
Вообще-то смотреть какого цвета потроха у Rust я не собирался. Ковырнул хобби-проект на Go, пошел на GitHub посмотреть состояние fasthttp: развивается ли? Ну хотя бы поддерживается? Вспрокрастинулось. Пошел, посмотрел где fasthttp сидит в бенчмарках TechEmpower. Смотрю: а там fasthttp едва показывает половину того, что удаётся лидеру — какому-то actix на каком-то Rust. Какая боль.
Здесь бы мне сложить ручки, стукнуть головой в пол (трижды) и закричать: "Алилуйя, воистину Rust — истинный бог, как слеп я был раньше!". Но то ли ручки не сложились, то ли лоб пожалел… Вместо этого полез в код тестов, написанных на Go и actix-web тестов на Rust. Чтобы разобраться.
Через пару часов узнал:
- почему Rust-фреймворк actix-web занимает первые позиции во всех тестах TechEmpower,
- как в Java заводится Script.
Сейчас всё расскажу по порядку.
Что за TechEmpower Framework Benchmark?
Если веб-фреймворк демонстрирует, собирается или, скажем, иногда задумывается о том, чтобы шепнуть знакомым "я — быстр", то он наверняка попадет в TechEmpower Framework Benchmark. Популярное такое место на сходить померяться производительностью.
У сайта своеобразный дизайн: вкладки фильтров, раундов, условий и результатов по разным типам тестов разбросаны по странице щедрой рукой. Настолько щедрой и размашистой, что их просто не замечаешь. Но щелкать по вкладкам стоит, информация за ними прячется полезная.
Легче всего попасть на результаты тестов plaintext, "Hello World!" для веб серверов. Авторы фреймворка обычно дают ссылку именно на него: мы, мол, в первой сотне держимся. Дело правильное и полезное. Вообще отдавать plaintext получается хорошо у многих, и лидеры идут плотной группой.
Рядом, в тех самых табах, прячутся результаты тестов других типов (сценариев). Всего их семь, подробнее посмотреть можно здесь. Эти сценарии тестируют не только то, как фреймворк/платформа справляется с обработкой простого http-запроса, но комбинацию с клиентом базы данных, шаблонизатором или JSON-сериализатором.
Есть данные тестов в виртуальной среде, на физическом железе. Кроме графиков есть табличные данные. В общем много интересного, стоит порыться, не просто глянуть позицию "своей" платформы.
Первое, что пришло мне в голову после того, как прошелся по результатам тестов: "А почему всё НАСТОЛЬКО отличается от plaintext?!". В plaintext лидеры идут плотной группой, но когда дело доходит до работы с базой данных, actix-web лидирует со значительным отрывом. При этом показывает стабильное время обработки запроса. Шайтан.
Еще одна аномалия: невероятно производительное решение на JavaScript. Называется ex4x. Оказалось, его код чуть менее чем полностью написан на Java. Используется Java runtime, JDBC. Код на JavaScript транслируется в байткод и склеивает Java библиотеки. Вот буквально взяли — и пристроили Script к Java. Хитростям бледнолицых нет предела.
Как посмотреть код и что там внутри
Код всех тестов есть на GitHub. Всё — в монорепозитории, что очень удобно. Можно клонировать и смотреть, можно смотреть прямо на GitHub. В тестировании участвует больше 300 различных комбинаций фреймворка с сериализаторами, шаблонизаторами и клиентом базы данных. На разных языках программирования, с разным подходом к разработке. Реализации на одном языке находятся рядом, можно сравнить с реализацией на других языках. Код поддерживается сообществом, это не работа одного человека или коллектива.
Код бенчмарков — отличное место для расширения кругозора. Разбирать как разные люди решают одни и те же задачи интересно. Кода не очень много, используемые библиотеки и решения легко выделить. Вот совсем не жалею, что туда забрался. Многое узнал. Прежде всего о Rust.
До того о Rust у меня было очень смутное представление. К любой статье о C, C++, D и особенно Go обязательно пристраивается пара-тройка комментаторов, подробно и с надрывом объясняющих, что суета, ерунда и глупость писать на чём-то другом, пока на свете есть Гасконь Rust. Иногда увлекаются настолько, что приводят примеры кода, чем человека неподготовленного или мало принявшего вгоняют в ступор: "Зачем, зачем, ЗАЧЕМ все эти символы?!"
Потому открывать код было страшновато.
Посмотрел. Оказалось, что программы на Rust можно читать. Более того, читается код настолько хорошо, что я даже установил Rust, попробовал тест скомпилировать и немного с ним повозиться.
Тут чуть не забросил это дело, потому что компиляция длится долго. Очень долго. Будь я Д’Артаньяном или хотя бы просто холериком — рванул бы в Гасконь, и тысяча чертей уныло потянулась бы следом. Но я справился. Чаю опять же попил. Кажется, даже не одну чашку: на моём ноутбуке первая компиляция заняла минут 20. Дальше, правда, всё идёт веселее. Возможно, до следующего большого обновления crates.
А разве дело не в самом Rust?
Нет. Не в языке программирования дело.
Конечно же Rust — язык замечательный. Мощный, гибкий, пусть с непривычки и многословный. Но сам по себе язык писать быстрый код не будет. Язык — один из инструментов, одно из решений, принятых программистом.
Как я говорил — отдавать plaintext быстро получается у многих. Производительность фреймворков actix-web, fasthttp и еще десятка других при обработке простого запроса вполне сравнима, то есть техническая возможность поконкурировать с Rust у других языков есть.
Вот сам actix-web, конечно "виноват": быстрый, прагматичный, отличный продукт. Сериализация удобная, шаблонизатор хороший — тоже очень помогают.
Заметнее всего отличаются результаты тестов, работающих с базой данных.
Немного покопавшись в коде, я выделил три основных отличия, которые (как мне кажется) помогли тестам actix оторваться от конкурентов в синтетических тестах:
- Конвейерный (pipelined) режим работы tokio-postgres;
- Использование одного соединения тестом на Rust вместо пула соединений тестом, написанным на Go;
- Обновление бенчмарками actix нескольких записей одной командой, отправляемой по упрощенному протоколу (simple query), вместо отправки нескольких команд UPDATE.
Что еще за конвейерный режим?
Вот фрагмент из документации tokio-postgres (используемого в бенчмарке клиентской библиотеки PostgreSQL), объясняющий что её разработчики имеют в виду:
Sequential Pipelined
| Client | PostgreSQL | | Client | PostgreSQL |
|----------------|-----------------| |----------------|-----------------|
| send query 1 | | | send query 1 | |
| | process query 1 | | send query 2 | process query 1 |
| receive rows 1 | | | send query 3 | process query 2 |
| send query 2 | | | receive rows 1 | process query 3 |
| | process query 2 | | receive rows 2 | |
| receive rows 2 | | | receive rows 3 | |
| send query 3 | |
| | process query 3 |
| receive rows 3 | |Клиент в pipelined (конвейерном) режиме не ждёт ответа PostgreSQL, а отсылает следующий запрос, пока PostgreSQL обрабатывает предыдущий. Видно, что так можно обработать ту же последовательность запросов к базе данных ощутимо быстрее.
Если соединение в конвейерном режиме будет дуплексным (обеспечивающее возможность получения результатов параллельно с отправкой), это время может еще немного сократиться. Кажется, уже есть экспериментальная версия tokio-postgres, где открывается именно дуплексное соединение.
Поскольку на каждый SQL-запрос, отправленный на выполнение, клиент PostgreSQL отправляет несколько сообщений (Parse, Bind, Execute и Sync), и получает на них ответ, конвейерный режим будет эффективнее даже при обработке одиночных запросов.
А почему в Go не так?
Потому что в Go обычно используются пулы соединений с базой данных. Соединения не предполагается использовать параллельно.
Если запустить те же SQL-запросы через пул, а не одно соединение, то с обычным последовательным клиентом теоретически можно получить даже меньшее время их выполнения, чем при работе через одно соединение, будь оно трижды конвейерным:
| Connection | Connection 2 | Connection 3 | PostgreSQL |
|----------------|----------------|----------------|-----------------|
| send query 1 | | | |
| | send query 2 | | process query 1 |
| receive rows 1 | | send query 3 | process query 2 |
| | receive rows 2 | | process query 3 |
| | receive rows 3 | |
Выглядит так, будто овчинка (конвейерный режим) выделки не стоит.
Только вот при высокой нагрузке количество соединений с сервером PostgreSQL может быть проблемой.
А при чём тут вообще количество соединений?
Тут дело в том как сервер PostgreSQL реагирует на увеличение количества подключений.
Левая группа столбцов демонстрирует взлёт и падение производительности PostgreSQL в зависимости от количества открытых соединений:
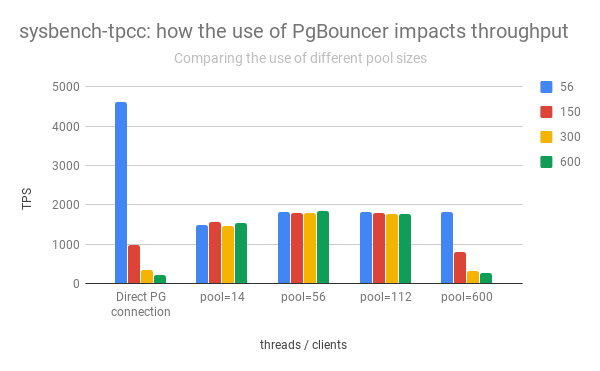
Видно, что при увеличении количества открытых соединений производительность сервера PostgreSQL стремительно падает.
Кроме того, открытие прямого соединения — не "бесплатно". Сразу после открытия клиент отсылает служебную информацию, "договаривается" с сервером PostgreSQL о том, как будут обрабатываться запросы.
Поэтому на практике приходится ограничивать количество активных соединений с PostgreSQL, часто дополнительно пропуская их через pgbouncer или еще какой odyssey.
Так почему actix-web оказался быстрее?
Во-первых сам actix-web чертовски быстр. Именно он задаёт "потолок", и он чуточку выше, чем у других. Другие использованные библиотеки (serde, yarde) тоже очень, очень производительны. Но мне кажется, что в тестах, работающих с PostgreSQL удалось оторваться потому, что сервер actix-web запускает один поток на ядро процессора. В каждом потоке открывается всего одно соединение с PostgreSQL.
Чем меньше активных подключений — тем быстрее работает PostgreSQL (см. графики выше).
Клиент, работающий в конвейерном режиме (tokio-postgres), позволяет эффективно использовать одно соединение с PostgreSQL для параллельной обработки пользовательских запросов. Обработчики http-запросов сваливают свои SQL-команды в одну очередь и выстраиваются в другую — на получение результатов. Результаты весело разгребаются, задержки минимальны, все счастливы. Общая производительность выше, чем у системы с пулом соединений.
Так нужно отказаться от пула, написать конвейерный клиент PostgreSQL, и сразу придёт счастье и скорость невероятная?
Возможно. Но не всем и сразу.
Когда конвейерный режим вряд ли спасет и уж точно не сохранит
Схема, использованная в коде бенчмарка не будет работать с транзакциями PostgreSQL.
В бенчмарке транзакции не нужны и код написан с учетом того, что транзакций не будет. На практике они случаются.
Если код бэкэнда открывает транзакцию PostgreSQL (например, чтобы сделать изменение в двух разных таблицах атомарным), все команды, отправленные через это соединение, выполнятся внутри этой транзакции.
Поскольку соединение с PostgreSQL используется параллельно, в него валится всё вперемешку. К тем командам, которые должны выполниться в транзакции по замыслу разработчика, подмешаются sql-команды, инициированные параллельными обработчиками http-запросов. Получим случайную потерю данных и проблемы с их целостностью.
Так что здравствуй транзакция — прощай параллельное использование одного соединения. Придётся позаботиться о том, чтобы соединение не использовалось другими обработчиками http-запросов. Нужно будет либо остановить обработку входящих http-запросов до закрытия транзакции, либо для транзакций использовать пул, открывая несколько соединений с сервером БД. Реализации пула для Rust есть, и не одна. Более того, они в Rust существуют отдельно от реализации клиента базы данных. Можно выбирать по вкусу, цвету, запаху или наугад. В Go так не получается. Сила дженериков (generics), ага.
Важный момент: в тесте, код которого я смотрел, транзакции не открываются. Там этот вопрос просто не стоит. Код бенчмарка оптимизирован под конкретную задачу и вполне конкретные условия работы приложения. Решение об использовании одного подключения на поток сервера принято наверняка осознанно и оказалось очень эффективным.
Есть в коде бенчмарка еще что-то интересное?
Да.
Сценарий, по которому проводится измерение производительности, прописан очень подробно. Как и критерии, которым должен удовлетворять код, участвующий в тестах. Одним из них является то, что все запросы к серверу базы данных должны выполняться последовательно.
Следующий (слегка сокращенный) фрагмент кода выглядит так, будто критерию этому не удовлетворяет:
let mut worlds = Vec::with_capacity(num);
// Отправляем num однотипных запросов к PostgreSQL
for _ in 0..num {
let w_id: i32 = self.rng.gen_range(1, 10_001);
worlds.push(
self.cl
.query(&self.world, &[&w_id])
.into_future()
.map(move |(row, _)| {
// ...
}),
);
}
// Ждём завершения всех запросов
stream::futures_unordered(worlds)
.collect()
.and_then(move |worlds| {
// ...
})Выглядит всё как типичный запуск параллельных процессов. Но, поскольку используется одно соединение с PostgreSQL, запросы к серверу базы данных отправляются последовательно. Один за другим. Как и требуется. Никакого криминала.
Почему так? Ну, во-первых, в коде (он приведен в редакции, отработавшей в 18 раунде) еще не используется async/await, он появился в Rust позже. А через futures num SQL-запросов отправить проще "параллельно" — так, как в коде выше. Это позволяет получить некоторый дополнительный прирост производительности: пока PostgreSQL принимает и обрабатывает первый SQL-запрос, ему скармливаются остальные. Веб-сервер не ждёт результат каждого, а переключается на другие задачи и возвращается к обработке http-запроса только когда все SQL-запросы выполнены.
Для PostgreSQL бонус в том, что однотипные запросы в одном контексте (подключении) идут подряд. Вероятность, что план запроса не будет перестраиваться, повышается.
Получается, преимущества конвейерного режима (см. диаграмму из документации tokio-postgres) вовсю эксплуатируется даже при обработке единичного http-запроса.
Что еще?
Использование упрощенного протокола (simple query) для пакетного обновления
Протокол обмена информацией между клиентом и сервером PostgreSQL допускает альтернативные способы выполнения SQL-команд. Обычный (Extended Query) протокол предполагает отправку клиентом нескольких сообщений: Parse, Bind, Execute и Sync. Альтернативой является упрощенный (Simple Query) протокол, по которому для выполнения команды и получения результатов достаточно одного сообщения — Query.
Ключевым отличием обычного протокола является передача параметров запроса: они передаются отдельно от самой команды. Так безопаснее. Упрощенный протокол предполагает, что все параметры SQL-запроса будут преобразованы в строку и включены в тело запроса.
Интересным решением, использованным в бенчмарках actix-web, было обновление нескольких записей таблицы одной командой, отправляемой по протоколу Simple Query.
По условиям бенчмарка при обработке пользовательского запроса веб-сервер должен обновить несколько записей в таблице, записать случайные числа. Очевидно, что обновлять записи по очереди последовательными запросами дольше, чем одним запросом, обновляющим все записи разом.
Запрос, формируемый в коде теста, выглядит примерно так:
UPDATE world SET randomnumber = temp.randomnumber FROM (VALUES (1, 2), (2, 3) ORDER BY 1) AS temp(id, randomnumber) WHERE temp.id = world.idГде (1, 2), (2, 3) — пары идентификатор строки/новое значение поля randomnumber.
Количество обновляемых записей переменно, подготавливать (PREPARE) запрос заранее нет смысла. Поскольку данные для обновления — числовые, и источнику можно доверять (сам код теста), то риска SQL injection нет, данные просто включаются в тело SQL и всё отправляется по протоколу Simple Query.
Вокруг Simple Query ширятся слухи. Мне встречалась рекомендация: "Работайте только по Simple Query протоколу, и всё будет быстро и хорошо". Я воспринимаю её с большой долей скептицизма. Simple Query позволяет уменьшить количество сообщений, отсылаемых серверу PostgreSQL за счёт переноса обработки параметров запроса на сторону клиента. Виден выигрыш для динамически формируемых запросов с переменным числом параметров. Для однотипных SQL-запросов (которые встречаются чаще) выигрыш не очевиден. Ну и то, насколько безопасной получится обработка параметров запроса, в случае Simple Query определяет реализация клиентской библиотеки.
Как я писал выше, в данном случае тело SQL запроса формируется динамически, данные числовые и генерируются самим сервером. Идеальная комбинация для Simple Query. Но даже в этом случае стоит протестировать другие варианты. Альтернативы зависят от платформы и клиента PostgreSQL: pgx (клиент для Go) даёт возможность отправить пакет команд, JDBC — выполнить одну команду несколько раз подряд с разными параметрами. Оба решения могут работать с той же скоростью или даже оказаться быстрее.
Так почему Rust лидирует?
Лидирует, конечно же, не Rust. Лидируют тесты на основе actix-web — именно он задаёт "потолок" производительности. Есть еще, например, rocket и iron, занимающие скромные позиции. Но на текущий момент именно actix-web определяет потенциал использования Rust в веб разработке. Как по мне — потенциал очень высокий.
Другой неочевидный, но важный "секрет" сервера на основе actix-web, позволивший занять первые места во всех бенчмарках TechEmpower — в том, как он работает с PostgreSQL:
- Открывается всего одно соединение с PostgreSQL на поток веб-сервера. В этом соединении используется конвейерный режим, позволяющий эффективно использовать его для параллельной обработки пользовательских запросов.
- Чем меньше активных подключений — тем быстрее отвечает PostgreSQL. Скорость обработки пользовательских запросов увеличивается. При этом под нагрузкой вся система работает устойчивее (задержки при обработке входящих запросов ниже, растут они медленнее).
Там, где важна скорость, такой вариант работы наверняка будет быстрее, чем при использовании мультиплексоров (таких как pgbouncer и odyssey). И уж точно он оказался быстрее в бенчмарках.
Очень интересно как async/await, появившийся в Rust, и недавняя драма с actix-web повлияют на популярность Rust в веб разработке. А еще интересно как изменятся результаты тестов после переработки их на async/await.











PsyHaSTe
Спасибо, хороший анализ, пару комментариев по статье.
Я сейчас работаю на проекте, которму скоро 5 лет будет, и за всё это время мы только сейчас начали задумываться что возможно нам нужны транзакции в некоторых новых сценариях. До этого за всё это время они были не нужны. А вот вопросы производительности нас интересуют, поэтому нам такой режим работы как раз-таки очень подошел бы. Я не говорю, что так везде — у меня была куча проектов где без транзакций никак, но требования — разные везде, и отсутствие транзакций — не самая редкая вещь которая может случиться.
Это вообще одна из основных оптимизаций, я когда провожу ревью всегда обращаю внимание на
awaitв цикле и прошу переписать на формирование массива запросов и единоразовое ожидание всех ответов. Это базовая оптимизация, и учитывая что она еще и идеологически правильнее, то не знаю в чем тут может быть претензия. Только так и надо посылать массив запросов. Может понадобиться побить на чанки, чтобы не заддосить шлюз, но принцип остается тем же.Риска SQL injection нет не потому, что тесту можно доверять, а потому что все нормальные ORM умеют эскейпить аргументы чтобы этого не произошло. Поэтому воспользоваться этим чтобы вместо расширенного (и не нужного в большинстве простых сценариев) протокола использовать сокращенный — совершенно логично.
Это аргумент в пользу того, чтобы научить приложения работать с одним соединением вместо пула, а не ругать актикс что они там считерили с соединенями.
Если это сильно повлияет на производительность — от этого могут отказаться.
DarthVictor
При работе с одним соединением долгий запрос к базе разве не будет блокировать все остальные запросы к базе? Хотя тут больше вопросы к «критерии, которым должен удовлетворять код, участвующий в тестах».
Вообще в тестах Techempower значительная часть участников имеет в графе ORM «Raw» то есть встроенной проверки на инъекцию не имеют. Но опять же тут вопросы к авторам тестов. Где запросы по id = «105; DROP TABLE Main --», где кривые запросы отчетов на несколько секунд? Где хотя бы не вовремя запустившийся вакуум?
blind_oracle
Для защиты от инъекций не нужен никакой ORM. Нужно просто использовать placeholder-ы которые предоставляет либа БД и не клеить запросы вручную.
PsyHaSTe
Орм не нужен для защиты, это просто еще один плюс от его использования. У меня была пара проектов где было запрещено использовать орм, и писались мегатонны хрупчайшего кода уровня
Который ломался чуть ли не каждую неделю потому что где-то либо тип столбца поменялся, либо их порядок немного нарушился.
Так что скажу наоборот: лучше использовать возможности ОРМ и получать бесплатную производительность за счёт использования облегченного протокола запросов.
DarthVictor
От инъекций можно защищаться по разному, тут вопрос в том что эта защита с точки зрения производительности может иметь какой-то оверхед. И в тестах было бы не плохо это отразить. Потому что если этого не требовать, то фреймворки без встроенной защиты будут иметь преимущество в тестах. Хотя в реальных приложениях (где эту защиту допишут) преимущества не будет.
В принципе у TechemPower есть колонка с типом ORM (Raw, Micro и Full) и возможно сравнивать имеет смысл только внутри одного класса.
blind_oracle
Мне кажется что эскейпинг контрольных символов в переменных это не самая трудоемкая задача. Общение с БД, сетевое и дисковое лэтенси, вот это всё будет на порядки сильнее влиять на скорость работы.
PsyHaSTe
Ну на картинке видно что запросы по одному соединению продолжают идти пока ответ ответ еще не получен, так что долгий запрос ничего тормозить не должен. Про трейдофы разных режимов открытия соединений думаю лучше посмотреть в документации постгреса, но по крайней мере на нагрузках схожих с бенчем я бы ожидал профита именно от такого формата.
Ну, создайте им issue, возможно они учтут ваши пожелания.
creker
Идут запросы, но не ответы, которые придут только последовательно. Если я правильно понимаю идею, то здесь борьба за то, чтобы пропихнуть в сокет сразу несколько запросов, не дожидаясь ответа на первый. Это не значит, что база эти запросы все параллельно выполнять начнет. Они их выполнит так же, как если бы слали по одному. Поэтому таки получается, что запросы друг друга блокируют. И если ответ на первый запрос идет долго, то все остальные будут его ждать. Я очень сомневаюсь, что постгре на уровне протокола может в то, что умеет HTTP2, когда в одном TCP соединении несколько логических каналов.
PsyHaSTe
Ну, собственно я и сделал референс на документацию постгре. Но вывод остается прежним: по крайней мере на нагрузках схожих на бенчмарк результаты будут тоже схожи.
creker
Все равно очень странно делать такую хрупкую схему. Это получается, что два параллельных клиента к нашему HTTP серверу, допустим, пойдут через одно PG соединение. И если один из запросов какой-то кривой, и ответ на него долго идет, то повлияет это на оба HTTP запроса. Между клиентами все таки должна быть изоляция хоть какая-то.
mayorovp
Кто бы ещё на стороне СУБД такую изоляцию сделал. Я регулярно наблюдал как сложный запрос останавливает сервер. Хотя это была вина не столько СУБД, сколько админов, разместивших СУБД и сервер приложений вместе.
Gorthauer87
Если запрос на чтение, то это еще можно как то представть, а вот если запись, то скорее всего запросу в какой то момент нужна будет блокировка, как ни крути.
Politura
Почему ненужного? Я уже давно не следил за развитием баз данных, но много лет назад параметрические запросы использовали не сколько для защиты от иньекций, сколько для производительности.
Когда на сервер приходит запрос, он делает следующее:
1. Смотрит, есть ли такой запрос в кеше запросов, если есть но параметры другие, берет план запроса ис кеша и исполняет под новые параметры. Если нет, то идет дальше:
2. Парсит запрос
3. Составляет план выполнения запроса, основываясь на правилах, на статистике индексов и тд.
4. Выполняет запрос.
5. Помещает его в кеш запроса, а т.к. кеш не резиновый, то оттуда выкидывается что-то, что лежало раньше.
Если мы не используем параметрические запросы, то для сервера все запросы будут всегда разные и он всегда будет делать шаги 1-5. Если использовать параметрические запросы, то на горячей базе чаще будет выполняться только шаг 1.
Ну я не исключаю, что мое понимание устарело и сервера теперь парсят запросы выкидывая из них значения и заменяя их параметрами перед тем как работать с кешем запросов и теперь нет большой разницы: параметрический запрос, или нет, но есть сомнения этому.
PsyHaSTe
Ну, тут я могу ответить классикой — чтобы оценить производительность нужно проводить профилирование. Я уверен, что есть запросы, которые от параметричности только выигрывают. Не спорю.
Но увы, без профилирования те которые выигрывают от тех которые проигрывают отличать не могу.
Druu
Тот же EF, насколько я помню, запросы по дефолту делает parameterized. Так, что, видимо, подавляющее большинство запросов выигрывает.
andreyverbin
Все верно вы понимаете, simple query подойдет когда у вас запросы динамические. Если же запрос один и тот-же, то потенциал simple query для такой ситуации будет сильно ниже.
Jef239
По мере развития техники компы становятся быстрее, размеры СУБД — больше, а скорость дисков настолько сильно не растет (кроме скачка с SSD). В итоге чем дальше — тем меньше времени занимает компиляция и составление плана.
И шаг 4, занимающий 99% времени.Politura
Горячая база потому и горячая, что частоиспользуемые данные уже лежат в кэше в озу, а не на диске.
leporo Автор
Спасибо, отличный комментарий!
Да!
Вальяжное вступление, возможно, сбивает с толку. Мне НРАВИТСЯ actix, я в восторге от того, насколько уместны, точны и осмысленны те технические решения, которые я увидел в коде.
В бенчмарках actix нет чита. Есть условие проведения бенчмарка — запросы к БД должны выполняться последовательно. В тексте я процитировал код, который может человеком, привыкшим к работе с пулом соединений, восприниматься как параллельный. Это не так.