
В статье описывается процесс оптимизации инфраструктуры хранения данных компании среднего класса.
Рассмотрены обоснования для такого перехода и краткое описание процесса настройки новой СХД. Приводим в пример плюсы и минусы перехода на выбранную систему.
Инфраструктура одного из наших заказчиков состояла из множества разнородных систем хранения данных разного уровня: от SOHO-систем QNAP, Synology для пользовательских данных до Entry и Mid-range систем хранения уровня Eternus DX90 и DX600 для iSCSI и FC для служебных данных и систем виртуализации.
Всё это различалось как по поколениям, так и по применяемым дискам; часть систем представляла из себя legacy оборудование, не имевшее поддержки вендора.
Отдельной проблемой было управление свободным местом, так как всё доступное дисковое пространство было сильно фрагментировано по множеству систем. Как следствие – неудобство администрирования и высокая стоимость содержания парка систем.
Перед нами встала задача оптимизации инфраструктуры хранения данных с целью снижения стоимости владения и унификации.
Поставленная задача была всесторонне проанализирована экспертами нашей компании с учётом требований заказчика к доступности данных, IOPS, RPO/RTO, а также возможности модернизации существующей инфраструктуры.
Основными игроками на рынке систем хранения данных уровня Mid-Range (и выше) являются IBM с продуктом Storwize; Fujitsu, представленная линейкой Eternus, и NetApp с серией FAS. В качестве системы хранения, удовлетворяющей заданным требованиям, и были рассмотрены эти системы, а именно: IBM Storwize V7000U, Fujitsu Eternus DX100, NetApp FAS2620. Все три являются Unified-СХД, то есть предоставляют как блочный доступ, так и файловый, и обеспечивают близкие показатели производительности.
Но в случае с Storwize V7000U файловый доступ организован через отдельный контроллер – файловый модуль, подключаемый к основному блочному контроллеру, являющийся дополнительной точкой отказа. Кроме того, данная система относительно сложна в управлении, и не предоставляет должной изоляции сервисов.
Система хранения Eternus DX100, также являясь Unified системой хранения, имеет серьёзные ограничения на количество создаваемых файловых систем, не давая необходимой изоляции. Кроме того, процесс создания новой файловой системы занимает продолжительное время (до получаса). Обе описанные системы не позволяют разделять используемые CIFS/NFS-сервера на сетевом уровне.
С учётом всех параметров, включая совокупную стоимость владения системы, была выбрана NetApp FAS2620, состоящая из пары контроллеров, работающих в режиме Active-Active, и позволяющая распределять нагрузку между контроллерами. А в сочетании во встроенными механизмами online-дедупликации и компрессии позволяет значительно сэкономить на месте, занимаемом данными на дисках. Эти механизмы становятся значительно эффективнее при агрегации данных на одной системе по сравнению с исходной ситуацией, когда потенциально идентичные данные располагались на разных системах хранения и дедуплицировать их между собой было невозможно.
Такая система позволила расположить под управлением единого отказоустойчивого кластера все типы сервисов: SAN в виде блочных устройств для виртуализации и NAS в виде CIFS, NFS shares для пользовательских данных Windows и *nix-систем. При этом осталась возможность безопасного логического разделения этих сервисов благодаря технологии SVM (Storage Virtual Machine): службы, ответственные за разные компоненты, не влияют на «соседей» и не позволяют получить доступ к ним.
Также остаётся возможность изолировать сервисы на дисковом уровне, не допуская проседания производительности при большой нагрузке со стороны «соседей».
Для сервисов, требующих быстрого чтения/записи, можно использовать гибридный тип RAID-массива, добавив к HDD-агрегату несколько SSD. Система сама расположит на них «горячие» данные, снизив задержки чтения часто используемых данных. Это в дополнение к NVRAM-кэшу, обеспечивающему кроме высокой скорости записи её атомарность и целостность (данные будут храниться в NVRAM, питаемом аккумулятором, до тех пор, пока от файловой системы не будет получено подтверждение их полной записи) на случай внезапного отказа питания.
После миграции данных на новую СХД появляется возможность более эффективного использования места кеширующих дисков.
Как было упомянуто выше, использование данной системы позволило решить сразу две задачи:
— Унификация
— Изоляция
— Масштабируемость
— Сведя все сервисы под управление одной системы мы ожидаемо получаем большее влияние от отключения одного компонента (1 из 2 контроллеров против 1 из 10+ в старой инфраструктуре).
— Уменьшилась распределённость инфраструктуры хранения. Если раньше СХД могли располагаться на разных этажах/в разных зданиях, то теперь всё сконцентрировано в одной стойке. Этот пункт может быть нивелирован покупкой менее производительной системы и использованием синхронной/асинхронной репликации на случай форс-мажорных ситуаций.
По причине конфиденциальности информации скриншоты из реальной среды заказчика продемонстрировать невозможно, поэтому шаги по настройке приведены в тестовой среде и полностью повторяют шаги, выполненные в продуктивной среде заказчика.
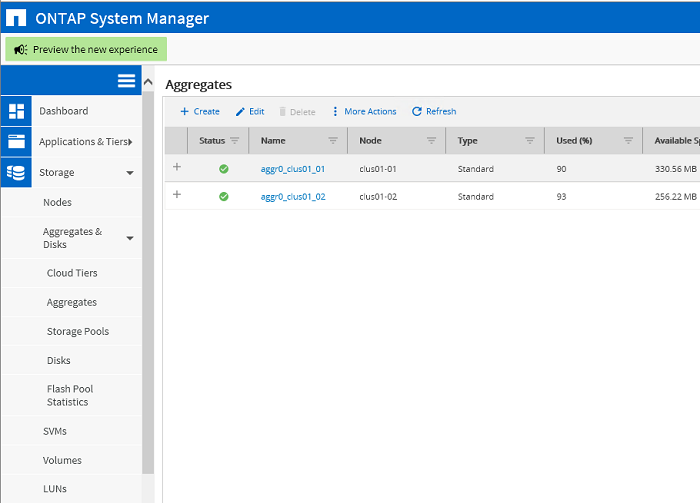
Начальное состояние кластера. Два агрегата для root-партиций соответсвтующих нод clus01_01, clus01_02 кластера
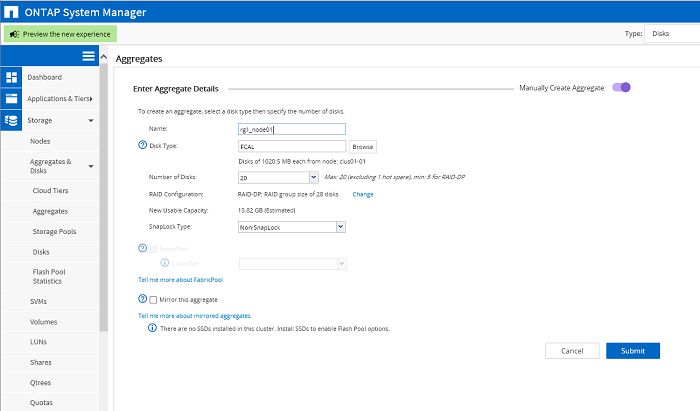
Создание агрегатов для данных. Для каждой ноды создан свой агрегат, состоящий из одного RAID-DP массива.
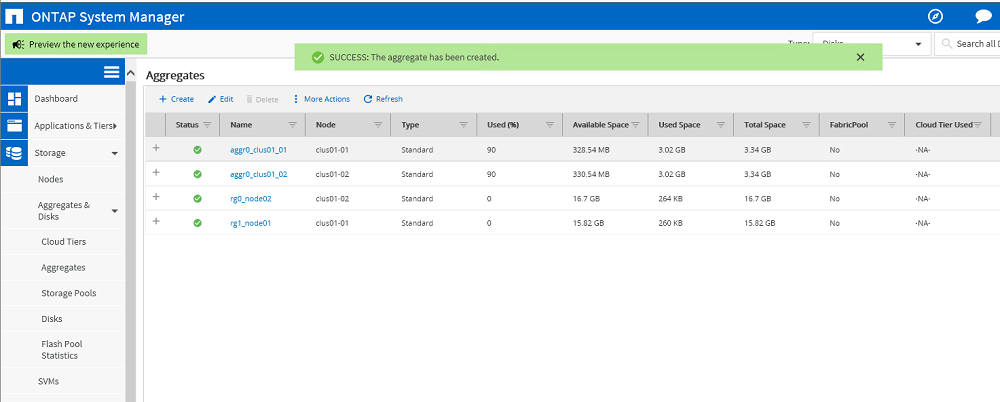
Итог: создано два агрегата: rg0_node02, rg1_node01. Данных на них пока нет.

Создание SVM в качестве CIFS-сервера. Для SVM обязательно создать root volume, для которого выбирается root aggregate — rg1_node01. В этом волюме будут храниться индивидуальные настройки SVM.
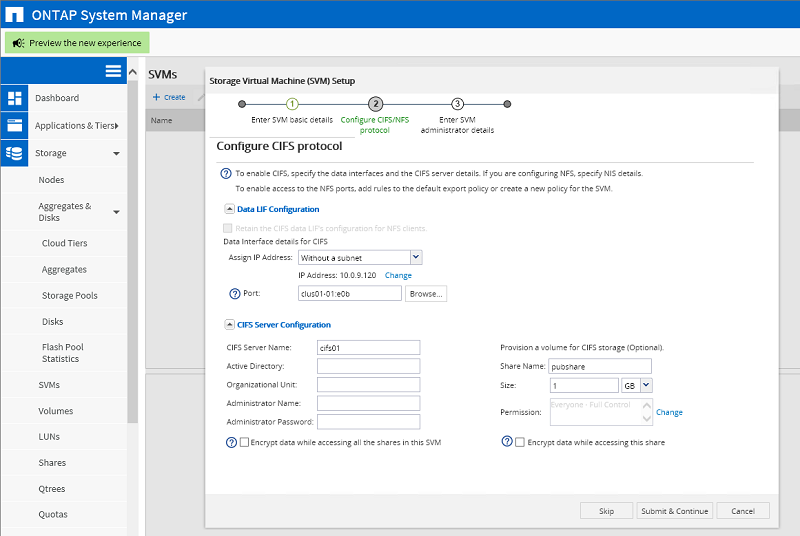
Конфигурирование CIFS-протокола данного SVM. Здесь задаётся IP-адрес сервера и физ.интерфейс, через который должен ходить трафик сервера. В качестве порта может быть выбран VLAN-порт, либо агрегированный LACP порт. На этом же шаге создаётся Volume для хранения данных, и общая папка, которая будет доступна по сети для пользователей.

После добавления пользовательских данных в общую папку, автоматические механизмы компрессии и дедупликации демонстрируют следующую эффективность. Фактически занятое на сервере место оказалось в 4,9 раза меньше, чем суммарный размер файлов. Реальный фактор сжатия зависит от типа записанных данных.
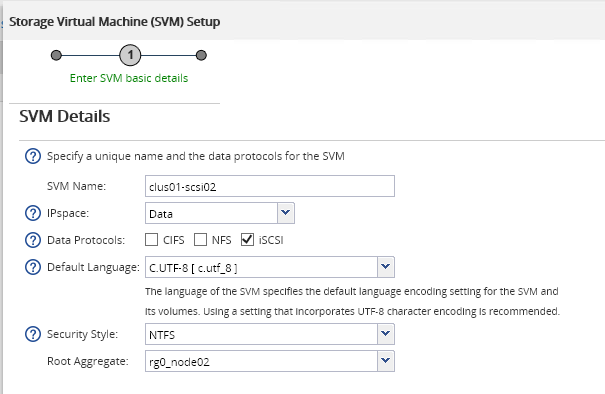
Создание SVM в качестве iSCSI-таргета. Аналогично выбирается агрегат, на котором будет расположен Root Volume данного сервера. На втором шаге данного Мастера по аналогии с CIFS-сервером задаётся IP-адрес виртуального интерфейса iSCSI-сервера, физ.порт для него, а также блочное устройство (LUN), которое будет презентовано инициатору.

Готовый LUN размером 10 ГБ. Ему следует задать группу инициаторов, которым он должен быть доступен.

Группа инициаторов состоит из одного Hyper-V Server с указанным внизу iqn.
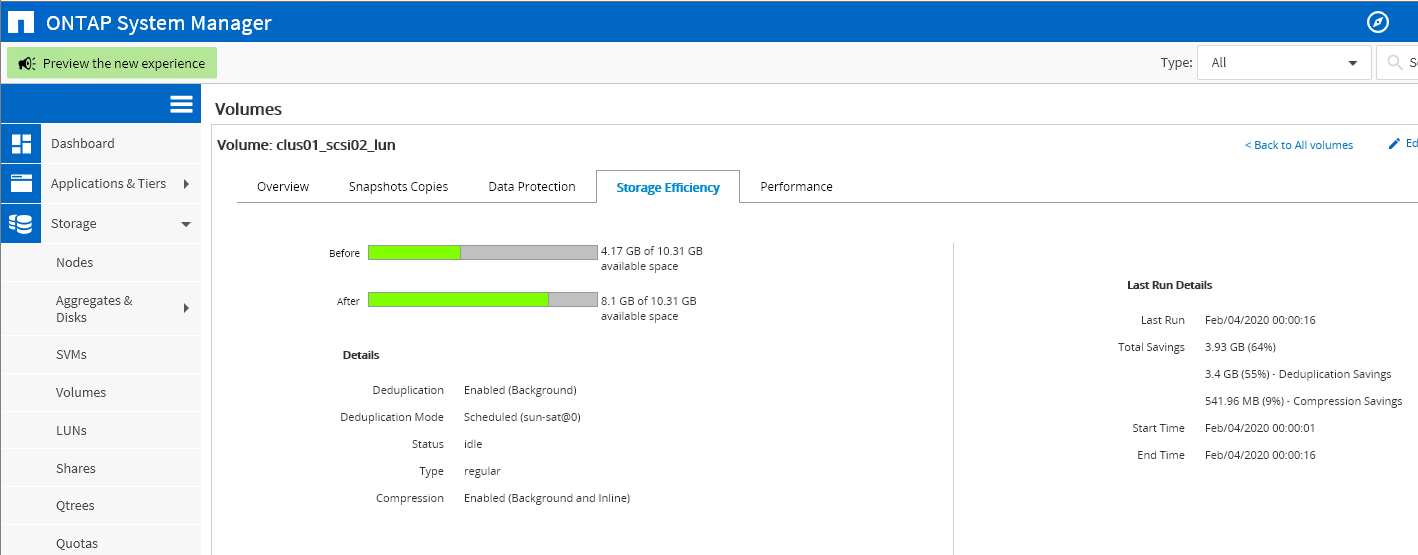
В примонтированном к Hyper-V Server LUN был создан файл жёсткого диска для виртуальной машины Linux. После выполнения регулярной оптимизации данные внутри Volume, расположенном на СХД, были сжаты более, чем в два раза. Если бы в данном LUN было больше однотипных виртуальных машин, то итоговые показатели экономии были бы ещё выше.
Рассмотрены обоснования для такого перехода и краткое описание процесса настройки новой СХД. Приводим в пример плюсы и минусы перехода на выбранную систему.
Введение
Инфраструктура одного из наших заказчиков состояла из множества разнородных систем хранения данных разного уровня: от SOHO-систем QNAP, Synology для пользовательских данных до Entry и Mid-range систем хранения уровня Eternus DX90 и DX600 для iSCSI и FC для служебных данных и систем виртуализации.
Всё это различалось как по поколениям, так и по применяемым дискам; часть систем представляла из себя legacy оборудование, не имевшее поддержки вендора.
Отдельной проблемой было управление свободным местом, так как всё доступное дисковое пространство было сильно фрагментировано по множеству систем. Как следствие – неудобство администрирования и высокая стоимость содержания парка систем.
Перед нами встала задача оптимизации инфраструктуры хранения данных с целью снижения стоимости владения и унификации.
Поставленная задача была всесторонне проанализирована экспертами нашей компании с учётом требований заказчика к доступности данных, IOPS, RPO/RTO, а также возможности модернизации существующей инфраструктуры.
Внедрение
Основными игроками на рынке систем хранения данных уровня Mid-Range (и выше) являются IBM с продуктом Storwize; Fujitsu, представленная линейкой Eternus, и NetApp с серией FAS. В качестве системы хранения, удовлетворяющей заданным требованиям, и были рассмотрены эти системы, а именно: IBM Storwize V7000U, Fujitsu Eternus DX100, NetApp FAS2620. Все три являются Unified-СХД, то есть предоставляют как блочный доступ, так и файловый, и обеспечивают близкие показатели производительности.
Но в случае с Storwize V7000U файловый доступ организован через отдельный контроллер – файловый модуль, подключаемый к основному блочному контроллеру, являющийся дополнительной точкой отказа. Кроме того, данная система относительно сложна в управлении, и не предоставляет должной изоляции сервисов.
Система хранения Eternus DX100, также являясь Unified системой хранения, имеет серьёзные ограничения на количество создаваемых файловых систем, не давая необходимой изоляции. Кроме того, процесс создания новой файловой системы занимает продолжительное время (до получаса). Обе описанные системы не позволяют разделять используемые CIFS/NFS-сервера на сетевом уровне.
С учётом всех параметров, включая совокупную стоимость владения системы, была выбрана NetApp FAS2620, состоящая из пары контроллеров, работающих в режиме Active-Active, и позволяющая распределять нагрузку между контроллерами. А в сочетании во встроенными механизмами online-дедупликации и компрессии позволяет значительно сэкономить на месте, занимаемом данными на дисках. Эти механизмы становятся значительно эффективнее при агрегации данных на одной системе по сравнению с исходной ситуацией, когда потенциально идентичные данные располагались на разных системах хранения и дедуплицировать их между собой было невозможно.
Такая система позволила расположить под управлением единого отказоустойчивого кластера все типы сервисов: SAN в виде блочных устройств для виртуализации и NAS в виде CIFS, NFS shares для пользовательских данных Windows и *nix-систем. При этом осталась возможность безопасного логического разделения этих сервисов благодаря технологии SVM (Storage Virtual Machine): службы, ответственные за разные компоненты, не влияют на «соседей» и не позволяют получить доступ к ним.
Также остаётся возможность изолировать сервисы на дисковом уровне, не допуская проседания производительности при большой нагрузке со стороны «соседей».
Для сервисов, требующих быстрого чтения/записи, можно использовать гибридный тип RAID-массива, добавив к HDD-агрегату несколько SSD. Система сама расположит на них «горячие» данные, снизив задержки чтения часто используемых данных. Это в дополнение к NVRAM-кэшу, обеспечивающему кроме высокой скорости записи её атомарность и целостность (данные будут храниться в NVRAM, питаемом аккумулятором, до тех пор, пока от файловой системы не будет получено подтверждение их полной записи) на случай внезапного отказа питания.
После миграции данных на новую СХД появляется возможность более эффективного использования места кеширующих дисков.
Положительные стороны
Как было упомянуто выше, использование данной системы позволило решить сразу две задачи:
— Унификация
- Один кластер в едином шасси, состоящий из двух контроллеров, позволяющий решать весь спектр задач, встающих перед компанией.
- Единая точка управления всеми сервисами хранения данных. Больше не нужно искать, с какой СХД отдан LUN, куда какие данные можно мигрировать в случае нехватки места и так далее.
- Единая точка обслуживания. Теперь используются однотипные диски, вставленные в общую дисковую полку. Система смонтирована в одну стойку, уменьшая необходимое количество Ethernet и Fiber Channel кабелей и свитчей.
- Так как новый кластер имеет доступ ко всем хранящимся данным, появляется возможность эффективно сжимать данные, выискивая одинаковые блоки в них. Наиболее эффективно это работает для виртуальных машин и бэкапов.
— Изоляция
- Используемая в NetApp технология SVM (Storage Virtual Machine), как уже было сказано выше, позволяет разграничить сервисы, сохранив при этом плюсы унификации. Теперь для каждой задачи можно создать отдельный SVM, который будет решать свою задачу. Предоставлять данные только по одному протоколу только строго заданным пользователям/сервисам.
- Изоляция на сетевом уровне.
Каждый SVM использует свой собственный виртуальный сетевой интерфейс, который использует строго заданную группу физических портов, либо VLAN-интерфейсов. Таким образом, даже если один через один и тот же физический порт идёт трафик разных SVM, этот трафик находится в разных VLAN’ах. То есть, сетевой порт СХД является trunk-портом.
Выделяются группы портов для iSCSI-трафика, чтобы разделить высокую сетевую SAN-нагрузку от пользовательского трафика вплоть до того, что отдельным системам можно зарезервировать отдельный физический порт, «не деля» его ни с кем.
- Изоляция на уровне дисковой подсистемы.
В типичной реализации создаётся минимально возможное кол-во RAID-групп (максимизация количества дисков в одной RAID-группе увеличивает производительность массива), на которых затем создаются отдельные файловые системы в виде Volume. Volume назначается SVM’ам, таким образом обеспечивается недоступность данных между SVM’ами в случае компрометации. А в случае заполнения «волюма» одним сервисом, «волюмы» других SVM’ов не пострадают.
В отдельных случаях по требованиям безопасности создаются выделенные RAID-группы для особо критичных данных, чтобы гарантированно изолировать данные даже на физическом уровне.
— Масштабируемость
- По мере роста объёма данных без сложных манипуляций добавляется необходимое количество дисковых полок без остановки сервиса. Новые диски сразу доступны обоим контроллерам для расширения имеющихся RAID-групп, либо для создания новых.
- Рост количества сервисов может привести к нехватке вычислительных ресурсов системы (CPU, RAM). В таком случае к имеющемуся кластеру можно добавить ещё одну storage-ноду, включив её в существующий кластер, расширив количество IO-интерфейсов, объём памяти и отказоустойчивость в нём.
- NetApp поддерживает S3-совместимые объектные хранилища как в качестве сторонних сервисов, так и предоставляя свои продукты для создания объектного хранилища on-premise для хранения холодных данных, архивов.
Отрицательные стороны
— Сведя все сервисы под управление одной системы мы ожидаемо получаем большее влияние от отключения одного компонента (1 из 2 контроллеров против 1 из 10+ в старой инфраструктуре).
— Уменьшилась распределённость инфраструктуры хранения. Если раньше СХД могли располагаться на разных этажах/в разных зданиях, то теперь всё сконцентрировано в одной стойке. Этот пункт может быть нивелирован покупкой менее производительной системы и использованием синхронной/асинхронной репликации на случай форс-мажорных ситуаций.
Пошаговая настройка
По причине конфиденциальности информации скриншоты из реальной среды заказчика продемонстрировать невозможно, поэтому шаги по настройке приведены в тестовой среде и полностью повторяют шаги, выполненные в продуктивной среде заказчика.
Начальное состояние кластера. Два агрегата для root-партиций соответсвтующих нод clus01_01, clus01_02 кластера
Создание агрегатов для данных. Для каждой ноды создан свой агрегат, состоящий из одного RAID-DP массива.
Итог: создано два агрегата: rg0_node02, rg1_node01. Данных на них пока нет.
Создание SVM в качестве CIFS-сервера. Для SVM обязательно создать root volume, для которого выбирается root aggregate — rg1_node01. В этом волюме будут храниться индивидуальные настройки SVM.
Конфигурирование CIFS-протокола данного SVM. Здесь задаётся IP-адрес сервера и физ.интерфейс, через который должен ходить трафик сервера. В качестве порта может быть выбран VLAN-порт, либо агрегированный LACP порт. На этом же шаге создаётся Volume для хранения данных, и общая папка, которая будет доступна по сети для пользователей.
После добавления пользовательских данных в общую папку, автоматические механизмы компрессии и дедупликации демонстрируют следующую эффективность. Фактически занятое на сервере место оказалось в 4,9 раза меньше, чем суммарный размер файлов. Реальный фактор сжатия зависит от типа записанных данных.
Создание SVM в качестве iSCSI-таргета. Аналогично выбирается агрегат, на котором будет расположен Root Volume данного сервера. На втором шаге данного Мастера по аналогии с CIFS-сервером задаётся IP-адрес виртуального интерфейса iSCSI-сервера, физ.порт для него, а также блочное устройство (LUN), которое будет презентовано инициатору.
Готовый LUN размером 10 ГБ. Ему следует задать группу инициаторов, которым он должен быть доступен.
Группа инициаторов состоит из одного Hyper-V Server с указанным внизу iqn.
В примонтированном к Hyper-V Server LUN был создан файл жёсткого диска для виртуальной машины Linux. После выполнения регулярной оптимизации данные внутри Volume, расположенном на СХД, были сжаты более, чем в два раза. Если бы в данном LUN было больше однотипных виртуальных машин, то итоговые показатели экономии были бы ещё выше.

DrunkBear
Простите, Dell EMC и HPE настолько мелки, а доля их на рынке СХД так мала, что даже вспоминать про них не стоит?
Да и сжатие весьма спорно при больших объемах записи.