

Определение уровня ИИ это один из самых сложных, но и один из самых важных вопросов в области компьютерных наук. Если вы не можете точно сказать, является ли машина созданная сегодня умнее машины созданной вчера, как тогда определить что вы прогрессируете?
На первый взгляд может показаться что это совсем не проблема. «Конечно же ИИ становится умнее», – один из взглядов на проблему. «Только посмотрите на все эти деньги и талантливых людей которые устремились в индустрию. Посмотрите на достижения, такие как поражение людей в GO, и разного рода задачи которые нельзя было решить 10 лет назад, а сегодня они стали обычным явлением, например распознавание изображений. Неужели это не прогресс?
Другой же взгляд заключается в том, что эти достижения не являются хорошим показателем интеллекта. Да, поражение людей в шахматах и Го впечатляет, но какое это имеет значение, даже если самый умный компьютер проигрывает при решении задач общего характера малышу или крысе?
С такой критикой выступает исследователь искусственного интеллекта Франсуа Шоле, инженер-программист в Google и известная фигура в сообществе машинного обучения. Шоле является создателем Keras, очень популярной библиотеки для создания нейросетей. Он так же написал множество учебников по машинному обучению и ведет популярный Твиттер-аккаунт, где комментирует разные события в индустрии.
В недавней статье «Об измерении Интеллекта» Шоле так же выдвигает аргумент, что мир ИИ должен определиться с тем что является интеллектом, а что им не является. По словам Шоле, если исследователи хотят добиться прогресса в создании универсального искусственного интеллекта, то им стоит перестать смотреть на популярные бенчмарки, такие, как видеоигры или настольные игры, а стоит начать думать о навыках которые действительно делают людей умнее, таких как наша способность обобщать и адаптироваться.
В интервью по электронной почти взятым The Verge, Шоле объяснил свои мысли по этому поводу, рассказав почему он считает, что текущие достижения в области ИИ были «искажены», как мы можем измерять интеллект в будущем, и почему страшные истории о сверх интеллектуальном ИИ (которые рассказывают Илон Маск и другие) занимают в воображении публики необоснованно много внимания.
Интервью было слегка отредактировано для ясности.
В вашей статье вы описываете две разные концепции интеллекта, которые влияли на область ИИ. Первая описывает интеллект как способность преуспевать в широком спектре задач, тогда как вторая отдает приоритет адаптивности и обобщению, то есть способности ИИ реагировать на новые вызовы. Какая концепция больше влияет сейчас, и каковы последствия этого?
В первые 30 лет истории отрасли наиболее популярной была первая концепция: интеллект как набор статических программ и явных баз знаний. Прямо сейчас маятник очень сильно качнулся в противоположную сторону: интеллект представляется как «чистый лист» или, если использовать более подходящую метафору, «только что инициализированная глубинная нейронная сеть». К сожалению, эта концепция почти не ставится под сомнение и в значительной степени не исследована. Эти вопросы долго обсуждались в научном сообществе — буквально десятилетия — но сейчас я не вижу осведомленности среди людей занимающихся глубинным обучением, возможно потому, что большинство из них пришли в эту область после 2016 года.
Интеллектуальные монополии лишь одной точки зрения никогда не бывают чем-то хорошим, особенно как ответ на плохо понимаемые научные вопросы. Это ограничивает набор задаваемых вопросов. Ограничивает количество идей которыми могли бы задаваться люди. Я думаю, что исследователи сейчас начинают осознавать этот факт.
В вашей статье вы также утверждаете, что для улучшения ИИ требуется более точное определение интеллекта. Вы утверждаете, что сейчас исследователи сосредоточены на бенчмарках и статистических тестах, таких как победа в видеоиграх и настольных играх. Почему вам не хватает этого показателя интеллекта?
Дело в том, что выбирая такую меру, вы будете использовать все доступные лазейки(Shortcuts, сокращенные пути), чтобы достигнуть её. Например, если вы выбираете игру в шахматы в качестве меры интеллекта (так было с 1970-х до 1990-х годов), в итоге вы получаете систему, которая играет в шахматы, и больше ничего. Нет никаких оснований предполагать, что эта система будет хороша для чего-то другого. В итоге вы получаете дерево поиска и минимакс, это ничего не говорит о человеческом интеллекте. Сегодня стремление к мастерству в видеоиграх, таких как Dota или StarCraft, попадает в ту же самую интеллектуальную ловушку.
Возможно, это не очевидно, потому что у людей навыки и интеллект тесно связаны. Человеческий разум может использовать свой универсальный интеллект для освоения специальных навыков для поставленной задачи. Людей, которые действительно хороши в шахматах, можно считать довольно умными, потому что, косвенно, мы знаем что они начинали с нуля и должны были использовать свой универсальный интеллект, чтобы научиться играть в шахматы. Они не были созданы для игры в шахматы. Итак, мы знаем, что они могли бы направить свой универсальный интеллект на другие задачи и научиться выполнять эти задачи аналогичным образом. Вот что такое универсальность.
Но с машинами немного по другому. Машина может быть разработана для игры в шахматы. Таким образом, вывод который мы делаем о людях – «может играть в шахматы, поэтому должен быть умным» – рушится. И наши антропоморфные предположения больше нельзя применить. Универсальный интеллект может осваивать навыки, специфичные для задачи, но обратного пути от навыка, специфичного для задачи, к универсальному интеллекту нет. Совсем. Таким образом, у машин навыки и интеллект это абсолютно разные вещи. Вы можете достигать произвольных навыков в произвольных задачах, если можете собрать бесконечное количество данных о задаче (или потратить бесконечное количество инженерных ресурсов). И это все равно не приблизит вас ни на дюйм к универсальному интеллекту.
Ключевой момент здесь это то, что нет задачи в которой, достижение высокого навыка было бы признаком интеллекта. Только если задача на самом деле не является мета-задачей, и чтобы её решить необходимо было бы приобретать новые навыки в широком диапазоне ранее неизвестных проблем. Именно так я предлагаю измерять интеллектуальность.

Если нынешние тесты не помогают нам развивать ИИ с более универсальным и гибким интеллектом, почему они так популярны?
Нет никаких сомнений в том, что усилия, направленные на то, чтобы победить людей-чемпионов в известных видеоиграх, в первую очередь обусловлены тем что такие проекты могут собрать большое внимание в прессе. Если бы общественность не интересовалась этими яркими «достижениями», которые так легко можно представить как якобы прогресс в достижении сверхчеловеческого ИИ, исследователи занялись бы чем-то другим.
Мне от этого немного грустно, потому что исследования должны отвечать на открытые научные вопросы, а не заниматься пиаром. Если я намерен «решить» Warcraft 3 на сверхчеловеческом уровне, используя глубокое обучение, можете быть совершенно уверены что все получится при условии что мы обладаем талантом в разработке и достаточными вычислительными мощностями(что будет стоить десятки миллионов долларов, чтобы решить такую задачу). Но сделав это, что я узнаю об интеллекте или универсальности? Ничего. В лучшем случае я бы приобрел инженерные знания по масштабированию глубинного обучения. Поэтому я не считаю это научным исследованием, потому что оно не учит тому, чего мы еще не знали. Мы не отвечаем ни на один открытый вопрос. Если бы вопрос звучал так: «Можем ли мы играть в Х на сверхчеловеческом уровне?», то ответ однозначно: «Да, если вы можете генерировать достаточно много тренировочных ситуаций и представлять их в достаточно выразительной модели глубинного обучения». Мы знали это уже на протяжении некоторого времени.(На самом деле я говорил это еще до того, как ИИ достиг чемпионского уровня в Dota 2 и Starcraft.)
Каковы на ваш взгляд, реальные достижения этих проектов? В какой степени их результаты неверно истолкованы или искажены?
Одно серьезное искажение, которое я вижу, состоит в том, что эти высокоуровневые игровые системы представляют как реальный прогресс в направлении «систем ИИ и их способности справляться со сложностью и неопределенностью реального мира» [это из заявления OpenAI в пресс-релизе к их OpenAI Five боту играющему в Dota 2]. Но они не могут. Если бы это было так, то это были бы очень полезные исследования, но это попросту неправда. Например возьмем OpenAI Five: он не смог справиться со сложностью Dota 2, потому что его обучали на 16 персонажах, и он не смог распространить знания на всю игру, в которой больше 100 персонажей. На его тренировку ушло 45000 лет игрового процесса – опять же, обратите внимание, как требования к тренировочным данным растет вместе со сложностью задачи – тем не менее, полученная модель оказалась очень хрупкой: игроки, не являющиеся чемпионами, смогли найти стратегии, позволяющие победить бота через несколько дней после того, как ИИ стал доступен для публики.
Если вы хотите когда-нибудь научиться справляться со сложностью и неопределенностью реального мира, вам стоит начать задавать такие вопросы, как: что же такое универсальность интеллекта? Как нам измерять и повышать уровень универсальности в наших обучающихся системах? И это совсем не то же самое что мы делаем сейчас, когда бросаем в 10 раз больше данных в большую нейронную сеть, чтобы она улучшила свои навыки на несколько процентов.
Тогда, какую меру интеллекта лучше выбрать индустрии?
Если кратко, то нам стоит прекратить оценивать навыки в заранее известных задачах, таких как шахматы, Dota или StarCraft, и вместо этого начать оценивать способность системы приобретать навыки. Это значит что мы должны использовать только новые задачи, ранее не известные системе, измерять предварительные знания о задании с которых система начинала, и измерять эффективность системы (сколько данных требуется, чтобы научиться выполнять задачу). Чем меньше информации (предварительных знаний и опыта) вам требуется для достижения определенного уровня навыков, тем вы умнее. Если учесть вышесказанное, то на самом деле, современные системы искусственного интеллекта не очень-то и умны.
Кроме того, при такой мере интеллекта, машины будут походить на людей более явно, потому что могут быть разные типы интеллекта, и человеческий интеллект – это то, что мы косвенно имеем в виду когда говорим об универсальном интеллекте. И это так же включает в себя попытки понять, с каким набором знаний люди рождаются на свет. Люди учатся невероятно эффективно – им требуется совсем немного опыта, чтобы приобрести новые навыки – но они не делают это с нуля. Они пользуются врожденными знаниями, помимо накопленных в течении жизни навыков и знаний.
В моей недавней статье я предлагаю новый датасет для оценки, ARC, который очень походит на IQ тест. ARC — это набор мыслительных задач, в котором каждая задача объясняется с помощью небольшой последовательности демонстраций, обычно трех, и вы должны научиться по этим нескольким демонстрациям выполнять задачу. В ARC задействована идея того, что каждая задача, по которой оценивается ваша система, должна быть совершенно новой и включать только знания соответствующие человеческим врождённым знаниям. Например, в таких задачах нельзя использовать человеческий язык. В настоящее время люди могут решить ARC без каких-либо устных объяснений или предварительной подготовки, но ни одна из известных на данный момент систем ИИ не может её решить. Это важный маркер того, что нам нужны новые идеи.
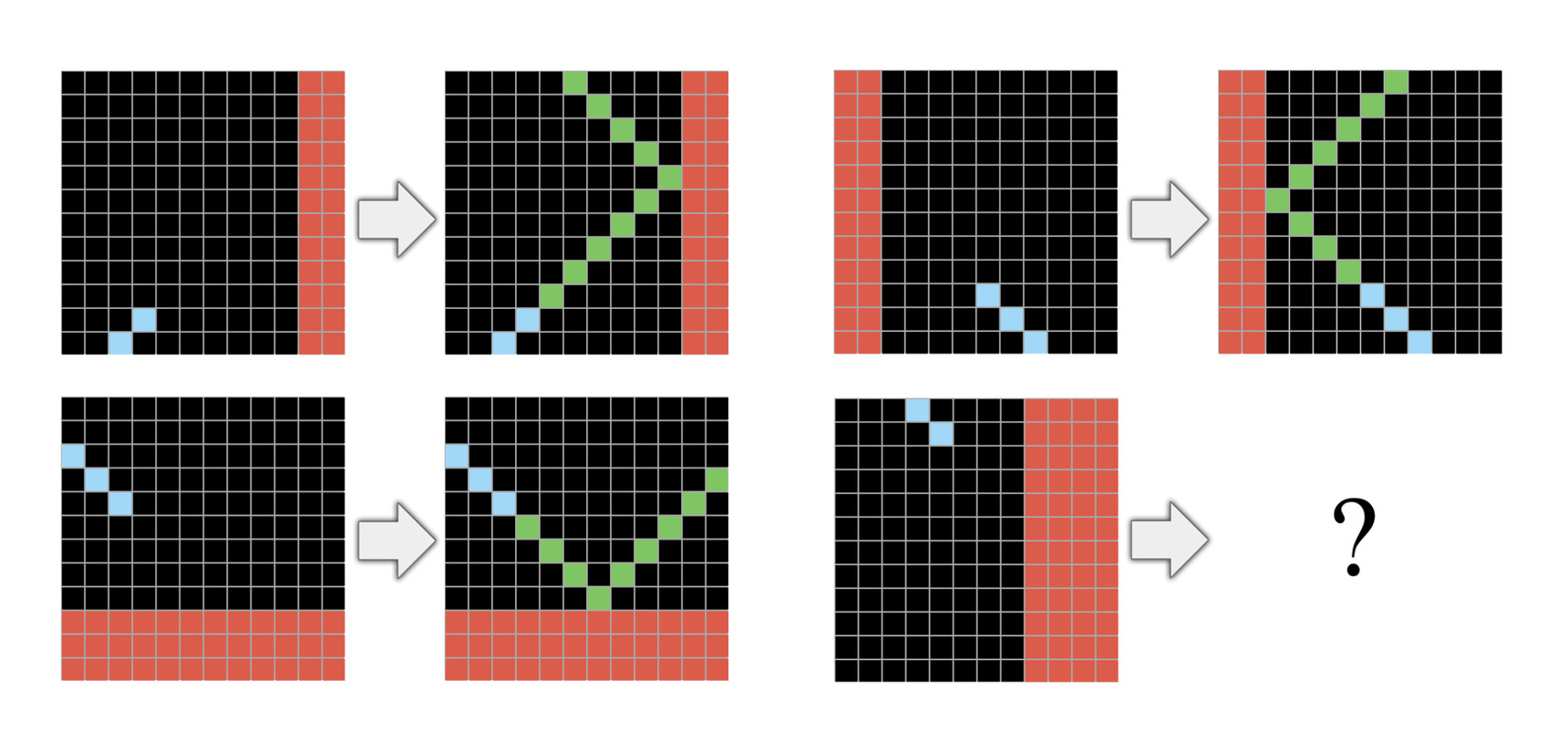
Как вы думаете, мир ИИ сможет продолжить свой прогресс просто увеличивая вычислительные мощности для решения проблем? Некоторые утверждают, что на протяжении всего времени это был самый эффективный способ для повышения производительности. Когда другие предполагают, что если мы последуем этому пути, то результаты и темпы роста начнут ухудшаться.
Это абсолютная правда, если вы работаете над конкретной задачей. Использование большего количества данных для обучения и больших вычислительных мощностей для вертикальной задачи повысит производительность этой задачи. Но это даст вам практически нулевое понимание того, как добиться универсальности в искусственном интеллекте.
Если у вас достаточно большая модель глубинного обучения, и хорошая выборка под задачу, то она научится решать эту задачу, какой бы она ни была – Dota или StarCraft, все что угодно. И это чрезвычайно ценно. Это можно использовать практически в бесконечном количестве задач завязанных на машинном восприятии. Единственная проблема в том, что объем данных, которые вам нужны, является комбинаторной функцией по отношению к сложности задачи, поэтому даже слегка сложные задачи могут стать чрезмерно дорогими.
Возьмем например автомобили на автопилоте. Миллионов тренировочных ситуаций будет недостаточно чтобы модель использующая только глубинное обучение научилась безопасно управлять автомобилем. Именно поэтому у нас еще нет автопилота 5-го уровня. А в самых совершенных системах автопилота глубинное обучение используется в основном, чтобы связать данные с датчиков и вручную созданные модели. А если бы у нас было универсальное глубинное обучение, то у нас был бы автопилот 5-го уровня в 2016 году в виде одной большой нейронной сети.
И наконец, учитывая, что вы говорите об ограниченности современного ИИ, мне кажется стоит спросить о том страхе, что чрезвычайно мощный ИИ может нанести вред человечеству в ближайшем будущем. Как вам кажется, это обоснованные опасения?
Нет, я не верю в обоснованность этой идеи. Мы еще никогда не создавали автономный ИИ. И нет абсолютно никаких признаков того, что мы сможем создать его в обозримом будущем. (Индустрия ИИ сейчас не двигается в этом направлении.) И мы даже не можем предположить, какими могут быть его характеристики, если мы в конечном итоге создадим его в далеком будущем. Если хотите аналогию, то это все равно что спросить в 1600 году: «Баллистика довольно стремительно развивается! А что если у нас когда-то появится пушка, которая сможет уничтожить целый город. Как мы можем быть уверены, что она убьет только плохих парней?». Это довольно плохо сформулированный вопрос, и его обсуждение в отсутствии каких-либо точных знаний об этом будущем ИИ, в лучшем случае сводится к философскому аргументу.
А еще эти страхи касательно сверх интеллекта отвлекают на себя внимание от других направлений в которых ИИ может быть очень опасным уже сегодня. Определённые способы использования ИИ представляют опасность и без сверх-интеллекта. Я писал о том как ИИ можно использовать для алгоритмических систем пропаганды. Так же уже было написано много о набирающем тренде использования ИИ в системах вооружения или об ИИ как инструменте для тоталитарного контроля.
Существует история об осаде Константинополя в 1453 году. Пока город сражался с Османской армией, его ученные и правители обсуждали какого же ангелы могут быть пола. И чем больше энергии и внимания мы уделяем дебатам по поводу пола ангелов или продумыванию тех ценностей которыми должен обладать сверх интеллектуальный ИИ, тем меньше мы уделяем внимания решению насущных и реальных проблем. Есть один известный лидер в IT, который любит говорить о сверхразумном ИИ как о главной угрозе человечеству. Что ж, пока эти идеи занимают все заголовки, вы не обсуждаете этично ли выпускать на наши дороги машины с недостаточно точным автопилотом, что приводит к авариям и гибелям людей.
Если принять эту критику – что в данный момент нет никаких технических оснований для этих страхов – почему, по вашему мнению, они так популярны?
Я думаю, что это просто красивая история, а людям такое нравится. Это не совпадение что все так напоминает религиозные истории о конце света, ведь такие истории распространялись и резонировали среди людей на протяжении долгого времени. По этой же причине этот страх часто используют в фантастических фильмах и романах. Все потому что это красивая история. А людям нужны истории, чтобы понимать мир. И на такие истории гораздо больший спрос, чем на понимание природы интеллекта или понимание того, что движет техническим прогрессом.
Так же больше интересных штук — в Telegram канале.
Комментарии (10)

BlackMokona
24.12.2019 09:52Как бэ все рекомендации и указания автора выполняются в разработке ИИ по играм.
Тот же Альфо Зиро в отличии от Го не нуждался в огромной базе данных реальных игр.
От Альфы к Альфе в Го они нуждались во всем меньших ресурсах для обучения.
Вся его критика вообще мимо летит.
Для ИИ игра это совершенно новая ситуация к которой он приспосабливается и адаптируется и ищет новые решения.
Альфа уже показал что может не только в ГО играть
Гугл уже показали нейросети которые используют свои способности по решению одной задачи для решения другой и тд.
Ну и небезопасные автопилоты которые безопаснее людей по статистики, конечно же не этично выпускать. Ха ха
mustitz
24.12.2019 18:10+1Не совсем так. AlphaZero (и LeelaZero) всё также нуждается в большой базе игр для обучения. Просто можно построить итеративный процесс, когда AlphaZero играет сама с собой, а результаты партий исползуются для обучения. Хочешь не хочешь, но AlphaZero сыграла сама с собой 7 000 000 партий.

chapuza
25.12.2019 00:05И при этом Шолле — ученый с мировым именем, пожалуй, второй после Хинтона в глубинном обучении, создатель
одной из самыхсамой широко используемой библиотеки, principal (а может, и distinguished) engineer в Google, и просто умнейший мужик.
А вы — никто.
Ха ха
DesertFlow
24.12.2019 11:44Но ведь на картинке в статье прямая отсылка к арканоиду, змейке и пониманию физики (отскакивает камней от стены). Не думаю, что без этих предварительных знаний можно решить эту задачу.
iridiumhawk
24.12.2019 12:36Не совсем согласен с данным утверждением. Я при анализе данной задачи не вспоминал про арканоид и физику. Я выискивал общие принципы построения картинок, и пришел к выводу о том что мы должны продолжить линию зелеными клетками (по смежным углам) до соприкосновения с красными клетками и затем в противоположном направлении до границ картинки. Знания физического мира не использовались, только обобщения.
Но вопрос к сильному/универсальному ИИ — сможет ли он использовать обобщение в любой задаче, или только в тех, на которых натренирован.BlackMokona
24.12.2019 12:49Обобщениями можно построить линию как угодно и обосновать это. Только отсылка к играм которые в свою очередь отсылают к физике делает правильный ответ правельным ответом
iridiumhawk
24.12.2019 13:17Для обобщения мы используем три предыдущих набора данных, что бы смоделировать четвертый набор. В этих трех наборах линия рисуется не «как угодно», а в соответствии с правилами, которые мы и выясняем. На основе этих правил мы завершаем четвертую картинку. Я обошелся без физики, только формальной логикой (в данном случае).
Но в целом могу согласиться, что есть задачи, в которых сильный ИИ должен использовать законы реального мира. А и более того, законы социального общества, например. Или то, что называется «эмоциональный интеллект». Как ИИ натренировать на все это, пока категорически непонятно.BlackMokona
24.12.2019 13:30Так вот на основе обобщения и используя предыдущие наборы данных, я выяснил что сумма синих и зелёных квадратиков равна 12. Сумма красных квадратов не имеет никакой корреляции, а число синий квадратов никак не влияет на результат. Важна только сумма синих и зелёных квадратов.
DesertFlow
25.12.2019 01:39Я при анализе данной задачи не вспоминал про арканоид и физику.
Тогда хорошо. Потому что до меня решение дошло только когда вспомнил про траектории. И кроме перечисленного, мне еще понадобились знания как рисуется траектория, т.е. последовательно увеличивая число точек, начиная от начала траектории.
IMnEpaTOP
Книги Шолле на русском языке издаёт Питер.
Глубокое обучение на Python сейчас закончились, дополнительный тираж будет готов в конце января (пока доступна лишь электронная версия).
Глубокое обучение на R можно купить и в бумаге и в цифре прямо сейчас.