

Артур Хачуян (далее – АХ): – Здравствуйте! Всем привет! Меня зовут Артур Хачуян, я руковожу компанией Social Data Hub, и мы занимаемся различным интересным интеллектуальным анализом открытых источников данных, инфополя и делаем всякие интересные исследования и так далее.
И сегодня коллеги из BBDO Group попросили рассказать о современных технологиях анализа больших данных, больших и не очень данных для рекламы: как это применяется, показать несколько интересных примеров. Я надеюсь, вы будете задавать вопросы прям по ходу, потому что я могу начать нудить и не раскрывать сути и так далее, так что не стесняйтесь.
Собственно, основные направления, где-то когда-либо применялись какие-то «околобигдатные» решения», они все понятны – это таргетирование аудитории, анализ, проведение каких-то анализ-маркетинговых исследований. Но всегда интересно, какие дополнительные данные можно найти, какие можно найти дополнительные смыслы после применения анализа.
Зачем нужны технологии для рекламы?
С чего мы начнём? Самое понятное – это реклама в социальных сетях. Сегодня снял с утра: почему-то «Вконтакте» считает я именно эту рекламу должен видеть… Хорошо это или плохо – это уже второй вопрос. Видим, под категорию призывников я попадаю точно:

Самое первое и интересное, что можно взять как технологическое решение… Первое, что я хотел решить, перед тем как мы начнём, – определиться с терминами: что такое открытые данные и что такое большие данные? Потому что у всех людей своё понимание на этот счёт, и я никому не хочу навязывать свои термины, но… Просто чтобы не было никаких расхождений.
Лично я считаю, открытые данные – все те, до которых я могу дотянуться без какого-либо логина или пароля. Это открытый профиль в социальных сетях, это поисковая выдача, это открытые реестры и т. д. Большие данные, в моём собственном понимании, я вижу так: если это табличка с данными – это миллиард строк, если это какое-то файловое хранилище – это где-то петабайт данных. Остальное в моей терминологии – это не большие данные, а что-то около.
Высокоточное профилирование и скоринг профилей
Идём по порядку. Самое первое и интересное, что можно придумать из анализа открытых источников данных – это высокоточное профилирование и скоринг профилей. Что это? Это история, когда по вашему аккаунту в социальной сети можно предсказать не только кто вы, не только ваши интересы.
Но сейчас, объединяя различные источники, можно понять средний уровень вашей зарплаты, сколько стоит ваша квартира, где она находится. И все эти данные можно использовать буквально из подручных средств. Например, если взять ваш аккаунт в социальной сети, посмотреть, скажем, где вы живёте, где вы работаете; понять, в какой секции бизнеса находится компания, в которой вы работаете; взять выгрузку похожих вакансий с HH и «Суперджоба», если вы аналитик, менеджер и т. д.; посмотреть, где вы живёте (базу, скажем ЦИАНа), понять, сколько стоит аренда жилья в этом месте, сколько стоит покупка жилья в этом месте, предсказать примерно, сколько вы зарабатываете. Дальше по вашим соцсетям можно понять, сколько вы путешествуете, где вы находитесь, насколько вы лояльны к работодателю.
Соответственно, из такого огромного количества метрик мы можем сделать всё, что угодно. Мы можем представить вам продукт, который вам интересен. Представляете, интернет-магазин? Вы заходите туда – этот интернет-магазин отлавливает ваш аккаунт в социальной сети и говорит вам: «Маша, ты только что рассталась с парнем, вот тебе такие-то, определённые продукты». Это не ближайшее будущее…
Как определяют геоположение человека?
Ответы на вопросы из аудитории:
- Обычно точным местом жительства считается 80% всех check-in’ов. Но для людей, которые не чекинятся нигде – несколько вариантов: либо чек-ин, либо геопозиция, либо это анализ постов и публикаций за весь период времени, когда что бы то ни было писал человек… И где-нибудь, да всплывёт что-нибудь типа «Хочу купить коляску возле Академической» или «Видел тут недавно граффити на стене некрасивое». То есть практически у 80% людей можно определить их геоположение, их место работы и их место жительства по данным либо по метаданным, которые можно собрать из социальных сетей.
Это, опять же, анализ постов. В самом простом понимании – это анализ чек-инов и геолокаций в соцсетях, которые не удаляют метаданные jpeg’а (можно по ним что-то разобрать). Но для оставшихся людей – это обычно текстовые трансляции: либо человек «светит» своё местоположение, когда пишет о чём-то, либо он «светит» свой телефон, по которому можно найти какую-нибудь его рекламу на «Авито» или его аккаунт на «Авто.ру». По этим данным можно объединить (например, «Я продаю автомобиль около Маяковской») и примерно предположить это. - Обычно люди публикую это в социальных сетях. Мы работаем только с открытыми источниками и здесь речь идёт исключительно об открытых источниках. Обычно публикуют объявления, то есть процентах в шестидесяти случаев самая частая история, когда люди «светят» свой актуальный сотовый номер телефона – это объявления о продаже чего-то. Либо в каких-то группах человек пишет («Я продаю там то-то, то-то), либо куда-то заходит.
Да! Комментируют обычно, типа: «Ответьте мне или киньте смс-ку, позвоните мне на номер. Такое очень часто бывает с людьми, которые что-либо продают, покупают в социальных сетях, с кем-то коммуницируют… Соответственно, по этому номеру потом можно привязать к нему его профиль на ЦИАНе, если он когда-то что-то публиковал, либо, опять же, на «Авито». Это просто самые популярные, топ источников, он дальше будет – это «Авито», ЦИАН и так далее. - Имеется в виду онлайн-магазин. Дальше будет технология распознавания лиц и мэтчинга профилей (мы о ней поговорим). Чисто теоретически такое можно применить и для офлайн-магазина. И вообще, моя большая мечта – когда появятся уличные баннеры, когда ты проходишь мимо камеры, она «трэчит» лицо. Но законодательно это дело запретят, потому что это нарушение приватности. Я надеюсь, что рано или поздно это будет.
- У меня из личного опыта. Очень часто, когда человек тебе что-то пишет, ты оперируешь каким-то фактами из его жизни, которые ты вроде как не должен узнать… Люди в большинстве случаев пугаются. Но! Исходя из статистики за последнее время, на 14 % уменьшилось количество закрытых аккаунтов в социальных сетях. Количество фейков увеличивается, количество открытых аккаунт растёт – люди всё больше двигаются к открытости. Я думаю, что через 3-4 года они перестанут так остро реагировать на то, что кто-то знает о них информацию, которую он потенциально не должен знать. Но на самом деле это очень легко получить, посмотрев его стену.
Что можно взять из открытых источников?
Примерный список вещей, которые можно понять с достаточно высокой достоверностью из открытых источников, – он есть. На самом деле есть ещё больше всяких разных метрик; это зависит от заказчика таких исследований. Есть какое-нибудь HR-агентство, которому интересно, ругаешься ли ты матом в социальных сетях или где-то в публичном пространстве. Кому-то интересно, ставишь ли ты лайки под публикациями Навального или, наоборот, под публикациями «Единой России», или какой-то порнографический контент – такие вещи достаточно часто случаются.
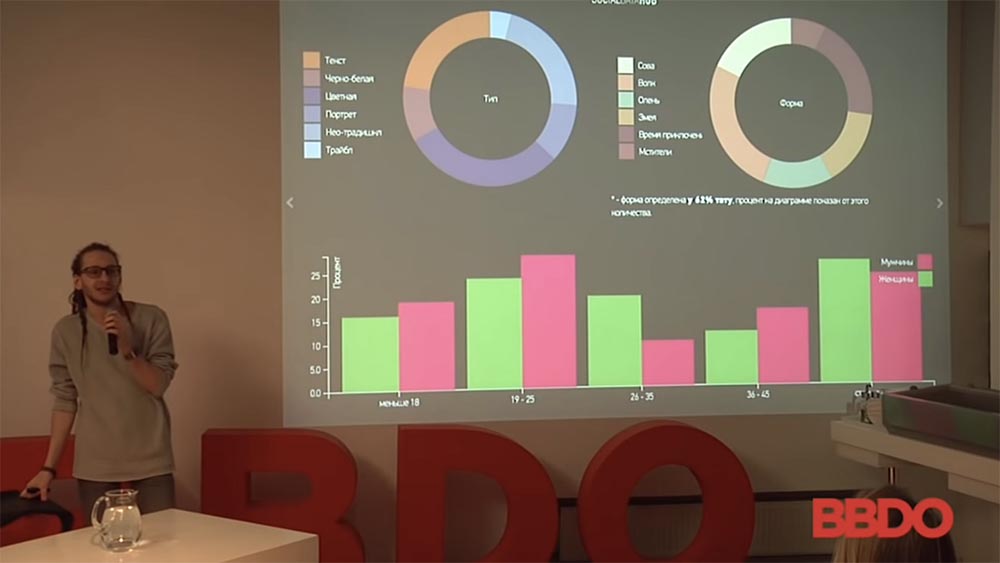
Основные из них – это семейные ценности, примерная стоимость квартиры, жилища, поиск автомобиля и так далее. По этому всему людей можно разбить по социальным группам. Это пользователи московского «Тиндера», кто они (по их картинкам, найденным их аккаунтам в «Фейсбуке»); на основании их интересов разбиты по всяким социальным группам:

Если двигаться ближе к рекламе, то мы уже потихоньку ушли от стандартного таргетинга рекламы, когда ты выбираешь в условном «Вконтакте», что тебя интересуют мужчины 18 лет, подписанные на определённые группы. У меня дальше есть такая картинка, сейчас вам покажу:

Суть в том, что большинство текущих сервисов, которые занимаются анализом, в принципе люди, которые занимаются анализом социальных сетей, именно занимаются анализом интересов… Первое, что приходит в голову людям – это про проанализировать топ групп своих подписчиков. Возможно, с кем-то это работает, но лично я считаю, что это кардинально неверно. Почему?
Ваши лайки собирают и анализируют
Вот возьмите сейчас свои телефоны, посмотрите на свой топ групп – обязательно там будет более 50% групп, о которых вы уже забыли, это какой-то контент на самом деле нерелевантный для вас. Вы его совсем не потребляете, но тем не менее система будет стрейчить вас по ним: что вы на рецепты подписаны, на какие-то популярные группы. То есть вы нарушите систему, которая анализирует ваш профиль, и ваши интересы будут не оправданны.
Двигаясь дальше… Что там? Мы предполагаем, что делают остальные люди. Самый, на наш взгляд, адекватный способ оценить интересы пользователей – это лайки. Например, во «Вконтакте» нет ленты лайков, и люди думают, что никто не знает о том, чему они ставят лайки. Да, часть лайков введена в «Инстаграме», в «Фейсбуке» мы что-то видим, но большинство контента в определённых группах не транслирует это общей лентой, и люди живут и думают, что никто не узнает, на что они ставят лайк.
И, собрав определённый, интересующий нас контент какого-то содержания, собрав эти посты, собрав эти лайки, потом по этой базе проверив этого человека, мы можем с высокой точностью определить, кто он, какая у него судьба, чем он интересуется. Определить точно в определённую социальную группу и провзаимодействовать с ним.
Покупка авто меняет поведение
У меня есть такой пример. Сразу оговорюсь, что у меня примеры околорекламные и околомаркетинговые, потому что, сами понимаете, большинство кейсов защищают NDA и так далее. Но всё-таки будет много чего интересного. Значит, история с этими людьми: это мужчины, которые купили автомобиль в промежутке 2010 по 2015 год. То, как изменилось их социальное поведение в сети, отмечено цветом. Процент девушек в подписчиках изменился, подписался на «пацанские» паблики, нашёл постоянного сексуального партнёра…

Всё это дело разбито по маркам автомобилей и по количеству людей. Отсюда можно сделать много интересных выводов о поведении людей, как это всё работает. Могу сказать, что «Порш Кайенн» и посаженная «Приора» по количеству привлечённой аудитории практически одинаковы. Качество этой аудитории, их поведение разные, но количество примерно одинаковое. Вывод отсюда можно сделать, ближе к вашему рынку, какой угодно. Продаёте вы «Ауди» — делаете слоган «Купи «Ауди» – «уедь» от родителей!» и так далее.
Это да, смешной пример к тому, что поведение людей, основанное на анализе лайков, на основании того из какой группы в какую они переходят, какой они контент анализируют – практически со 100% вероятностью даёт понять, кто вы. Потому что, если вы не обладаете доступом к сетевому трафику, не читаете личные сообщения, лайки всегда подскажут, кто этот человек – беременная женщина, мама, военный, полицейский. А для вас, как для человека, который может размещать рекламу, это большое попадание в цель.
Ответы на вопросы аудитории:
- Каждый столбик – это количество человек данного автомобиля; как изменился паттерн их поведения. Вот смотрите: люди, купившие «Порш Кайенн» – 550 примерно человек (жёлтое), процент девушек в подписчиках увеличился.
- Выборка – это пользователи социальных сетей «Вконтаке», «Фейсбук», «Инстаграм» с 2010 по 2015 год. Единственное уточнение: здесь выбраны машины, которые с более чем 80% точностью можно определить на фотографиях с помощью определённых инструментов.
- За определённый промежуток времени его машина (ну, то есть не его, это мы уже оставляем на поверку социальных сетей)… За определённый промежуток времени человек постоянно с автомобилем фотографировался, находился с ним, публикации были разные, фотографии были с разных углов и так далее. Там дальше будет картинка, какие люди с какими машинами фотографируются и… Да, это второй вопрос – доверие данным социальных сетей.
- Раз уж мы его подняли – к сожалению, не всегда данные социальных сетей верны. Люди не всегда склонны публиковать свою информацию. Лично я проводил такое исследование: сравнивал количество выпускников московских ВУЗов с тем, какое количество людей зарегистрировано в социальных сетях. В среднем на 60% людей больше в социальных сетях зарегистрировано – выпускников МГУ за определённый год по определённым специальностям, нежели их на самом деле в принципе существует. Так что да – здесь, естественно, есть процент ошибок, и никто это не скрывает. Здесь просто за основу взяты те автомобили, которые можно с более чем 80% вероятностью определить.
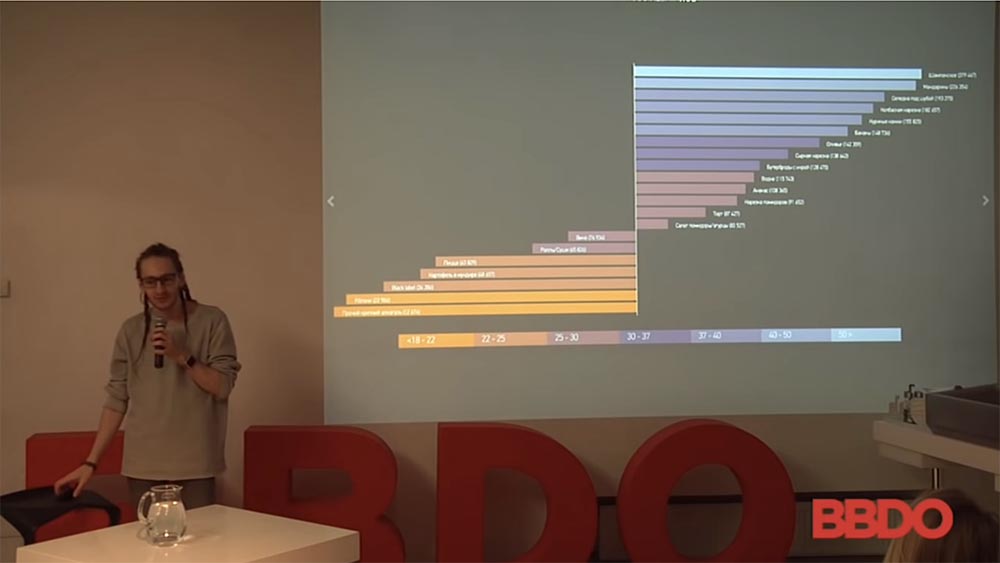
Список источников для обучения модели
Вот примерный список источников, который можно использовать, который используется для того, чтобы с большой достоверностью определить социальный профиль человека, кто он.

С социальных сетей мы берём профиль, с ЦИАНа – стоимость квартиры примерно, «Хед-Хантер», «Суперджоб» – это средняя зарплата для данного человека. Надеюсь, здесь нет представителей «Хед-Хантера», потому что они считают, что не очень хорошо у них эти данные брать. Тем не менее это средняя зарплата по определённым регионам для определённых типов деятельности по вакансиям.
«Авито», «Авто.ру»: очень часто люди, когда засветили свой телефон, он у них обязательно есть (в большом количестве случаев) хоть что-то на «Авито», либо на «Авто.ру», или ещё на нескольких сайтах, с которых можно понять, кто они. Если по этому телефону продавали коляску или автомобиль… Росстат и ЕГРЮЛ – это всё-таки больше реестры, с помощью которых можно ранжировать компанию-работодателя – по какой-то формуле, по модели, которую может задать любой человек (можно примерно определить деньги этого человека и т. д.).
«Тиндер» помогает собирать данные о положении людей
Плюс, есть такая интересная штука (как вариант, очень смешно в исследовании) – это, опять же, сбор данных с московского «Тиндера» с помощью ботов для этого «Тиндера». Определялось расстояние до людей, а дальше определялось их примерное местоположение.

Задачей этого исследования было определить количество аккаунтов «Тиндера» на территории государственных учреждений – в Думе, прокуратуре и так далее. Но вы себе, как рекламодатель, можете представить как угодно: это может быть, например, «Старбакс» или ещё кто-то… То есть количество людей того же «Тиндера», которые пьют у вас кофе, что-то заказывают, находятся в магазинах. По поводу этого геоположения: так можно поступить с любым сервисом.
Ответ на вопрос из аудитории:
- «Тиндер»? Вы не знаете? «Тиндер» – это такое приложение для знакомств, где вы просматриваете фотографии (влево-вправо), и это приложение показываем вам расстояние до человека. Если вы с трёх разных точек получите расстояние до этого человека, вы можете примерно (+ 5-7 метров) определить местоположение. В данном случае, для определения на территории прокуратуры или Госдумы, это не так сложно. Но, опять же, это может быть ваш магазин, это может быть что угодно.
У нас, например, давно-давно был такой кейс (не исследование), когда мы получали от одного из операторов сотовой связи данные о плотности потока, данные о плотности перемещения сотовых точек, и эта вся информация накладывалась на координаты рекламных щитов, находящихся на автомагистралях. И задача сотового оператора – определить, какое примерно количество человек проезжает и потенциально может видеть эту щитовую рекламу.
Если здесь есть специалисты по щитовой рекламе, вы можете сказать: супер-достоверно нельзя понять – кто-то едет, кто-то не посмотрел, кто-то посмотрел… Тем не менее это пример того, как 20 миллиардов полигончиков таких по Москве, на которых есть плотность этих людей в каждый час по определённым маршрутам… Можно посмотреть, мимо чего эти люди проходили в любой момент и примерно оценить пассажиропоток.
Ответ на вопрос из аудитории:
- Никто такие данные не даёт. Мы проводили такое исследование для одного из операторов, это исключительно внутренняя история, поэтому она, к сожалению, не представлена в виде картинок. Но зачастую крупные рекламные агентства не имеют проблем с тем, чтобы обратиться к оператору. По крайней мере, в Москве есть много прецедентов, когда, например, страховые компании обращаются к компаниям типа «ГетТакси», которые дают обезличенные данные о том, какой возраст водителя, как они ездят (хорошо – плохо, лихачат – нет), для того чтобы прогнозировать полисы и так далее. Все с этим борются, но на каком-то внутреннем уровне анонимные данные дать – я думаю, что такой проблемы нет ни у кого.
Распознавание изображений и образов
Идём дальше. Моё любимое – распознавание изображений. Здесь будет небольшой кусочек про поиск людей по лицам, но мы в основном эту часть не берём. Мы берём именно распознавание образов и определения, что на этом изображении – марка автомобиля, цвет его и так далее.

У меня есть такой шуточный пример:

Было такое исследование по поиску татуировок в различных социальных сетях. Соответственно, это же можно применить к любому бренду, к любому визуальному образу, практически к любому визуальному образу. Есть те, которые нельзя определить достаточно достоверно (мы их не берём).
Вот моё любимое. Автомобильные бренды достаточно часто обращаются за такой задачей, потому что их задача, например, – найти всех владельцев каких-нибудь BMW X6, понять, кто они, как они между собой связаны, чем они интересуются и так далее. Это к вопросу о том, с какими автомобилями фотографируются люди в социальных сетях.

Здесь вообще не было никакой фильтрации: предмет их, автомобиль не их; просто такая разбивка автомобилей – возраст и так далее. Но визуальное распознавание образов используется достаточно часто: это и поиск беременных женщин, и поиск логотипов брендов в каком-то масс-медиа (кто и что постит).

Самый мой любимый кейс (которым пользуются различные рестораны): какие роллы постят в социальной сети. Смешная штука, но на самом деле это позволяет много чего интересного понять, во-первых, о собственных покупателях: кто к тебе пришёл и почему они это сделали. Потому что не секрет, что в суши-барах большинство людей (не буду говорить «девушек») фоткается, чтобы зачекиниться, сфотографировать что-то и т. д.
Бренд этим может пользоваться. Бренду интересно, какую именно продукцию ему нужно красиво фотографировать и выкладывать, какие люди туда приходили. Такую вещь можно провернуть практически с чем угодно, начиная от еды.
Распознавание образов на видео
Ответ на вопрос из аудитории:
- На видео – нет. Оно у нас есть в тестовом режиме. Мы пробовали такую технологию, но получается, что… Она достаточно хорошо распознаёт всё дело с видео, но применение этому мы никуда не нашли. Пока. Кроме как анализ того, сколько, какие видеоблогеры где-то говорят… Было такое исследование. Сколько их лица встречаются, как часто. Но для брендов пока не придумали, куда это придумать. Возможно, когда-нибудь это придёт.
Опять же, это еда, это могут быть беременные женщины, мужчины (не беременные), автомобили – всё, что угодно.
Как вариант, было такое новогоднее исследование для одного СМИ. Тоже далеко от рекламы, но тем не менее. Это – какую еду люди постили на Новый год:
Оно здесь ещё разбито по возрасту. Можно просмотреть такую корреляцию, что молодые люди еду в основном заказывают, взрослые в основном делают традиционный стол. Шуточная вещь, но, представляя её себе как владелец бренда, вы можете оценить большое количество вещей: кто и как с вашей продукцией обращается, что о ней пишут. Зачастую не всегда люди упоминают сам бренд в тексте, и традиционные мониторинговые системы аналитические не всегда могут понять, найти это упоминание бренда исключительно потому, что в тексте он не упомянут. Или в тексте он написан с ошибками, нет хэш-тегов или что-то угодно.
Фотографии видно. С фотографией можно понять, центральный ли это объект кадра, не центральный объект кадра. Дальше можно посмотреть, что этот человек написал. Но чаще всего это используется как поиск потенциальной аудитории, которая ездила на определённых автомобилях и так далее. А потом мы с этими автомобилями будем делать много чего интересного.
Ботов учат подражать человеку
Вот такой вариант применения подсчёта людей тоже был:

Бывает вариант сопоставления людей, когда нужно по каким-то фотографиям найти людей, понять их социальный профиль, кто они. Опять же, возвращаемся к вопросу о том, что если у нас стоит камера в офлайн-магазине, то это достаточно хороший способ понять, кто к вам приходит, кто эти люди, чем они интересуются, что их сподвигло к вам прийти.
Дальше самое интересное: если мы соберём их аккаунты в социальных сетях, поймём, кто эти люди, чем они интересуются, мы сможем (как вариант) сделать бота, похожего на этих людей; этот бот начнёт жить, как эти люди, и анализировать, какую рекламу он видит в различных социальных сетях. Это позволит достаточно точно понять, какие бренды на этого человека ориентированы. Это тоже достаточно частая история, когда необходимо не просто проанализировать, кто этот человек и какие у него интересы, а ещё и какую рекламу на него потенциально конкуренты ваши или другие заинтересованные люди таргетировать.

Анализ связей в социальных сетях

Следующая штука интересная: это анализ взаимосвязей между людьми. Сам, собственно, анализ связей в сети, эти сетевые графы – в этом нет вообще ни капли, ничего нового, это всем известно.

Но применение к рекламным задачам – это самое интересное. Это поиск людей, которые задают тренды, это поиск людей, которые распространяют информацию по определённым критериям внутри этой сети. Скажем, нас интересуют те же владельцы определённой модели БМВ. Собрав их всех вместе, мы можем найти тех, кто держит у себя в руках общественное мнение. Это необязательно блогеры автомобильные и так далее. Обычно это простые товарищи, которые сидят в различных пабликах, интересуются каким-то контентом и могут за очень короткий промежуток времени завлечь в эту зону ответственности, в зону интереса ваш бренд или кого-то интересующего для вас.
Здесь есть такой пример. Есть у нас потенциальные какие-то люди, связи между людьми. Здесь оранжевые – это люди, мелкие точки – это общие группы, общие друзья.

Если собрать все эти связи между ними, можно очень чётко посмотреть, что есть люди, у которых между собой есть большое количество общих групп, общих друзей, они там находятся между собой… А если эту же визуализацию разбить на группы по интересам, по контенту, который они распространяют, насколько они взаимодействуют друг с другом… Вот здесь можно посмотреть, что предыдущая картинка стала вот таким образом:

Здесь чётко выделились цветом группы. В данном случае это взяты студенты нашей магистратуры в Высшей школе экономики. Здесь видно, что фиолетовые / синие – это те, кто любят Transparency International, «Открытую Россию», паблики Ходорковского. Снизу слева – зелёные, те, кто любит «Единую Россию».
Можно посмотреть, что предыдущая картинка была вот такая (это просто связи между людьми), а стала чётко разграниченной. То есть все люди всегда связаны между собой, у них есть одинаковые интересы, они дружат друг с другом. Сверху одни, снизу другие, там ещё какие-то товарищи. И если каждый из этих маленьких подграфов отдельно провизуализировать с другими параметрами и посмотреть скорость распространения контента (грубо говоря, кто там что репостит), можно найти в каждой части одного-двух человек, которые всегда держат в руках общественное мнение, провзаимодействовав с которым, попросив отправить пост какой-то или ещё-что – можно получить отклик всей этой интересной аудитории.
У меня есть ещё один такой пример. Тоже граф: это сотрудники BBDO Group, найденные в соцсетях как пример. Выглядит как неинтересное, большое, зелёное, связи между ними…

Но у меня есть вариант, где между ними уже построены группы. Потом, если кому-нибудь будет интересно, есть интерактивная версия – можно покликать, посмотреть.
Сверху справа – те, кто любит Путина. Вот здесь фиолетовые – это дизайнеры; те, кто увлекается дизайном, чем-то таким интересным и так далее. Здесь белые штуки – это руководящий состав (видимо, я так понял); это люди, которые никак, в общем, не связаны, но работают примерно на одинаковых позициях. Остальное – это их общие группы, связи и так далее.
Брендам нужны не блогеры, а лидеры мнений
Берём этих людей и находим – дальше рекламное агентство, рекламная компания решает сама: она может денег дать этому человеку, чтобы он как-то провзаимодействовал с этим контентом, ещё что-то, или направить на них свою определённую рекламную кампанию. Тоже достаточно часто применяется, особенно сейчас, потому что все бренды хотят работать с блогерами, хотят, чтобы продвигали их контент, а рекламные агентства не очень хотят контактировать (ну, бывает такое).
И реальный выход из этой ситуации – найти людей, которые не блогеры, не бьюти-блогеры, а например, какие-то реальные существа, которые взаимодействуют с этим брендом, могут в каком-нибудь убогом своём паблике «Мэйл.ру Ответы» написать, получить определённое количество просмотров. Эти люди, которые постоянно интересуются контентом этого человека, они всё это дело распространят, и бренд получит свою вовлечённость.
Второй вариант, как использовать подобную технологию сейчас, достаточно актуальный – это поиск ботов, моё любимое. Это и репутационный риск для ваших конкурентов, и возможность отсеять от рекламной кампании нерелевантных людей, и всё, что угодно (и удаление комментариев, и поиск связей между людьми). У меня есть такой пример, он тоже есть большой интерактивный – его можно подвигать. Это связи людей, которые писали комментарии в сообществе «Лентач».
Такой пример – для того, чтобы вы понимали, насколько хорошо и просто видно ботов; и для этого не нужно обладать каким-то техническими знаниями. Значит, «Лентач» выпустил пост о расследовании ФБК про Дмитрия Медведева, и определённые люди стали писать комментарии. Мы собрали всех людей, которые писали комментарии – эти люди зелёные. Сейчас подвину:

Люди – это зелёные (которые писали комментарии). Они есть здесь, они есть здесь. Голубые точки между ними – это их общие группы, жёлтые – общие подписчики, друзья и так далее. Вот основная масса людей связана между собой. Потому что, какая бы ни была теория трёх, четырёх, пяти рукопожатий, все люди связаны между собой в социальных сетях. Нет людей, которые отделены друг от друга. Даже мои друзья-социофобы, которые используют «Вконтакте» исключительно для просмотра видео, всё равно на какие-то одинаковые с нами паблики подписаны.
Навальный тоже использует ботов. Боты есть у всех
Основная масса людей (вот она, здесь) связаны между собой. Но есть такая маленькая группка товарищей, которая находится в друзьях исключительно друг у друга. Вот они, зелёненькие, вот их общие друзья и группы. Они даже отдельно здесь отвалились:

И по счастливой случайности именно эти люди именно под этим постом писали: «У Навального нет доказательств» и так далее, писали одинаковые комментарии. Выводы делать я, конечно, не берусь. Но тем не менее, у меня был другой пост в «Фейсбуке», когда были дебаты Лебедева и Навального, я точно так же анализировал комментарии: там получилось, что все люди, которые написали «Лебедев – говно», они не заходили в соцсети последние четыре месяца, не подписаны ни на один из пабликов, внезапно зашли именно в этот пост, написали именно этот комментарий и ушли. Выводы, опять, отсюда делать нельзя, но кто-то из команды Навального мне написал коммент, что ботов они не используют. Ну и ладно!
Ближе к рекламе, ближе к бренду. Боты сейчас есть у всех! Они есть и у нас, есть и у конкурентов, ещё у кого-то. Их надо выкидывать либо оставлять, чтобы они хорошо жили; на основании таких данных (указывает на предыдущий слайд) доводить их до совершенства, чтобы они выглядели как реальные люди и только тогда ими пользоваться. Хотя пользоваться ботами плохо! Тем не менее достаточно частая история…
В автоматическом режиме такая вещь позволяет отфильтровать из своего анализа людей нерелевантных для анализа, людей, которые не должны попасть в выборку, не должны попасть в это исследование. Очень часто используется. Опять же, не все владельцы автомобилей действительно являются владельцами автомобилей. Иногда интересны только люди, у которых есть потенциально автомобиль, которые сидят в каких-то группах, с кем-то общаются, у них там есть определённая аудитория.
Анализ фактов и мнений
Следующее, что у меня есть, тоже моё любимое. Это анализ фактов и мнений.

Упоминание о своём бренде в различных источниках сейчас умеют делать все. В этом нет никакого секрета. И тональность вроде все умеют считать… Хотя лично я считаю, что сама по себе метрика тональности не очень интересная, потому что, когда ты приходишь и говоришь клиенту, – «Мужик, у тебя 37% нейтрала, – и он такой говорит, – «Ничего себе! Круто!» Поэтому интереснее было бы двинуться чуть дальше: от оценки тональности до оценки мнений того, что о вашем продукте говорят.
И это тоже очень интересная вещь, потому что… Я лично считаю, что нейтральных сообщений в принципе быть не может, потому что, если человек что-то пишет в публичном пространстве, это сообщение по-любому как-то окрашено. Вот я лично никогда не видел нейтрального сообщения с упоминанием какого-то бренда. Обычно это какая-то грязь.
Если возьмём большое количество этих сообщений (их может быть миллионов, 10 миллионов), выделим из каждого сообщения главную мысль, объединим их, мы можем понять достаточно достоверно, что люди говорят об этом бренде, что они считают. «Мне не нравится упаковка», «Мне не нравится консистенция» и так далее.
Что думают о «Трансаэро», чупа-чупсе и президенте США
Смешной пример у меня есть такой: это инфографика о том, что бы сделали пользователи социальных сетей с компанией «Трансаэро» после её банкротства.

Там есть много интересных примеров: сжечь, убить, выслать в Европу, были даже 2%, которые написали – «Отправить их в Сирию на военные действия». Двигаясь от смешной штуки, это может быть любой бренд практически – начиная от моих любимых собачьих кормов, заканчивая какими-нибудь автомобилями. Кому не нравится упаковка, кому не нравятся реальные вещи – с этим всегда можно работать, с этим всегда можно считаться. Есть большое количество примеров, когда люди чуть ли не производство своей продукции меняли, потому что в соцсетях писали, что чупа-чупс недостаточно круглый или он недостаточно сладкий.
Есть ещё такой смешной пример. Догадайтесь, какие комментарии и про кого?

Почему-то сейчас именно анализ мнений, анализ фактов, выделяемых из сообщений, не очень используется, не очень широко распространён. Хотя эта технология не суперсекретная, в этом вообще практически нет никакого ноу-хау, потому что из комментариев людей выделить подлежащее, сказуемое и сгруппировать их – для этого не нужно быть гением компьютерной лингвистики. Это сделать не так сложно. Но я надеюсь, что в ближайшие пару лет люди начнут это использовать, потому что… Будет классно – это такой автоматический фидбек! Знаешь всегда, что про тебя говорят. Ну, вы поняли, что это про президента США сделано.
Ответ на вопрос из аудитории:
- Да, это «Фейсбук» англоязычный. Они здесь переведены на русский язык. Где-то это писалось.
Big Data и политтехнологии
На самом деле у меня есть много разных интересных примеров политиканских про Трампа и про всех остальных, но решили их сюда не приводить. Но политиканский пример есть один.
Это выборы в Госдуму. Когда были? В прошлом году? Почти полтора года назад.

Здесь люди, у которых удалось определить их точное местоположение, вплоть до определённой геоточки, чтобы понять, в какой они избирательный УИК попадают. А дальше из этих людей взяты только те, которые высказали своё определённое мнение, за кого они пойдут голосовать.
С точки зрения политтехнологий, это не очень правильно, потому что всё это дело нужно нормировать на плотность населения и так далее. Тем не менее синие здесь собираются голосовать сами знаете за кого, красные – за оппозиционных товарищей, которых было, кстати, не так много.
Я лично считаю, что Big Data до политтехнологий ещё очень нескоро дойдёт, но, как вариант, кандидат – тоже бренд. И это тоже в какой-то степени анализ фактов и мнений о своём бренде, и достаточно интересная вещь, потому что можно в реальном времени понимать, кто там про что делает. Я вот знаю несколько кейсов у BBC, когда они в режиме реального времени в какой-то трансляции мониторили соцсети: отклик такой-то, люди пишут про это, задавай такой-то вопрос – и это классно! Я думаю, что будет очень скоро применяться, потому что интересно всем.
Моделирование позиций брендов

Дальше у меня моделирование позиций брендов. Маленькая такая, короткая штука о том, как с помощью различных метрик (не лайков подписчиков в соцсетях, а с помощью комплексных метрик, интереса к контенту, времени, проведённого за получением метрик) можно ранжировать бренды.

У меня пример есть по «фарме» по определённой. Здесь маленькие кругляшки внутренние, яркие – это количество текстового контента, который создаёт сам бренд, большой кругляшок – это количество фото- и видеоконтента, который создаёт сам бренд.
Близость к центру показывает, насколько этот контент интересен аудитории. Там большая модель, есть куча всяких параметров: лайки, репосты, время отклика, кто там поделился в среднем… Здесь можно посмотреть: есть замечательный «Кагоцел», который вбухивает огромное количество денег в создание собственного контента, и они за счёт этого находятся достаточно близко к центру. А есть товарищи, которые тоже свой контент создают, но он аудитории неинтересен. Такой, не очень адекватный пример, потому что все эти аккаунты практически мёртвые.
Егора Крида любят больше Басты

К сожалению, остальные… из того, что показать… Вот, есть ещё русские рэперы, как вариант, из реальных компаний.
В чём плюс? В том, что компания может в такую модель заложить практически всё, что угодно, начиная от средней зарплаты подписчиков, которые сидят у тебя в бренде; любую модель, какая им нравится. Потому что каждое рекламное агентство собственные метрики считает по-разному, бренды собственные метрики считают по-разному.
Тут тоже есть такой – Баста, которые генерит большое количество контента, но при этом находится на периферии, потому что этот контент, видимо, не очень интересен аудитории. Опять же, судить я не берусь. Но тем не менее есть Егор Крид, который, по данным социальных сетей, вообще чуть ли не лучший исполнитель современности, а публикует при этом только свои личные фотографии. Тем не менее у него большое количество подписчиков: их где-то около миллиона человек. Я не помню точное количество; помню, что процент вовлечённости этих людей гораздо выше 85%, то есть на миллион подписчиков он получает 850 тысяч откликов этих реальных людей – это реальное сумасшествие. Это так.

Ответы на вопросы аудитории:
Сколько времени ушло на составление модели анализа рэперов?
- Для каждого взята своя целевая аудитория, свои интересы этих людей, для каждого посчитаны… Всё это нормировано на расстояние до центра примерно, радиальное их положение не важно (оно здесь просто для красоты размазано, чтобы они друг на друга не наезжали). Важна только примерная близость к центру. Это модель, которую мы используем. Мне, например, круг больше нравится, кто-то это делает в виду полукруга.
- Эта модель составлялась быстро, часа за два, за три (да, одного человека). Здесь исключительно метрики вставляли: что на что умножаем, складываем, дальше как-то нормируется. Зависит от модели. Бывают люди, которым интересна средняя зарплата (это не шутка) их подписчиков. А для этого нужно их контакты найти, «Авито», всё это посчитать, помножить. Бывает, такое долго считается, но конкретно это (указывает на предыдущий слайд) – здесь простые очень параметры: подписчики, репосты и так далее. Она делалась где-то два-три часа. Соответственно, эта вещь потом в реальном времени обновляется, ею можно пользоваться.
Теперь самое интересное. У меня с примерами всё, потому что неинтересно долго говорить одному. И я надеюсь, что вы сейчас будете задавать вопросы, и мы дальше, собственно, от темы к теме двинемся, потому что у меня такие примеры того, как технологии могут использоваться и так далее…
Ответы на вопросы аудитории:
- У меня был один-единственный личный кейс с одним, если так можно сказать, «околоказино», когда там ставилась камера, распознавались лица и так далее. Процент распознанных людей точно достаточно велик – что у нас, что у конкурентов. Но на самом деле это достаточно интересно. Я это вижу как интересную вещь: можно понять, кто эти люди, и достаточно хорошо спрогнозировать, почему именно они пришли сюда, что у них в жизни так изменилось, что они решили прийти в казино. Но насчёт конкретных видов бизнеса… Если ставить такую вещь в аптеке, то тут смысла нет – никак ты не спрогнозируешь, почему человек пришёл именно в аптеку.
Глобальная задача тут была – построить модель, для того чтобы понять, когда человек потенциально захочет заинтересовать твоим брендом, чтобы ему рекламу дать не после того, как он что-то купил (как это происходит сейчас), а рекламу ему дать «в прогноз» того, когда это всё это произойдёт. С таким «околоказино» было интересно; там получился достаточно интересный процент этих людей – почему: кто-то внезапно повышение получал, кто ещё-то что-то – интересные такие инсайты. А вот с какими-то магазинами, с ритейлом, с магазином каких-нибудь таблеток, мне кажется, будет не очень правильно.
Применяется ли Big Data в офлайне?
- В офлайне оно было. Надо только понимать точно, примерно – эта модель сойдётся, не сойдётся. Опять же, с водой газированной… Мне на самом деле всё интересно, но я лично не понимаю, насколько, как могут зависеть профили этих людей, их поведение от того, когда они захотят купить воду в бутылочках. Хотя это, может, действительно так, я не знаю.
Сколько открытых аккаунтов в соцсетях?
- У нас конкретно 11 соцсетей – это «Вконтакте», «Фейсбук», «Твиттер», «Одноклассники», «Инстаграм» и какие-то там мелочи (я могу посмотреть список, типа «Мэйл.ру» и так далее). «Вконтакте» у нас точно есть копия всех этих товарищей. У нас есть люди «Вконтакте» — это 430 миллионов всех, когда-либо существовавших (из них где-то 200 млн – постоянно активные); есть группы, есть связи между этими людьми и есть контент, который нас интересует (текстовый), и часть медиа, но очень маленькая… Грубо говоря, мы смотрим на эту картинку: если там есть лица – мы их сохраняем, если мемасик – мы его не сохраняем, потому что на сохранение медиаконтента даже у нас не хватило бы ничего.
Есть русскоязычный «Фейсбук». Где-то сейчас 60-80% — «Одноклассников», через пару месяцев мы их доберём, наверное, всех до конца. Русский «Инстаграм». Для всех этих соцсетей есть группы, люди, связи между ними и текст. - Около 400 миллионов человек. Есть тонкость: есть люди, у которых не указан город (они потенциально русские / нерусские); из них в среднем по соцсетям, вот – по «Вконтакте» 14% закрытых аккаунтов, в «Фейсбуке» не знаю точную цифру.
- В «Инстаграме» тоже не сохраняем медиа – исключительно, если только там лица есть. Такой (другой) медиаконтент мы не сохраняем. Обычно интересно: только текст, связи между людьми; всё. Самые частые исследования по «Инстаграму» — это обычные исследования по аудитории: кто эти люди, как и, самое важное здесь, связь этих людей с другими соцсетями. Найти профиль этого человека во «Вконтакте» и «Фейсбуке» для того, чтобы рассчитать его возраст и так далее.
- Нет пока надобности брать всех остальных – просто потому, что нет заказчиков. По поводу языка: у нас есть русский, английский, испанский, но всё равно это используется пока исключительно для брендов из России; ну, или компаний, которые ведут их из России.
- Мы ежедневно во много-много-много потоков опрашиваем людей: собираем мы данные, собирая веб, а обновляем эти показатели, используя Api. За 2-3 дня можно пройти весь «Вконтакте», прошерстив их; где-то за неделю можно пройти весь «Фейсбук», поняв у кого там что обновилось, что – нет. А дальше уже этих людей отдельно пересобрать: что конкретно изменилось, записать всю эту историю. На моей памяти очень редко для какой-то реальной бизнес-задачи был использован чей-то старый профиль в социальных сетях. Это было раз, когда обращался один политический деятель, и его задачей было понять, что за люди приходят в штаб, кем эти люди были 6-8 месяцев назад (не удалили ли они свой профиль, а на самом деле за другого кандидата, пришли бюллетени портить).
И пару раз – личные истории, когда чьи-то фотографии в открытом доступе опубликовали. Необходимо было связи найти и т. д. К сожалению, очень жалко, но в суде мы свидетельствовать не можем, потому что наша база юридически неликвидная. - Хранилище MongoDB – моё самое любимое.
Соцсети пытаются вести борьбу со сбором данных
- Обычно мы рекламодателям выгружаем исключительно список этих аккаунтов, а дальше они используют стандартную… То есть в социальных сетях, во «Вконтакте» там, можно список этих людей указать.
Но для «Фейсбука» используются «куки» купленные. Мы сами с «куками» не работаем, но было несколько историй, когда рекламодатель сам давал каких-то людей, мы с ними взаимодействовали – у них есть сети вот эти вот, с тизерной, не тизерной рекламой, эти «куки». Привязать можно – не вопрос! Но я не очень люблю эти штуки, потому что считаю, что это не очень достоверно. Это чисто на мой взгляд, это как TNS, которая «тречит» телевизоры – непонятно, смотришь ты этот телевизор, не смотришь, посуду ты моешь, пока у тебя телевизор работает… И здесь то же самое: я очень часто что-то гуглю в интернете, но это не значит, что я хочу это купить. - Если вы используете стандартную какую-то сеть контекстной рекламы: у меня было несколько историй, когда мы им выгружали этих людей, пытались с помощью их интерфейсов перевязать их с «куками» на их сайтах. Но я не очень люблю такие вещи.
Формула вычисления зарплаты интернет-пользователя
- Общая формула для средней зарплаты: это регион, где человек проживает, это категория бизнеса, в которой работает он (то есть компания, которая является его работодателем), дальше его берётся его должность в этой компании, прикидывается средняя зарплата на этой должности… Средняя зарплата берётся с «Хед-Хантера» и «Суперджоба» (и там несколько ещё источников) для данной вакансии в данном регионе и для данного контекста бизнеса.
С «Авито» и «Авто.ру» обычно берутся дополнительные параметры, если человек засветил телефон. С «Авито» можно посмотреть, какие вещи человек продаёт – дорогие, недорогие, б/у, не б/у. С «Авто.ру» можно посмотреть, есть ли у него автомобиль – владеет он, не владеет. Это где-то менее 20% людей, которые случайно где-то уронили свой телефон, и их аккаунт можно с этими данными перевязать.
Какими объёмами оперирует компания, занятая сбором данных?
- Объём хранящихся фотографий в петабайтах – 6,4. Скорость роста сейчас точно сказать не могу, потому что в 2016 году мы начали «перископы» записывать и чуть-чуть начали записывать видео.
Я не могу точно сказать, когда был ноль. Мы из компании в компанию переходили – всё это долгие такие истории. Но могу сказать, что ВК, «Фейсбук», «Инстаграм» и «Твиттер» — всё это дело (люди, группы и связи между ними) с текстом и контентом – это на самом деле не так много данных, вряд ли там даже петабайт набрался. Я думаю, что это гигабайт 700, наверное, 800.
Помогаете клиентам определить актуальную нишу, куда «копать»?
- Когда клиент приходит, мы такие вещи ему подсказываем, но сами, как «Гугл Трендс», такими вещами не занимаемся.
- У нас было несколько историй околосоциологических, с выборной, предвыборной историей – мы это всё анализировали. С брендами и оценкой мнений о брендах практически всегда всё сходится. Вот выборные-предвыборные истории – нет (с оценкой, какой кандидат должен выиграть). Уж кто здесь не прав – мы, или те, кто считает во ВЦИОМе – не знаю.
- Обычно мы берём у самого бренда эти контрольные результаты, они это берут у товарищей, которые заказывают исследования – телефонные там, маркетинговые и так далее. Плюс, это всё дело можно проверить с элементарными вещами: кто-то там на рассылку отвечал, кто-то опросы… Если это крупный бренд («Кока-Кола», например), у них есть обязательно миллион-два внутренних своих отзывов от клиентов – это не только комментарии в соцсетях и какие-то мнения; это внутренние какие-то системы, отзывы и так далее.
Закон не «знает», что такое персональные данные!
- Мы анализируем исключительно открытые источники данных, никогда ни в какую грязную чернуху не лезем. Модель наша построена на том, что все открытые данные мы храним в каких-то публичных дата-центрах, ещё где-то арендуем, а анализируем у себя, на территории офисов, в своих серверах, и никуда это за территорию не выходит.
Но наше законодательство в сфере открытых данных весьма расплывчатое.
У нас нет чёткого понимания, что такое открытые данные, что такое персональные – есть этот 152-й ФЗ, но всё равно… Они считают как? Вот, если у меня в одной базе есть ваше имя и ваш телефон, в другой базе у меня есть ваш телефон и ваш e-mail, в третьей есть, скажем, ваш e-mail и ваш автомобиль; всё это – вроде как не персональные данные. Если это всё вместе соединить, вроде как по закону это станет персональными данными.
Мы обходим это двумя способами. Первый – это ставим клиенту сервера с софтом, и тогда эти данные не выходят за его территорию, и тогда клиент несёт ответственность за распространение этих персональных данных, не персональных данных и так далее. Либо второй вариант: если это какая-то история, где придётся судиться с соцсетью или ещё что-то…
У нас было такое исследование, когда мы собирали (был праймериз «Единой России») для «Лайфньюс» аккаунты этих товарищей и смотрели, какое они порно лайкают. Смешная штука была, но тем не менее. Мы продаём это как наше собственное, личное мнение, не раскрывая юридически в документах, что мы анализировали – ЕГРЮЛ, зарплату, социальные сети; продаём экспертное мнение, а там уже в кулуарах человеку объясняем, что мы анализировали и как.
Было несколько историй, но они были связаны с какими-то публичными коммерческими проектами. Например, у нас есть свободные некоммерческий проект для тех, кто катается на лонгбордах (такие доски длинные): задача была собирать публикации людей – когда кто-то постит «Я поехал в парк Горького кататься». И вот он должен попасть на карту, и люди вокруг него могут увидеть, что кто-то рядом с ним. ВК очень долго бодалась с нами на эту тему, потому что им не нравилось, что мы без разрешения людей публикуем эту информацию. Но до суда тогда дело не дошло, потому что мы внутри нескольких крупных сообществ в правила дописали, что данные могут использоваться сторонними, агентствами, компаниями, анализы и т. д. Конечно, не особо этично было, но тем не менее. - Мы просто очень вовремя спохватились и начали всем продавать экспертное мнение.
С образовательными заведениями работаете?
- С образовательными сотрудничаем, да. У нас есть целый ряд: у нас в Высшей школе есть магистратура, с другими ВУЗами мы сотрудничаем. ВУЗы мы очень любим!
- Есть контакты мои – можно написать. И ссылочка на презентацию, если кому будет интересно – там все эти примеры, можно двигать.
- Если известны телефон, почта – это почти стопроцентный вариант, никто не уберёт. Если телефона нет – обычно это картинка, картинки нет – это год, место жительства, работа. То есть по году, месту жительства и работе практически всех всегда можно идентифицировать достаточно тонко. Но это, опять же, вопрос о задаче.
Есть у нас, скажем, клиент, который продаёт интернет-телевидение. Вот у них кто-то купил подписку на эти «Игры престолов», и задача – из их CRM найти этих людей в социальных сетях, а потом найти потенциальных из их ареала влияния. Я просто к тому, что у них есть, скажем, имя, фамилия и e-mail… И дальше очень сложно поэтому что-то сделать. По e-mail’у можно найти примерно в большинстве случаев людей. - По составу друзей мы людей соцсетями обычно «мэтчим», но это не всегда правильно. Не то, что не всегда правильно – это не всегда работает. Во-первых, для этого нужны большие трудозатраты, потому что эту операцию (по мэтчингу людей) придётся провести сначала для каждого из друзей – понять, перешли ли они из соцсетей, или нет. А потом – ни для кого не неизвестный факт, что «Вконтакте» у нас одни друзья, в «Фейсбуке» у нас другие друзья. Не у всех, но у меня, например, так; и у большинства людей это тоже так.
Как собирают максимально полные данные?
- Установкой софта клиенту на его сторону. Ставится к ним сервер, который забирает от нас только публичные данные, а внутри обрабатывает их персональные. С клиентом заключается NDA. Это, конечно, не очень правильно, что они нам это передают, но юридическая ответственность возлагается на клиента – ну, то есть установкой софта ему, либо передача анонимных данных. Но это было очень редко, потому что – правильные, неправильные анонимизации – теряется в большинстве случаев зависимость между этими людьми.
Кто покупает ПО для распознавания лиц?
- Мы на самом деле сюда идём, потому что у нас основной софт, который мы продаём, – это поиск по лицам, анализ взаимосвязей, – и продаём это государственным органам. И полтора года назад мы решили, что все эти истории засунем в рекламу, в маркетинг, в публичный рынок – так образовалась Social Data Hub, коммерческое юрлицо. И вот мы сюда только сейчас приходим. Полтора года тут уже тусуемся, пытаемся людям объяснить, что не нужно людям выгрузки давать с упоминанием, что нужно им ответы на вопросы давать, что не нужно там тональности и так далее. Так что сложно сказать, куда…
- (Кого вы имеете в виду?) Всяким товарищам, которым нужно искать террористов, педофилов.
Могу сразу сказать (это следующий вопрос будет): никаких учителей, по нашим данным, за репост не посадили. - Во «Вконтакте» – 14%, в «Фейсбуке» нет как такового закрытого профиля (там бывает закрытый список друзей и так далее). И самое интересное, я вот сейчас написал сообщение – сейчас посчитают и скажут.
Не публикуйте то, за что будет стыдно!
- Не постить в соцсети ничего, за что будет стыдно – я лично этим руководствуюсь. Хотя у меня было много личных таких, потому что я матом ругаюсь в «Фейсбуке». Ну, было и было, что поделать… Не постить ничего, за что будет стыдно! Если вы собираетесь потом куда-то в Общественную палату работать – да, лучше не комментировать. Если вы не собираетесь этого делать – по большому счёту, всем наплевать. Могу только заверить, что никто не читает вашу личную переписку, и всё это нагнетание всей этой истории…
Ко мне еженедельно точно обязательно кто-нибудь приходит и говорит: «Вот, у меня там у друга фотографии вылили в паблик какой-то анонимный! Помоги!» Кстати, никогда не публикуйте ничего в анонимные паблики. - Я не знаю, как остальные мониторинговые системы – мы точно это учтём, что упоминание бренда было негативное, прости господи… Но могу сказать, что всякие окологосударственные товарищи интересуются только людьми, у которых больше 5 тысяч аудитория, и их общественное мнение может на кого-то повлиять. В моей практике ни разу такого не было, чтобы HR-агентство, которое заказывает у нас оценку профилей, сказало: «Кто Навального лайкает – мне никого не берите»!
О публикации результатов. Сколько людей занято в исследованиях?
- Из топ-10 рекламных компаний сейчас семь публикуют. Сложно сказать: когда мы полтора года назад это начали… У нас есть по несколько человек в каждой сфере – в банках есть несколько человек, в HR-ах есть несколько человек, есть несколько человек в рекламщиках. И вот мы сейчас думаем, к кому выгоднее идти первым, под кого нужно начинать интерфейсы какие-то делать…
- (о количестве людей на сегмент рынка) Не больше 25 человек, потому что мы никого не насиловали.
- Вообще, в принципе эти технологии с рынка используют, я думаю, больше 50 %. Кто в рекламных кампаниях, кто в какой-то внутренней аналитике. Я бы сказал, что процентов 40 используют это во внутренней аналитике, 50-60 % продают это для конечных брендов. Но это уже зависит от самих рекламных компаний. Понимаете, кто-то отчитывается просто за потраченные деньги, подкрученную рекламу, а кто-то пишет, действительно сколько людей привели, какую аудиторию… Я бы сказал так, но я могу ошибаться – не очень себе представляю, как все эти товарищи работают. Знаю только в количественных данных.
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Комментарии (9)

WTFRU7
02.01.2020 09:39+1Это всё интересно смотреть, и да, каждому на ум придёт, что по фотке того или иного пользователя неплохо было бы иметь информацию о его машине, а, соответсвенно, вычислять примерный его материальный статус. Понятно, что можно такое сделать, натренировать нейронную сеть и тд, но пока что из этих рассказов у меня создаётся впечатление набора фантастических сплетен — хотелось бы знать, что это и правда реализовано в виде программного решения, которое работает.
fivehouse
02.01.2020 13:38+1хотелось бы знать, что это и правда реализовано в виде программного решения, которое работает
Ну, вы же понимаете, что все защищено NDA. Даже от целого ГЕНЕРАЛЬНОГО ДИРЕКТОРА! Но точно можно сказать, что все уже реализовано как минимум в виде слайдов презентации. Также из статьи складывается представление, что какой либо целостной или структурированной картины в голове у перца нет даже в его фантазиях.sshikov
02.01.2020 18:55>Также из статьи
Из трех, я бы сказал. Если поискать на хабре две предыдущие — то из них ровно такое же впечатление складывается.
lotse8
02.01.2020 13:37Я всегда говорил, что пользоваться соцсетями — это писать товарищу майору доносы на самого себя. Но многим это нравится. И можно только догадываться, какие интересные досье на политиков и бизнесменов всех стран собирают спецслужбы США по фейсбукам и твиттерам, да и гугл еще неплохо им в этом помогает.

Eirik
02.01.2020 14:13+2Фраза «14 марта 2017 года в лектории BBDO выступил Артур Хачуян» — значит что эта статья по технологиям 2х летней давности?
ChePeter
02.01.2020 16:15+1Почему то все апологеты нынешнего Датасайнс уверены, что если 9 рыжих усатых пришли и купили квартиру, то десятый точно купит с вероятностью 9/10. Хотя это на самом деле неизвестно — не то, что неверно или верно, а именно неизвестно. Или если знать, что человек говорил, писал, слушал, кушал, пил и т.д. последние несколько дней, то можно точно определить, что он купит сегодня через 10 минут — например можно предсказать операции брокеров NYSE. (это тоже одна из основных легенд и мифов этого дела)
Но лекции Артур Хачуян читает прекрасные и великолепно!
Ark_V
02.01.2020 16:15Но сейчас, объединяя различные источники, можно понять средний уровень вашей зарплаты, сколько стоит ваша квартира, где она находится. И все эти данные можно использовать буквально из подручных средств.
А разве это не противоречит 152-ФЗ в части запрета объединения баз данных, содержащих персональные данные, обработка которых осуществляется в целях, несовместимых между собой?
И разным прочим его положениям вплоть до того, что информация в общедоступные источники персональных данных должна включаться с письменного согласия субъекта персональных данных?
И это еще не новомодный GDPR.
vzhicharra
03.01.2020 14:15Ну хорошо, я отследил конкретных людей, я хочу показать им рекламу своего стирального порошка.
Разве фейсбук позволяет таргетировать конкретных персон?
Я могу указать — вот именно ему ему и ему показывать?
stalker1984
Ну конечно же в биоинформатике не настоящая бигдэйта, ага. Точка зрения зависит от позиции наблюдателя.