением GeoIP информации в сообщение. Из параметров надо указать поле, в котором содержится IP-адрес, используемую базу, и название нового поля, в которое будет прописана информация. У меня в примере тоже самое делается и для destination IP-адреса, но пока что в этом простом сценарии эта информация будет неинтересна, так как адрес назначения всегда будет являться адресом роутера. Однако в дальнейшем в этот пайплайн можно будет добавить логи не только с файрволла, но и с других систем, где актуально будет смотреть на оба адреса.
Фильтр mutate позволяет изменять поля сообщения и модифицировать сам текст в полях, в документации подробно написано много примеров того, что можно делать. В данном случае используется для добавления тега, переименования полей (для дальнейшей визуализации логов в Kibana требуется определённый формат объекта geo-point, дальше я ещё коснусь этой темы) и удаления ненужных полей.
На этом секция обработки данных заканчивается и остаётся только обозначить, куда слать структурированное сообщение. В данном случае сбором данных будет заниматься Elasticsearch, нужно только ввести IP-адрес, порт и название индекса. Индекс рекомендуется вводить с variable полем даты, чтобы каждый день создавался новый индекс.
Настройка Elasticsearch
Возвращаемся к Elasticsearch. Для начала надо удостовериться, что сервер запущен и функционирует. С Elastic эффективнее всего взаимодействовать через Rest API в CLI. С помощью curl можно посмотреть состояние ноды (localhost заменить на ip-адрес докер хоста):
?? curl localhost:9200Дальше можно пробовать открыть Kibana по адресу localhost:5601. В веб-интерфейсе Kibana настраивать ничего нет необходимости (разве что поменять тему на тёмную). Нам интересно посмотреть, создался ли индекс, для этого нужно открыть раздел Management и слева вверху выбрать Elasticsearch Index Management. Здесь можно посмотреть, сколько документов заиндексировано, сколько это занимает места на диске, так же из полезного можно посмотреть информацию по мапингу индекса.
Как раз дальше нужно прописать правильный mapping template. Эта информация Elastic нужна для того, чтобы он понимал, к каким типам данных какие поля относить. Например, чтобы делать специальные выборки на основе IP-адресов, для поля src_ip нужно явно указать тип данных ip, а для определения географического положения нужно определить поле geoip.location в определённом формате и прописать тип geo_point. Все возможные поля описывать не надо, так как для новых полей тип данных определяется автоматически на основе динамических шаблонов (long для чисел и keyword для строк).
Записать новый template можно или с помощью curl, или прямо из консоли Kibana (раздел Dev Tools).
?? curl -X POST -H "Content-Type: application/json" -d @elasticsearch/logstash_mikrot-template.json http://192.168.88.130:9200/_template/logstash-mikrotПосле изменения мапинга нужно удалить индекс:
?? curl -X DELETE http://192.168.88.130:9200/logstash-mikrot-2019.12.16Когда прилетит хотя бы одно сообщение в индекс, проверить мапинг:
?? curl http://192.168.88.130:9200/logstash-mikrot-2019.12.16/_mappingДля дальнейшего использования данных в Kibana, нужно в разделе Management > Kibana Index Patternсоздать pattern . Index name ввести с символом * (logstash-mikrot*), чтобы матчились все индексы, выбрать поле timestamp в качестве поля с датой и временем. В поле Custom index pattern ID можно ввести ID паттерна (например, logstash-mikrot), в дальнейшем это может упростить обращения к объекту.
Анализ и визуализация данных в Kibana
После того, как создали index pattern, можно приступать к самому интересному — анализу и визуализации данных. В Kibana есть множество функционала и разделов, но нам пока что будут интересны только два.
Discover
Здесь можно просматривать документы в индексах, фильтровать, искать и смотреть полученную информацию. Важно не забывать про шкалу времени, которая задаёт временные рамки в условиях поиска.
Visualize
В этом разделе можно строить визуализацию на основе собранных данных. Самое простое — это отобразить источники сканирующих ботнетов на географической карте, точечно или в виде heatmap. Так же доступно множество способов построить графики, сделать выборки и т.д.
В дальнейшем я планирую рассказать подробнее про обработку данных, возможно визуализацию, может что-то ещё интересное. В процессе изучения буду стараться дополнять туториал.
Troubleshooting
В случае, если в Elasticsearch индекс не появляется, нужно в первую очередь смотреть логи Logstash:
?? docker logs logstash --tail 100 -fLogstash не будет работать, если нет связности с Elasticsearch, или ошибка в конфигурации пайплайна — это основные причины и о них становится ясно после внимательного изучения логов, которые по умолчанию пишутся в json докером.
Если ошибок в логе нет, нужно убедиться, что Logstash ловит сообщения на своём настроенном сокете. Для целей дебага можно использовать stdout в качестве output:
stdout { codec => rubydebug }После этого Logstash будет писать дебаг информацию при полученном сообщении прямо в лог.
Проверить Elasticsearch очень просто — достаточно сделать GET запрос curl`ом на IP-адрес и порт сервера, либо на определённый API endpoint. Например посмотреть состояние индексов в человекочитаемой таблице:
?? curl -s 'http://192.168.88.130:9200/_cat/indices?v'Kibana тоже не запустится, если не будет коннекта до Elasticsearch, увидеть это легко по логам.
Если веб-интерфейс не открывается, то стоит убедиться, что в Linux правильно настроен или отключён firewall (в Centos были проблемы с iptables и docker, решились по советам из топика). Также стоит учитывать, что на не очень производительном оборудовании все компоненты могут загружаться несколько минут. При нехватке помяти сервисы вообще могут не загрузиться. Посмотреть использование ресурсов контейнерами:
?? docker statsЕсли вдруг кто-то не знает, как корректно изменить конфигурацию контейнеров в файле docker-compose.yml и перезапустить контейнеры, это делается редактированием docker-compose.yml и с помощью той же команды с тем же параметрами перезапускается:
?? docker-compose --compatibility up -dПри этом в изменённых секциях старые объекты (контейнеры, сети, волюмы) стираются и пересоздаются новые согласно конфигу. Данные сервисов при этом не теряются, так как используется named volumes, которые не удаляются с контейнером, а конфиги монтируются с хостовой системы, Logstash так умеет даже мониторить файлы конфигов и перезапускать пайплайн конфигурацию при изменении в файле.
Перезапустить сервис отдельно можно командой docker restart (при этом не обязательно находиться в директории с docker-compose.yml):
?? docker restart logstashПосмотреть конфигурацию объекта докер можно командой docker inspect, совместно с jq использовать удобнее.
Заключение
Хочу отметить, что security в этом проекте не доложено потому, что это тестовое (dev) окружение и не планируется выпуск наружу за пределы роутера. Если разворачивать для более серьёзного использования, то нужно следовать best practice, устанавливать сертификаты для HTTPS, делать резервирование, нормальный мониторинг (который запускается не рядом с основной системой). К слову, на моём сервере работает Traefik в докере, который является обратным прокси для некоторых сервисов, а так же терминирует TLS на себя и делает аутентификацию. То есть, благодаря настроенному DNS и reverse proxy, появляется возможность из интернета зайти в веб-интерфейс Kibana с ненастроенным HTTPS и паролем (насколько я понял, в комьюнити версии Kibana не поддерживает парольную защиту веб-интерфейса). Планирую в дальнейшем описать свой опыт настройки Traefik для использования в домашней сети с Docker.
theLastOfCats
Что за тема в редакторе?
mekhan Автор
Это тема Shades of Purple, но с немного кастомизироваными цветами.
"workbench.colorCustomizations": {"[Shades of Purple]": {
"activityBar.activeBorder": "#fa00e5",
"activityBar.foreground": "#fa00e5",
"editor.selectionHighlightBorder": "#cc42aa",
// "editor.lineHighlightBorder": "#cc42aa",
"editor.lineHighlightBackground": "#b242e680",
"list.activeSelectionForeground": "#cc42aa",
"editorSuggestWidget.highlightForeground": "#cc42aa",
"editorSuggestWidget.foreground": "#ddaad0",
"menu.selectionForeground": "#cc42aa",
"statusBar.background": "#7e01a7",
"peekViewResult.selectionForeground": "#cc42aa",
"breadcrumb.focusForeground": "#cc42aa",
"dropdown.foreground": "#ddaad0",
"badge.foreground": "#cc42aa",
"editorHint.foreground": "#fa00bb",
"editorLineNumber.activeForeground": "#fa00bb",
"list.focusForeground": "#fa00e5",
"tab.activeForeground": "#b974e0",
"breadcrumb.activeSelectionForeground": "#cc42aa",
"breadcrumb.foreground": "#ddaad0",
"contrastActiveBorder": "#cc42aa",
"focusBorder": "#cc42aa",
// "foreground": "#fa00bb",
"widget.shadow": "#cc42aa",
// "contrastBorder": "#fa00bb"
}
}
gecube
Поставил плюс, ну, потому что круто же!
Какие планы дальше? Netflow?
Но все равно не отпускает вопрос — а не похоже ли это на стрельбу по воробьям? Когда для мониторинга одной маленькой маломощной железки собирается железный кластер о трёх серверах?
Дополнение. Это не новая версия компоуза, а есть два параллельных формата — 2+2.x и 3.x. Первый — с лимитами и прочими полезными ништяками, второй — для сворма. Т.к. сворм не используете, то имеет смысл переключиться на 2.4.
плохая история. При ребуте сервера порядок запуска сервисов (докер контейнеров) будет произвольный. Оборачивать docker-compose в systemd unit — фу-фу-фу. Лучше уж тогда: перейти на отдельные systemd юниты для сервисов, деплоить ансиблом. Но здесь важно от того насколько это MVP/PoC.
И еще. Приложенный компоуз не заведется, т.к. на хосте с эластиком надо sysctl из раздела vm подпраивть.
mekhan Автор
Спасибо за замечания. По поводу «стрельбы по воробьям» — это делалось как простой PoC на выходных в свободное от работы время, чтобы разобраться с некоторыми технологиями, использовать такую схему никому не предлагаю :) то есть, это чисто для демонстрации тонких моментов сбора и визуализации данных.
Ну это же не мониторинг, роутер используется чисто как приманка для автоматических сканеров портов и ботнетов с той стороны интеренетов. С таким же успехов можно взять дешёвый VPS и там развернуть syslog + logstash, например. О каких железных кластерах идёт речь, не понял. У меня все сервисы запускаются на одном домашнем сервере (на самом деле, Elastic и Kibana я потом запустил на другом более мощном сервере и прокинул порты через SSH).
Всё верно, две ветки параллельно развивающиеся ветки, я немного неправильно передал смысл. Но я уже привык было к спецификациям версии 3.х (в других многочисленных docker-compose.yml), а в этом проекте понадобилось залимитировать ресурсы, так как запускать ELK без лимитов на низкопроизводительном железе чревато (у меня сервер иногда вис намертво). Оказалось, что в версии 3.х можно использовать с лимитами ресурсов и без swarm с этим ключом --compatibility.
А как правильно сделать, чтобы у сервиса оставалась зависимость от другого сервиса и всё работало нормально? Я где-то видел рекомендации на этот счёт, но как-то не вникал в суть, всё-таки это не продакшен и если что-то не так, что вручную можно разрулить проблему с незапустившимся сервером.
Ну так тут про systemd юниты речь не идёт, я не сторонник такого. А про автоматический деплой такой лабы ансиблом вообще тоже думал, было бы интересно реализовать.
Возможно, на чистой системе нужно будет что-то сделать дополнительно на уровне OS, я не проверял весь сценарий на свежеразвёрнутом докер-хосте, а на своих двух серверах это сделал давно. В любом случае, это немного выходит за скоп тех знаний, что я хотел донести до сообщества :) хотя добавить в статью не сложно, сейчас сделаю.
Если будет не лень, то когда-нибудь в следующем году добавлю сбор Netflow (или sflow), для этого нужно найти интересный участок сети, домашняя локалка уже не так интересна для этого. Либо можно добавить access логи реверс-прокси, чтобы видеть, в какие url долбятся боты, это тоже забавно. И совсем не сложно сделать по аналогии.
gecube
Здесь скорее проблема в повторяемости результата. Мы же все сталкивались с ситуацией, что берешь какой-то гайд с интернета, начинаешь по нему идти, а потом что-то не получится. И бросаешь такой расстроенный. Или убиваешь кучу времени на решение несущественной проблемы, т.к. реально дело в одной опции, но тебе нужно разобраться во всех зависимостях, хитросплетениях системы
Обернуть конкретные контейнеры в системди юниты и между ними наладить связи?
Интересно, спасибо
Я имел в виду две вещи. И то что эластик очень ресурсоемок (джава как никак), так и то, что маленький микротик может генерить логов столько, что для их разбора понадобится существенно больше вычислительных ресурсов.
Vld_Sergio
Микротиков в хозяйстве может быть несколько сотен, например. Топовые клауд-роутеры вполне себе производительные. Зато благодаря контейнеризации это можно всё масштабировать.
gecube
Это все истерия с контейнеризацией. Не все нужно туда всовывать по разным причинам. И тот же КХ и эластик масштабируются сами по себе нормально. Без контейнеров. Я уж не говорю о том, что джава — сама по себе контейнер в некотором смысле.
Т.е. — если надо масштабировать горизонтально КХ/эластик — проще нарезать виртуальных машин. Или железных серверов доставить. Чем играть с контейнерами. Я уж не говорю о том, что оба продукта не любят делить вычислительный узел с какой-либо ещё нагрузкой. Иначе можно ловить весьма странные спецэффекты
Если речь про тестовый стенд — ну, да, тут контейнеры могут помочь его собрать из готовых компонентов максимально быстро. Но надо же отделять "демо" и "промышленную" эксплуатацию
iddqda
поддержу.
пару лет назад игрался в разворачивание нескольких шард эластика плюс конечно же логстеш и кибана в докере и все внутри одного хоста.
И что-то вся эта фигня очень долго взлетала и через несколько часов стабильно падала. Правда данных было действительно много. принимал логи разные + netflow с ядра немаленькой ентерпрайз сети. Но как прототип эта конструкция вполне себя оправдала.
iwram
В свое время тоже использовали logstash. Но сейчас переходим на fluentd. Более легковесный, использует немного ресурсов, настраивается легко и есть встроенные парсеры по syslog.
Конкретно по особенностям реализации в микротик, надо поставить «галку» «BSD Syslog» и логи будут приходить в читаемом виде, вместо Src.Address по итогу в поле hosts будет приходить «Identity name» — что особенно полезно в случае роутеров, которые находятся за 2-3 натом и нет впн.
mekhan Автор
Полезное замечание для тех, кто собирает логи в продакшене. Я использовал logstash только лишь из-за того, что это популярный продукт, с понятным мануалом и конфигом, и есть уже готовые шаблоны, в том числе для того формата, который стоит в Микротике по умолчанию. Так-то ест он много, я тоже думаю попробовать перейти на fluentd, хотя у меня нагрузки особо нет и запускаю такое время от времени.
GhOsT_MZ
А что стало причиной перехода? Logstash перестал переваривать поток логов? Или конфигурация разрослась и стало крайне неудобно?
gecube
ну, мне лично вообще из елка импонирует только сам эластик, а вся обвязка их… Ну, такое себе. Да, это цельная экосистема, да — можно получить поддержку от эластика (только вот исторически в РФ за нее никто не платит). Но вот fluentd в фонде CNCF, что напрямую не является преимуществом. Но говорит о том, что вендор-лока никакого не будет.
GhOsT_MZ
Интересное мнение. У нас немного другой опыт. Из всей связки мы используем только Logstash. ES выкинули на помойку по ряду причин. Во-первых, он таки тяжелый. Во-вторых, он не очень хорошо переживает «катастрофы» в виде отключения питания. Да, понимаю, тут сказывается небольшой опыт работы с ним. Но, если он исключительно для логов, далеко не все будут для этой цели искать нормального специалиста или глубоко изучать это решение. И третье — скорость работы. И последнее, документоориентированные СУБД позволяют вольности в виде содержимого документов, а это может превратить данные в помойку.
Собственно, на данный момент в роли хранилища логов используем ClickHouse. Из плюсов, достаточно быстрый, особенно на фоне ES (для сравнение, ClickHouse на аналогично наборе данных отдает ответ за 300мс против 1,5 сек у ES). Также, он не позволяет вольностей в виде содержимого записей, и как итог — предсказуемое наполнение базы.
А вот Logstash пока импонирует, вероятно потому что событий у нас не так много, порядка 150 событий/сек.
gecube
Касательно КХ — мне не очень понравилась их реализация шардинга-репликации.
По Эластику — у них раньше действительно была проблема с целостностью данных, но КХ тоже не про это ) если подумать.
В принципе, мне кажется, что КХ для логов — это не самый плохой и допустимый вариант.
gecube
уточню — fluentd или fluent-bit? Второй тоже неплохой и ЕЩЕ БОЛЕЕ ЛЕГКОВЕСЕН.
iwram
td-agent (fluentd). Как писал выше, с logstash в качестве hosts выступает src address, если хочется менять имя, то надо менять в грок, откуда пришло-менять имя и перенаправлять. Но ведь хочется один конфиг и чтобы все автоматом.
также по другим логам, раскидываешь в свои индексы меняя match и store.
По fluent-bit посмотрю, слышал но не тестил.
P.S. По домашним замерам от работы fluentd и logstash — также есть видимая разница по нагрузке процессора и потреблению электричества. Хотел написать отдельно статью по часто используемому софту с сопоставимой нагрузкой, касательно энергопотребления.
mekhan Автор
Было бы очень интересно почитать про энергопотребление, так как мне как раз актуально для таких хобби-проектов запускать софт на домашнем мини-сервере. И в планах купить ещё пару серверов, собрать кластер. Интресно, на сколько энергопотребление различается при использовании разных софтовых продуктов.
iddqda
Прикольно. Пару лет назад игрался ровно в то же самое.
Правда не в микротик а в JuniperSRX. Там можно логировать каждую сессию.
В результате на основе логов получился чудный анализатор трафика.
Самое сложное было грок фильтр набросать.
Где то у меня это все осталось. Могу поделиться.